
基于改进SRGAN的驾驶员异常行为检测算法
2024-02-09 00:00:00赵益辰张雅丽
电脑知识与技术 2024年36期
关键词:深度学习







关键词:图像超分辨率;驾驶员异常行为检测;SRGAN;深度学习;ConvNeXt
中图分类号:TP391 文献标识码:A
文章编号:1009-3044(2024)36-00024-05"开放科学(资源服务) 标识码(OSID) :
0 引言
随着汽车保有量的持续增长,交通安全问题已成为影响人身安全的主要问题之一。据公安部数据,2022年全国共发生交通事故254 609起[1],平均每天发生约695起交通事故。研究表明,驾驶员的不良行为是导致交通事故的重要因素之一,驾驶分心导致的交通事故占重大事故的14%~33%[1]。在交通事故中,未系安全带的驾驶员死亡率为75%,而系安全带的生还率高达95%[2]。因此,对驾驶员异常行为的检测具有重要的现实意义。
针对驾驶员异常行为监测,许多学者开展了一系列研究。Zhao[3]等人通过改进YOLOv5的方式,对低照度图像下驾驶员分心行为进行准确检测。Huo[2]等人提出了一种STN-CNNs模型,通过加入空间变换神经网络,使检测模型可以更好地定位图像中的驾驶员区域,并通过改进的Hough变换检测驾驶员安全带佩戴情况,但由于数据集中部分图片清晰度不高,影响了检测精确度。针对这一问题,Kang[4]等人针对收集到的道路监控驾驶员图像噪声明显、图像质量低等问题,利用改进的EDSR模型进行图像超分辨率,通过去掉BN层精简模型结构,有效提升了图像重建质量,但该研究未对驾驶员行为进行检测。
为了解决上述问题,本文首先基于前期研究,构建了驾驶员异常行为超分辨率数据集LD以及驾驶员异常行为目标检测数据集SD。针对数据集中图像清晰度不高和噪声较为明显的问题,本文提出了一种改进的超分辨率生成对抗网络SRGAN[5]算法以提升图像质量。在四倍超分辨率任务中,尽管原始SRGAN 算法能够生成相对清晰的图像,但由于其生成器和判别器结构的局限性,训练过程不够稳定[6],且在重建过程中容易丢失部分高频信息,导致生成图像出现纹理细节缺失、边缘模糊等现象,进而影响重建效果。为了解决这些问题,本文提出了改进SRGAN算法引入ConvNeXt-v2[7]模块替代原有模型中的残差块,以解决高频特征丢失的问题,并增强算法对边缘轮廓的感知能力。此外,在判别器中加入了金字塔注意力模块,以减少噪声干扰,进一步提升图像质量。最后,本文将改进的SRGAN超分辨率算法与YOLOv8目标检测模型相结合进行对比实验。实验结果表明,本文提出的模型显著提升了驾驶员异常行为检测的准确性。
1 驾驶员异常行为监测模型
1.1 数据集构建
许多研究采用YawDD等驾驶员车内视角公开数据集,主要针对驾驶员异常行为的事前预防和事中发现。然而,由于车内自主监控在现实中推广难度较大,目前主要通过公共安全部门的惩戒性处罚方式来管理驾驶员行为。但是,从公共安全部门角度出发的针对驾驶员异常行为的研究较少,主要原因包括数据集构建困难和城市道路图像质量较差,导致目标检测效果不理想[8]。为解决上述问题,本文首先建立了城市道路监控驾驶员行为数据集,并对数据图像进行超分辨率重建。
