
基于在线品牌社区意见领袖的用户关键需求挖掘
2024-02-21 04:36刘春华
计算机技术与发展 2024年2期
申 彦,刘春华
(1.江苏大学 信息管理与信息系统系,江苏 镇江 212013;2.江苏大学 计算机科学与通信工程学院,江苏 镇江 212013)
0 引 言
随着社会的快速发展与技术的不断进步,产品迭代更新周期越来越短,用户需求也在快速发生变化。企业要想在不断变化的市场中占据优势,就必须深刻理解和把握用户的需求,并将其作为产品改进和提升的依据,快速响应动态变化的用户需求。
互联网时代的到来,催生了大量的社交平台。为了聚焦品牌,维护客户关系管理,企业纷纷创建了自身品牌专属的社交平台即在线品牌社区。从在线品牌社区中的海量用户及其评论信息中快速捕获用户关键需求成为了企业新的挑战与机遇。
KANO模型是根据马斯洛需求层次理论,研究需求与满意度的经典模型,然而其需求挖掘过程融入了过多调查人员的主观性[1-2]。在线品牌社区中的海量评论是用户关切的重要表达,已成为用户关键需求获取的重要渠道,弥补了KANO模型主观性强的不足。因此,该文从“双关键性”即用户的关键性和需求的关键性双角度出发,提出了一种基于在线品牌社区意见领袖的用户关键需求挖掘方法(Users’ Key Demands Mining Based on the Opinion Leaders in Online Band Community),简称KEY-DEMANDS-OL,快速捕获用户关键需求,其主要贡献如下:
(1)克服KANO模型主观性较强的不足,利用客观评论大数据获取用户需求。
(2)构建了在线品牌社区意见领袖识别指标体系,通过意见领袖评论大数据获取用户关键需求。
(3)在贝叶斯情感极性分类时考虑了程度副词的语义,进一步精确了用户评论情感极性的分类。
1 相关研究工作
现有用户需求挖掘方法可依据是否考虑了需求类别划分为两类[3]。
