
水文模型知识图谱构建与应用
2024-02-27 08:07:42周逸凡赵红莉赵慧子
水利学报 2024年1期
周逸凡,段 浩,赵红莉,赵慧子,李 豪,韩 昆
(1.中国水利水电科学研究院,北京 100038;2.水利部数字孪生流域重点实验室,北京 100038)
1 研究背景
数据急剧增长后,如何高效获取、管理和利用知识逐渐成为热点问题。知识图谱以图结构存储知识,将对象或概念通过关系相互连接,从关联的角度分析问题,提供了一种更好的组织、管理和理解海量信息的能力[1],响应了信息化快速发展背景下人们对知识储存与知识表现形式的更高需求。知识图谱具有很强的知识组织关联、更新维护、可视化表达等能力。专业领域的知识图谱可以辅助相关领域的复杂问题分析或提供决策支持等服务,其在医药[2]、电力[3]、军事[4]、智能制造[5]及水利[6-8]等领域都有成功应用的案例。知识图谱技术在水利领域的应用,可以有效地组织和关联水利知识,进一步增强对水利知识查询、检索的服务能力。
知识图谱在水利领域的研究可以分为两个阶段,早期是文献知识图谱,这类图谱基于文献计量学表达科学知识的发展进程与结构关系,实现知识脉络的梳理与研究热点的分析,如水文化变迁研究[9]、水生态文明热点分析[10]、水资源管理研究趋势分析[11]等。这类知识图谱仅表达文献主题词热点、作者等信息时空分布与发展,难以实现更深层次水利领域知识的可视化表达与应用。随着知识图谱技术的发展,研究者开始探索基于已有关系型数据库抽取整合水利对象数据,构建水利对象关联关系知识图谱,实现水利对象的可视化表达与关联分析等应用。如曾晓玲等[12]以黄河水利委员会资源整合成果中的黄河水利大数据数据库为例构建黄河流域知识图谱为各项业务提供决策支持;冯钧等[13]以现有关系型数据库中的水利对象数据为例,实现水利信息知识图谱的构建与检索应用;张焱等[14]基于整合的水利对象数据构建开发了智慧水利一张图系统,完成了水利多要素信息的多视角查询,与水利业务互联互通;段浩等[6]将各类水利业务与学科知识数据,进行多源异构实体融合,形成水利综合知识的建模和表达,构建了水利综合知识图谱,基于该图谱实现水利知识的跨域查询与检索。这些水利知识图谱实现了对大规模复杂水利数据的整合与管理,但缺少对水利细分学科领域的知识组织与应用研究,缺乏足够多的应用场景和实用案例,知识图谱对水利领域智能化知识服务的支撑能力尚未得到充分挖掘,同时,在水利领域的命名实体识别中,如何处理稀疏样本和识别长尾实体等问题还需要深入研究[15]。
