
基于前景区域生成对抗网络的视频异常行为检测研究
2024-03-04 06:05邝永年
广东工业大学学报 2024年1期
邝永年,王 丰
(广东工业大学 信息工程学院, 广东 广州 510006)
视频异常行为检测是计算机视觉应用的重要领域。针对复杂的视频监控应用场景,文献[1]提出异常行为应被定义为发生概率低的行为,文献[2]提出异常行为是不可预测的行为。传统的视频异常行为检测方法[1-5],主要基于视频数据的动作特征和外观特征。如基于动态纹理的概率模型[4]以及混合概率[5]的主成分分析,建模光流捕捉局部运动特征,实现视频异常行为检测。
近年来,涌现出很多基于深度学习网络的视频异常行为检测方法[6-12]。基于半监督训练深度学习技术成为主流的视频异常检测方法。基于半监督训练的视频异常检测方法需要重点设计重构架构或预测架构。文献[6]提出用卷积自动编码器学习长时间视频中运动模式的规律特征,并通过重构误差判断是否存在异常行为。文献[7]对自动编码器添加记忆模块,用于查询检索与重构图像最接近的内存项;文献[8]在自动编码器中添加卷积长短记忆网络,补充时间信息。为检测物体的外观和运动信息,文献[9]构建由卷积自动编码器和U型网络(U-Net) 组成的深度卷积神经网络。在预测架构中,以连续的视频帧作为输入,以一帧预测帧作为输出。文献[2]基于生成对抗网络,以U-Net为生成器,马尔可夫判别器(Patch Generative Adversarial Networks, Patch GAN)[13]为判别器,并加入运动约束。文献[10]向外观自编码器和动作自编码器分别输入连续帧图和帧差图进行预测。文献[11]结合自动编码器,补充深度学习神经网络所欠缺的可解释性,增强检测视频异常帧的能力。文献[12]基于时空自注意力机制,通过增强图卷积网络,捕捉人体关节的局部和全局信息,进而检测判断异常行为的发生。
值得注意的是,当前基于半监督训练深度学习技术的视频异常帧异常行为检测方法,主要是基于峰值信噪比(Peak Signal-to-Noise Ratio, PSNR)准则,检测准确率和运行时间有待改善。为改进半监督训练深度学习网络对视频异常行为的检测性能,本文通过区分视频帧的前景与背景,增强前景信息和弱化背景信息,提出基于前景区域的峰值信噪比(Foreground area Peak Signal-to-Noise Ratio, F-PSNR)准则,能有效改进现有网络的视频异常行为检测性能,并降低检测运行时间。
1 视频异常行为检测的网络模型
本文采用的深度学习网络如图1所示。将视频流分解和处理成具有连续时间序列和相同尺寸的视频帧。给定输入连续t帧视频帧,按顺序输入生成器网络,生成对应第t+1帧实际帧的预测帧。通过加入强度、梯度、运动以及对抗约束,构建出生成器网络的损失函数。
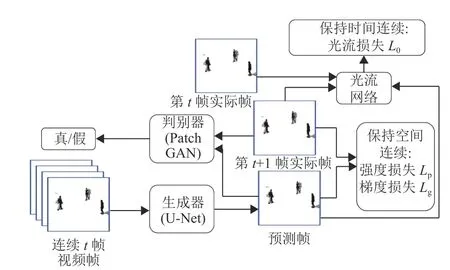
图1 网络架构Fig.1 Network architecture
1.1 生成器网络
U-Net网络作为生成器网络,其包括编码模块和解码模块。编码模块通过卷积操作提取所需的图像特征;解码模块通过反卷积操作恢复图像帧。每次卷积或反卷积操作都会出现梯度消失以及信息缺失的问题。使用U-Net作为生成器网络,通过其特有的连接操作可以有效减少梯度消失以及信息缺失。每个卷积层的特征与其对应的同分辨率的反卷积层的特征进行连接,作为下一个反卷积层的输入。这种连接操作使网络将浅层特征图的信息通过与更高层的特征图结合起来,保证了上下文信息的完整性。
