
基于大数据的视听娱乐商家智能选址系统的设计与实现
2024-02-09 00:00:00林剑宇
电脑知识与技术 2024年36期
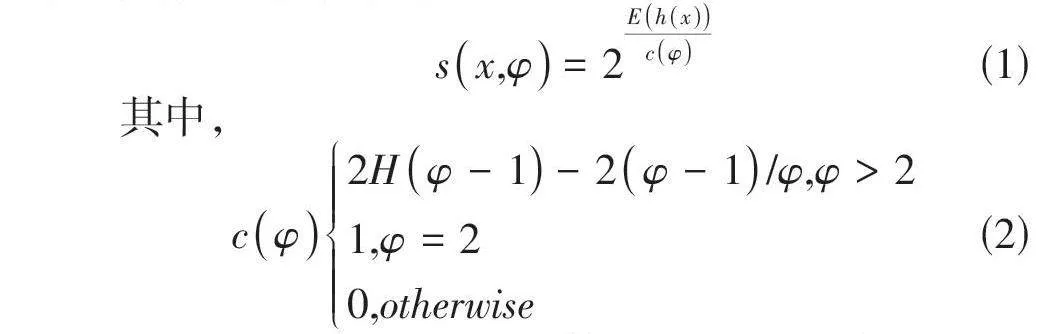

关键词: 大数据;商家选址;数据挖掘;聚类算法
中图分类号:TP315 文献标识码:A
文章编号:1009-3044(2024)36-0120-03"开放科学(资源服务) 标识码(OSID) :
0 引言
对于线下娱乐视听商家而言,选址策略是其成功的关键,直接影响长期经营和经济效益。合理的选址不仅能够提升收益,还会通过人流量、交通和商业环境等因素影响消费者行为,从而塑造商家的经营定位和策略。因此,选址通常是商家差异化竞争的核心环节。
传统的选址方式主要依赖人工探访,效率低且主观性强。随着大数据和数据挖掘技术的迅速发展,从海量数据(包括人口规模、交通、竞争和配套等多个维度) 中提取有价值的信息,为商家提供科学的决策支持成为可能。结合机器学习技术,企业能够基于数据做出更为精准的选址决策,提升选址的预见性和科学性,为商家的战略定位提供强有力的数据支撑。
1 商家选址系统总体框架
选址问题一直是运筹学中的经典研究热点。最早的选址问题由经济学家 Alfred Weber 于 1909年提出,他致力于最小化顾客到仓库的总距离,这就是著名的 Weber问题[1]。随着大数据和机器学习技术的进步,选址分析逐渐依赖数字化技术,从而显著提升效率和精确度。
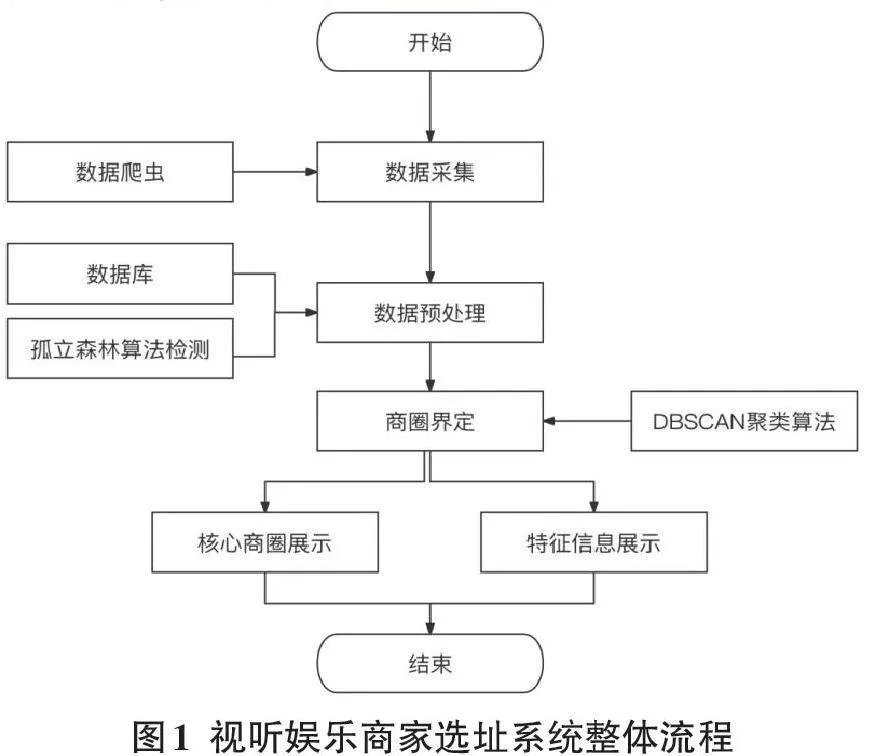
本项目通过综合分析多维度数据,为视听娱乐商家提供科学的选址决策支持。系统整体框架如图 1 所示,主要包括以下步骤:
1) 数据采集。利用爬虫技术从各大平台和数据源获取房价、交通、餐饮、娱乐等多维度数据。这些数据的全面性和覆盖范围对选址决策的准确性至关重要。获取的数据存储于 MySQL 数据库中,每个数据点包含编号、名称、类型、地址、经纬度、所在城市等属性。
2) 数据预处。对数据库中的原始数据进行预处理,包括数据清洗、异常值检测和数据整合,确保数据的一致性和可用性。
3) 商圈划分。采用 DBSCAN 聚类算法对商圈进行识别和划分,分析商圈周边各维度数据,深入挖掘各个商圈的经营特征。
