
基于上下文特征提取的边缘生成三阶段图像修复算法
2024-02-02 14:54芮志超郭艳艳
测试技术学报 2024年1期
芮志超,郭艳艳
(山西大学 物理电子工程学院,山西 太原 030006)
0 引言
由于图像在传输和获取过程中受到人为或环境的影响会导致图像信息丢失,需要对图像进行修复处理,增强其视觉效果。传统图像修复是根据图像样本相似度、结构纹理一致性等方法,结合数学、物理理论构建算法模型修复破损图像,主要包括基于扩散的方法[1]和基于补丁的方法[2-3]。但是,传统的修复算法只能基于已有区域的信息来填充未知区域,未出现在已知区域的内容无法预知填充。
近年来,深度卷积网络和生成式对抗网络已被大量应用到图像修复中[4-6]。Pathak D等[7]在2016年提出了上下文编码器,该算法通过构建一个编码器-解码器结构完成缺损图像的编解码工作,并添加判别损失完成图像的精细修复,但该算法只能修复简单结构的破损图像,对于人脸图像修复远远不足;Yu J等[8]在2019年提出利用门控卷积层替代传统卷积层,解决了传统卷积层将图像所有像素视为有效像素的缺点,该算法只适用于规则掩膜,而对于自由掩膜而言,图像修复效果差;Nazeri K等[9]在2019年提出一种Edge-Connection模型,通过设计额外的辅助网络,利用缺损区域边缘信息辅助图像修复;Guo X等[10]在2021年提出了一种结构约束纹理合成和纹理引导结构重建的耦合网络来完成整个修复过程,并设计了双向门控特征融合模块来实现结构和纹理信息的融合。
综上所述,现有修复人脸图像的算法可以划分为单阶段修复模型、渐进式两阶段模型和基于结构先验或者语义先验约束的图像修复模型。单阶段修复模型在修复背景复杂、纹理精细的图像时,容易产生模糊的纹理细节;渐进式两阶段模型虽然能生成纹理细节,但是图像整体的结构会发生扭曲;而基于结构先验或者语义先验约束的图像修复模型,结构与语义一致性有了保障,但修复图像纹理细节不贴近真实图像。
针对上述问题,本文提出了一种基于上下文特征提取的边缘生成三阶段的图像修复算法。首先,算法利用破损图像的上下文特征进行初步修复,并对初修复结果的边缘进行重建;然后,将重建后的边缘结构以及初修复结果一起作为先验信息,来约束最后阶段的精修复过程。并且,在边缘修复网络和精修复网络中加入Res2net模块[11]和自注意力机制,提取多尺度特征以提升网络的表征能力,自适应计算远距离特征之间的依赖关系以解决图像修复区域和未缺失区域的边界衔接问题。