为使生成器网络的预测视频帧尽可能接近对应的实际视频帧,本文训练条件生成对抗网络,最小化其损失函数LG。其中,损失函数LG包含强度损失Lp、梯度损失Lg、 光流损失Lo以 及对抗损失LGa;λp、λg、λo、λa分 别为强度损失Lp、梯度损失Lg、光流损失Lo以及对抗损失LG
a 在总损失函数中所占的权重,满足λp+λg+λo+λa=1。
具体的损失函数LG建模如下。
式中:Fˆt+1、Ft+1分 别为生成的第t+1帧预测视频帧和其相对应实际帧。强度损失函数用来约束预测视频帧Fˆ 与实际视频帧F之间的内容差异,即保持生成的预测视频帧的像素值在RGB空间上尽可能与实际视频帧的像素值保持相似,建模如下。
式中:Fˆ、F分别为生成的预测视频帧和其相对应实际帧的像素数据;Fˆi,j,k、Fi,j,k为该预测视频帧其相对应实际帧的在空间索引为 (i,j)处 第k通道的像素值;Row、C ol 为视频帧行、列像素数,C nl为视频帧颜色通道数。
梯度损失函数Lg用来约束预测视频帧与实际视频帧之间的边缘梯度信息,锐化生成图像,突出边缘信息,建模如下。
为了提取视频中的运动信息,通过光流网络(FlowNet) 模型生成光流图。f(Ft+1,Ft)表示光流网络计算连续2帧Ft和Ft+1的光流图。2帧视频帧行、列像素数均为R ow、 Col。光流网络生成的行、列像素数为Row、C ol,2个通道数的光流图,第1个通道表示帧在水平方向即行方向的光流分量,第2个通道表示帧在垂直方向即列方向的光流分量。光流损失函数Lo建模如下。
式中:fi,j,k(Ft+1,Ft)为 光流网络计算2帧Ft和Ft+1的光流图在空间索引为(i,j)第k光流方向通道的光流分量值。
生成对抗网络由生成器网络和判别器网络组成。生成器网络的作用是通过学习训练集视频的特征,在判别器网络的指导下,输出尽可能拟合为训练集视频帧的真实分布,从而生成具有训练集特征的相似数据。而判别器网络则负责区分输入判别器网络的视频帧是真实视频帧的还是生成器网络生成的虚假视频帧,并通过对抗学习中的对抗损失反馈给生成器网络。生成器网络和判别器网络交替训练,生成器网络和判别器网络的对抗损失减少,判别器网络能有效识别生成器网络输出的低质量视频帧,促使生成器网络输出判别器网络难以识别的高质量视频帧。生成器网络输出视频帧的质量和判别器网络的判别能力达到均衡。
生成对抗网络架构能有效用于预测。在视频异常行为检测任务中,生成器网络学习正常行为的连续视频帧并预测下一帧,尽可能将预测帧拟合为其对应的实际帧。加入判别器网络,形成生成对抗网络架构后,总体结构模型简单,提高了生成器生成预测帧图像质量,从而实现了较高的异常行为检测精度。
对抗学习通过区分实际视频帧和生成的预测视频帧,优化生成对抗网络的生成器与判别器。判别器的判别结果分为0和1,其中0和1分别代表假标签以及真标签。训练生成器网络的目标是通过学习正常视频帧的特征生成出更加接近实际视频帧的预测视频帧,即生成使判别器判断为真标签的视频帧。因此,生成网络的对抗损失函数建模为
式中:D(·)i,j为判别器判断视频帧中空间索引(i,j)处为真标签的概率,D(·)i,j∈[0,1]。
1.2 判别器网络
本文生成对抗网络的判别器网络采用Patch GAN[13]。Patch GAN把一幅图像划分为若干图像块,最后输出一个对应图像块的判别结果的矩阵,判别结果分为0类和1类,其中0和1分别代表假标签以及真标签。像素点的判别结果即为其所属图像块的判别结果。整张图像的判别结果取所有图像块的判别结果的平均值。