未考虑需求类别的用户需求挖掘方法一般会将关注度高、情感程度低的产品特征直接作为用户需求。李贺等[4]对在线手机评论进行评论主题及产品特征挖掘,有效识别了用户需求要素。吴东胜等[5]结合观点值和关注值构建了产品的需求挖掘模型。纪雪等[6]则根据产品属性的平均满意程度来辅助确定新产品的开发需求。邓昭等[7]依据关键词的权重排序来辅助汽车仪表盘的设计。此外,张国方等[8]使用BERT模型对汽车之家在线口碑进行了情感分析,挖掘出了用户的需求。
考虑了需求类别的用户需求挖掘方法是将各产品特征的情感值与KANO模型中的各需求类型进行匹配,分类别挖掘用户需求。白涛等[9]提出了一种利用模糊KANO模型来进行用户需求分类和重要性统计的方法,并验证了方法有效性。Wu等[10]利用改进的模糊KANO问卷对用户需求进行了优先级排序。胡东方等[11]提出了基于KANO的工程特征映射模型和基于人工免疫系统的产品设计模型,设计满足顾客需求的产品方案。徐海丽等[12]利用文本挖掘,建立属性情感值与KANO模型的联系,获得用户的需求类别。Shwetank等[13]将KANO模型和QFD方法整合,对用户需求进行了分类。
通过梳理可发现,大多数研究仍采用的是主观性较强的KANO问卷,亟需研究出一种能够自动整合用户生成内容和KANO模型进行需求分类的高效用户需求挖掘方法,为企业提供决策支持。
2 KEY-DEMANDS-OL的具体步骤
在数据源方面,KEY-DEMANDS-OL没有使用主观性较强的KANO问卷,而选择了在线品牌社区的海量用户评论;在初始改进率方面,KEY-DEMANDS-OL在考虑情感极性的同时,增加了情感程度,丰富了需求分类语义,具体步骤如下所示。
2.1 在线品牌社区意见领袖的识别
2.1.1 识别指标体系构建
借鉴原欣伟等[14]、Li Y Y等[15]、祝琳琳等[16]的研究,经过对当前在线品牌社区特征的分析,从用户的行为特征和内容特征两个角度,KEY-DEMANDS-OL最终确立了5项一级指标和14项二级指标,具体如表1所示。

表1 意见领袖识别指标
2.1.2 意见领袖识别方法
(1)基于熵权法的指标权重确定。
