
混合采样下多级特征聚合的视频目标检测算法
2024-02-12 07:42:56秦思怡盖绍彦达飞鹏
浙江大学学报(工学版) 2024年1期
秦思怡,盖绍彦,达飞鹏
(1.东南大学 自动化学院,江苏 南京 210096;2.东南大学 复杂工程系统测量与控制教育部重点实验室,江苏 南京 210096)
视频目标检测是计算机视觉领域的一项基础任务,在社会安防、国防军事和智能交通等领域中有着广泛的应用需求[1].近年来,基于深度学习的视频目标检测算法取得了显著的进展,这些方法可以大致分为基于光流的方法[2-3]、基于视频目标跟踪的方法[4-5]和基于注意力机制的方法[6-7].基于光流的算法使用额外的光流模型,显著增加了目标检测整体模型参数量;基于视频目标跟踪的方法使用了额外的任务,而不是让网络直接检测目标.这2 种方法的速度和准确性存在很大的不平衡[8].基于注意力机制的方法考虑图像特征聚合的计算成本,序列级语义聚合算法(sequence level semantics aggregation algorithm,SESLA)[9]作为基于注意力机制的方法代表,根据区域级特征之间的语义相似性,提出长程特征聚合方案.Chen等[10]设计全局-局部聚合模块,以更好地建模目标之间的关系.Jiang 等[11]提出称为可学习的时空采样(learnable spatio-temporal sampling,LSTS)模块,用于学习相邻帧特征之间语义层次的依赖关系.现有方法大多因采用固定的采样策略,可能无法充分利用视频序列中的全局上下文信息.另外,现有算法由于无法有效、准确地融合不同的尺度和多层级的特征,常常导致目标的误检、漏检问题.
针对上述问题,本文提出混合加权采样下多级特征聚合注意力的视频目标检测网络(video object detection algorithm based on multi-level feature aggregation under mixed sampler,MMNet).本文的主要工作如下.
(1)设计混合加权参考帧采样策略(mixed weighted reference-frame sampler,MWRS),利用更有效的全局随机帧和关键帧前、后帧的信息优势,具有全局感知和上下文感知的信息增强功能.
(2)基于注意力机制,提出多级特征聚合注意力模块(multi-level feature aggregation attention module,MFAA).该模块的2 个分支分别关注不同层次的特征,针对性地对特征权重进行分配,通过特征随机失活操作提高模型的鲁棒性,聚合多层次的特征来提高识别和定位的准确率.
(3)在ImageNet VID 数据集[12]上进行实验,结果表明,所提出的MMNet 具有检测速度较快、精度较高的优点,可以较好地解决视频目标检测算法检测精度和速度不平衡的问题,证明了该方法的有效性.
1 相关工作
1.1 YOLOX-S 单阶段检测器
在视频目标检测任务中,采用基础检测器对输入的视频帧进行特征提取,得到初步的预测结果,对大量的检测结果进行初步特征选择.
基础的图像检测器主要分为单阶段和两阶段检测器.基于区域的卷积神经网络(region based convolutional neural network,RCNN)[13],提出两阶段目标检测器的基本框架.针对两阶段检测器普遍存在的运算速度慢的缺点,YOLO[14]提出单阶段检测器,不需要生成候选框,直接将边框的定位问题转化为回归问题,提升了检测速度[15].Joseph等在YOLO 的基础上进行一系列改进,提出YOLO的v2[16]和v3[17]版本.Liu 等[18]提出另一种单阶段目标检测方法——单阶段多边框检测算法(singlestage multibox detector algorithm,SSD).Yan 等[19]提出YOLOv5,设计不同的CSP 结构和多个版本,提高了网络特征的融合能力.
采用YOLOX-S 单阶段检测器作为基础检测器,因为其具有高性能、高效性和多尺度特征表示的优势.YOLOX-S 是YOLOX 系列[20]的标准化版本之一,是对YOLOv5 系列中的YOLOv5-S 进行一系列改进得到的.YOLOX-S 作为轻量级模型,在保持较高检测精度的同时,具有较小的模型体积和内存占用.YOLOX 通过使用多尺度特征表示来提高目标检测的准确性,使用解耦检测头和简化的最优传输样本匹配方案(simplified optimal transport assignment,SimOTA)技术,能够在不同尺度上检测目标物体,综合利用多层级的特征表示,使得YOLOX 在处理视频中不同尺度的目标物体时更具优势.
