
访问控制日志驱动的ABAC策略自动提取与优化增强
2024-03-05 11:03:11夏桐袁凌云车兴亮陈美宏
计算机应用研究 2024年2期
夏桐 袁凌云 车兴亮 陈美宏


收稿日期:2023-06-05;修回日期:2023-07-24 基金项目:国家自然科学基金资助项目(62262073);云南省应用基础研究计划资助项目(202101AT070098);云南省万人计划青年拔尖人才项目(YNWR-QNBJ-2019-237);云南省重大科技专项计划资助项目(202202AE090011)
作者简介:夏桐(1998—),女,河南信阳人,硕士研究生,主要研究方向为访问控制、可解释机器学习;袁凌云(1980—),女(通信作者),云南昭通人,教授,博导,CCF高级会员,主要研究方向为物联网安全、区块链、传感器网络(blues520@sina.com);车兴亮(1995—),男,云南楚雄人,硕士研究生,主要研究方向为图神经网络;陈美宏(1999—),女,湖北恩施人,硕士研究生,主要研究方向为区块链、联邦学习.
摘 要:为解决基于属性的访问控制(ABAC)策略自动提取的低质量问题,提出一种基于访问控制日志驱动的ABAC策略自动提取与优化增强方法。首先,构建集成学习模型,将用户行为和权限分配映射为策略逻辑树,识别访问授权决策的关联性及潜在规律,初步生成策略;其次,通過单属性优化和规则二元约简两种方法深度优化策略,简化策略结构并压缩策略规模;最后,提出基于误差度量的规则冲突解决方法,以增强互斥、完备的ABAC策略,并进一步基于多目标优化的策略性能平衡算法实现不同场景需求的最优模型选择。分别在平衡数据集和稀疏数据集上进行测试和验证,实验结果表明,该方法在平衡数据集上的准确性最高可达96.69%,可将策略规模压缩至原来的19.7%。在稀疏数据集上的准确性最高可达87.74%,可将策略规模压缩至原来的23%。此方法兼顾策略的预测精度与结构的简洁性,同时适用于平衡日志和稀疏日志,确保访问控制系统在实际应用中能够实现高效、安全的访问授权管理。
关键词:基于属性的访问控制; 策略提取; 策略增强; 集成学习; 多目标优化
中图分类号:TP311;TP309.2 文献标志码:A
文章编号:1001-3695(2024)02-041-0587-09
doi:10.19734/j.issn.1001-3695.2023.06.0232
Automatic extraction and optimization enhancement of ABAC policy driven by access control log
Xia Tonga, Yuan Lingyuna,b, Che Xinglianga, Chen Meihonga
(a.College of Information Science & Technology, b.Key Laboratory of Educational Information for Nationalities, Ministry of Education, Yunnan Normal University, Kunming 650500, China)
Abstract:To address the low-quality problem of automatic extraction of ABAC policies, this paper proposed an automatic extraction and optimization enhancement method of ABAC policies driven by access control logs. Firstly, the method constructed an ensemble learning model to map user behavior and permission allocation into a policy logic tree, identifying the relevance and underlying patterns of access authorization decisions to generate preliminary policies. Secondly, the method employed two algorithms of single attribute optimization and rule binary reduction to deeply optimize the policies, simplifying policy structure and compressing policy scale. Finally, the method proposed an error metric-based rule conflict resolution approach to enhance mutually exclusive, complete ABAC policies. Furthermore, the method used policy performance balancing algorithm of a multi-objective optimization to achieve the optimal model selection for different scenario requirements. This paper tested and verified on balanced datasets and sparse datasets respectively, the experimental results demonstrate that the method achieves a highest accuracy of 96.69% on the balanced dataset, compresses the policy scale to 19.7% of the original. On the sparse dataset, the highest accuracy reaches 87.74%, with the policy scale compresses to 23% of the original. This method balances the prediction accuracy and structural simplicity of policies, and is applicable for both balanced logs and sparse logs, ensuring the access control system can implement efficient and secure access authorization management in practical applications.
