
基于轻量级Transformer 的城市路网提取方法
2024-02-12 07:43:02冯志成杨杰陈智超
浙江大学学报(工学版) 2024年1期
冯志成,杨杰,陈智超
(1.江西理工大学 电气工程与自动化学院,江西 赣州 341000;2.江西省磁悬浮技术重点实验室,江西 赣州 341000)
随着经济水平的提升和城市化进程的加快,城市路网体系日益庞大,道路提取是城市规划和决策的重要环节之一[1-2].现有的道路提取方法主要依赖于手工标注,存在工作量大和效率低的问题[3].
随着诸多对地观测项目的实施,遥感图像取得了飞速发展[4].此外,语义分割技术[5-6]可以基于图像区分目标和背景,为道路自动提取提供技术支撑.传统的语义分割方法大多先基于手工算子进行提取特征,再通过模板匹配或边缘检测捕获道路区域[7-8].手工算子的选择需要丰富的先验知识,道路提取效果往往不佳.基于深度学习的方法遵循编码器-解码器结构[6],可以通过学习的方式更新参数.编码器用于提取图像的高级特征,大多为通用特征提取模型,例如基于卷积神经网络的MobileNet[9-10]和ResNet[11]、基于视觉Transformer 的Vision Transformer[12]和MobileViT[13].解码器用于捕获不同层次的特征,提高特征利用率,实现像素分类.FCN[14]基于全卷积神经网络实现语义分割,通过2 个连续的卷积层实现像素分类.DeepLab V3[15]在解码器中通过不同大小的空洞卷积捕获多尺度特征.类似地,PSPNet[16]和DDRNet[17]基于不同大小的池化层提取多尺度特征,有效提升了分割性能.STDC[18]、BiseNet V2[19]和PIDNet[20]使用多分支结构聚合不同层次的信息,在实时性和分割精度方面具有不错的表现.
众多研究人员将语义分割技术应用于道路自动提取领域.Zhou 等[21-22]使用大型模型作为编码器,设计多分支并行结构和全局上文模块处理不同层次的特征.Diakogiannis 等[23-24]分别通过空洞卷积和深化模型结构优化编码器的特征提取能力,使用损失函数缓解道路类别和背景类别的不均衡矛盾.这些研究基于全监督方式训练模型,实现了可靠的分割精度.一些研究人员引入半监督和无监督的方式,实现道路提取.Li 等[25-26]通过自训练方式优化语义分割模型,为无标注数据生成伪标签,再将其用于模型训练.Song 等[27]将遥感图像转换为通用地图,从通用地图中实现道路提取.这些研究探索了未标注数据的有效应用,但精度普遍低于全监督方式.上述研究使用大型模型实现特征提取,在解码器中通过复杂的模块利用特征信息,提升道路提取精度,但不利于模型的实时推理.
综合上述分析,本文提出轻量级城市道路提取模型RoadViT.在编码器中,通过轻量级模型MobileViT 编码特征,有效引入Transformer 实现全局信息建模.在解码器中,提出金字塔解码器提取多尺度特征,适应不同大小的道路区域.结合Mosaic[28]与多尺度缩放和随机裁剪实现数据增强,获取精细多样的图像数据.针对遥感图像中道路类别和背景类别不平衡的问题,设计动态加权损失函数.
1 遥感影像路网提取方法
为了精准、快速地从城市遥感影像中提取路网,提出基于轻量级Transformer 的语义分割模型RoadViT.该模型遵循编码器-解码器架构,详细组成如图1 所示.
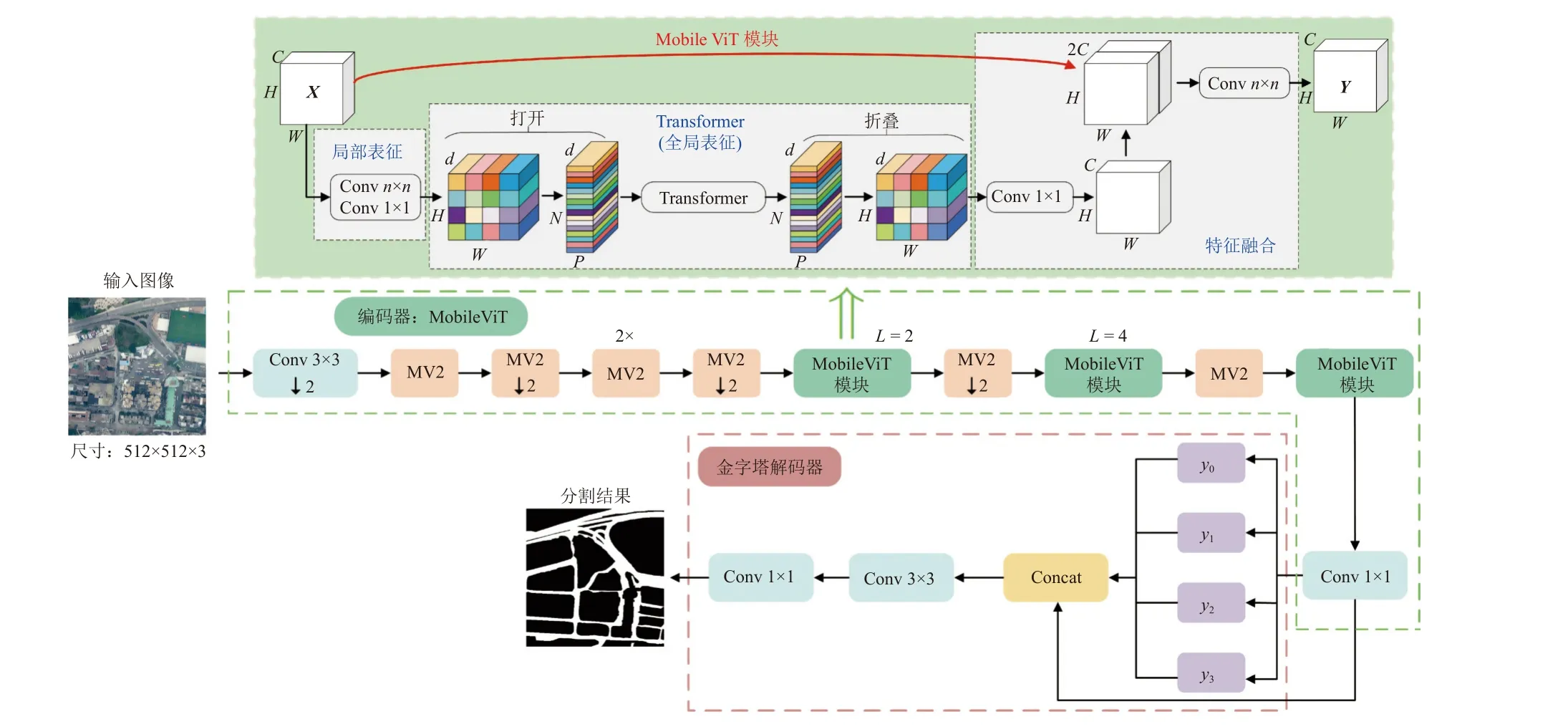
图1 提出的城市路网提取模型RoadViT 的结构Fig.1 Structure of proposed urban road network extraction model RoadViT
1.1 编码器: MobileViT
在轻量级城市路网的提取任务中,编码器需要从输入图像中提取高级上下文信息,这要求编码器具有丰富的特征提取能力,并且保持轻量性.选择了目前先进的MobileViT 作为编码器,可以有效利用卷积神经网络的空间偏置特点和Transformer 的全局信息处理能力,有效地加强特征提取性能.在结构上,MobileViT 由多个MV2 模块和MobileViT 模块堆叠而成,MV2 模块是MobileNet V2[9]提出的轻量级倒残差瓶颈单元,MobileViT模块是轻量、高效的视觉Transformer,核心部件如图2 所示.图2(a)中,e为扩张系数.图2(b)中,输入X的维度为d×k,Q、K和V的维度为k×dh×h,d=dh×h.
