
基于查询特征表示学习的联邦复杂查询基数估计
2024-02-21 03:47:28田萍芳顾进广徐芳芳
计算机技术与发展 2024年2期
徐 娇,田萍芳,顾进广,徐芳芳
(1.武汉科技大学 计算机科学与技术学院,湖北 武汉 430065;2.湖北省智能信息处理与实时工业系统重点实验室,湖北 武汉 430065;3.武汉科技大学 大数据科学与工程研究院,湖北 武汉 430065;4.国家新闻出版署富媒体数字出版内容组织与知识服务重点实验室,北京 100083)
0 引 言
准确的基数估计是实现最佳查询计划的关键因素。现有方法大多基于深度学习来解决基数估计问题,例如,在给定知识图谱的情况下,Davitkova A等人[1]提出了LMKG方法来学习和估计最常用的查询类型(即星形和链形查询)的基数,通过将图模式的基数估计问题表示为一个深度学习任务,有效地捕获不同子图模式之间的相关性,从而提供非常准确的估计结果。然而,这种基于RDF图模式的方法专注于具有特定拓扑结构的简单查询,适用范围有限[2-3]。例如,在现实场景中,带有FILTER或DISTINCT运算符的复杂SPARQL语句构成了一大类频繁使用的查询[4],但现有方法缺乏对这类复杂查询的基数估计支持。
为了解决以上问题,该文提出基于查询特征表示学习的联邦复杂查询基数估计模型,以学习和预测输入查询的基数。模型包含两个方法,基于全连接多层神经网络(Multi-Layer Perceptron,MLP)来预测结果。对于FILTER类查询,将查询表示为:顶点集、边集、连接集和FILTER条件子句集四个特征,FILTER条件子句集使用新提出的特征化方法编码,其他三个特征集则使用SG-Encoding进行编码,将合并的向量集作为参数输入模型,模型预测查询基数。而对于DISTINCT查询,使用模型预测唯一行的比率。结果表明,该方法能得到更精确的基数估计,具有实际应用价值。
综上所述,该文的贡献可以归纳为:
(1)提出了一种FILTER查询特征化的方法,分为简单范围谓词编码和通用合取编码,将编码得到的特征向量作为模型的输入,解决了SPARQL联邦查询向量化问题;
(2)提出了一种基于MLP估计唯一率的方法,以实现DISTINCT查询估计不包含重复项基数的功能;
(3)提出了基于查询特征表示学习的联邦复杂查询基数估计模型,该模型可以学习并预测联邦系统中包含FILTER或DISTINCT关键字的SPARQL查询。
1 相关工作
以往的研究表明,在WHERE子句中包含AND,OR和NOT运算符的查询构成了一大类频繁使用的查询,它们的表达能力大致相当于关系代数,而在SPARQL系统中,这类查询通常由FILTER运算符进行标识和连接。此外,对于具有DISTINCT以及在计划中的查询,查询规划器需要集合论基数,例如,在考虑排序选项时。因此,上述两类查询的基数估计对于查询优化非常重要[5-7]。另外,对于深度学习的基数估计而言,查询特征化技术是必要的[8]。
