
开放场景中的高精度车牌识别算法
2024-02-21 04:36邓春华
计算机技术与发展 2024年2期
舒 森,邓春华
(武汉科技大学 计算机科学与技术学院,湖北 武汉 430065)
0 引 言
车牌识别是现代智能交通系统的重要组成部分,广泛应用于停车场管理、交通监控、交通违规处理。目前限制条件下的车牌识别技术比较成熟,广泛应用于实际生活。然而,在开放场景中,由于不同拍摄角度、较远距离、不同尺度、光线明亮度、运动模糊、数据集类别不均衡等影响,中文车牌识别仍具挑战。
在深度学习时代之前,大多数方法[1-2]都是利用颜色、阴影和纹理等手工制作的特征,并通过级联策略与车牌检测和识别相结合。尽管它们达到了较好的性能,但是该方案依赖手动设计的特征,其性能无法满足实际应用需求。而随着深度学习的发展,使用卷积神经网络(Convolutional Neural Networks,CNN)能够有效地提取对象丰富的特征,极大地增强了车牌识别的性能,基于CNN的车牌识别算法[3-4]在限制条件下已经形成较成熟的技术。
已有的中文车牌公共数据集存在较多缺陷。最大的车牌数据集CCPD[5]拥有超过250 K个样本,97%以上的车牌都是“皖”开头。而其它中文公共数据集[6-7]拥有的车牌数量远远少于CCPD,实际应用价值不高。针对上述车牌类型和字符分布不均衡的现象,该文制作了一系列配套中文车牌数据集。
现有的车牌识别方法[3,5]大多为采集数据训练的模型和单一算法,极大地依赖于采集的数据,以及单一地使用检测或分类模型不能达到高鲁棒性的效果。结合制作的数据集,该文提出了一种检测、分类一体化的逐级车牌识别算法。该算法结合了对象检测、图像分类的优点,有机融合真实车牌和模拟车牌样本进行混合训练,有效克服了采集数据训练的模型和单一算法鲁棒性不足的缺陷,具有较强的实际应用价值。此外,针对车牌字符分类算法需要高精度字符分割的基础,该文提出了一种多锚点字符位置回归算法,能够利用车牌中置信度较高的字符位置信息预测其它位置信息。构建的一系列中文车牌数据集,均衡了车牌类型、车牌字符分布。
1 相关工作
典型的车牌识别方法都是采集数据训练模型和使用单一的检测算法进行字符识别。最近基于深度学习的研究工作,通过对检测网络进行改进,都取得了较好的车牌识别效果。Laroca等人[8]提出了一种统一的车牌检测和布局分类方法,提高了使用后处理规则的识别结果。Zhou等人[9]采用YOLOv4[10]目标检测框架实现车牌的检测,和使用循环神经网络(Recurrent Neural Network,RNN)实现字符识别。Tanwar等人[11]通过采集印度车牌数据集并使用语义分割来解决车牌检测,裁剪出不受图像方向影响的车牌,使用轻量级的CNN进行字符识别。文本检测中的ABCNet v2[12]能够有效检测弯曲文本,可以很好的兼顾图像中形变的车牌。但是采集数据训练模型和单一算法对于采集到的数据过于依赖,并且只使用检测算法,车牌识别的鲁棒性不高。
车牌识别是对检测后的车牌区域中的字符进行识别。车牌识别主要分为基于分割的方法和无分割的方法。基于分割的方法包含字符分割、字符识别。这种方法需要准确的字符分割,并且图像模糊和环境因素也会进一步降低字符分割的准确性。现有的研究中,无分割的方法逐渐取代了基于分割的方法。
无分割方法先从车牌中提取特征,并将其传递给CNN或RNN模型来识别字符序列。近年来,出现了大量的无分割的端到端车牌识别方案。Zherzdev等人[3]提出的LPRNet采用一种端到端的识别方案,使用原始RGB像素作为CNN输入,不需要字符分割,速度快、效果好。Qin等人[13]提出了一种统一的方法,可以端到端地识别单行和双行车牌,而无需行分割和字符分割。Li等人[14]提出的光学字符识别场景应用集合框架PP-OCRv3,对车牌识别进行了集成,直接检测出车牌字符。这种直接检测字符的无分割方法固然速度快,效果较好,但是存在着字符漏检的情况,影响车牌识别结果。如何实现每次都能完整地识别出车牌的结果,是个值得研究的问题。
但是,由于中文车牌中汉字复杂多样,中文车牌识别仍具有挑战性。同时,开放场景中的车牌识别也面临很多问题。因此,为中文车牌检测和识别提出一个新的框架仍然具有价值。
近年来研究人员构建了多种车牌数据集。Zhang等人[6]提出了一个数据集,其中包含来自中国大陆31个省份的1 200张车牌图像。中科大的杨威团队提供一个大型车牌数据集(CCPD)[5],拥有超过250 K张图像,其中包含具有各种角度、距离和照明的车牌。随后在2019年更新构建了CCPD2019,并在2020年增加了一个新能源汽车子数据集(CCPD-Green)。Gong等人[7]生成了一个名为中国路牌数据集(CRPD),其中包含多目标中国车牌图像作为对现有公共基准的补充,是最大的带有顶点注释的公共多目标中文车牌数据集。
2 数据集介绍
车牌识别能力的高低取决于模型训练的好坏,而模型的训练严重依赖于数据集。由于现有的车牌数据集中存在着规模过小[6-7]、车牌类型和字符分布不均衡[5]等问题,难以训练一个稳健的中国车牌识别模型去解决开放场景中的车牌识别任务。针对这种现象,该文制作了一系列配套中文车牌数据集,具体如表1所示。