针对以上问题,本研究以水文模型方案推荐为知识应用场景,提出水文模型相关知识的组织模型,建立以文献文本为数据源、以Bidirectional Encoder Represenstations from Transformers(BERT)模型为核心的多策略知识抽取和融合方法,构建水文模型知识图谱实例,为模型方案推荐等知识服务提供支撑,为水利知识图谱构建提供方法和应用场景参考。
2 水文模型知识图谱构建框架与流程
水文模型是对自然界复杂水文现象与过程的一种综合近似描述[16],在水文测报、水资源调度、防汛抗旱等业务应用中发挥重要作用。在应用水文模型时,需要先了解水文模型的适用条件、参数取值的经验与已有应用案例精度等知识。这些知识大量蕴含于非结构化文本(期刊文献、研究报告等)中,一般采用人工查阅结合经验分析的方式得到,对于知识的获取速度慢,且无法形成对这类零散知识的高效管理。水文模型知识图谱的构建可以从海量文本中快速准确地提取出水文模型知识,并对其进行高效合理的管理、共享与应用[17]。
本文面向水文模型推荐等应用场景,构建水文模型知识图谱并实现图谱的应用。知识图谱的构建方式大体可以分为自顶向下与自底向上两种[18]。自顶向下的构建方式指预先确定知识的组织架构,再根据知识模型抽取数据填充知识库,较依赖于人工参与。相反,自底向上的构建方式指先进行数据的抽取,再对抽取的数据进行归纳,向上合并形成本体与关系模式,但缺少在专家经验的指导下定义的明确框架与标准,抽取的结果与领域学科知识体系匹配度难以保证,不适用于垂直领域图谱构建[19]。
水文模型知识图谱属于水利垂直领域知识图谱,专业性强,有更严格的层次结构与表达形式,因此本文采用自顶向下的方式构建知识图谱。水文模型知识图谱构建框架与流程如图1所示,主要包括需求分析与本体建模、数据获取与处理、知识抽取与融合、知识存储4个部分。
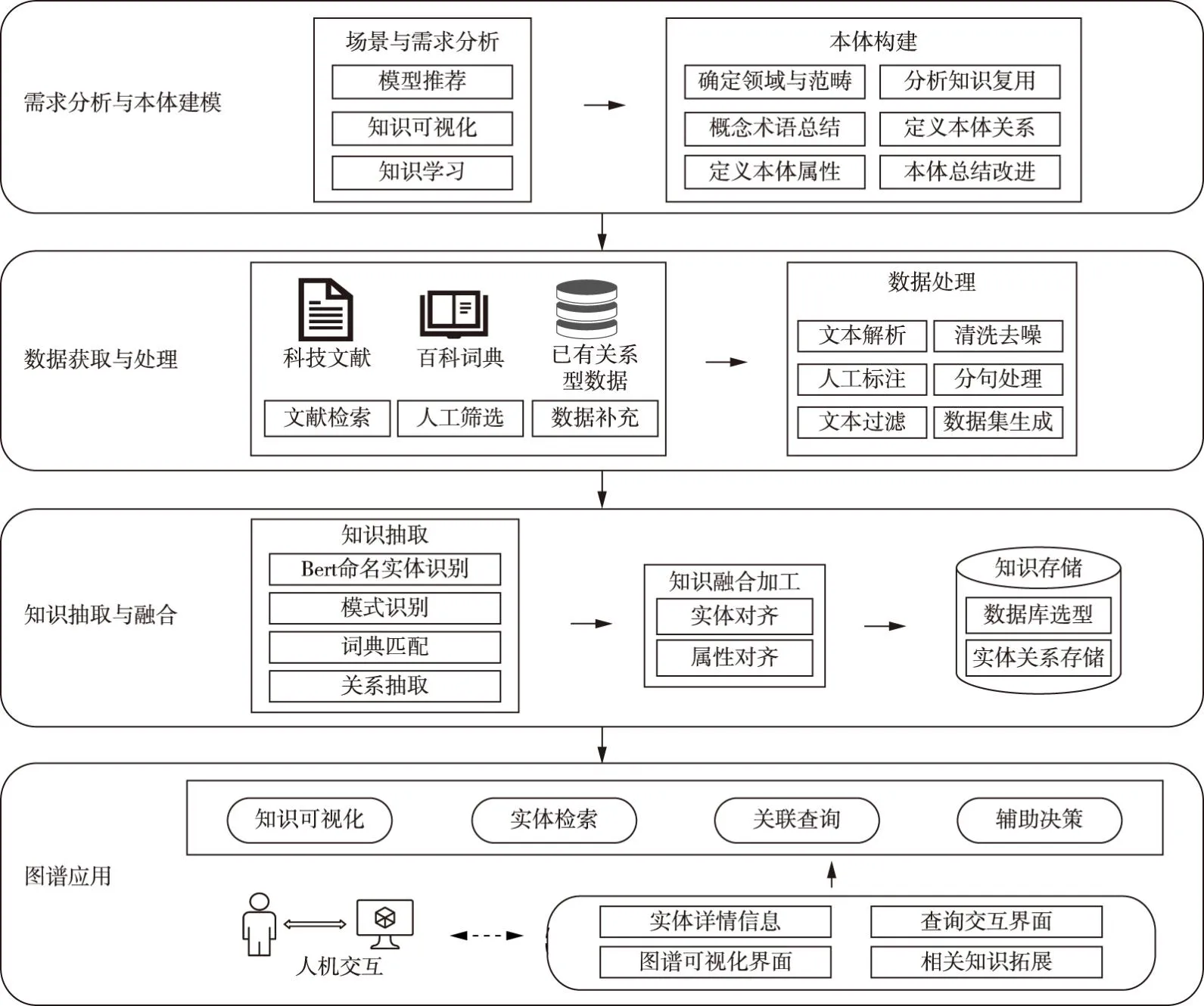
图1 水文模型知识图谱构建框架与流程
(1)需求分析与本体建模。根据水文模型方案检索与推荐场景的知识需求,确定需采集的知识边界及其中的概念与关系,构建知识模型,确定水文模型本体及关系结构。
(2)数据获取与处理。采集水文模型相关的非结构化文本,作为知识抽取与融合的基础语料;对文本进行清洗去噪、文本分句、人工标注等一系列处理,得到用于知识抽取的数据集。
(3)知识抽取与融合。构建知识抽取策略,综合深度学习模型与模式识别等多种方法,进行水文模型命名实体识别与实体关系抽取,进行知识融合与加工,得到水文模型实体关系。
(4)知识应用。确定数据库类型与结构,将抽取融合后的实体关系数据转换为相应的数据结构导入数据库中,实现知识存储与更新;数据库可与服务平台连接,支撑知识查询检索、分析推荐等应用。
3 图谱构建关键技术与方法
