
汉字识别中图特征提取方法
2024-02-20 01:25唐善成梁少君戴风华来坤曹瑶倩
科学技术与工程 2024年2期
唐善成, 梁少君*, 戴风华, 来坤, 曹瑶倩
(1.西安科技大学通信与信息工程学院, 西安 710054; 2.中交第二公路工程局有限公司, 西安 710065)
光学字符识别(optical character recognition, OCR)是计算机视觉领域的重要任务[1-2],其中汉字识别是一个极具挑战性的子任务, 主要原因为中文汉字字符级别类别繁多、存在很多相似字和易混淆的汉字对、部分汉字笔画结构复杂[3-4]。
随着深度学习技术的快速发展,许多学者开展了基于深度学习的汉字识别研究[5-6]。Shi等[7]将文字识别任务视为序列识别任务,并提出了一个可端到端训练的卷积循环神经网络模型(convolutional recurrent neural network, CRNN),CRNN 可以直接从序列标签学习, 不需要详细的标注, 具有循环神经网络(recurrent neural networks, RNN)相同的性质, 模型容易训练, 易收敛,有效改善了文字识别算法的性能;Zhang等[8]提出了自适应文字识别模型,通过视觉匹配技术提高了模型泛化性能;Yue等[9]提出了RobustScanner模型,通过增加位置增强分支改善了模型在无语义数据集上的识别性能;Fang等[10]提出了自治、双向和迭代的文字识别模型(autonomous, bidirectional and iterative language modeling for scene text recognition, ABINet),通过融合视觉模型与语言模型降低了噪声对模型的负面影响;Zhu等[11]、Wang等[12]、Sheng等[13]、Yu等[14]应用 Transformer[15](注意力机制变体)优化注意力机制的并行处理,降低算法的计算复杂度。Yan等[16]提出原始表示学习网络(primitive representation learning network, PREN),将特征图中的元素作为无向图中的节点,利用图卷积神经网络(graph convolutional network, GCN)得到更高级的特征以提升识别准确率[17]。这些方法较有效提升了识别准确率,但主要基于图像像素点提取汉字特征向量,并没有提取到汉字更本质的特征,识别准确率还有提升空间。
