
基于睡眠数据的抑郁症诊断研究
2024-02-09 00:00:00丁建明李长云
电脑知识与技术 2024年36期

关键词:机器学习;抑郁症诊断;睡眠特征;随机森林
中图分类号:TP311 文献标识码:A
文章编号:1009-3044(2024)36-0070-03"开放科学(资源服务) 标识码(OSID) :
0 引言
全球抑郁症患者数量持续增长,患者人数约为3.22亿,且在2005年至2015年间增长了18.4%[1]。现有诊断方法主要依赖临床访谈和问卷调查,主观性强且缺乏客观指标。而睡眠障碍是抑郁症的核心症状之一,超过90%的抑郁症患者存在睡眠异常[2]。
常见的睡眠异常形式包括入睡困难、难以维持睡眠以及早醒[3]。抑郁症患者的睡眠结构异常还表现为睡眠时长减少、REM潜伏期缩短、慢波睡眠减少和觉醒频率增加等[4-6]。其中,REM睡眠的变化尤为显著,被认为是抑郁症的特异性标志。研究表明,抑郁症患者的睡眠时相前移与睡眠-觉醒周期的异常存在显著联系[7]。
本研究结合REM潜伏期、睡眠潜伏期、N1-N3期潜伏期、卧床时间、睡眠效率和慢波睡眠持续时间等多项睡眠特征,应用随机森林(RF) 算法,分析这些特征在抑郁症诊断中的应用潜力,旨在为抑郁症的客观诊断提供新的依据和支持。
1 数据与方法
1.1 数据的描述
本研究使用安徽省精神卫生中心提供的睡眠数据,包含105例抑郁症患者和55例健康对照。纳入标准为:根据ICD-10 诊断标准确诊为抑郁症(18~65 岁) ,排除严重躯体疾病和神经系统疾病。对照组无精神或神经系统疾病及睡眠障碍。所有数据均由睡眠监测系统采集。
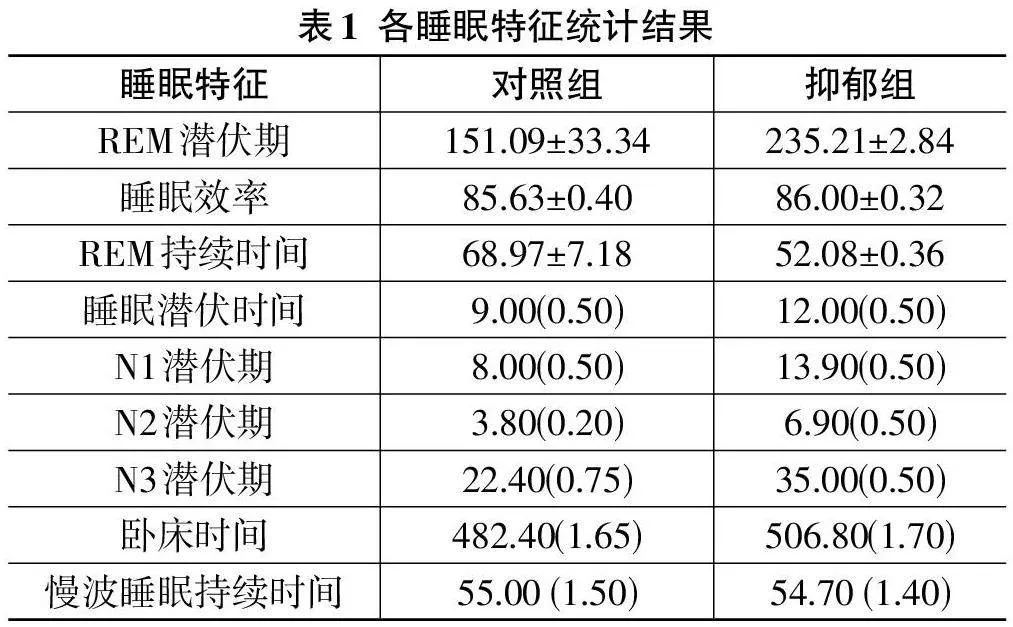
本研究数据集包括以下关键睡眠特征:REM潜伏期(入睡到首次进入快速眼动睡眠的时间) 、睡眠效率(实际睡眠时间与卧床时间的比率) 、REM持续时间(快速眼动睡眠期的持续时间) 、睡眠潜伏时间(从躺下到入睡的时间) 、N1、N2、N3阶段潜伏期(非快速眼动睡眠的不同阶段时间,尤其N3 阶段与深度睡眠相关) 、卧床时间(整夜停留在床上的总时间) 以及慢波睡眠持续时间(深度恢复性睡眠的总时长) 。
数据分析采用SPSS 26,正态分布数据用x±s 表示,非正态分布数据用中位数和四分位间距[M(IQR)]表示,结果如表1所示。
1.2 数据预处理
在模型构建前,对原始数据进行预处理以确保数据质量,具体步骤如下,缺失值处理:采用插值法或均值填充,优先保留关键特征;异常值处理:通过箱形图或Z值检验检测异常值,视情况进行删除或调整;标准化和归一化:消除特征间量纲差异,确保不同单位的特征可比较;统计描述:计算关键特征的均值、标准差等统计量以理解数据分布。经过这些处理,数据得以清理,确保模型的稳定性。
