
基于人工智能的恶意软件检测与防御机制
2024-02-09 00:00:00柏嵩胡月文
电脑知识与技术 2024年36期

关键词:恶意软件检测;深度学习;特征提取;机器学习
中图分类号:TP311 文献标识码:A
文章编号:1009-3044(2024)36-0036-03"开放科学(资源服务) 标识码(OSID) :
0 引言
在数字化时代,恶意软件作为网络安全的重大威胁,其变种与新形态不断涌现,对传统基于签名和规则的检测方法构成了严峻挑战。鉴于此,探索并开发更为先进、智能的恶意软件检测与防御机制显得尤为迫切。
为了应对上述挑战,本文旨在探讨一种基于人工智能的新型检测与防御机制,该机制深度融合机器学习与深度学习技术,旨在自动学习并识别其行为特征及模式,以降低网络对恶意软件的检测时间,并提高阻断率,进而为网络安全防护领域提供创新性的理论与实践指导。
1 恶意软件检测与防御概述
恶意软件(Malware) 是一种通过破坏计算机系统、窃取数据,或造成其他危害来达到攻击者目的的软件。李雨颖等[1]对动态行为特征的勒索软件检测技术进行分析,得出危害的主要类型包括病毒、蠕虫、特洛伊木马等恶意软件,其通过社交工程、漏洞利用、网络钓鱼等手段进行攻击,带来数据泄露、经济损失和隐私侵犯等危害。刘昊等[2]对恶意软件检测的方法进行了分类和介绍,提出传统的检测方法有基于特征码、行为、签名和启发式的检测,各有优缺点,包括防病毒软件、防火墙、入侵检测系统(IDS) 和入侵防御系统(IPS) 等[3],这些方法在一定程度上有效,但面对日益复杂和多变的恶意软件威胁,显得越来越力不从心,促使了基于人工智能技术的新一代恶意软件检测与防御机制的发展[4]。
2 基于人工智能的恶意软件检测方法
2.1 特征提取与选择
通过分析大量的正常和恶意软件样本,提取出能够区分两者的关键特征。这些特征可以是静态特征(如文件哈希值、文件头信息等) 或动态特征(如系统调用序列、网络行为等) 。特征提取是保证检测模型准确性的关键步骤[5],其具体步骤如下。
步骤1数据收集:从各种可信来源收集正常软件样本,包括常见的操作系统文件、应用程序、驱动程序等;同时,从安全公司、研究机构或公开恶意软件数据库中收集恶意软件样本,涵盖病毒、木马、勒索软件等类型。
步骤2特征提取:在不执行软件的情况下提取特征,包括计算文件的MD5、SHA-1、SHA-256等哈希值以唯一标识文件,提取文件头部信息(如PE文件头中的魔术字、时间戳、入口点等) ,分析文件内容的字节序列以识别特定模式或签名,提取文件中可见的字符串以识别特定的恶意命令或URL,以及提取文件的元数据(如数字签名、编译器版本、作者信息等) 。