假设被评价对象如用户共M个,其中每个被评价对象的评价指标共有N个,则指标数据集可以用矩阵L表示,其中L=(L1,L2,…,Lm,…,LM),每个被评价对象可以表示为Lm=(lm1,lm2,…,lmn,…,lmN)。其中m=1,2,…,M,n=1,2,…,N。
(a)对数据进行标准化处理,如式1。
(1)

(b)分别对各指标下各个被评价主体指标值的占比pmn进行计算,如式2所示。
(2)
利用式3和式4计算第n个指标的熵值Hn。p表示指标的信息熵系数。
(3)
(4)
(c)计算得出第n个指标的熵权值,如式5。
(5)
其中,ω(n)表示第n个指标的权重系数。n个指标的权重满足式6。
(6)
(2)基于灰色关联分析的意见领袖影响力计算。
设X0表示意见领袖代表的理想指标序列,为参考序列,Xi表示用户的实际指标数列:
(a)对参考序列X0和比较序列Xi进行确定。设原始数据集合X如式7所示。
(7)
其中,m为用户总数,n为指标总数。参考序列为X0=(X01,X02,…,X0j,…,X0n),比较序列为Xi=(Xi1,Xi2,…,Xij,…,Xin),i=1,2,…,m;j=1,2,…,n。
(b)原始数据集进行无量纲标准化处理,如式1所示。得到的标准化后的数据集合X'如式8所示。
(8)
(c)根据标准化后的指标集合和参考序列X0进行绝对差值计算,如式9所示。
(9)
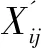
(d)对灰色关联系数进行计算,如式10所示。
(10)
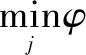
(e)计算各个指标的加权灰色关联度。用到灰色关联度将分散的灰色关联系数ξij综合到一个数值上以便比较。具体计算如式11所示。
(11)
(12)
其中,ω(j)表示第j个指标的权重,指标的权重和满足式12。
根据熵权法和灰色关联分析法计算每个用户的灰色关联度,确定用户影响力,识别出意见领袖。
2.2 用户关键需求挖掘
2.2.1 用户需求特征提取
评论中词语的词性和词语的频率决定了该词能否成为关键词。此外,名词和动词更能表达句子的核心含义,应作为核心关键词;副词表示程度,可用于情感程度的计算。因此,词频统计以及词性识别是根据用户评论挖掘用户需求的关键。