4) 选址分析与可视化。 开发视听娱乐商家可视化选址后台,运用预测模型进行深入的选址分析,分类标识商圈等级,提供直观的视觉决策支持。系统为每个商圈提供详细的信息展示,包括生态详情和选址建议,并通过多色标志系统区分商业和公共设施,覆盖内环、中环和外环三个区域。系统助力用户全面理解商圈环境,做出科学的选址决策。
通过上述流程,系统实现了从数据采集与预处理、商圈划定与质量判断,再到可视化系统实现和选址建议的完整决策支持流程,显著提高了选址的科学性和准确性。
2 商家选址算法系统设计
2.1 商圈数据采集
影响商家选址的因素较多,包括环境因素、地理因素、市场因素、成本费用因素以及营业条件等多个方面。因此,需要丰富的商圈周边数据为商家选址提供支持[2]。
本方案通过爬虫技术从主流团购平台采集了反映商圈生态、竞争状况和客群特征的关键数据,涵盖商场、餐饮和电影院等多种商业形态。这些数据提供了商圈内部不同业态的分布和互动情况,是评估商圈活力和吸引力的重要指标。
此外,为全面描绘客群特征、交通便捷度和人口规模,系统还采集了包括住宅总数、物业价格和公共交通网络等数据。房产数据来自互联网房产中介平台,包含小区名称、地理位置、户数和房价等信息,能够反映区域的居住密度和消费能力。
通过采集公交和地铁线路数据,进一步丰富了交通情况的维度,包括站点名称、所在城市、经纬度坐标、线路编号和名称。这些数据有助于分析交通流量和便利性。
通过多维度数据的整合和分析,系统能够全面考虑选址的各项因素,确保选址决策的全面性和充分性。
2.2 基于孤立森林算法的数据预处理
由于数据来源于网络,存在范围广、异常数据多的问题。为确保数据质量,在数据分析前需要对数据进行预处理。本文采用孤立森林算法对数据进行异常值检测和处理。
孤立森林算法是一种用于异常检测的机器学习算法,通过隔离机制随机选择特征和切分值来孤立数据点,从而有效识别出异常值。该算法能够监测并剔除不准确的数据,确保数据集具有更高的可靠性。
孤立森林算法的主要思路是:对给定的数据集进行多次切分,构建孤立树;每次切分随机选择一个特征和切分值,将数据集分成左右两个子数据集;切分过程持续进行,直到达到一定的树高度或每个子数据集中仅剩一个数据点。 数据越密集的区域需要更多的切分次数,而异常点由于分布稀疏,通常在较少的切分次数中就能被孤立。
孤立森林算法主要步骤如下:
1)构建孤立树:对给定的数据集Χ = {x1,...,xn },从中随机选取φ个数据点放入根节点随机抽取子样本X’。