表1 数据集介绍
该系列数据集包括模拟车牌子集、实时监控运动车辆车牌子集、字符级别的标注子集、模拟字符子集、单字符分割的分类子集。其中模拟车牌子集和字符级别的标注子集用于训练,实时监控运动车辆车牌子集用于测试,模拟字符子集用于训练和单字符分割的分类子集用于训练和测试。考虑到各地车牌收集的困难,采取模拟生成大量省份分布均衡的200 K张车牌和200 K个字符用于辅助训练。每种省份车牌平均23 K张,模拟字符子集中平均每种字符有2.9 K个。
2.1 车牌数据集
车牌数据集包括模拟车牌子集、实时监控运动车辆车牌子集、字符级别的标注子集。
模拟车牌子集含有多种类型的模拟车牌(蓝牌、绿牌、黄牌、黑牌、白牌),增加车牌中汉字的比重,并对模拟车牌进行了仿射变换、亮度和对比度调整、高斯模糊等处理,以增强车牌的多样性。每张车牌都带有字符级的详细标注,包括字符类别、中心点坐标、宽和高。
实时监控运动车辆车牌子集,包含蓝牌、绿牌、黄牌等车牌。其中的车牌由两部分组成,一部分是从CRPD[11]中检测得到,另一部分是从实时监控运动的车辆中检测而得,兼顾了各个省份的车牌。
字符级别的标注子集中的车牌都是现实场景中的真实车牌,并且对每张车牌都进行了字符级别的标注,对应的标签中都包含着车牌中每个字符的类别、中心点坐标、宽和高等信息。该子集主要是蓝牌。各车牌子集中绿牌尺寸为480×140像素,其余车牌尺寸为440×140像素。
2.2 字符数据集
字符数据集包括模拟字符子集和单字符分割的分类子集。模拟字符子集是通过对字符模板进行仿射变换、高斯模糊、亮度和对比度调整、颜色变换等操作制作而成,蓝牌字符和绿牌字符各占一半。单字符分割的分类子集是在进行了高斯模糊和调节亮度和对比度等预处理的真实车牌图像中获得的字符,命名为SCSCS(Single Character Segmentation Classification Subset),字符大小为64×128像素。包含61.6 K个绿牌字符,150 K个蓝牌字符,其中训练集、验证集和测试集按照6∶2∶2划分。
3 主要工作
针对车牌类型和字符分布不均衡的问题,该文提出了一种检测、分类一体化的逐级车牌识别算法。该算法结合了对象检测、图像分类的优点,有机融合真实车牌和模拟车牌样本进行混合训练,能够有效克服采集数据训练的模型和单一算法鲁棒性不足的缺陷。针对车牌字符分类算法需要高精度字符分割和基于分割方法不足的问题,该文提出了一种多锚点字符位置回归算法取代基于分割的方法,能够有效利用车牌中置信度较高的字符位置信息回归出其它位置信息。
3.1 检测、分类一体化的逐级车牌识别算法
开放场景中,由于不同拍摄角度、较远距离、不同尺度、光线明亮度、运动模糊等因素的影响,单一的端到端深度学习的车牌识别方法的鲁棒性不佳,不能很好地应用。于是提出检测、分类一体化的逐级车牌识别算法,逐级进行对象检测并与字符分类相结合。考虑到图像中车辆数据获取较为容易,同时车辆图像具有更易区分的纹理特征及语义特征,逐级进行车辆检测、车牌检测、字符检测,并结合字符分类,具体如图1所示。

