
针对恶意软件检测的特征选择与SVM协同优化
2024-02-22 08:00张新英吴媛媛
计算机工程与设计 2024年2期
张新英,李 彬,吴媛媛
(1.郑州经贸学院 智慧制造学院,河南 郑州 451191;2.中原工学院 机电学院,河南 郑州 451191)
0 引 言
移动互联网的迅速发展使得移动端软件数量高速增长。移动端操作系统也因良好的用户体验占据了基本所有移动端OS市场[1]。但由于像鸿蒙、安卓等系统具有开放性,使得恶意软件与日俱增,给移动网络用户带来了严重的网络安全问题。通过移动网络流量分析建立精准恶意软件检测模型对于建立安全网络使用环境将具有重要作用。恶意软件检测主要包括静态检测和动态检测方法。前者[2-4]以反编译方式获取静态特征,进而构建分类模型。然而,静态方法的软件特征选取的相关性不足,分类精度低。后者[5-7]利用特征分析获取软件序列特征及相关环境变量,并以此对恶意软件分类。然而,该方法在最优特征选择和恶意功能准确识别上存在困难。
近年来,群体智能优化算法因为具有良好的随机搜索性能,通过综合考虑多特征组合对分类模型性能的影响,已广泛地应用于特征选择的求解。如文献[8]通过融合粒子群算法和外观比间隔算法在安卓环境设计了针对恶意软件的特征选择策略,有效减少了冗余特征。文献[9]结合EGA算法进行特征选择,学习模型的精度得到了提高,最优特征子集也实现了降维。将智能优化算法、特征选择及分类模型综合考虑,可以进一步提高分类精度。如文献[10]结合STOA和GA算法选择最优特征子集,提升了模型分类精度。文献[11]利用GOA算法优化封闭式特征选择,并同步搜索分类模型的关键参数,特征子集相关性更高,但由于GOA本身全局搜索能力差,分类精度还待提升。
哈里斯鹰优化算法HHO[12]是一种新的智能优化算法,其原理简单、参数少、全局搜索能力强,已在图像识别[13]、机器学习[14]、电力控制[15]、TDOA定位[16]等方面得到了有效验证。但HHO依然存在全局寻优精度差、收敛速度慢的不足。本文提出一种基于改进HHO优化特征选择与SVM的恶意软件检测模型,通过多种策略对HHO进行综合寻优性能改进,利用改进算法优化SVM学习模型,对特征子集和SVM参数调整同步优化。结合网络流量数据特征构建包含正常和恶意特征的软件数据集,构建分类模型。并通过实验测试验证改进模型达到了预期效果,能够提升恶意软件检测模型的分类能力。
1 HHO算法
哈里斯鹰优化算法HHO是一种启发于美国亚利桑那州南部猛禽协作捕食行为的元启发式算法,该物种可以通过追踪、围捕、攻击对猎物进行高效协作捕食。HHO算法由全局搜索和局部开发两个阶段组成,并通过猎物逃逸的能量因子E采取不同的搜索行为,该因子定义为
E=2E0(1-t/Tmax)
(1)
其中,E0=2rand(0,1)-1表示能量初始状态,该状态在(-1,1)间随机变化,t、Tmax分指当前迭代和最大迭代。
|E|≥1时,算法进入全局搜索阶段,哈里斯鹰会根据猎物的位置和其它个体的位置随机选择栖息点,并通过两种等概率策略搜索目标猎物,数学模型如下
X(t+1)=

(2)
(3)
其中,N为种群规模,X(t+1)、X(t) 分别为个体的新位置和原位置,Xrand(t)、Xrabbit(t) 分指随机个体和搜索目标个体,q、r1~r4为[0,1]随机值,[lb,ub]为搜索边界,Xm(t) 为种群位置均值。