汉字关键点是由构成笔画的端点、拐点、叉点等组成的关键点集,汉字图特征基于关键点集及其图结构表示汉字形状特征和整体分布情况。现提出一种汉字图特征提取算法,首先对汉字图像二值化,然后提取图像骨架,最后提取汉字图特征。相较于图像像素特征,通过图特征表征汉字可以提取更本质更稳定的特征,降低空间复杂度。
1 汉字图特征提取方法
汉字图特征提取过程如图1所示,主要包含汉字图像二值化、汉字图像骨架提取、汉字图特征提取3个部分。
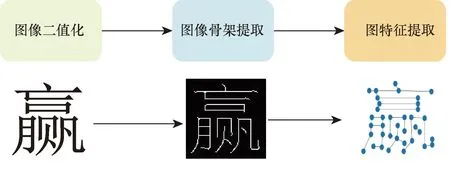
图1 汉字图特征提取过程Fig.1 Chinese character map feature extraction process
(1)汉字图像二值化:消除汉字图像中的噪声,提高图特征提取的准确度。
(2)汉字图像骨架提取:保留汉字图像中重要的像素点,剔除无关的像素点,便于汉字图特征提取。在提取过程中,既需要保证原始汉字笔画的连续性还需要保留原始汉字的几何特征及拓扑结构。
(3)汉字图特征提取:首先提取汉字关键点,然后引入图数据结构,利用图数据结构存储汉字关键点及位置、笔画的特征信息。图数据结构中度的性质可以有效解决汉字中笔画拐点处的歧义问题。
1.1 汉字图像二值化
假设I(x,y)为原始汉字图像,g(x,y)为二值化汉字图像,TH为图像二值化分割阈值,将每个像素划分为两个类别,记为C1与C2,则汉字图像二值化变换函数可表示为
(1)
本文分割阈值采用最大类间方差法(Otsu’s method, OTSU)算法计算。OTSU算法假设存在阈值TH将汉字图像I(x,y)所有像素分为两类C1(≤TH)和C2(>TH),每个像素被分到两个类别的均值记为μ1、μ2,分割后的图像全局均值μ可表示为
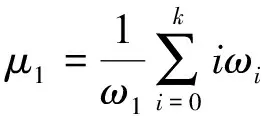
(2)
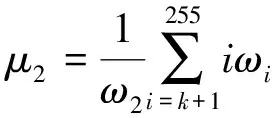
(3)
μ=μ1ω1+μ2ω2
(4)
式中:ωi为图像中像素灰度为i的概率;ω1、ω2为原始汉字图像中像素被分到C1和C2类的概率,其计算过程为
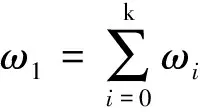