1.2 自注意力机制
在视频目标检测任务中,需要对基础检测器输出的粗糙的分类特征进行再细化.由于特征各个维度对目标的贡献不同,为了突出更重要的特征,抑制不太重要的特征,在网络中引入注意力机制.
注意力机制是从大量信息中筛选出少量重要信息,并聚焦到这些重要信息上,忽略大多不重要的信息.标准的自注意力机制(self-attention,SA)是注意力机制的变体,减少了对外部信息的依赖,擅长捕捉数据或特征的内部相关性[21],结构如图1(a)所示.

图1 SA 和MFAA 模块的结构Fig.1 Structure of SA module and MFAA module
标准的自注意力机制可以描述为将一组查询、键和值映射到输出.实际计算中,将一组查询、键和值分别打包为矩阵Q、K和V,矩阵由输入的特征向量X经过线性变换得到,如下所示:
式中:各个变换矩阵W可以经过网络的学习得到.
注意力函数的输出为值V的加权和,其中分配给每个值的权重由查询与相应键的softmax 函数计算[22]得到,计算过程为
式中:SA 为输出矩阵;d为Q和K中每个特征的维度,除以可以使得QKT符合N(0,1)的分布,类似于归一化,可以防止输入softmax 函数的值过大而导致偏导数趋近于0,还可以使注意力的分布更加均匀.
2 网络结构的设计
构建的视频目标检测网络MMNet 的框架如图2 所示,输入为一系列连续的视频帧,输出标记目标类别和位置的视频帧.将输入的视频帧通过混合加权参考帧采样,得到一系列随机参考帧和关键帧的前后连续帧.将得到的视频帧入到单阶段检测器YOLOX-S 中进行特征提取,输出初步的分类和回归的预测特征Xc和Xr.由于大多数初步预测结果的置信度较低,需要从特征图中选择高质量的特征.使用topK 算法,根据置信度分数由高到低排序,挑选出前750 个预测特征.使用非最大抑制(non-maximum suppression,NMS)算法[23],通过不断检索分类置信度最高的检测框,使用交集-重叠来表示2 个边界框之间的内在关联,将大于人工给定阈值的边界框视作冗余检测框删去,以减少冗余[24].将选择后的特征输入多级特征聚合注意力模块,在不同尺度上聚合分类和回归的特征后进行最终分类.

图2 MMNet 算法的网络结构图Fig.2 Structure diagram of MMNet
2.1 混合加权参考帧采样策略
研究能够平衡检测准确性和效率的采样策略,对于视频目标检测任务至关重要.主流的采样方法一般采用全局随机采样[25]或者局部采样[26].这2 种采样方法都存在因为特征捕获不全面导致的特征聚合不足的问题.全局采样方法缺乏来自相邻帧的空间和时间信息,失去了视频的时间维度优势;局部采样在目标运动速度较快或者遮挡严重的情况下,为关键帧检测提供的有效信息少.为了解决这些问题,更好地增强互补特征,设计混合加权参考帧采样策略,引入全局的特征信息和前后帧时间信息,进行特征集成增强.
MWRS 的输入为需要检测的连续视频帧.如图3 所示,MWRS 包括加权随机采样(weighted random sampling)操作和局部连续采样(local consecutive sampling)操作.

图3 混合加权参考帧采样策略的结构Fig.3 Structure of MWRS strategy
加权随机采样操作分为以下3 个步骤.
1)确定每一帧的权重.采用差值哈希算法计算每个视频帧与关键帧fk的整体图像相似度,将相似度si作为对应视频帧fi的采样权重wi,其中i为视频帧的索引值.差值哈希算法的主要流程如下:在对视频帧进行哈希转换时,通过左、右2 个像素大小的比较,得到最终长度为64 的0-1 哈希序列,计算关键帧哈希序列和其余每一帧哈尼序列的汉明距离di(Hamming distance),再利用公式si=1-di/64得到相似度.
2)计算相对采样概率.将所有帧的权重相加,得到总权重.对于每一帧,将其权重除以总权重,得到该帧的相对采样概率,计算过程如下:
式中:wi为步骤1)求得的视频帧对应的权重;Pi为每一帧的相对采样概率,每一帧的采样概率和它的权重成正比[27].