图1 方法框架
对于字符分类,由于在开放场景中获取到的车牌存在缺损、模糊、遮挡、变形等情况,并且其中的中文字符容易笔画模糊并且现有的数据集中字符类型分布不均衡,给车牌字符的识别带来了极大的困难。由此,该文使用多阶段字符分类训练方法来训练出这个字符分类模型。通过模拟数据和真实数据相结合,多次训练,不断提高字符识别效果。
3.2 多锚点字符位置回归算法
在字符检测时,获得的车牌并非所有都是满足标准车牌格式,仍含有少数车牌中字符存在向左偏移或者向右偏移的情况,给车牌中的字符定位带来了较大的挑战。
无分割的方法对于过度偏移车牌上的识别还是会存在字符检测不准的问题。因此,为了更加精确地定位车牌中字符的位置,提出了多锚点字符位置回归算法,设计了三种锚点来匹配车牌,可以根据字符检测模型获得的局部字符位置信息精确地回归出未被检测字符的位置信息。三种锚点为左偏移锚点、标准锚点和右偏移锚点,左偏移锚点是指车牌中的字符相较于标准车牌整体向左偏移;标准锚点是根据标准车牌规格所确定的锚点,字符基本处于车牌地中间区域,足以满足大多数正常规格的车牌;右偏移锚点是指车牌字符相较于标准车牌整体向右偏移。该文设计的多锚点字符位置回归算法可以有效处理多种车牌,包括蓝牌、黑牌、部分白牌、绿牌、双牌以及特殊白牌。如图2所示,以蓝牌和绿牌为例介绍多锚点字符位置回归算法。

(a) (b) (c)
图中左边的是蓝牌,右边的是绿牌,其中第一行的(a)是左偏移锚点,(b)是标准锚点,(c)是右偏移锚点。第二行从左到右分别是车牌字符向左偏移车牌、正常车牌和字符向右偏移车牌。第三行和第四行分别为未使用多锚点字符位置回归算法和使用多锚点字符位置回归算法的车牌字符定位情况。多锚点字符位置回归算法流程如图3所示。

图3 多锚点字符位置回归算法流程
对于经过字符检测模型的初步检测结果,当已检测字符个数小于车牌中字符个数,则通过多锚点字符位置回归算法回归出未检测的字符。首先通过比较车牌中的字符在三种锚点中的数量确定车牌属于哪种锚点,如式1所示:
(1)
其中,anchor为车牌所属锚点,L,S,R表示车牌属于左偏移锚点、标准锚点和右偏移锚点,max表示该锚点下的字符最多,n为车牌中已检测字符的个数,Li,Si,Ri表示第i个字符属于左偏移锚点、标准锚点和右偏移锚点。通过确定车牌所属的锚点,从而确定车牌中字符对应的偏移值,最终确定车牌中已检测字符在车牌中的次序。
然后通过已确定次序字符的位置信息回归出未检测的字符。首先通过车牌中已检测字符的中心点坐标、宽度和高度,获得其平均值,如式2所示:
(2)

