
基于多模态融合的开放域三维模型检索算法
2024-02-12 07:43:06毛福新杨旭程嘉强彭涛
浙江大学学报(工学版) 2024年1期
毛福新,杨旭,程嘉强,彭涛
(1.天津职业技术师范大学 工程实训中心,天津 300222;2.天津华大科技有限公司,天津 300131;3.天津职业技术师范大学 汽车与交通学院,天津 300222)
近年来,越来越多的工作者开始使用深度学习方法处理三维模型数据.与传统非深度学习的三维模型算法相比,基于深度学习的方法在准确率及各项指标上具有更好的表现,泛化能力更强,能够处理更复杂的问题,在实际应用中更具有可行性.目前已有众多基于深度学习算法处理不同格式三维模型数据的研究,如使用三维模型多视图作为输入的MVCNN[1]算法、用于处理三维模型点云数据的PointNet[2]算法、处理三维网格数据的MeshNet[3]算法等.为了进一步提升算法的性能,许多研究开始转变为挖掘三维数据中的更多信息,如KD-Networks[4]算法使用kd-tree 的树状结构探索点云模型的结构,SeqView2Seq-Labels[5]算法使用序列模型探索三维模型多视图数据之间的视图关联性.Li 等[6]发现单一模态下的三维模型表征能力是有限的,因此三维模型算法的研究方向逐渐转变为融合多模态的数据以获得更多信息.鉴于自然语言处理领域中Transformer模型[7]在各项任务上的优秀表现,Dosovitskiy 等[8]将其迁移至计算机视觉领域中,用于处理图像和三维模型数据.
与此同时,Feng 等[9]开始研究基于开集数据的三维模型算法.目前已有算法大多是基于闭集数据的,而在闭集数据上的研究成果难以应用于开集数据,在面对未知类的三维模型时难以发挥其优势,因此现有算法在开集数据上的准确率及各项指标往往较低.考虑到三维模型在多个领域的发展趋势,将来会有更多新类型的三维模型参与到应用中,因此开放域下的三维模型算法研究具有重大意义.
针对开放域下未知三维模型数据的表征及检索问题,本文提出开放域三维模型检索算法.算法充分挖掘多模态信息语义的关联性和一致性,以无监督方式探寻未知样本间的类别信息,并在网络模型的参数优化过程中引入未知类信息,促使网络模型在开放域条件下具备更好的表征及检索性能.算法基于Transformer 注意力机制实现了多模态数据的层级化融合,利用多模态数据的多元信息和多角度表征能力实现了更高效的模型特征.在对开放域类别信息的探索中,算法利用高效的表征能力探索未知数据分布,并利用探索信息实现模型参数的再次优化,强化了算法的表征能力.
1 相关工作
目前的三维模型检索算法主要分为3 类:基于形状的三维模型检索、基于视图的三维模型检索和基于多模态融合的三维模型检索.下文将对上述3 类算法中的典型工作进行介绍.
1.1 基于形状的三维模型算法
Osada 等[10]提出基于三维模型形状分布的算法,该研究提出计算任意三维多边形模型形状特征的算法.Hedi 等[11]提出适用于非刚性模型和局部相似模型的三维目标的匹配算法,该算法使用在特征点周围提取的三维曲线来表示模型的曲面.随着深度学习领域的发展,许多基于深度学习的算法被提出.Avetisyan 等[12]提出端到端三维模型检索的方法,该方法将不完整的3D 扫描模型转换为具有完整对象几何结构的CAD 重建模型.
1.2 基于视图的三维模型算法
Sarkar 等[13]提出新的基于多层高度图(multilayered height-maps,MLH)的三维形状全局表征算法,该方法中视图合并体系结构的引入融合了来自多个视图的视图关联信息.Yang 等[14]利用关系网络学习多视图之间的局部关联,采用增强模块作为网络中的关键结构,通过建模不同区域之间的相关性来增强多个视图的信息.Huang 等[15]提出新的基于视图的权重网络(view-based weight network,VWN),用于获取三维形状表征,其中基于视图的权重池层被设计用于特征聚合.与基于多视图的方法相比,Sfikas 等[16]提出基于全景图的卷积神经网络算法,目的是通过使用三通道的全景图像构建增强图像表征,在捕获特征连续性的同时减少冗余信息.
1.3 基于多模态融合的深度学习算法
Pérez-Rúa 等[17]提出新的多模态融合网络结构,利用神经网络的方法指导融合操作.该方法利用网络模型对各模态之间不同层次的输出进行评价,使用评价结果指导多模态融合进程.Zhang等[18]提出基于稀疏表示的多模态融合算法,与传统的假定基函数的多尺度变换算法不同,基于稀疏表示的融合算法从1 组训练图像中学习过完备字典(over-complete dictionary)进行图像融合,实现了对源图像更加稳定和有意义的表示.Hou 等[19]提出多模态融合算法,算法采用多项式张量池(polynomial tensor pooling,PTP)结构融合多模态特征,并以PTP 为基本单元建立层次多项式融合网络(hierarchical polynomial fusion network,HPFN),递归地将局部关联信息进行传递,获得全局关联信息.
2 基于多模态融合的开放域三维模型检索算法
本文算法的网络结构如图1 所示.网络使用无监督方式学习未知类信息,以提升开放域条件下的检索性能,共包括以下3 个子网络.1)单模态特征提取网络:实现不同模态数据的向量化,网络分为多个不同的支路,用于从对应模态的三维模型数据提取特征向量.2)多模态融合网络:采用改进的Transformer 解码器逐步融合多模态信息,当面对未知样本时,利用多模态融合信息可以有效地提升三维描述符的表征能力.3)开放域的检索模块:利用无监督的分类模型实现对未知数据的类别探索,通过迭代实现模型参数的优化,使得网络模型在开放域条件下获得更好的检索性能.