3.1 本体建模本体是描述特定领域中概念及其相互之间关系的概念模型[20]。通过本体层实现对领域知识体系的描述并规范数据之间的关系,便于计算机与人类理解。本文采用六步 “循环法”[21]构建水文模型知识图谱本体的主要过程如下:
(1)需求分析。根据场景知识需求,确定知识图谱的知识边界,为水资源调度、防洪抗旱等业务推荐水文模型方案,所涉及的知识包括已有水文模型的适用条件、已有应用及精度等内容。
(2)考查可复用本体。查阅已构建的领域知识图谱或者公开的本体存储库如DBpedia,以及开源社区或项目上存在的领域本体,尚未发现水文模型领域可复用本体。
(3)总结重要概念与术语。依据步骤(1)确定的知识边界,分析涉及的概念及对应的专业术语,水文模型知识体系涵盖了水利事实类术语与水利学科类术语,包括流域、水文站、自然人、科研机构等事实类概念,以及水文模型、水文要素、评价指标等学科类概念。
(4)形成本体模型。梳理概念内容,分析概念间可能存在的关系,确定本体及本体关系。水文模型知识图谱共包含“水文模型”“流域”“水文站点”“计算时段”“水文要素”“文献”“自然人”和“机构”八类概念,其中水文模型包括模型与父模型;共有“任职于”“研究者”“知识来源”“继承于”“模拟区域”“模拟时期”“计算内容”“出口站点”和“实测站”九类关系。
(5)定义本体属性。确定本体属性,属性的取值类型等,水文要素具有评价指标属性,用于评价模型模拟的精度,属性类型为数值型(Number)。
(6)构建知识图谱本体层。根据专家建议与相关研究者的意见反馈对知识模型进行改进,构建面向特定应用场景的具有适用性的水文模型知识模型,完成水文模型知识图谱本体层的构建,本体关系结构如图2所示。
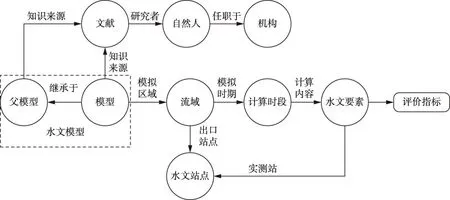
图2 水文模型知识图谱本体设计
3.2 实体抽取实体抽取又称命名实体识别,目的是从非结构文本中识别本体模型各类概念的实体。本文采用以BERT预训练模型为主的多策略实体识别方法,实现面向期刊论文的实体自动抽取。
BERT作为最具代表性的预训练语言表征模型,在生物医学[22]、军事[23]、电子病历[24]与食品[25]等诸多领域的命名实体识别中都有优秀表现。BERT模型包括输入层、嵌入层、双向Transformer、Softmax层、输出层几部分,如图3所示。输入层接收原始的文本输入;嵌入层将输入文本转换为词向量、位置向量和句向量的组合表示;双向Transformer捕捉输入文本的上下文信息和语义关联;Softmax层对双向Transformer的输出进行分类,将每个位置的表示映射到不同的标签并转换为概率分布;输出层接收Softmax层的结果,将每个位置概率最高的标签作为模型的输出。
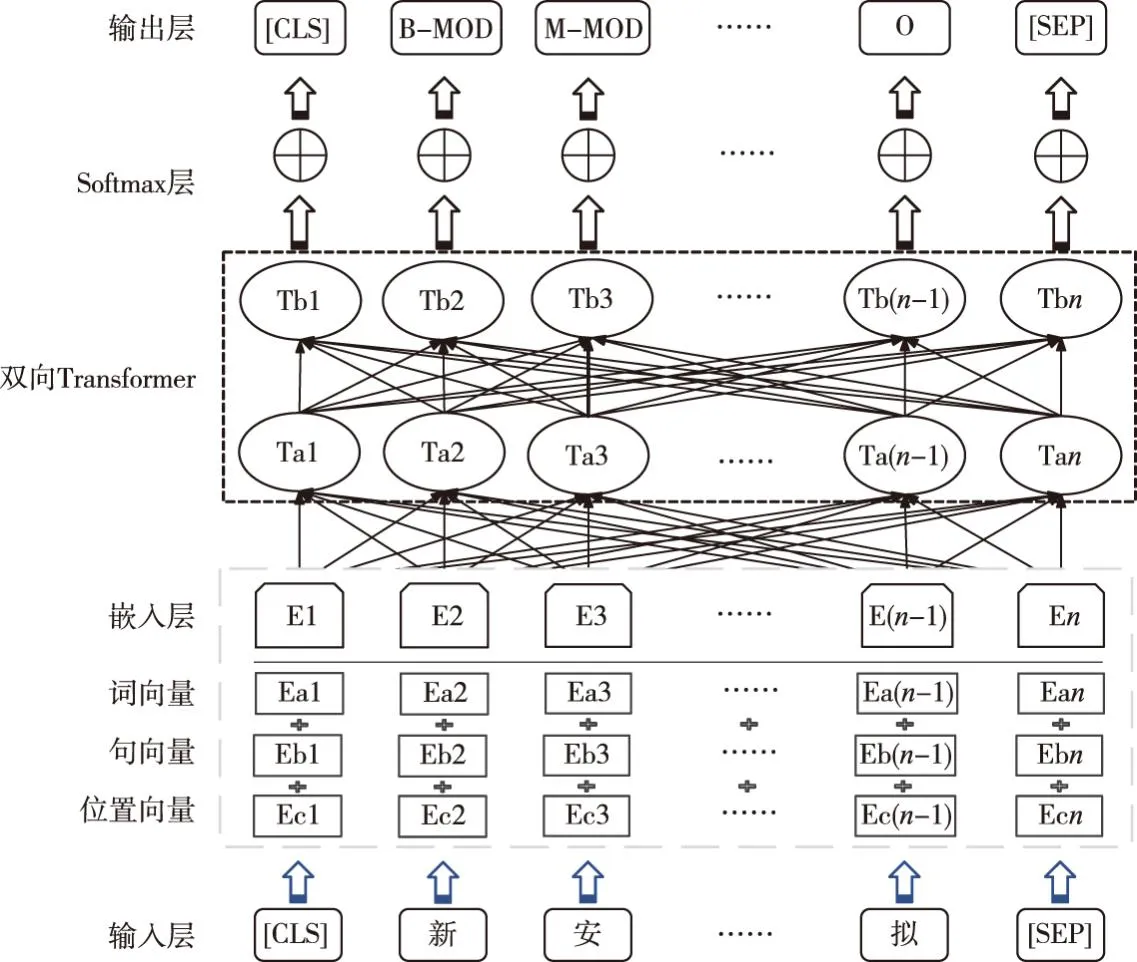
