
计及误差补偿的两阶段短期电力负荷预测方法
2024-03-01 07:07杨淑凡王永威谢闻捷
电工材料 2024年1期
杨淑凡, 王永威, 谢闻捷
(三峡大学 电气与新能源学院,湖北宜昌 443002)
0 引言
电能很难实现大规模储存,为保证发电量和用电量的动态平衡,需根据用户的用能特点和负荷变化的不确定性,要做好短期电力负荷的精确预测[1]。短期负荷预测是电力系统经济可靠运行的有效工具,基于短期负荷的预测结果,能够帮助发电生产进行规划安排,减少资源浪费,对电网运行的可靠性和安全性进行分析并制定维护计划[2]。
地域不同、社会经济活动、气候变化及电价的波动都会对用户用电行为产生影响。传统预测法包括回归分析法[3]、时间序列法[4]、指数平滑法[5]、灰色理论法[6]等,这类方法预测精度不高,且非线性拟合性能差,无法满足日益增长的负荷预测要求。智能预测法主要基于各类人工智能方法进行预测,例如BP神经网络[7-8]、支持向量机(SVM)[9]、极限学习机(ELM)[10],这类算法相比于传统方法能更有效地处理非线性问题。深度学习算法在传统人工智能算法的基础上得到了进一步的拓展提升[11-12]。组合模型可以结合多种预测模型的优点,有效处理数据样本中的线性和非线性特征,从而提高负荷预测精度。为降低数据样本的波动性和复杂程度,可以采用基于信号分解的组合模型。文献[13]利用经验模态分解算法(EMD)分解短期负荷序列,用最小二乘支持向量机作为预测算法,但EMD算法会出现模态混叠问题,LSSVM不能有效处理时序数据间的关联性问题。文献[14]并没有考虑气象、日类型等外界因素对负荷波动带来的影响,该组合模型的预测误差主要集中在每天负荷峰谷时段。文献[15]采用的LSTM网络无法对预测结果纠错,导致预测的精度降低。
基于以上研究,为避免因外界因素诸如一天中时刻、温湿度、日类型以及预测模型预测过程中的固有误差对居民用户短期负荷预测性能造成的影响,本文构建了一个计及误差补偿的两阶段短期电力负荷预测组合模型:第一阶段,利用变分模态分解[16](Variational mode