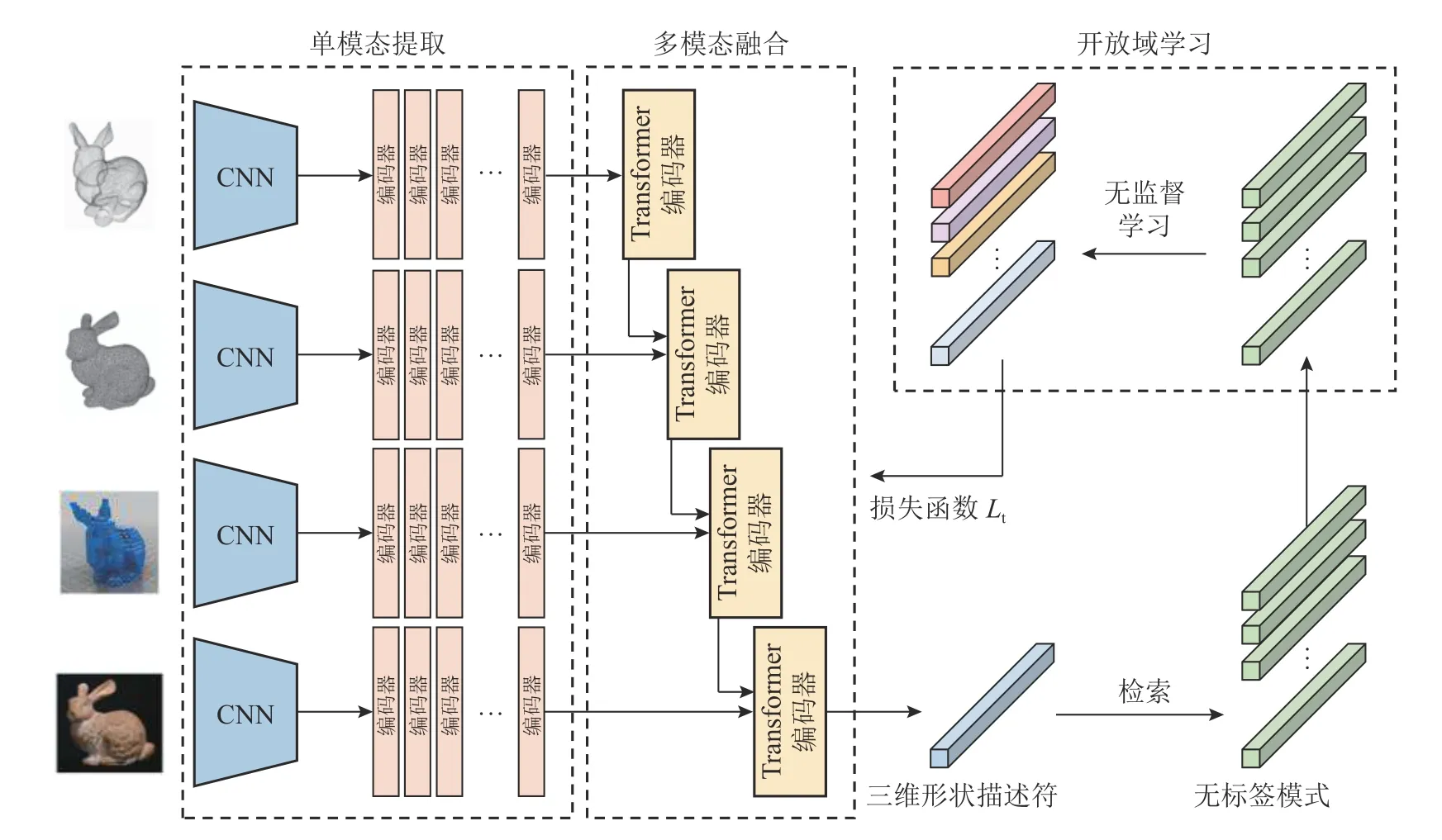
图1 基于多模态融合的开放域三维模型检索算法的原理图Fig.1 Schematic diagram of open domain 3D model retrieval algorithm based on multi-modal fusion
2.1 单模态特征提取网络
单模态特征提取网络的结构如图2 所示.该网络用于处理不同模态的三维模型数据,包括多视图、点云、网格和体素数据.设置4 个支路用于分别提取不同模态的特征向量,其中多视图支路采用图像处理网络VggNet[20],多视图特征定义为Fi.点云支路使用VoxNet[21]提取模型的局部特征Fp.网格支路使用MeshNet[22]提取特征向量Fm,体素支路使用三维卷积神经网络提取特征,对应特征定义为Fv.在获得作为各模态的特征向量后,在每个支路后端分别设置多层堆叠的Transformer 编码器结构,用于学习三维模型模态内的关联信息,并采用该结构更新特征向量.每层编码器都包含2 个子层,分别为自注意力层和前馈网络.
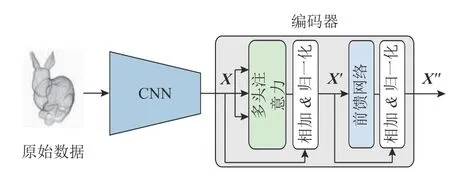
图2 单模态特征提取网络Fig.2 Single mode feature extraction network
自注意力层的网络结构由全连接层(fully connected layer)和归一化点乘注意力机制(scaled dotproduct attention)构成.由全连接层将输入特征X分别映射为归一化点乘注意力机制的3 个输入——查询(query)向量、键(key)向量和值(value)向量,分别记为Q、K和V.归一化点乘注意力机制的过程可以表示为
式中:A ttentionscaled(·) 为归一化点乘注意力机制,X′为经注意力机制更新后的特征向量,d为特征向量的维度,S oftmax(·) 函数能够将向量中的元素映射至0~1.0,对数值进行归一化.归一化点乘注意力机制将Q和K中的向量逐一点乘并进行归一化,得到输入特征之间的相关矩阵,再使用相关矩阵与值向量相乘,对输入特征向量进行更新.
前馈网络由全连接层和激活函数组成,用于更新归一化点乘注意力机制输出的特征向量X′
.前馈网络的计算过程可以表示为
式中:W1、b1、W2和b2为前馈网络中的可学习参数,用于对特征向量进行线性变换;X′′为前馈网络输出的特征向量;m ax(0,XW1+b1) 为激活函数的计算方式,激活函数为ReLU 函数.