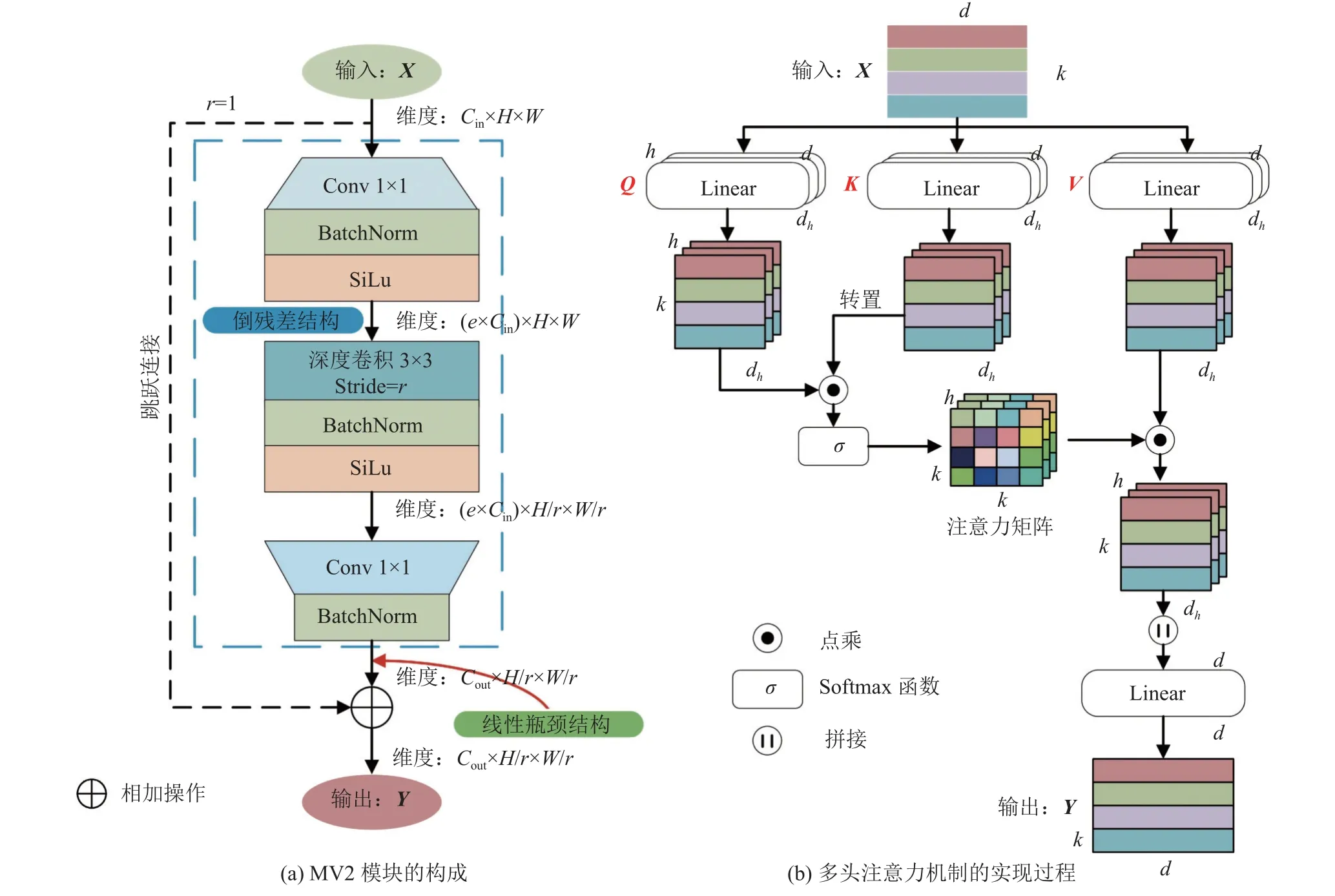
图2 MV2 模块和多头注意力机制的实现过程Fig.2 Implementation process of MV2 module and multi-head attention mechanism
MV2 模块由倒残差结构和线性瓶颈结构组成,将标准卷积分解为深度卷积和1×1 卷积,实现过程如图2(a)所示.MV2 模块的计算如下所示:
式中:X和Y分别表示输入特征和输出特征,r为深度卷积的步长.倒残差结构是残差结构的改进,先通过1×1 卷积φ1,p扩张通道维度,然后通过深度卷积φd在高维空间编码空间信息,最后通过1×1 卷积φ2,p实现信息融合和通道降维.当特征信息从高维空间经非线性函数映射到低维空间时,存在信息坍塌的问题.当进行通道降维时,使用线性瓶颈结构减少信息丢失,即不使用非线性激活函数.当且仅当步长为1 时,使用跳跃连接.