Key words:attribute-based access control(ABAC); policy extraction; policy enhancement; ensemble learning; multi-objective optimization
0 引言
信息安全领域中,访问控制技术是防止未授权访问以及保护敏感信息和关键资源不被滥用的重要手段[1]。随着企业规模和信息系统复杂性的增加,传统的访问控制模型已无法满足实际需求。为此,基于属性的访问控制(ABAC)模型应运而生。相较于传统模型,ABAC模型以属性为基础实施细粒度的访问控制,更能满足多元化的安全需求[2]。实现ABAC模型需要定义和生成策略,但手动编写策略往往困难且易出错,因其涉及众多因素,如用户身份、资源属性及上下文信息等[3]。因此,自动化策略提取技术成为简化策略开发、快速部署ABAC模型的关键。此技术基于统计学习和人工智能算法,通过分析历史访问日志数据,自动识别和生成精细化的访问控制策略,提高策略的实时性和准确性[4~6]。该自动化和动態调整机制减轻了对人工干预的依赖,降低了无授权访问和误操作引发的数据泄露风险,使企业能够及时应对各种网络环境和业务需求的变化,实现持续的数据安全保护。
尽管众多学者对ABAC策略自动提取技术进行了深入研究[7~12],但在某些方面仍存在局限性。例如,ABAC策略规则由一组正负属性过滤器组成,负向过滤器在需要表达例外情况时尤为重要,但大多技术无法支持挖掘包含负过滤器的授权规则。当面对稀疏日志,即某类访问请求事件在整体日志数据中的分布极为分散时,如何有效挖掘高质量的访问控制策略成为一大挑战。此外,现有方法缺乏初次策略提取后对策略进行优化的技术,会导致策略过度拟合访问日志数据,且精度低、复杂性高,以及解释性差等问题。为解决上述问题并提高策略的实用性及易理解性,深入优化和增强策略显得尤为重要。此类优化不仅能提升策略的执行效率和可维护性,还能有效降低因错误配置或冲突导致的安全风险。现阶段,ABAC策略优化和增强方法已有所进展,如策略简化[13~15]、负向规则的支持[16]以及可解释性和审查性的提高[17],但仍需解决策略冗余和冲突、平衡策略准确性和简洁性,以及面对大规模ABAC环境下策略生成和管理等问题。
由此,本文基于系统访问日志进行ABAC策略自动提取及优化增强。首先,利用贝叶斯优化方法在搜索空间中调整超参数,以构建高精度的集成预测模型;其次,通过可视化策略逻辑树学习“用户-权限”的关联规律,自动提取包含正向和负向授权规则的ABAC策略,并对生成策略进行深度优化和增强,确保策略预测精度的同时降低策略复杂度;最后,在测试日志上全面评估策略质量,提取准确性高、适用性广以及解释性强的ABAC策略。总体来说,本文的主要贡献包括:
a)提出一种基于集成学习算法的ABAC策略自动提取方法,该方法根据属性和约束条件自动生成正负类访问控制策略。
b)在策略优化和增强阶段,采用单属性优化算法简化策略结构;提出规则二元约简算法压缩策略规模;提出规则冲突解决算法消除策略冲突,实现稳定、简洁且互斥的优化策略。
c)引入准确性、规则结构复杂度和解释性等策略质量评价指标,基于多目标优化的策略性能平衡算法,实现在各种访问场景中快速选择策略生成的最优模型。在平衡和稀疏类型日志上的实验均取得良好效果,验证了该方法的通用性和普适性。
1 相关工作
目前,国内外学者已在ABAC策略自动提取领域进行了一系列研究。总的来说,这些研究成果主要划分为策略自动提取的技术应用和策略质量优化的方法探究两大核心部分。文献[13]提出一种专门针对稀疏日志设计的策略自动提取方法(Rhapsody)。该方法采用关联规则技术初步提取策略,并引入一种新的规则质量度量方法——可靠性(reliability),以解决策略中过度授权规则的问题。此外,Rhapsody通过挖掘无更短等效规则的方式,简化策略整体结构,有效提高策略质量。然而,当处理大规模问题和具有大量属性的日志时,Rhapsody性能有待改进。文献[14]实现基于日志的富语义策略挖掘方法(LRSAPM)。该方法采用FPGrowth技术从访问日志和属性数据中初步提取策略,并基于T可靠度剔除策略中准确率较低、过度授权风险较高的规则。此外,基于语义质量度量标准对策略去冗余,保留语义质量较高的规则,形成完善的ABAC策略,但该方法对稀疏日志和低频访问的处理能力有待提高。文献[15]提出一种从系统访问日志中自动学习ABAC策略规则的方法。该方法采用K-modes聚类的无监督学习技术检测访问日志模式,初步提取ABAC授权规则,并采用规则剪枝及策略细化两种方法优化策略质量和精简度。规则修剪采用Jaccard相似度指标,消除对策略质量改善较小或冗余的规则,从而压缩策略规模;策略细化根据FN或FP记录中的模式,对提取策略进行修正,消除多余的属性条件或添加缺失的属性条件。上述优化方法虽增强了策略的准确性和简洁性,确保了提取策略与原始策略保持一致,但此方法难以设定恰当的聚类K值,提取出的策略稳定性较弱。上述这些方法主要关注正向类型的访问控制策略,并未涉及负向授权的处理。
文献[16]基于现有的PRISM数据挖掘技术,首次实现正向和负向ABAC授权规则的提取,并在无现成访问日志可供使用的情况下提供一套生成授权日志的详细方法,同时该研究保证了策略的准确性和规则结构的简洁性,但其过程中涉及反复迭代计算和日志的多次读取,导致整体运行时间相对较长。文献[17]提出一种名为VisMAP的可视化ABAC策略提取方法。该方法将现有的用户访问权限具象化为图形二进制矩阵,并将寻找最优二进制矩阵表示任务转换为矩阵最小化问题。然后,通过分析访问控制矩阵的可视化表示,提取ABAC授权规则,并尽可能减少策略中的规则数量来满足现有的访问需求,提高策略的简洁性和易理解性。但由于矩阵稀疏且求解空间巨大,运行效率相对较低。文献[18]提出一种基于访问控制日志的访问控制策略生成方法。该方法利用机器学习分类器的递归属性消除法实现策略属性的最优选择,使用决策树算法提炼日志中隐藏的属性和权限关系,并结合实体属性选择结果,实现ABAC策略提取。虽然该方法能实现日志中95%的策略覆盖,但策略规模压缩之后仍较大,且策略简洁性和可解释性尚未考虑。此外,存在一些基于黑盒机器学习和深度学习等不可解释学习模型的策略自动提取方法[19~21],这类方法目前只能为策略提取提供属性数据,无法直接生成完整的ABAC访问控制策略。
关于上述文献的ABAC策略自动提取和质量优化的研究,本文将重点从以下五个方面予以改进和优化。首先,确保提取策略的正确性,即与原始授权日志一致,避免不一致的策略对系统安全性和稳定性产生负面影响;其次,简化策略结构复杂度,使其易于操作和维护;同时,使用策略提取算法实现正负类授权规则的自动生成,构建更全面和灵活的访问控制策略;此外,在处理稀疏日志时,算法也能从非均衡和低频访问日志信息中提取有用规则,确保生成策略能够有效处理访问控制需求;最后,将聚焦于策略的可解释性研究,策略可解释性对保证系统安全、合规及有效的策略管理至关重要,它可以帮助管理员、用户和审计员更好地理解和信任策略规则,降低错误率并增强系统透明度。