1) 超分辨率图像数据集构建
为了提高模型对多样化数据的鲁棒性,并考虑监控场景的特点,本文采用了两个数据集联合训练。首先,使用DIV2K数据集[9]对模型进行预训练,之后使用自建数据集LD进行微调,最终在LD数据集上评估模型的超分辨率效果。LD数据集的部分代表性图片如图1所示。
2) 目标检测数据集构建
自建的LD数据集覆盖了不同的驾驶员行为,包括正常驾驶、未系安全带、使用手机等。同时,数据集涵盖了不同光照条件、单一驾驶员目标和多个车内目标,以确保目标检测模型在实际场景中的准确性。基于LD数据集,进一步建立了驾驶员异常行为目标检测数据集SD。
SD数据集中包括658张正常驾驶图像和1 295张异常驾驶行为图像,其中训练集1 562张,验证集391 张,训练集与验证集的比例约为8∶2,具体如表1 所示。
对原始图片进行筛选与裁剪后,使用LabelImg图像标注软件建立了PASCAL VOC格式的目标检测数据集。对数据集中的驾驶员检测区域进行了矩形边界标注,示例如图2所示。
1.2 SRGAN 残差块改进
ConvNeXt[10]是Facebook AI于2021年提出的深度卷积网络模型,使用纯卷积网络实现了对Trans⁃former[11]模型性能的超越。ConvNeXt主要由4个阶段(stage) 堆叠构成,每个阶段包含一个下采样模块和多个ConvNeXt块。为了增强SRGAN网络对图像中物体边缘轮廓的重建效果,本文借鉴了ConvNeXt-v2的思想,重新设计了原始SRGAN 网络的残差块。ConvNeXt-v2版本去除了LayerScale,提高了模型的训练速度;增加了GRN层以缓解特征折叠问题。改进的残差块结构如图3所示。
在改进的残差块中,使用LayerNorm层归一化取代了原始SRGAN残差块中的BatchNorm层归一化,以减少生成图像中的伪影问题。同时,使用深度可分离卷积调整通道维度,进一步增强对图片特征的提取能力。最后,经过上采样操作将特征图放大为原来的4 倍。改进的生成器结构如图4所示。
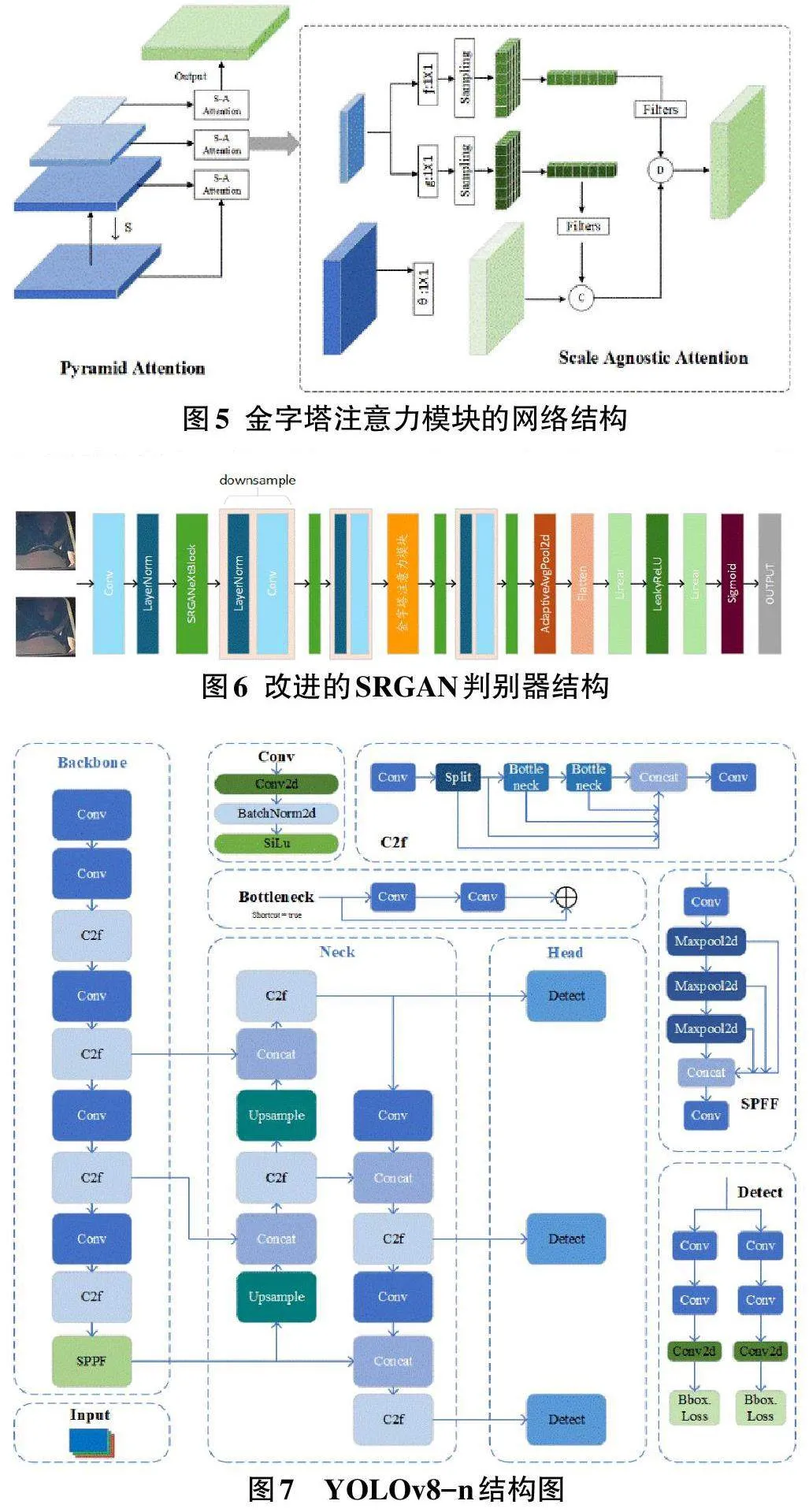
1.3 金字塔注意力机制
为了提高算法对驾驶员图像细节的关注度,有效抑制道路监控图像噪声对生成图像的干扰,并增强模型对复杂道路场景的鲁棒性,本文在SRGAN判别器中引入了金字塔注意力机制[12](pyramid attention) 。金字塔注意力机制能够充分利用图像中的跨尺度自相似性,显著提高模型在面对噪声或伪影等干扰时的鲁棒性。金字塔注意力机制可用公式(1) 进行表述:
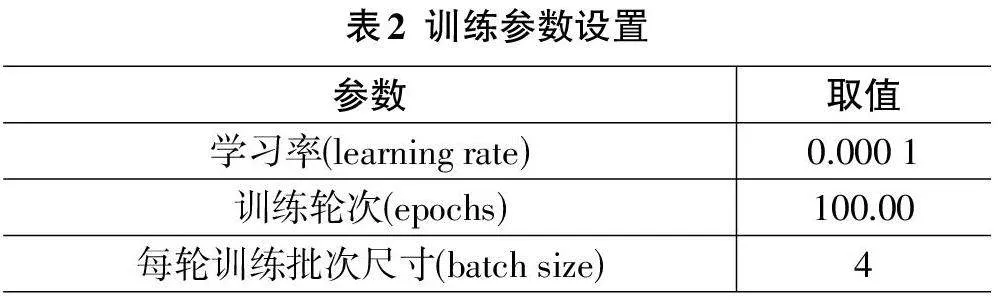
金字塔注意力模块的结构如图5所示。在判别器中引入DW卷积,可以在减少模型参数量的同时增加模型宽度,从而提高模型的训练速度[13]。改进后的SRGAN判别器结构如图6所示。将金字塔注意力模块嵌入在第2个SRGANeXt模块之后,帮助判别器在平均池化层判别前强化细节特征,有效提高判别器的区分能力。