|E|<1时,算法进入局部开发阶段,猎物会试图逃逸,哈里斯鹰会以突袭的方式攻击猎物。HHO算法采用4种策略模拟这种捕食行为,4种策略分别为软包围、硬包围、渐近快速俯冲式软包围和渐近快速俯冲式硬包围。HHO算法根据能量因子E和逃脱概率λ决定采用哪种策略。
(1)软包围。 |E|≥0.5且λ≥0.5, 猎物拥有能量逃脱包围,个体会以包围方式消耗猎物的能量,使猎物精疲力尽,并完成猎物捕食。数学模型如下
(4)
其中,ΔX(t) 为猎物与个体的间距,J为猎物跳跃距离,r5为(0,1)间随机量。
(2)硬包围。 |E|<0.5且λ≥0.5,表明猎物逃逸能量不足,种群将以围捕方式向猎物发出突击突袭。数学模型如下
X(t+1)=Xrabbit(t)-E|ΔX(t)|
(5)
(3)渐近快速俯冲软包围。 |E|≥0.5且λ<0.5,表明猎物有逃脱能量,此时种群会建立软包围对猎物进行围捕。数学模型如下
X(t+1)=

(6)
其中,D为维度,S为行向量,LF为Levy飞行算子。
(4)渐近快速俯冲硬包围。 |E|<0.5且λ<0.5,表明猎物拥有较少的能量,此时种群会建立硬包围对猎物围捕。数学模型如下
X(t+1)=

(7)
2 混合多策略改进哈里斯鹰优化算法MHHO
2.1 基于Bernouilli shift混沌的种群初始化方法
智能算法的搜索过程起始于初始种群的分布,若初始种群的分布较好,在搜索区域内的均匀性、多样性得到了保证,无疑可以加快算法搜索到最优解。标准HHO算法在初始种群生成方面采用了随机生成机制,这样可以保证智能算法搜索的随机性,但无法保证较高的初始种群质量,进而降低算法搜索效率。在优化领域内,混沌映射是一种比随机数生成器更有效的方法,它不仅具备随机性,而且规律性及对空间搜索的遍历性要强于随机数。目前常用的混沌映射方式有多种,研究表明,Bernouilli shift混沌映射、Tent混沌映射相比较于Sine、Logistic以及ICMIC等混沌映射具有更高的搜索效率。设置最大迭代次数Tmax=10 000,笔者对Bernouilli shift、Tent、Logisitc和Sine这4种混沌映射取值频次进行了实验,图1是取值频次的分布直方图。从结果来看,Bernouilli shift、Tent两种混沌映射的混沌取值均匀性明显优于Logisitc和Sine,后面两者在[0,1]的边界区域取值频次明显高于中间区域,说明算法在边界区域的搜索密度过高,而中间区域则搜索不足,种群个体分布的多样性不平衡。前面两者的取值频次更加均匀,保证所有搜索区域内个体的均匀分布,提高了接近最优解的概率。

图1 不同混沌映射的取值频次
基于以上分析,本文将采用Bernouilli shift混沌映射机制来生成改进HHO算法的初始种群。Bernouilli shift混沌映射公式为
(8)
其中,δ为混沌参数,当δ∈(0,0.5)∪(0.5,0.8) 时,式(8)处于混沌状态。
生成Bernouilli shift混沌值后,混沌值与种群搜索空间的映射规则为
X(t)=lb+Z(t)×(ub-lb)
(9)
