
人工智能生成内容的著作权法之辩
2024-03-02 03:21刘少军聂琳峰
南昌大学学报(人文社会科学版) 2024年1期
刘少军 聂琳峰
(中国政法大学 民商经济法学院,北京 100088)
2022年11月30日,OpenAI重磅发布ChatGPT,短短5天内注册用户超过100万,2个月内活跃用户高达1亿。作为一款人工智能语言模型,ChatGPT具有强大的理解能力、严谨的推理能力和精准的表达能力,足以胜任语言交流、文本撰写和代码编辑等工作。随着人工智能之争愈燃愈热,我国多家机构也迅速跟进。2023年2月20日,复旦大学发布了大型语言模型——MOSS;同年3月16日,百度发布了大型语言模型——文心一言。从功能来看,ChatGPT属于人工智能生成内容(artificial intelligence generated content,简称AIGC(1)①①一般认为,AIGC既指内容本身,又指内容生产过程,还指内容生产技术合集。基于论述方便,本文对这三个概念不作区分。)的前沿应用之一。
当前,学界对人工智能生成内容的著作权法研究方兴未艾,取得了一系列研究成果,为机器阅读法律性质、生成内容可著作权性和生成内容著作权归属研究提供了诸多视角。但是,这些研究都有一个明显缺陷——未关注人工智能生成内容的类型差异。事实上,人工智能生成内容的类型差异在很大程度上决定了其著作权差异。因此,科学的研究思路应当是:以技术路径为出发点,先分析机器阅读的法律性质,再分析人工智能生成内容的可著作权性,最后分析人工智能生成内容的著作权归属。
一、人工智能生成内容的技术路径分析
“技术就是被捕获并使用的现象。”[1]53技术本身充满着生机与希望,也充斥着危机与风险[2]52,因此对AIGC技术路径进行全景解析成为降低技术非理性风险、加强科技伦理治理的前置环节。具体而言,AIGC技术路径可以从生成程序和内容类型两个维度展开,前者注重动态过程观察,后者倾向静态结果观察。
(一)生成程序:数据输入→机器学习→内容输出
数据、算法和算力是数字时代的核心生产要素,数据输入阶段以数据为主,机器学习阶段以算法、算力为主,内容输出阶段是数据、算法和算力结合的产物。
第一,数据输入阶段。数据输入是生成程序的首要环节。数据的多少和好坏决定了内容输出的质量。数据输入并非数据的机械堆砌,数据输入阶段包括数据收集、清洗和标注三个环节。数据收集是指从各种渠道获取大量资料;数据清洗是指对已收集数据进行预处理,如删除重复数据、填补缺失数据、处理异常数据等;数据标注是指对数据进行注释,使得计算机自动识别数据的模式与关系,并进行分类、分析和推理。这是训练计算机算法的关键一步。
第二,机器学习阶段。机器学习是生成程序的核心环节。学习的模式和方法决定了内容输出的质量。以ChatGPT为例。它采用一种基于自注意力机制的深度神经网络模型——transformer。ChatGPT的机器学习过程包括预训练和精调两个环节。预训练是指transformer对未标注的海量数据进行无监督学习,目的在于掌握文本中的语法和语义关系等;精调是指transformer对已标注的特定数据进行监督学习,如给定多组已知的输入和输出数据,让transformer学习输出与输入之间的映射关系,目的在于使模型理解人类意图,与人类行为对标。
第三,内容输出阶段。内容输出是生成程序的终局环节。数据输入和机器学习只是赋予人工智能以结构化的知识储备和类人化的思维方式。只有这两个阶段无法直接产生AIGC。以ChatGPT为例。只有使用者输入相关指令,才会触发ChatGPT的深度神经网络模型。ChatGPT根据输入指令和语言模型预测下一个可能的文本序列,再将这个文本序列作为输入指令预测下一个可能的文本序列。循环往复,不断迭代,直到生成语言流畅、语境合理、逻辑严谨的文本。
随着人工智能技术的迭代升级,AIGC呈现数实融合动向,从单模态迈向多模态、跨模态。这推动了不同模态数据之间的转换与生成,如文本、语音、图片和视频等模态之间实现了自由切换。考虑到人工智能的渐进式发展趋势,预计触觉、嗅觉等也将逐步纳入多模态序列。实际上,数实融合的终极载体是元宇宙,AIGC的无限复刻性、自主生成性有助于建成元素丰富、体感真实和全景沉浸的元宇宙世界。
(二)内容类型:孪生内容、伴生内容、原生内容
根据指令输入与内容输出的对应程度高低,可以将内容输出依次分为孪生内容、伴生内容和原生内容。