步骤3特征选择:在提取了静态和动态特征之后,使用主成分分析法(PCA) 进行特征选择。PCA通过将原始特征转换为一组不相关的主成分,保留数据中最具代表性的部分,从而减少特征维度。具体来说,PCA通过计算特征的协方差矩阵,并对其进行特征值分解,选择具有最大特征值的特征向量作为主成分。这一过程能够有效降低数据的复杂性,保留主要信息,确保模型在后续训练和预测中的性能和效率。
2.2 机器学习模型训练
将预处理后的训练集数据输入SVM模型中进行训练,目标是找到一个最优的决策边界(超平面) ,使得恶意软件和良性软件数据点之间的分离度最大化。在训练的过程中,SVM算法会识别出支持向量,即那些位于决策边界附近的数据点,决策边界的数学形式为:
递归神经网络则在处理序列数据(如系统调用序列) 方面表现出色。通过大规模数据集的训练,深度学习模型能够自动学习到恶意软件的复杂特征,从而实现更高的检测精度。
2.4 基于AI 的检测系统架构
构建基于人工智能的恶意软件检测系统涵盖了数据采集模块、特征提取模块、模型训练与更新模块以及实时检测模块这四大核心组件。首先,数据采集模块是整个系统的基石,它负责广泛而深入地收集大量的正常软件和恶意软件样本。这些样本来源多样,可能包括公开的恶意软件库、实际网络环境中的捕获样本以及合作伙伴的共享数据,从而确保数据集的丰富性和多样性。紧接着,特征提取模块会对这些收集到的样本进行精细的特征分析。这一步骤至关重要,因为它涉及从原始数据中提取出能够有效区分正常软件和恶意软件的关键特征。这些特征可能包括文件的静态属性(如文件大小、签名等) 、动态行为特征(如系统调用序列、网络活动等) 以及可能的恶意代码模式。随后,模型训练与更新模块会利用这些经过精心提取的特征来构建和训练检测模型。在这一阶段,各种先进的机器学习算法和深度学习技术会被应用,以学习和识别恶意软件的特征模式。同时,随着新数据的不断涌入和恶意软件技术的不断发展,该模块还需要持续地对模型进行更新和优化,以确保其检测能力的时效性和准确性。最后,实时检测模块会将经过训练和优化的模型部署到实际的生产环境中。它负责实时监控和分析来自各种来源的数据流,如网络流量、系统日志等,以快速准确地识别出潜在的恶意软件活动。
3 环境设计
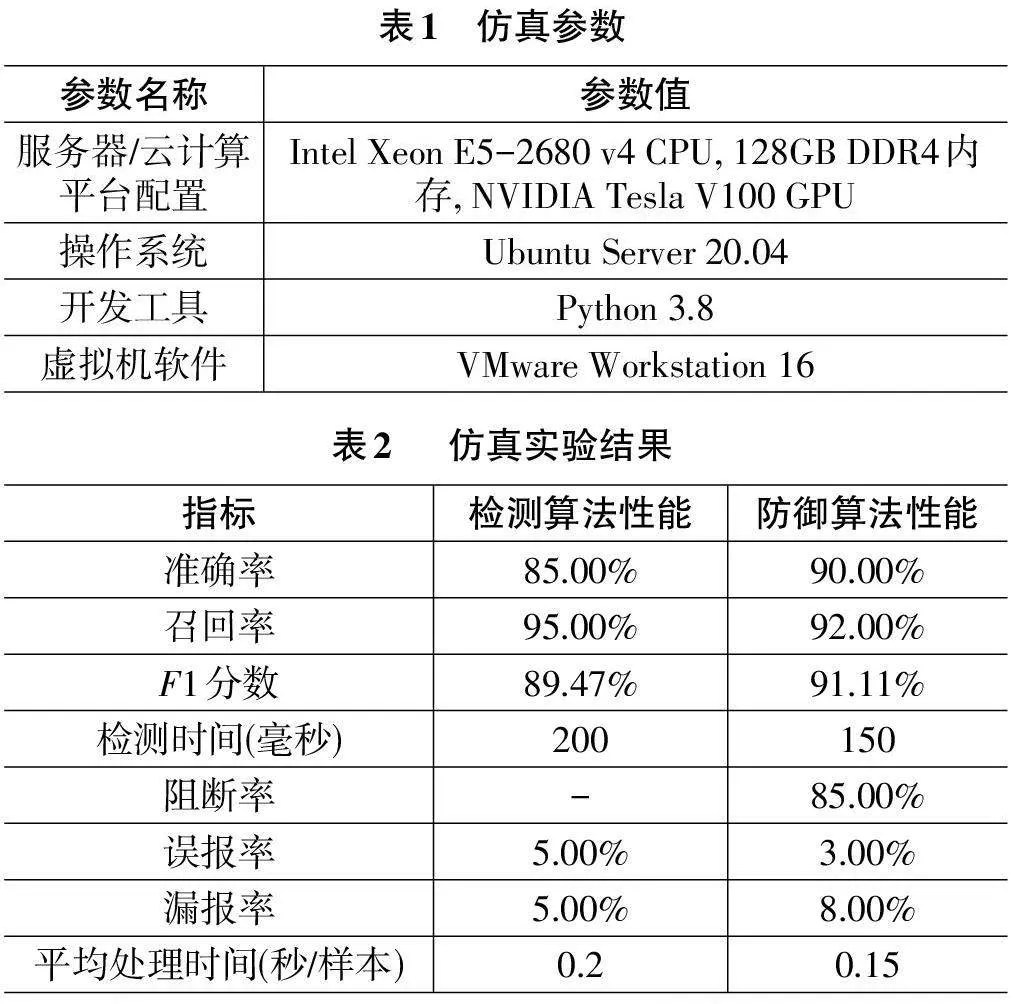
本次设计的仿真实验环境旨在全面评估基于人工智能的恶意软件检测与防御机制的性能和效果。实验环境搭建在高性能服务器或云计算平台上,具体配置如表1所示。数据集方面,本文收集了5000个恶意软件样本和5000个正常软件样本,并进行了预处理,提取了二进制代码、系统调用序列、网络流量等特征。在恶意软件检测方法上,本文采用了静态分析和动态分析相结合的方式,应用了深度学习模型(如CNN) 和机器学习模型(如随机森林) 进行训练和分类。防御机制方面,本文实现了实时监测与响应以及自动化防御策略,应用了强化学习技术和基于规则的防御引擎。实验设计与实施阶段,本文将数据集划分为训练集和测试集,从而全面测试防御机制的有效性。