其中,[lb,ub] 为个体搜索边界,Z(t) 为第t次迭代生成的Bernouilli shift混沌值。
2.2 能量因子非线性调整
根据HHO算法的搜索机制可知,参数E是实现HHO算法进行全局搜索或局部开发的控制参数,搜索能力和开发能力也是智能算法搜索最优解的主要指标。根据参数E的定义式(1),其值呈线性递减规律,表明迭代前期E值较大,偏向全局搜索,然后线性递减,逐步转向局部开发。但这种线性模式无法真实反映自然种群对搜索目标的多轮次搜捕,无法将算法效率提升到最大。针对这一问题,改进HHO算法将能量因子E设计为非线性更新模式,并引入余弦函数将其改进为周期性的更新模式,以描述种群对目标的多轮次搜捕特征,具体为
(10)
其中,参数k用于控制能量因子的递减周期数。根据式(10),种群将实现多轮次全局搜索与局部开采,并依据概率靠近并捕食目标猎物。
能量因子E同时决定了猎物逃逸的跳跃距离J,为了避免HHO算法中跳跃的随机性,将J设置为E的函数形式,以指导猎物的跳跃距离,具体为
(11)
根据式(11)可知:能量因子与跳跃距离呈现一致变化。若猎物能量充足,则逃逸距离更远;若猎物能量耗尽,则几乎只能停留在原地。
2.3 最优解变异扰动方法
在HHO算法的迭代晚期,种群个体逐步趋近于种群最优解,容易导致多样性缺失,搜索陷入局部最优。为此,改进算法将设计一种针对最优解的动态变异扰动机制,引入两种变异算子,以动态选择概率决定具体变异方式,以此实现对最优解的扰动,提高个体多样性和算法跳离局部极值的概率。
(1)随机游走变异
该机制表明个体将以随机游走的方式搜索食物源,并更新个体位置。随机游走公式为
X(t)=[0,cumsum(2r(t1)-1),…,cumsum(2r(tn)-1)]
(12)
其中,X(t) 为随机游走步数,cumsum为累加和函数,n为最大迭代次数,函数r(t) 定义为
(13)
根据随机游走原理可知,个体在所有维度上都以随机游走更新个体位置。同时,由于搜索空间存在可行域边界,为了确保种群个体在可行域内进行随机游走,算法将利用式(14)对最优解对应的位置进行归一化处理
(14)
其中,归一化处理的Xbest(t) 即为最优解进行随机游走变异的新位置,参数中,maxi、mini对应个体维度i进行随机游走的最大值与最小值,maxi(t)、 mini(t) 对应第t次迭代时个体维度i的最大值与最小值。由随机游走方式可知,迭代前期,随机游走边界更大,利于算法充分地全局搜索;迭代后期,游走边界收窄,利于算法可以做更充分的精细开发。
(2)柯西-t变异
柯西分布特征是:两端具有较长尾翼,分布密度小,分布较长;而在分布原点处概率密度大、分布紧凑。这种分布可以对个体进行强烈的扰动,增加算法脱离局部最优的概率。而t-分布在自由度较低时与柯西分布相似,自由度较高又与高斯分布相似,前者扰动能力更强,后者则局部开发能力更佳。结合柯西分布和t-分布构造柯西-t变异算子,定义为
Xbest(t+1)=Xbest(t)[λ1·cauchy(0,1)+1]+λ2·t(Tmax)
(15)
其中,Xbest(t)、Xbest(t+1) 分别对应于原始最优解和变异后的最优解,cauchy(0,1) 为柯西算子,t(Tmax) 为以Tmax为自由度的t分布算子,λ1、λ2分别表示栖西分布和t-分布的自适应权重系数,用于调整两种变异算子对最优解的扰动程度,定义为