综上所述,受文献[18]用决策树模型自动提取策略的启发,以决策树为基学习器的集成学习树模型(如random forest、XGBoost、GBM等)一定程度上可保留决策树的可解释性,并在处理大规模数据和复杂问题、提高预测精度和稳定性、处理高维和非线性问题,以及提高计算效率等方面优于单棵决策树,它能够作为实现ABAC策略自动提取的一种选择方案。但直接使用集成学习模型生成策略会面临以下问题:过多、过深的决策树会导致单条策略规则过于复杂,缺乏简洁性,以及规则间存在大量冗余和冲突。因此,本文拟采用高精度的黑盒集成学习树模型自动提取ABAC策略,以减轻安全管理员的工作负担,生成直观且可视化的访问授权规则,这也是目前集成学习模型应用于ABAC策略提取的首次尝试。随后,使用优化和增强算法改进策略质量,具体包括移除单条规则中冗长属性条件以降低策略结构复杂度、删除冗余规则以压缩策略规模、消除重复覆盖规则以解决策略冲突,从而提高策略简洁性和解释性,以促进ABAC模型在各类场景中的广泛应用,并为保障信息安全提供有力支持。
2 问题定义
定义1 ABAC策略核心组成。ABAC模型的实现需要创建一组基于属性的决策规则,这些规则累积形成访问控制策略,即资源访问的允许或拒绝取决于一系列规则r的评估结果,这些规则为访问授权或拒绝提供明确条件。规则r主要包含主体用户U、客体资源O、执行操作OP和授权结果D的属性表达式(e)。属性表达式可分为属性值对和属性-属性对。属性值对代表用户或资源属性的具体值,属性-属性对则表示需要匹配的用户和资源属性组合。以下是一些ABAC策略中规则的示例。
u.position=faculty;u.chair=true;o.type=transcript;u.department=o.department;action=read;permit(1)
u.position=manager;u.department=accounts;o.type=budget;action=approve;deny(2)
本文涉及的相关符号定义如表1所示,使用大写字母表示集合,小写字母表示集合中的元素。
定义2 ABAC策略生成问题。授权日志可以表示为l=〈u,o,op,d〉,其中,u∈U为用户,o∈O为资源,op∈OP为用户对资源的操作,d∈D代表访问执行结果,所有的授权日志l组成访问日志集合L。此日志集合中,可能存在各类日志分布情况,包括平衡日志和稀疏日志。
平衡日志是指各类访问请求事件(如允许访问请求、拒绝访问请求)的出现频率相对均衡,即样本数据在不同类别间的分布较为均匀。而稀疏日志是指某类访问请求事件(例如拒绝访问请求)在整体日志数据中的出现频率极低,造成数据在各类事件间的分布极不均匀,形成稀疏分布。现实情况中,用户通常会访问他们有权限访问的资源,尤其在被拒绝后,用户可能不会再尝试访问这些资源,这就会产生大量的允许访问日志,而拒绝访问的日志就相对较少,从而形成稀疏日志。
根据用户集合U、用户属性集合Uatt和用户属性函数Fu组成用户属性关系表UA;同理可得资源属性关系表OA。以UA为例,具体描述如下。
假设UA(ui)={a1∶v1;a2∶v2;…;an∶vn},其中ui∈U表示具体用户;a1,a2,…,an,an∈Uatt表示用户ui拥有的具体属性;v1,v2,…,vn表示用户ui属性an对应的具体取值vn。给定用户集合U={u1,u2}和用户属性集合Uatt={身份,部门},以及如表2所示的属性关系。
此时UA可表示为
UA(u1)={身份:管理员,部门:人事}(3)
UA(u2)={身份:员工,部门:销售}(4)
在给定访问日志集合L、用户属性关系表UA、资源属性关系表OA以及相关的策略质量评估指标情况下,本文目标是从复杂的访问控制日志中挖掘出能够精确反映权限关系的ABAC策略。
定义3 ABAC策略准确性。ABAC策略准确性是衡量其在接受或拒绝访问请求时是否正确的重要指标。高准确性的策略能够在实际应用中降低误报和漏报的风险,确保系统的安全和合规。本文参照文献[18],将准确性分为接受策略准确性(ACC_1)、拒绝策略准确性(ACC_0)以及整体策略准确性(ACC_0/1),如式(5)~(7)所示。
ACC_1=TAR(L)AR(L)(5)
ACC_0=TDR(L)DR(L)(6)
ACC_0/1=TAR_DR(L)AR_DR(L)(7)
其中:TAR(L)、TDR(L)、TAR_DR(L)分别表示使用提取的访问控制策略对测试日志中的接受类别日志记录、拒绝类别日志记录、整体类别日志记录进行权限评估,且评估结果为正确的日志数量;AR(L)、DR(L)、AR_DR(L)分別表示测试日志中接受类别日志记录、拒绝类别日志记录、整体类别日志记录的总数量。
定义4 ABAC策略规则结构复杂度。本文致力于提升ABAC策略提取质量,并将加权结构复杂度(weighted structure complexity,WSC)作为主要评估指标。WSC是一种衍生自策略规模(策略中的规则条数policy scale,PS)的度量方法[22],主要用于衡量策略规则结构长度的复杂程度。具体来说,WSC通过计算策略中各元素的加权和来评估结构复杂性。较低的WSC值意味着策略结构更为简洁且易于管理。WSC的计算方式如式(8)~(10)所示。
WSC(Π)=∑r∈RWSC(r)(8)
WSC(e)=∑a∈att(e)|e(a)|(9)
WSC(r)=ω1WSC(eu)+ω2WSC(eo)+ω3WSC(eop)(10)
其中:属性表达式e表示某一用户eu、资源eo或操作eop拥有的属性约束;e(a)表示属性表达式e中属性a的值域大小;att(e)表示被e所使用的属性集合;wi为自定义权重。通过使用这种度量方法,能够有效评估策略的结构复杂度,从而更有针对性地对策略进行优化,实现高质量的ABAC策略提取。
定义5 ABAC策略可解释性(interpretability,INT)。它是衡量其透明度和可理解性的关键指标。具有较高可解释性的策略有助于管理员和审计员更好地理解并维护访问控制规则,同时也便于用户了解自己的访问权限。通常来说,可解释性是指人们能够理解决策原因的程度,参考文献[23]对规则提取的可解释研究,本文将可解释性指标定义为
INT(Π)=1-αNatt+βNcov+δNcntα+β+δ(11)
Natt=1totalatt∑ruleNi=1activeiatt-1ruleN-1(12)
Ncov=1ruleN(1-∑ruleNi=1ruleimatch-1countdata-1)(13)
Ncnt=ruleselect-1ruleN-1(14)