(5)
(6)
ω1+ω2=1
(7)
类间方差σ2可表示为
σ2=ω1(μ1-μ)2+ω2(μ2-μ)2
(8)
将式(4)代入式(8),得到
σ2=ω1ω2(μ1-μ2)2
(9)
使得式(9)中类间方差σ2最大化的灰度级k就是OTSU阈值TH。按照式(5)和式(6),遍历0~255个灰度级,求出使式(9)最大的k即为最佳阈值。
1.2 汉字图像骨架提取
为了便于描述汉字图像骨架提取算法[18],将汉字图像中笔画像素部分定义为前景,用1表示,将其他像素部分定义为背景,用0表示。假设当前被处理的像素为p1,其8邻域像素位置定义如图2所示。

图2 像素的8邻域像素位置Fig.2 The 8-neighborhood pixel position of the pixel
汉字图像骨架提取过程分为两步。
步骤1循环所有前景像素点,对满足式(10)~式(13)的像素点标记为删除。
(10)
S(pi)=1
(11)
p2p4p6=0
(12)
p4p6p8=0
(13)
式中:N(pi)为与pi相邻的8个像素点中前景像素点的数量;S(pi)为从p2~p9~p2像素中出现0~1的累计次数。
步骤2与步骤1类似,满足式(14)~式(17)的像素点标记为删除。
2≤N(p1)≤6
(14)
S(pi)=1
(15)
p2p4p8=0
(16)
p2p6p8=0
(17)
循环上述两步骤,直到两步中都没有像素被标记为删除为止,输出的结果即为汉字图像骨架。
1.3 汉字图特征提取
根据当前像素pi的八邻域特征来定义关键点。N(pi)表示跟pi相邻的8个像素点中,为前景像素点的数量。M(pi)表示当前pi点8邻域中出现0~1模式的累计次数,其中0~1模式是指在当前点的八邻域中按照一定遍历方向(顺时针或逆时针)从某点开始到该点结束时由0变为1的次数。关键点可以定义为:N(pi)=1,M(pi)=2记为端点;N(pi)=2,M(pi)=4记为拐点;N(pi)=3,M(pi)=6记为歧点;N(pi)=4,M(pi)=8记为四叉点;N(pi)=5,M(pi)=6记为五叉点;N(pi)=6,M(pi)=4记为六叉点;N(pi)=7,M(pi)=2记为七叉点;N(pi)=8,M(pi)=4记为八叉点。
根据以上关键点的定义,汉字关键点提取步骤如下。