训练判别器时,生成器的权重是固定的。判别器网络的目标是将生成器生成的视频帧判断为假标签,将实际视频帧判断为真标签。建模判别器的对抗损失函数为
2 视频异常行为得分函数
2.1 前景提取
本文提出的视频异常行为检测方法感兴趣的区域为前景区域,因此需要先将前景区域提取出来。如图2所示。本文中使用的前景提取方法为背景差分法的混合高斯模型(Mixture of Gaussians, MOG)算法[14],实际视频帧通过前景提取获取到前景掩码后,再与掩码进行与运算后得到实际视频帧的前景区域。生成视频帧通过与所对应的实际视频帧的前景掩码进行与运算后得到生成视频帧的前景区域。
以帧Ft+1说明前景掩码矩阵Gt+1:前景提取器判断图像的像素点是否为前景,如该像素点为前景,则掩码该像素点的值置1所对应的地方,如为背景,则掩码该像素点的值置0所对应的地方,以此获得前景掩码二值矩阵Gt+1,Gt+1∈RRow×Col。

2.2 前景区域峰值信噪比
本文采用前景区域峰值信噪比F-PSNR作为计算两帧差异值的判断准则。定义前景区域峰值信噪比F-PSNR如下。

当峰值信噪比数值越大时,预测视频帧和实际视频帧的相似度越高,表明该实际视频帧是正常行为帧的概率越大;当峰值信噪比越小时,表示该视频帧为异常行为帧的概率越大。
2.3 异常行为检测得分函数
将测试集的F-PSNR数值作归一化处理,定义归一化异常行为检测得分函数S(t)如下。

3 分析与讨论
3.1 实验数据集
考虑视频异常行为检测任务的经典数据集UCSDPed1[4]数据集、UCSD-Ped2[4]数据集以及CUHKAvenue[15]数据集。
(1) UCSD-Ped1[4]数据集:包含34个正常视频训练集以及36个异常视频测试集,正常行为定义为正常行走的路人,异常行为有骑车、溜冰、机动车等行为,该数据集的所有视频分辨率为320×240。
(2) UCSD-Ped2[4]数据集:包含16个正常视频训练集以及14个异常视频测试集,正常行为定义为正常行走的路人,异常行为有骑车、溜冰、机动车等行为。数据集的所有视频分辨率为320×240。
(3) CUHK-Avenue[15]数据集:包含15个正常视频训练集以及21个异常视频测试集,正常行为定义为正常行走的路人,异常行为有奔跑、随手抛弃垃圾、横跨草坪等行为。数据集的视频分辨率为640×360。
3.2 实验设置
使用的深度学习训练框架为 Pytorch,所有的实验都基于NVIDIA RTX3080。将输入的视频帧大小调整到 256×256 以满足网络的输入标准。训练时使用自适应矩估计梯度下降法进行参数优化。训练次数设置为80 000轮次,每组训练批次有4组数据,每组数据输入连续4帧实际帧并输出1帧预测帧。以训练后得到的生成器网络为基准网络进行后续实验。
本文采用U-Net生成器网络。输入连续的4帧256×256的RGB三颜色通道图像,输出1帧256×256的RGB三颜色通道图像。其中,卷积层以及反卷积层使用的卷积核的尺寸为3×3,最大池化层所使用的卷积核的尺寸为2×2。
本文采用Patch GAN判别器网络。输入1帧256×256的RGB三颜色通道图像,输出8×8的二值矩阵。其中,前5层卷积层卷积核的尺寸为3×3、步长为2的卷积层,最后一层卷积核的尺寸为1×1。
本实验刻画接受者操作特征(Receiver Operating Characteristic, ROC)曲线,取曲线下面积(Area Under Curve,AUC)作为视频异常帧检测性能评价指标。AUC值越高,表示该网络的异常行为检测效果越好。本文考虑以下2种对比方案。