深度学习用于基数估计在SQL领域已进行了深入研究[9-17]。MSCN[7]模型基于神经网络来支持具有多个谓词的基表和连接大小估计,但其查询特征化缺乏领域知识和可解释性,因为在训练过程中通过其结构学习隐含的黑盒特征。Naru[18]使用自回归模型来学习点查询的条件联合概率,但会增加范围查询的开销,因为它们的估计是多个点查询的总和。DeepDB[19]则在一定程度上依赖于采样来寻找匹配的连接属性构建SPN。基于树型门控循环单元的方法[20]同时对基数和代价进行估计,能够有效学习计划与基数和代价之间的高维关系,进而给出精确的估计结果。
在SPARQL联邦查询中,SPLENDID[21]使用VOID统计信息和基于成本的基数估计模型为联邦查询选择执行计划,但其成本模型没有涵盖分组、聚合和SERVICE子查询等复杂查询场景。Odyssey[22]基于特征集方法,在基数估计时考虑了使用DISTINCT修饰符的查询,但所使用的共享相同属性集的实体相似原则主要适用于星形查询。CostFed[23]基于数据摘要文件来估计查询成本,其中通过创建资源桶来考虑资源频率分布的不对称性,以至于对数据集中高频三元组模式估计质量好,但对于低频三元组模式则表现较差。基于查询特征表示学习的联邦知识查询基数估计方法[24]通过将SPARQL查询表示为特征向量,使用CEFQR模型学习和预测查询中的基数。虽然该模型在基数估计问题上表现优异,但是如上文所述,该方法缺乏对复杂查询基数估计的支持。
受到SQL领域的启发,笔者认为可以将SPARQL复杂联邦查询的基数估计问题表示为一个监督学习任务,标签是实际基数,输入的是查询特征,输出的是预测的基数。相较于查询特征表示学习的方法(CEFQR[24]),文中方法具有以下创新:首先,文中方法不再局限于简单联邦查询,而是将模型扩展为支持复杂查询的基数估计。相应地,提出了复杂类查询的编码技术;其次,文中模型除了预测SPARQL查询的基数外,还能估计查询中不重复结果的基数,应用范围更广泛。总得来说,文中模型更具实用价值。
2 基于查询特征表示学习的联邦复杂查询基数估计模型
2.1 模型概述
模型的整体架构如图1所示。根据输入查询类型的不同,模型输出相应的预测值。当输入类型是包含FILTER关键字的查询时,模型输出预测基数Wout,相反,若为DISTINCT类查询则输出唯一率Rout。从输入查询到模型输出预测结果主要经历三个阶段:第一阶段,将输入查询转换成一组向量V,V由多个集合组成。对于FILTER类查询,V=(A,X,E,F),其中A表示邻接张量,X表示节点特征矩阵,E表示谓词特征矩阵,F表示FILTER条件子句特征矩阵;而针对DISTINCT类查询,V=(A,X,E)关于两类查询的编码方式,A,X,E矩阵的特征化表示使用LMKG所提出的SG-Encoding编码,F条件子句的编码方式将在2.2节详细介绍。第二阶段,给定向量集合V,将V的每个向量作为MLPout的输入,MLPmid是全连接的单层神经网络。然后MLPmid将V中的每个向量集合连接合并成H维向量Qvec,其中Qvec表示V中所有元素的单个转换表示的平均值,即:
(1)
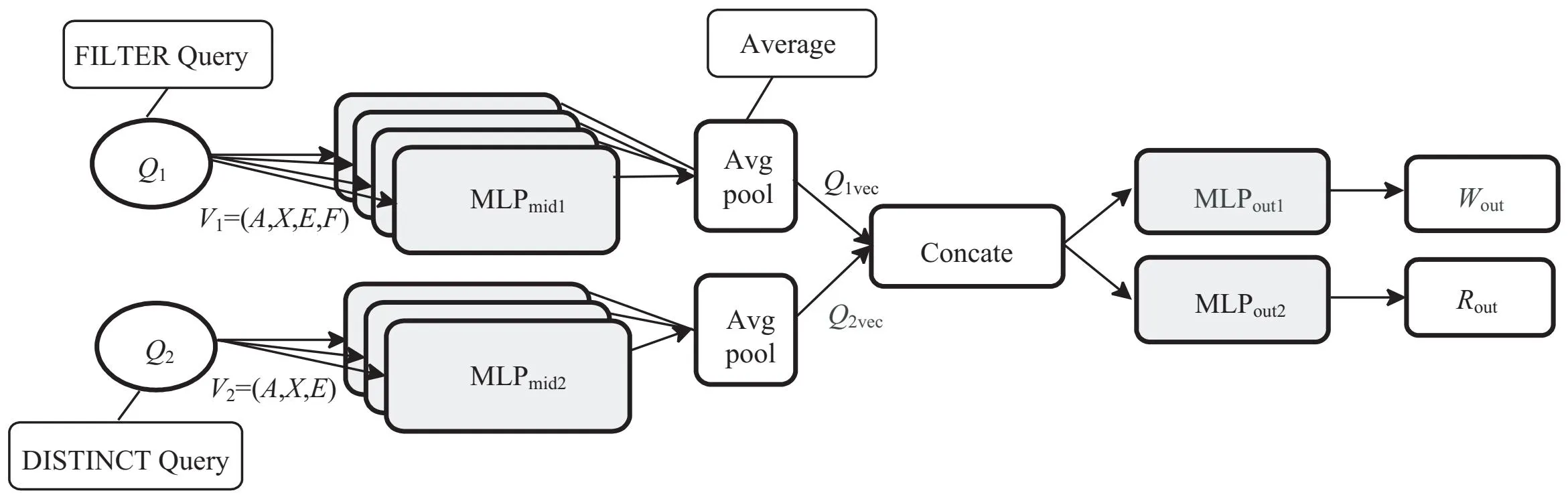