在识别在线品牌社区意见领袖的基础上,对其发表的评论进行词频的统计与词性的识别。保留其中的名词n、动词v以及副词adv并且统计其词频,代表该评论的核心关键,作为意见领袖代表的需求特征。经过处理的意见领袖的评论输入情感分析模块,进行基于贝叶斯的需求满足度计算。
2.2.2 基于贝叶斯的需求满足度计算
用户的评论实际上反映了用户对产品需求的满足程度,因此,用户的实际需求可以通过对用户评论的分析来挖掘,用户的需求满足度也可通过对评论的情感极性判断和情感程度的计算获得。详细计算过程如下:
(1)基于贝叶斯的需求极性计算。
采用贝叶斯模型判断极性,具体的计算方法如下:
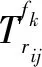
根据全概率公式进一步化简上式可得:
(13)
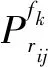
(2)情感程度计算。
采用哈工大的情感程度词表,依据副词表达的情感强烈程度,将情感程度划分成5个等级,详细内容如表2所示。在对意见领袖评论的情感程度进行计算时,依据其需求特征提取时保留的副词所对应的程度等级对满足度进行加权,详细计算过程如式14所示。

表2 情感程度量化
(14)

(15)
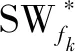
2.2.3 需求分类
KANO模型将需求分为了期望型、魅力型、基本型、无关型和反向型五类。当前在实际的生产运营过程中通常只考虑用户的期望型需求、魅力型需求、基本型需求和无关型需求四种[19-20]。
所提KEY-DEMANDS-OL方法在传统用户需求分类挖掘方法的基础上进行了改进,没有利用主观设计的调查问卷,而是利用在线品牌社区中海量的用户评论数据,识别代表性用户即意见领袖,利用算法自动整合意见领袖的评论和KANO模型。此外,修正了用户需求的初始改进率,增加考虑了情感程度,对用户关键需求进行自动化的分类挖掘,详细的计算过程如下:
(16)