MobileViT 模块通过Transformer 机制有效地捕获了全局信息,其核心是多头注意力机制(multihead attention,MHA).MHA 在自注意力机制的基础上引入多个关注头,可以捕获不同层次的输入和输出关系,实现过程如图2(b)所示.自注意力机制的计算如下所示:
输入特征先通过3 个线性变换,分别得到查询矩阵Q、索引矩阵K、内容矩阵V.对Q和K进行矩阵乘法,基于矩阵K的维度dk实现加权,获取注意力矩阵.注意力矩阵通过softmax 函数fs进行调整,再与V通过矩阵乘法获取输出特征Fa.
在MHA 中,输入特征将被分配给不同的自注意力头,每个自注意力头先学习不同的信息关系,再进行加权融合,计算过程如下所示:
在h个自注意力头中,每个自注意力头对不同的特征矩{阵进行线性}转换得到Q、K和V,通过参数矩阵进行加权.每个自注意头的输出通过拼接操作fcat和参数矩阵WO,获取输出特征Fout.
1.2 金字塔解码器
在语义分割任务中,解码器需要还原高级上下文信息,以预测每个像素的概率分布.卷积神经网络的实际感受野远小于理论感受野,使得基于卷积神经网络的语义分割模型无法捕获足够的上下文信息[16].设计金字塔解码器,通过串行多个平均池化实现下采样和多尺度信息捕获,有效提升模型的感受野和上下文信息的利用率,结构如图3 所示.通过池化核为5 和步长为2 的平均池化实现串行下采样,捕获多尺度上下文信息,通过全局平均池化获取全局上下文信息.使用1×1卷积实现信息融合和通道压缩,经过双线性插值将特征图上采样至输入尺寸.在通道维度将多尺度特征进行拼接,通过跳跃连接维持高级上下文信息的权重.通过3×3 卷积和1×1 卷积,实现信息融合和像素类别的概率分布生成.
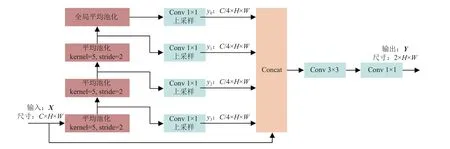
图3 金字塔解码器的结构Fig.3 Structure of pyramid decoder
1.3 动态加权损失函数
在高分辨率的城市遥感影像中,道路像素往往少于背景像素,这会造成类别的不平衡问题.针对训练过程中类别不平衡的问题,通常的方式是给较少的类别附加固定的权重,但可能会造成权重系数的选取困难.如图4 所示,提出动态加权函数fd(x),基于图像中的道路像素数量自适应地生成加权系数,表达式为
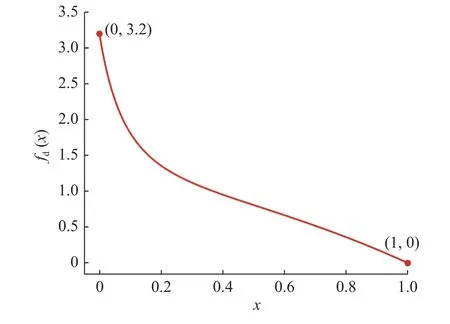
图4 动态加权函数的图形和表达式Fig.4 Graph and expression of dynamic weighting function
式中:x为道路像素与所有像素的比值,遵循以下权重系数分配原则.1)道路像素占比越少,需要对道路像素给予更多的关注,即道路类别的权重系数越大;2) 当所有像素均为道路时,道路类别的加权系数为0,不需要对道路类别进行额外的关注.
图像分割的损失函数通常为交叉熵损失函数fc(x),当引入fd(x) 时,本文的损失函数可以表示为
式中:I和L分别为模型输出的特征图和标签,L为大小为H×W的矩阵,由0 和1 组成,0 表示该像素是背景,1 表示该像素是道路;Pr和Pb分别为道路像素和背景像素的数量.计算真实标签中道路像素的占比,通过动态加权函数获取权重矩阵Fd∈RH×W.将Fd与损失矩阵fc(I,L)∈RH×W进行逐元素相乘操作 ⊗,着重关注道路类别,通过相加操作维持背景类别的权重.调整后的损失矩阵通过平均操作fm获取损失值Ls.
1.4 数据增强
遥感影像是精细化和高空间分辨率的图像,分辨率越高的图像可以为模型提供更精细的特征,但会造成训练成本的急剧上升.直接将图像缩放至低分辨率会造成信息损失,不利于城市路网的精准提取.通过多尺度缩放和随机裁剪策略降低分辨率,有效维持了遥感图像的精细化特征.引入Mosaic[28]实现多图像混合,构建多样的图像数据提升模型性能,过程如图5 所示.图中,α 为多尺度缩放因子.将输入图像按随机比例进行放大,生成更精细的遥感影像.通过随机裁剪,生成尺寸一致、但位置不同的图像.随机选取3 张图像进行多尺度缩放和随机裁剪,将这4 张图像通过随机混合.输出图像被用于模型训练,有效获取了更精细和多样的图像数据.
2 数据准备及模型训练
CHN6-CUG[22]是中国城市道路遥感影像数据集,图像数据来源于北京、上海、武汉、深圳、香港和澳门6 个城市,图像的空间分辨率为50 cm/像素.CHN6-CUG 包含4 511 张大小为512×512 像素的标记图像,其中3 608 张用于模型训练,903 张用于测试.
DeepGlobe 道路提取数据集[22]包含6 226 张1 024×1 024 像素的卫星遥感图像和标签,每幅图像的空间分辨率为50 cm/像素.图像包含城市、郊区和乡村的道路,来源于泰国、印度和印度尼西亚,其中4 980 张用于模型训练,1 246 张用于测试.
所有的模型基于Pytorch1.10 进行构建,采用12 GB 显存的Tesla P100 进行单卡加速训练.模型优化器选择SGD,初始学习率为0.01,学习率衰减系数为0.01.训练周期设置为200,每批次训练4 张图像.在模型测试阶段,将模型转为ONNX 格式,并部署在边缘设备Jetson TX2 上进行测试.Jetson TX2 具有8 GB 显存的NVIDIA Pascal GPU,可以有效地加速模型推理.