从表2可以看出检测算法和防御算法均表现出了较高的性能。检测算法的准确率达到了85.00%,召回率达到了95.00%,F1分数为89.47%,显示出算法在识别恶意软件方面的有效性。同时,检测算法的平均处理时间为0.2秒/样本,相对较快。然而,检测算法也存在一定的误报率和漏报率,分别为5.00%。相比之下,防御算法在阻断率方面表现突出,达到了85.00%,显示出其在防御恶意软件攻击方面的能力。同时,防御算法的准确率、召回率和F1分数也均高于检测算法,分别为90.00%、92.00%和91.11%。此外,防御算法的平均处理时间更短,为0.15秒/样本,且误报率也更低,为3.00%。
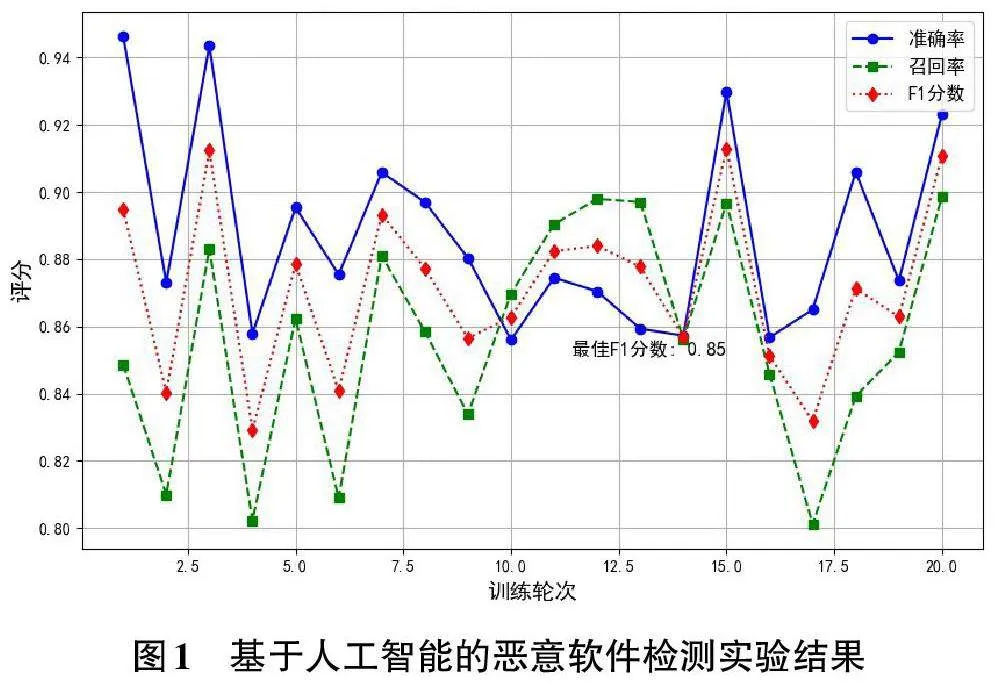
进一步,为验证检测算法的性能表现,在训练20次之后,分析其准确率、召回率和F1分数性能指标的变化,如图1所示。
基于生成的实验结果图,可以观察到以下几点:在整个训练过程中,准确率和召回率均保持在较高水平,分别在0.85到0.95和0.80到0.90之间波动。F1分数作为准确率和召回率的调和平均数,整体趋势与它们一致。特别是在第14轮次时,F1分数达到最高值,说明此时模型在平衡准确性和召回能力方面表现最佳。整体而言,该人工智能模型在检测恶意软件方面具有较好的性能和稳定性。
5 结论
本文通过深入研究与实验验证,提出了一种基于人工智能的恶意软件检测与防御机制。该机制充分利用了机器学习与深度学习技术的优势,实现了对恶意软件行为特征及模式的自动学习与高效识别。实验结果表明,该机制还可以成功进行恶意软件的检测和防御方面,相较于传统方法有了显著提升。未来将从检测更为复杂的恶意软件攻击手段出发,设计更为高效的监测和防御算法,以确保网络安全。
猜你喜欢
电子制作(2018年19期)2018-11-14 02:37:08
自动化学报(2017年11期)2017-04-04 02:52:58
新教育时代·教师版(2016年23期)2016-12-06 06:02:38
科技创新与应用(2016年31期)2016-12-03 03:33:48
法制与社会(2016年32期)2016-12-01 15:25:53
时代金融(2016年27期)2016-11-25 17:51:36
科教导刊(2016年26期)2016-11-15 20:19:33
软件导刊(2016年9期)2016-11-07 22:20:49
软件工程(2016年8期)2016-10-25 15:47:34
科学与财富(2016年28期)2016-10-14 21:19:17