第一,孪生内容。孪生内容是指AI对使用者输入指令的同比例复制,如同1%(AI提供)+99%(输入指令)=100%(孪生内容),只限于跨模态复刻。孪生内容的关键特征是准确性。模态转换必须保证原始信息的精准呈现。孪生内容被广泛应用于赛事转播、天气预报等领域。如2022年北京冬奥会的AI手语主播,她能根据赛事文本和手语词典来同步传译赛事内容。
第二,伴生内容。伴生内容是指AI对使用者输入指令的差异化表达,如同50%(AI提供)+50%(输入指令)=100%(伴生内容),跨模态、单模态编辑均可。伴生内容的关键特征是二次编辑。AI根据使用者需求对输入指令进行智能修改,保证原始信息的重点呈现。伴生内容被广泛应用于影视娱乐等领域,如剧本润色、影视色彩渲染等。
第三,原生内容。原生内容是指AI对使用者输入指令的创造性表现,如同99%(AI提供)+1%(输入指令)=100%(原生内容),跨模态、单模态编辑均可。原生内容的关键特征是全新创作。AI在使用者给定模糊概念的基础上,进行自由生成与创作,原始信息仅为全新创作提供方向指引。原生内容应用领域非常广泛,如百度的文心一格可以根据用户的简单描述立即生成图片,ChatGPT可以根据用户的一个想法立即生成文章。
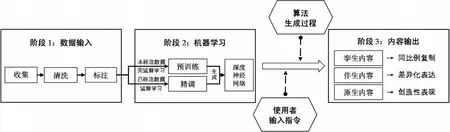
图1 人工智能生成内容的技术路径
二、人工智能机器阅读的法律性质之辩
个人阅读内含双重法益,即原作品著作权人的专有权利与其他人对原作品的接触权利,前者旨在激励作品创作,后者旨在促进作品传播。为平衡作品创作与传播,一定限度的合理使用制度应运而生,如《中华人民共和国著作权法》(以下简称《著作权法》)第二十四条。一方面,“合理使用”体现为他人不经著作权人许可即可免费使用作品;另一方面,“一定限度”体现为使用限于个人学习等目的,且不得影响作品正常使用和著作权人权益。机器阅读则不同。人工智能机器阅读横跨数据输入阶段与机器学习阶段,会自动收集、整理并分析大量信息。考虑到机器阅读的自动性、规模性与个人阅读的人工性、有限性之差异,如果机器阅读仍适用合理使用制度,可能会不当扩大接触权利并压缩专有权利[3]657。从逻辑关系来看,确定机器阅读的法律性质是确定生成内容可著作权性和著作权归属的前置条件。因此,应当首先明确机器阅读的法律性质。
(一)现行解释方案之检视
关于人工智能机器阅读的法律性质,学界众说纷纭,主要有授权许可说、合理使用说和法定许可说。三者集中体现了著作权行使与著作权限制之间此消彼长的关系。
1.授权许可说:权利行使>权利限制
授权许可说的基本观点是,计算机的任何复制行为均需要得到著作权人的授权许可,包括机器阅读。该说主张作品是作者人格、精神的延伸,作者理应全面控制作品[4]141-143,其理论渊源是人格理论(2)根据知识产权法哲学,知识产权正当性理论主要有劳动理论、人格理论、激励理论和衡平理论。。受人格理论影响,以《伯尔尼公约》为核心的传统著作权法体系的整体基调为“作者中心主义”,这严重挤压了合理使用制度的适用空间[5]174。部分学者认为,计算机的复制行为应受《伯尔尼公约》第九条第一款和《世界版权公约》第四条之二以及各国著作权法的约束,即复制行为必须取得著作权人授权许可[6]123。显而易见,以人格理论为基础的授权许可说更重视著作权专有属性,即著作权行使>著作权限制。
授权许可说有其不足之处。第一,可操作性较差。不同于个人学习,机器学习样本包罗万象。如果逐一识别学习样本的著作权属并征得著作权人授权许可,其交易成本太高。第二,过度保护著作权人限制了知识传播和技术发展。以《著作权法》第一条为例。本法制定目的在于鼓励创作与促进传播,而授权许可说片面强调著作权人的人格利益和权利保护,只鼓励了创作,未能促进传播。第三,若一项作品的人格属性很少或殆无,如汇编作品,人格理论就难以为授权许可说提供正当性[4]168。
2.合理使用说:权利行使<权利限制