图1 模型架构
MLPmid(v)=ReLU(vUmid+bmid)
(2)
其中,Umid∈RLxH,bmid∈RH表示学习的权重和偏差,而v∈RL是输入行向量。选择一个平均值(而不是求和)来简化对集合V中不同数量元素的泛化。在第三阶段,使用两层神经网络MLPout估计查询的预测基数Wout或唯一率Rout,对于FILTER类查询,Wout=MLPout1(Qvec)。唯一率Rout的计算过程将在2.3节详细讨论。
模型对目标基数C进行归一化:首先取对数使目标值分布更均匀,然后使用从训练集获得的对数化后的最小值和最大值来归一化到区间[0,1]。归一化是可逆的,因此模型可以对预测结果Wout∈[0,1]反归一化得到预测基数。
模型的构建包括两个步骤。首先,生成一个随机训练集。其次,使用训练集训练该模型,直到平均Q-error开始收敛到其最佳绝对值,Q-error被定义为估计值(Y)与真实值(y)之间的比率,如公式3。在训练阶段,使用了早停技术。此外,实验使用TensorFlow[25]框架和Adam[26]训练优化器来训练和测试模型。
(3)
2.2 FILTER查询特征化方法
如上所示,该文重点关注对FILTER条件子句的编码。
(1)简单范围谓词编码。
对于匹配单个变量的范围谓词查询,定义条件子句F=(var,op,val),var表示用于筛选的变量名,在使用SG-Encoding对(A,X,E)进行编码时,会对子图节点(主语和宾语)和谓语进行排序,之后创建Term-ID映射列表,var根据此列表进行One-Hot编码。op表示比较运算符>,=,<中的任意一种,使用长度为3的二进制编码。val表示比较的文字值,使用公式4将var归一化为[0,1]范围的val*。
(4)
在进行范围谓词编码时,考虑了值的离散分布,将所有类型的点和范围谓词都编码到封闭区间。例如,?x=5变成[5,5],?x≤5变成[Min(x),5]。当条件子句的开放范围很大时,只需要对满足筛选条件且在变量值域范围内的值进行编码,来减少特征化过程的时间,这对训练模型是很有益的。例如图2,在Q1查询中,给定max(?age)=50,min(?age)=15,对FILTER(?age<24)子句的编码过程为:首先使用Term-ID映射列表将?age编码为[10],然后根据变量的值域范围将筛选谓词限定为15
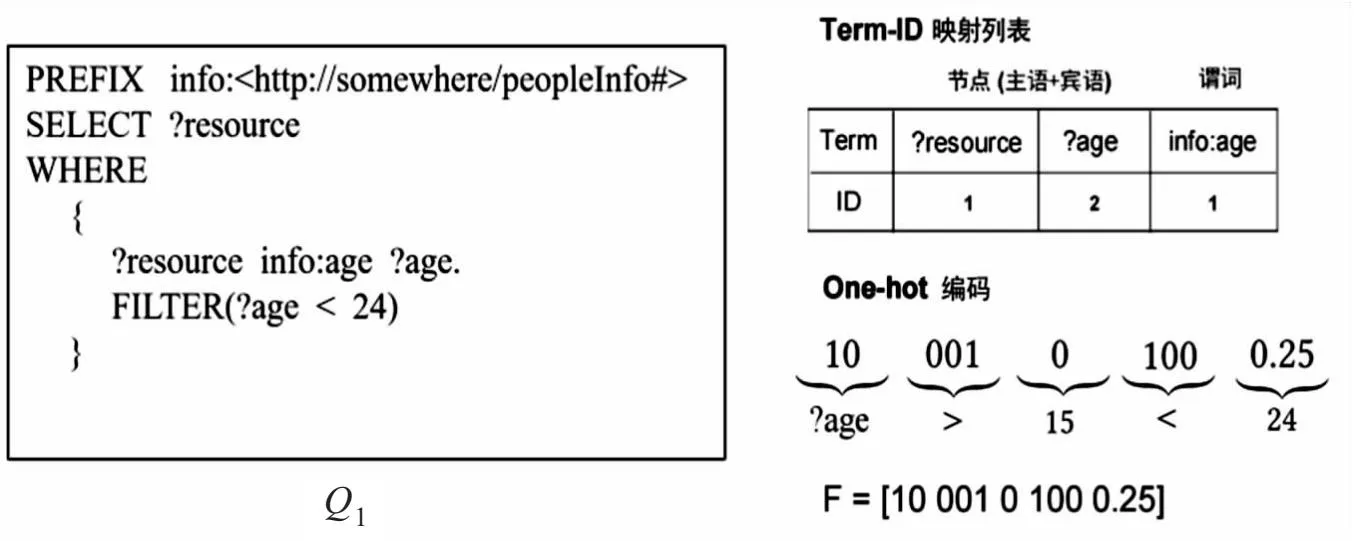
图2 简单范围谓词编码过程
(2)通用合取编码。
对于具有多个变量且每个变量存在多个谓词的范围查询,使用通用合取编码。通过观察发现,当条件子句中存在多个变量,且每个变量具有多个谓词时,变量必然属于主语、谓语或宾语中的一类,那么满足条件的值则一定存在于对应节点的值域范围内。因此,编码步骤简述为:(a)对每类节点的数据域进行分区;(b)在特征向量中给每个分区一个条目;(c)给每个条目分配一个值,指示它所代表的分区是否满足查询Q中的谓词,使用0表示没有值满足条件,1/2表示部分满足,1表示都满足。其中,每类节点N(N∈{s,p,o})的最大分区数为n(N)=min(n,max(N)-min(N)+1),n表示设定的最大分区数阈值。另外,特征向量中的条目v(v∈N)具有基于零的索引index(v),计算方式如式5。