步骤1查找汉字图像中所有像素点,标记满足关键点定义的像素点。
步骤20°横向查找。查找每一行像素,当第一次遇到关键点时,将当前关键点用Start标记,表示为图结构中边的开始节点;当再一次遇到关键点时,跳转到步骤4。汉字图像中每行像素点全部查找完时,结束查找。
步骤390°竖向遍历。查找每一列像素,当第一次遇到关键点时,将当前关键点用Start标记,表示为图结构中边的开始节点;当再一次遇到关键点时,跳转到步骤4。汉字图像中每列像素点全部查找完时,结束查找。
步骤4判断当前关键点与开始节点之间是否有前景像素连接,若有连接,则继续判断前景像素数量是否大于笔画长度阈值strokelength,若大于笔画阈值,则将此关键点与开始节点用图结构保存,并将开始节点与当前关键点之间的像素用掩码标记(用0表示),并更新当前关键点为开始节点;若有前景像素连接但不满足阈值或没有前景像素连接,则只更新当前关键点为开始节点,返回继续查找。
步骤545°左竖向遍历。查找每一行像素,当第一次遇到关键点时,将当前关键点用Start标记,表示为图结构中边的开始节点,然后沿着当前关键点的左下方继续查找是否有关键点存在,当前像素更新的优先级为:左下方>正下方>正左方,当再一次遇到关键点时,跳转到步骤7。汉字图像中每行像素点全部查找完时,结束查找。
步骤6135°右竖向遍历。查找每一行像素,当第一次遇到关键点时,将当前关键点用Start标记,表示为图结构中边的开始节点,然后沿着当前关键点的右下方继续查找是否有关键点存在,当前像素更新的优先级为:右下方>正下方>正右方,当再一次遇到关键点时,跳转到步骤7。汉字图像中每行像素点全部查找完时,结束查找。
步骤7判断笔画长度是否大于笔画阈值,若大于,将此关键点与开始节点用图结构保存,并将开始节点与当前节点之间的像素用掩码标记;最后更新当前关键点为开始节点。如小于笔画阈值,则将当前关键点更新为开始节点。当左下方或右下方没有前景像素或到达边界时,返回继续查找。
步骤8用一个 strokelength * strokelength的滑动窗口去判断每一个关键点所在的窗口内是否存在两个或两个以上的关键点,若存在多个关键点,则按照自下向上的合并规则将所有关键点合并为一个。