合理使用说的基本观点是,计算机的复制行为无须著作权人许可,且无须向其支付报酬,但复制行为不得影响该作品的正常使用,也不得损害著作权人的合法权益。该说主张增加社会智力产品总量来促进社会发展,其理论渊源是激励理论。该理论认为智力产品有三重属性:一是非排他性,不同使用者的使用行为之间并非互斥,即使用可以并行;二是非消耗性,不同使用者的使用行为不会增加智力产品的利用成本,即边际成本为零;三是公共属性,该属性源于非排他性。经济学家保罗·萨缪尔森认为,私人产品具有排他性,公共产品具有非排他性,因而具有非排他性的智力产品应当属于公共产品[7]122。显而易见,以激励理论为基础的合理使用说更重视著作权公有属性,即著作权行使<著作权限制[8]221-224。
合理使用说有其不足之处。第一,激励理论无法区分合理使用说与法定许可说。两种学说都能够激励创作,只是合理使用说对使用者的激励程度更高,法定许可说对著作权人的激励程度更高。第二,机器阅读适用合理使用说可能有违激励理论的初衷。机器阅读范围浩瀚无垠,理论上可以抵达知识总量极限。倘若机器阅读适用合理使用说,相当于所有智力产品的销售价格均归于零,长此以往必然减损个人的智力生产动力。这种逆向淘汰最终不利于社会知识增值。
3.法定许可说:权利行使≈权利限制
法定许可说的基本观点是,计算机的复制行为无须著作权人许可,只需向其支付报酬;复制行为不得影响作品正常使用,也不得损害著作权人合法权益。该说的理论渊源是衡平理论,认为一段时期内的知识总量是恒定的。恒定范围内的公有知识和专有知识此消彼长。公有成分过高会弱化著作权保护,降低创作动力;专有成分过高会导致接触作品困难,妨碍知识传播。这两种偏差最终会导致同一结果,即知识总量的萎缩。衡平理论主张兼顾著作权人对智力产品的专有垄断和社会公众对智力产品的合理需求[4]235。显而易见,以衡平理论为基础的法定许可说兼顾著作权专有属性和共有属性,即著作权行使≈著作权限制。之所以不用“=”,一是行使与限制的完全平衡几无可能;二是“≈”象征行使与限制的动态平衡,特殊情形下可以适当倾斜保护某个方向。
法定许可说有其可取之处。第一,符合正义论。授权许可说要求逐一取得著作权人许可,不符合鼓励传播的立法宗旨;合理使用说完全忽视了著作权人,不符合鼓励创作的立法宗旨。法定许可既尊重著作权人的专有权利,又保证人工智能的言之有物,正好符合著作权法兼顾保护与限制的二元价值取向。第二,符合效率论。对著作权人而言,法定许可带来了充分的经济刺激,能提高创作效率;对机器阅读而言,法定许可绕过了烦琐谈判环节,能提高作品利用、传播效率[9]23。因此,三种学说中以法定许可说最为合理,可以将机器阅读行为的法律性质确定为一种法定许可行为。
(二)应然解释方案之构建
根据法律关系的构成要素[10]151-162,可以尝试从主体、客体和内容三个角度建立机器阅读的法定许可制度。
1.机器阅读法定许可之主体
机器阅读涉及两个主体,分别是人工智能所有者和著作权人。就人工智能所有者而言,人工智能机器阅读源于其指令,应由其向著作权人支付法定许可费;就著作权人而言,考虑到著作权保护需要,如其明确表示不接受机器阅读行为,法定许可不应当延及该作品。
2.机器阅读法定许可之客体
除作品外,客体还包含大量的其他信息。根据不同的信息种类,法定许可权限自然不同。一是不受著作权法保护的信息,如事实数据、公理常识、法律政策、无独创性内容和已逾保护期的作品等,这些信息任何人均可自由访问,机器阅读也不例外;二是受著作权法保护但未发表的作品,未发表行为表明不希望他人接近作品,法定许可不应当延及该作品;三是受著作权法保护且已发表的作品,这类信息恰好落入法定许可权限内,应当允许机器阅读。另外,若客体为个人信息,机器阅读就要以保护个人人格利益为前提,并坚持目的限定、范围最小等原则;若客体为商业秘密,该信息类似未发表作品,法定许可不应当延及该信息[11]50。
3.机器阅读法定许可之内容
内容即指行为,机器阅读可能涉及复制、翻译和汇编等行为。鉴于我国正处于人工智能发展红利期,适当解绑制度束缚有利于实现数字普惠,可以适度增加机器阅读的行为类型。只要不涉及著作人身权规定的行为,如署名或歪曲篡改等,其他著作财产权规定的行为均不受限。至于法定许可使用费的支付问题,可以由著作权集体管理组织作为中介制定统一的费用标准并代为交割[12]79。至于机器阅读痕迹保存问题,可以借助区块链的不可篡改性进行固定,以便后期查验与统计[13]167,[14]136。
综上,从著作权的行使与限制角度出发,法定许可说更适合机器阅读行为。因此,建议在《著作权法》第二章第四节“权利的限制”中增设机器阅读法定许可条款:“除著作权人明确保留外,人工智能所有者可以不经著作权人许可,对已发表的作品进行复制、翻译和汇编等,但应当按照有关规定向著作权人支付报酬,并且不得损害著作权人的合法权益。”