(5)
最后,每类节点特征化的连接产生总的特征向量F。例如图3,给定查询Q2中涉及的主语和宾语的最值为:min(S)=-9,max(S)=50,min(O)=0,max(O)=115,并且n=12。对FILTER (?id<7&& ?age>10 &&?age<30)子句的编码过程为:首先,对于?id<7,因为?id属于主语,所以计算它在S分区中的索引,根据公式5,index(?id)=3,则在S分区中第四个条目设置为1/2(索引从0开始),左侧的所有条目均为1,表示小于7的值符合条件,相应地,右边的所有条目均设置为0。同理,按照上述步骤处理?age上的条件。最后得到向量F如图3所示。

图3 通用合取编码过程
2.3 估计唯一率
对于DISTINCT类查询,首先,给出唯一率的定义:如果SPARQL查询Q在RDF数据集D上的执行结果行(包含重复)中有x%是唯一的,那么查询Q在数据集D上的唯一率等于x%,计算公式为:
(6)
其中,QD表示Q在D上的基数,运算符‖ ‖返回去除重复的基数, | |返回包含重复项的基数。
使用完全连接的双层神经网络MLPout来计算输入查询的预测唯一率Rout。首先,MLPout将大小为H的Qvec向量作为输入,然后使用第一层将输入向量转换为大小为0.5H向量,最后使用第二层将0.5H向量转换为表示唯一率的单个值Rout,计算方式如下所示:
Rout=MLPout2(Qvec2)
(7)
MLPout2(v)=Sigmoid(ReLU(vUout1+bout1)Uout2+bout2)
(8)
其中,Rout是估计的唯一率,Uout1∈RHx0.5H,bout1∈R0.5H和Uout2∈R0.5Hx1,bout1∈R1是学习的的权重和偏差。
如上所述,使用经验性强且快速的ReLU激活函数来评估所有神经网络中隐含层单元,唯一率的值分布在[0,1]范围内。在预测唯一率Rout时,应用第二层中的Sigmoid激活函数来输出该范围内的浮点值。特别地,不对Rout做任何特征化,并且使用真实唯一率的值来训练模型,而不需要任何中间的特征化步骤。
值得注意的是,本模型对于DISTINCT类查询,预测唯一行的比率是基于以下目的:希望在不改变现有基数估计模型的情况下扩展模型以支持DISTINCT查询。例如,给定SPARQL查询Q,任意有限基数估计模型(估计结果中包含重复行的模型)M,设基数C=M(Q),C包含重复项,通过执行Rout·C即可得到集合论基数(不包含重复项基数)。
2.4 训练数据