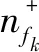
(17)

(18)
(19)
(20)
(21)
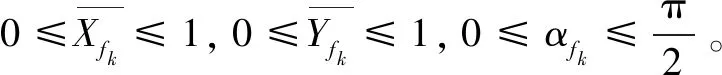
(22)
最后,计算用户需求特征fk的重要性Ifk,详细的计算公式如下:
(23)
至此,可按计算所得的用户需求特征的重要性排序Ifk获得用户关键需求。
3 实验与结果分析
3.1 实验数据的获取与预处理
采用八爪鱼对华为在线品牌社区——花粉俱乐部中的华为Mate40板块进行数据采集。经过去除无效信息、去除重复信息等预处理后,最终得到包含1 000个用户的22 572条评论与讨论信息。KEY-DEMANDS-OL算法采用Python实现。
3.2 KEY-DEMANDS-OL结果分析
3.2.1 意见领袖识别结果
指标权重系数、关联系数和意见领袖识别结果如表3~表5所示。实验中,参考文献[19-20],并依据帕累托法则,将影响力排名前20%的用户作为意见领袖。

表3 指标权重系数
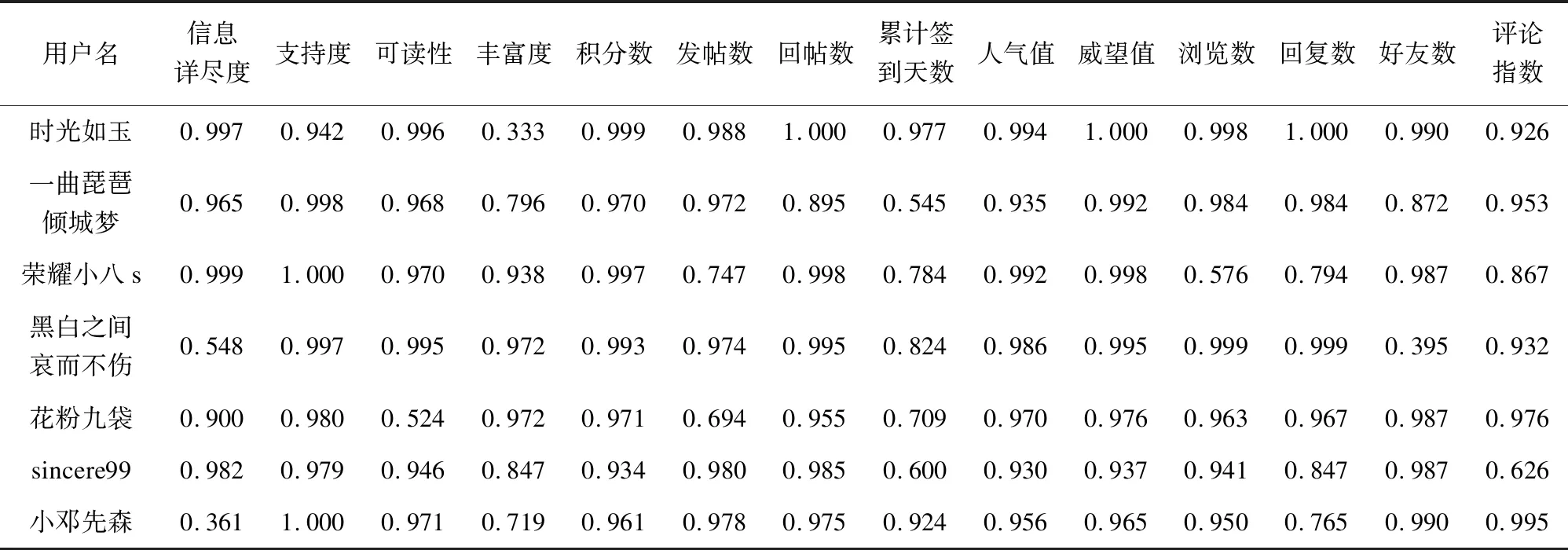
表4 指标相关系数

表5 意见领袖识别结果(Top10)
3.2.2 用户关键需求分析
该步骤的数据来自于意见领袖的评论和讨论信息。经过词频统计、词性分析与词语相似度检验,结合在线品牌社区评论组织结构及分类得到的用户需求特征如表6所示。
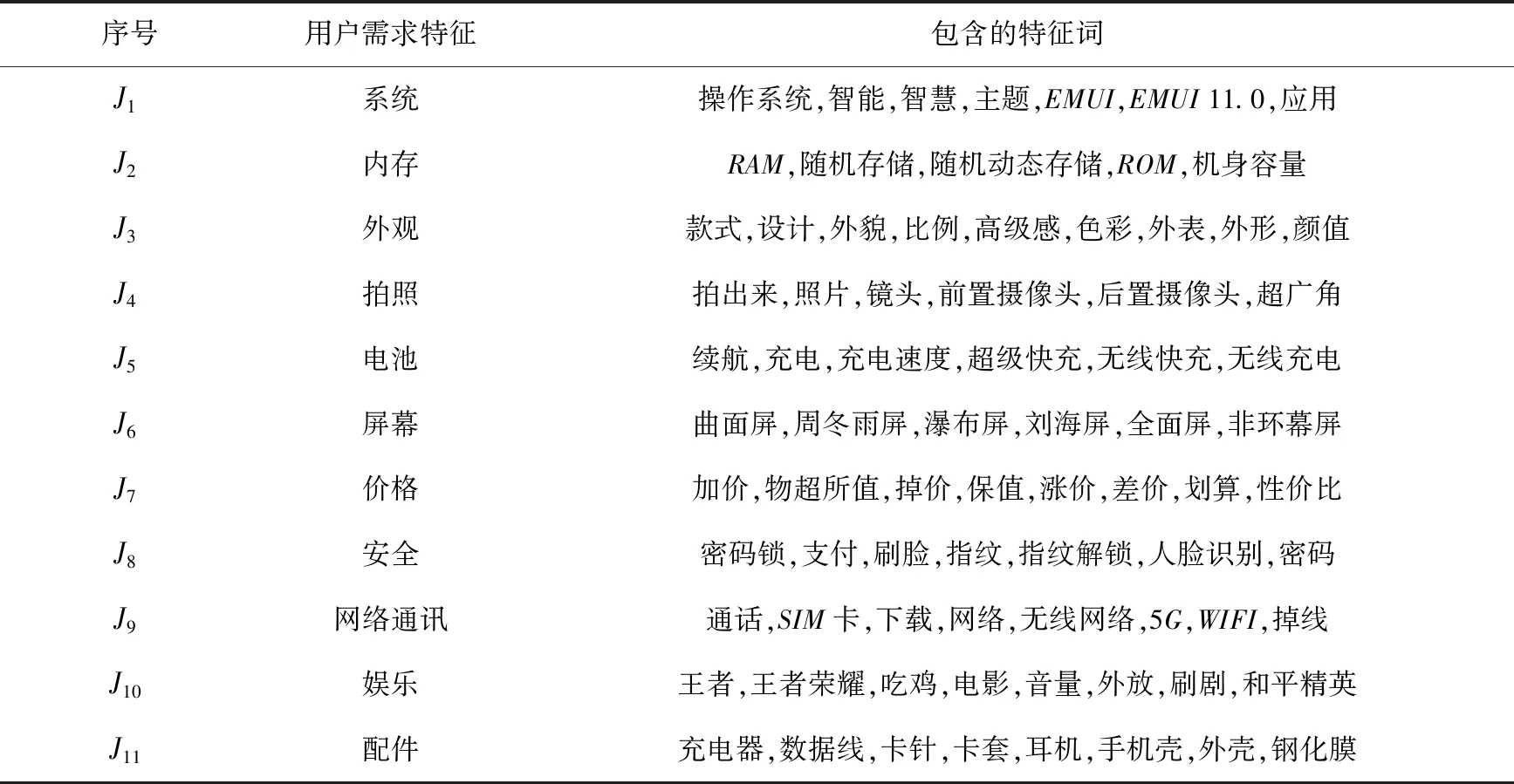
表6 用户需求特征
通过对情感极性以及基于贝叶斯的需求满足程度的计算,结合KANO模型确定的用户需求类别和重要性排列顺序如图1和表7所示。

图1 关键需求分类结果
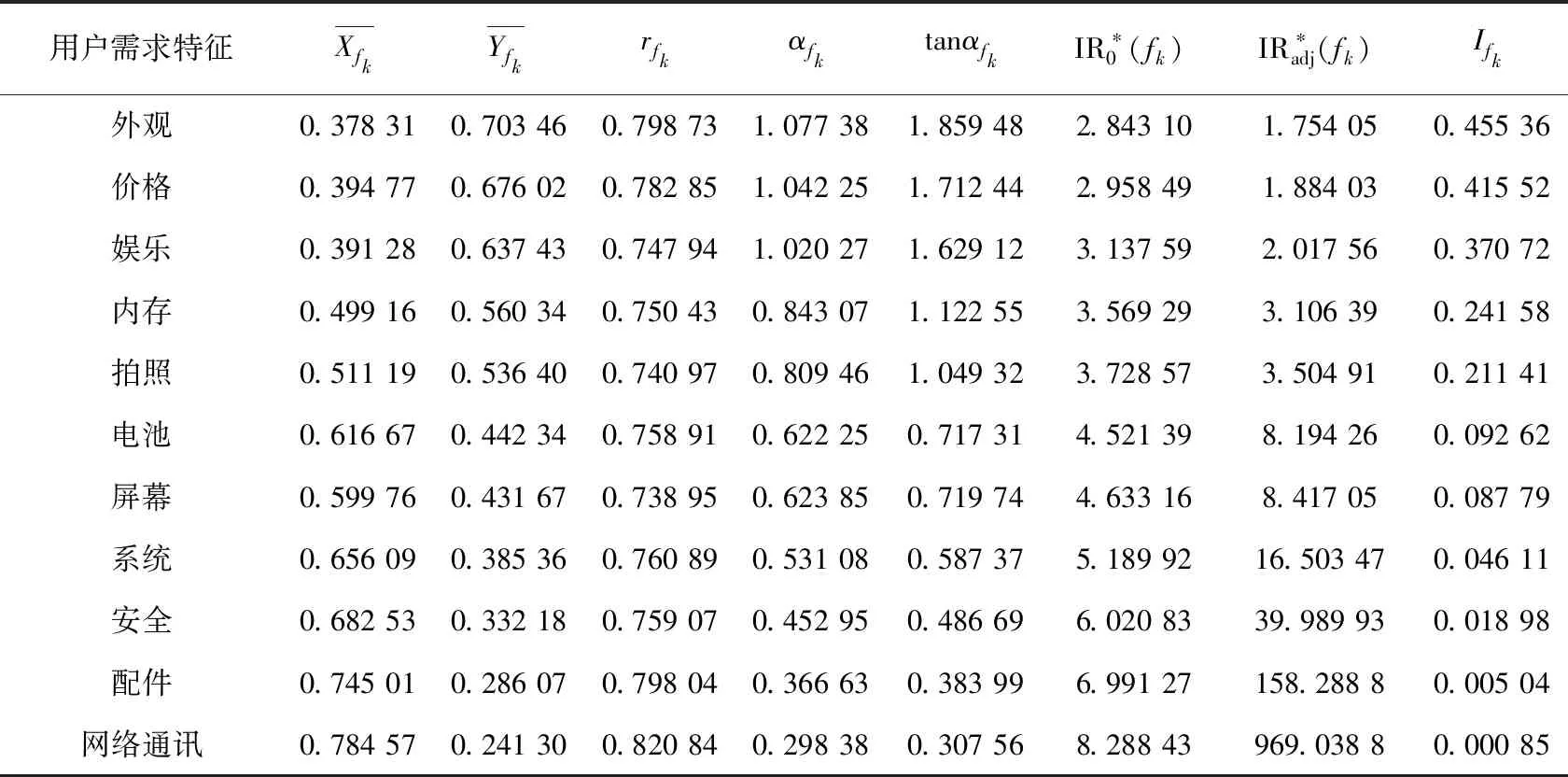
表7 用户关键需求排序结果