图3 BERT命名实体识别模型结构
为了更准确地抽取目标实体,本研究在BERT模型预测的基础上,针对不同实体的特点采用不同的抽取策略,包括模式匹配、LAC工具预测等方法,并为每种策略划定权重分数。在各策略分别抽取出实体后进行分数排序与模式过滤,最终得到目标抽取结果。实体抽取策略及权重分数划定见表1。
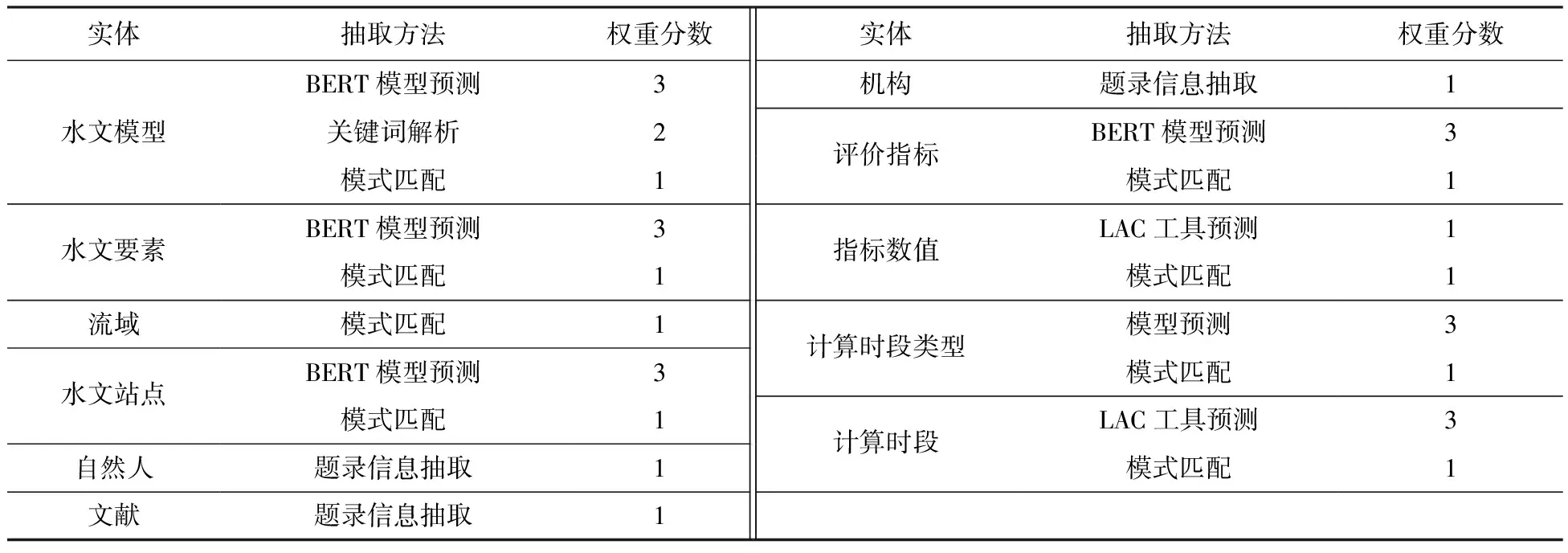
表1 实体抽取策略及权重
参考层次分析法中的标度思想[26],以分数的形式体现不同策略在不同实体抽取过程中的相对重要程度。以“水文模型”实体为例,由于存在中英文结合的情况,在形式和语义上存在一定的复杂性,采用单一BERT模型识别效果不佳,因此采用模式匹配等方法进行补充,提高抽取精度。模式匹配基于预定义的规则模板寻找特定的模式结构,有一定准确性,但泛化能力弱,取其标度为1;文章关键词是作者选定的用于描述研究主题和内容的核心概念和术语,具有一定的先验性,相较于模式匹配重要程度较高,取标度为2;BERT模型预测是根据对文章的语义理解与上下文关联所抽取得到的结果,具有综合较高的准确性和泛化能力,取标度为3。以标度为三种方法的权重分数,基于这三种方法抽取论文中可能是主题模型的词并对各方法抽取出的实体赋分,对抽取词分数加和后排序,再使用模式匹配的方式过滤一遍抽取词,最后得到模型实体,如图4所示。
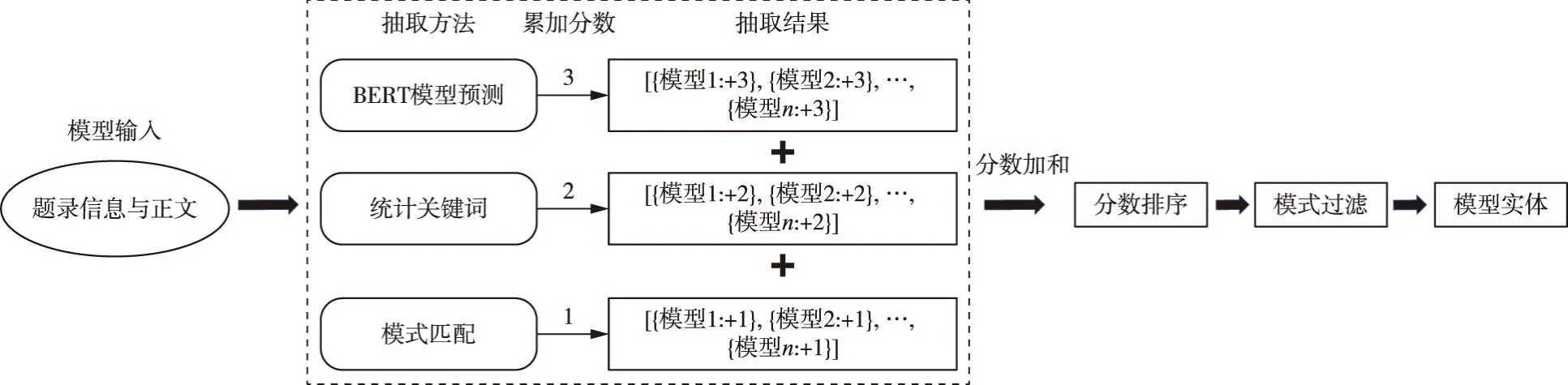
图4 模型实体抽取方案
3.3 关系抽取目前关系抽取的常用方法为基于模板的关系抽取、基于监督学习的关系抽取与基于弱监督学习的关系抽取[27]。本文采用了一种直接匹配和模式匹配结合的方法来提取实体关系。
对于单篇文章来说,抽取出的每一组实体间存在预定义好的关系,实体抽取后自动匹配预定义关系即可。例如,从一篇文章中抽取的“自然人”与“机构”实体之间存在明确的“任职于”关系,“水文模型”与“流域”之间存在“模拟区域”关系等。但对于模型之间存在的继承关系,例如,一个模型是基于另一个模型发展或改进出来的,这类关系的表述常常涉及复杂的语义理解,或隐含在某种语境或者表达方式之中,无法通过直接匹配获得。本文采用模式匹配的方式,用Python中的函数refindall正则表达式构造关系模式进行抽取。构造的继承关系规则示例见表2。
3.4 知识融合从非结构化文本中抽取的实体可能存在多词共指等问题,需要进行实体的融合加工,提高知识库的整体质量。水文模型知识图谱融合加工的主要任务包括水文模型与评价指标的实体融合。
实体融合是判断数据集中的2个或多个实体是否指向同一对象的过程[28]。本文采用词汇表映射法,构建水文模型词汇表,将同一模型的不同表述映射到标准名称上,根据映射表将同义模型实体合并。本研究共整理了98种模型的名称词表,部分水文模型词汇见表3。