1.4 YOLOv8目标检测模型
YOLO[14] (You Only Look Once) 算法是一种基于CNN的目标检测算法,可用于目标检测、图像分类等领域,具有检测速度快、体积小、准确度高等优点。YOLOv8是目前主流的单阶段目标检测算法,根据网络深度、特征图宽度及参数量大小,YOLOv8可分为YOLOv8-n、YOLOv8-s、YOLOv8-m、YOLOv8-l、YO⁃LOv8-x共5个版本。其中,YOLOv8-n的网络卷积深度较小,检测速度快。基于配置与轻量化部署的需求,本文选用YOLOv8-n作为目标检测的基准模型。
YOLOv8-n主要由主干(Backbone) 、颈部(Neck) 和检测头(Head) 三个部分组成,其结构如图7所示。
2 实验结果与分析
2.1 实验环境搭建
本文的模型训练在云服务器上进行,服务器系统为Ubuntu 20.04,硬件配置包括12 GB 内存的Intel®Xeon® Gold 6230 @ 2.1 GHz CPU 和6 GB 显存的NVIDIA GeForce RTX 3060 GPU。实验的软件环境包括Conda 3.9科学计算包、Pytorch 2.0.1深度学习框架和Python 3.8,训练过程中采用CUDA 11.7.1加速GPU 运算。改进的SRGAN模型训练超参数设置如表2所示,优化过程采用ADAM 算法,以提高模型的收敛速度。
2.2 重建图像质量评价指标
改进的SRGAN 模型使用DIV2K 数据集进行训练,并使用自建驾驶员异常行为数据集LD进行微调。为了增强数据,训练图像进行了随机水平翻转和90度随机旋转,同时将训练集归一化到[0,1]区间。
2.3 改进的SRGAN 算法效果展示
图8 和图9 分别展示了SRGAN 网络与改进的SRGAN网络在三个真实场景下驾驶员区域图像重建效果的对比图。
如图9所示,在细节重建效果上,改进的SRGAN 相比原始SRGAN网络提升明显。引入改进后残差块的网络模型对图片边缘提取了更多有用信息,对安全带的轮廓重建效果更显著,手部的细节更加真实,且质量更加细腻。同时,加入金字塔注意力机制的SRGAN网络在图片噪声抑制方面效果显著,减少了图片噪声在重建时的干扰,提升了超分辨率图像的质量。
2.4 改进的SRGAN 算法消融实验
针对SRGAN网络在细节重建真实感较差、轮廓感知不明显以及噪声敏感等问题,本文引入Con⁃vNeXtv2模块改进生成器与判别器的残差块,同时在判别器中加入金字塔注意力机制。为验证改进方法对网络重建效果的提升,本节对改进的SRGAN超分辨率算法进行了消融实验。选用LD数据集中的测试集,放大因子为4倍。根据表3实验结果可以看出,两种改进方法均对网络的重建能力有显著提升。改进的SRGAN 网络的PSNR 与SSIM 平均值相比原始SRGAN网络分别提升了4.2251 dB和0.098,并且使用ConvNeXtv2代替残差模块对网络的图片重建效果提升最为明显。