decomposition,VMD)对具有复杂波动不确定性的电力负荷数据进行分解,降低每个模态的复杂程度,作为负荷预测模型的输入数据集,以在时间序列预测中表现优异的BiLSTM模型为基础,利用萤火虫扰动改进的麻雀搜索算法优化BiLSTM模型中的参数设置,使BiLSTM模型能够根据电力负荷数据的特性,快速、精准地确定最优超参数,构建基于VMD-FASSA-BiLSTM的负荷预测模型;第二阶段,将第一阶段得到的预测值与真实值作差得到模型固有的误差序列、与本文选定的外界影响因素一起作为BiLSTM网络的输入,建立二者之间的非线性关系,利用该模型实现对误差的预测,最后将两阶段的预测结果相加即为最终的预测结果。将上述研究方法应用于某地区某小区的真实电力数据进行仿真实验,验证所提方法在居民用户负荷预测效果中的有效性。
1 基于FASSA-BiLSTM电力负荷预测方法的建模
1.1 麻雀搜索算法的改进
SSA是Xue[17]基于对麻雀的觅食和反捕行为的观察而提出的一种新的智能群体优化算法,与传统算法相比拥有更快的收敛速度和更强的寻优能力。
由于SSA算法在寻优过程中容易陷入局部最优解、在寻优阶段后期种群的多样性减少,导致算法全局搜索能力降低,收敛精度不高,需对其进行改进,克服以上弊端。
(1)混沌初始化:种群个体初始位置的分布情况对算法的寻优能力有很大影响。采用随机性和遍历性更强的混沌序列初始化种群,使初始种群的分布更加均匀。本文采用Cubic混沌映射策略,由此生成的初始种群分布更加均匀,个体之间的差异更小。Cubic混沌映射函数如下:
式中,a、b为混沌影响因子。Cubic映射范围取决于a、b的值。b∈(2.3,3)时,其映射状态为混沌序列。
(2)萤火虫扰动策略:麻雀种群的搜索方式主要是在具有最优位置的个体附近进行,搜索的步长较小,容易陷入局部最优解。因此需要对种群中具有最优位置的个体进行变异扰动,比较扰动前后的适应度值,择优选取,帮助种群跳出局部最优解。本文采用萤火虫扰动策略,对于任意数量的萤火虫,总是会趋向更亮的一只;但是距离越远,亮度也会降低;如果附近没有更亮的萤火虫,则会做随机无规则运动。
萤火虫之间的相对亮度表示为:
式中:rij为第i只和第j只萤火虫之间的欧氏距离;I0是由目标函数的优秀程度决定的萤火虫最大亮度;γ为亮度吸收系数,取值范围为[0,∞)。
萤火虫之间的吸引力表示为:
式中:j*为萤火虫i所能感知到的具有最强亮度的萤火虫,j*=argmax(Iij);η0为最大吸引力。
第i只萤火虫根据式(9)和第j*只萤火虫的位置进行位置更新:
式中:α为步长因子,α和rand均为[0,1]内的随机常数。
1.2 基于FASSA的BiLSTM参数优化方法