评价指标反映了水文模型模拟或预报的精度,不同的评价指标从不同方面体现了模型与参数在研究区域的适用情况。根据不同的研究目的与问题,应用案例中水文模拟使用的评价指标也并不统一,同时评价指标同义不同名的情况也多有存在,不利于知识表达与实际应用。需要将同义评价指标对齐,并划分评价指标级别,实现指标名称的标准化。与水文模型类似,同样采用词汇映射表的方法,将文献中出现的同义评价指标整理对齐后更新。以相对误差为例,表4为评价指标对齐分级示例。

表4 评价指标对齐分级示例
3.5 知识存储Neo4j是目前主流的属性图数据库之一,采用的是基于节点和关系的数据模型,每个节点代表一个实体或概念,每条边代表两个实体之间的关系,通过节点和边之间的连接构成一个图形化存储结构,这种结构极大地方便了复杂关系的表示和查询,且有良好的伸缩性与灵活性,具有较高的用户认可度。根据水文模型知识图谱对关系查询、快速响应与持续扩展的要求,本研究选择Neo4j图数据库进行知识存储与更新管理。
知识抽取与融合的结果以篇论文为单位存储在表格中,每一行为一篇文章的抽取结果,表头代表了抽取的实体类型,如“论文名字”“作者”“水文模型”等。每个单元格内的数据以字符串列表的形式存储,可包含多个条目,其中“计算时段”和“指标数值实体”嵌套了字典来描述键值对信息。
本研究使用py2neo库对Neo4j数据库进行操作,包括节点关系的创建、数据查询、数据更新等。py2neo是Python编程语言的Neo4j图数据库驱动程序,它提供了一个Pythonic的API,用于连接Neo4j数据库,与数据库进行交互。
(1)节点关系创建。使用py2neo库的Graph类创建一个数据库连接;遍历处理后的每一行表格数据创建节点关系,使用Node类创建一个新的节点,并使用graph.create()将其添加到数据库中;使用Relationship(a_node,relation,b_node,kwargs)来创建a_node与b_node之间的关系。
(2)数据库更新。构建实体关系补充与数据库更新工具。在采集新数据之后,通过py2neo连接数据库,查询图数据库以判断新实体和关系是否已存在,将新的实体和关系进行入库保存,并通过update()方法对已存数据进行更新,完成自动抽取、融合、入库的知识更新流程。
4 图谱构建实例与应用
4.1 数据处理本文训练数据来源于CNKI中国期刊全文数据库,设置检索主题为“水文模型”,年份范围为2005—2022年,筛选后得到1209篇水文模型领域期刊论文。