2.2 多模态特征融合网络
多模态特征融合网络的结构如图3 所示.该网络由多层堆叠的特征融合模块构成,特征融合模块由Transformer 解码器结构改进而来,用于融合2 个模态的特征向量.特征融合模块的数量应与网络模型输入的模态数量相同,定义特征融合模块的数量为h.特征融合模块的运算过程可以由以下公式表示:
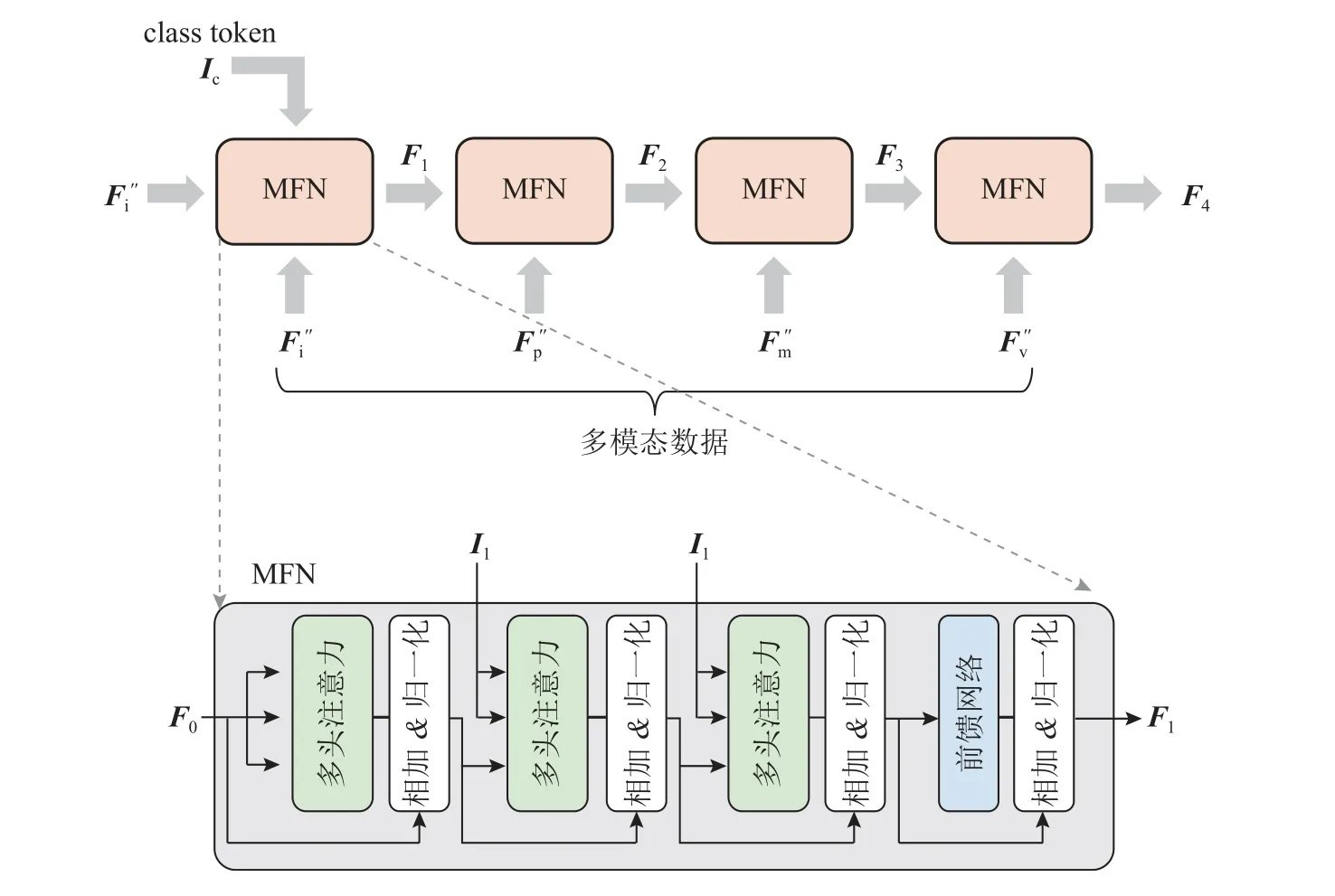
图3 多模态特征融合网络Fig.3 Multi-modal feature fusion network
式中:t为特征融合模块的层数;Ft为第t层特征融合模块输出的特征向量;Ft-1为t-1层的输出;It∈RNd为特征融合模块第t层的输入,是特征提取网络对应支路的输出,其中N为特征向量的数量,d为特征向量的维度.
考虑到基于Transformer 的BERT 算法[23]在输入数据中加入class token,专门用于进行分类任务,以消除网络对某个样本的偏向性.鉴于BERT算法在表征任务上的先进性,本文算法设置了class token 用于分类.当t=1 时,当前特征融合模块为初始层,不存在t-1 层的输出,此时设置F0为class token 和I1拼接后的组合,记为F0∈R(N+1)d.网络最终层输出Fh中对应class token 位置的特征向量为三维模型的描述符.
在多模态融合网络后设置分类器,采用融合特征和样本标签计算交叉熵损失,根据梯度反向传播优化网络模型中的参数.分类器由2 层全连接层及激活函数组成,分类过程可以表示为
式中:p为分类器输出的分类结果;W3、b3、W和b4为分类器中的可学习参数;Fh为多模态融合网络输出,Fh[0:1] 表示Fh中的第1 个特征向量;max(0,·)函数为激活函数ReLU,用于增强网络模型处理非线性问题的能力.
2.3 基于无监督算法的开放域学习
面对开放域的数据集仅使用带标注的已知样本进行训练,网络模型难以学习和提取未知类样本的特征.本文借鉴无监督算法以学习未知样本信息,在多模态融合的基础上进一步提升网络模型对未知样本的检索能力.
根据已标注数据集对网络模型进行训练,得到预训练模型.使用预训练模型提取所有未知样本的特征,采用无监督算法对特征向量进行聚类,得到未知样本的聚类结果及聚类中心.设置距离阈值,选取与类中心距离低于阈值的样本,将聚类结果作为伪标签,用于进一步训练网络模型,其中距离度量采用余弦距离进行计算.对于得到的聚类中心,定义为Ic∈RCd,其中C为未知样本类别的数量.将class token 由随机初始化的嵌入替换为聚类中心,此时多模态特征融合网络的输入为F0∈R(C+N)d,融合网络的输出为Fh∈R(C+N)d.将Fh中的前C个特征向量进行拼接,并作为三维模型的描述符,记作Fs∈RCd,用于进行检索任务.