1 系统模型
如图1 所示,系统主要采用生成式对抗网络框架[12]。该架构由生成器和鉴别器组成,生成器部分主要包含3个网络结构:粗修复网络、边缘修复网络、精修复网络。鉴别器采用补丁鉴别器[8,13]。

图1 三阶段修复算法结构图Fig.1 Structure diagram of three-stage inpainting algorithm
1.1 粗修复网络
为了能初步重建大面积不规则的缺失区域,粗修复网络结构参考文献[8]中的架构,由13 个普通卷积层和4 个空洞卷积层组成,其中普通卷积层包含两层卷积核大小为3,步长为2的下采样层,两层步长为1/2 的上采样层,上采样通过结合下采样中提取的各层信息,还原图像缺失区域;而4层空洞卷积层的空洞率大小分别为2,4,8,16,目的是为了扩大卷积核的感受野,提升网络性能。粗修复网络结构见表1 所示。
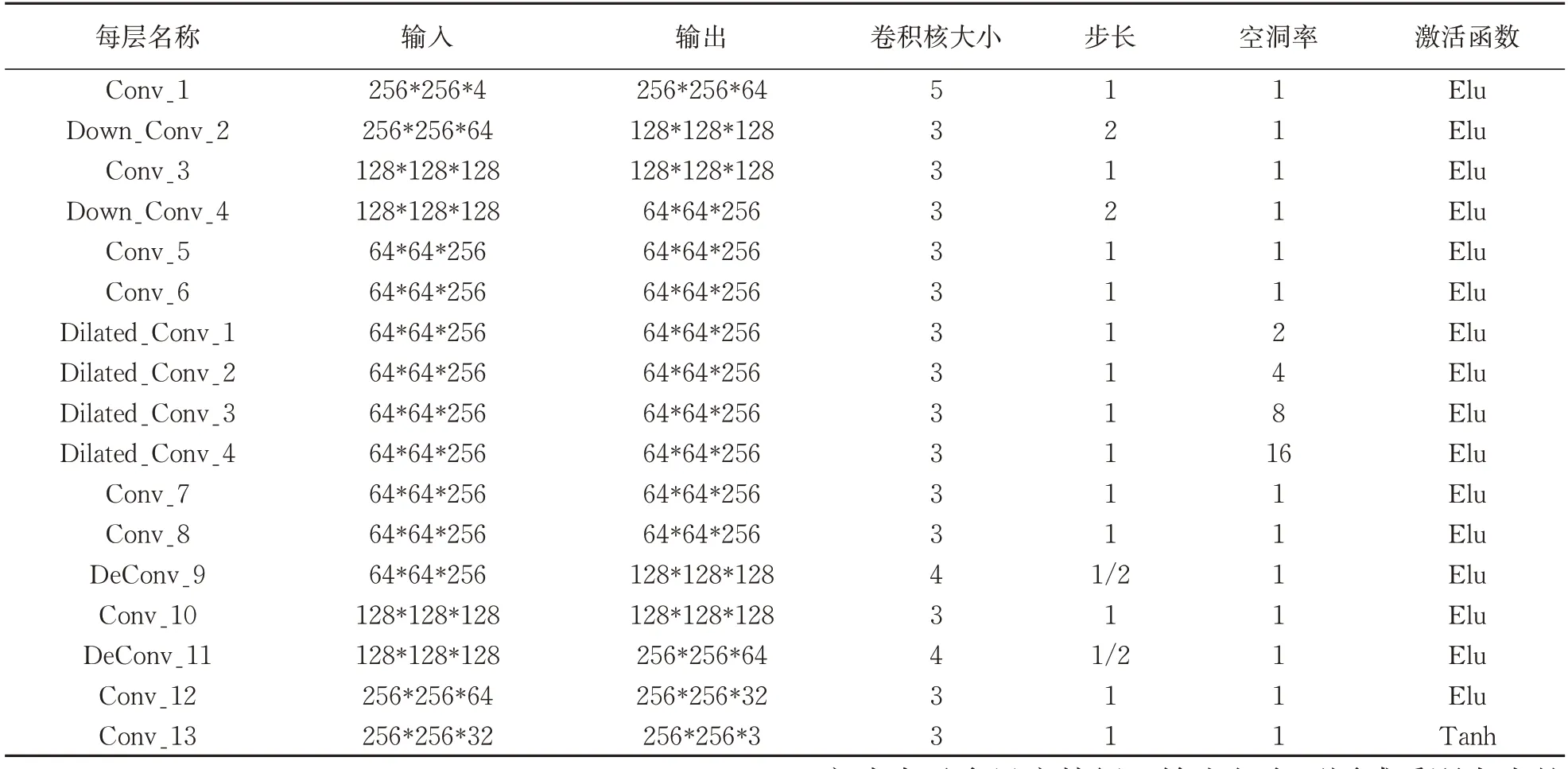
表1 粗修复网络结构Tab.1 Coarse inpainting network structure
用Igt代表原始图像,表示破损图片,M为随机生成的自由掩模(缺失部分为1,背景为0),粗修复网络Gc生成的修复结果为
1.2 边缘修复网络
利用canny 算子对粗修复网络Gc输出的结果进行边缘提取得到Bcanny,将Bcanny和自由掩模M输入到边缘修复网络Ge中。
边缘修复网络由13个普通卷积层、4个Res2net层和4个自注意力机制层组成[14],其中普通卷积层的结构与粗修复网络相同。Res2net层[15-16]以分层的方式表示多尺度特征,输出包含不同感受野大小的组合,该组合结构扩大感受野大小的同时,有效解决网格伪影现象;而自注意力机制通过自适应调节目标特征与周围特征相关性权重的方式加强特征之间的联系,以保证前景和背景的一致性。边缘修复网络结构见表2 所示。
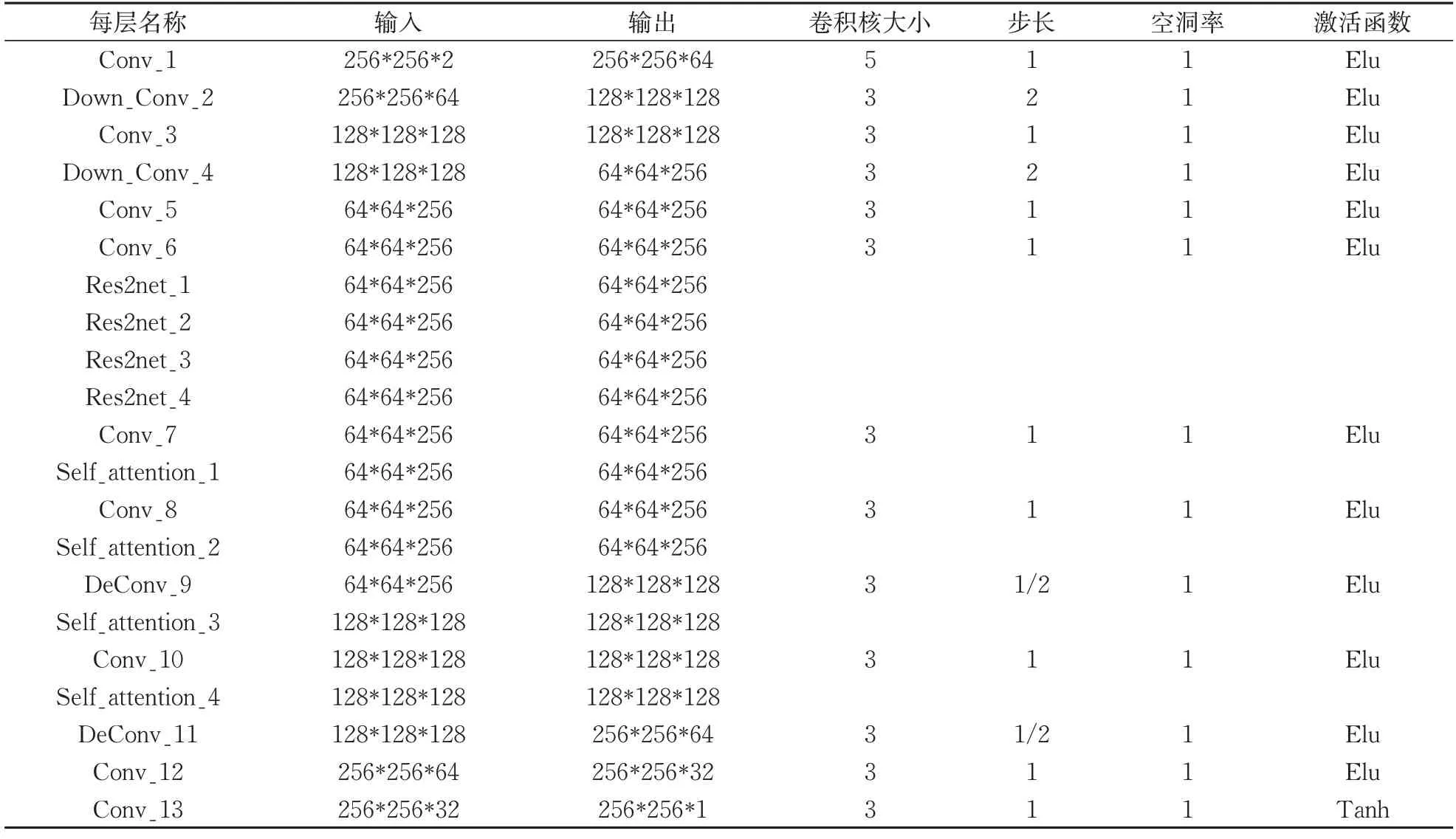
表2 边缘修复网络结构Tab.2 Edge inpainting network structure
边缘修复网络Ge输出边缘预测结果为