其中:Natt、Ncov、Ncnt分别代表策略中规则的平均属性数、策略的样本覆盖范围以及策略选择率;α、β、δ分别表示各指标的权重,其取值可根据研究者的需求确定,此处参考文献[23],设定为三者权重相等;activeiatt表示第i个规则的属性个数;totalatt表示策略中含有的属性个数;ruleimatch表示与第i条规则匹配的样本数量;countdata表示总样本数;ruleN表示策略规模;ruleselect表示优化后的策略规模。当Natt∈[0,1]较小,即平均属性数少时,表示规则具有简洁性,策略管理员更容易理解;当Ncov较小,即规则具有较好的覆盖范围时,表示规则的稳定性较强;当Ncnt较小,即预测策略规模较少时,表示访问系统的执行效率高。因此,可解释性指标INT的值越大,策略的可解释性越强。
3 ABAC策略自动提取与优化增强
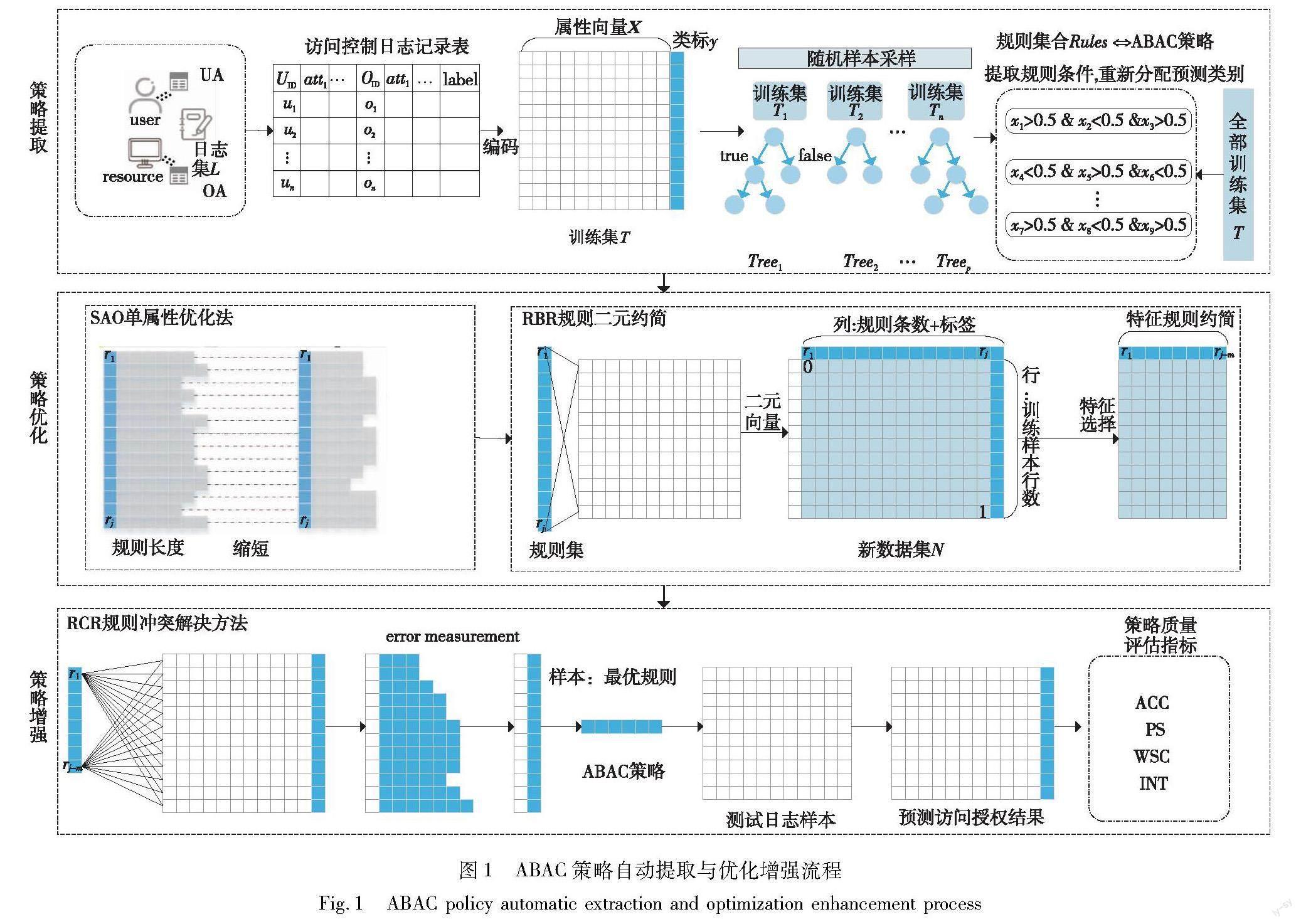
针对现有ABAC策略生成问题,本文构建一种策略自动生成优化流程,以提升生成策略的质量,其涵盖策略提取、优化和增强三个阶段。首先从原始训练数据中提取关键规则,作为构建初始策略的基础;接着,深度优化策略中的规则,通过缩短规则长度和降低规则条数,精炼策略;最后,消除冲突规则和覆盖重叠,实现策略增强,得到一套互斥且全面的ABAC策略。具体实现流程如图1所示。
3.1 基于集成学习模型的ABAC策略自动提取
3.1.1 数据预处理
针对策略提取在效率和准确性上待提升的问题,本文将从访问日志中提取ABAC策略问题转换为机器学习领域的二分类问题。通过构建高效且强大的随机森林(random forest)、梯度提升机(gradient boosting machine,GBM)和极限梯度提升(extreme gradient boosting, XGBoost)集成学习分类器, 能够准确预测基于多种属性组合(如用户属性、资源属性和环境属性)的访问请求授权状态。为实现这一目标,首先获取系统的资源授权日志l,将访问控制日志集L、用户属性关系表UA和资源属性关系表OA按主键ID进行全连接操作,构建访问控制日志记录表。接下来,将各种属性转换为便于处理的类型。对于离散值属性,采用独热编码(one-hot)进行编码,其中0表示该用户不具有该属性,1表示该用户具有该属性。对于连续值属性,将其转换为离散型属性,并使用one-hot编码进行处理。此外,整合冗余属性值并纠正错误的属性标定,确保属性能够准确反映权限关系。为简化问题,本文假设环境条件可取任意值。
如图1所示,给定训练集T,其中X为属性向量,y为类标。令T=(Xi,yi),i=1,2,…,n为标记样本的集合,此时Xi∈X且Xi=(Xi1,Xi1,…,Xif),f是属性数量,yi∈y={0,1}是二分类标签。使用上述数据训练集成学习模型M,它由多棵策略逻辑树Tree组成,这种树型的访问控制结构包含叶子节点和非叶子节点。位于树底部的叶子节点表示授权结果,如允许访问或拒绝访问。非叶子节点包含内部节点和根节点,分布在树的其他位置,表示具体属性及其约束条件。每个非叶子节点都有左右两个分支,其属性及约束条件通常以各种表达式(逻辑、条件和集合表达式等)的形式存在。若满足该节点条件,授权流程将沿着左分支前进,否则转向右分支。每条从根节点到叶子节点的路径代表一条访问控制规则,通过遍历每棵树的所有路径集合,实现ABAC策略的自动提取。
3.1.2 集成学习模型构建
使用集成学习模型构建策略逻辑树Tree时,为每个节点选择最优分裂点是实现ABAC精确决策的核心。合理选取分裂点能增强模型预测的精度和稳定性,避免过拟合或欠拟合的风險。此外,它能简化树的结构,减少其深度和节点数量,使属性和约束条件间的复杂关系表达更为直观。这一过程优化了ABAC策略提取的效率和准确性,使决策过程高效、可靠。在应用random forest模型时,首先使用自助重采样(bootstrap sampling)生成新数据集T′;然后随机选择一组属性子集,通过计算基尼不纯度(Gini impurity)[24]来确定Tree中每个节点的最佳分裂点。
G(T′)=1-∑Kk=1p2k(15)
其中:p2k表示T′中第k类的样本比例;K表示T′的类别总数。
确定最佳分裂点时,设属性A的约束切分点a将数据集T′分裂为两个子集T′1和T′2。子集T′1包含A≤a的所有样本,子集T′2包含A>a的所有样本。|T′1|和|T′2|是子集T′1和T′2的样本数量,|T′|是数据集T′的样本数量。分别计算这两个子集的基尼不纯度,并根据子集大小进行加权平均,从而得到分裂后的基尼不纯度。
G(T′,A,a)=(|T′1||T′|)×G(T′1)+(|T′2||T′|)×G(T′2)(16)
遍历所有属性和切分点,计算相应的G(T′,A,a),选取使得G(T′,A,a)最小的属性和切分点作为最优分裂点。
另一方面,应用GBM和XGBoost模型构建策略逻辑树时会充分利用所有样本数据[25,26],且这两种模型会选择能最大程度降低损失函数的属性及约束切分点作为最优分裂,如GBM模型中,常采用对数损失函数[25]。设属性B的切分点b将样本集T分成两个子集Tleft和Tright,Tleft包含B≤b的样本,Tright包含B>b的样本。计算左子集Tleft中标签为1的样本比例,表示为pleft;计算右子集Tright中标签为1的样本比例,表示为pright。计算所有属性及约束切分点的损失函数,选择对应最小损失函数值作为最优分裂点。
Loss(B,b)=-∑i∈Tleftyilog(pleft)+(1-yi)log(1-pleft)-
∑i∈Trightyilog(pright)+(1-yi)log(1-pright)(17)
XGBoost模型采用的损失函数考虑了一阶和二阶梯度信息[26],即损失函数相对于预测值的一阶和二阶导数。这需要为Tleft和Tright分别计算损失函数的一阶和二阶导数总和。设GL和HL分别表示Tleft的一阶和二阶导数的和,GR和HR分别表示Tright的一阶和二阶导数的和。接下来,计算通过切分点b进行分裂后的损失减少量得分ΔLoss。
Δ Loss=12×[(GL2HL+λ)+(GR2HR+λ)-(GL+GR)2(HL+HR+λ)]-γ(18)
其中:λ和γ是正则化参数;λ控制叶子节点权重的正则化;γ控制叶子节点数量的正则化。遍历所有属性和切分点,选择ΔLoss最大的属性和切分点作为Tree节点的最优分裂点。
3.1.3 策略逻辑树规则转换
考虑一个包含P棵策略逻辑树的集成学习模型M,从中选择第p棵树Treep(1≤p≤P)并对其第q条路径r{wqp}进行分析。假设路径q中包含S个非叶子节点,将第s(1≤s≤S)个非叶子节点v{psq}视为包含属性x∈X及其约束条件θ∈⊙的决策表达式F{v{psq}(x,θ)}。当路径q在节点s处延伸至左分支时,将F{v{psq}(x,θ),true}添加到路径中,若路径向右分支延伸时,则将表达式的补集F{v{psq}(x,θ),false}添加到路径。因此,路径r{wqp}可以用一系列属性-约束对的有序序列表示。
r(wqp)={&s∈S(F{v{psq}(x,θ)},true,false)}(19)
最后,通过分析M中P棵树的所有决策路径,得到一组决策规则集合R,Q表示Treep的叶子节点数,整个过程能够自动化提取ABAC策略。
ΠR={∪P,Qp,qr(wqp)|p=1,2,…,P;q=1,2,…,Q}