图3展示了“给”图特征提取过程,从结果中可以看出,当汉字图像中存在倾斜、弯曲笔画时,图像骨架表示会出现阶跃变化,在拐点处容易产生关键点判定歧义问题。如图4所示,汉字中“倾斜笔画”提取过程中所存在的歧义问题,图4(b)和图4(f)中白色圆圈部分为提取的关键点,可以看出,倾斜的笔画会提取多个关键点,中间的两个关键点与“口”字的关键点均被判断为拐点,从而产生歧义。
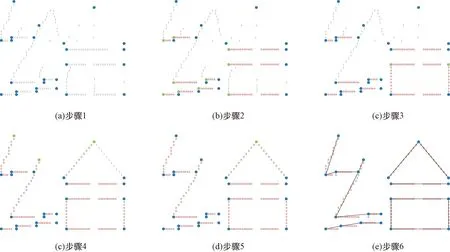
图3 “给”图特征提取过程Fig.3 “给” the graph feature extraction process

图4 倾斜笔画与“口”字关键点提取过程图Fig.4 Slanted strokes and word “口” key point extraction process diagram
针对倾斜笔画拐点处存在的歧义现象,利用余弦公式与节点度特征进行优化。节点的度是指当前节点邻居节点的数量。图5展示了“给”的优化过程,具体可描述为对得到的图特征,循环查找图中所有节点,获取每个节点的度信息,如果当前节点的度为2,则利用两个邻居的边长计算当前节点与其相邻两个节点的夹角余弦值,根据夹角余弦值得出夹角度数,如果夹角度数在[0, 10]与[170, 180]之间,则标记当前节点,如图5(b)中圆圈所标记节点,最终循环完所有图节点后,删除标记节点,将剩余图节点进行连接,并更新边长。
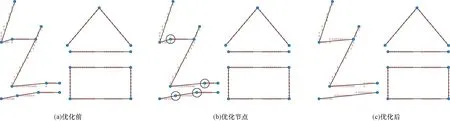
图5 “给”图特征优化过程Fig.5 “给” the graph feature optimization process
2 实验结果与分析
2.1 实验数据集
实验数据集包含5种字体,分别为:方正兰亭(FZLTCXHJW)、黑体(SimHei)、宋体(SimSun)、华文细黑(STXihei)、标准宋体(STSong)。每个字体包含3 908个常用汉字,汉字图像尺寸统一为128像素×98像素。
2.2 汉字图特征提取
汉字图特征提取实验。汉字图特征提取过程如图6所示,每个“赢”提取到的图特征均由37个图节点构成,实验结果表明虽然每个字体的二值图形状不同,但都能提取到相同的图特征。方法能够正确提取笔画复杂汉字的图特征,图7展示方正兰亭字体下的部分汉字图特征提取结果。
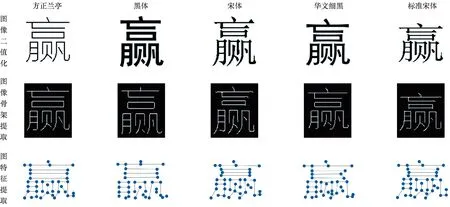