1.3 精修复网络
精修复网络结构基于U-net 架构[17],由13 个普通卷积层、4 个Res2net 层、4 个自注意力机制层组成,通过跳跃连接将编码器特征直接传输到解码器中。其中普通卷积层与粗修复网络中的结构相同,Res2net层、自注意力机制层与边缘修复网络中的结构相同;增加的跳跃连接结构将一些低维特征直接传递到后面的卷积层中,减少了特征损失。精修复网络结构见表3 所示。

表3 精修复网络结构Tab.3 Refinement inpainting network structure
将粗修复结果ICpre、边缘修复结果Bpre和自由掩模M共同输入到精修复网络中。精修复网络Gr的输入分别为
1.4 损失函数
粗修复网络Gc、边缘修复网络Ge和精修复网络Gr的损失函数分别为
联合损失函数定义为
鉴别器将生成的图像以及原图作为输入,并判断输入的生成图像是真是假。通过最大化鉴别器对抗损失训练网络,其中鉴别器D对抗损失定义为
2 实验与分析
实验配置为:64 位Windows 10 操作系统,Nvidia GeForce RTX 2080Ti,实验框架采用TensorFlow深度学习框架,编程语言使用python3.6。本文采用Celeba-HQ人脸数据集进行训练和测试,训练集包含20 000张256*256大小的人脸图像,测试集包含1 000张人脸图像。在训练阶段,本文算法的训练时间为62 h。在测试阶段,共耗时30 min 12 s 完成测试,平均每张图像需耗时1.812 s 完成修复。
为了验证本文算法的有效性,将本文算法与PatchMatch 算 法[2]、Deepfill-v1 算 法[8]、Edge-Connect 算法[9]和CTSDG 算法[10]进行对比实验,以主观视觉对比和客观指标分析两种评价方法进行实验对比分析。
2.1 主观评价
主观实验对比如图2 所示。其中第1,2行表示破损程度为[10%,20%)的实验对比图,第3,4 行表示破损程度为[20%,30%)的实验对比图,第5,6 行表示破损程度为[30%,40%)的实验对比图,第7,8 行表示破损程度为[40%,50%)的实验对比图。

图2 Celeba-HQ测试集实验结果Fig.2 Celeba-HQ test set experimental results