通过PDF解释器将期刊解析成文本数据,利用jieba工具对分词去停用词,并结合模式匹配的方式对解析后的文本过滤清洗。通过分句算法,使文本转换为规则句子,为保证实体识别的准确性,截断超长句子,并通过实体匹配的方式使包含实体的句子和非包含实体的句子满足均匀分布,得到处理后的规则句子集。用BMOES标注法对句子进行人工标注。将标注好的句子集转换成输入模型的序列标注的形式,即一列文本内容与一列标签相对应。最后将带标签的句子按照8∶2的比例生成训练集、测试集作为模型输入数据。数据处理流程如图5所示。
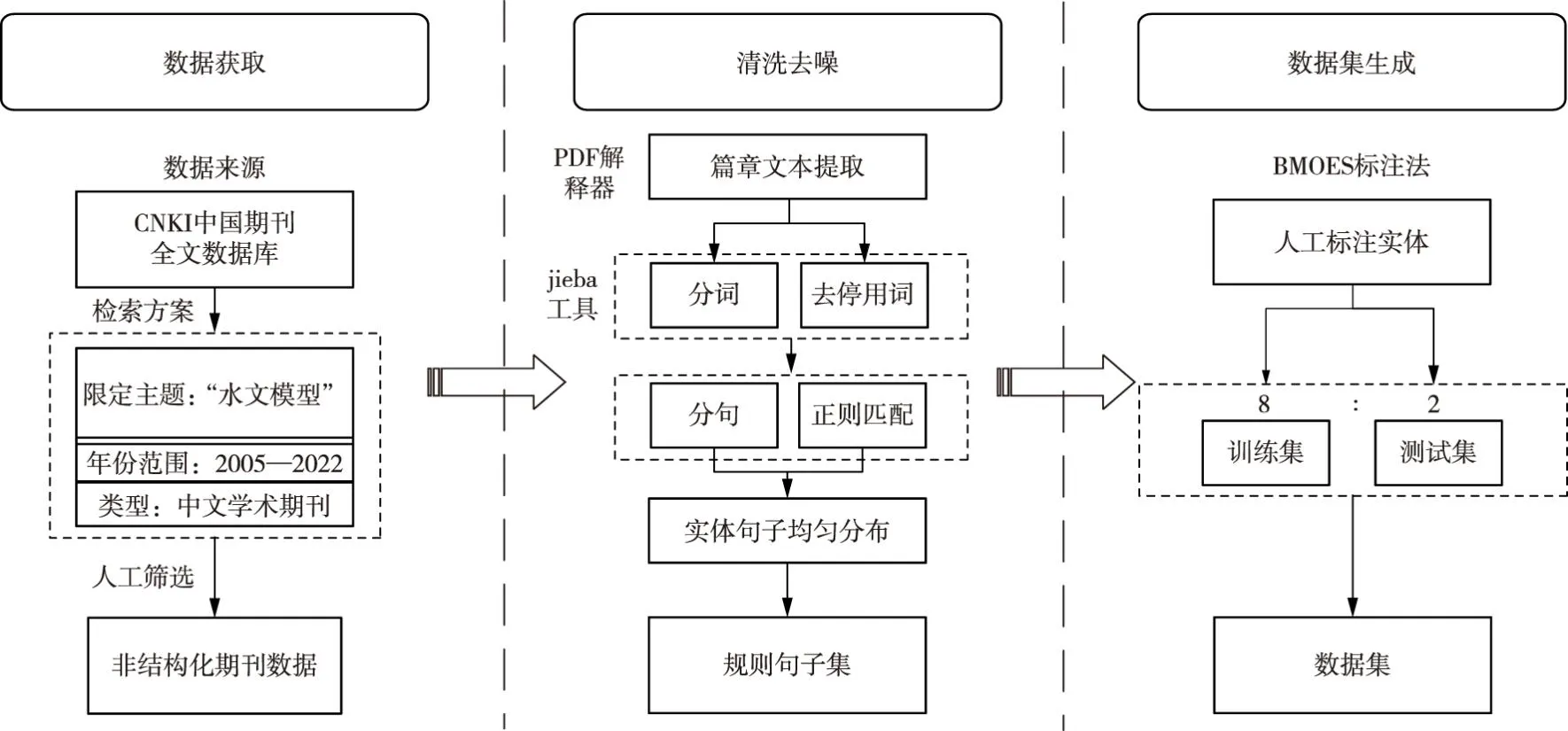
图5 数据处理流程
赵慧子等[29]曾以883篇水文模型领域中文期刊论文为数据源,进行了水文模型领域命名实体识别研究,构建的数据集共包含各实体45 621个,句子26 078个,其中不包含实体的句子6000余个。本文在此基础上扩大文论数量至1209篇,对BERT模型进行了增量训练。扩大后的数据集包含各类实体51 152个,句子总量达到32 088个,其中不包含实体的句子7200个。
4.2 知识抽取利用处理好的数据训练BERT模型,使用精确率P(Precision)、召回率R(Recall)、F1值(H-mean值)三个值作为评价指标对模型精度进行评估,计算公式分别为:
(1)
(2)
(3)
增量训练中对BERT模型进行超参数调整:最大序列长度等于128,epoch为10,batchsize为32,存储步数为425,dropout为0.1。实体抽取的精度结果如表5所示。
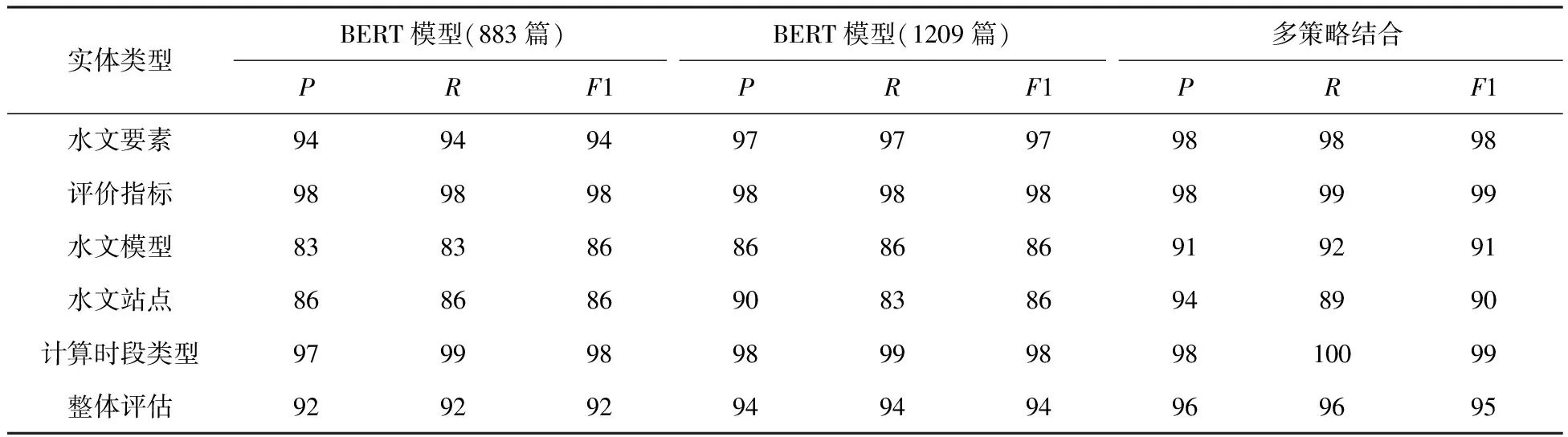
表5 实体抽取精度 单位:%
从表5可以看出:
(1)对于大部分的实体类型,增量训练都带来了性能提升,尽管这种提升在不同的实体类型之间有所不同,但这说明了增量训练有助于提升模型在识别各种类型实体时的性能。
(2)“水文要素”“评价指标”“计算时段类型”这三类实体的性能提升相对较小。这可能是由于这些类别在初始训练集中已经有较多的样本进行学习,且其语义特征较为明显,增量训练带来的影响不大,或者说模型已经趋于这些类别的性能上限;而对于“水文站点”和“水文模型”这两类实体,增量训练带来了较大的性能提升。究其原因,或许原训练集中这两类实体的样本数量相对较少,加之其特征复杂,导致BERT模型在识别这两类实体时的性能未能得到充分的发挥。在新增的326篇文档中,这两类实体的出现频率得到了提升,使模型有更多的机会去学习和理解这些实体,进而提高了对这两类实体的识别性能。在细化的角度上,原训练集的数据可能未能涵盖这两类实体的全部特性,而新增的训练数据则为模型展示了更全面的实体特征和语境信息,更丰富的数据表现形式有利于模型更好地掌握并识别这两类实体。
