
基于聚类和深度学习的车联网轨迹隐私保护机制
2024-02-12 07:42申自浩唐雨雨王辉刘沛骞刘琨
浙江大学学报(工学版) 2024年1期
申自浩,唐雨雨,王辉,刘沛骞,刘琨
(1.河南理工大学 计算机科学与技术学院,河南 焦作 454000;2.河南理工大学 软件学院,河南 焦作 454000)
车联网用户在使用基于位置的服务[1]应用时会生成大量的轨迹数据,直接发布会引起严重的隐私泄露问题[2-3].k-匿名[4]、l-多样性[5]和t-近邻性[6]技术通过将数据匿名化实现隐私保护,但无法抵御组合攻击、同质攻击、背景知识攻击等窃取隐私的方法.Dwork[7]提出差分隐私(differential privacy,DP)技术,在数据中加入适量的噪声以实现隐私保护,可以抵御背景知识攻击.若噪声添加过多,则会降低数据的可用性.Cheng 等[8]提出个性化轨迹聚类和差分隐私保护机制,在数据效用方面有一定的提升,但未考虑轨迹属性中的时空特征.本文引入时间图卷积网络(temporal graph convolutional network,T-GCN)模型,在涉及复杂空间的结构中,能够充分提取轨迹的时空特征,在隐私保护中能够实现隐私预算的合理分配.
针对大多数聚类质量损失数据的问题,Cai 等[9]提出利用DBSCAN 聚类的轨迹发布DPTD 的机制,能够保护多数轨迹的隐私.Zhang 等[10]提出LGAN-DP 算法,利用深度学习方法合成轨迹,使用k-means 聚类对轨迹结果集进行处理,提高了数据的私密性.k-means、DBSCAN 聚类高度依赖用户指定的参数,性能不够稳定.Guan 等[11]提出基于稳定隶属度的自动调优多峰值聚类SMMP算法,解决了参数调优问题,但只能应用在低维空间.本文提出改进的稳定隶属度多峰值聚类(Improved stable-membership multi-peak clustering,ISMMPC)算法,可以自动调整聚类阈值,开展多原型聚类,解决多维度中应用的问题.
Kim 等[12]提出DPGeo 框架,在对抗自编码器中使用DP 收集的扰动数据集训练轨迹生成,局限性是轨迹精度级别不高于网格表示级别.晏燕等[13]提出时空长短期记忆模型,通过添加拉普拉斯噪声预测位置的结构,缺点是提供的隐私预算不够精确.康海燕等[14]使用基于时空密度聚类的轨迹预测隐马尔可夫模型,通过分析时空的相关性,预测时空序列数据的不同分布,但仅适用于平滑数据,无法捕捉轨迹中隐藏的非线性特征.本文结合T-GCN 模型与DP 技术,既能够精确预测隐私预算,又能够对轨迹中隐藏的线性和非线性特征进行探索.
本文设计基于聚类和深度学习的轨迹隐私保护机制(trajectory privacy protection mechanism based on clustering and deep learning,PPCDL).考虑轨迹空间的时空特征,分析通过时间戳划分轨迹区域带来的数据稀疏性对轨迹隐私保护的影响,设计ISMMPC 算法和T-GCN 模型,提高隐私保护的效果和轨迹数据的可用性.
1 预备知识
1.1 轨迹模型
定义1网格图G.G=(V,E),E为边的集合,V={V1,V2,···,Vn×n} 为网格位置上的节点,n×n为网格区域位置的个数.
定义2特征矩阵X.将网格上的轨迹信息作为网格中节点的属性特征,构成特征矩阵X.Xtg表示tg时的轨迹信息,tg为第g个时间戳.
时空轨迹是在G和X下学习映射函数F得到的tg时的轨迹数据,可以表示为
式中:m为历史时间序列长度,T为预测时间序列步长.
定义3总数矩阵S.设tg划分后的区域为Ag,根据Ag进行划分得到n×n个网格区域,构造矩阵S记录Ag的轨迹数.矩阵元素sij(i,j=1,2,···,n) 为对应网格区域内的累计轨迹数,i、j为元素下标.maxS为最大的sij.S可以表示为
定义4密度矩阵P.构造矩阵P表示Ag的轨迹密度.矩阵元素 ρij(i,j=1,2,···,n) 表示对应网格区域内轨迹的密度,其中 ρij=sij/aAg,其中aAg为Ag的面积.P可以表示为
定义5隐私预算矩阵E.构造矩阵E表示为Ag分配的隐私预算,矩阵元素 εij(i,j=1,2,···,n) 表示对应网格区域内的隐私预算分配大小.εij的初始值为0.E可以表示为
1.2 差分隐私
定义6ε-差分隐私.设有随机算法K,所有可能输出构成的集合O的概率为P[·],对于任意2 个相邻数据集D和D′,若2 个相邻集合的概率分布满足
则称算法K提供 ε-差分隐私保护.算法K满足 ε 差分隐私,P[·] 表示隐私泄露的概率.ε 表示隐私保护的程度,ε ∈(0,1.0).