图2 中从左到右每一列分别表示原始破损图片,PatchMatch 算法、Deepfill-v1 算法、Edge-Connect 算法、CTSDG 算法,本文算法修复后的图片以及原始图像。
从修复对比图中第2 列可以看出,Patch-Match 算法在处理小规模缺失图像时,具有良好的性能表现,但随着破损区域规模的增大,该算法会产生扭曲的结构和大面积的伪影,原因在于该算法仅能利用周围已知区域来填充未知区域,当缺失部分较大时,存在的已知信息不足以修复完整的图像。从修复对比图中第3 列可以看出,Deepfill-v1 算法修复区域出现结构扭曲的现象,原因在于Deepfill-v1 算法只关注纹理修复,没有考虑结构的问题。从修复对比图中第4 列第3,4 行可以看出,修复结果产生了模糊的眼眶结构,原因在于Edge-Connect 算法会生成混合的边缘,通过使用边缘结构先验可能会导致错误的纹理结构。从修复对比图中的第4 列第7,8 行可以看出,CTSDG 算法修复结果中脸颊部分明显存在色彩鲜艳度缺失的问题,原因在于CTSDG 算法未注重缺失部分的色彩修复。相比于PatchMatch算法、Deepfill-v1 算法、Edge-Connect 算法和CTSDG 算法,本文算法得到了更好的图像细节与边缘,更接近于真实图像。
2.2 客观评价
本文使用峰值信噪比(Peak Signal to Noise Ratio,PSNR)和结构相似性(Structural Similarity,SSIM)定量评估5 种模型的修复结果。PSNR值越大,代表图像的失真越少;SSIM 指标值越大,代表和原始图像的差距越小,即修复结果图像质量越好。在相同破损程度的情况下,本文提出的修复算法的性能优于其他 4 种图像修复算法,如表4 所示。
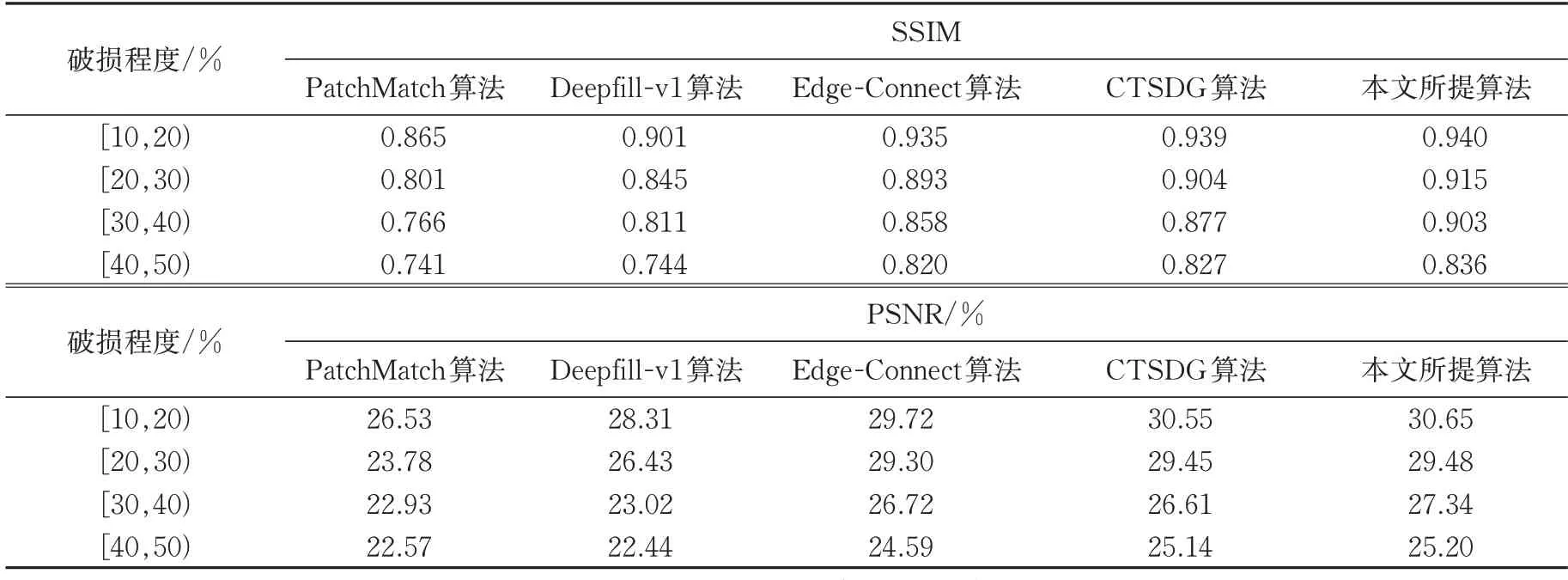
表4 各算法在Celeba-HQ测试集性能指标Tab.4 Celeba-HQ test set indicators of every algorithm
2.3 消融实验
为了说明本文所提网络各模块的有效性和必要性,对其进行消融实验,主要包括有无Res2net模块对比实验和有无自注意力机制对比实验。随机选取Celeba-HQ 数据集中的两幅图进行消融实验对比,并进行主观与客观指标评价。