三、人工智能生成内容的可著作权性之辩
可著作权性主要围绕AIGC是否构成作品进行探讨。若构成作品,则围绕其建立著作权相关法律制度;若不构成作品,则根据其属性适用其他法律规则。
(一)现行解释方案之检视
关于AIGC的可著作权性,学界莫衷一是,主要有非作品说和作品说。两者结论互斥,但判断标准有部分重合。
1.非作品说
非作品说认为AIGC并非作品。关于分析路径,非作品说内部各执一词。
观点一为作者视角。该观点提出自然人创作作品是著作权法体系的基本规则。如《伯尔尼公约》第七条规定“本公约给予保护的期限为作者有生之年及其死后五十年内”,死亡只属于自然人,所以公约之作者只能为自然人;2019年国际知识产权保护协会的专家组决议“由人类介入而产生独创性表达是人工智能生成品享有著作权保护的必要条件”(3)AIPPI World Congress:Resolution 2019-Study Question Copyright in Artificially Generated Works(2019),https://www.aippi.org/content/uploads/2022/11/Resolution_Copyright_in_artificially_generated_works_English.pdf.,“由人类介入”表明作者只能是自然人;《著作权法》第十一条第二款规定“创作作品的自然人是作者”,AIGC并非源于自然人,不属于著作权法意义上的作品[15]54。
观点一有其不足之处。第一,该观点存在逻辑逆反。从逻辑来看,著作权的推理顺序为:先判断是不是作品,再认定作者是谁,最后确定著作权归属。如《著作权法》第三条为作品判断条款,第九条为作者认定条款,第十一条为归属确定条款。该观点将作者认定置于首位,可能会陷入逻辑循环[16]196,即“∵作者不是自然人,∴生成内容不是作品”,“∵不是作品,∴没有作者”,“∵没有作者,∴不是作品”。第二,该观点预设前提存疑。该观点预设自然人不可能成为AIGC作者,这一预设本身缺乏正当性理由。人工智能源于设计者。虽然AIGC可能超出使用者预期,但是难以超脱设计者的概括预期。对于设计者、使用者是否可能成为AIGC作者,该观点涉猎不深。
观点二为作品视角。该观点主张作品必须具有独创性。独创性表现为作者将独立创意雕琢进作品的过程,而人工智能生成过程只是代码的排列组合,生成结果具有唯一性。即使生成内容的形式、风格无限接近人类,也无法满足独创性要求。据此,该观点认为,AIGC不属于著作权法意义上的作品[17]151。
观点二有其不足之处。第一,该观点理论基础存疑。该观点源自人格理论。该观点承认原创内容、汇编内容均为作品,前者人格属性明显大于后者,可见该观点对不同内容类型实行了人格属性双重评价标准。按照这个推理逻辑,人格属性殆无的汇编内容属于作品,人格属性相似的AIGC自然也属于作品。可见,推理结论与观点结论正好相反。第二,该观点认为AIGC之所以不具有独创性,是因为生成结果具有唯一性。实际情况是同一指令下ChatGPT的生成内容具有多样性(详见示例1)。
示例1 ChatGPT问答(4)为证实人工智能生成内容是否具备唯一性,作者数次向ChatGPT-4提出同一问题,每次输出结果均不相同。本示例列举了其中两次问答。
User:以“春天”为题写个故事,限100字以内。
GPT:春天来临,小花拼命努力,绽放出耀眼光彩。小草也不甘示弱,迎风舞动。一天,太阳公公累了,躲进云层。小草与小花默契地共同撑起一把绿伞,为疲惫的太阳遮风挡雨。
User:以“春天”为题写个故事,限100字以内。
GPT:春天到来,小松鼠走出冬眠的巢穴。在森林里寻找美食时,遇见了小兔子。它们结伴欢快地探索春天的美景,分享甘甜的果实。春日阳光下,两个小伙伴结下了深厚的友谊,携手欢度美好时光。
由示例1可知,当输入同一指令时,人工智能生成内容并不相同,即生成结果不具有唯一性。
2.作品说
作品说认为AIGC构成作品。与非作品说类似,作品说内部也众说纷纭。