为了综合评价模型的实时性和分割性能,使用参数量P、每秒浮点运算次数(FLOPs)、每秒帧数和道路类别的交并比RIoU作为评价指标.其中,P和FLOPs 用于评价模型的复杂度.
式中:TP表示真正例,FP表示假正例,FN表示假反例.
3 实验结果
3.1 技术有效性的验证
为了验证本文使用技术的有效性,将其和一些通用技术进行对比,结果如表1 所示.为了对比各种数据增强方式对模型性能的提升,在CHN6-CUG 数据集上,使用MobileViT+FCNHead 作为基础模型进行实验.FCNHead 是简洁的解码器,由2 个连续的卷积层构成.可见,使用Cutout[29]随机擦除部分图像后,模型精度提升了0.3%.Cutmix[30]通过混合图像实现数据增强,模型精度显著提升了1.1%,这表明利用混合图像的方式有利于构建多样的图像数据.通过Mosaic 混合多张图像,模型精度提升了2.3%.引入多尺度缩放和随机裁剪,获取更精细的图像信息,精度提升了4.6%,这表明更丰富的图像信息可以提升分割性能.结合Mosaic 与多尺度缩放和随机裁剪,构建精细、多样的图像数据,模型精度提升了5%.现有的SPP[31](spatial pyramid pooling)通过并行不同大小的最大池化操作捕获多尺度特征,有效提升了1.9%的精度,但并行拼接特征会显著增加参数量和FLOPs.提出的金字塔解码器串行相同大小的平均池化操作,有效捕获了不同尺度的局部信息和全局信息,通过卷积操作调节不同层次信息的权重.在使用金字塔解码器后,模型参数量和FLOPs 仅分别为使用SPP 的65%和62%,但精度提升了0.9%.为了验证多头注意力机制(MHA)可以实现全局信息建模,有效增强模型的特征提取性能,引入去除MHA 的MobileViT 进行实验.在去除MHA后,模型的参数量和FLOPs 显著降低,但卷积神经网络仅具有局部信息建模的能力,不利于全局的道路提取,分割精度为41.5%.
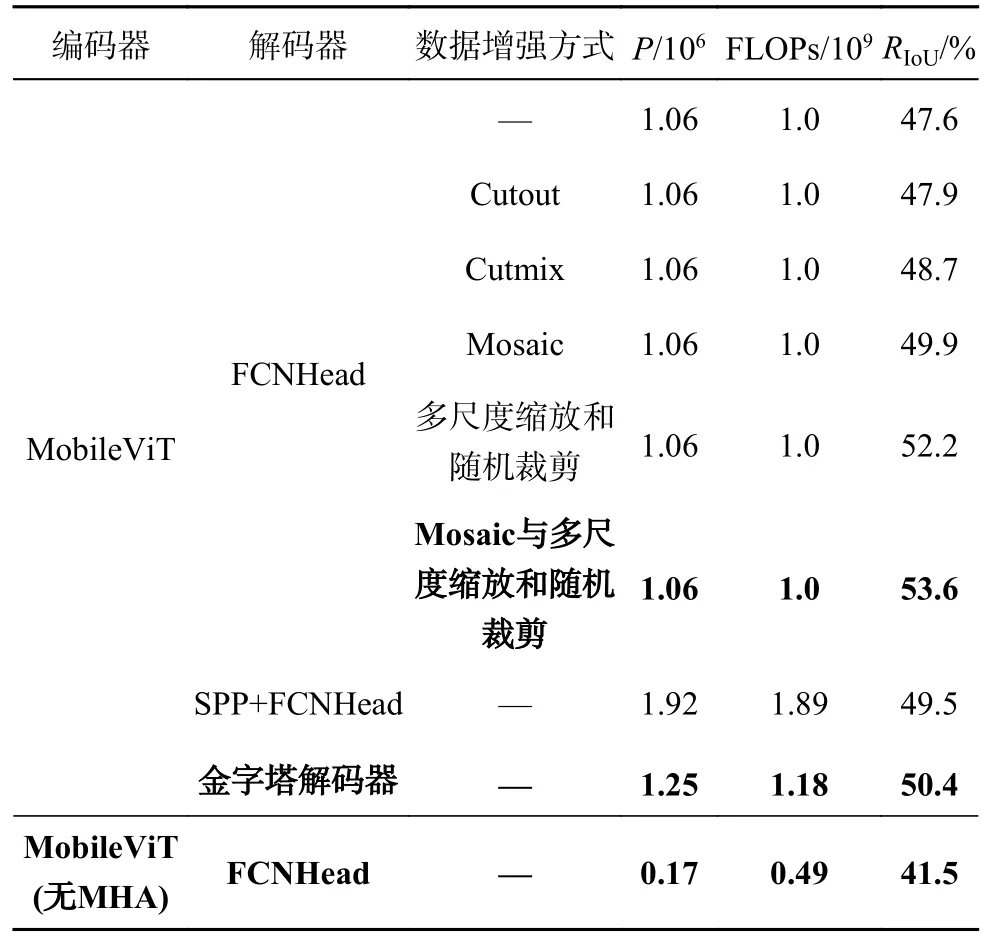
表1 不同技术对模型性能的效果Tab.1 Effect of different techniques on model performance
3.2 消融实验
为了验证所提技术对RoadViT 分割性能的贡献,设置消融实验进行验证,各模型的RIoU曲线、参数量和FLOPs 如表2 所示.可见,仅通过MobileViT 进行特征提取,利用FCNHead 实现像素分类,模型的参数量和FLOPs 仅分别为1.06×106和1.0×109,RIoU达到47.6%.引入Mosaic 与多尺度缩放和随机裁剪,获取更详细、多样的图像信息,在不增加模型复杂度的前提下,RIoU提升了5%.这表明丰富多样的图像信息有利于模型性能的提升.通过动态加权损失函数,缓解道路类别和背景类别的不均衡矛盾,有效提升了道路的提取精度,RIoU达到49.5%.使用提出的金字塔解码器代替FCNHead,参数量和FLOPs 仅分别为1.25×106和1.18×109,RIoU达到50.5%.相比于FCNHead,RIoU提升了2.9%,这表明金字塔解码器通过多个池化分支可以有效地提取多尺度特征,以适应不同大小的道路区域.将不同技术进行组合,验证提出技术的贡献.引入动态加权损失函数优化模型训练,精度提升了2.1%.在动态加权损失函数的基础上,通过金字塔解码器捕获多尺度信息,模型性能提升了1.9%.在金字塔解码器的基础上,使用数据增强获取详细多样的图像数据,分割精度显著提升了6%.将提出技术进行融合,设计轻量级模型RoadViT,道路提取精度可达57.0%.为了适应不同的精度需求,根据不同大小的Mobile-ViT,RoadViT 可以扩张为RoadViT-m 和RoadViTl.综上所述,RoadViT 可以快速、可靠地提取道路,有利于基于遥感图像构建城市路网.