图3 为消融实验的主观实验结果,如图3(b)中所示,在缺少Res2net 模块的情况下,恢复的人脸图像纹理、细节特征不清晰;由图3(c)可知,缺少自注意力机制将导致修复区域与已知区域缺乏一致性,出现前景与背景不融洽的现象。

图3 消融实现主观实验结果Fig.3 Subjective results of ablation experiments
表5 数据表明本文算法在缺少Res2net 模块情况下,PSNR 指标下降2.94%,SSIM 指标下降2.45%;在缺少自注意力机制情况下,PSNR指标下降3.32%,SSIM 指标下降1.79%。由此证明算法中加入Res2net 模块和自注意力机制会使修复图像的质量更好。

表5 消融实验客观指标对比表Tab.5 Ablation experiment objective index comparison table
3 结束语
针对人脸图像的特征复杂多样,细节和结构特征难以恢复等问题,提出了一种基于上下文特征提取的边缘生成三阶段的图像修复算法。首先,将待修复图像输入到粗修复网络中,对图像缺损部分进行初步修复;然后,将初修复结果所提供的边缘结构作为边缘修复网络的输入,完成边缘结构的细节重建;最后,将初修复结果和重建的边缘结构一起输入到精修复网络,共同约束图像的精修复过程,并在边缘修复网络和精修复网络中加入Res2net 模块、自注意力机制,增强了网络对于有限特征的提取能力,改善了图像目标区域与周围区域边界不连贯的问题。通过与4 种现有的修复方法在主观、客观方面的实验对比分析,本文所提算法修复的人脸图像,在SSIM 和PSNR 性能指标上优于现有算法,且在边缘细节的恢复中有着更好的视觉效果。
猜你喜欢
软件(2020年3期)2020-04-20
摄影之友(影像视觉)(2018年12期)2019-01-28
Coco薇(2017年8期)2017-08-03
通信产业报(2016年44期)2017-03-13
Coco薇(2015年5期)2016-03-29
北京信息科技大学学报(自然科学版)(2016年6期)2016-02-27
管理现代化(2016年3期)2016-02-06
管理现代化(2016年3期)2016-02-06
智能系统学报(2015年4期)2015-12-27
雕塑(1999年2期)1999-06-28