(16)
根据式(16)可知,迭代早期,λ1取值较大,此时柯西算子对最优解的扰动程度更大,利于广泛区域内对最优解进行扰动,算法全局搜索能力更强。而随着迭代进行,晚期时λ2取值变大,此时t-分布算子占据更大比例,利于算法在局部区域内的精细开采,加快算法收敛。
为了在两种变异算子间作出动态切换,引入一种动态选择概率对变异方式进行决策,以动态概率针对最优解进行交替扰动,提高扰动随机性和跳离局部极值的概率。将动态选择概率定义为
P=-exp(1-t/Tmax)10+0.05
(17)
变异扰动的具体过程为:若随机值≤P,选择随机游走变异机制,即式(12)、式(13)、式(14)对最优解进行扰动;若随机值>P,则选择柯西-t变异机制,即式(15)对最优解进行扰动。
2.4 互利共生策略
HHO算法在搜索过程中随机因素影响较大,搜索方向具有一定盲目性,这会降低算法搜索精度和收敛速度。为此,MHHO引入互利共生改进种群搜索机制。令Xi、Xj为两个可以交互生存的共生个体,共生交互的位置更新为
(18)
RMV=(Xi+Xj)/2
(19)
其中,bf1、bf2∈{1,2} 为利益因子,Xbest为最优解,RMV为两个个体的交互关系。
将当前个体与选择的随机个体进行共生交互,以此改进MHHO的全局搜索能力,并融入惯性权重机制调整种群的共生交互程度,由此得到新的位置更新为
X(t+1)=
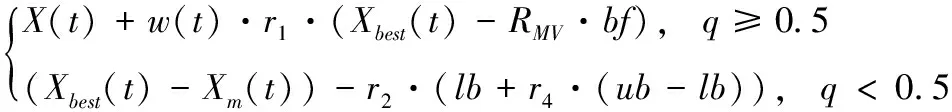
(20)
RMV=(X(t)+Xrand(t))/2
(21)
(22)
其中,Xrand(t) 为迭代t时选择的随机个体,Xm(t) 为迭代t时的种群平均位置,惯性权重w定义为
w(t)=wmin+(wmax-wmin)·exp(-(2t/Tmax)3)
(23)
其中,[wmin,wmax] 为惯性权重变化区间。
2.5 MHHO算法设计
步骤1 参数初始化,包括种群规模、迭代次数、混沌因子、能量因子递减周期数、惯性权重最值等;基于混沌Bernouilli shift映射机制初始化MHHO算法的种群结构;
步骤2 计算个体适应度,更新算法参数E、J;
步骤3 若 |E|≥1, 实施算法全局搜索,按式(2)更新位置;
步骤4 否则,实施算法局部开发;若 |E|≥0.5且λ≥0.5, 按式(4)更新位置;若 |E|<0.5且λ≥0.5, 按式(5)更新位置;若 |E|≥0.5且λ<0.5, 按式(6)更新位置;若 |E|<0.5且λ<0.5,按式(7)更新位置;
步骤5 以最优解实施混合变异,具体地:若随机值≤P,选择随机游走变异机制,即式(12)、式(13)、式(14)对最优解进行扰动;若随机值>P,则选择柯西-t变异机制,即式(15)对最优解进行扰动;
步骤6 运行互利共生策略,按式(20)对解进行重新更新;
步骤7 更新全局最优解及其适应度;
步骤8 若达到算法终止条件,则输出全局最优解;否则,跳转步骤2继续执行。
2.6 MHHO算法基准函数测试