观点一为作者视角。该观点主张个人对智力劳动产品享有著作权。该观点的理论渊源是劳动理论,认为每个人都拥有自己的身体及其劳动,这种拥有必然会延伸至劳动产品。故而,劳动成为判断智力产品是否属于作品的唯一标准。这又引申出了“额头冒汗原则”:只要作者付出了汗水,就创作了著作权法意义上的作品。具体到AIGC,该观点认为AIGC与个人作品付出的汗水是相同的。部分学者认为是人工智能所有者或使用者付出了汗水;部分学者认为是人工智能本身付出了汗水,因人工智能无法享受权利、履行义务,只能由自然人代位行使[18]140。
观点一有其不足之处。第一,该观点模糊了作品与非作品的界限。按照该理论,任何智力劳动产品均为作品,那么很多不具有作品属性的内容也将成为作品,如对事实的陈述、对公理的整理等,这些活动同样付出了劳动,将其视为作品会不当扩大著作权保护范围。第二,该观点有将人工智能当成法律主体之嫌。就目前技术水平而言,人工智能还不具备法律权利能力和行为能力,贸然将其视作法律主体可能会扰乱社会秩序。
观点二为作品视角。该观点主张作品必须具有独创性。相比之下,非作品说第二种观点侧重独创性主观主义,认为独创性的核心是人格属性;作品说第二种观点侧重独创性客观主义,认为独创性的核心是客观最低限度创造性。
观点二有其可取之处。第一,在推理逻辑上,该观点符合著作权的推理顺序。第二,在发展趋势上,独创性客观主义符合近年著作权法“去人格化”趋势。如著作权法晚近新增的计算机软件作品,几乎没有人格属性;又如腾讯诉上海盈某科技案(5)(2019)粤0305民初14010号。,法院在裁判理由部分指出:“判断涉案文章是否具有独创性,应当从是否独立创作及外在表现上是否与已有作品存在一定程度的差异,或具备最低程度的创造性进行分析判断。”相比之下,独创性主观主义局限性十分明显。该观点认为独创性集中体现为作者创作意图,但作品自脱离作者那一刻起,作者创作意图已无从知晓[19]105,正如“一千个人眼中有一千个哈姆雷特”。当然,观点二仍有不足之处。该观点仅根据独创性客观标准评价AIGC是否属于作品,并未考虑使用者输入指令对可著作权性的潜在影响。
(二)应然解释方案之构建
非作品说的观点一和作品说的观点一都存在逻辑颠倒的弊病;非作品说的观点二代表独创性主观主义,作品说的观点二代表独创性客观主义。结合近年来著作权法的“去人格化”趋势,作品说的观点二可能更为合理,只是该观点忽视了输入指令对可著作权性的潜在影响。因此,本文可以考虑以独创性客观主义为基础,结合输入指令对AIGC可著作权性进行类型化分析。
1.AIGC可著作权性之构成要件
从规范角度来看,可著作权性必须从作品构成要件出发。根据《著作权法》第三条,作品有四个构成要件:“文学、艺术和科学领域内”“具有独创性”“以一定形式表现”“智力成果”。关于要件一和三,学界并无争议;争论主要集中于要件二和四。值得注意的是,该条并未提及作者。这表明作品判断与作者认定相互独立,也印证了从作者视角出发确实存在逻辑瑕疵。
第一,AIGC具有独创性。独创性是指AIGC必须具备最低限度创造性,即该生成内容与其他作品之间必须存在可辨别的变化,这种变化本身就是独创性[20]156-157,从腾讯诉上海盈某科技案中可见一斑。至于作者希望通过作品传达出何种思想,与独创性判断无关,每个人所理解的文本思想也并非作者思想,只是读者自身的想法[21]73-74,[22]39。
第二,AIGC属于智力成果。从文义解释来看,“智力成果”中“智力”一词英文为intellectual,“人工智能”中“智能”一词英文为intelligence。两者均源自拉丁语intellectus,意为理解能力,表明人工智能与智力成果之间确有共通之处。从外在形式来看,人工智能生成内容与人类智力创作成果的语言结构、叙事风格和情绪表达等无实质性差异,无提前告知情况下,人类几乎无法辨别两者;从形成过程来看,人工智能计算机硬件对应人类智力活动的最低层次——生理活动,人工智能计算机语言对应人类智力活动的中等层次——信息处理,人工智能程序本身对应人类智力活动的最高层次——思维策略[23]15,可见人工智能基本上实现了人类智力活动的等同替换。因此,AIGC应当属于智力成果。
如果AIGC符合作品四个构成要件,就属于著作权法意义上的作品,可以将其认定为《著作权法》第三条第九项规定的“符合作品特征的其他智力成果”,未来也可以考虑增设一项“人工智能生成作品”。
2.AIGC可著作权性之内容类型
多数学者止步于构成要件环节,认为AIGC均构成作品。其实除了AIGC本身,还必须考虑输入指令对AIGC的潜在影响。