对比方案1:通过生成器得出预测帧,计算PSNR后归一化得出异常得分;
对比方案2:通过生成器得出预测帧,对实际帧以及预测帧进行前景提取后的图像,计算PSNR后归一化得出异常得分。
3.3 性能结果分析
图3显示了UCSD-Ped1测试集的ROC曲线。对比方案1的AUC值为0.794 6,对比方案2的AUC值为0.794 4,本文方案的AUC值为0.802 3。这表明了本文基于前景区域的异常行为帧检测方案的有效性。根据图3的ROC曲线前段,对比方案1相较于本文所提方案的效果好,原因在于生成器对于某些小画幅的正常行为不能很好地预测。这表明F-PSNR相较于PSNR对异常行为的预测更加敏感。
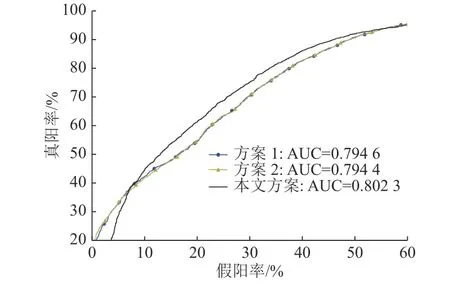
图3 UCSD-Ped1测试集实验结果Fig.3 Experience result in UCSD-Ped1
图4显示了UCSD-Ped1测试集的第2段视频,该视频含有200帧,存在的异常行为是人行道中骑自行车。相比于基于PSNR准则,本文基于F-PSNR准则的方案对正常行为的检测取得更高的异常检测得分,而对异常行为的检测取得较低的异常检测得分,使异常检测得分具有更高的分辨率,故能很好地对正常行为以及异常行为进行区分。
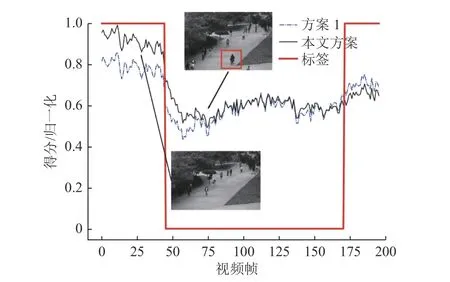
图4 UCSD-Ped1测试集第2段视频实验结果Fig.4 Experience result of the 2nd test video in UCSD-Ped1
图5显示了UCSD-Ped1测试集某视频帧前景提取的实验结果。图5(a)是原视频帧,图5(b)是原视频帧通过前景提取的前景区域,图5(c)是本实验提取前景的掩码。可以看到,在UCSD-Ped1测试集的场景下,前景提取能很好地提取出前景区域,表明F-PSNR能实现较好的视频异常行为检测性能。图6显示了UCSD-Ped2测试集的ROC曲线。对比方案1的AUC值为0.868 8,对比方案2的AUC值为0.866 1,本文方案的AUC值为0.878 8。本文基于前景增强异常行为检测方案具有显著的性能增益。图6的ROC曲线后段,对比方案1相较于本文所提方案的效果好,这是因为网络对于某些小画幅的正常行为无法有效地预测。此外,相比于检测全景区域的峰值信噪比PSNR准则,仅检测前景区域的峰值信噪比FPSNR准则对异常行为具有较强的检测敏感性,导致F-PSNR误判了预测帧的正常行为。

图5 UCSD-Ped1测试集前景分析Fig.5 Foreground analysis in UCSD-Ped1

图6 UCSD-Ped2测试集实验结果Fig.6 Experience result in UCSD-Ped2
图7显示了UCSD-Ped2测试集的第4段视频,该视频含有180帧,存在的异常行为是人行道中骑自行车以及驾驶机动车。相比于基于PSNR准则,本文基于F-PSNR准则的方案对异常行为的检测取得较低的异常检测得分,使异常检测得分具有更高的分辨率,能很好地对正常行为以及异常行为进行区分,因而具有较好的视频异常行为检测性能。
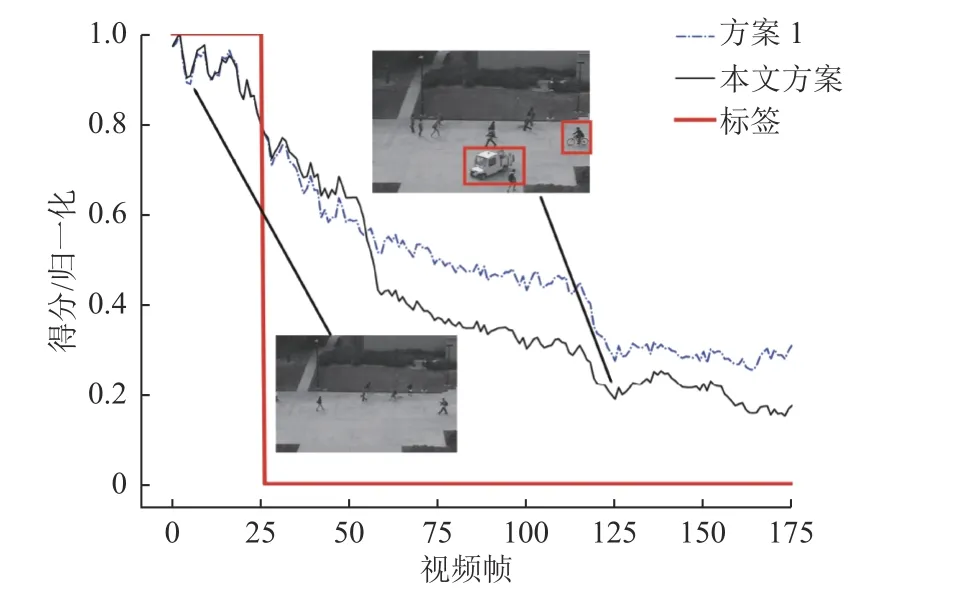
图7 UCSD-Ped2测试集第4段视频实验结果Fig.7 Experience result of the 4th test video in UCSD-Ped2