利用无监督算法逐步探索未知样本类别信息,为样本生成伪标签,设置相应的损失函数,对模型进行多次优化.损失函数可以表示为
式中:fs为三维模型的描述符;ti为样本的伪标签,当输入样本属于第j类时tj=1,否则tj=0,此处伪标签由无监督算法给出;c lassifier(·) 为分类器,计算方式见式(4),其中Softmax 操作的第i个输出项表示为S oftmax(·)i.
3 实验结果与分析
3.1 实验数据集
实验采用的开放域数据集由开源数据集Model-Net40 样本组成,如图4 所示.ModelNet40 数据集包含40 个类别的样本及样本对应的标签,含有桌子、椅子、飞机、轿车等.整个数据集共包含12 311个三维模型,其中训练集中包含9 843 个三维模型,测试集中包含2 468 个三维模型.将Model-Net40 数据集按类划分为2 个子数据集,每个子数据集分别包含不同的20 个类的三维模型,舍弃其中一个子数据集的标签并将其作为开放域数据集的未知类数据,另一个包含标签的子数据集作为开放域数据集的已知类数据.

图4 ModelNet40 数据集的三维模型数据Fig.4 Three-dimensional model data of ModelNet40 datasets
3.2 评价指标
采用的检索性能评价指标包括全类平均正确率(mAP)、最近邻(NN)相似度、归一化折损累计增益(NDCG)和平均归一化检索秩(ANMRR).前3 个指标越大,则方法表现越好;最后一个指标越小,则方法表现越好.为了评估算法在开放域上的性能,在未知类数据集上进行实验,计算各项检索指标.mAP 是综合性量化指标,综合了所有检索结果的平均精确率.NN 是指在检索结果中与查询模型相似度最高的三维模型的检索精度.NDCG 对检索结果中排名靠后的样本赋予较小的权重,因为排名靠后的三维模型相似度低,基本不具有参考意义.ANMRR 为基于排序的度量指标,考虑了实际检索结果中相关对象的排序信息.
3.3 对比实验
为了验证本文算法在开放域条件下的有效性和性能先进性,选取当前主要的三维模型表征模型进行对比实验.所选取的方法包括基于点云、基于多视图、基于网格和基于体素的三维模型算法.
检索实验的各项指标如表1 所示.对比方法中基于点云的经典方法PointNet 取得了81.72%的mAP 指标,经典多视图方法MVCNN 取得了83.86%的mAP 指标,基于网格的方法MeshNet 取得了82.15%的指标,基于体素的方法3D Shape-Nets 取得了71.41%的指标.其中基于多视图的算法GVCNN 考虑了视图之间的关联信息,强化了三维描述符的表征能力,取得了84.94% 的指标值,与MVCNN 相比提升了1.08%.相较于体素、网格及点云模态,多视图模态通常会带来更好的检索性能,主要原因在于前几种模态直接处理三维模型的原始表示,只具备局部几何信息,没有考虑全局相关性,缺少一些全局信息,实际三维模型的表征能力不佳.多视图通过从多角度获取视图,不仅能够捕获局部信息,而且具有紧凑的全局信息,二者相辅相成.多视图模态存在一些缺点,如缺少三维模型的一些几何信息.采用多模态融合的方式,可以充分利用不同模态所特有的显著信息,能够明显地提升检索性能.