考虑到车牌检测结果中单个字符可能存在多个预测结果,当m大于1时,先计算出字符宽度和高度的标准差,如式3所示:
(3)
其中,σw,σh为已检测字符的宽度和高度的方差。结合σw,σh,重新计算出已检测字符中心点坐标平均值,如式4、式5所示:
(4)
(5)

w=
(6)
h=
(7)
其中,w,h为回归的未检测字符的宽度和高度,W∈Rl,H∈Rl为已检测字符预测结果的宽度和高度矩阵。
(8)
(9)
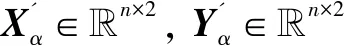
4 实验结果与分析
4.1 实验细节
该文选择了SCSCS,PDRC(License Plate Detection and Recognition Challenge),CCPD2019这三个数据集进行训练和测试,实时监控运动车辆车牌子集仅作为测试。PDRC是飞桨对CCPD2019处理后得到的数据集,其中不包含没有车牌的车图像,已删除清晰度太低的图片,并进行去重,全为蓝牌。图片总数121 K张,训练集和测试集数量分别为95 774和25 657,具体如表2所示。其中,PDRC和CCPD的图片大小调整为640×640像素,实时监控运动车辆车牌子集的图片大小为440×140像素。

表2 PDRC和CCPD,CCPD2019的比较
该文使用平均识别精度(Average Precision,AP)和每秒处理帧数(Frames Per Second,FPS)作为评价指标,AP来比较模型的优劣,fps衡量模型的识别效率。
在训练阶段,文中方法由PyTorch实现,实验在配备Intel Xeon(R) E5-2683 v3 CPU和单个NVIDIA GTX-1080TI GPU的平台上进行训练。
在车辆检测阶段,采用CSPDarknet53[10]作为主干网络,输入图片大小为640×640像素,采用SGD优化器,其学习率设置为0.001,动量因子为0.9,权重衰减为5e-4,batch size设置为64。在车牌检测阶段,由于车牌也可以看做文本,鉴于ABCNet v2[12]在文本检测中的良好效果,该文采用其进行车牌的检测,batch size设置为2,最大迭代次数为260 K,初始学习率设置为0.01,在第20 K次和30 K次迭代时分别降至0.001和0.000 1。在车牌识别阶段,采用CSPDarknet53作为主干网络,训练数据由模拟车牌子集和真实车牌数据集组成,输入图片大小为512×512像素,采用SGD优化器,其学习率设置为0.001 3,动量因子为0.949,权重衰减为5e-4;batch size设置为64。由于batch size为64,所以在训练的每个batch中加入18个含有多个汉字的模拟车牌,用来增加车牌中汉字的比重,以加强识别汉字的能力。在多阶段字符分类网络训练过程中,采用ResNet50[15]作为主干网络,训练数据由模拟字符子集和单字符分割的分类子集组成,学习率设置为0.02,动量因子为0.9,权重衰减为5e-4,batch size设置为64,一共训练50个epoch,采用SGD优化器进行训练。
4.2 结果分析
为了验证在字符分类中所使用的模拟数据与真实数据相结合的多阶段字符分类训练方法的有效性,设计了在SCSCS上的消融实验。
多阶段分类训练中,在第一阶段,使用模拟字符子集进行训练,子集中均衡地包含各种字符,尤其是各种省份汉字字符。第二阶段,在每一次batch训练后,在验证过程中将预测结果中置信度小于0.5的字符视为困难字符,其余视为简单字符。并将困难字符的模拟字符加入下一次训练的batch中,简单字符和困难字符的比例设置为9∶1。第三阶段,在第二阶段训练的基础上加入SCSCS中的字符一起训练,在每个batch中模拟字符和真实字符的比例设置为5∶1。通过多次训练,不断增强字符识别的泛化能力和鲁棒性。在SCSCS上测试了三个阶段的准确度,结果如表3所示。可以看出多阶段训练方法是有效的,其中第二阶段在两种车牌测试集上提升约1百分点。在第三阶段中加入真实车牌字符后,都有了很大的提升,分别在蓝牌、绿牌上提升了约5.7百分点和4百分点,验证了模拟字符子集和SCSCS结合训练的有效性。