3)进行加权采样.生成kg个0~1.0 的随机数 ξ,按照相对概率依次累积判断.若随机数落在某一帧的相对概率范围内,则选取该帧为关键帧的参考帧.这样既可以引入更有效的全局特征信息来检测关键帧的目标,又可以增大模型捕捉到少数样本的概率,在一定程度上解决数据集样本不平衡的问题.
为了补充视频的连续时空信息,将当前需要检测的视频帧作为关键帧,同步进行局部连续采样操作来采样关键帧fk前、后kl个连续帧,其中k表示关键帧所对应的位置索引,k+σ 表示采样关键帧后的 σ 个连续帧,k-τ 表示采样关键帧前的 τ 个连续帧(σ +τ=kl).因为视频信息具有很大的冗余性,增加采样帧数会降低检测效率.经过实验(结果见表1)验证,取kg和kl的比值为4∶1.将2 种采样操作得到的视频帧拼接为1 个序列,再送入YOLOX-S 检测器中进行特征提取.

表1 不同采样比例在ImageNet VID 验证集上的精度Tab.1 Accuracy of different sampling ratios on ImageNet VID verification set
2.2 多级特征聚合注意力模块(MFAA)
单个的自注意力机制对当前位置的信息进行编码时,会过度地将注意力集中于自身的位置,对特征的聚合不够有效和充分.考虑到回归和分类特征对特征再细化都有所贡献,提出多级特征聚合注意力模块,提取包含相互关系的特征信息,挖掘更加丰富的特征信息,从而增强模型的表达能力.
多级特征聚合注意力模块主要包括全局信息注意力分支(global attention branch)和局部信息注意力分支(local attention branch),如图1(b)所示.
模块的输入是分类特征Xc和回归特征Xr经过图2 的全连接层(fully connected layer,FC)线性变换分别得到的,分类特征的查询Qc、键Kc、值Vc和回归特征的查询Qr、键Kr、值Vr如下所示:
分类特征通常可以提供更全面的语义信息,用于对整个视频序列中的目标物体进行分类.由于全局帧通常具有更广阔的视野和更全局的场景信息,将Qr和Kr输入全局信息注意力分支.局部信息注意力机制的目标是捕捉目标物体的局部特征和动态变化,回归特征是对目标的位置和边界框进行回归预测,可以更好地捕捉目标物体的细节和运动变化,因此将Qc和Kc输入局部信息注意力分支,利用生成的权重对Vc进行增强.
2.2.1 全局信息注意力分支 因为视频流中包含很多冗余信息,标准自注意力机制在视频目标检测数据集上往往会出现过拟合的问题.为了克服以上问题,设计全局信息注意力分支,如图1(b)的右半部分所示.在自注意力机制中加入掩码机制,从输入的分类特征的置信度得分中随机地掩盖得分,让自注意力机制不仅考虑Qc与Kc之间的相似性,而且考虑Kc的质量.执行随机失活操作,主动抛弃一部分中间层的特征值,对高注意力值进行部分惩罚,鼓励模型更多关注与目标有关的其他图像块,有助于捕捉全局鲁棒特征,以缓解过拟合问题.全局信息注意力分支的输出矩阵可以表示为
式中:dc为Qc和Kc中每个特征的维度,S为YOLOXS 检测器得到的分类初步预测结果的置信度矩阵,° 表示哈达玛乘积,drop 表示随机失活操作,Mask 表示掩码操作.
2.2.2 局部信息注意力分支 采用全局信息注意力分支,有效地减少了高注意力值的数量,在有效捕获低频全局信息的同时,对高频局部信息的处理能力不足.为了解决该问题,设计局部信息注意力分支,如图1(b)的左半部分所示.
分别聚合Qr和Kr的局部信息,为了减少参数和计算量,采用2 个深度卷积操作(depth-wise convolution,DWconv)[28]得到Ql和Kl,计算两者的哈达玛积.为了得到更高质量的权重系数,加入非线性因素,增强模型的表达能力.非线性激活Tanh函数的输出为-1~1,是以0 为中心的,并且在0 附近的梯度大,能够加速模型收敛,所以引入Tanh函数,将结果转换为-1~1 的权重系数,采用随机失活来提高鲁棒性.整个过程如下.
式中:SAlocal为局部信息注意力分支的输出矩阵,dr为Qr和Kr中每个特征的维度.