第一,孪生内容不属于作品。如人工智能根据输入指令内容,自动将文本内容生成语音内容。只看语音内容,完全符合《著作权法》第三条第六款的视听作品。然而,语音内容本质上是输入指令的同比例复制,两者之间不存在可辨别的变化。因此,孪生内容缺少独创性,不属于作品。至于输入指令是否构成作品,需要根据构成要件具体判断。
第二,伴生内容属于演绎作品。如人工智能根据输入指令内容,自动对文本内容进行润色修改。只看改后文本,完全符合《著作权法》第三条第一款的文字作品。改后文本本质上是输入指令的差异化表达,它同时承载着原文内容和修改内容,是对原内容的再演绎,与原内容之间存在可辨别的变化。因此,伴生内容具有独创性,属于演绎作品。至于输入指令是否构成作品,需要根据构成要件具体判断;如果输入指令构成作品,演绎作品的著作权人行使权利时就必须尊重输入指令的著作权。
第三,原生内容属于原创作品。如人工智能根据输入指令方向,进行自由创作。如示例1,只看生成文本,完全符合《著作权法》第三条第一款的文字作品。该生成文本本质上是输入指令的创造性表现,与其他作品之间存在可辨别的变化。因此,原生内容具有独创性,属于原创作品。至于输入指令,它仅属于方向指引,很难将其界定为作品。
四、人工智能生成内容的著作权归属之辩
著作权归属是指AIGC符合作品构成要件后,由谁享有著作权。在谈及作品权利归属前,必须明确AIGC涉及的相关方,主要包括人工智能本身、所有者、使用者和社会公众(6)人工智能设计者:负责人工智能程序设计的自然人或组织;人工智能所有者:享有人工智能程序所有权的自然人或组织;人工智能使用者:使用人工智能程序生成内容的自然人或组织。以ChatGPT为例。GPT编程人员为设计者,GPT所属公司为所有者,GPT用户为使用者。。
(一)现行解释方案之检视
关于人工智能生成内容的著作权归属,学界意见不一。如果以相关方为归属依据,著作权归属理论至少包括人工智能持有说、所有者持有说、使用者持有说和公共产品说。除此之外,少数学者主张将AIGC视为人工智能的孳息,生成内容归属于所有者。在本质上,孳息说与所有者持有说殊途同归,无单独探讨的必要[24]28。还有少数学者主张绕过作品判断和权属确定的窠臼,直接赋予AIGC邻接权[25]15。问题在于,邻接权的设立目的在于促进作品传播,如对作品进行录音、录像和表演等,相当于将作品从形式甲变成形式乙,并不新增知识;AIGC包括孪生内容、伴生内容和原生内容,仅跨模态的孪生内容接近邻接权,其余两者均属于作品创作,可以新增知识。故而,将创作产生的著作权认定为促进传播的邻接权,既不符合邻接权设立目的,也不当限缩了著作权利范围,更不利于知识增值。因此,孳息说、邻接权说并未成为主流。
1.人工智能持有说
人工智能持有说的基本前提是人工智能必须成为法律主体,既要具备独立思维能力,又要具备独立责任能力,两者缺一不可[26]70。以ChatGPT为代表的人工智能正处于由弱人工智能向强人工智能的过渡阶段,当前还不具备独立的思维能力,假使未来具备独立的思维能力,也难以独立承担责任[27]36。在可预见范围内,人工智能无法成为法律主体,更无法成为著作权人。即使最具前瞻性的学者,也只主张将人工智能与人类列为共同作者,著作权仍归属于人类。
2.使用者持有说
使用者持有说的基本观点是,使用者是AIGC著作权人。其理由有二。第一,使用者与作品的时空联系最为紧密。使用者输入指令是人工智能生成内容的触发条件,即输入指令与生成内容之间具有条件关系。纵然输入指令十分简单,也不能否认使用者付出智力劳动的事实,其对智力劳动成果应当享有著作权[23]40。第二,有利于建立良性利益分配模式。赋权使用者会增加使用者数量,使用者增加会提高所有者利润收入,利润上升会推动所有者加大资金投入,资金充裕会优化人工智能性能,性能升级又会吸引更多使用者,从而形成技术进步、知识繁荣的良性循环。
使用者持有说有其不足之处。第一,该观点陷入劳动理论的泥淖。劳动理论会不当扩大著作权保护范围,形成事实上的思想垄断。第二,该观点认为输入指令与生成内容之间具有条件关系,所以输入指令的使用者对生成内容拥有著作权。事实上,并非只有输入指令与生成内容之间具有条件关系,设备提供行为、电力提供行为也与生成内容之间有条件关系。按照条件关系判断,设备提供者、电力提供者也应当享有著作权,但是这一结论显然不合理。第三,若使用者拥有生成内容著作权,则会严重影响学术生态,从国内外多家学术期刊声明不接受人工智能署名的论文中可初见端倪(7)国外学术期刊如《自然》《柳叶刀》等,国内学术期刊如《暨南学报(哲学社会科学版)》等。。