Q=∑node∈Treeq|leafnode(Treep)|(20)
在集成模型的训练过程中,选用的样本仅占全部训练样本的一部分。因此,本文方法只从这些样本中提取规则条件,并依据这些条件结合整个训练样本集对每条规则的预测类别重新优化定义。在移除重复规则之后,构建一个初级的ABAC策略。核心算法如下:
算法1 ABAC策略提取
输入:training samples T,tree ensemble model classifier。
输出:orig policy。
M←Train(TreeEnsembleclassifier,T) /*使用训练集T训练树集成学习模型M*/
orig policy← //初始化决策规则(策略)集合
for each Tree in M do
for each branch in Tree do
convert path to decision rule r and add to orig policy /*將决策路径转为决策规则,添加到orig policy中*/
end for
end for
for each rule r in orig policy do
N_c=|t∈T|满足r且t的类别为c| //记录满足r的样本数量和类别
c_r=argmax_c(N_c) /*为规则r分配出现次数最多的类别作为预测结果*/
r:rc_r
end for
remove duplicate r from orig policy
return orig policy
3.2 策略优化
上述策略提取过程中,由于random forest、GBM和XGBoost的集成特性以及基于决策树的非线性特点,无论采用哪种方法,提取出的规则都具有较高的复杂度,这对于理解策略内在逻辑和进行细粒度访问控制具有一定的挑战性。因此,在实际应用中,需要对策略进行优化和完善,提高其可读性、维护性和执行效率,以便更好地满足实际需求和安全性要求,确保访问控制系统在各种场景下高效且稳定运行。为实现这一目标,本节提出基于单属性优化和规则二元约简的策略优化方法。
3.2.1 单属性策略优化
集成学习方法整合众多去耦合策略逻辑树,构建出精确且稳定的预测模型。然而,每棵树生成的规则可能存在冗余或过于复杂的属性条件。为解决该问题,借鉴文献[27]的规则修剪思想,设计一种单属性策略优化(single attribute optimization,SAO)方法,通过审查每条规则,识别并移除重复、不相关或冗长的属性条件。这些条件不会影响规则的执行结果,但会增加计算成本。使用此方法,可以在保證策略预测准确性的同时,简化策略结构。
在SAO方法中,采用一种称为归一化误差比值(norma-lized error ratio,NER)的度量标准来评估删除某个属性对规则的影响。设ABAC策略为ΠR={r1,r2,…,rj},具体的规则误差度量函数表示为
E(rj,T)={1-T(rpredj)T(rj)|rj∈Π}(21)
其中:T(rj)为满足rj的样本数量;T(rpredj)为满足rj且预测正确的样本数量。通过对比原始规则产生的误差和剔除某个属性条件后得到新规则产生误差之间的比值,可以更加准确地判断该属性对规则的贡献程度。
NER=E_t-E_origmax(E_orig,ε)(22)
其中:E_orig代表原始规则误差;E_t表示在剔除第t个属性后得到新规则的误差;ε是一个正数(例如10-2),用在E_orig接近0时调节NER值,避免因分母过小导致的计算不稳定。当归一化误差比值低于预设误差阈值E_threshold时,可以认为第t个属性条件对规则的贡献相对较小,从而考虑将其从规则中移除。
为了更清楚地阐述SAO方法的工作原理,以一个具体例子进行说明。假设一条规则为{部门=‘财务&职位=‘经理&工作时长>‘2年&教育程度=‘硕士访问权限=‘高级},其中ε=0.01,E_threshold=0.20且E_orig=0.4。当移除条件{部门=‘财务},规则变为{职位=‘经理&工作时长>‘2年&教育程度=‘硕士访问权限=‘高级}。设移除条件后的规则误差为E_1=0.415,那么NER=0.415-0.4max(0.4,0.01)=0.0375<<0.20。由于归一化误差比值低于预设误差阈值,表明条件{部门=‘财务}对规则的贡献较小,所以可以将其从规则中删除,这样规则长度从4缩短至3。通过实施SAO方法,对规则中的每个属性条件进行分析,剔除冗长和不必要的属性,优化策略整体结构。核心算法如下:
算法2 单属性优化
输入:training samples T;orig policy;E_threshold;ε。
输出:pruned policy。
pruned policy←
for each rule r in orig policy do
E_Orig←E(r,T) //计算r的原始误差
for each condition t in reversed order of r do /*从后往前迭代去除r的每个属性条件*/
E_t←E(remove t from r,T) /*计算去除r中第t个属性条件的误差*/
calculate NER
if NER ≤E_threshold then
remove condition t from r
update r,E_Orig=E_t //更新r和原始误差
end if
pruned policy←add(r)
end for
end for
return pruned policy
3.2.2 规则二元约简
尽管SAO方法能有效缩短规则长度,但规则数量仍未减少,为进一步筛选关键授权规则并压缩策略规模,本文提出一种名为规则二元约简(rule binary reduction,RBR)的策略优化方法。其核心思想是将规则转换为二元特征向量,并与原始训练样本结合形成新数据集,使用特征选择方法筛选最优规则子集。
具体而言,RBR方法将每条规则视为一个特征,为其创建一个反映所有训练样本是否满足该规则的二元特征向量,并将其加入到原始训练样本的特征集,形成一个新数据集N。规则集合的条件部分为{r1,r2,…,rj},其中Nij表示第i个训练样本是否满足规则rj,即
Nij=1 第i个样本满足规则rj0 第i个样本不满足规则rj(23)
基于此,构建一个行数与训练集样本相同的新数据集N,包含二进制变量及其对应的标签。
N={[Ni1,Ni2,…,Nij,labeli],i=1,2,…,n}(24)
这里采用递归特征消除法(recursive feature elimination,RFE)[28]实现规则约简。首先,将新数据集N输入到机器学习分类器(如支持向量机(SVM)、决策树或随机森林)进行训练,为保持一致性,本文使用所有特征训练随机森林分类器C。然后,在每轮迭代中,移除一个特征规则feat_r,并使用剩余特征规则和对应标签重新训练分类器C(-feat_r)。通过比较,剔除规则前后分类器的准确率Δ_Acc_r,评估被剔除规则的重要性。