(3)与多策略结合的方法相比,尽管BERT模型在增量训练后的性能有所提升,但在所有的实体类型中,多策略结合的方法仍然表现更好。这是因为多策略结合方法融合了不同方法的优点,对复杂的语言环境和各种类型的实体有更强的处理能力。针对具体的应用场景和需求,可以选择性地结合多种策略,以进一步提升实体抽取的精度和鲁棒性,多策略的方法扩宽了实体抽取模型的应用潜力和前景[29]。
4.3 图谱可视化本文使用ECharts可视化neo4j数据。ECharts是一款基于Javascript的数据可视化图表库,提供直观、生动、可交互、可个性化定制的数据可视化图表。图6示例了以辽河流域为中心的图谱可视化效果,可了解到相关的水文模型、研究者及所在机构等对象,所属流域、模拟区域、继承于等关系。如想进一步了解相关模型区域的模拟情况,可以继续通过双击目标实体扩展查询,并链接到水网图谱或学科知识图谱,展示其相关实体关系。
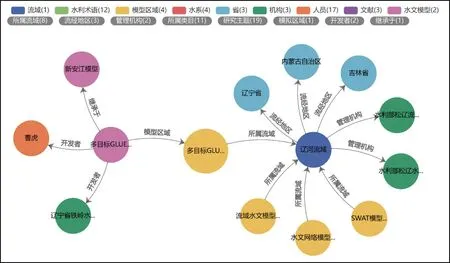
图6 图谱可视化示例
4.4 知识检索将本研究构建的水文模型知识图谱集成至“水利专业知识服务系统”在线平台,在系统检索栏中可进行水文模型相关知识的检索。
(1)对模型实体的检索查询。针对模型实体进行检索查询。例如以“VIC模型”为检索词,查询结果如图7所示。表6为部分检索结果示例。查询结果表明VIC模型在黑河、黄河、滦河、珠江、漳河以及柳江等流域均有应用。在黄河流域的兰州站断面模拟情况较为突出,效率系数在0.86以上,相对误差为0.05。知识检索内容与知网检索文献中的实体关系相对应,能够帮助用户更快速的了解目标区域的模拟效果,学习水文模型知识,实现文献关键知识的高效查询,从而为水文研究和实践工作提供更多支持。
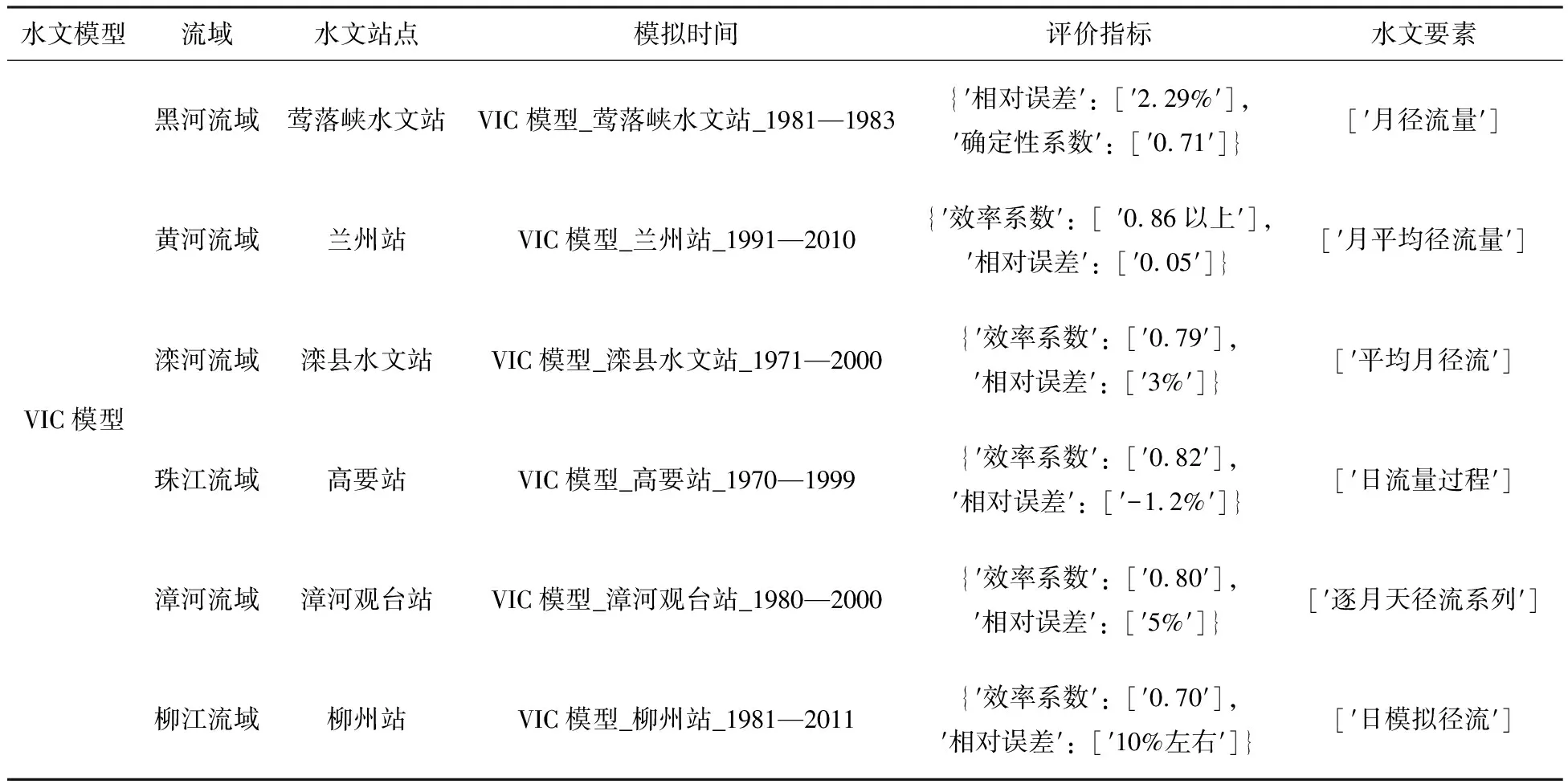
表6 模型实体部分查询结果示例
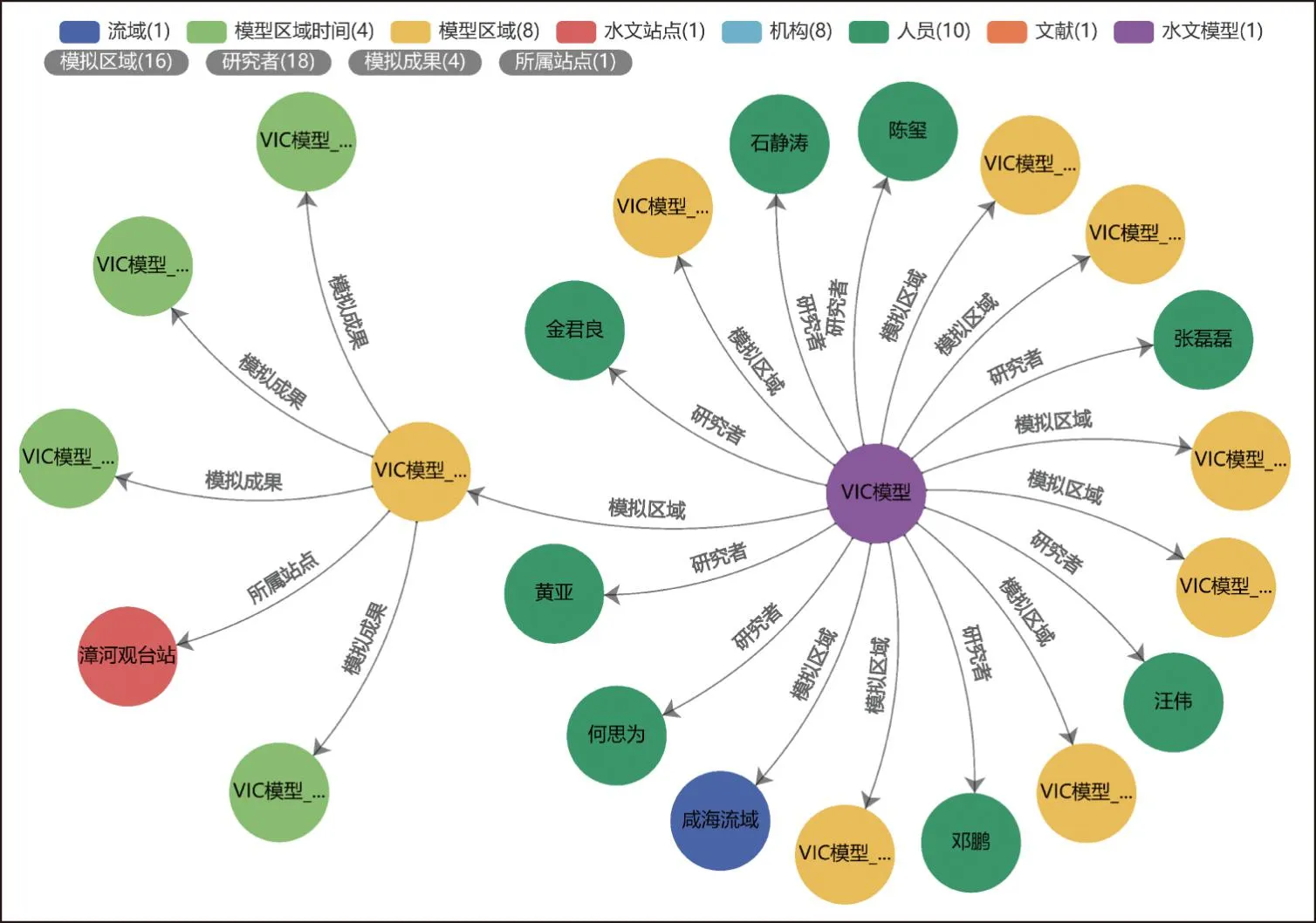
图7 模型实体查询示例
(2)对指定断面的模型查询。例如以“莺落峡水文站”为检索词,查询结果如图8所示,表7为部分检索结果示例。查询结果表明有学者采用过VIC模型、CREST V2.1分布式水文模型、SWAT模型、SRM融雪径流模型以及WASMOD模型等模拟或预报过莺落峡水文站水文要素,其中SRM融雪径流模型应用效果较好,其效率系数达到0.84。这类检索查询可以帮助用户了解对于指定断面,哪些模型有更好的表现,根据历史模拟情况为用户推荐最适合的模型。
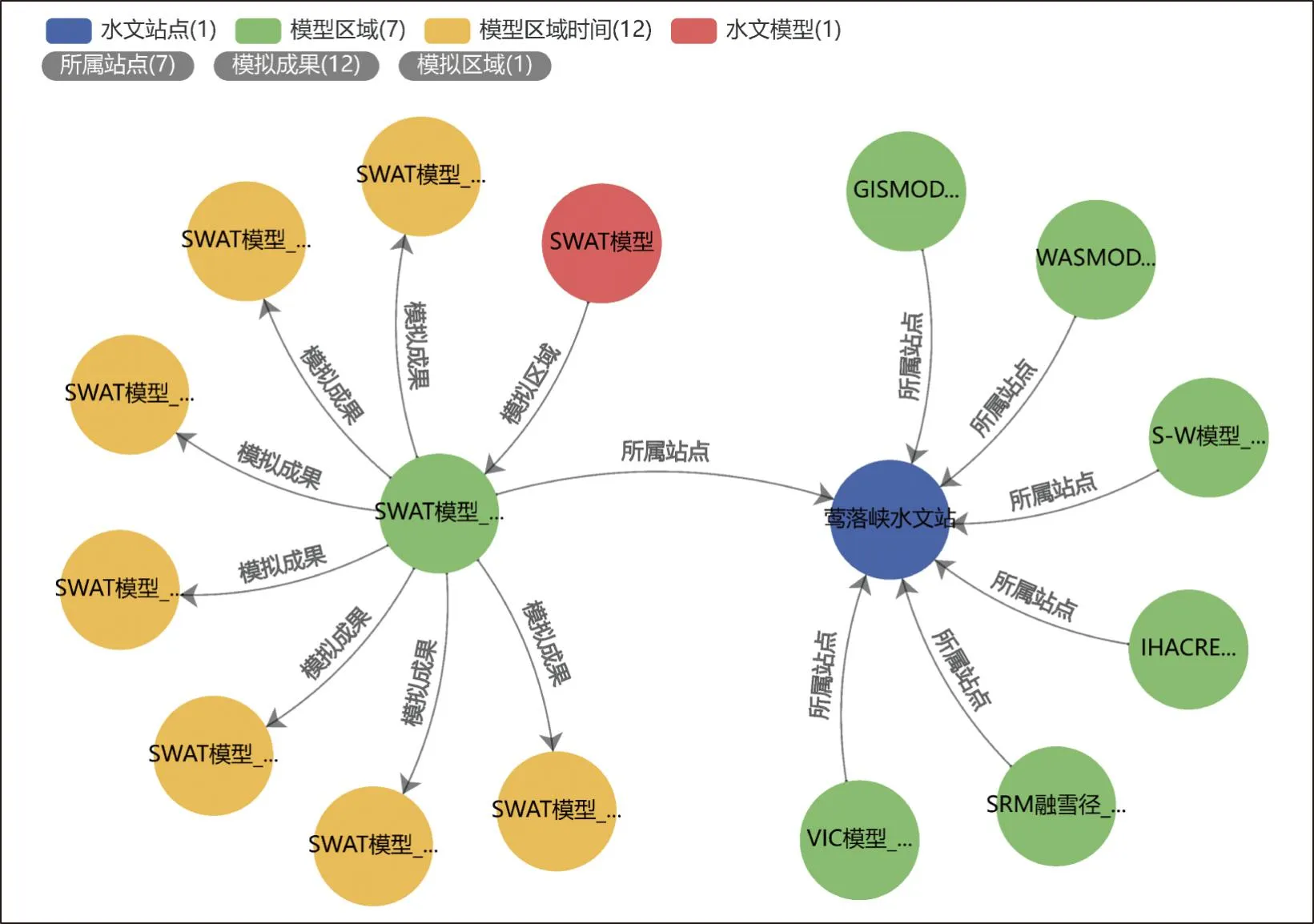
图8 站点实体查询示例