定义7 全局敏感度.设函数f:D→Rd,对于任意的相邻数据集D和D′,全局敏感度为
式中:d为函数f的查询维数,‖·‖1表示L1范数.
定义8拉普拉斯机制.对于给定数据集D,假设有函数f:D→Rd,敏感度为Δf,随机算法K(D)=f(D)+Y提供 ε-差分隐私,其中噪声数量Y服从拉普拉斯分布.
Y与 Δf成正比,与 ε 成反比.
1.3 时间图卷积网络模型
时间图卷积网络模型包括图卷积网络(GCN)和门控循环单元(GRU),如图1 所示.
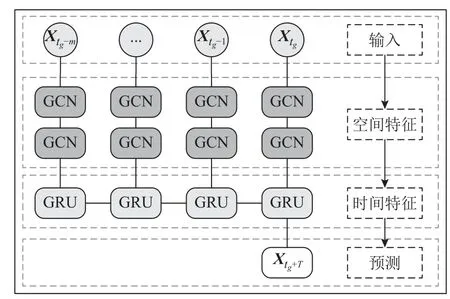
图1 时间图卷积网络模型Fig.1 Temporal graph convolutional network model
T-GCN 使用m个时间序列数据作为输入,利用2 层GCN 模型进行图卷积操作,捕获路网区域位置复杂的拓扑结构,以学习空间特征.将得到的具有空间特征的时间序列输入到GRU 模型中,通过单元间的信息传递获得动态变化,捕获时间特征.T-GCN 可以充分学习时空依赖性,实现轨迹预测.具体可以表示为
2 PPCDL 机制
2.1 问题描述
车联网中许多保护轨迹数据的方法会忽略轨迹的时空特征.地理空间的限制及时间序列上位置的相关性,使得攻击者有较大可能推断出用户的真实敏感位置和轨迹信息.实际上,大多数的轨迹隐私保护机制只考虑单个位置点的隐私保护,忽略了连续位置点对轨迹隐私保护的影响.这会使得攻击者很容易推断出2 个位置点之间的地理位置关系,推断出用户经过或停留的位置点,导致用户的位置或轨迹隐私泄露.轨迹中的位置是时间相关的,引入时间戳,用于获得不同时间的轨迹位置分布,探究位置之间的某种相关性及用户的行为模式.时间戳的引入会使得轨迹数据变得稀疏,难以承受注入的噪声,降低了数据价值.引入ISMMPC 聚类,以减小时间戳导致的数据稀疏性.ISMMPC 在对轨迹数据聚类的同时,保留了时间特征和空间特征.根据聚类后的轨迹区域密度进行隐私预算预分配,形成隐私预算矩阵.基于时间图卷积网络模型,对隐私预算矩阵进行预测.在T-GCN 模型的训练过程中,不断优化隐私预算的分配,在对数据减少注入噪声的同时,保护了轨迹数据的隐私安全.
2.2 PPCDL 实现
2.2.1 轨迹聚类 ISMMPC 算法在时间戳划分后的区域实现聚类,捕获轨迹的位置分布.根据轨迹的分布情况,形成任意形状和数量的子簇,无须预先确定聚类的子簇量.图2 给出ISMMPC 聚类过程.图中,n为子簇数量.