由于设计多级特征聚合注意力模块的主要目的是分类结果的再细化,只须分别计算全局信息注意力分支与局部信息注意力分支生成的权重和Vc的积,再将结果拼接在一起,得到多级特征聚合注意力模块的输出.MFAA 模块的输出矩阵为
式中:c oncat 表示拼接操作.
2.3 损失函数
视频目标检测任务中,损失函数的设计是为了在视频目标检测任务中解决不同的问题和优化目标,一般为如下形式:
式中:Lcls、Lbbox和Lobj为分别用于分类任务损失、检测框(bounding box,BBox)回归任务和目标置信度任务的3 种损失函数;α、λ 和 μ 为各个损失函数的权重参数,用于平衡不同任务的损失[26].
在采用以上通用的损失函数形式的基础上,对各种损失函数的方法进行不同的组合设计.通过实验进行比较和测试,使用二分类交叉熵损失(balanced cross entropy loss,BCE Loss)作为分类和置信度损失函数,表达式如下:
式中:y为1 时表示正样本,反之为负样本;y′为网络预测的样本输出,取值区间与y相同.
之前研究中常用的交并比(intersection over union,IoU)损失函数是基于预测框和标注框之间的交并比,在视频目标检测任务中使用,可能出现失去梯度方向,从而无法优化的情况.选用DIoU(distant-IoU)损失函数[29]作为检测框损失函数,表达式如下所示:
式中:b和bgt分别为预测框和标注框的中心点,Si为预测框和标注框交集的面积,Su为预测框和标注框并集的面积,ρ 表示欧氏距离操作,c为最小包围2 个检测框的框的对角线长度.DIoU 损失函数的惩罚项能够直接最小化中心点间的距离,解决IoU 损失函数的梯度问题.
3 实验及结果分析
3.1 实验数据集和评估标准
在ILSVRC2015 挑战赛中引入的ImageNet VID 数据集上进行模型训练与测试.ImageNet VID 数据集包含30 个基本类别,是ImageNet DET 数据集[12]中200 个基本类别的子集.具体来说,ImageNet VID 数据集包含3 862 个用于训练的视频、555 个用于验证的视频和937 个用于测试的视频,在训练集和验证集的视频帧上都被标记上真实值的检测框.训练集的每段视频包含6~5 492 帧图像,单帧图像均为720 像素的高分辨率图像,所以仅训练集就达到100 多万张图像,这种大规模的数据有利于拟合一个较好的模型,以完成视频目标检测任务.为了使数据集富有多样性,挑选静态图像目标检测数据集ImageNet DET中相同数量的对应类别的图片作为训练数据集的补充.
采用推理时每帧检测时间t作为检测速度的评价指标,t包括进行采样操作的时间.每帧的检测时间越短,表明检测速度越快.
用参数量P和浮点运算次数(floating point operations,FLOPs)作为模型复杂度的评价指标.参数量和浮点运算量越小,表明模型复杂度越低.
使用平均精度(average precision,AP)作为检测精度的评价指标,AP 指算法在某一类图像上进行检测的平均精度.在计算AP 时,需要对预测框和真实框进行匹配,按照置信度从高到低排序,计算每个置信度下的精度和召回率.对这些精度-召回率点进行插值,得到平滑的曲线,计算该曲线下的面积作为AP.
AP50 指的是计算平均精度时,使用0.5 作为IoU 的阈值.IoU 评估真值检测框与预测检测框之间的重叠程度,以确定检测结果的准确性.在目标检测任务中,AP50 常用来评估模型检测出来的物体与真实物体的重叠程度是否达到了一定的阈值.AP50 越大,表示模型的检测准确率越高.
3.2 实验细节
实验所用计算机的硬件配置如下:中央处理器(CPU)为Intel®CoreTMi7-13700F,主频为2.10 GHz;图形处理器(GPU)为GeForce RTX 4090.深度学习框架使用PyTorch 2.0.0,环境配置使用anaconda 20.04.1,操作系统为Ubuntu 18.04,CUDA版本为CUDA 12.0.
优化方法为使用随机梯度下降算法(stochastic gradient descent,SGD),采用数据集中的单个样本或一批样本的梯度来更新模型参数,适用于大规模数据集和复杂模型.SGD 算法的更新公式为
式中:ωt为在时间步t的模型参数;∇ωL(ωt;xi;yi) 为在 (xi,yi) 上损失函数L相对于模型参数的梯度;η为学习率,控制更新步长.