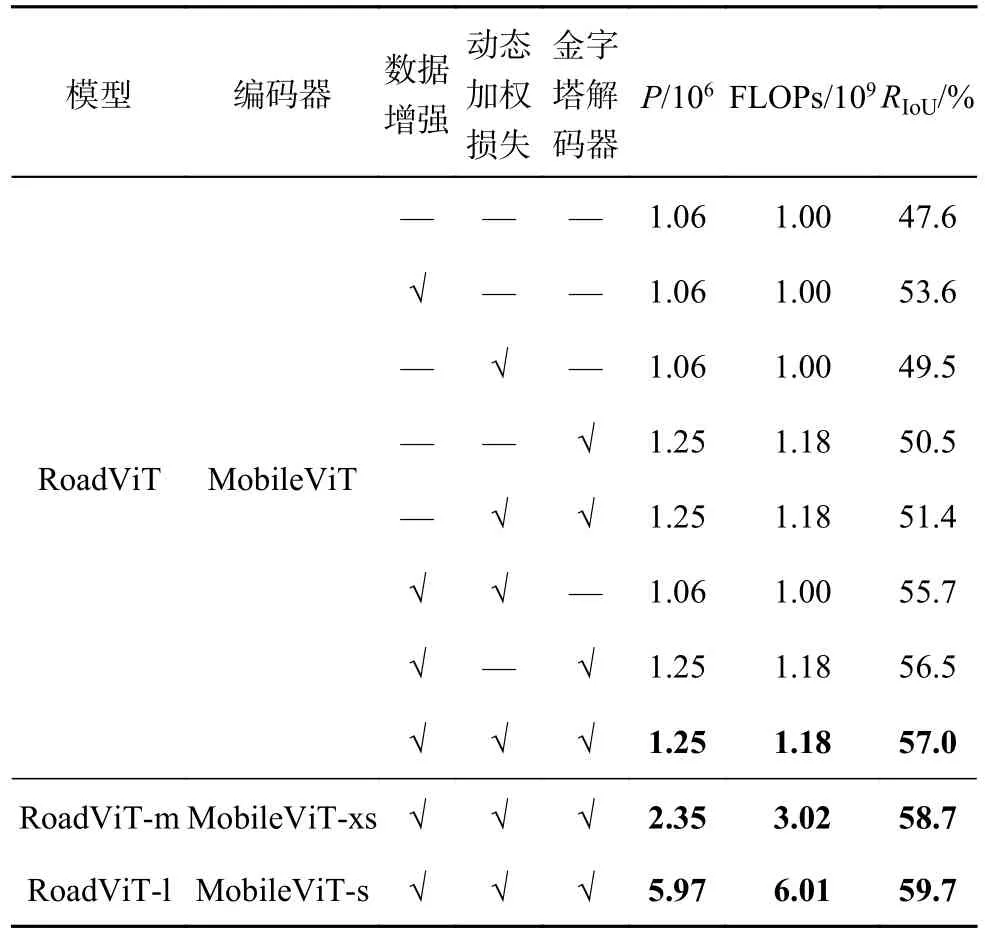
表2 RoadViT 的消融实验Tab.2 Ablation experiments of RoadViT
3.3 主流模型的性能对比
为了进一步验证RoadViT 的先进性,将其和主流模型进行对比.选取的大型模型有DeepLab V3(ResNet18)、STDC、DDRNet 和PSPNet(ResNet18),轻量级模型有PSPNet(MobileNet V2)、LRASPP、DeepLab V3(MobileNet V2)、BiseNet V2 和PIDNet,实验结果如表3 所示.
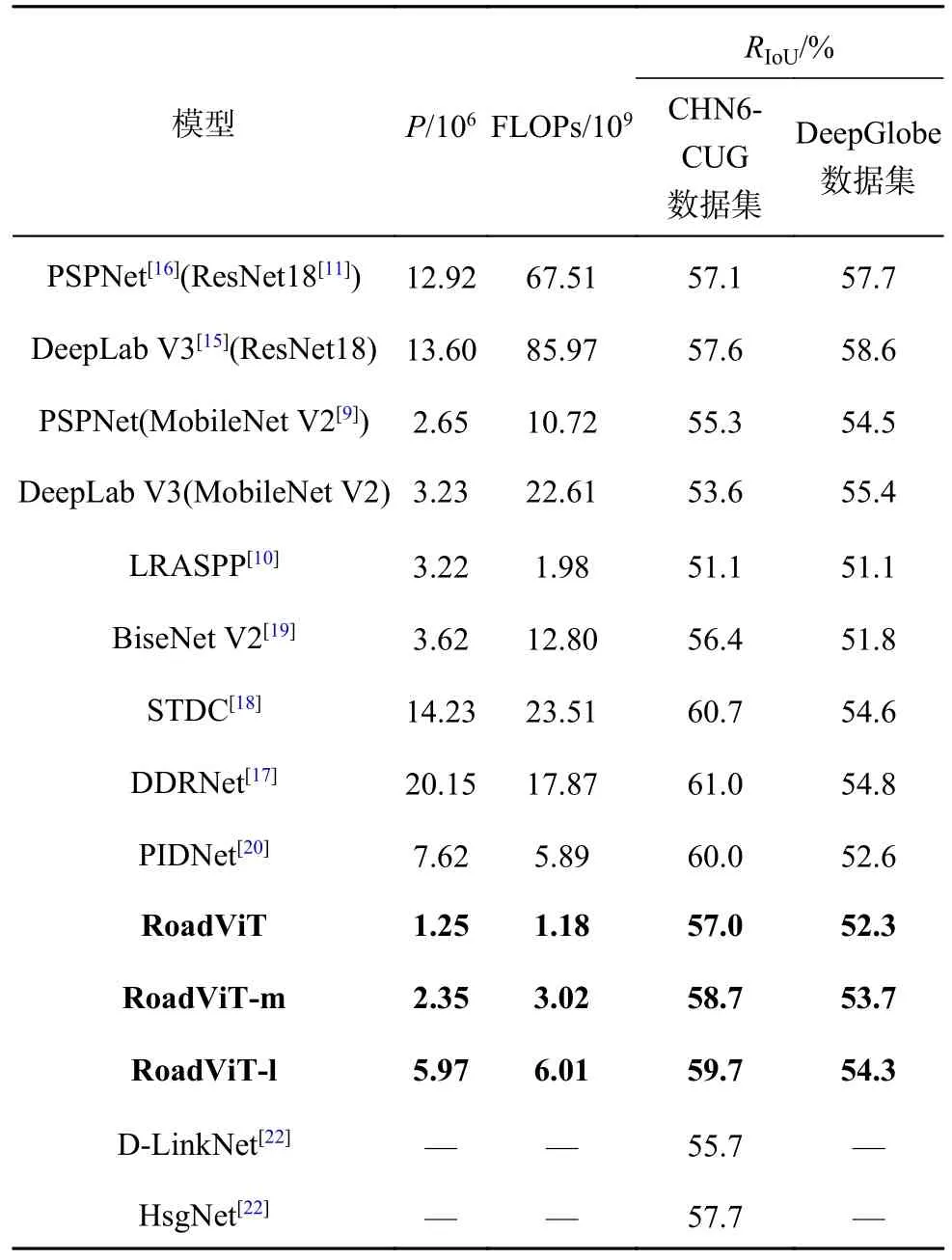
表3 RoadViT 和主流模型在不同数据集上的对比Tab.3 Comparison of RoadViT and mainstream models on different datasets
3.3.1 CHN6-CUG 数据集 从表3 可知,Road-ViT 在保证轻量的前提下,RIoU达到57.0%,参数量和FLOPs 仅分别为1.25×106和1.18×109.相比于轻量级模型LRASPP、DeepLab V3(MobileNet V2) 和PSPNet(MobileNet V2) 与大型模型DLinkNet,RoadViT 在模型的轻量性和精度上都更具优势.RoadViT 的精度优于轻量级模型BiseNet V2,但参数量和FLOPs 仅分别为BiseNet V2 的34.5%和9.2%.随着模型复杂度的增大,RoadViTm 和RoadViT-l 的性能随之提升,RIoU分别为58.7%和59.7%.DeepLab V3(ResNet18)和PSPNet(ResNet18)通过大型模型Resnet18 实现特征提取,有效提升了分割性能,但具有繁多的参数和昂贵的计算开销.相比之下,RoadViT-m 的精度优于HsgNet、PSPNet(ResNet18)和DeepLab V3(ResNet18),但参数量仅分别为后两者的18.1%和17.3%,FLOPs 分别为后两者的4.5% 和3.5%.与STDC 和DDRNet 相比,RoadViT-l 的精度分别降低了约1%和1.3%,但具有更低的模型复杂度,参数量分别为它们的42%和30%,FLOPs 分别为它们的26%和34%,有利于实时提取城市道路.RoadViT-l 与PIDNet 的计算复杂度相近,尽管RoadViT-l 的精度略低,但参数量仅为PIDNet 的78.3%.综合考虑模型的轻量性和分割性能,RoadViT 是兼顾模型复杂度和精度的城市道路提取模型,可以应用于持续工作的机载设备和资源有限的场景,对城市路网建设具有积极意义.