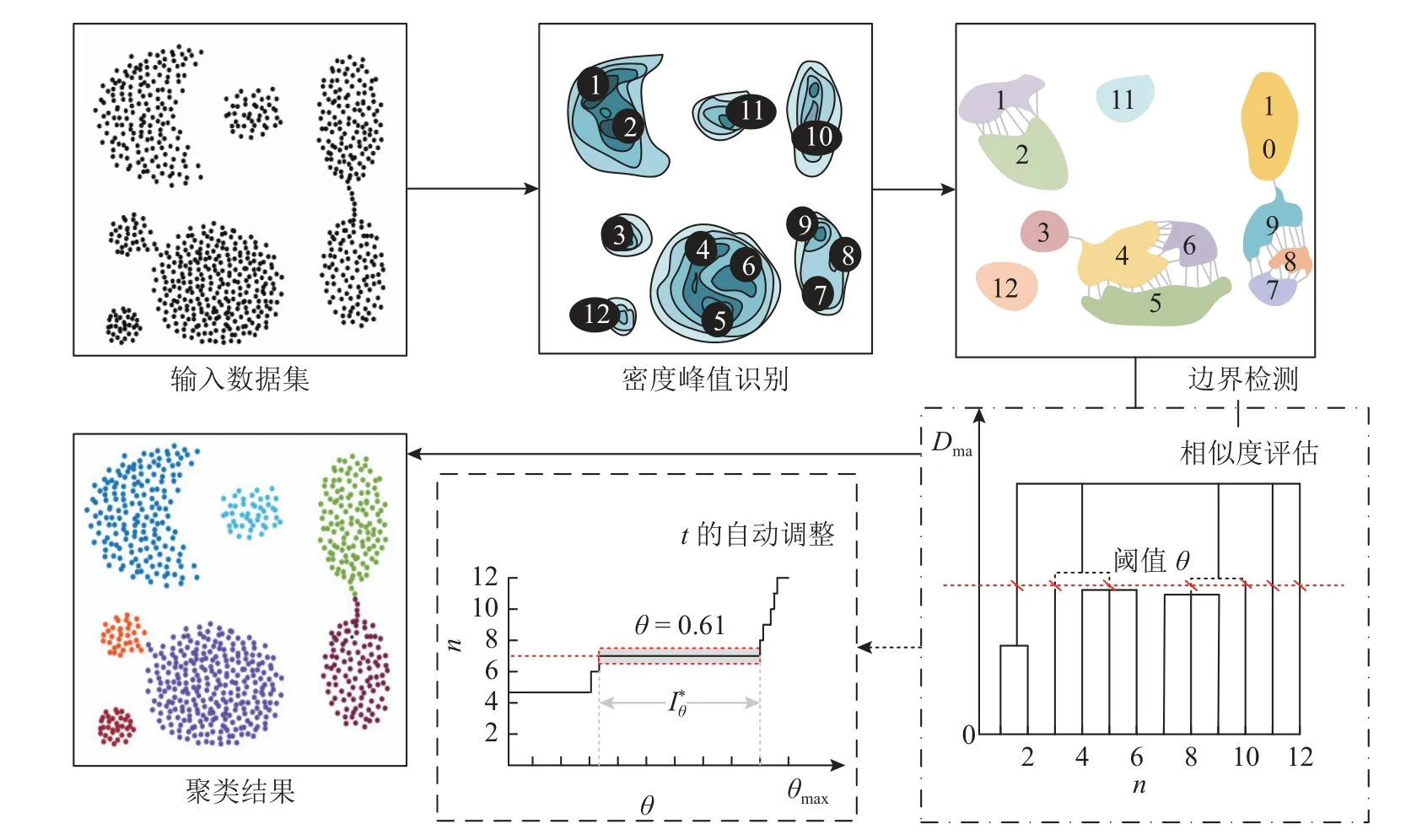
图2 改进稳定隶属度多峰值聚类过程Fig.2 Process of improved stable-membership multi-peak clustering clustering
ISMMPC 算法利用密度峰值聚类技术[15]获取区域Ag的密度峰值集合,选取最高的密度峰值作为中心点,将中心点周围未分配的数据点分配到同一聚类中形成子簇.在所有数据点分配完成后,使用边界链接的连通性来评估的内聚性.在跨簇的边界点中,将未链接的边界点 τi和最近未链接的跨簇边界点 τj关联起来,作为边界链接特定值 γ (γ ∈[0,1.0]),定量评估子簇间的相邻关联度.,判断集群内聚性.赋予每个边界点一个若高相似度的子簇链接良好,则表示具有多个高γ值的边界链接.采用马氏距离评价子簇之间的相似性,距离越近越相似.马氏距离Dma可以表示为
式中:Wγ为特征值的权重.
用nγ表示所有边界链接数量,Γ (Dma) 返回所有Dma值与Dma最大值的均一度,可以表示为
算法1 给出ISMMPC 聚类的实现过程.