Δ_Acc_r={Acc(C)-Acc(C(-feat_r))|r∈{r1,r2,…,rj}}(25)
如果Δ_Acc_r>0,说明剔除的规则对分类器性能影响较大,其重要性较高;反之,若Δ_Acc_r≤0,表示剔除的规则对分类器性能影响有限,重要性较低。最后,按照规则重要性进行排序并筛选结果。
Sorted=argsort(-Δ_Acc_r)(26)
FinalCond={feat_r|r∈Sorted[:m]}(27)
其中:argsort(-Δ_Acc_r)表示按照准确率降序排列規则的索引;m为所需规则数量;FinalCond为最终选定的规则子集。RBR方法通过逐步优化规则数量和质量,从新数据集N中筛选出一组相关且高度具备区分性和预测能力的非冗余规则子集,再将其应用到全部训练日志上重新分配预测结果,最终形成优化的ABAC策略。核心算法如下:
算法3 规则二元约简
输入:training samples T;pruned policy。
输出:reduced policy。
initialize dataset N with same row count as T /*初始化一个与训练集样本行数相同的新数据集N*/
for each rule r in pruned policy do
B_r=[0*n] //创建一个长度为n的向量列表
for each sample t[i] in T do //遍历训练集的每个样本
if t[i] is satisfies r then B_r[i]=1 else set B_r[i]=0 /*将规则转换成二元特征向量*/
end for
N.tail←column(B_r) /*将二元特征向量B_r作为一个新列追加到数据集N的末尾*/
end for
Acc_scores←{ } //存储删除的每条规则以及对应的模型准确率
for each column j in N do
Accj=train(N.remove column j),rf //计算剔除第j列(第j条规则)的准确率
Acc_scores[j]←Accj
end for
reduced policy← //存储小于原始准确率的规则
for each key j in Acc_scores do
calculate Δ_Acc_rj=Acc(train(N,rf))-Acc_scores[j] /*计算第j条规则的重要性*/
if Δ_Acc_rj>0 then
reduced policy←add(j)
end if
end for
return reduced policy
3.3 策略增强
对初步提取出的ABAC策略应用SAO和RBR方法进行优化后,可以得到一种改进的ABAC策略,但优化策略中仍存在非互斥和不完备的规则,即一条训练日志数据被多条规则重复覆盖。为解决该问题,本文提出一种基于误差度量的规则冲突解决(rule conflict resolution,RCR)方法,避免因规则间的冲突导致错误判断和执行,具体实施步骤如下。
首先,将优化策略表示为R={r|r=rj,j=1,2,…,j-m},通过训练样本集T={t|t=ti,i=1,2,…,n},为每个样本ti找到适用的规则子集R_i={rij|rij∈R∩rij适用于ti}。然后,对这些规则进行误差度量,根据式(28)挑选出误差最小的规则,若存在误差相同的多条规则,则选择长度最短的一条作为该样本的最优规则。
r_min=argmin{E(rij,T)|rij∈R_i}(28)
r_opt=argmin{Len(rij)|rij∈r_min}(29)
最后,依次迭代所有训练样本,确保每个样本仅被其最优规则覆盖。通过为每个样本寻找准确度最高的规则,RCR方法既能确保ABAC策略包含所有必要的访问控制规则,又能有效降低规则冲突,提高策略稳定性。
算法4 规则冲突解决
输入:reduced policy;training samples T。
输出:optimal policy。
optimal policy← //存储互斥、非冲突的规则
for each sample in T do //遍历训练集中的每个样本
applicable_r←{ } //存储满足当前样本的具体规则和对应误差
for each rule r in reduced policy do
if r applies to sample then
calculate r_error=E(r,T)
add {r:r_error} to applicable_r
end if
end for
sort applicable_r by r_error in ascending order /*按照规则误差升序排列*/
min_error_r=arg min{r∈keys(applicable_r)}applicable_r[r]
if length of min_error_r>1 then
choose the shortest rule from min_error_r /*从误差子集中挑选最短长度作为此样本的最佳规则*/
add this rule to optimal policy
end if
end for
return optimal policy
4 实验评估
4.1 实验设置
4.1.1 实验环境设置
本实验旨在比较random forest(RF)、XGBoost(XGB)和GBM三种集成模型在ABAC策略自动提取与优化方面的应用,以进一步提高策略预测准确性、降低策略复杂度并增强其可解释性。集成模型的复杂性表现在多个方面,包括决策树的数量、最大深度、特征数量、决策树算法、集成策略以及正则化等。具体来说,当树的数量和深度增加时,终端节点的数量会迅速上升,从而导致树的复杂性增加,使得解读其决策规则变得困难。为了确保实验对比的公平性,本文在(30,40,50,60,70,80,90,100)内设置树的数量,并在(4,5,6,7)内设置深度。同时,针对不同数据集,采用贝叶斯优化方法为每种模型寻找其他最优参数。为确保实验设计的严谨性和可重复性,表3详细列出了实验环境和具体参数设置。
4.1.2 数据集描述
为验证本文方法的有效性,选用两类数据集进行实验:一是来自文献[7]中的手写数据集University,二是来自Kaggle平台的公开数据集——Amazon.com-Employee Access Challenge,简称为Employee。University数据集的特点是操作类别平衡,允许类别日志和拒绝类别日志的数量相等。Employee数据集包含大量的主客体,日志集相对稀疏,拒绝访问请求的日志数量极少,且资源属性仅有一个。表4为数据集的基本信息。本文将这两个数据集按8∶2随机划分为训练集和测试集,并进行3次随机拆分,实验结果的各项指标均为3次拆分后各指标的平均值。该方式旨在更准确地评估本文方法在不同数据集上的表现。
4.2 性能分析
4.2.1 策略准确性对比