设置动量为0.9,利用余弦函数进行学习率的衰减.刚开始训练时,模型的权重是随机初始化的,此时若选择较大的学习率,可能带来模型的不稳定振荡,所以选择在第一轮训练预热学习率的方式.在预热期间,学习率从0 线性增加到优化器中的初始预设值0.000 2,之后学习率线性降低.
在网络的输入端采用马赛克数据增强,通过随机缩放、随机裁剪、随机排布的方式进行图像拼接.将混合加权参考帧采样策略的总采样帧数设置如下:kg=48,kl=16.用COCO 数据集预训练的权重初始化单阶段检测器YOLOX-S,将非最大抑制算法的阈值设置为0.75,对MMNet 进行微调训练.在训练阶段,训练批次为32,训练轮数为10.为了避免模型过拟合和提高准确度,从352×352到672×672 以32 步长随机调整输入图像的大小.在测试阶段,将图像大小统一调整为576×576.
3.3 对比实验结果与分析
为了验证算法的有效性,采用对比实验,与8 种先进方法的比较如表2 所示.为了排除GPU性能对速度指标的影响,在表2 中标注了T 的结果表示是在TITAN RTX 型号的高性能GPU 上得到的,未标注的结果都是在普通GPU 上得到的.
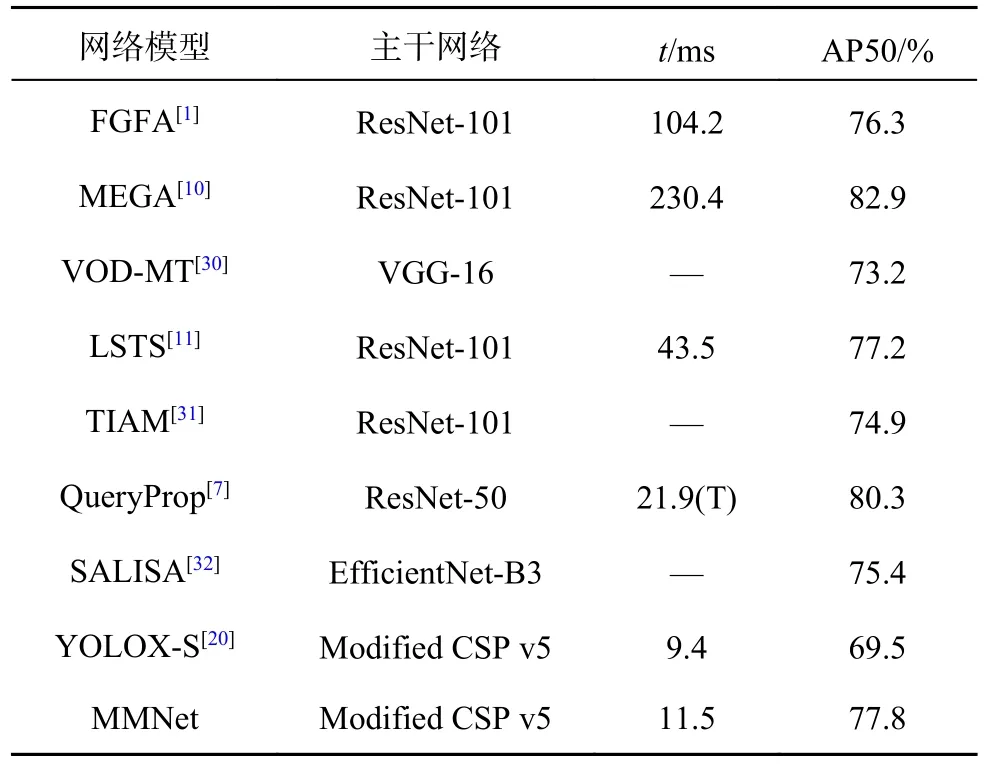
表2 不同算法在ImageNet VID 验证集上的实验结果Tab.2 Experiment results of different algorithms on ImageNet VID verification set
从表2 可以看出,MMNet 在ImageNet VID 数据集上取得了77.8%的AP50 和11.5 ms/帧的速度.与基准方法YOLOX-S 相比,速度只损失了2.1 ms/帧,精度提高了8.3%.MMNet 在精度上的表现优于FGFA、VOD-MT、LSTS、TIAM 和SALISA 算法.与检测结果更精确的MEGA 和QueryProp 算法相比,MMNet 的检测速度有大幅度的提升.结果表明,MMNet 提高了视频目标检测的精度,极大地加快了视频检测速度,证明改进算法是精确、高效的.