第1 行是获取数据集.第2~8 行是开展每一点的k个周围点的选取,时间复杂度为O(),表示平均k个点的最近高密度点.得到每个区域的密度峰值及子簇数量,时间复杂度为O(n).第9~11 行是显示边界链接特定值的计算,定量评估子簇间的关联度,复杂度为O(nkb),其中kb=min {k/2,2lnn}.第12~16 行是计算马氏距离和估计子簇间的相似性,时间复杂度为O(n2).第17~23行是对子簇的自适应合并,得到聚类结果集C,时间复杂度为O(n2).ISMMPC 聚类的总时间复杂度为.
2.2.2 时间图卷积隐私预算矩阵的预测 图3 给出T-GCN 组成结构,T-GCN 模型可以从交通数据中学习空间特征.GRU 以和当前的流量信息作为输入,得到tg时的流量信息.该模型在捕获当前时刻的交通信息的同时,保留历史交通信息的变化趋势.假设节点5 为某轨迹点,利用GCN 模型可以得到该轨迹点与周围轨迹点之间的拓扑关系,对路网拓扑结构和轨迹上的属性进行编码,得到空间依赖关系.对节点的特征矩阵进行图卷积操作,再将结果输入GRU 中提取时序上的特征.
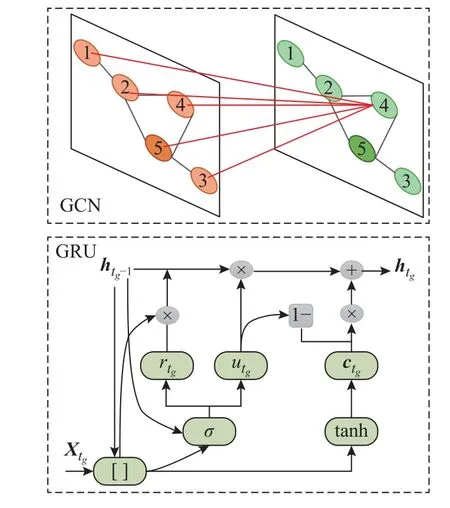
图3 时间图卷积网络模型的组成结构Fig.3 Composition structure of temporal graph convolutional network model
式中:αij=ij(ij+1)/2,ε 为总隐私预算.
结合T-GCN 模型提取数据的时间和空间特征,预测隐私预算矩阵Eij,图4 给出T-GCN 模型的时空预测过程.将获得的初始隐私预算矩阵Eij按时间顺序组织为时空序列矩阵集合Jij.将时空数据Jij输入到深度学习模型中,不断地进行T-GCN小单元的学习、训练,预测最终的隐私预算矩阵.根据在每个总数矩阵Sij中按照式(13)计算得到相应的拉普拉斯噪声添加到每个区域的轨迹信息中,对扰动后的轨迹数据进行发布.
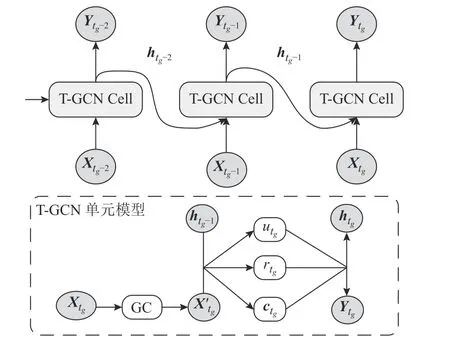
图4 时间图卷积网络模型的时空预测过程Fig.4 Spatiotemporal prediction process of temporal graph convolutional network model
3 实验分析
采用真实数据集Divvy Bikes 和T-drive 进行仿真实验,验证PPCDL 的数据有效性、时间开销,评估差分隐私的保护效果.
3.1 实验数据集
T-GCN 训练模型使用Adam 优化器进行训练,激活函数为Elu.对于输入层,将数据集的80%数据作为输入,其余数据作为测试过程的输入.将PPCDL 与DPTD[9]、LGAN-DP[10]、DPGeo[12]进行对比分析.Divvy Bikes 数据集包含了芝加哥生活中的共享单车自2015 年至2020 年骑行使用的数据,其中有每次骑行的起始点和时间戳、起始时间、起始经纬度等.T-drive 数据集包含北京市出租车的轨迹总距离约为900 万km,位置点超过1 500 万个,轨迹数据由每辆出租车的ID、时间戳、经度和纬度信息表示的GPS 位置点序列组成.在实验预处理中,数据集选用轨迹密度相对较大的区域.
3.2 评价指标
隐私保护的目的是发布有用信息,同时隐藏敏感的信息.当进行隐私保护时,既要保护用户的隐私安全,又要保证用户享受到较高的服务质量.采用3 种度量方法,量化原始数据和发布数据之间的差异.