3.3.2 DeepGlobe 数据集 为了进一步验证Road-ViT 的有效性,在DeepGlobe 数据集上进行对比实验.相比于轻量级模型LRASPP 和BiseNet V2,RoadViT 以更低的模型复杂度取得了更好的分割性能,实现了与PIDNet 近似的精度(RIoU=52.3%),但参数量和FLOPs 仅分别为PIDNet 的16.4%和20%,这表明提出的RoadViT 可以有效地兼顾分割性能和轻量性.RoadViT-m 和RoadViT-l 取得了不错的分割精度,RIoU分别为53.7% 和54.3%.RoadViT-l 取得了与STDC 和DDRNet 相似的精度,但具有明显的轻量化优势.尽管PSPNet(MobileNet V2)和DeepLab V3(MobileNet V2)以轻量级模型MobileNet V2 作为编码器,实现了较小的模型参数量,但复杂的模型结构限制了它们的计算实时性,RoadViT-l 的FLOPs 仅分别为它们的56%和27%.类似地,DeepLab V3(ResNet18)和PSPNet(ResNet18)实现了最高的分割精度,但具有高昂的计算复杂度,FLOPs 高达67.51×109和85.97×109,不利于实时的道路提取.综上所述,提出的RoadViT 通过简洁的模型结构实现道路提取,有效兼顾了分割精度和实时性,在主流模型中具有轻量化的优势.
3.4 模型实际部署的测试
3.4.1 推理时间的测试 为了验证RoadViT 的实时性,将其和主流模型转为ONNX 格式,并部署在Jetson TX2 上测试推理速度v,结果如图6所示.图中,N为测试次数.LRASPP 在实时性上的表现出色,平均可达14 帧/s,但分割精度不佳.Road-ViT 取得了不错的分割性能,推理速度可达10 帧/s,在主流模型中处于相对领先的地位.基于Road-ViT 扩张的RoadViT-m 和RoadViT-l 具有不错的实时性,推理速度分别为8 和6 帧/s.尽管PSPNet和DeepLab V3 以轻量级模型MobileNet V2 为编码器,在模型复杂度上表现出色,但平均速度约为5 帧/s.其中,BiseNet V2 和STDC 通过简洁、有效的模型结构提取道路区域,在实时性上的表现良好,分别可达8 和6 帧/s.PIDNet 取得了与Road-ViT-l 近似的推理速度,具有不错的实时性.DDRNet 在模型精度上具有显著的优势,但在边缘设备上的推理速度较小,仅约为4 帧/s.DeepLab V3(ResNet18)和PSPNet(ResNet18)通过大型模型ResNet18 实现特征提取,但推理速度仅约为3 帧/s.综上所述,在主流模型中,RoadViT 在实时性上具有优势.