根据对模型重建过程中的特征图分析可得,改进的SRGAN可以感知更多的高频信息,保留图像的纹理和边缘方面,改进的SRGAN相比原始SRGAN表现得更好,同时对比度的提高体现出对不同特征之间的差异进行了更为明显的区分,使生成图像的轮廓更加清晰。
2.5 横向对比实验
为了体现改进的SRGAN网络的有效性,本节选取了4个具有代表性的超分辨率算法进行横向对比。超分辨率算法在DIV2K数据集和自建数据集LD上进行测试,实验结果如表4 所示。可以看出,改进的SRGAN在PSNR指标上优于其他算法,证明其在重建图片精度上的优势。结构相似度SSIM指标体现了模型对边缘结构的重建质量,虽然改进的SRGAN 在SSIM指标上略低于EDSR,但生成的图像在人眼感受上更加真实。为了更直观地展示各算法的图像重建效果,上述算法各自重建的图像整体对比图如图11 所示。
2.6 改进SRGAN 对驾驶员异常行为检测精度的验证实验
为验证提出的改进算法在驾驶员异常行为检测任务中的有效性,本节进行了改进SRGAN处理前后的驾驶员异常行为检测精度对比实验。实验结果表明,加入改进SRGAN超分辨率算法可以提高YOLOv8算法对驾驶员异常行为检测的精度。实验结果如表5 所示,与单独使用YOLOv8模型进行检测相比,加入改进SRGAN处理后的图像检测AP精度提升了4.5%,改进对检测精度的提升效果显著。
3 结论
本文针对道路监控图像质量较低对驾驶员异常行为检测精度的影响,提出了一种基于ConvNeXt和金字塔注意力机制的改进SRGAN算法。通过改进生成器和判别器,引入ConvNeXt-v2模块增强高频特征提取与轮廓细节重建;在判别器中加入金字塔注意力机制,有效抑制噪声干扰,提升了图像重建的整体质量。实验结果表明,与原始SRGAN模型相比,本文提出的改进模型的PSNR和SSIM值分别提升了4.225 1dB和0.098,且在图像重建细节效果上具有明显优势。同时,通过将改进的SRGAN算法与YOLOv8目标检测模型相结合,平均AP精度提升了4.5%,显著提高了检测准确度。
尽管取得了较好的效果,但仍存在模型参数量较大、推理速度有待提升等问题。未来研究将进一步优化算法结构,减少模型参数,提高推理速度,以实现更高效的实时应用。
猜你喜欢
中国教育技术装备(2016年19期)2016-12-27 19:23:52
中国远程教育(2016年11期)2016-12-27 18:07:31
现代商贸工业(2016年25期)2016-12-26 09:58:02
江苏教育·中学教学版(2016年11期)2016-12-21 11:45:08
江苏教育·中学教学版(2016年11期)2016-12-21 11:36:29
现代情报(2016年10期)2016-12-15 11:50:53
考试周刊(2016年94期)2016-12-12 12:15:04
新教育时代·教师版(2016年23期)2016-12-06 06:02:38
法制与社会(2016年32期)2016-12-01 15:25:53
软件导刊(2016年9期)2016-11-07 22:20:49