利用6个基准函数对算法的寻优性能进行测试,函数说明见表1。MHHO算法中,设置N=20,Tmax=400,比例系数α=0.99、β=0.01,能量递减参数k=4,惯性权重最值为wmin=0.4,wmax=0.9,混沌参数δ=0.4。引入标准HHO算法[12]、樽海鞘群算法SSA[18]和改进哈里斯鹰优化算法CEHHO[19]进行实验对比分析。同类型测试可以扩展到其它基准函数和CEC2014数据集上进行。

表1 基准函数说明
表2是4种算法在目标函数平均精度和标准差两个指标上的统计结果。可以看出,MHHO算法可以在所有测试数据找到最优解,表明MHHO寻优能力更强,且在单峰、多峰目标函数上仍然拥有较为稳定的寻优能力。CEHHO算法引入精英对立学习和新型局部搜索机制,提升了HHO算法的搜索能力,但其收敛速度较慢,复杂个体选优机制也提高了算法的复杂性。但该算法相比标准HHO和SSA算法在部分函数测试上还是得到了最优解。图2是4种算法的收敛曲线。从曲线的坠落程度看,MHHO算法在不同类型的基准函数上可以以更少的迭代次数找到精度更高、更接近于最优解的候选解,其寻优速度和收敛速度都明显优于3种对比算法。HHO算法和SSA算法的收敛曲线都快速地进入到较平缓的阶段,说明算法进入了早熟收敛,寻得的是局部最优解,且无法跳离。CEHHO算法相比这两种算法能够通过寻优手段的改进拓展到新的搜索区域,从而提高了算法的寻优精度。总体来看,本文的MHHO算法通过引入混沌映射、能量因子非线性调整、变异扰动和互利共生机制对HHO算法的综合性能改进能够增强算法的全局寻优能力和求解精度,实现了对算法搜索能力的提升。
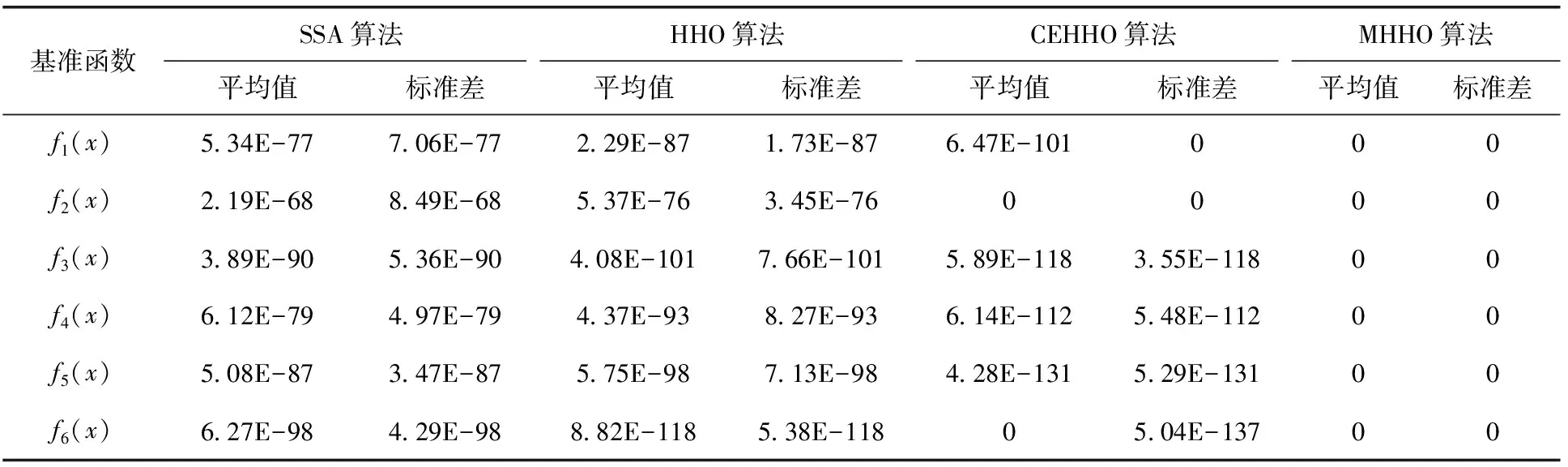
表2 对比结果

图2 算法的寻优曲线
3 针对恶意软件检测的MHHO算法同步优化支持向量机和特征选择模型
网络流量动态检测可以捕获信息流,从而获取代码的统计特征。这种能够通过大数据分析技术构建更完善的特征库,最终的分类模型准确度和恶意软件检测模型更具优势。然而,庞大的数据量和特征维度环境下,维数灾难是必须解决的问题。因此,特征选择将是针对数据预处理的必要步骤。特征选择的目标删除不相关和冗余特征,降低模型计算开销,生成最优特征子集以提升分类器学习效率。智能优化算法结合封装式特征选择,虽然在分类性能上具有一定优势,但优化机制繁琐,预设参数对模型敏感性高。MHHO对算法的求解精度和收敛效率进行了优化,模型精度更高,更加适应于解决恶意软件检测这类实际问题。
3.1 种群编码与适应度评估
利用MHHO算法进行特征选择,是为了剔除恶意软件数据集中的冗余特征和相关性较差的特征,实现特征降维从而提高分类效率。此时,MHHO算法解决的是一种离散优化问题,为了寻找最佳的特征子集,MHHO算法以二进制字符串的形式对种群个体位置进行编码,以表示特征选择的一个候选解。即:若某个特征被选择,则将其位置编码为“1”,否则其位置编码为“0”。相应解码时,通过收集位置上为1的特征数是即可得到最佳特征子集。
以支持向量机SVM构建数据集的分类模型,惩罚因子C和核函数参数g起着决定性作用。C用于描述分类结果对误差的容忍程度,C值过高容易带来数据过拟合,模型泛化能力降低;但C值过低又会带来分类误差增大,数据欠拟合甚至样本错分。而g则控制着数据映射至高维空间时的分布状况,即控制核函数径向作用范围,g值过高会导致模型复杂度趋近无穷,产生严重过拟合;而g值过小会使得数据线性可分割程度随之降低。