表3 在SCSCS上三个阶段的准确度
为了证明文中方法的有效性,与其他方法在PDRC上进行了比较。先通过ABCNet v2对数据集进行检测,获得了车牌数据集,其中95 774张车牌用作训练,25 537张车牌用作测试。通过与其他方法的比较,验证多锚点位置回归算法的有效性,结果如表4所示。结果表明,文中方法在数据集整体,Tilt,Weather子集中提升0.5百分点,在DB,Challenge子集中提升超过1百分点,由于FN子集中车牌形状更加复杂,导致识别结果略低。

表4 文中方法与其他方法在PDRC上的比较
在实时监控运动车辆车牌子集上与其他方法进行比较,测试结果如表5所示。可以看出由于CCPD数据集中汉字的不均衡性,导致训练而成的模型LPRNET[11]和PP-OCRv3[14]具有局限性,不能很好地识别文中提供的实时监控运动车辆车牌子集。可以证明文中提出的系列配套数据集的有效性,与采集数据模型和单一模型相比,文中方法有着较强的鲁棒性,能够适应多种场景下的车牌识别。

表5 不同方法在实时监控运动车辆车牌子集上的准确度
在采集的图片上进行了验证,效果如图4所示,能够较好地识别测试图片。

图4 场景测试效果
文中方法在数据集整体和各子集中都基本该文也在CCPD数据集上与其他方法作了比较。因为Xu[5]和Gong[7]都在不同的情况下评估了他们的方法,为了公平比较,该文在CCPD的各测试子集上进行实验。按照Xu[5]和Gong[7]的实验,Faster-RCNN[16], YOLOv4[10],SYOLOv4(ScaledYOLO-v4)[17],STELA[18]作为检测模型,HC(Holistic-CNN)[19]和CRNN[20]作为识别模型,端到端方法TE2E[21]和RPNet[5]用于比较。该文还将ABCNet v2[12]与LPRNET[11]和PP-OCRv3[14]结合起来做更多的比较。如表6所示,可以看出文中的方法在数据集整体和各子集中都基本达到或接近最佳状态,并在整体识别精度达到99%。在旋转或倾斜的车牌图像(Rotate)和通用车牌图像(Base)子集中都取得了更好的成绩。在效率上,由于该文是在单个NVIDIA GTX-1080TI GPU上进行测试,ABCNet v2的检测影响了整个方法的效率,所以与其他方法相比略低。因为文中方法是一个多线程的解决方案,整体的识别效率由最耗时的检测部分决定,因此比ABCNet v2与LPRNET和PP-OCRv3结合的两种方案的识别效率略高。

表6 文中方法与其他方法在CCPD上的比较
5 结束语
综合考虑开放场景中车牌识别容易受到拍摄角度差异较大、车辆运动模糊等因素的影响以及车牌数据集中类别不均衡的问题后,提出了一种融合算法和系列数据集一体化的方法。其中构建的一系列中文车牌数据集,极大地均衡了车牌类型、车牌字符分布,丰富了车牌数据集;提出了一种检测、分类一体化的逐级车牌识别算法,解决了采集数据训练模型和单一算法的鲁棒性不足的问题;使用无分割的字符位置尺度回归算法,能够较精确地回归出车牌中的所有字符。在多个数据集上验证了文中方法的有效性,具有高鲁棒性,能够满足开放场景中的车牌自动识别需求。虽然在车牌识别上达到了高性能,但是在识别效率上略有不足,未来将探索在保持高性能的同时实现较高的识别效率。
猜你喜欢
语数外学习·高中版下旬(2023年7期)2023-09-25
安庆师范大学学报(自然科学版)(2021年1期)2021-11-28
通信电源技术(2021年2期)2021-05-21
电子技术与软件工程(2020年22期)2021-01-30
数字技术与应用(2020年12期)2021-01-22
移动通信(2020年5期)2020-06-08
南京大学学报(数学半年刊)(2020年1期)2020-03-19
电子制作(2019年12期)2019-07-16
小猕猴智力画刊(2017年5期)2017-05-25
电子制作(2017年22期)2017-02-02