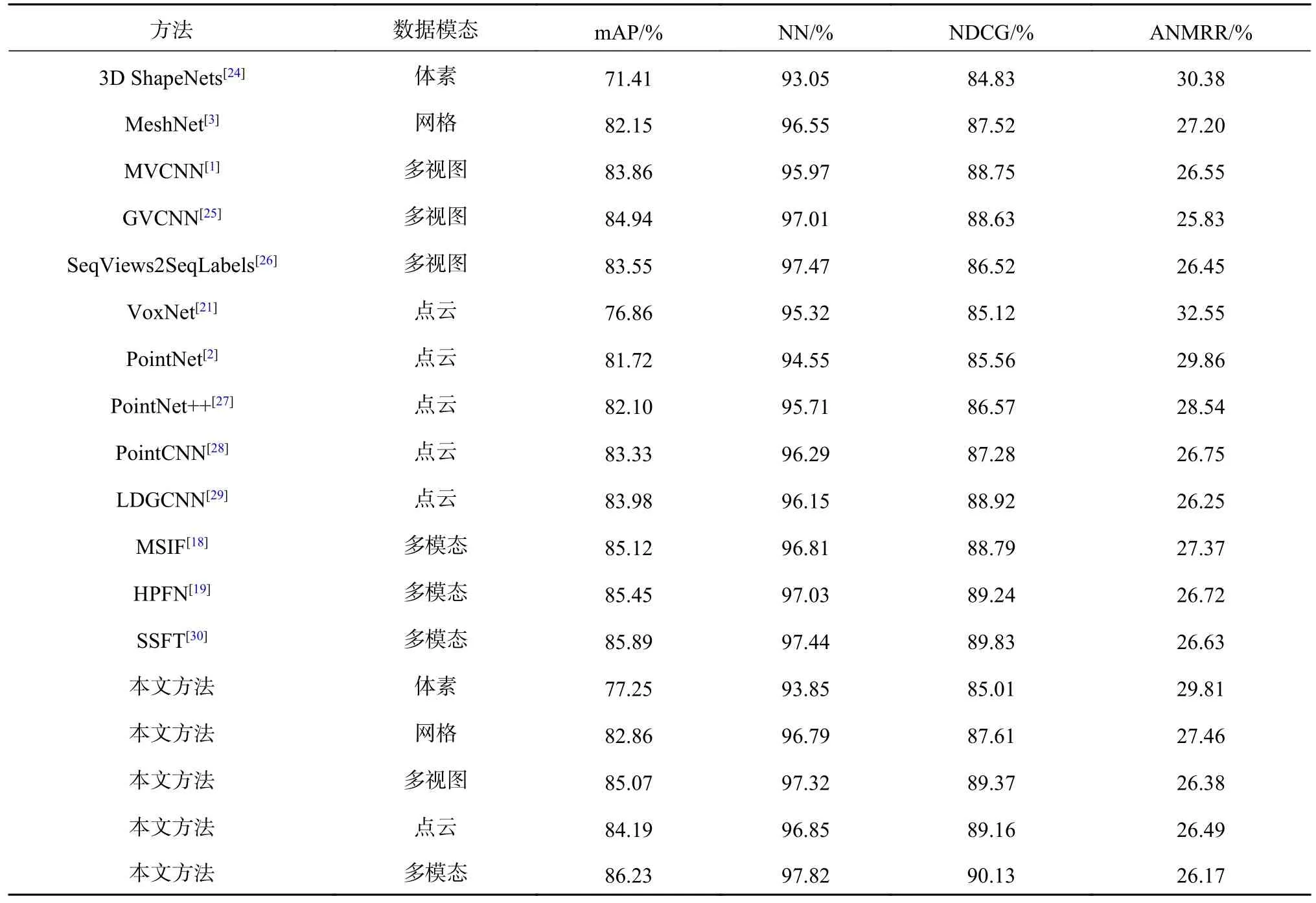
表1 各类算法在未知类数据集的检索性能Tab.1 Retrieval performance of various algorithms in unknown class data sets
使用编码器更新特征间关联性,借助多模态融合及无监督学习带来的信息优势,在开放域条件下取得了优秀的检索性能.本文算法的mAP 指标为86.23%,与之前的最佳方法GVCNN 相比提升了1.29%,在对比实验中实现了最佳的检索性能,验证了本文算法在检索性能上的先进性.从实验结果可知,即使只采用单模态形式,本文方法的检索性能也比相应模态的方法更好,主要原因是采用无监督算法能够显著提升模型在开放域上的性能表现.
3.4 消融实验
为了验证本文网络模型各模块的有效性,评估各模块对网络模型检索性能的贡献,开展消融实验,其中对比的模块包括编码器、解码器和无监督学习.消融实验数据如表2 所示.
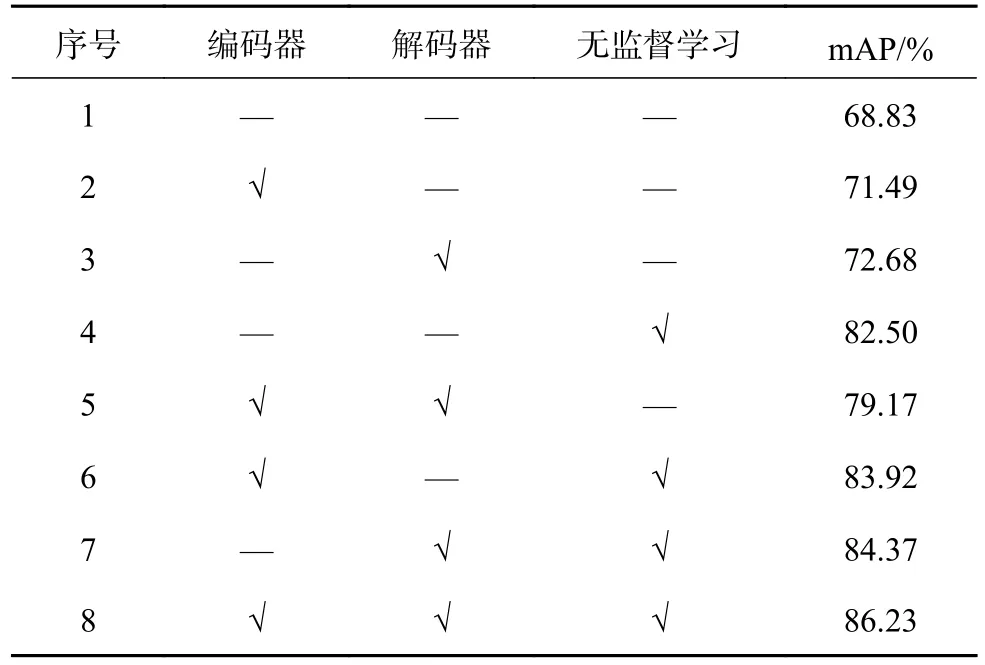
表2 提出算法在不同网络结构下的检索性能Tab.2 Retrieval performance of proposed algorithm in different network structures
实验结果如表2 所示.表中,“√”表示使用该网络结构.由于编码器的输入与输出格式一致,去除编码器不影响后续网络的运行.若不使用编码器,则将原编码器输出直接输入至后续网络中.解码器作为多模态融合模块,若不使用解码器模块,则采取拼接的方式融合多模态特征.当不采用无监督学习时,仅使用已标注数据集对网络模型进行训练,随后直接使用网络模型在未知类数据集上进行检索实验.
从表2 可知,编码器和解码器将网络模型的mAP 指标分别提升了约3%和4%.编码器模块可以学习三维模型模态内的关联信息,挖掘模态显著性特征.解码器模块相较于简单的拼接方式,可以高效地融合多模态特征,不仅剔除了表征数据的冗余信息,而且能够获得更加鲁棒的特征向量.引入无监督学习提升了约14%的mAP 指标,说明使用无监督算法学习未知类样本信息,可以大幅提升网络模型在开放域上的检索性能.当使用多个模态功能时,mAP 指标进一步提升,说明不同模块之间不会产生副作用,相反,均会对整体网络产生积极作用,提升最终性能.
3.5 编码器参数实验
在单模态特征提取网络后端设置多层堆叠的编码器结构,用于学习三维模型模态内的关联信息.为了验证编码器的层数设置对网络模型性能的影响,开展编码器参数实验.