图8显示了UCSD-Ped2测试集某视频帧前景提取的实验结果。图8(a)是原视频帧,图8(b)是原视频帧通过前景提取的前景区域,图8(c)是本实验提取前景的掩码。在UCSD-Ped2测试集的场景下,前景提取能很好地提取出前景区域, F-PSNR具有较好的视频异常行为检测性能。
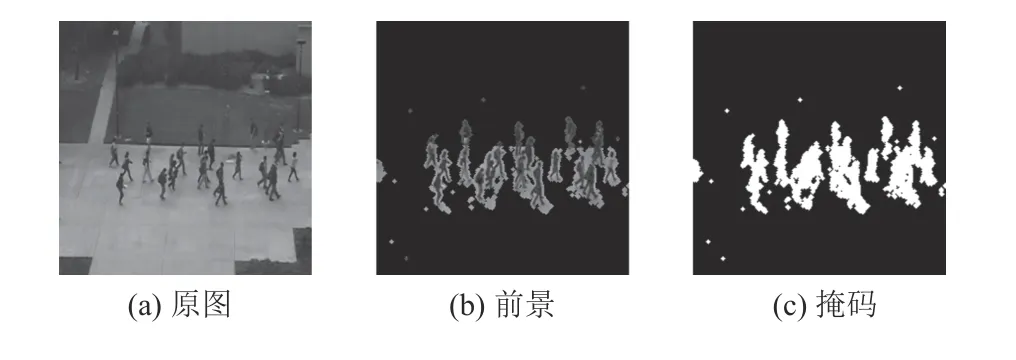
图8 UCSD-Ped2测试集前景分析Fig.8 Foreground analysis in UCSD-Ped2
图9显示了CUHK-Avenue测试集的ROC曲线。对比方案1的AUC值为0.850 6,对比方案2的AUC值为0.810 8,本文方案的AUC值为0.873 2。本文方案相比对比方案1以及对比方案2均有提升。对比方案2相比于对比方案1性能下降的原因在于前景提取未能很好地将前景提取出来。但部分前景信息的缺失并未导致本文方案F-PSNR评估的准确率下降。实验结果表明,部分前景信息的缺失对实验结果并未造成明显的影响,本文方案依旧优于传统方案。

图9 CUHK-Avenue测试集实验结果Fig.9 Experience result in CUHK-Avenue
图10显示了CUHK-Avenue测试集某视频帧前景提取的实验结果。图10(a)是原视频帧,图10(b)缺失了图10(a)红框内的前景人物的前景区域,图10(c)是本实验提取前景的掩码。因背景与前景融合在一起,前景提取未能有效提取前景,这导致CUHK-Avenue测试集中前景信息的缺失。图10实验结果表明,视频异常行为检测方案的设计重点是前景信息提取。

图10 CUHK-Avenue测试集前景分析Fig.10 Foreground analysis in CUHK-Avenue
表1显示了PSNR与F-PSNR在3个数据集中的测试集检测时间。在CUHK-Avenue测试集中,FPSNR相比PSNR检测时间减少了46.23%;在UCSDPed1测试集中,F-PSNR相比PSNR检测时间减少了44.37%;在UCSD-Ped2测试集中,F-PSNR相比PSNR检测时间减少了41.41%。相比于传统的PSNR准则,F-PSNR准则能有效降低计算复杂度。

表1 检测时间对比Table 1 Detection time comparison table
4 结论
本文提出了基于前景区域生成对抗网络的视频异常行为检测的改进方案,通过建立F-PSNR准则,计算视频帧的异常得分,进而完成视频异常行为检测任务。所提方案能有效提升视频异常行为检测的准确率,并降低检测运行时间。实验结果表明,所提基于F-PSNR准则的检测方法的性能在UCSDPed1数据集及UCSD-Ped2、CUHK-Avenue数据集上有所提升。未来将改进视频异常行为检测的深度学习网络模型,提高前景区域信息的有效利用率。
猜你喜欢
导航定位学报(2022年5期)2022-10-13
建材发展导向(2021年6期)2021-06-09
今日农业(2020年17期)2020-12-15
中国外汇(2019年11期)2019-08-27
通信学报(2019年5期)2019-06-11
电光与控制(2018年10期)2018-10-13
通信技术(2018年3期)2018-03-21
太空探索(2016年10期)2016-07-10
浙江大学学报(工学版)(2015年4期)2015-03-01
电子设计工程(2015年20期)2015-01-29