本实验旨在比较RF、XGB和GBM三种模型在提取ABAC策略方面的准确性表现。将每种模型提取的策略结果输入到之前定义的策略优化和增强流程中,得到经过优化和增强后的ABAC策略,并将经过优化和增强后的模型分别命名为RFOpt、XGBOpt和GBMOpt,以进一步对比它们的性能差异。图2和3展示了集成学习模型在不同访问控制数据集下,针对接受、拒绝和整体策略准确性的变化情况。
在University数据集验证中,RFOpt、XGBOpt和GBMOpt模型在拒绝策略和整体策略准确性方面均优于原始模型。其中,GBMOpt的ACC_0最大幅度提高了38.7%,达到96.56%;同样,GBMOpt的ACC_0/1提高了17.64%,达到96.69%。然而,在接受策略准确性方面,RFOpt、GBMOpt模型并未超越原始模型。主要原因在于策略优化过程中的权衡取舍,优化过程主要致力于提高整体策略准确性和降低误报率,所以牺牲其他指标的部分性能是可以接受的。具体来说,RF和RFOpt的接受策略准确性均为100%;GBMOpt的ACC_1下降了3.19%,但准确性仍高达96.81%;相较于XGB,XGBOpt的ACC_1提高了2.26%,达到97.03%。
在Employee数据集验证中,RFOpt、XGBOpt和GBMOpt模型在接受和整体策略准确性方面均优于原始模型。其中,RFOpt的ACC_1提高了10.24%,达83.11%;XGBOpt的ACC_1提高了19.82%,达86.63%;GBMOpt的ACC_1大幅提高了48.6%,达82.43%。此外,RFOpt、XGBOpt和GBMOpt的ACC_0/1分别提高了4.43%、7.43%和21.04%,达到81.2%、87.74%和84.34%。然而,RFOpt模型在拒绝策略准确性方面与原始RF模型相当,XGBOpt和GBMOpt则未超过原始模型。主要原因在于Employee数据集的稀疏性,接受日志量远超拒绝日志,导致模型偏向学习接受策略,即便采用ADASYN技术增强少数类样本,但新增样本基于插值产生,会引入噪声进而影响模型性能。具体来说,XGBOpt和GBMOpt的准确性分别降低了5.35%、6.9%,但仍达88.87%、86.17%。
在ABAC策略提取过程中,经过优化和增强的模型在整体策略准确性上明显优于原始模型。然而,受数据特征和问题深度的影响,这些模型在不同数据集上的表现并非一致。在接受和拒绝策略准确性上,优化模型的性能有时会下降,这是优化过程中权衡各性能指标的结果。因此,实际应用时必须考虑数据集特性和实际需求,以确保模型优化与应用场景契合。
4.2.2 策略规模大小对比
图4展示了University和Employee数据集在不同集成学习模型下策略规模大小的变化趋势。实验结果表明,RFOpt、XGBOpt和GBMOpt模型在University和Employee數据集上的策略规模均明显低于原始模型。在University数据集中,RFOpt、XGBOpt和GBMOpt分别将策略规模压缩至原来的7.7%、4%和19.7%。在Employee数据集中,其比例分别为21.3%、23%和27.7%。结果表明,RFOpt、XGBOpt和GBMOpt优化算法在压缩策略规模方面表现良好,但处理不同数据集时的适应能力存在差异。
4.2.3 策略复杂性对比
如图5所示,优化模型RFOpt、XGBOpt和GBMOpt在可解释性方面明显优于原始模型RF、XGB和GBM。虽然原始模型在各数据集上的解释性表现稳定,但具体得分较低。其中,XGBOpt在University数据集上的可解释性最高,为95.16%,而在Employee数据集上,GBMOpt最高,为78.82%。此外,优化模型提取的策略在规则结构复杂度(WSC)上显著低于原始模型。在University数据集上,RFOpt、XGBOpt和GBMOpt提取的策略WSC都低于20,相较于RF、XGB和GBM模型,WSC降低的比例分别为94.8%、97.4%和83.1%。同样,在Employee数据集上,这些优化模型提取的策略WSC都低于65,与RF、XGB和GBM相比,分别降低了86.5%、85.6%和76.1%,且更小的WSC值表示更强的可解释性。实验结果表明,在这些应用场景中,相较于优化模型,原始模型提取策略在规则结构复杂度上高出数十倍。因此,本文方法通过策略优化与增强,在保证准确性和解释性的同时,有效降低了策略规则结构复杂度,实现了结构简洁性与预测性能间的有效平衡。
4.2.4 策略性能平衡对比
基于上述分析,观察到经过优化和增强的模型在提取ABAC策略的性能指标方面有显著提升。其中,策略准确性是衡量模型质量的关键指标,直接影响策略的应用价值;WSC指标则量化了策略的结构简洁性和易于管理的程度。然而,策略规模并非总是与模型性能或有效性有直接关系。因此,本文采用帕累托多目标优化方法,同时考虑策略准确性和WSC指标,以寻找最优模型解,达到策略准确性和结构簡洁性的最佳平衡。在不同数据集上,找出在策略精度和WSC间达到平衡的最优模型是关键。表5详细展示了各模型在不同数据集上进行ABAC策略提取与优化增强的相关指标及结果。
在帕累托前沿上,可以基于需求和约束选择最优解,这个过程需要在不同目标之间权衡以实现平衡。图6以ACC_0/1和WSC为例,展示了在不同权重设置下的结果。当权重为(0.5,0.5)时,准确性和WSC之间实现了最佳平衡。此时University数据集的平衡点为(96.69%,13.09),由表5可知,最优模型为GBMOpt;而Employee数据集的平衡点为(87.74%,50.15),最优模型为XGBOpt。当权重为(0.9,0.1)时,策略偏重准确性,University和Employee数据集的最优模型仍为GBMOpt和XGBOpt。当权重为(0.1,0.9)时,策略偏重WSC,此时University数据集的最优模型为RFOpt,而Employee数据集的最优模型为GBMOpt。总体来看,通过调整权重,可以在准确性和WSC间找到最佳平衡,从而确定最适合的优化模型,实现高效、透明且易于管理的策略。
5 结束语
本文提出一种基于访问控制日志驱动的ABAC策略自动提取与优化增强方法,且在各项策略质量评估指标上取得了显著成效。该方法使用random forest、XGBoost和GBM三种集成学习树模型,从历史日志中自动提取初始策略。通过策略优化和增强算法来解决直接使用集成学习模型的不足,并实现了多个目标,即有效压缩策略规模、简化策略结构复杂度、提高策略的整体预测准确性和解释性,同时强化策略的完备性和互斥性,避免冲突和错误发生。在平衡数据集和稀疏数据集上的实验,证明该方法既能精确预测访问请求的授权状态,又能确保策略的清晰易懂。下一步将针对动态变化的环境和需求,研究策略自适应更新和调整技术,并探索提高策略检索效率的方法,以实现在大型系统和高并发场景下更快速、更高效的访问控制决策。
参考文献:
[1]Ferrari E. Access control in data management systems[M].[S.l.]:Morgan & Claypool Publishers, 2010.