使用均方根误差(root mean square error,RMSE),评估PPCDL 的数据有效性.RMSE 是衡量原始数据与发布数据间的差异,是评估发布数据准确性的常用方法.设隐私预算矩阵的真实值为E,预测值为,样本量为N,RMSE 越小,预测越准确,则指标的公式为
使用查询误差(query error,QE),评估差分隐私的保护效果.给定查询函数f,f(A)为查询区域A的正确结果,其中|A|为查询区域的大小.f()为有噪声的查询结果,则查询错误定义为
使用JS(Jensen-Shannon divergence)散度,评估真实轨迹和加噪后轨迹间的相似性.给定已发布的原始数据和加噪数据的概率分布函数 φ、ϖ ,φi、ωi为函数 φ 和 ϖ 的概率,则JS 散度定义为
3.3 实验结果分析
为了验证轨迹数据集获得的隐私保护效果,使用T-GCN 模型预测隐私预算矩阵,给定总隐私预算ε={0.1,0.3,0.5,0.7,0.9}.对原始轨迹数据和添加噪声的轨迹数据进行查询,得到测试数据的RMSE 误差、QE 误差和JS 散度.通过修改ε 来评估不同总隐私预算下数据集的保护程度,实验结果如图5、6 所示.
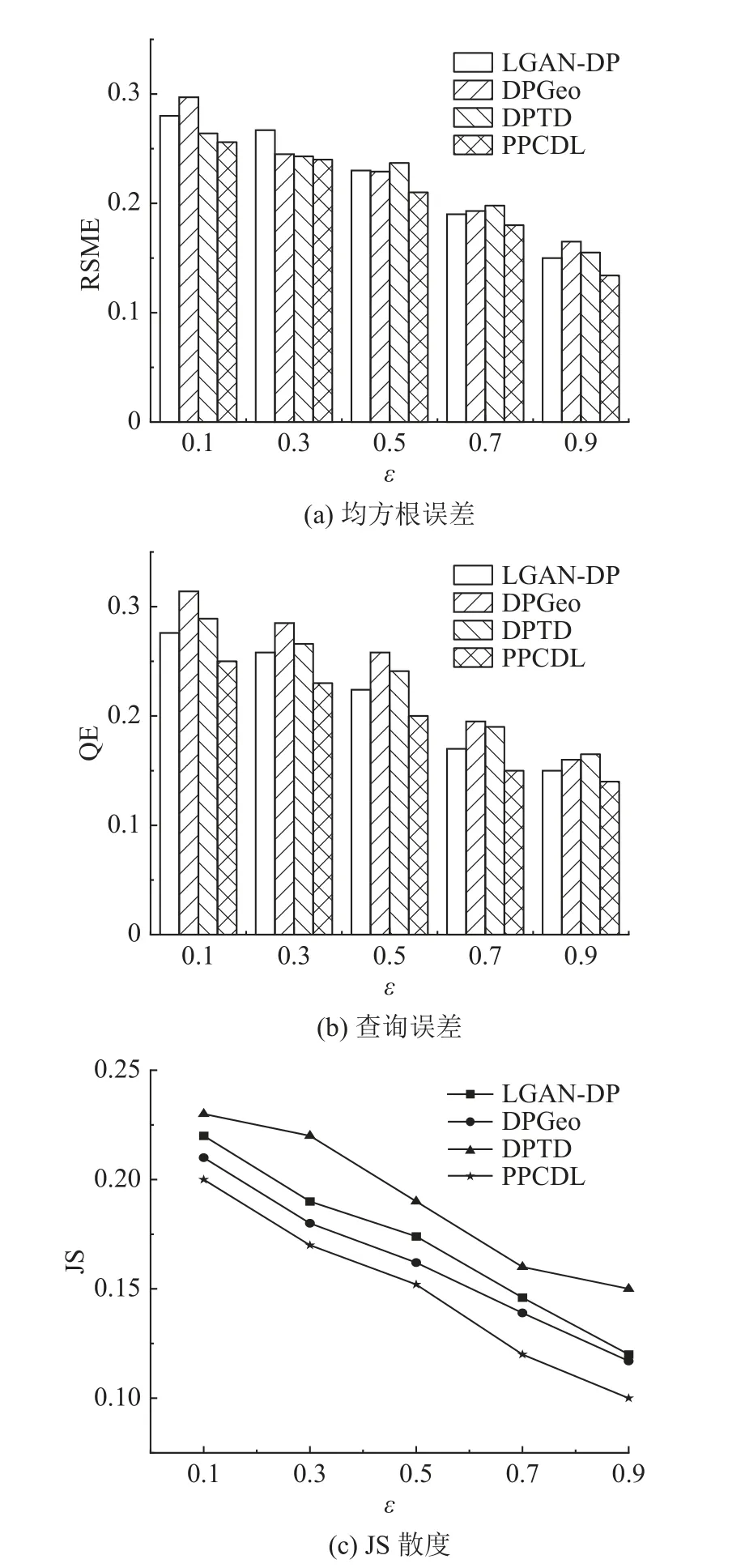
图5 Divvy Bikes 数据集上的各项指标Fig.5 Metrics on Divvy Bikes dataset