采用萤火虫扰动策略改进麻雀搜索算法,利用FASSA对BiLSTM负荷预测模型进行快速精准的超参数寻优,避免因模型参数的选取不当影响预测模型的训练结果,导致训练得到的预测模型不能达到最优精度且会加大模型的训练难度。FASSABiLSTM算法流程如图1所示。建立FASSA-BiLSTM模型的主要步骤如下。
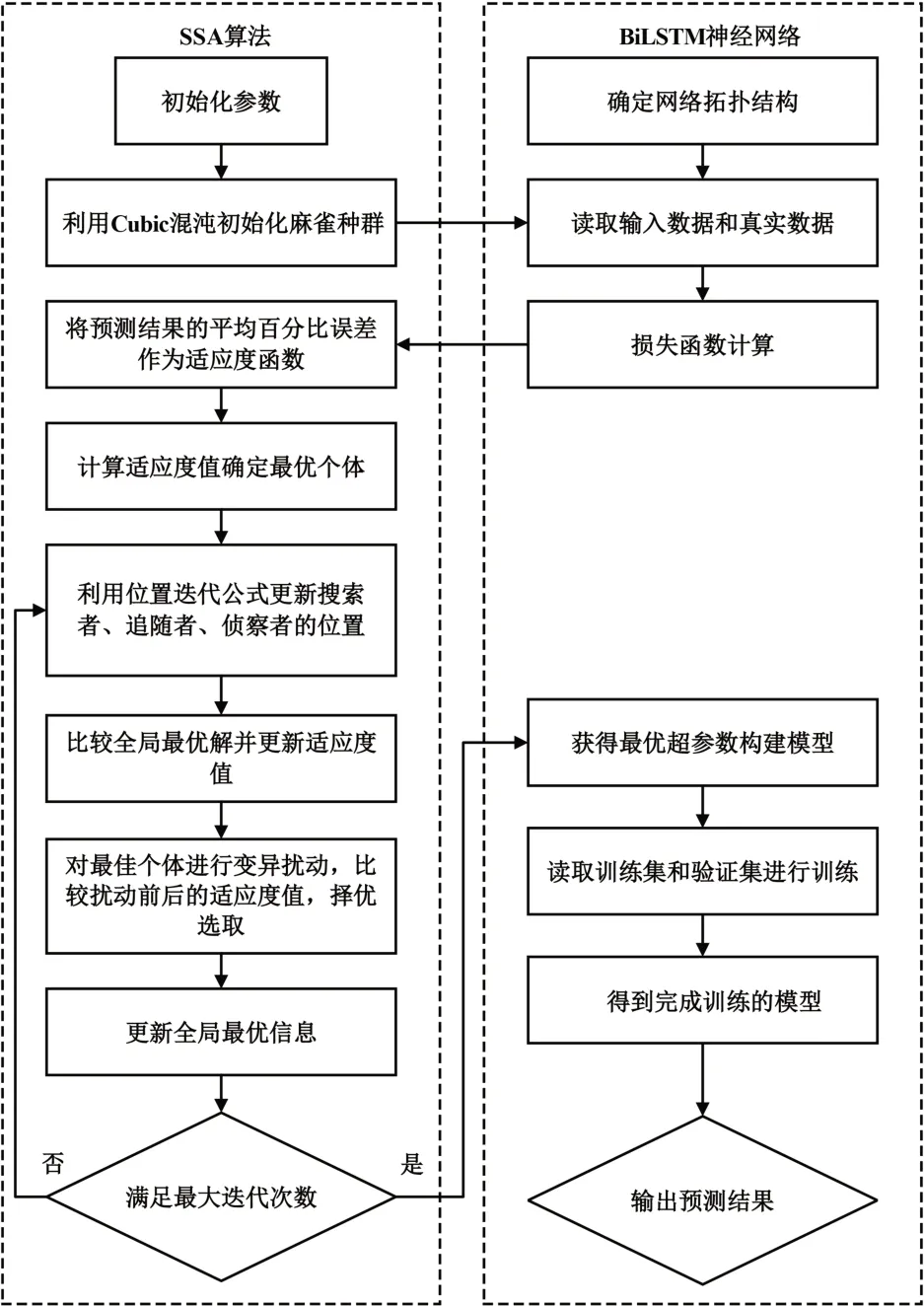
图1 改进SSA-BiLSTM流程
(1)初始化参数:初始化FASSA 的参数;初始化BiLSTM结构,将BiLSTM的相关超参数初始化,以BiLSTM模型的隐藏层神经元个数和学习率作为优化目标。
(2)建立目标函数:将未经训练的BiLSTM负荷预测模型的预测值与实际值相比的平均百分比误差(MAPE)作为FASSA的适应度函数,并计算每只麻雀的适应度值,选取适应值大的前smum个作为搜索者,剩余的为追随者,侦察者的数量为dmum,并得到最优适应度值与最差适应度值及其对应的位置。
(3)寻优过程:在搜索者、追随者和侦察者更新位置的同时,利用萤火虫扰动策略更新变异麻雀的位置,重新计算各个体的适应度值并再次更新最优位置,得到每个个体的最佳位置。当达到设定的最大迭代次数后,得到最优的超参数数值。
(4)BiLSTM训练:将FASSA求得的最优超参数代入到BiLSTM负荷预测模型中,重新进行训练测试,得到负荷预测模型。
2 计及误差补偿的两阶段组合预测模型
2.1 评价指标
为评价预测模型的性能,采用平均绝对百分比误差(mean absolute percentage error,MAPE)和均方根误差(Root Mean Square Error,RMSE)作为模型的评价指标,其公式分别为:
式中:yi和xi分别表示i时刻的真实值和与预测值;n为样本数量。
2.2 负荷预测模型结构
基于优化模型的短期负荷预测过程分为两个阶段,具体的预测流程构架如图2所示。

图2 计及误差补偿的短期负荷预测模型
第一阶段,即初始负荷预测阶段:首先用VMD对原始数据序列进行分解,提高输入数据的质量;然后用FASSA搜索算法对BiLSTM的隐藏层神经元个数和学习率这2个超参数进行自适应寻优,得到最优参数组;最后通过训练好的FASSA-BiLSTM负荷预测模型进行负荷预测,并叠加得到的各分量的预测值,得到初始负荷预测结果。