2)随机切分:从数据的d 个维度中随机选择一个维度q ,并随机产生一个切割点p。将切割点p 作为一个分割面,将当前数据集划分为两个子数据集:指定维度小于p的样本点放入左子数据集节点;指定维度大于或等于p 的放入右数据集节点[3]。
3)递归切分:递归执行第二步和第三步,直至孤立树(iTree) 达到指定的高度,或者所有叶子节点中的数据点为1。
4)异常值评分:每一个数据点xi 都需要遍历每一棵孤立树(iTree),计算该数据点在森林中的平均路径长度h (x"i")。路径越短,数据点越可能是异常值。异常值分数的计算公式如下所示:
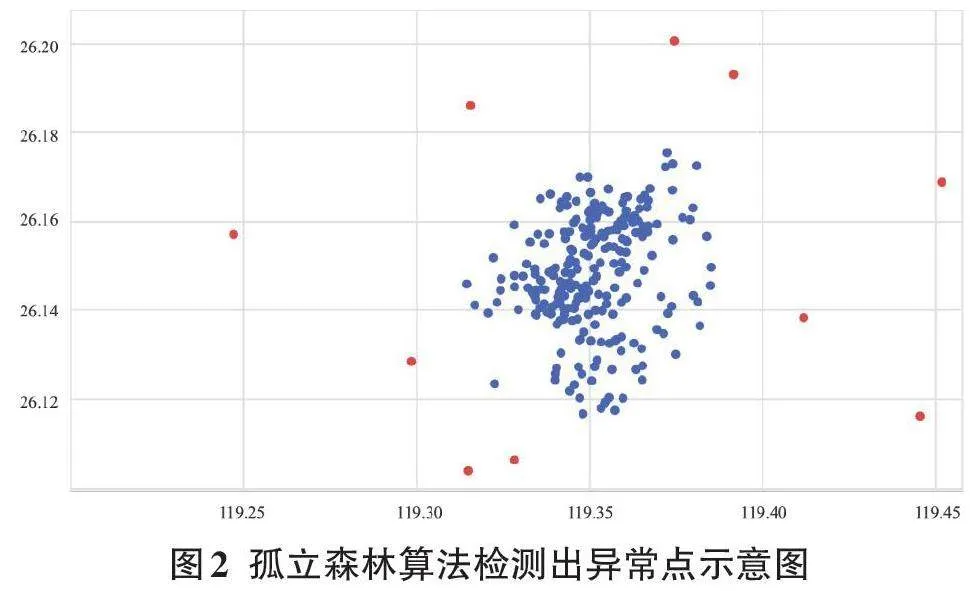
经过上述两个阶段的运算,系统能够对每一个经纬度数据点进行离群点识别。如图 2 所示,在经纬度网格中: 蓝色点代表密集的非离群点,这些点通常分布在数据集的中心区域;
红色点则代表偏离数据集中心的离群点,即数据样本中的异常数据。
孤立森林算法能够准确地将这些异常点从样本数据中标记出来,为后续的数据分析和处理提供了可靠的基础。
2.3 商圈范围界定模型
商圈选址的准确性深受其周边环境的影响,商圈分析因此成为决策过程中的核心工具。商圈特色和构成要素为商家调整策略、提升经济效益提供依据,同时影响门店经营。因此,商圈的准确界定对商家选址至关重要。为了有效识别和划定商圈范围,本文采用了基于密度的 DBSCAN 聚类算法。
1) 商圈可视化展示。商圈被划分为三个不同的环区,并采用多色标志来区分不同类型的商业设施和公共设施。内环(400米范围) :商圈的核心部分,包含最密集的商业活动和人流量。 中环(1500米范围) :商圈的拓展部分,包含更多的商业和服务设施。 外环(2500米范围) :最外层的环区提供更广泛的地理和商业信息,涉及一些居民区或学校。
2) 商圈详细信息。提供商圈的生态详情,包括商业活跃度、交通便利性、人口密度等。
3) 选址建议。基于逻辑回归预测算法,对商圈的消费指数、交通指数、人流指数等维度进行评分,为商家提供科学的选址建议。
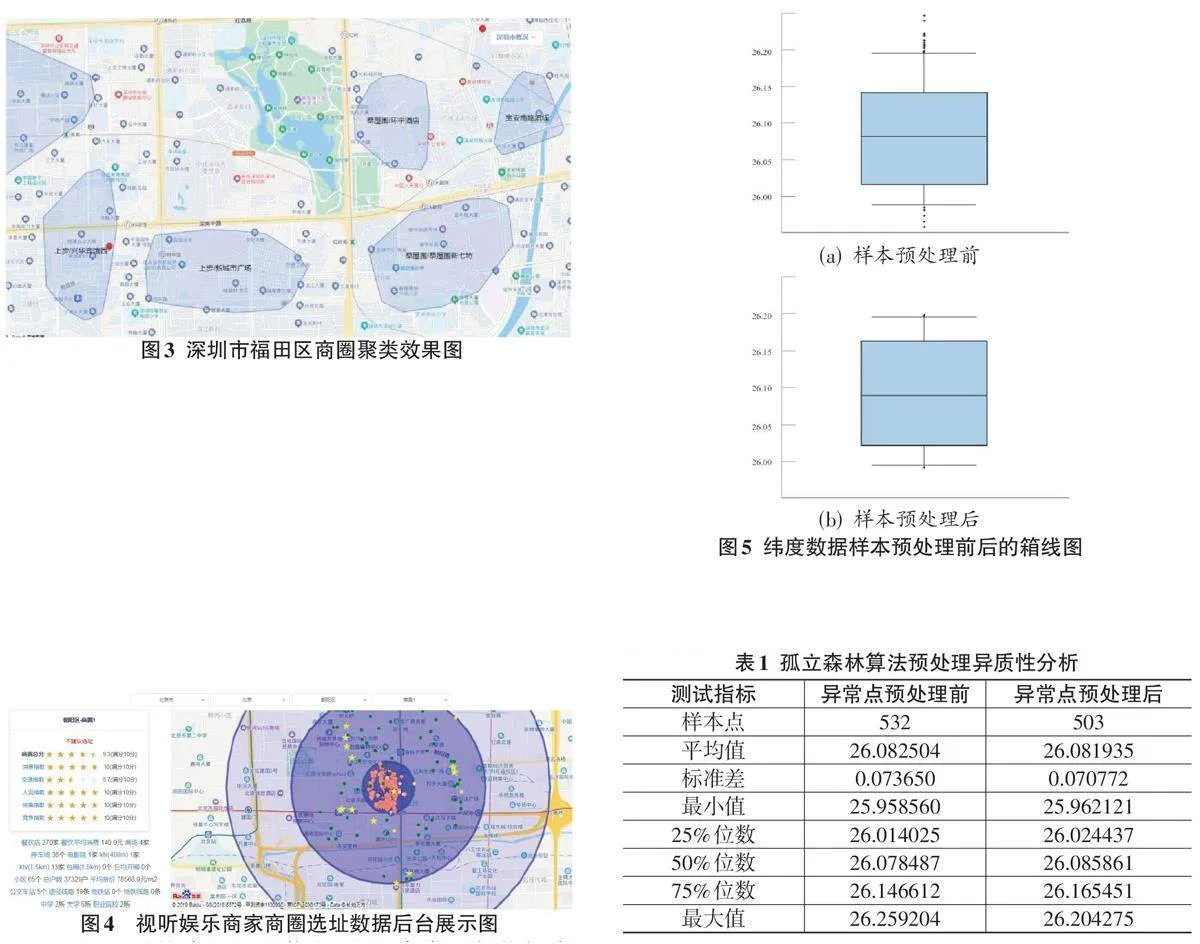
图 4 展示了北京市朝阳区某商圈的选址后台界面。商家可通过该系统全面了解商圈环境,并根据自身的经营定位选择合适的开业地点。系统详细展示了商圈的生态详情和选址建议,同时基于逻辑回归预测算法,对商圈的消费指数、交通指数、人流指数等选址细分维度进行打分,使商家对商圈的周边商业环境有更深入的认知。