从表7可以看出,分析得到的需求排序结果为:“外观”“价格”“娱乐”“内存”“拍照”“电池”“屏幕”“系统”“安全”“配件”“网络通讯”。结合KANO模型,从图1可知,在11个用户需求项中,魅力型需求一共有3个,包括“外观”“价格”“娱乐”;期望型需求2个,包括“拍照”以及“内存”;基本型需求一共有6个,依次为“电池”“屏幕”“系统”“安全”“配件”和“网络通讯”。根据表7中的用户需求重要性排序及KANO模型可知,在进行产品改进时的先后顺序依次应为:“电池”“屏幕”“系统”“安全”“配件”“网络通讯”“拍照” “内存”“外观”“价格”“娱乐”。
KEY-DEMANDS-OL捕获的用户关键需求对企业优化产品具有重要的启示与指导。华为在推出Mate40时,提出了该款手机具有六大优势即非凡性能、非凡设计、非凡影像、非凡快充、非凡体验和非凡安全。针对此产品的基于在线品牌社区意见领袖的用户关键需求挖掘结果的启示及建议如下。
(1)魅力型需求包含了“外观”“价格”和“娱乐”。这说明用户对该款手机在这些方面的表现感到非常满意,符合Mate40手机预设。魅力型需求是进一步吸引用户,提升用户满意度和忠诚度的关键,企业在资源允许的条件下,应全力满足用户的魅力型需求,提高品牌竞争力。
(2)用户的期望型需求包含了“拍照”和“内存”。这说明了“拍照”尽管是该款手机的卖点之一,但很多用户在拍照时对相应的拍摄功能并不了解,没有拍摄出应有的出色效果,造成了很多用户的满意度较低,使得该特征成为了用户的期望型需求。此外,用户期待非凡的体验,需要手机大容量内存的支持,但当前产品内存提供仍显得不足,“内存”亦是期望型需求之一。期望型需求是用户需求的“痒处”,企业下一步急需对“拍照”这一功能加入新手指导模块或者在拍摄过程中给与更多快捷方式的支持。同时,相比竞品,进一步增大手机内存,促进其转化为魅力型需求,提升用户的满意度。
(3)用户的基本型需求包含了“电池”“屏幕”“系统”“安全”“配件”和“网络通讯”。这说明了对于该款手机提出的非凡安全和非凡快充两大亮点所对应的“安全”和“电池”两个特征,并没有让用户满意,成为了基本型需求。其主要原因是该款手机的安全模式虽功能强大,但使用繁琐。电池虽支持快充,性能优异但充电时发热严重。