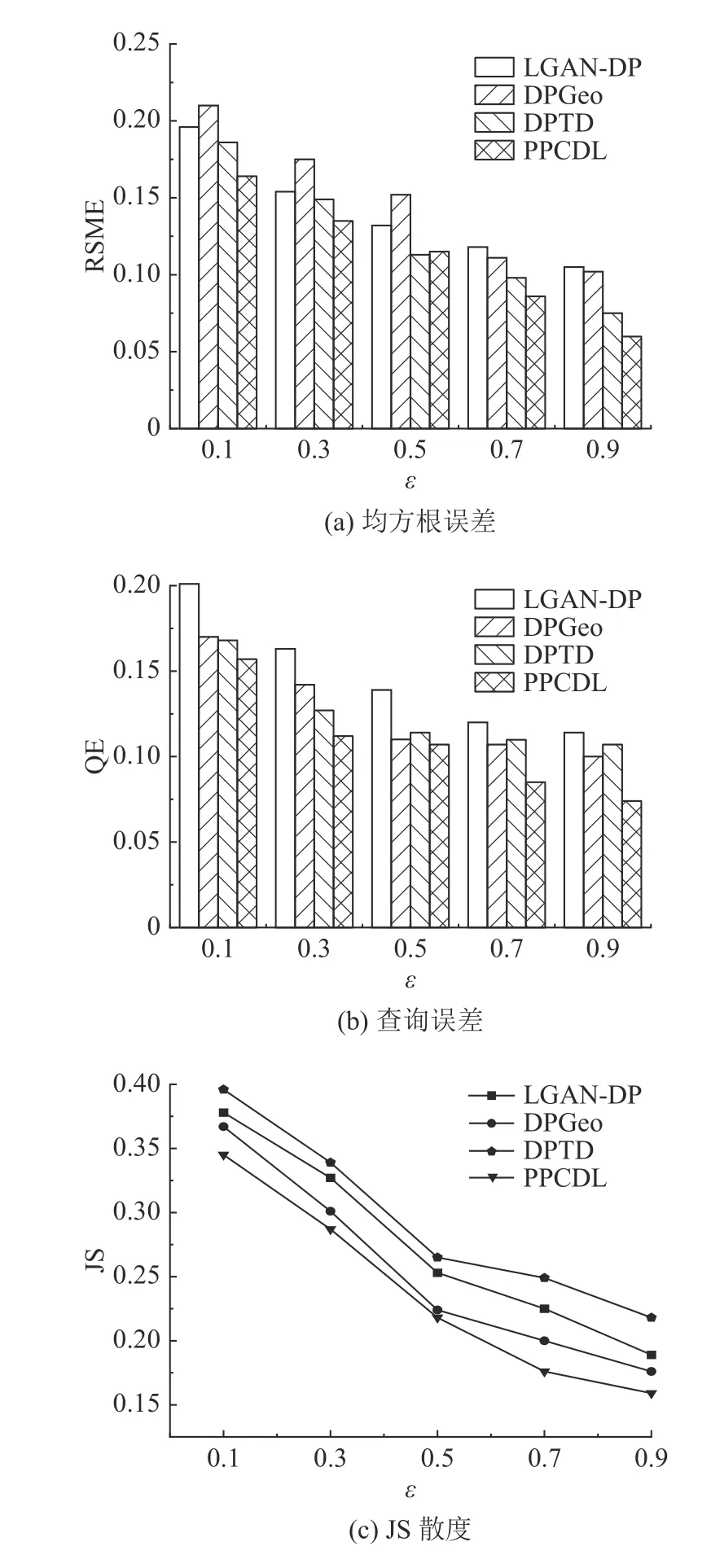
图6 T-drive 数据集上的各项指标Fig.6 Metrics on T-drive dataset
从图5(a) 可以看出,PPCDL 的RMSE 小于其他3 个机制.随着隐私预算的增加,RSME 逐渐较小.原因是 ε 的增加使得注入数据中的噪声减少,数据可用性增加.PPCDL 使用时空特征,利用TGCN 算法可以预测隐私预算矩阵,隐私预算矩阵不断迭代的过程使得预算在该轨迹区域有更合理的分配,较好地均衡了噪声误差和数据可用性.DPTD 使用前缀树存储轨迹数据,随着轨迹序列长度的增大,前缀树节点不断增加,使得实用性变差.LGAN-DP 和DPGeo 都没有精确地提供隐私预算.对比2 个数据集的RSME 结果可知,T-drive数据集上的RSME 更小.原因是在T-drive 中选择的轨迹密度相对更大,T-drive 中是北京市几个临近区域的出租车轨迹数据,Divvy Bikes 中是芝加哥市公开的共享单车行程数据,相对而言,Divvy Bikes 中的轨迹分布更加分散.PPCDL 的隐私预算预分配是按密度分配的,因此稠密区域的拉普拉斯噪声比稀疏区域大,在合理的轨迹位置添加噪声,实现了个性化的隐私保护.