结合学习模型及特征选择进行数据分类,传统方法是以所有原始特征训练模型,再作参数调优,再作特征选择。该方法容易导致模型训练所用的关键特征被忽略,降低训练精度。而先作特征选择,再作模型参数调优,则训练过程涉及二次寻优,极大降低计算效率。结合两种方法的优势和不足,改进模型利用MHHO算法对SVM关键参数和特征选择进行同步优化,将种群个体编码为两部分:关键参数C、g和特征选择二进制数字串。因此,种群个体编码方式可表示为图3。
其中,原始数据集的特征量为n。
MHHO算法搜索最优解,主要以适应度函数评估个体位置优劣。结合特征选择为多目标优化问题的属性,适应度函数将同步考虑特征数量选择最少和分类准确率最大两个目标,即以最少数量的特征选择量实现最大化的分类准确率,以相关性最优的特征子集选择出来。因此,MHHO算法的适应度函数为
(24)
其中,α、β分别为针对分类准确率和选择规模的比例系数,α、β∈[0,1],且α+β=1,accuarcy表示分类准确率,FS表示特征选择量,n为特征总量。
3.2 模型设计
利用MHHO算法实现SVM优化与特征选择的过程如下:
输入:MHHO参数:种群规模、维度、迭代次数、混沌参数、能量因子递减周期数、惯性权重最值、适应度函数中的比例系数α、β;SVM模型参数C的搜索范围 [Cmin,Cmax] 和g的搜索范围 [gmin,gmax];
步骤1 对原始数据集进行归一化预处理,统一数据量纲;然后确定训练样本和测试样本;
步骤2 依据样本数据特征对种群个体进行二进制编码,并对算法进行种群初始化;
步骤3 初始化支持向量机的C和g值,结合MHHO对参数C、g及二进制编码的特征选择方案迭代寻优;
步骤4 解码特征选择方案,编码为1的个体位置选择为最优特征子集元素;
步骤5 以C、g及特征子集配置SVM分类器。利用K-折交叉验证法训练分类器*,计算适应度并更新最优解;
步骤6 算法迭代终止,保存最优解;否则,返回至步骤3;
输出:最优C、g和特征子集、分类准确率及适应度。
注*:分类器通常将数据集分为训练样本和测试样本验证模型性能,但其训练模型效果差、泛化能力不足。在改进算法中利用K-折交叉验证法提升模型泛化能力,先将数据集分为K个子集,随机选择K-1个进行模型训练,剩余1个进行模型测试,重复K次以均值结果比较性能。
协同优化的详细流程如图4所示。

图4 MHHO-SVM特征选择流程
3.3 恶意软件检测模型
图5是基于移动Andriod环境下的恶意软件检测模型,主要目标是通过分析数据流量集,检测Andriod平台下的恶意软件。模型先通过数据采集模块收集原始网络流量,再将网络流量集中的数据进行预处理,最后通过分类器对对模型训练和评估。网络数据采集主要利用流量数据技术,本文采用较为常规的嗅探法进行数据采集,通过在交换机的镜像端口上设置数据采集点,捕获流经端口的数据报文,该方法采集的信息较为全面,同时可以对网络中的数据报文进行完全复制。数据预处理过程主要包括对原始数据的简单清洗,补充缺失值,并删除一些明显离群的异常数据,最后对数据进行归一化处理,以统一量纲。特征选择模块即利用MHHO算法迭代求解最优特征子集,降低特征维度。得到最优特征子集之后,结合优化后的SVM在训练集中对模型进行训练,并以测试集进行测试,以评估指标对分类结果进行总体评估。影响模型检测效果的主要因素包括数据的特征维度和分类算法的性能,在固定的网络流量集样本前提下,所选特征子集的规模及特征相关性都决定着模型的预测精度。因此,需要挖掘原始数据、精炼特征选择,同时优化分类算法的性能。