使用专门的查询生成器获得初始训练语料库。生成初始语料库分为两个步骤。第一步,生成两种类型的图模式。对于星型子图模式,随机选取一个起始节点,然后从该起始节点模拟一个随机步长m次,得到大小为m的星形图模式。类似地,对于链模式,从随机选择的节点开始游走,并在大小达到n后停止。其中m和n的大小由缩小采样的比例因子来决定。第二步,将图模式转换为示例查询。示例查询由三重模式,条件子句和查询结果的真实基数构成。首先,生成足够数量的子图模式后,将图模式中包含的所有主语、谓语、宾语按行转换成三重模式。在迭代转换过程中,对于每个三重模式中未绑定的变量,将其加入候选变量集。其次,生成查询的条件子句,条件子句由(var,op,val)组成,其中var从候选变量集中随机生成一个变量,op则由操作符集{>,=,<}随机生成单个操作符,val的值根据子图中对应的主语、谓语、宾语的值域随机生成。特别地,当某个三重模式的候选变量集的大小大于1时,为该三重模式生成多个条件子句(≤候选变量集的大小),多个条件子句之间用&&连接。最后,发送由三重模式组成的SPARQL查询获取真实基数,如果真实基数为0,则表示生成的查询不合法,将其丢弃。第三步,样本分类。执行完上述步骤后,将所有包含条件子句的示例查询加入语料库1,用于训练 FILTER查询的基数。其余查询加入到语料库2,用于估计唯一率。语料库2的训练样本由三重模式,查询结果的真实唯一行比率组成。通过以上步骤,最终得到了文中模型的初始训练集。
3 实验与分析
3.1 实验设置
使用LUBM[27]数据集进行实验。为模拟SPARQL联邦查询,首先将LUBM的1 700万条数据按谓词数12,12,11划分为三个数据集(LUBM谓词总数为35),然后通过随机选取最终得到15个谓词,划分后每个数据集的三元组总数依次为9 101 646,11 507 508,7 082 141。最后在划分得到的数据集上生成30万个具有0到2个连接的随机查询和1 000个物化样本作为训练数据,并且将训练数据分为90%的训练样本和10%的验证样本。使用训练数据来训练模型并得到对应的真实基数。
此外,为了验证模型的基础能力和扩展能力,在划分的数据集上合成了4种不同的工作负载:(1)FilterCrd_1,具有4 500个唯一查询,用于验证模型关于范围筛选的估计能力;(2)FilterCrd_2,具有500个唯一查询,旨在验证模型能否扩展到2个以上连接;(3)DistinctCrd_1,具有4 500个唯一查询,用于验证模型估计唯一率的基础能力;(4)DistinctCrd_2,具有500个唯一查询,旨在验证模型能否扩展到2个以上连接。表1显示了不同工作负载中连接数量的分布。以下将该文用于联邦复杂查询的基数估计模型(Cardinality Estimation of Federated Complex Queries,CEFCQ)记为CEFCQ,同时实验将CostFed[23]和CEFQR[24]作为对比基线。

表1 4种工作负载的连接分布
3.2 估计质量