图6 不同字体中“赢”的图特征提取过程Fig.6 Graph feature extraction process of “赢” in different fonts
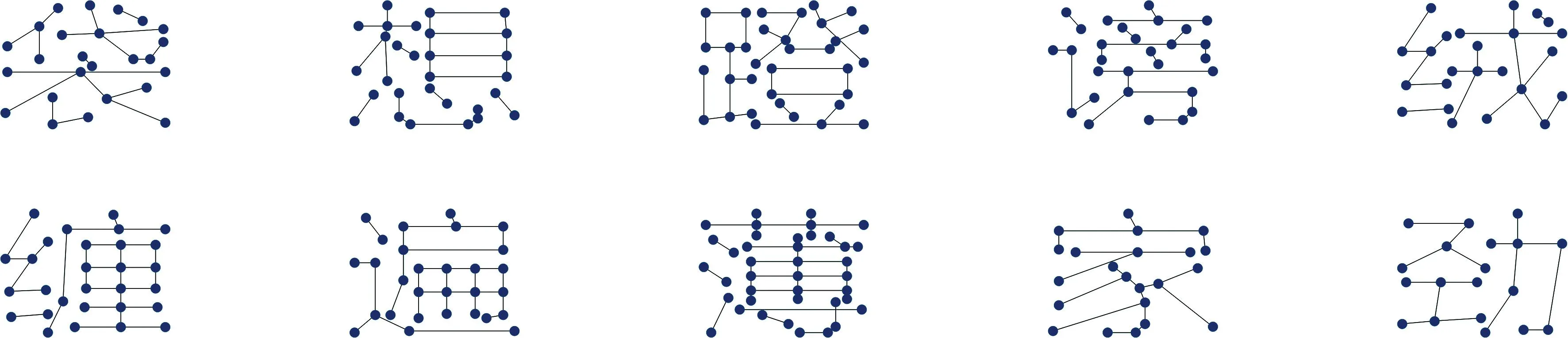
图7 汉字的部分图特征提取结果Fig.7 Partial image feature extraction results of Chinese characters
汉字图特征提取方法稳定性实验。实验中发现一些汉字的不同字体笔画空间位置不同,如图8所示,这会影响汉字图特征中节点以及边提取结果。不同字体汉字图特征相同的情况如表1所示,结果表明在5种字体中汉字图特征相同的数量最低为3 003个,最高为3 195个,最高约占总数的81.7%,汉字图特征提取算法表现较稳定。
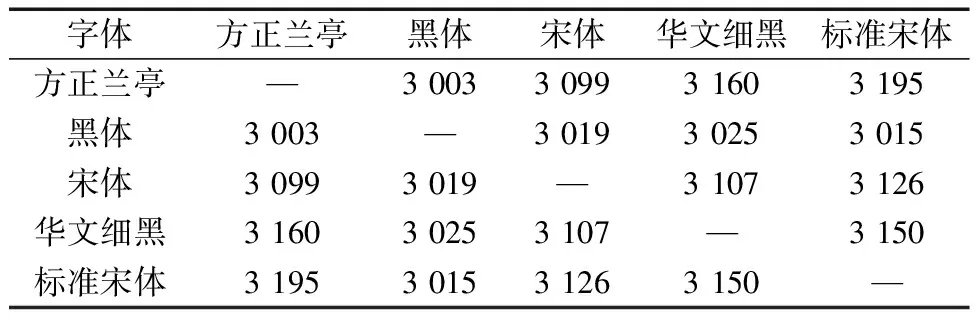
表1 不同字体汉字图特征相同的情况Table 1 Situations where the characteristics of Chinese characters in different fonts are the same
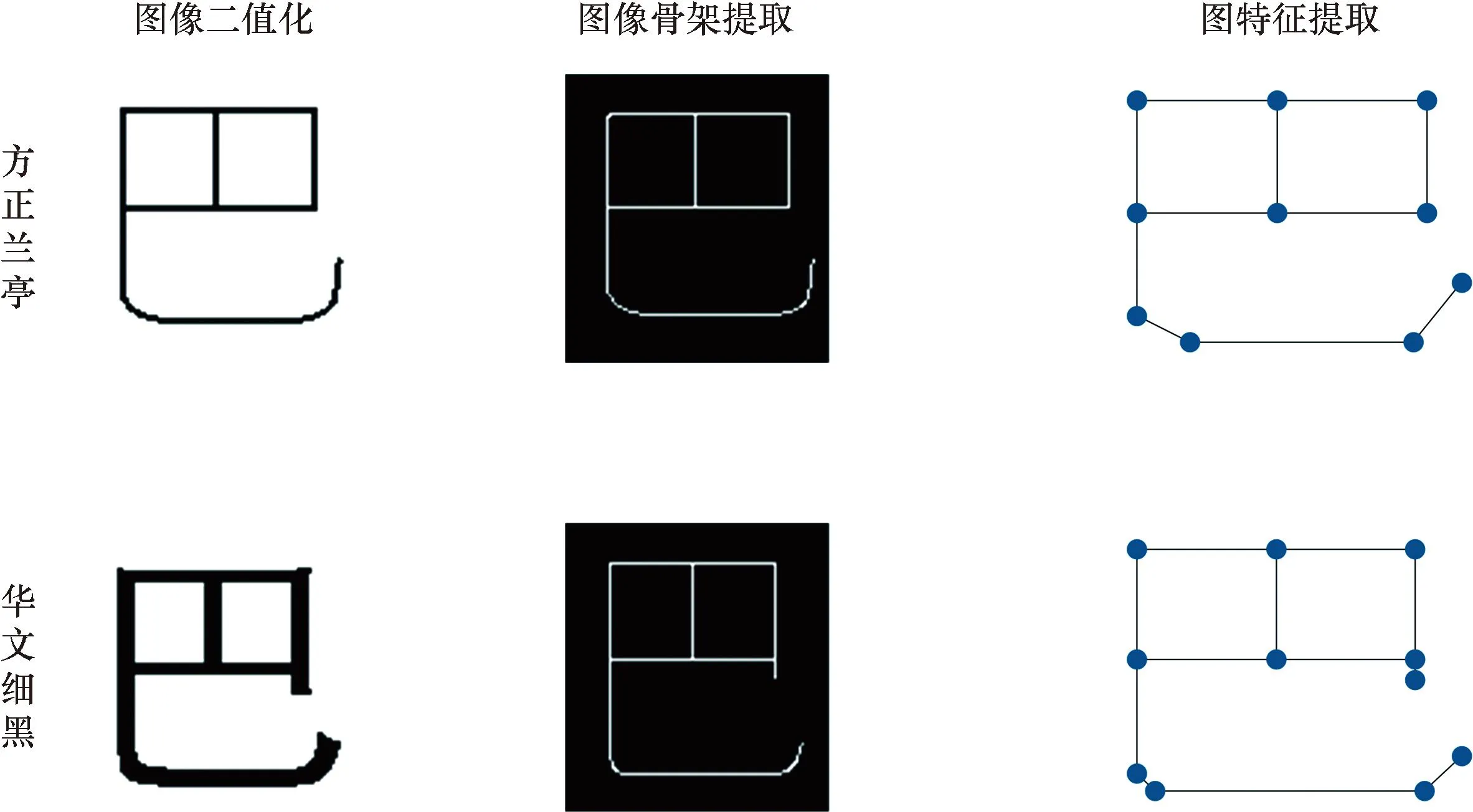
图8 不同字体笔画空间位置示例Fig.8 Examples of stroke space positions in different fonts
汉字图特征优化实验。为了验证图特征提取方法有效解决拐点处关键点判定歧义问题,对五种字体优化前后结果进行对比,优化前与优化后结果对比如图9所示。图9为5种字体的同一个字“弘”的优化前与优化后的图特征结果对比,从结果中可以看出优化前汉字的图特征中存在大量冗余关键点,优化后的图特征更能有效表征汉字信息。不同字体优化前后的图节点数量如表2所示,结果表明通过优化平均每种字体减少5 217个图节点,平均有2 348个汉字被优化。
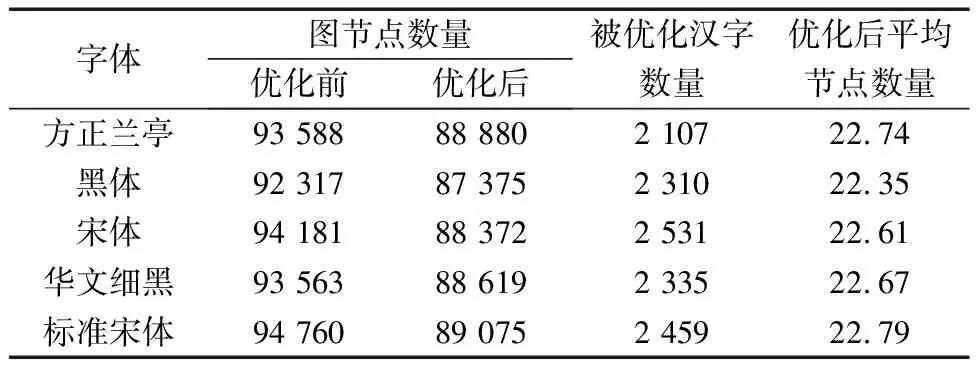
表2 不同字体优化前后的图节点数量Table 2 The number of graph nodes before and after optimization with different fonts