实验结果如表3 所示.表中,第1 列为编码器层数,分别设置2~10 层的编码器进行实验.网络模型在设置5~8 层编码器时mAP 指标均达到约85.8%,当前层数能够达到较好的网络模型性能,继续增加编码器层数将增加不必要的计算量.原因是编码器中注意力机制的目的是实现对冗余信息的剔除,但是当编码器层数过多时,往往会由于q和v的向量积操作而造成数据的平均化,降低数据的区分性,导致检索性能变差,因此网络模型的检索性能整体上随着编码器层数的增加而提高.增加编码器带来的性能提升有限,但会造成计算量的增加,因此需要考虑增加编码器所带来的计算量,选择适当的编码器参数进行实验.
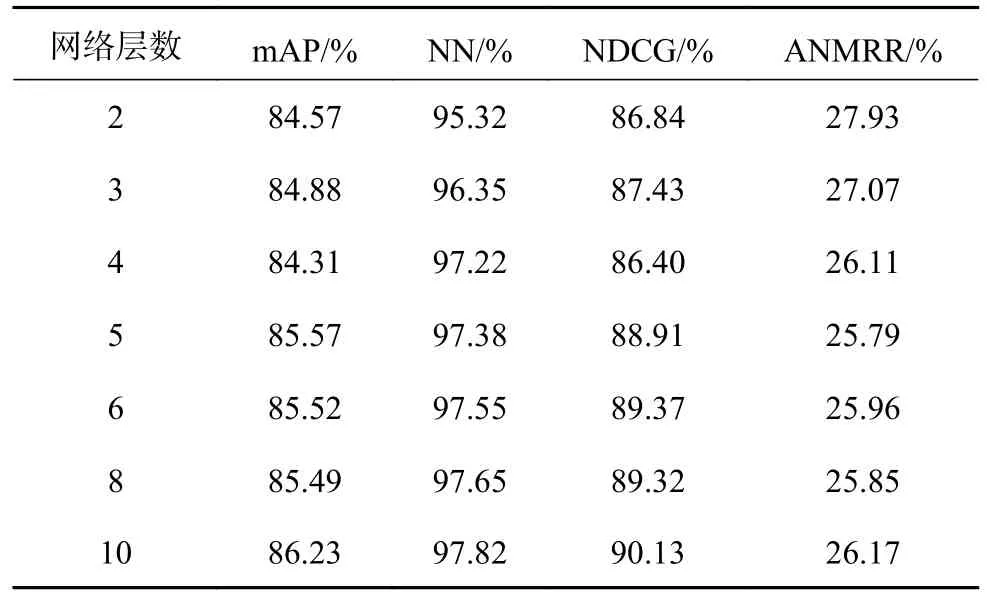
表3 提出算法在不同编码器层数下的检索性能Tab.3 Retrieval performance of proposed algorithm under different encoder layers
3.6 无监督算法的对比实验
采用无监督算法生产样本的伪标签作为分类参考,以实现网络参数的优化.其中无监督算法选择了常见的K-means 方法[31].为了探究聚类方法对网络模型检索性能的影响,开展无监督算法间的对比实验.
实验设置的无监督算法包括K-means、分层聚类、DBSCAN、Canopy 和高斯混合模型(GMM).实验结果如表4 所示,采用K-means 算法取得了最高的指标,其中mAP 为86.23%,而其余无监督算法的mAP 均低于86%.由实验数据可知,不同的无监督算法对网络模型的检索性能会产生一定的影响,采用朴素的聚类方法难以获得未知类的信息,因此需要选择更合适的算法用于学习未知类样本.
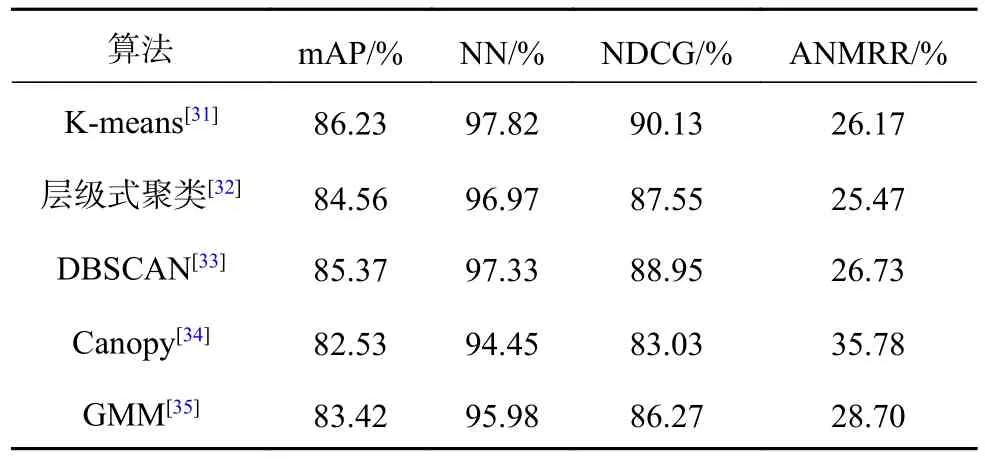
表4 提出算法在不同无监督算法下的检索性能Tab.4 Retrieval performance of proposed algorithm under different unsupervised algorithms
3.7 多模态表征对比实验
利用多模态融合得到表征能力更强的三维模型描述符,以提升检索性能.为了验证多模态对三维描述符表征能力和网络检索性能的影响,开展多模态表征对比实验.
实验结果如表5 所示.表中,第1~4 行展示了单模态输入时网络模型的检索性能;第5、6 行展示了双模态输入时网络模型的性能,其mAP 指标均值比单模态mAP 指标高约3%;最后1 行展示了使用全部模态时网络模型的检索性能,达到86.23%的mAP.整体而言,网络模型的检索性能随着输入的模态数量增加而提高,验证了采用多模态信息提升开放域下检索性能的思路的正确性.