在两个查询工作负载FilterCrd_1和DistinctCrd_1上验证CEFCQ模型的基础估计能力,图4展示了实验结果,其中盒须图中方框边界位于第25/75百分位,水平“胡须”线标记为中位数位置。总体而言,CEFCQ的两个方法都优于CostFed和CEFQR,并且CEFCQ表现得更稳健,同时具有更低的尾部误差。首先,相较于CEFQR,CEFCQ的提升虽然不是很明显,但其在扩展了查询类型的基础上仍能表现出优于CEFQR的估计质量,说明了CEFCQ的实用价值;其次,CEFQR能提供较CostFed更精确的估计,这是由于CEFQR不依赖于从SPARQL端点收集的统计信息,使用监督学习模型能更准确地估计连接基数;另外,随着连接数量的增加,模型的估计质量在下降,这是因为估计多连接(连接数大于0)查询时,基数值是累加的,可见CEFCQ对0个连接的查询估计质量最优。
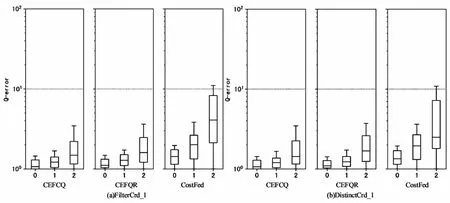
图4 模型在不同工作负载上的估计误差盒须图
为了提供更多详细信息,在表2和表3中分别显示了三个模型在以上工作负载上中位数、百分位数、最大Q-error和平均Q-error。结果表明CEFCQ在各项指标上均表现优秀。

表2 各模型在工作负载FilterCrd_1上的估计误差

表3 各模型在工作负载DistinctCrd_1上的估计误差
3.3 扩展到更多连接
实验的目标是验证CEFCQ是否能够推广到连接数比训练时多的查询。因此,使用查询工作负载FilterCrd_2和DistinctCrd_2(见表1)来验证CEFCQ模型中两个方法的泛化能力。值得注意的是,在实验过程只使用具有0到2个连接的查询来训练CEFCQ。图5的实验结果表明:整体来看,当连接数量大于训练时的最大连接数2时,CEFCQ中两个方法的估计质量都有所下降,但是对比CostFed,本模型仍然具有更好的可扩展性。
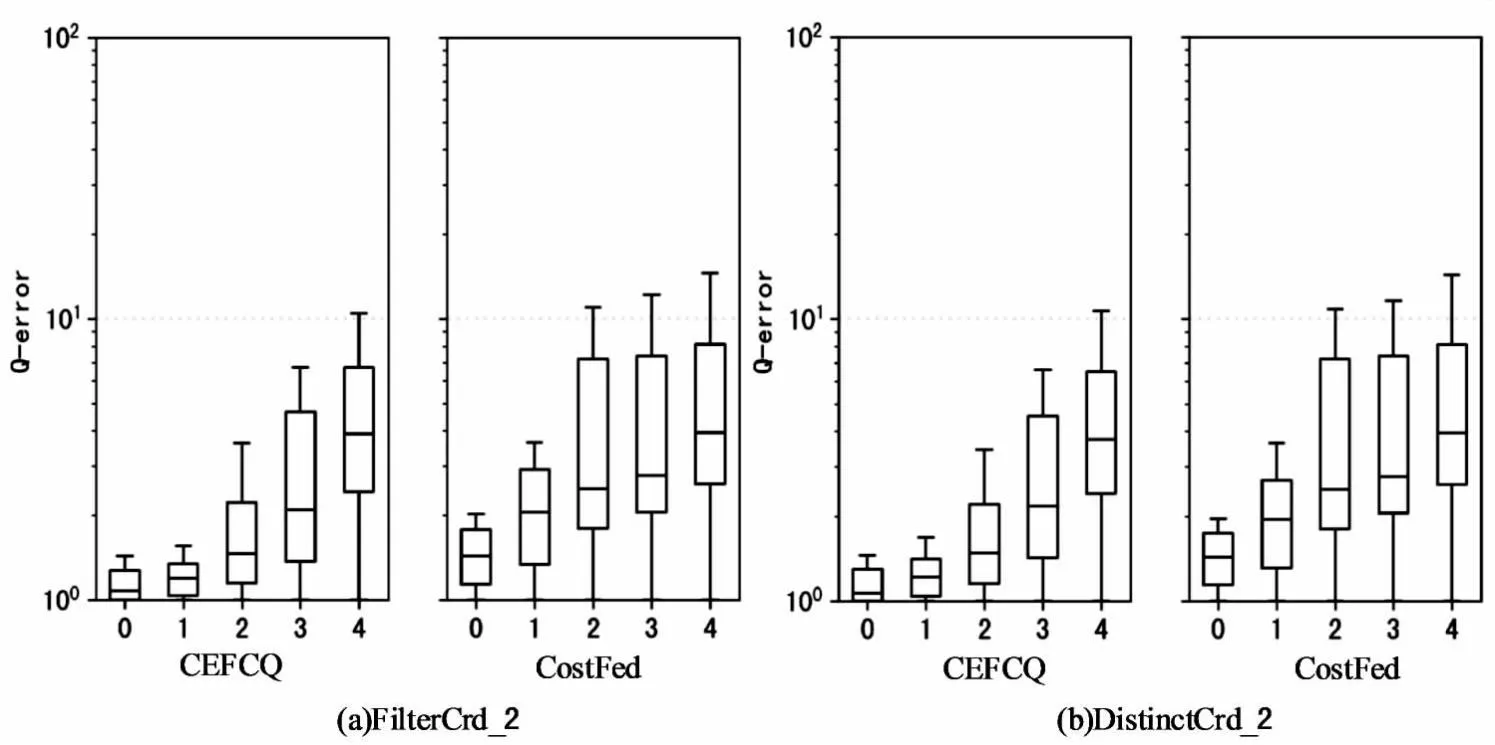
图5 各模型在不同工作负载上的估计误差(展示CEFCQ如何泛化到具有更多连接的查询)
首先,在FilterCrd_2上验证模型中FILTER特征化方法的扩展性,当连接数大于2时,由于CEFCQ需要学习更多术语和图模式之间的相关性,从而降低了估计精度。连接数从2到3时,第95百分位的Q-error从5.7增加到9.8,对比CostFed在相同查询上,第95百分位的Q-error为94.3。当连接数为4,第95个百分位数Q-error进一步增加到了17.21(CostFed:560.3)。
其次,在DistinctCrd_2上验证CEFCQ学习唯一率的泛化能力,当连接数大于2时,CEFCQ容易受到异常值的影响,虽然在训练模型时对数据进行了归一化和缩放,但偏度的影响仍然存在。连接数从2到3时,第95百分位的Q-error从7.7增加到15.42(CostFed:133.2)。当连接数为4,第95个百分位数Q-error增加到28.34(CostFed:631.8)。作为参考,DistinctCrd_2中的500个查询中有48个,超过了训练期间的最大唯一率。其中32个查询有3个连接,另有16个查询有4个连接。剔除这些异常值后,连接数为3和4的查询上,第95个百分位数的Q-error分别降至10.2和24.5。
为了提供更多的细节,表4给出了CEFCQ和CostFed在两个工作负载上Q-error的中位数、最大值和平均值。可以看到CEFCQ在各个指标上均优于CostFed。