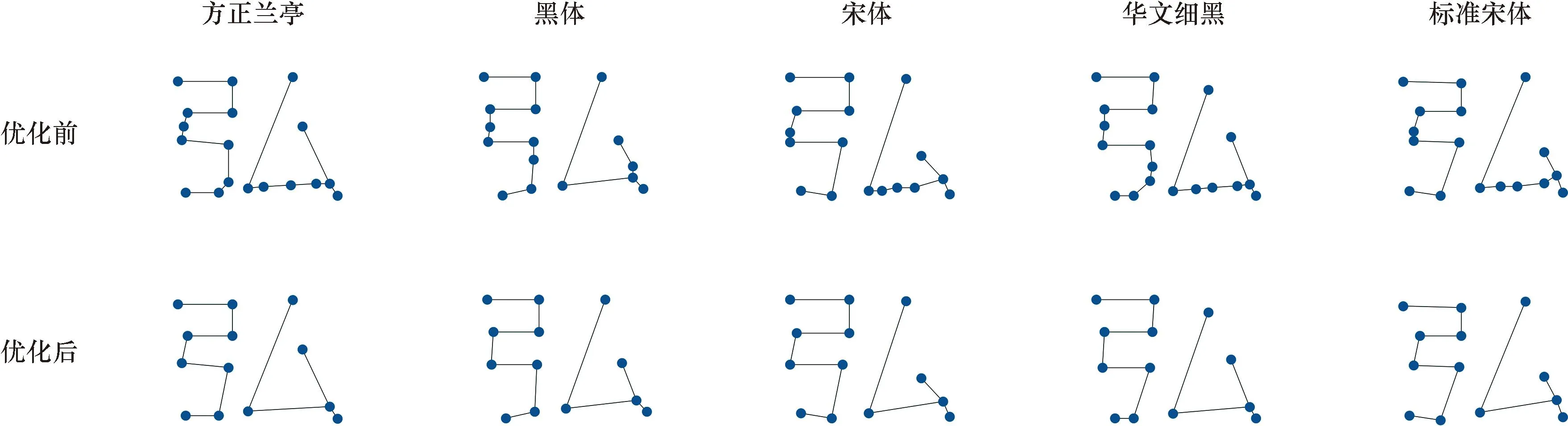
图9 不同字体的“弘”字优化前后结果对比Fig.9 Comparison of the results before and after optimization of the word “弘” in different fonts
汉字图特征空间复杂度实验。为了验证图特征提取方法有效降低汉字特征表示空间复杂度,对5种字体图节点数量与边数量进行统计,如表3所示,结果表明,图节点总数平均为88 464个,边总数平均为74 821个;每个汉字图节点数平均为22.6,边数平均为19.1。汉字图特征用稀疏矩阵表示所占用空间为19字节×3字节,用邻接矩阵表示所占用空间为19字节×19字节;汉字像素特征用单通道图像表示所占用空间为128字节×98字节;用汉字图特征表示汉字可大幅降低空间复杂度。
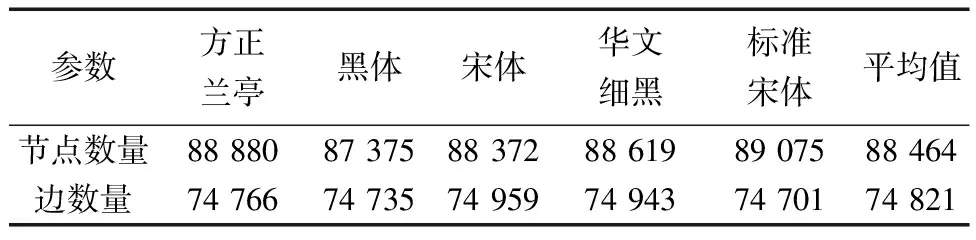
表3 不同字体图节点与边数量Table 3 Number of graph nodes and edges in different fonts
3 结论
现有汉字识别方法主要基于图像像素表示汉字特征,存在不能有效表示汉字本质特征、空间复杂度较高的问题,为了解决此问题提出了一种汉字图特征提取方法。方法主要包含汉字图像二值化、汉字图像骨架提取、汉字图特征提取三个部分,结合汉字关键点与图数据结构表示汉字形状特征。实验结果表明,方法能够正确提取笔画复杂汉字的图特征,有效表示汉字本质特征,在不同字体上表现较稳定,可大幅降低空间复杂度。未来可以在汉字识别研究中检验汉字图特征提取方法的有效性,进一步提升方法稳定性。
猜你喜欢
中学生数理化·中考版(2022年12期)2022-02-16
今日农业(2021年8期)2021-11-28
娃娃乐园·综合智能(2020年2期)2020-03-12
上海大学学报(自然科学版)(2018年5期)2018-11-02
电脑知识与技术(2018年35期)2018-02-27
自动化学报(2017年11期)2017-04-04
中国卫生(2014年2期)2014-11-12
小雪花·成长指南(2014年10期)2014-10-31
语文知识(2014年7期)2014-02-28
移动一族(2009年3期)2009-05-12