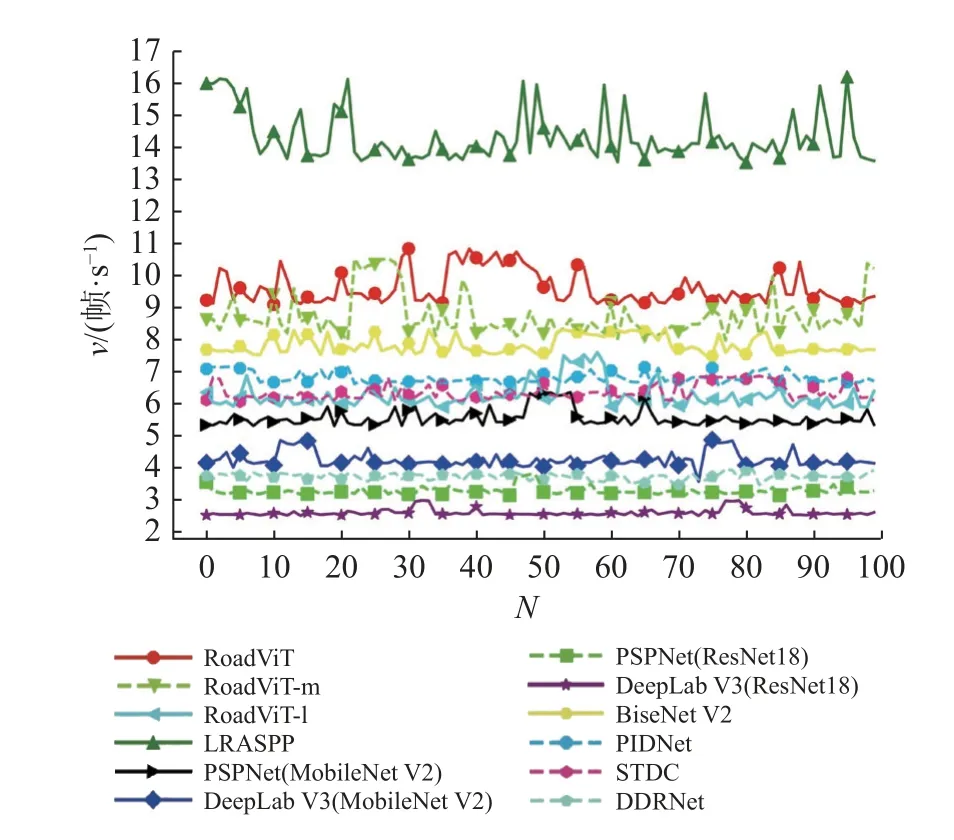
图6 模型的推理速度对比Fig.6 Comparison of inference speed for models
3.4.2 硬盘空间占用的测试 模型体积是模型轻量性的重要指标之一,更小的模型体积可以提高数据的响应速度,有利于模型在资源受限设备的部署和应用.模型体积Sm是模型所需的计算机存储空间.将RoadViT 和其他模型的体积进行对比,结果如图7 所示.RoadViT 的模型体积仅为5.46 MB,仅约为PSPNet(ResNet18)的11%,但两者的分割性能近似.相比于轻量级模型PSPNet(MobileNet V2)、BiseNet V2、DeepLab V3(MobileNet V2) 和LRASPP,RoadViT 不仅在模型体积上更具优势,而且在分割性能上更加出色,这表明RoadViT 可以兼顾模型的轻量性和分割性能.随着RoadViT参数量的增加,RoadViT-m 和RoadViT-l 的模型体积仅分别为9.12 MB 和22.9 MB.RoadViT-m 取得了优于DeepLab V3(ResNet18)和PSPNet(ResNet18)的分割精度,但模型体积仅约为它们的1/5.Road-ViT-l 的精度与PIDNet、STDC 和DDRNet 类似,但在模型体积上更具优势.综合考虑模型体积和分割性能,RoadViT 是轻量、高效的城市道路提取模型.3.4.3 技术效果的对比及分析 为了验证使用技术对道路提取性能的影响,利用二值化图像对比和分析不同技术的效果,结果如图8 所示.图中,黑色像素和白色像素分别表示背景和道路,矩形框突出不同技术的道路提取效果.对比图8(c)、(d)可知,多头注意力机制可以捕获全局信息,提取更完整、连续的道路区域.相比于图8(d),图8(e)引入数据增强获取精细的图像信息,可以对识别难度高的道路进行提取.从图8(d)、(f)可知,利用动态加权损失函数可以缓解样本不均衡的矛盾,优化模型的提取精度.图8(g)表明,金字塔解码器通过捕获多尺度信息,可以提取不同大小的道路区域.利用RoadViT 可以提取较完整和连续的道路,有利于构建城市路网.
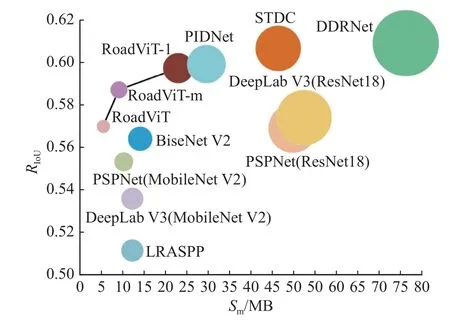
图7 各模型的体积和分割精度对比Fig.7 Comparison of volume and segmentation accuracy for models

图8 不同技术对分割效果的影响Fig.8 Impact of different techniques on segmentation effect
3.4.4 遥感影像路网提取测试 为了验证Road-ViT 的道路提取效果,选择城市和城郊图像进行测试.使用二值化图像与其他方法进行对比,通过矩形框突出的RoadViT 的效果,结果如图9 所示.从图9(a)~(c)可知,对于不同的道路环境,利用RoadViT 提取的道路区域和真实区域基本吻合,有利于基于遥感图像构建城市路网.随着编码器MobileViT 的扩张,RoadViT-m 和RoadViTl 提取的道路区域更完整和连续,可以有效地识别难度较高的前景信息.根据图9(c)、(f)~(i)的对比可知,当处理细小和弯曲的道路时,这些轻量级模型存在提取道路缺失和不连续的问题,本文的RoadViT 改善了这种现象,可以适应不同环境下的道路提取.使用ResNet18 替换轻量级模型MobileNet V2,图9(j)、(k)的道路提取效果得到显著的提升,缓解了提取道路不连续的矛盾,但效果次于RoadViT-l.PIDNet、STDC 和DDRNet 提取的道路区域和真实区域重合度较好,可以有效地处理道路细节部分,但对遮挡部分和识别难度高的像素存在不足,导致提取的道路存在间断现象.综上所述,对于不同弯曲程度、大小和场景的道路遥感图像,利用RoadViT 可以提取较完整连续的道路,有利于城市路网的建设.