在ImageNet VID 测试集上,将MMNet 和YOLOX-S 算法的检测结果可视化,以更直观地分析优劣,结果如图4 所示,检测框上方显示的是目标类别和置信度.如图4(a)所示,当目标被遮挡或者目标姿势不常见时,对比算法因为没有充分利用帧间信息,可能会产生漏检的情况.如图4(b)所示,由于非目标物体和目标形状相似,或者目标运动速度较快,对比算法因为特征聚合不全面,可能产生误检的情况.本文算法利用更全面的参考帧信息,使用注意力机制聚合全局和局部特征,提取了更有效的特征,因此当关键帧出现各种混淆情况时,能够正确地检测出目标.

图4 2 种算法在ImageNet VID 测试集上的检测结果可视化对比Fig.4 Comparison of visualization results of two algorithms on ImageNet VID test dataset
3.4 消融实验
为了评估本文算法中不同模块的有效性,采用控制变量法,对混合加权参考帧采样策略和多级特征聚合注意力模块进行消融实验.所有实验均在ImageNet VID 验证集上评估.
3.4.1 混合加权参考帧采样策略 为了验证混合加权参考帧采样策略的有效性,评估在基准方法YOLOX-S 上加入混合加权参考帧采样策略对不同速度目标检测精度的影响.目标速度分为慢速、中速和快速,这3 个类别是根据相邻帧中相同目标的平均IoU 分数来分类的.慢速:IoU > 0.9.中速:0.9 ≥ IoU ≥ 0.7.快速:IoU < 0.7.表3 中最后1 行是测试整个数据集的平均精度,实验结果如表3 所示.表中,加粗字体表示指标结果最优.

表3 混合加权参考帧采样策略在ImageNet VID 验证集上测试不同速度目标的精度结果Tab.3 Accuracy result of detecting objects with different speeds of MWRS strategy on ImageNet VID verification set %
从表3 可以看出,加入混合加权参考帧采样策略后的模型相比于YOLOX-S 来说,整体检测精度均有提升,虽然对慢速目标的检测精度只有小幅度提升,但对中速和快速目标检测有明显提升.这是因为慢速目标视频的前、后帧与关键帧相比变化不大,视频帧信息的冗余程度更大,这种情况下,MWRS 策略对精度的提升效果有限.在目标移动速度较快的情况下,目标的形变和位移较大,更需要捕获更全面、更高质量的参考帧信息.该实验结果表明,MWRS 策略能够将加权随机帧和局部连续帧结合起来作为补充信息,提高了有效特征的利用率,说明MWRS 策略在提高视频目标检测精度方面是有效的.
为了评估混合加权参考帧采样策略中不同的加权随机采样和局部连续采样帧数比例的效果,在ImageNet VID 验证集上,设计5 组kg和kl的比值进行实验,结果如表1 所示.
从表1可以看出,增大kg和kl比值后模型的精度明显提升,直到比值大于4 后检测精度趋于稳定.这是因为比值越大,意味着模型能够看到更多的全局信息和长期依赖关系,这有助于模型更好地理解序列中的整体结构和上下文信息,有助于提高模型的准确性.然而,kg∶kl一旦达到一定值,进一步增大kg∶kl可能不会提高模型的性能,因为模型已经从全局帧中获取了足够丰富的全局信息.综合考虑视频模板检测的精度要求和参考帧采样的时间成本,其余实验选择采用kg∶k1=4∶1 的采样策略.
3.4.2 多级特征聚合注意力模块 为了验证多级特征聚合注意力模块的有效性,在ImageNet VID验证集上设计以下3 个对照组:一是基准方法YOLOX-S,二是在YOLOX-S 上加入标准自注意力机制SA,三是在YOLOX-S 上加入多级特征聚合注意力模块.实验结果如表4 所示.