由上述实例可见,利用构建知识图谱的相关关键技术,可实现基于期刊文献论文的水文模型知识的快速学习;可视化的水文模型知识图谱能更直观地展示水文模型知识中的实体关系;基于水文模型知识图谱的查询检索,可以快速便捷地得到指定模型的适用区域、指定流域或断面的适用模型等信息。
5 结论
本文针对水资源调度、防洪抗旱等业务中水文模型推荐等知识应用场景,详细探讨了水文模型知识图谱的构建过程,提出了水文模型知识组织方法,研究了水文模型知识抽取与知识融合对齐等关键技术以及如何将所得知识应用于实际场景,本文研究成果及结论如下:
(1)本文采用六步法的本体建模方法,构建了水文模型知识的本体模型。该模型可支持水文模型继承关系、模拟水文要素、应用流域与效果、研究者及机构等知识的组织和表达。
(2)构建了水利垂直领域以BERT模型为核心的多策略知识学习方法,采用垂直领域数据对通用BERT模型进行了调优和增量训练,使其更适应水利专业文档的特性,同时联合模式匹配、工具识别等方法多策略优势互补。实验结果表明,本文对BERT模型的增量训练使知识抽取的精度提高了2%。在此基础上,多策略方法的使用可使整体精度再提高2%左右。
(3)构建了水文模型知识图谱实例并进行了知识服务应用,验证了水文模型知识图谱构建方法的有效性,并对图谱进行了可视化表达。基于“水问”平台提供知识检索功能,实现指定模型的适用流域检索和指定流域断面的适用模型检索等水文模型知识应用服务,可应用于水文预报业务中多种模型的快速比选,从而针对特定的水文预报业务和流域下垫面条件选择最合适的模型。
本研究为水利细分领域知识图谱的构建与应用提供了新思路,在本研究成果基础上,还可进一步采集更多水利文献,扩大数据集规模,增加实体数量并丰富实体与关系类型;尝试提高模型推荐的智能化水平,如研究基于相似度计算的智能推荐算法,帮助模型与参数的移用,或采用基于内容或协同过滤的推荐方法,并利用机器学习预测模型使用模式,进一步提高推荐的准确性和效率。
猜你喜欢
哲学分析(2023年4期)2023-12-21 05:30:27
水资源开发与管理(2023年8期)2023-09-08 13:27:10
少先队活动(2020年12期)2021-01-14 01:47:40
中国音乐学(2020年4期)2020-12-25 02:58:06
河南水利年鉴(2020年0期)2020-06-09 05:43:48
河南水利年鉴(2020年0期)2020-06-09 05:43:30
河南水利年鉴(2017年0期)2017-05-19 02:29:33
中成药(2017年3期)2017-05-17 06:09:01
领导科学论坛(2016年9期)2016-06-05 14:59:58
文学教育(2016年27期)2016-02-28 02:35:15