此外,该款手机虽然采用了好看的瀑布屏设计、启用最新的EMUI系统、赠品较多、支持5G信号,但也存在着屏幕绿屏严重、系统更新慢、赠品领取扣费和WIFI信号不稳定的问题,使得“屏幕”“系统”“配件”和“网络通讯”四个特征成为了用户的基本型需求。基本型需求是用户需求的“痛点”,当需求被满足时,用户不会感到满意,但当不被满足时,用户会很不满意。因此,企业在追求极致功能的同时,也要时刻关注用户的基本型需求,针对其不满意点不断进行产品优化和改进,促使其向期望型需求进行转化。
3.3 对比分析
对比KEY-DEMANDS-OL和挖掘所有用户信息的传统方法的运行效率,记录下两种方法从载入数据到分析完成的时间,共10次,计算其平均值。因算法执行的绝对时间受计算机CPU及内存等性能参数影响,不同设备执行时间并不一致,为了更好体现所提方法优势,同时给出了本次实验不同方法运行时间的相对比值以及绝对值,如图2所示。

图2 运行时间对比
为验证基于在线品牌社区意见领袖的用户关键需求挖掘方法(KEY-DEMANDS-OL)的有效性,与挖掘所有用户评论信息的传统方法进行了对比分析,如表8所示。
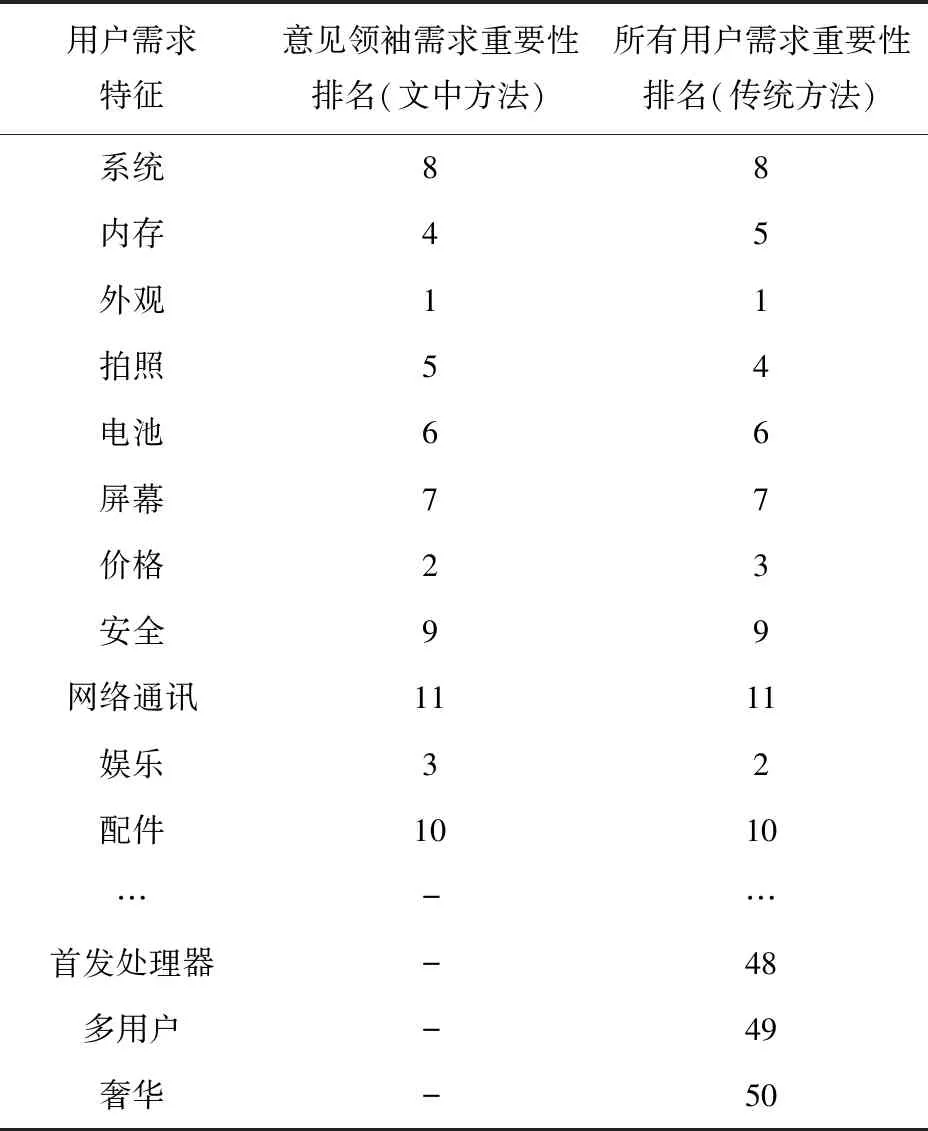
表8 与传统方法的对比分析
从表8中可以看出,在基于所有用户评论挖掘的用户需求重要性排名中,仅有“内存”“拍照”“娱乐”和“价格”4个需求与基于意见领袖挖掘的用户需求重要性排序有所差异,但相差不超过1。而其余7个需求的重要性排名与基于意见领袖挖掘的需求重要性排名相同。实例分析的结果再次验证了帕累托法则,即约20%的意见领袖代表了约80%的用户关键需求,可通过意见领袖的识别,捕获用户关键需求。更为重要的是,KEY-DEMANDS-OL方法在进行需求挖掘时所需处理的数据量大幅降低,提高了用户需求挖掘的时效性,且可以帮助企业从纷繁复杂,无代表性的海量用户需求中解脱出来,通过意见领袖的代表性,聚焦用户的关键需求,以精准优化产品。例如,在挖掘所有用户评论获取的前50大需求中,有诸如“首发处理器”“多用户”“奢华”等长尾小众需求。当然,小众需求并不是不重要,而是主流关键需求须首先满足。在这个前提之下,再在后续产品或者特色产品中考虑小众需求。而KEY-DEMANDS-OL方法仅挖掘获取意见领袖代表的主流关键需求,是当下产品要尽快解决的问题以及须改进的地方,因此能更加聚焦,快速发现用户关键需求。