1.3 随机森林简介
随机森林(Random Forest, RF) 是一种基于集成学习的分类算法,其核心思想是通过构建多个决策树进行分类,并通过多数投票生成最终预测结果。这种方法能够有效减少单一模型过拟合风险,提高模型泛化能力。每棵决策树的训练数据通过 Bootstrap 抽样生成,即从原始数据集中有放回地随机抽取多个子数据集,保证每棵树的多样性。
1.3.1 决策树的构建
在随机森林中,决策树通过递归划分数据集构建,常用的划分标准包括基尼不纯度和信息增益。
基尼不纯度(Gini Impurity) :衡量一个节点的纯度,纯度越高,分类越精确。
通过交叉验证和参数调整,模型在抑郁症诊断中展现了高稳定性和准确性,能够有效识别关键睡眠特征,具备广泛应用的潜力。
2 实验结果与分析
2.1 模型性能评估
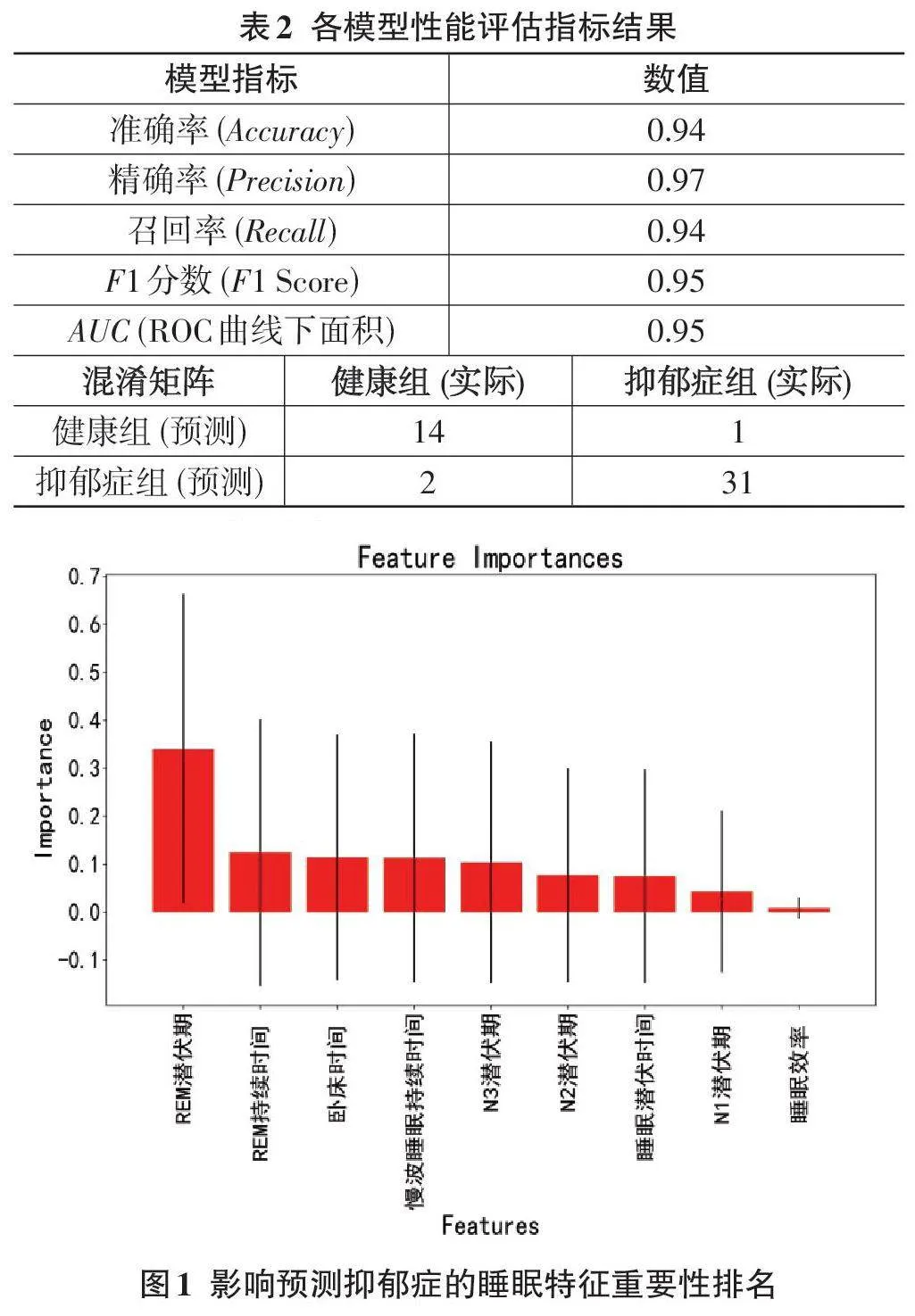
本研究使用随机森林(RF) 模型对抑郁症患者和健康对照组进行分类,评估结果显示该模型在抑郁症诊断中的表现出色。主要评估指标如下,准确率(Ac⁃curacy) :0.94;精确率(Precision) :0.97;召回率(Recall) :0.94;F1分数:0.95;AUC:0.95。这些指标表明模型在区分抑郁症患者与健康个体方面具有很强的能力。 通过混淆矩阵展示分类结果:真阳性(TP) = 31;假阳性(FP) = 1;真阴性(TN) = 14;假阴性(FN) = 2。模型表现出较低的误诊率和漏诊率,进一步验证了其在实际应用中的可靠性和价值。详细结果如表2所示。
2.2 特征重要性分析
本研究通过随机森林(RF) 算法生成特征重要性排名,识别出对抑郁症诊断最具影响力的睡眠特征。结果如图1所示,REM潜伏期显示出最高的重要性,表明其对抑郁症的预测具有显著作用,这与临床发现的REM潜伏期缩短一致。
总体分析表明,REM潜伏期等关键特征为优化模型和临床应用提供了重要参考。
2.3 实验结果的讨论
本研究中,随机森林模型在抑郁症诊断中表现出较高的准确率和可靠性,尤其在识别REM潜伏期缩短和慢波睡眠减少等关键睡眠特征方面。这些特征被广泛认为是抑郁症的生物标志,RF模型能够成功捕捉到这些特征,从而为临床诊断提供了有力支持。然而,该模型也存在一些局限性。
样本量限制:本研究纳入的样本量为160例。尽管模型在此数据集上表现良好,但相对较小的样本量限制了模型的泛化能力,尤其是在面对不同人群或临床环境时,模型可能难以捕捉到足够的多样性,导致在新数据上的表现不够稳定。应通过扩大样本规模,特别是纳入来自不同年龄段、性别以及不同病情程度的抑郁症患者,以增强模型的代表性和鲁棒性。