[2]Hu V C, Kuhn D R, Ferraiolo D F, et al. Attribute-based access control[J]. Computer, 2015, 48(2):85-88.
[3]Hu V C, Ferraiolo D, Kuhn R, et al. Guide to attribute based access control(ABAC) definition and considerations(draft)[J]. NIST Special Publication, 2013,800(162):1-54.
[4]Zhao Yinyan, Su Mang, Wan Jie, et al. Access control policy maintenance in IOT based on machine learning[J]. Journal of Circuits, Systems and Computers, 2021,30(10): 2150189.
[5]Gumma V, Mitra B, Dey S, et al. Pammela: policy administration methodology using machine learning[C]//Proc of International Conference on Security and Cryptography. 2022: 147-157.
[6]Nobi M N, Krishnan R, Huang Yufei, et al. Toward deep learning based access control[C]//Proc of the 12th ACM Conference on Data and Application Security and Privacy. New York:ACM Press, 2022:143-154.
[7]Xu Zhongyuan, Stoller S D. Mining attribute-based access control policies from logs[C]//Proc of the 28th Annual IFIP WG 11.3 Working Conference on Data and Applications Security and Privacy. Berlin: Springer, 2014: 276-291.
[8]Sun Wei, Su Hui, Xie Huacheng. Policy-engineering optimization with visual representation and separation-of-duty constraints in attribute-based access control[J]. Future Internet, 2020,12(10):164.
[9]Abu J A, Bertino E, Lobo J, et al. Polisma-a framework for learning attribute-based access control policies[C]//Proc of the 25th Euro-pean Symposium on Research in Computer Security. Cham: Springer, 2020: 523-544.
[10]Sahani G,Thaker C,Shah S. Supervised learning-based approach mi-ning ABAC rules from existing RBAC enabled systems[J]. EAI Endorsed Trans on Scalable Information Systems, 2022,10(1):e9.
[11]Sanders M W, Yue Chuan. Mining least privilege attribute based access control policies[C]//Proc of the 35th Annual Computer Security Applications Conference. 2019: 404-416.
[12]Cappelletti L, Valtolina S, Valentini G, et al. On the quality of classification models for inferring ABAC policies from access logs[C]//Proc of IEEE International Conference on Big Data. Piscataway, NJ: IEEE Press, 2019: 4000-4007.
[13]Cotrini C, Weghorn T, Basin D. Mining ABAC rules from sparse logs[C]//Proc of IEEE European Symposium on Security and Privacy. Piscataway, NJ: IEEE Press, 2018: 31-46.
[14]毋文超, 任志宇, 杜學绘. 基于日志的富语义ABAC策略挖掘[J]. 浙江大学学报: 工学版, 2020,54(11): 2149-2157. (Wu Wenchao, Ren Zhiyu, Du Xuehui. Rich semantic ABAC policy mining based on log[J]. Journal of Zhejiang University: Engineering Science, 2020,54(11): 2149-2157.)
[15]Karimi L, Aldairi M, Joshi J, et al. An automatic attribute-based access control policy extraction from access logs[J]. IEEE Trans on Dependable and Secure Computing, 2021,19(4): 2304-2317.
[16]Iyer P, Masoumzadeh A. Mining positive and negative attribute-based access control policy rules[C]//Proc of the 23rd ACM on Symposium on Access Control Models and Technologies. New York:ACM Press, 2018:161-172.
[17]Das S,Sural S,Vaidya J,et al. VisMAP: visual mining of attribute-based access control policies[C]//Proc of the 15th International Conference on Information Systems Security. Cham:Springer,2019:79-98.
[18]刘敖迪, 杜学绘, 王娜, 等. 基于访问控制日志的访问控制策略生成方法[J]. 电子与信息学报, 2022,44(1): 324-331. (Liu Aodi, Du Xuehui, Wang Na, et al. Access control policy generation method based on access control log[J]. Journal of Electronics and Information Technology, 2022,44(1): 324-331.)
[19]Narouei M, Khanpour H, Takabi H. Identification of access control policy sentences from natural language policy documents[C]//Proc of the 31st Annual IFIP WG 11.3 Conference on Data and Applications Security and Privacy. Cham: Springer, 2017: 82-100.
[20]Alohaly M, Takabi H, Blanco E. Automated extraction of attributes from natural language attribute-based access control (ABAC) policies[J]. Cybersecurity, 2019, 2: 1-25.
[21]劉敖迪, 杜学绘, 王娜, 等. 基于深度学习的ABAC访问控制策略自动化生成技术[J]. 通信学报, 2020,41(12): 8-20. (Liu Aodi, Du Xuehui, Wang Na, et al. Automatic generation technology of ABAC access control policy based on deep learning[J]. Journal of Communications, 2020,41(12): 8-20.)
[22]Bui T, Stoller S D, Li Jiajie. Greedy and evolutionary algorithms for mining relationship-based access control policies[J]. Computers & Security, 2019,80: 317-333.
[23]Gorzaczany M B, Rudziński F. A multi-objective genetic optimization for fast, fuzzy rule-based credit classification with balanced accuracy and interpretability[J]. Applied Soft Computing,2016,40:206-220.
[24]Belgiu M, Drǎgu L. Random forest in remote sensing: a review of applications and future directions[J]. ISPRS Journal of Photogrammetry and Remote Sensing, 2016,114: 24-31.
[25]Natekin A, Knoll A. Gradient boosting machines, a tutorial[J]. Frontiers in Neurorobotics, 2013,7: 21.
[26]Chen Tianqi, Guestrin C. XGBoost: a scalable tree boosting system[C]//Proc of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining.New York:ACM Press, 2016: 785-794.
[27]Deng Houtao. Interpreting tree ensembles with intrees[J].International Journal of Data Science and Analytics,2019,7(4):277-287.
[28]Huang Xiaojuan, Zhang Li, Wang Bangjun, et al. Feature clustering based support vector machine recursive feature elimination for gene selection[J]. Applied Intelligence, 2018,48: 594-607.
猜你喜欢
科教导刊·电子版(2017年22期)2017-09-20 17:34:04
时代金融(2016年36期)2017-03-31 05:44:10
科技创新与应用(2017年6期)2017-03-23 20:57:00
现代电子技术(2017年1期)2017-02-16 11:32:52
建筑科学与工程学报(2016年6期)2017-01-18 15:37:05
数学学习与研究(2016年17期)2017-01-17 18:31:20
软件导刊(2016年11期)2016-12-22 21:30:28
电脑知识与技术(2016年21期)2016-10-18 22:51:02
电脑知识与技术(2016年13期)2016-06-29 21:00:53
科教导刊·电子版(2016年10期)2016-06-02 19:22:10