由实验结果可知,KEY-DEMANDS-OL方法仅需分析约20%的意见领袖的信息,便可发现当下用户的主流需求,大幅提高了用户关键需求挖掘的执行效率,更加适合在当前产品迭代更新飞快、用户需求多变的情况下对用户关键需求进行快速追踪。
4 结束语
从意见领袖和用户关键需求着手,采用熵权法和灰色关联分析法对意见领袖进行了识别,进而采用文本挖掘、情感分析以及KANO模型对用户需求进行分类和排序,挖掘出代表性用户的关键需求。针对实际案例对提出的方法进行了验证,表明了所提KEY-DEMANDS-OL方法的实用性与有效性。该文为相关研究提供了一个用户关键需求快速挖掘的方法,对产品的研发与改进提供了重要的定量参考与决策支持。此外,随着在线品牌社区的更迭,在KEY-DEMANDS-OL方法的后续使用中,主体框架可保持不变,意见领袖识别指标体系可以进行调整,以适应不同的业务领域。诚然,KEY-DEMANDS-OL方法取得了一定的进展,但仍存不足,如在进行海量用户评论处理时没有很好地利用分布式计算框架,评论处理效率有待进一步提升。此外,在进行评论分析时上下文关联语义考虑不足。笔者将在后续研究中持续关注,力求有新突破。
猜你喜欢
黄河之声(2022年6期)2022-08-26
中老年保健(2022年1期)2022-08-17
音乐教育与创作(2022年4期)2022-04-26
中学生数理化(高中版.高考理化)(2021年6期)2021-07-28
学苑创造·A版(2019年9期)2019-11-07
意林·全彩Color(2019年7期)2019-08-13
学苑创造·A版(2019年2期)2019-02-19
中学生英语(2016年13期)2016-12-01
艺海(剧本创作)(2015年1期)2015-12-19
中国商人(2013年1期)2013-12-04