3.所有者持有说
所有者持有说的基本观点是,所有者是AIGC的著作权人。其理由如下:人工智能是所有者向机器注入智能的结果,人工智能会根据所有者设定的智力方向进行有限创新,此时人工智能视为所有者的意志延伸,当然由所有者享有AIGC著作权[18]145。如同代理关系,被代理人向代理人注入代理事项和权限,代理人在权限范围内的行为由被代理人承担责任。即使代理人实施代理行为与被代理人知道代理行为之间存在时差,但代理行为并未超脱被代理人的概括认知,也理应由被代理人承担责任。
部分学者对所有者持有说提出质疑。(1)所有者双重获利问题。所有者持有说意味着所有者同时享有人工智能程序及其生成内容的利益,这有违公平正义,即一个行为不得双重保护[20]110。该质疑不足为虑。第一,避免双重获利源自损益相抵原则,即受害人所获赔偿不得高于损失范围,禁止受害人额外得利引发道德风险。但所有者并非受害人,其双重获利也不会引发道德风险,对所有者机械套用受害人规则无异于张冠李戴。第二,所有者双重获利源于双重付出。在数据输入阶段,所有者需要根据法定许可说向原作品著作权人支付相应报酬;在机器学习、内容输出阶段,所有者均需要承担相应设计、运行成本。故双重获利具有经济合理性。(2)所有者意识缺失问题。使用者作为介入因素中断了所有者与生成内容之间的关联,使用者相比所有者距离作品更近。该质疑不足为虑。第一,关于意识缺失。所有者虽无法预料具体生成内容,但每次生成过程必然沿着所有者预设轨道执行,所有者对生成内容具有概括认知。同时,所有者的意识延伸包括人工智能系统。当使用者启动人工智能生成程序时,所有者已经具备掌握使用者输入指令和人工智能生成过程的能力。第二,关于时空差异。先到先得规则并不适用于著作权,不然法人作品永远只能是自然人享有著作权,毕竟其距离更近,但这不符合逻辑。根据相当因果关系说,使用者介入因素十分正常,所有者在设计人工智能程序时已经预见到使用者的输入指令行为,生成内容与所有者、使用者之间均有因果关系,根据所有者、使用者的作用大小确定著作权归属更为合理。(3)部分学者提出将著作权归于使用者有利于激励创作[20]108。其实,这个激励作用源自著作权本身而非归属结果,归于所有者同样可以激励创作。可以说,所有者持有说是各学说中最合理的,只是该观点尚未考虑输入指令的介入影响,毕竟AIGC是所有者智力注入行为和使用者输入指令行为的结合产物,根据两个因素对生成内容的贡献程度来确定著作权属可能更为合理。
4.公共产品说
公共产品说是非作品说的延伸。该说认为AIGC不属于作品,既无法成为著作权客体,也难以成为邻接权客体,故不受著作权法保护,任何人均可自由使用。
公共产品说有其不足之处。第一,公共产品说的理论前提存疑。非作品说之作者视角的推理顺序存在逻辑逆反,非作品说之作品视角的人格理论存在合理性瑕疵。非作品说尚且难以自圆其说,更无法为公共产品说提供理论基础。第二,公共产品说不利于促进技术发展和知识增值。促进和兼顾公共利益是我国著作权法的原则之一,但这项原则更多是指平衡作者利益与公共利益,既要保护作者权利,鼓励作者创作更多的作品,又要保护公共权益,允许公众适当接触作品。而公共产品说全盘舍弃作者权利,从长期来看有损技术进步与知识增值,单独追求公共利益最终反噬公共利益。
(二)应然解释方案之构建
人工智能持有说缺乏法律基础,使用者持有说具有逻辑瑕疵,公共产品说不符合著作权立法目的。在各家学说中,所有者持有说较为合理,只是未考虑介入因素影响。因此,可以考虑结合协议内容和各方贡献程度确定AIGC的著作权归属。
1.AIGC著作权归属之协议优先
意思自治原则是民事法律关系的基本原则。根据意思自治原则,民事主体可以基于自由意志,通过签订合同等民事法律行为设立、变更或终止与他人的法律关系。如《中华人民共和国民法典》第五条的“自愿原则”和《著作权法》第九条第三款的“著作权转让规则”,都体现了意思自治原则。鉴于此,如果人工智能所有者和使用者等相关主体对AIGC著作权归属问题有特别约定,只要该约定不违反法律强制性规定,应当以约定为准。事实上,多数人工智能公司与用户签订的著作权协议已明确著作权归属。如NovalAI服务协议的1.3所有权条款,约定由人工智能使用者享有著作权;又如文心一格用户协议的5.4知识产权条款,约定由人工智能所有者享有著作权。