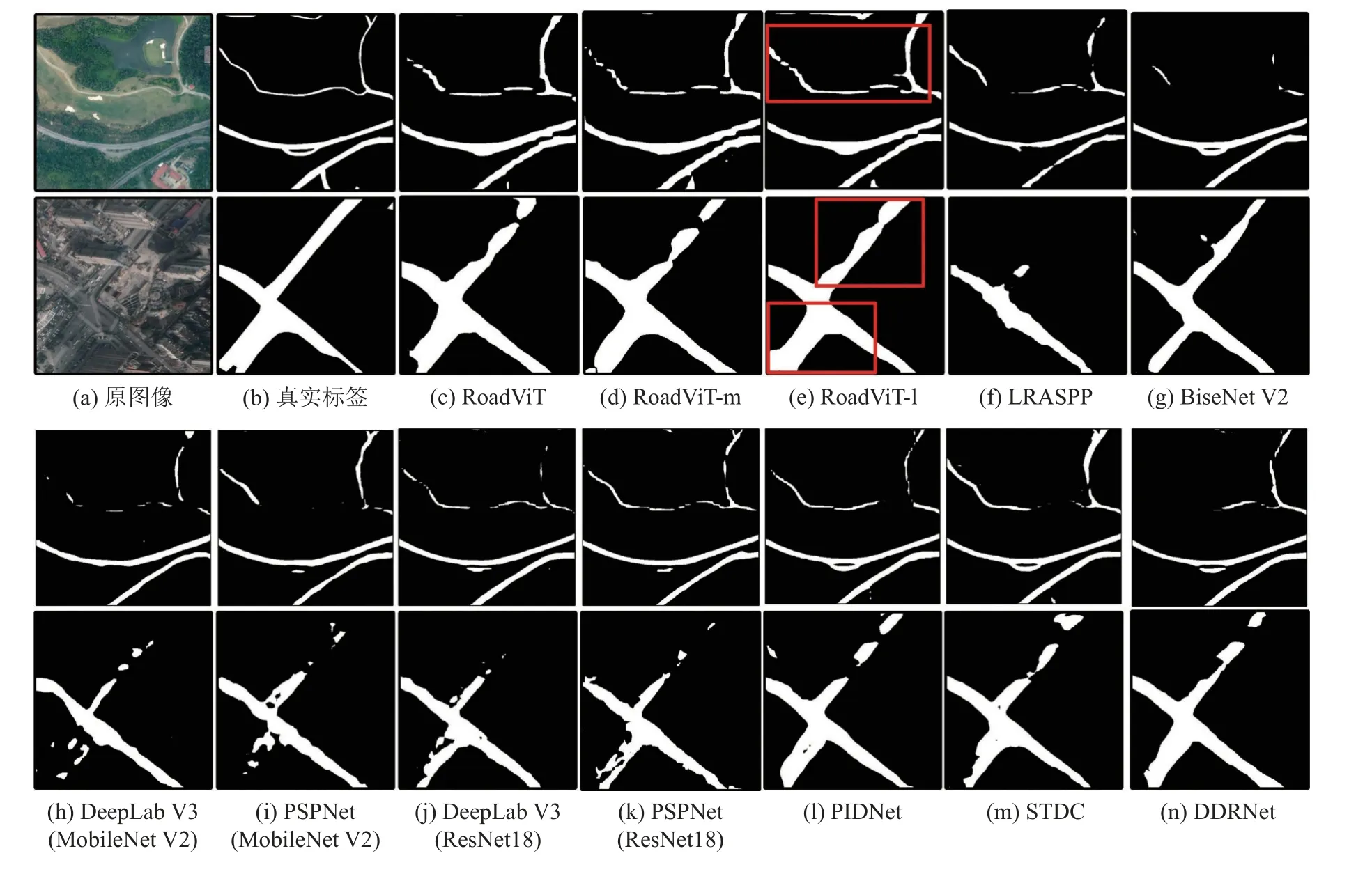
图9 RoadViT 和主流模型的实际道路提取效果对比Fig.9 Comparison of actual road extraction results between RoadViT and mainstream models
4 结论
(1)道路提取是城市建设和规划的重要步骤之一,传统手工提取需要长时间的标注劳动,效率不高.本文提出轻量级城市路网提取模型Road-ViT,可以轻量、高效地区分背景和城市道路,对构建城市路网体系具有积极意义.
(2)提出的RoadViT 的参数量和FlOPs 仅分别为1.25×106和1.18×109,在Jetson TX2 上的推理速度可达10 帧/s,轻量性和实时性在主流模型中处于相对领先的地位.RoadViT 在CHN6-CUG数据集和DeepGlobe 数据集上的道路分割精度分别为57.0%和52.3%,可以有效地从遥感图像中提取道路.综合考虑模型的实时性和精度,RoadViT适用于持续工作的机载设备和资源受限的场景.
(3)在模型结构上,RoadViT 由MobileViT 和金字塔解码器组成,在训练过程中通过Mosaic 与多尺度缩放和随机裁剪,构建精细多样的图像数据.MobileViT 是结合卷积神经网络和Transformer的轻量级模型,可以有效地捕获局部信息和全局信息.利用提出的金字塔解码器,可以提取多尺度特征,生成像素类别的概率分布.本文设计动态加权损失函数,有效缓解了城市遥感图像中道路类别和背景类别的不平衡矛盾.
猜你喜欢
小学生必读(低年级版)(2021年10期)2022-01-18 15:10:46
小学生必读(低年级版)(2021年11期)2021-03-09 06:14:46
小学生必读(低年级版)(2021年12期)2021-03-04 07:18:44
内蒙古民族大学学报(社会科学版)(2020年2期)2020-11-06 09:08:52
家庭影院技术(2019年8期)2019-12-04 14:43:19
太空探索(2016年5期)2016-07-12 15:17:55
新校长(2016年8期)2016-01-10 06:43:59
时代英语·高三(2014年5期)2014-08-26 17:01:17
商事法论集(2014年1期)2014-06-27 01:20:42
中国中医药现代远程教育(2014年16期)2014-03-01 04:28:46