表4 多级特征聚合注意力模块在ImageNet VID 验证集上不同速度目标的精度Tab.4 Accuracy of detecting objects with different speeds of MFAA module on ImageNet VID verification set %
从表4 可知,加入多级特征聚合注意力模块后的模型的表现远好于基准方法,且更优于标准自注意力模块对精度的提升效果,故所提的MFAA模块对视频目标检测任务能够起到更好的作用.MFAA 模块对于不同速度目标的检测精度提升效果不同:对于慢速目标,精度相对于基准算法提高了1.9%;对于中速目标,精度提高了4.2%;对于快速目标,精度提高了4%.MFAA 模块对运动速度较快的目标检测的效果提升明显,能够更好地聚焦运动目标的显著特征,抑制背景噪声干扰,提高模型最终的检测精度.MFAA 模块采用的随机失活操作强迫模型基于不完整的特征进行学习,可以帮助特征聚合从单阶段检测器中捕获更好的语义表示,有利于模型注重覆盖目标的细节信息.实验结果说明,MWRS 模块对于视频目标检测任务是有效的.
如表5 所示,在YOLOX-S 的基础上单独采用混合加权参考帧采样策略,能够在保持检测速度的同时,达到AP50=77.1%的检测精度;单独加入多级特征聚合注意力模块,能够只损失1.9 ms/帧的检测速度,达到AP50=77.5%的检测精度.共同运用2 个模块,在参数量和网络复杂度略大于基准算法的同时,运算速度略微下降,精度达到AP50=77.8%.这说明结合混合加权参考帧采样策略和多级特征聚合注意力模块,能够提高视频目标检测任务的精度.本文算法的改进使得网络能够高效地聚合特征信息.
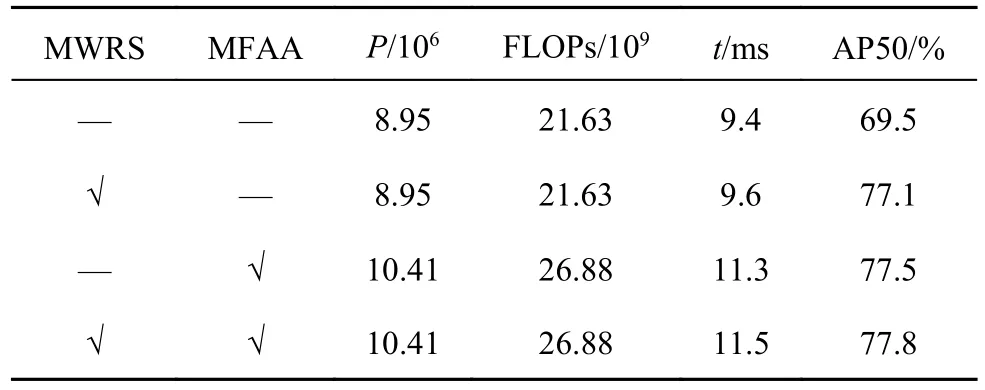
表5 所提算法在ImageNet VID 验证集上的消融实验结果Tab.5 Results of ablation experiments of proposed algorithm on ImageNet VID verification set
4 结语
本文提出基于混合加权参考帧采样策略和多级特征聚合注意力的视频目标检测网络MMNet.通过设计的混合加权参考帧采样策略,对加权全局帧和局部参考帧进行采样,为关键帧的检测提供更全面的补充信息.提出多级特征聚合注意力模块,使用双分支结构来聚合全局信息和局部信息,有助于网络捕捉到更丰富的特征信息.在ImageNet VID 数据集上的实验结果表明,MMNet 的检测精度为77.8%,在一定程度上缓解了由于目标遮挡、罕见姿势或者动态模糊等带来的漏检和误检问题,检测速度为11.5 ms/帧,速度远超大部分视频目标检测算法,在确保检测精度的情况下满足了实时性的要求.MMNet 存在使用的数据集检测目标种类不多和难、易样本数量不平衡问题,后续将在更多的视频数据集上进行研究,设计新的更适合视频目标检测任务的损失函数,提高算法的鲁棒性.
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09 18:39:41
疯狂英语·新策略(2019年10期)2019-12-13 08:43:28
当代陕西(2019年10期)2019-06-03 10:12:04
电子制作(2018年11期)2018-08-04 03:25:38
数学小灵通·3-4年级(2017年9期)2017-10-13 08:10:54
传媒评论(2017年3期)2017-06-13 09:18:10
第二课堂(课外活动版)(2016年2期)2016-10-21 16:58:54
测绘科学与工程(2016年5期)2016-04-17 06:51:15
电子设计工程(2015年3期)2015-02-27 12:03:45
河南科技(2014年23期)2014-02-27 14:19:15