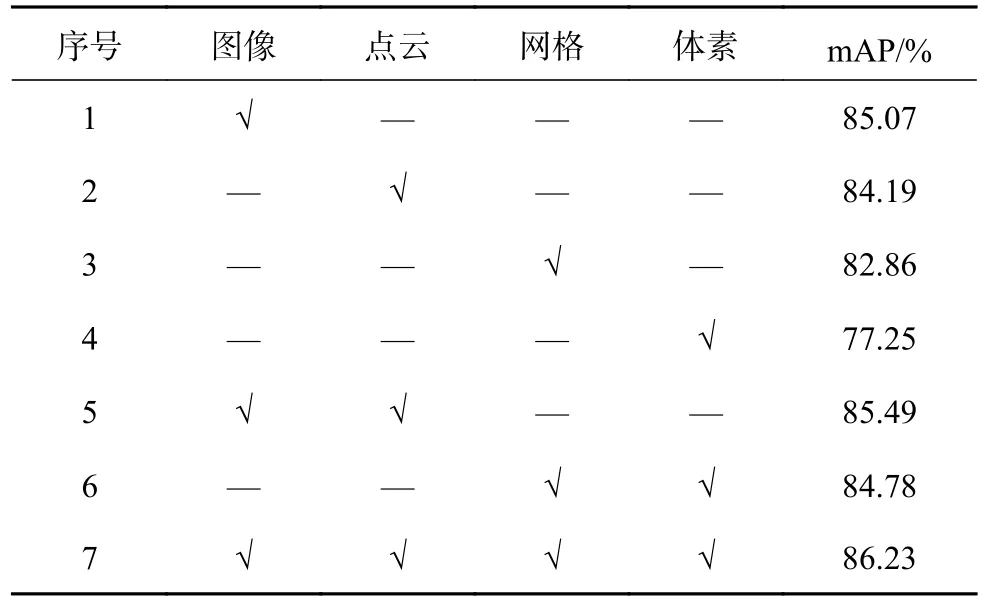
表5 提出算法在不同模态输入下的检索性能Tab.5 Retrieval performance of proposed algorithm under different input modalities
考虑到采用层级化的多模态融合网络,用于逐步融合各模态信息,该结构导致不同模态进行融合的顺序不同.为了探究多模态融合网络的输入顺序对网络模型性能的影响,开展不同融合顺序下的性能对比实验.
实验结果如表6 所示.表中标注了不同模态的融合顺序,由1~4 的序号表示.4 个模态具有24 种不同的融合顺序,由于篇幅原因无法完全展示,如表6 所示为部分融合顺序时的网络模型检索指标、最低和最高检索性能时的指标及对应的融合顺序.从表6 可知,不同的融合顺序对网络模型性能产生的影响较小,最低和最高检索性能时的mAP 指标分别为85.14%和86.23%,不同融合顺序导致的性能误差小于1.09%,因此可以验证融合顺序对网络模型性能的影响较小.

表6 提出算法在不同融合顺序时的检索性能Tab.6 Retrieval performance of proposed algorithm in different fusion sequences
3.8 可视化分析
为了体现本文方法在检索任务上的优越性,开展可视化实验.采用t-SNE(t-distributed stochastic neighbor embedding)方法进行可视化[36],具体而言,使用t-SNE 方法将数据集中所有样本的高维特征进行降维,以获得每个样本的二维表示,近似地展示高维特征的分布情况[37].为了验证开放域条件下的检索性能,提取无标签数据集内的样本特征,其中包含20 类的三维模型样本.
如图5(a)所示为不进行开放域学习,仅使用有标签数据训练时的可视化结果,此时网络模型难以处理未知类样本.如图5(b)所示为利用无监督算法进行开放域学习后的可视化结果,与仅使用有标签数据训练相比,采用提出的模型能够更有效地区分未知类样本,使得不同类别间的样本区分度更大.本文算法通过无监督方法引入未知类信息,能够有效地提升网络模型在开放域环境下的目标识别性能.
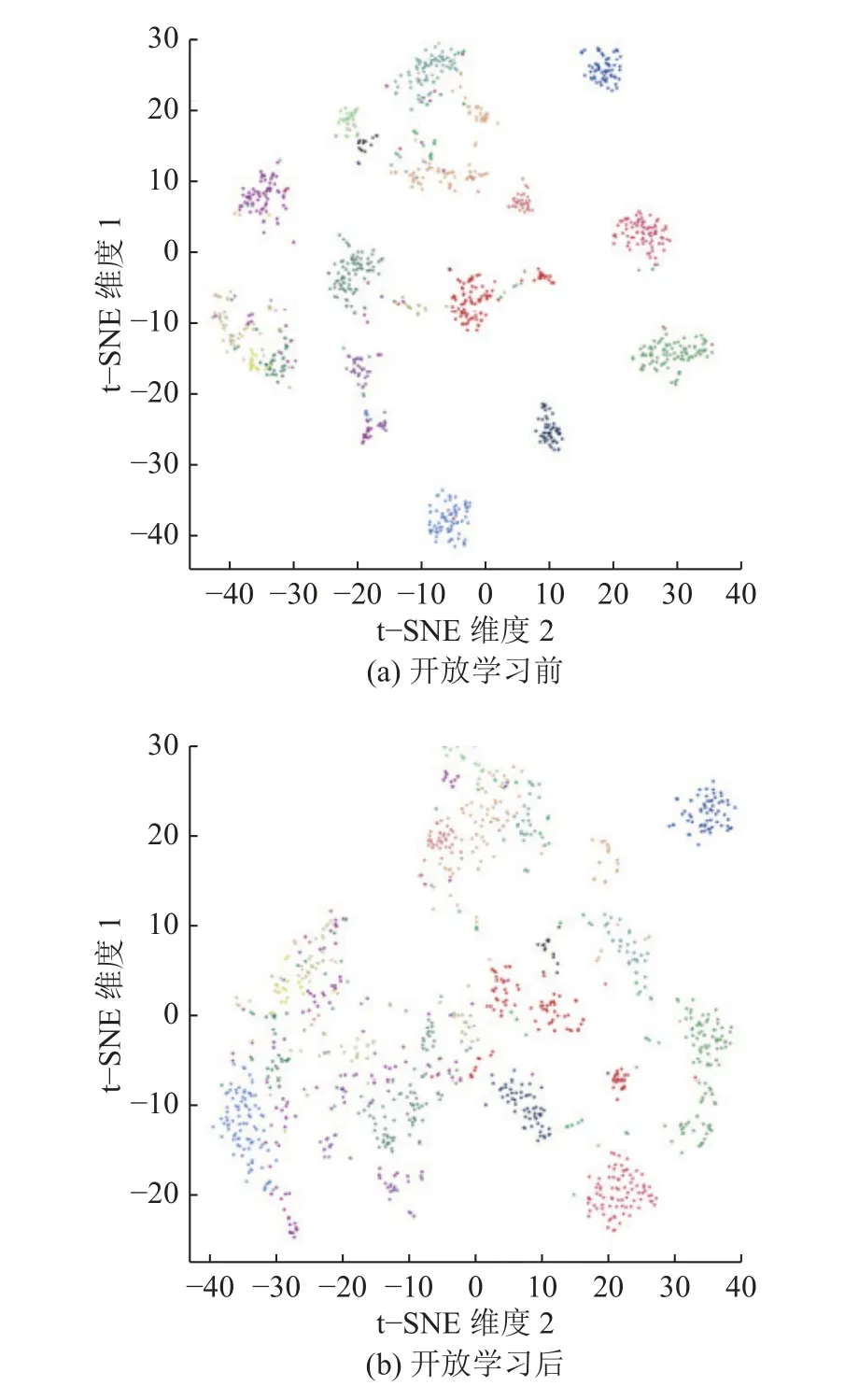
图5 t-SNE 特征分布图Fig.5 Feature distribution visualized by t-SNE
如图6 所示为本文算法在开放域条件下的部分检索效果图,展示了输入的三维模型样本以及数据集中与其最相似的10 个三维模型.提取输入三维模型的特征向量,将其与开放域数据集中所有样本的特征向量进行相似度比较;按照相似度从高到低的原则,对检索结果进行排序,将排序结果作为输出结果,其中使用的相似性度量方法为余弦距离[38].从结果可以看出,检索结果基本与输入的待检索样本一致,表明本文提出的表征模型能够实现对开放域未标注数据的有效探索和高效表征.