表4 各模型在工作负载FilterCrd_2和DistinctCrd_2上的估计误差
3.4 超参数和模型成本
为了优化CEFCQ的性能,搜索了超参数空间,考虑了不同的设置,其中改变了批次大小的数量(16,32,64,…,2 048)、隐藏层大小(16,32,64,…,1 024)和学习率(0.001,0.01)。检查了所有得到的112个不同的超参数组合。结果表明,隐藏层的大小对CEFCQ在验证测试中的准确性影响最大。在达到最佳结果之前,隐藏层的大小越大,CEFCQ在验证测试中就越准确。之后,由于过度拟合,质量下降。此外,学习率和批次大小主要影响训练的收敛行为,而不是模型精度。在验证集上平均运行5次,最佳配置是:批次大小为128、隐藏层大小512和0.001的学习率。因此,在文中模型评估中使用这些设置。在此设置下,CEFCQ在训练集上运行大约200次后,在验证集上收敛到大约3.7的平均Q-error(见图6)。平均运行5次,200个轮次(epochs)的训练阶段大约耗时48分钟。

图6 平均Q-error的收敛
4 结束语
该文提出了一种基于查询特征表示学习的联邦复杂查询基数估计模型方法。具体来说,主要考虑两类复杂查询,即FILTER条件筛选查询和DISTINCT查询。把估计这类查询基数的问题看做一个监督学习任务,提出一种在联邦查询中的监督学习模型。对于FILTER查询,提出一种FILTER特征化的技术,目的是将编码得到的特征向量作为模型的输入。在估计DISTINCT类查询时,模型输出估计的唯一率。对于这两种方法,进行了大量实验。实验结果表明,相较于之前的工作,该模型在基础估计能力和泛化能力上都得到了很大提升。结合现有工作的不足,未来研究将集中在两个方向。首先,扩展该模型以支持更多查询类型,例如带有Top-k,GROUP BY,OPTIONAL等操作符的查询。其次,由于该模型在估计结果时是基于RDF数据集是静态的假设下,但真实的RDF数据集是不定时更新的,因此当原始数据集发生变化时模型只能使用新的查询训练集重新训练,这会极大地增加计算成本。因此,下一步计划优化模型以支持数据集的增量更新。
猜你喜欢
四川师范大学学报(自然科学版)(2023年1期)2023-03-12 07:23:28
四川劳动保障(2021年9期)2022-01-18 05:10:58
——论胡好对逻辑谓词的误读
现代哲学(2020年5期)2020-11-30 17:00:36
计算机集成制造系统(2020年8期)2020-09-11 02:49:36
西夏研究(2020年2期)2020-06-01 05:19:12
无锡职业技术学院学报(2019年4期)2019-12-27 08:48:51
小学生必读(中年级版)(2018年6期)2018-09-05 03:10:20
西夏学(2018年2期)2018-05-15 11:24:42
小学生学习指导(低年级)(2017年9期)2017-08-07 02:12:34
外语学刊(2016年4期)2016-01-23 02:33:55