第二阶段,即误差补偿阶段:由于预测值和真实功率之间存在一定偏差,为进一步提高预测精度,需要对第一阶段的初始负荷预测值进行误差补偿。利用VMD-FASSA-BiLSTM模型得到的负荷预测结果,提取每个时间点的预测误差序列,然后与造成负荷波动和非线性的影响因素(温度、湿度、日类型)共同构成误差训练集,作为误差补偿模型的输入,并建立BiLSTM网络得到预测误差序列。最后将两个阶段得到的预测结果相加,即最终的负荷预测结果。
3 算例仿真
3.1 数据简介
居民用户负荷预测与很多因素有关, 本文主要从日类型因素、历史负荷和温湿度三方面,寻找密切影响社区居民用户用电负荷变化的因素,与负荷数据一起作为预测模型的输入变量,进而提升预测结果的精度。输入变量x的特征集设置如表1所示。
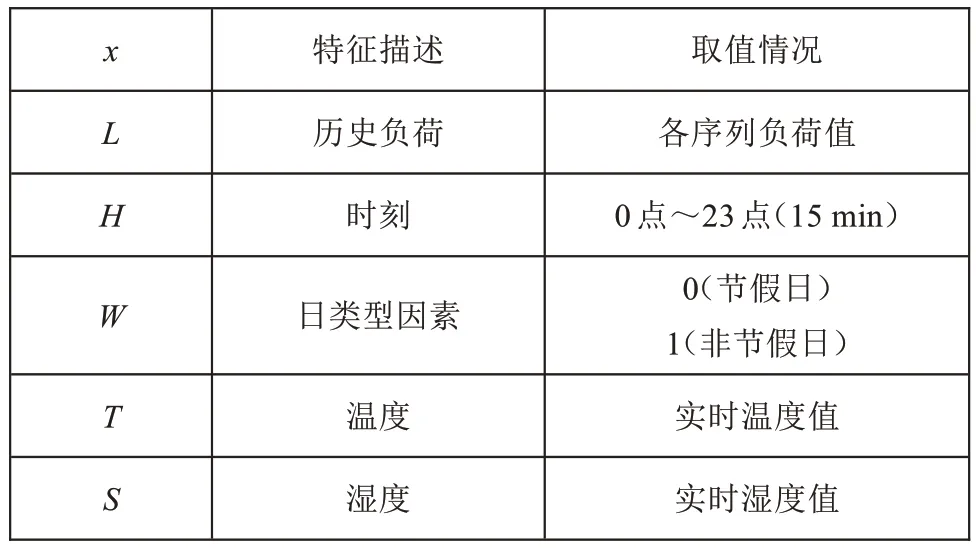
表1 输入变量设置
为验证所提负荷预测模型的准确性,采用的实验样本为江苏省某市某社区2019年6月1日至6月22日的电力负荷数据、日类型因素和温湿度数据,采样间隔为15 min,每天能采集96条原始电力负荷数据,共2112个采样点。将6月1日到6月21日的所有数据划分为训练集,得到已训练的负荷预测模型后,对6月22日全天96个时间点的各个负荷数据进行预测,与实际的数据对比,即可作为验证模型预测精度的判断依据。6月22日该天的特征数据如表2所示。

表2 6月22日相关特征数据
引入最大信息系数[18]来定量分析评价4种外界气象影响因素与负荷数据的相关性。选取4月1日至4月22日的气象数据,气象数据是以1 h为时段提供的24点曲线,因此需要对气象因素的数据进行插值处理,成为和负荷曲线相匹配的96点曲线。计算结果如表3所示。

表3 各影响因素与负荷序列的相关性分析
分析表3中的相关性数据,负荷与一天中的温度具有强相关性,与湿度具有中度相关性,与风速和气压的相关性较弱。结合生活实际,温湿度主要通过影响用户体感舒适度来影响用电负荷的变化,人的体感是温度湿度综合作用的结果。为了选取与负荷相关性更强的气象因素,将阈值设置0.5,因此预测模型气象影响因素的输入选择为温度、湿度。
3.2 负荷序列分解结果
负荷数据序列具有时间依赖性和非平稳波动特性,所以先用VMD将其分解,减少序列的噪声影响,降低其复杂程度。采用遗传算法确定VMD分解的两个关键参数:分解模态数K以及惩罚因子α。遗传算法的种群规模和最大迭代次数均设为50,采用单点交叉,交叉概率为0.8,变异概率设为0.1。通过遗传算法得到的参数最优解分别为K=5,α=1816。原始负荷数据和经VMD分解后的数据如图3和图4所示。