从图5(b)可以看出,ε 的增加,减少了添加的拉普拉斯噪声,使得有噪声区域的查询结果逐渐向无噪声区域的查询结果趋近,所以QE 减小.对于按时间戳划分后的区域,进行聚类后的稠密区域的拉普拉斯噪声比稀疏区域大.当使用数据计算平均查询误差时,QE 随着噪声的增加而增大,降低了数据排序的一致性.PPCDL 的优势是使用聚类和T-GCN 算法可以更精确地预测隐私预算,合理地为轨迹数据添加拉普拉斯噪声,有效地实现差分隐私保护.随着 ε 的增加,PPCDL 的QE 变化慢的原因是在区域的隐私预算的预测训练过程中,训练分配的预算结果逐渐趋于稳定化,添加的噪声浮动变缓.
从图5(c)可以看出,2 个数据集上的JS 散度随着 ε 的增加而减小,原始数据的概率分布和加噪数据的概率分布越来越相似.这是因为随着 ε 的增加,添加的噪声会逐渐减小,使得轨迹间的相似度增大.较小的JS 散度可以保证较强的隐私性,对真实位置引入较大的扰动.相反,较大的JS散度通过向真实位置引入较小的噪声,保证较弱的隐私性.JS 散度结果表明,PPCDL 的数据可用性大于对比机制.
对T-drive 数据集开展划分细粒度的实验.在T-drive 数据集上设置不同间隔的5 个时间戳,设置相同的隐私预算,通过逐步加大时间戳的长度,查询当天的轨迹数据,得到指标的平均性能.从图7 可以看出,通过改变时间戳来验证划分对隐私保护的影响,PPCDL 的RMSE 误差、QE 误差和JS 散度都优于对比机制.这是因为PPCDL 合理地分配了隐私预算.稠密区域的拉普拉斯噪声比稀疏区域大.在每个位置合理添加噪声,实现了不同程度的隐私保护,提高了轨迹数据的可用性.随着时间戳的不断增大,轨迹序列长度增大,RMSE 误差呈现增大趋势,导致噪声不断增加,影响数据的可用性.在时间戳延长到一定程度后,RSME 减小,这是因为此时覆盖的轨迹序列长度比其他时间段大几倍,此时数据会受到非轨迹区域的噪声数据干扰,当计算平均指标时,RSME 会减小.对于QE 误差来说,查询密集区域位置较容易实现,但加入的噪声量较大.当计算QE 误差时,QE 随着噪声的增加而增大.由于原始数据和发布数据的差异,JS 散度随着噪声的增加而增大.当JS 散度较小时,表明该区域包含了大量不属于轨迹序列的位置.
为了验证PPCDL 的效率,在数据集中将轨迹划分成不同数量的分组,在 ε=0.1 的情况下,将PPCDL 与其他机制进行时间开销的对比,实验结果如图8 所示.图中,nt为参与训练轨迹的组数,逐步递增;t为平均轨迹生成时间,每个值重复20 次,取平均值.随着参与者轨迹数据个数的不断增加,运行时间不断增大,更大的分组数意味着更复杂的集群过程,需要更多的时间,因此平均轨迹生成时间随着分组数量的增加而增大.PPCDL 的运行时间相较于对比机制更短,得出结果的速度更快.