通过这种综合的地理信息展示,商家不仅能够直观了解商圈的商业活跃度,还能综合考虑居住环境、交通便利性和教育设施等对商业选址有重要影响的因素,从而根据自身经营定位选取合适的商圈开业地段。
4 实验设计与结果分析
为了评估孤立森林算法在数据预处理中的效果,实验分别采用箱线图法(定义:一种用于显示一组数据分散情况的统计图) 和标准差法对地址经纬度数据进行分析[5]。
图 5展示了纬度数据样本预处理前后的箱线图。左图为算法处理前的箱线图,存在较多异常值,且数据分布偏态非常明显;右图为经过孤立森林算法处理后的箱线图,异常值显著减少,数据分布更加紧凑和集中。这一结果表明,异常值处理方法具有较高的有效性。
通过对孤立森林算法预处理的数据进行异质性分析,从表 1 的下四分位数(25% 位数) 、中位数(50%位数) 和上四分位数(75%位数) 可以看出数据分布的中心趋势。在异常点预处理之前,纬度样本点数据的标准差为 0.073650,而经过预处理后,标准差降低到了0.070 772。这一变化表明数据的分散程度有所降低,分布更加趋于集中,算法对异常点的检测准确性较高。
5 总结与展望
综上所述,本文针对视听娱乐商家的选址问题,开发了一套基于大数据的智能选址系统。该系统集成了数据采集、预处理、商圈聚类分析和选址预测模型,实现了从数据收集到决策支持的完整闭环。利用 DBSCAN 聚类算法,系统能够有效划定商圈范围,为商家提供科学的选址建议,显著提升了选址的预见性和准确性。
未来,系统将整合更多的数据维度,如消费者行为数据、社交媒体评价等,进一步优化算法模型。同时,计划将系统应用于零售业和餐饮业,扩大应用范围,提升资源配置效率。此外,还将优化用户界面设计,增强交互体验,提高决策效率。
猜你喜欢
大众投资指南(2021年35期)2021-02-16 01:06:26
电力与能源(2017年6期)2017-05-14 06:19:37
软件导刊(2016年12期)2017-01-21 14:51:17
现代电子技术(2016年23期)2017-01-12 09:40:23
科技视界(2016年20期)2016-09-29 10:53:22
电脑知识与技术(2016年8期)2016-05-19 11:16:25
科技视界(2016年8期)2016-04-05 18:39:39
信息通信技术(2015年6期)2015-12-26 01:16:46
电子设计工程(2014年18期)2014-02-27 12:00:13