图3 原始负荷数据

图4 负荷序列VMD分解
3.3 FASSA-BiLSTM参数寻优
根据FASSA算法对BiLSTM网络的重要参数(隐藏层神经元个数和学习率)进行寻优,将预测结果和真实数据之间的平均百分比误差作为寻优过程中的适应度函数。设置迭代次数和麻雀种群数量均为100,预警值为0.8。搜索者比例为20%,追随者比例为70%,剩下10%作为侦察者。BiLSTM相关参数的寻优范围如表4所示。最终经FASSA寻优得到的BiLSTM最优参数为{[23,28],0.0024}。

表4 BiLSTM参数寻优范围
为验证FASSA在优化BiLSTM参数时的可行性和优异性能,与其他三种优化算法的结果进行对比分析,以平均百分比误差为适应度的迭代曲线如图5所示。由图5可知,四种优化算法中FASSA收敛速度最快且收敛的精度最高,在20次迭代后达到收敛,FASSA-BiLSTM的适应度值为0.021,且相较于标准的SSA算法,收敛速度和收敛精度都有很大的提升。由此可见,利用FASSA优化BiLSTM的相关参数建立的负荷预测模型具有可行性和优越性。
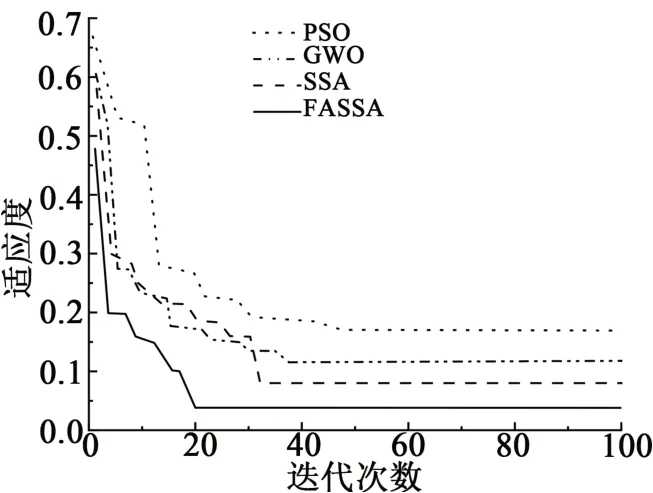
图5 适应度曲线
3.4 计及误差补偿的负荷预测
VMD-FASSA-BiLSTM模型的各部分参量确定后,将VMD分解得到的各IMF分量代入负荷预测模型中进行训练验证,迭代预测出6月22日全天96个时间点对应的数据,然后叠加各分量的预测结果,得到完整的负荷预测数据。
为保证对比试验的合理性和有效性,以上所有预测模型的参数选择均在多次实验下选取的最佳值,均各自执行10次将其结果取均值,预测结果如图6与表5所示。

表5 不同组合方法的精度比较

图6 不同负荷预测模型的预测结果
由图6、表5可知,组合算法具有更好的预测效果,因为组合模型能使整个预测过程更加精细,且本文所提算法的预测结果更接近真实电力负荷数据曲线的变化趋势,预测精度优于其他算法。VMD-FASSA-BiLSTM与VMD-FASSA-ELM、VMD-FASSA-SVM模型相比,其误差指标RMSE分别降低了52.93 kW、38.67 kW;MAPE指标分别降低了0.73%、0.49%。说明结合BiLSTM方法所建立的预测模型精度更高,这是因为BiLSTM能很好地学习提取双向时序数据间的特征。