需要注意的是,根据《著作权法》第九条第一款的人身权、财产权二分法,著作财产权可以约定转让,主要包括复制权、演绎权和传播权;著作人身权不可以约定转让,主要包括发表权、署名权、修改权和保护作品完整权。但是发表权与著作财产权是一体两面的,著作财产权转让必然包括发表权。因此,AIGC著作权归属应当以协议为先,协议范围包括著作人身权的发表权和著作财产权。
2.AIGC著作权归属之贡献程度
在未约定著作权归属的前提下,可以根据各方贡献程度确定AIGC著作权归属。这种贡献只包括创作贡献,不含其他贡献。AIGC主要源自所有者注入的知识智力和使用者提供的输入指令。所有者属于前置因素,使用者属于介入因素。同时,各方贡献程度还必须结合可著作权性。当一项生成内容不属于作品时,讨论著作权归属毫无意义。借此,著作权归属方案如下:
第一,孪生内容不属于作品,所有者、使用者均无法享有著作权。孪生内容是输入指令的同比例复制,与输入指令之间不存在可辨别的差异,孪生内容因缺乏独创性不构成作品。既然不构成作品自然,就无须探讨孪生内容著作权的归属。
第二,伴生内容同时属于演绎作品和合作作品,所有者和使用者均享有著作权。从贡献程度看,在“所有者→使用者→生成内容”这组因果关系中,所有者的前置因素和使用者的介入因素均十分重要,生成内容应当同时归属于所有者和使用者。从内容形式角度来看,伴生内容是对输入指令的差异表达,具有客观独创性,所以伴生内容属于演绎作品。从内容生成角度来看,使用者具有具体创作意识,并实施了输入指令这个创作行为;所有者具有概括创作意识,使用者这个介入因素也十分正常。根据相当因果关系说,应当将输入指令这个创作行为也归属于所有者,那么所有者和使用者在不同时点上拥有共同创作意识和行为,所以伴生内容还属于合作作品。
第三,原生内容属于原创作品,仅所有者享有著作权。从贡献程度来看,在“所有者→使用者→生成内容”这组因果关系中,几乎只有所有者的前置因素发挥作用,生成内容本身只能归属于所有者的智力注入行为。对于原生内容而言,它与输入指令之间存在可辨别的差异,具有独创性属于原创作品。
至于输入指令是否构成作品,需要根据作品构成要件具体判断。若不构成作品,则所有者、使用者均无法享有著作权;若构成作品,只能由使用者享有著作权,毕竟所有者对输入指令没有贡献。
五、结语
习近平指出:“人工智能是引领新一轮科技革命和产业变革的重要驱动力,正深刻改变着人们的生产、生活、学习方式,推动人类社会迎来人机协同、跨界融合、共创分享的智能时代。”[28]如同蒸汽机之于蒸汽时代、发电机之于电气时代、计算机之于信息时代,人工智能正成为人类迈入智能时代的核心要素,以ChatGPT为代表的生成式人工智能正是新一轮智慧科技的前沿应用。生成式人工智能主要涉及三个著作权法问题:一是机器阅读法律性质之辩,法定许可说能更好地平衡著作权专有属性与公有属性。二是生成内容可著作权性之辩,需要结合内容类型并考虑输入指令的潜在影响。同比例复制之孪生内容并非作品,差异化表达之伴生内容当属演绎作品,创造性表现之原生内容当属原生作品。三是生成内容著作权归属之辩,需要结合内容类型并考虑参与主体的贡献程度。孪生内容因非作品无人享有著作权;伴生内容同时源于所有者与所有者的概括合作行为与意识,两者共享著作权;原生内容只源于所有者,仅由所有者享有著作权。总之,对于人工智能生成内容可能引发的著作权难题,著作权法应当秉持公平合理、友好促进、包容共享的姿态,以法治之理性、善治之弹性和智治之韧性积极回应著作权法之辩。
猜你喜欢
浙江工业大学学报(社会科学版)(2022年2期)2022-11-22
中国食用菌(2022年5期)2022-11-21
中国食用菌(2022年1期)2022-11-21
社会科学战线(2022年5期)2022-07-23
法制博览(2018年25期)2018-01-22
武汉理工大学学报(社会科学版)(2016年6期)2017-01-10
知识产权(2016年4期)2016-12-01
知识产权(2016年10期)2016-08-21
天津造纸(2014年3期)2014-08-15
电子知识产权(2013年12期)2013-04-14