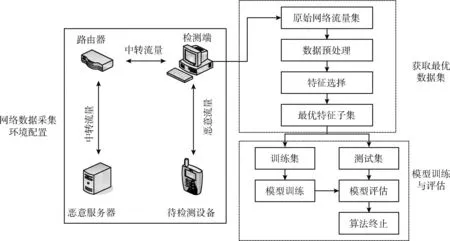
图5 恶意软件检测
4 实验分析
4.1 实验配置
为了验证MHHO算法同步优化SVM参数及特征选择问题的有效性,选择UCI的4个keel数据集和CICInvesAndMal2019数据集CIAM进行测试。数据集的样本数、特征数和类别数等相关属性说明见表3。其中,segment和CIAM数据集样本规模较大,而sonar和spectfheart数据集样本规模较小,但包含特征数相对较多,不同规模和特征的数据集有利于检测算法的适应性。而CIAM为恶意软件检测数据集,包含软件安装及运行的特征数据。该样本集共有2000个样本,65个数据特征。仿真平台为Matlab2017a,学习器选用LIBSVM。实验样本数据的提取方式是:利用Matlab的dlmread进行读取,同时将非数字类别替换为数字。在对原始数据进行预处理之后,将划分出模型的训练样本和测试样本。设置N=20,Tmax=400,α=0.99、β=0.01,能量递减参数k=4,惯性权重最值为wmin=0.4,wmax=0.9,混沌参数δ=0.4,K-折交叉验证法取K=10。算法运行20次取平均值比较。

表3 数据集属性说明
选择互信息、卡方检验、随机森林递归特征消除法RFRFE以及标准HHO算法[12]、鲸鱼优化算法WOA[17]、樽海鞘群算法SSA[18]、改进哈里斯鹰优化算法CEHHO[19]进行数据集特征选择对比,以SVM为分类算法。将特征值进行归一化处理,并以二进制方式对种群个体进行编码。特征值归一化公式为
(25)
其中,x为原始特征值,xmin、xmax为数据特征最小及最大值,xnorm为预处理特征值。
为了衡量模型分类及其泛化能力,利用平均分类准确率AAC和平均特征选择量ASN两个指标评估算法性能。定义如下
(26)
其中,Acc(i) 为第i次算法运行的分类准确率结果,Size(i) 为第i次算法运行的特征选择量结果。
4.2 实验结果
为了便于指标的对比,将互信息、卡方检验及FRFRE特征选择量筛选阈值设置为特征子集量,然后以贝叶斯模型进行参数调优。结果见表4。从规模上看,传统的互信息法、卡方检测法属于过滤式特征选择方法,特征降维上难以实现预期效果。RFRFE方法比较前两种过滤法效果略有优势,但缺乏特定参数下特征子集规模的调优,无法实现在特征降维和模型分类准确率上的同步优化,性能差于智能优化算法的实验结果。在5种结合智能优化算法的实验中,MHHO算法所选特征数量是所有模型中最少的,由于在恶意软件检测数据集CIAM中仅选取13个特征即可达到约85%左右的分类准确率,特征维度降低了约75%,表明所采取的改进机制能够有效降低数据集的特征维度,实现高效特征选择。而在分类模型的准确率指标上,MHHO算法基本在5个数据集上均实现了最高的分类准确率。此外,结合图6和图7中对所有群体智能优化算法的对比分析可知,本文所提出的MHHO算法处理恶意软件检测中对其数据集进行特征选取时能够更好地实现特征降维,选取更高质量、相关性更高的特征,并在分类准确率上得到更好的性能表现。