分别建立初始负荷预测模型、仅补偿模型自身固有误差的预测模型以及以模型自身固有误差和外界影响因素进行补偿的预测模型,3种模型的预测结果与真实值的绝对误差对比如图7所示。
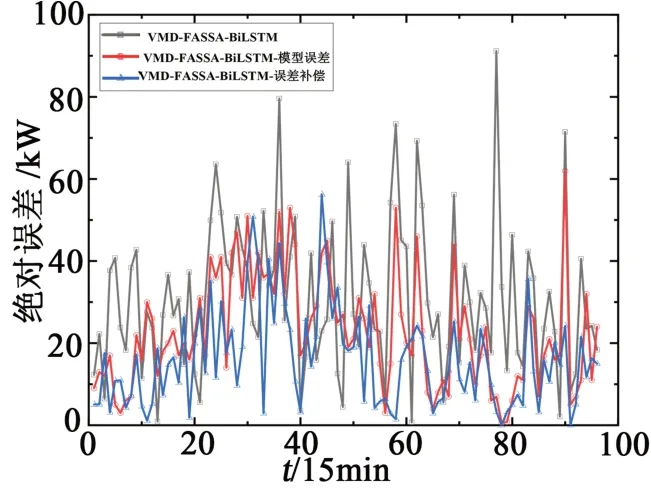
图7 误差纠正前后绝对误差对比图
在VMD-FASSA-BiLSTM预测模型的基础上,加入误差补偿模型,通过引入模型训练过程中的训练误差序列以及影响负荷波动的外界因素,使最终的负荷预测模型得到的预测结果在各采样时间点的单点误差变小,预测更加精确,其误差指标RMSE和MAPE相比于未引入误差纠正的模型分别降低了14.71 kW、0.94%。此外,实验还证明了本文所引入的误差纠正因素均对模型的预测性能有明显的改善。综上所述,误差补偿模型可以降低模型自身训练过程中产生的误差对预测结果的影响,并且可以深入挖掘外界影响因素中的隐含信息,从而有效地提高综合模型的预测精度。
4 结论
为进一步提高短期负荷预测的精度并降低模型自身的固有误差和外界因素对预测结果的影响,构建了计及误差纠正的两阶段短期电力负荷预测模型,通过对实际电力数据的仿真试验得到以下结论。
(1)基于萤火虫扰动策略改进后的FASSA算法拥有更优的适应度值,其求解迭代速度和求解精度均优于PSO、GWO和SSA算法,在对BiLSTM网络超参数寻优过程中有更好的性能。
(2)综合考虑了预测模型固有的误差序列以及外界因素对负荷预测的影响,在引入误差纠正模型后,模型的精度得到了提升。与其他5种负荷预测模型相比,本文提出的负荷预测模型具备更高的预测精度,MAPE达到1.26%。
(3)VMD分解过程中仍存在噪声影响,未来可研究信号去噪,优化信噪比的相关策略,以期获得更高质量的分解数据,得到更好的预测结果。
猜你喜欢
计算机仿真(2022年8期)2022-09-28
小天使·一年级语数英综合(2018年7期)2018-09-12
电子制作(2018年11期)2018-08-04
小天使·一年级语数英综合(2017年6期)2017-06-07
测绘科学与工程(2016年5期)2016-04-17
中国塑料(2016年11期)2016-04-16
为了孩子(孕0~3岁)(2016年1期)2016-01-16
小天使·一年级语数英综合(2015年8期)2015-07-06
电子设计工程(2015年3期)2015-02-27
河南科技(2014年14期)2014-02-27