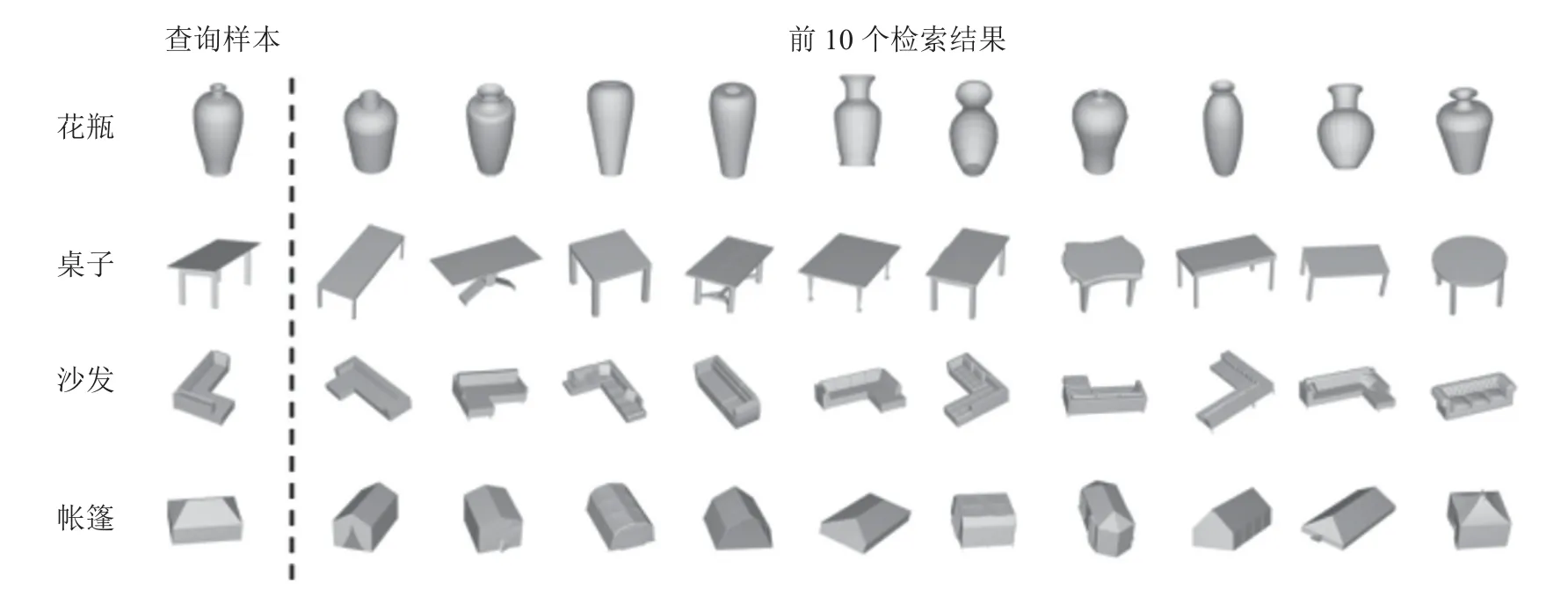
图6 输入样本及相应检索结果中的前十项Fig.6 Input models and corresponding Top10 ranked results
4 结语
本文提出基于多模态融合的开放域三维模型检索算法.该算法有效利用了多模态信息语义一致的关联性,借助无监督算法探寻未知样本间的类别信息,实现了对表征网络模型的参数优化,使得网络模型在开放域条件下通过迭代优化学习实现未知数据的有效表征,取得更好的检索性能.实验部分采用三维模型领域权威数据集Model-Net40 进行实验,通过与其他典型算法的对比实验及消融实验,证明了本文方法的合理性和优越性.
猜你喜欢
意林图解作文(小学版)(2019年6期)2019-07-16 08:35:46
成都信息工程大学学报(2018年3期)2018-08-29 01:08:40
中学生数理化·中考版(2017年6期)2017-11-09 02:46:46
非公有制企业党建(2017年10期)2017-11-03 02:26:27
现代兵器(2017年4期)2017-06-02 15:59:24
现代兵器(2017年4期)2017-06-02 15:58:14
电子设计工程(2017年20期)2017-02-10 03:39:29
专利代理(2016年1期)2016-05-17 06:14:36
电子器件(2015年5期)2015-12-29 08:42:24
电测与仪表(2014年13期)2014-04-04 12:04:18