特征维度有限:本研究仅基于部分睡眠特征(如REM潜伏期、慢波睡眠持续时间等) 进行分析,而其他生理指标(如心率变异性、皮质醇水平) 也可能与抑郁症密切相关。未纳入这些额外的生理数据可能导致模型在特征识别上的局限性,从而降低诊断的全面性。可以通过结合多模态生理数据,进一步提高模型的诊断性能。例如,结合心率、皮质醇水平等生物标志,能够帮助RF模型更准确地区分不同类型的抑郁症患者。
模型解释性不足:尽管RF模型能够通过特征重要性评估识别出关键特征,但其内部的复杂性使得模型的解释性较差。临床上,医生往往更关注模型做出某一预测背后的原因和机制。可以结合SHAP(Shap⁃ ley Additive Explanations) 值等解释性方法,进一步分析每个特征对预测结果的贡献程度。通过这种方法,不仅可以提高模型的透明性,还能够帮助临床医生更好地理解不同睡眠特征在抑郁症中的作用机制,从而为个性化治疗提供依据。
单中心数据的局限性:本研究的数据来自单一中心,可能存在一定的地域和人群偏差,影响模型的普适性。应纳入更多来自不同地区、不同医疗机构的多中心数据,以验证模型在不同临床环境中的适用性。多中心验证有助于评估模型在不同人群中的表现,从而确保其在广泛的临床应用场景中的可靠性。
3 结论
3.1 研究总结
本研究利用随机森林(Random Forest) 算法,基于多项睡眠特征构建了抑郁症诊断模型,并取得了较高的诊断准确率。通过对REM潜伏期、睡眠效率和慢波睡眠持续时间等多维睡眠特征的分析,研究结果表明,REM潜伏期被识别为最重要的预测指标,这一发现与既往关于抑郁症患者睡眠结构异常的研究相一致[8]。
此外,本研究验证了通过非侵入性睡眠监测数据进行抑郁症诊断的可行性,展示了机器学习在精神疾病客观诊断中的潜力。相较于传统的诊断方式,这一方法提供了更为客观和可靠的判断依据。这不仅为抑郁症的早期筛查和诊断提供了数据支持,也为其他精神疾病诊断工具的开发提供了新的思路。
3.2 未来工作展望
为了进一步提升模型的准确性和实用性,未来研究可从以下几方面进行扩展:
1) 引入更多生理数据。除了睡眠特征,还应结合心率变异性(HRV) 、血压、体温、皮质醇水平等生物标志物。心率变异性等生理数据与睡眠特征可能存在潜在联系,这些数据将有助于全面了解抑郁症患者的生理状态。通过整合这些指标,模型可以为抑郁症的诊断提供更深入的依据,增强模型的诊断能力。
2) 扩大样本量与多中心验证。本研究样本量较小,存在地域和人群偏差。未来应扩大样本规模,进行多中心研究,纳入不同地理区域和患者群体的数据。这将提升模型的泛化能力,并验证其在不同临床环境中的表现,确保其在广泛人群中的有效性。