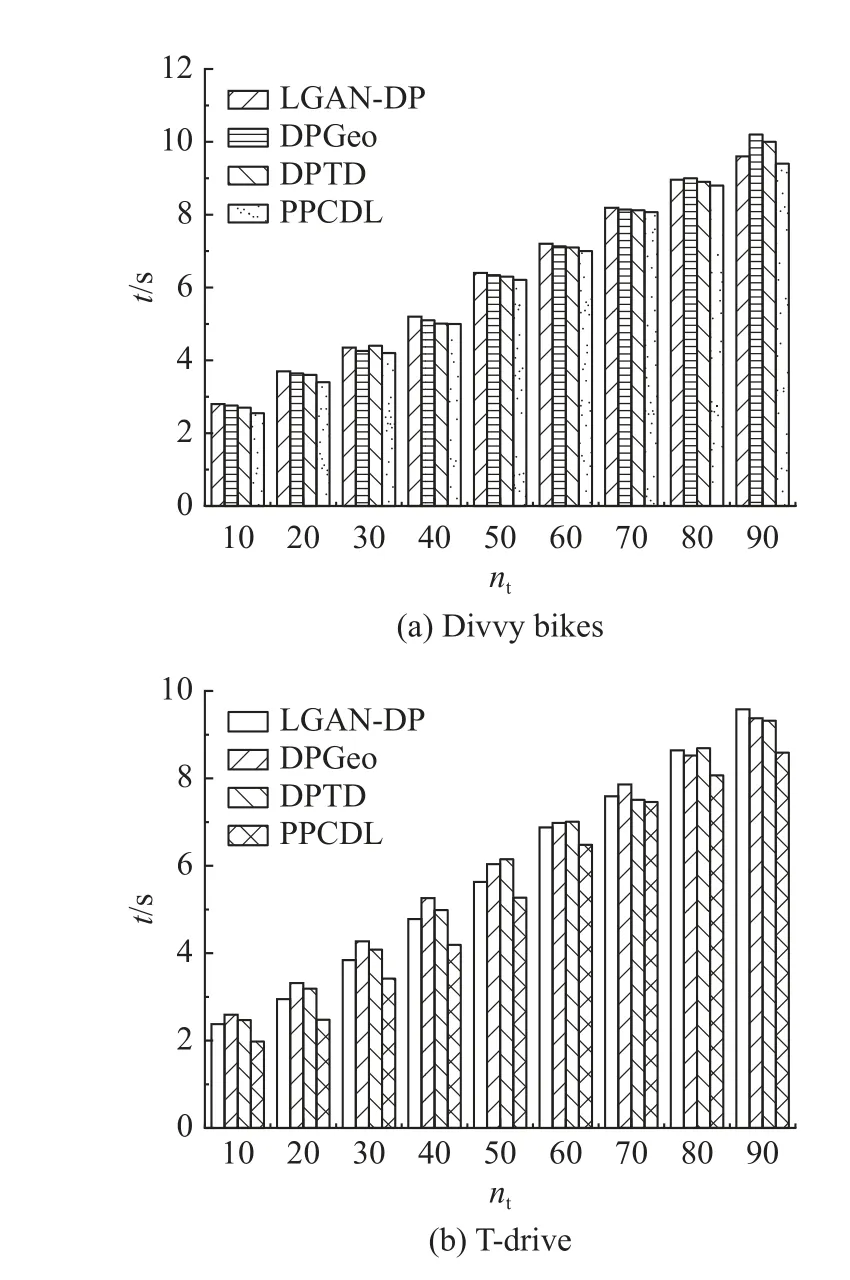
图8 不同方案的运行时间开销Fig.8 Runtime overhead for different schemes
4 结论
(1)在相同的隐私预算下,PPCDL 的隐私预算利用率和发布的轨迹数据集的有效性均优于对比机制.预测的隐私预算可以防止攻击者利用数据发布的时间差来获取真实的轨迹.
(2)在未来的工作中,将关注如何更好地对隐私预算初始化,以提升深度学习的训练速度,更好地实现车联网轨迹隐私保护.
猜你喜欢
四川党的建设(2022年8期)2022-04-28
北京航空航天大学学报(2021年9期)2021-11-02
小学生学习指导(低年级)(2020年11期)2020-12-14
读友·少年文学(清雅版)(2020年4期)2020-08-24
读友·少年文学(清雅版)(2020年3期)2020-07-24
电子制作(2019年11期)2019-07-04
作文大王·低年级(2018年10期)2018-12-06
现代装饰(2018年5期)2018-05-26
北京航空航天大学学报(2018年1期)2018-04-20
中国三峡(2017年2期)2017-06-09