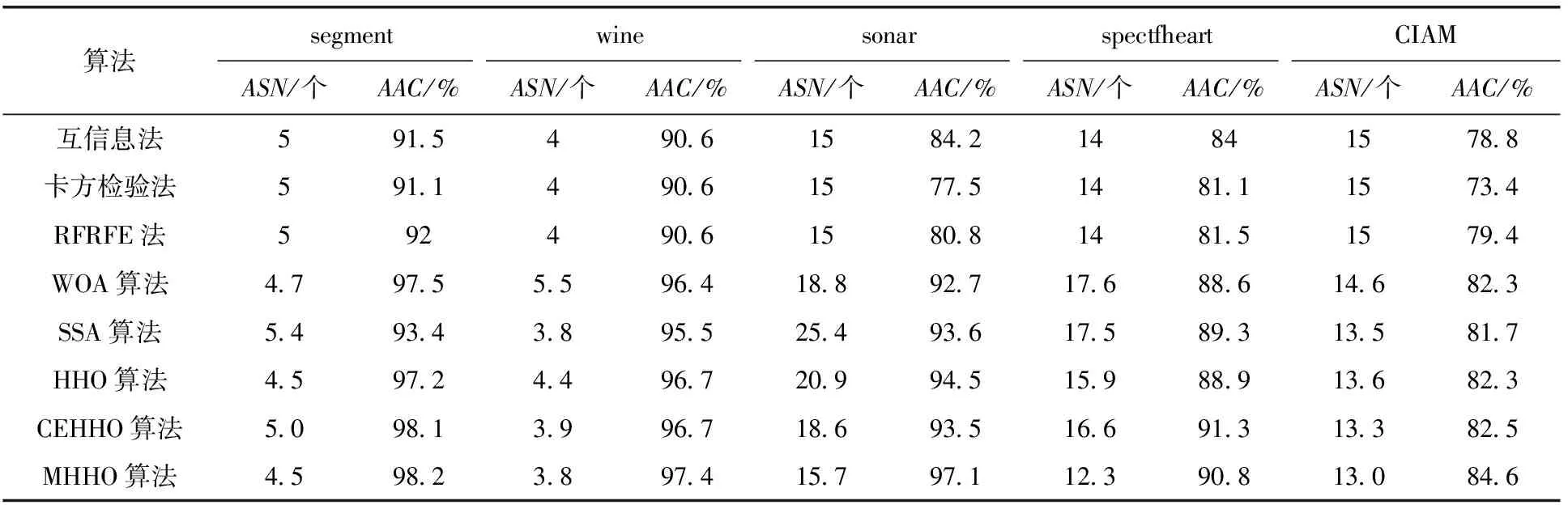
表4 不同算法实验结果
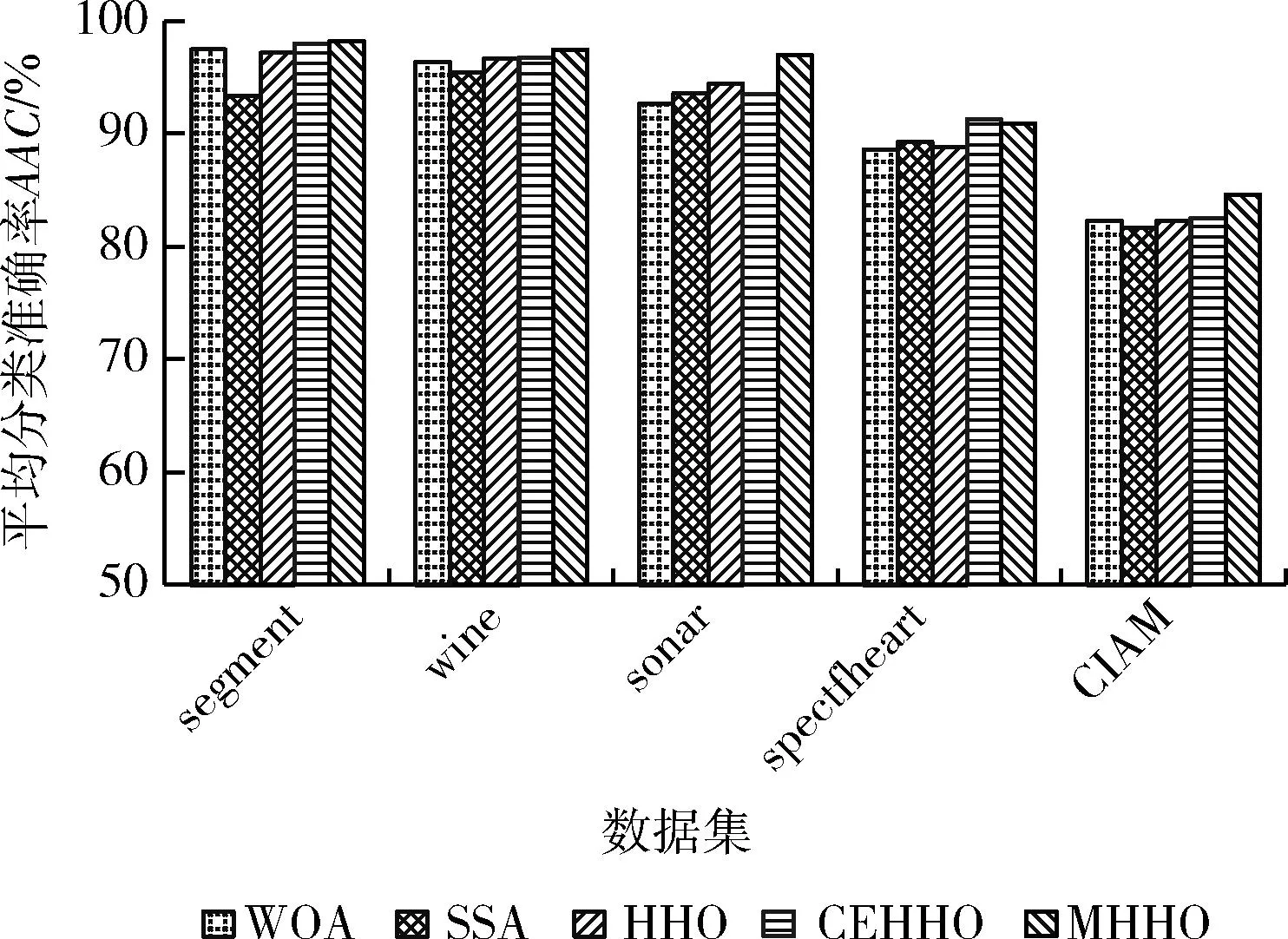
图6 不同智能优化算法得到的平均分类准确率

图7 不同智能优化算法得到的平均特征选择量
为了进一步验证MHHO的优势,接下来仅以恶意软件检测数据集CICInvesAndMal2019进行实证分析,再选择几种分类学习模型:随机森林RF、朴素贝叶斯法NB、标准支持向理机模型SVM、极端梯度提升树分类算法XGBoost,以及轻量梯度提升机分类算法LightGBM进行实验分析。除平均分类准确率AAC和平均特征选择量ASN两个指标外,再引入解的平均适应度AF和算法的平均计算时间AT进行全面对比,指标定义为
(27)
(28)
其中,fitness(i) 为第i次的适应度结果,runtime(i) 为第i次算法运行时间,SDF为适应度标准差。
实验结果见表5。可见,RF、标准SVM和XGBoost这3种模型虽然在特征降维上有一定作用,但得到分类准确率并不理想,没有实现同步优化。NB、LightGBM在分类准确率上具有一定优势,但最优特征子集的选取上不具备优势。本文的恶意软件检测模型MHHO-SVM在处理网络流量动态检测数据集上具有更明显的优势,在特征规模降维和分类准确率上实现了同步优化。在解的适应度上,MHHO-SVM模型是所有模型中最高的,而更小的标准差值SDF则反映出该模型具有更好的稳定性,平均计算时间上略高于XGBoost和LightGBM,但在综合性能上表现最优。

表5 实验结果
应用MHHO-SVM模型进行恶意软件检测,可视为一种动态检测方法,更加符合目前恶意软件检测应用背景。该模型通过利用特征分析工具,获取软件的序列特征和网络流量,利用智能优化算法更加强大的随机搜索能力,实现特征降维和分类准确率的提升,从而更加准确地对恶意软件进行分类描述。
5 结束语
提出一种改进HHO优化SVM和特征选择的恶意软件检测模型。为了提高分类模型的性能和特征子集的选取能力,利用Bernouilli shift混沌映射、能量因子非线性周期性调整、最优解变异扰动机制和互利共生策略对HHO算法全局寻优能力和求解精度进行了优化,并构建基于网络流量特征的恶意软件检测模型。实验结果表明,改进算法能够更准确地选取特征子集,实现特征降维,而且能够提升学习模型的分类准度,更准确地识别恶意软件样本。
猜你喜欢
青少年科技博览(中学版)(2022年9期)2022-11-01
今日农业(2022年15期)2022-09-20
第二课堂(小学版)(2019年7期)2019-07-16
红土地(2018年7期)2018-09-26
金色少年(奇趣科普)(2017年1期)2017-03-03
电子制作(2017年23期)2017-02-02
中国科技信息(2016年12期)2016-08-29
西北工业大学学报(2015年4期)2016-01-19
振动工程学报(2014年4期)2014-03-01
计算机工程(2014年6期)2014-02-28