3) 引入纵向数据。通过纵向研究设计,长期跟踪抑郁症患者的睡眠数据变化,模型可以捕捉更多动态信息,提升对疾病进展的预测能力。随着病程发展,模型可评估疾病恶化或缓解趋势,从而增强临床干预的实用性。
4) 探索深度学习模型的应用。未来研究可探索长短期记忆网络(LSTM) 和卷积神经网络(CNN) ,以更好地捕捉睡眠数据的动态变化。LSTM擅长处理时间序列,适合捕捉睡眠数据中的时间依赖性;CNN可提取局部特征,进一步提升复杂数据的识别精度。
5) 多模态数据融合。可将不同类型的生理数据与睡眠数据结合在同一模型中。多模态数据整合有助于捕捉不同生理系统之间的交互作用,提升对抑郁症特征的全面识别能力,揭示更多潜在的病理机制,为个性化治疗提供新思路。
6) 提升模型解释性与临床可用性。虽然深度学习模型在精度上表现优异,但“黑箱性”限制了临床应用。结合LIME等技术,能够分析各特征对预测结果的贡献,提升透明度,帮助医生理解决策过程,增加模型在临床中的使用率。
7) 开发实时睡眠监测系统。基于模型的诊断能力,可以结合可穿戴设备和实时监测平台,开发抑郁症筛查工具。这类系统能无创、自动化采集睡眠数据,并实时评估抑郁风险,提供早期干预机会,成为个性化治疗的有效手段。
8) 跨学科数据整合。未来可结合基因数据和神经影像数据,进一步探索抑郁症的多维生物标志物。基因数据揭示遗传风险,神经影像数据识别脑功能异常。将这些数据整合至模型中,可以提高诊断的准确性,并揭示抑郁症的生物机制。
通过引入生理数据、扩展样本、采用深度学习模型及提升模型解释性,未来的研究可进一步增强基于睡眠特征的抑郁症诊断模型。这些改进不仅提高了模型的精度,还推动了自动化精神疾病筛查工具的发展,为抑郁症的早期诊断与干预提供了新的路径。
猜你喜欢
安徽农学通报(2017年1期)2017-02-15 17:49:06
软件(2016年7期)2017-02-07 15:54:01
南水北调与水利科技(2016年6期)2017-01-06 13:43:27
电子技术与软件工程(2016年22期)2016-12-26 21:36:42
科技创新与应用(2016年31期)2016-12-03 03:33:48
时代金融(2016年27期)2016-11-25 17:51:36
科教导刊(2016年26期)2016-11-15 20:19:33
电脑知识与技术(2016年23期)2016-11-02 23:25:12
科学与财富(2016年28期)2016-10-14 21:19:17
科教导刊·电子版(2016年10期)2016-06-02 18:04:11
