
基于改进YOLOv5s的轻量级绝缘子缺失检测
2024-02-02 14:54池小波张伟杰贾新春续泽晋
测试技术学报 2024年1期
池小波,张伟杰,贾新春,续泽晋
(1.山西大学 自动化与软件学院,山西 太原 030013;2.山西大学 数学科学学院,山西 太原 030006)
0 引言
绝缘子状态检测和安全防护对保障输电线路的正常运行起着至关重要的作用。为了提高绝缘子的检测效率,无人机巡检已经代替人工巡检成为主流的巡检方式。由于无人机采集到的图片数量繁多且图像中的背景复杂,绝缘子尺寸大小存在很大差异,如果采用人工判读的方式极有可能出现误检和漏检。因此,利用计算机视觉和图像处理的技术进行绝缘子定位和故障检测成为目前主要研究方向。Dalal N等[1]采用方向梯度直方图(HOG)的方法提取目标特征,然后利用提取到的特征训练图像特征分类器;李卫国等[2],廖圣龙[3],刘洋等[4]分别从绝缘子的纹理特征、颜色以及轮廓入手,采用边缘计算的方法对绝缘子进行检测;黄新波等[5]针对玻璃绝缘子在光照条件下颜色特征不明显的问题,提出采用联合分量灰度化算法来进行目标增强。上述传统检测方法虽然可以识别绝缘子,但是其泛化性和鲁棒性较差,识别准确率也较低。
目前应用广泛的基于深度学习的目标检测模型主要分为两大类:一类是基于回归的一阶段(one-stage)检测方法,该类方法直接对图像上的目标进行预测和分类,不需要预先生成候选框,常见的one-stage 模型有SSD[6]以及YOLO 系列的改进模型,如YOLOv2[7],YOLOv3[8]等;另一类是基于候选区域的两阶段(two-stage)检测算法,首先通过算法生成一些候选框,进而对候选区域进行分类和位置修正,R-CNN[9]、Faster-RCNN[10]等是two-stage 的代表模型。Tao X 等[11]提出一种深度卷积神经网络(CNN)级联架构,用于定位和检测绝缘子缺陷;何宁辉等[12]采用改进的Faster-RCNN 网络捕获图像中绝缘子和缺失部位。随着YOLOv4[13]和YOLOv5 等方法的提出,不论是检测精度还是速度,one-stage 均大幅度优于two-stage。刘行谋等[14]提出一种基于K-means和YOLOV4 的复杂背景下绝缘子缺失检测方法;王年涛等[15]利用GhostNet 模块改进YOLOv5 主干网络,提升了模型的检测精度;田庆等[16]通过引入注意力模块,提出基于SE-YOLOv5s的绝缘子检测模型,显著提升模型的准确率和召回率。尽管上述文献已经取得了一些有价值的研究成果,但在实际应用场景中,这类目标检测模型均存在参数量大、计算复杂度高、推理速度较慢等问题。针对这些问题以及考虑到航拍绝缘子图像背景复杂、小目标检测困难等现状,本文提出一种基于改进YOLOv5s 的轻量级绝缘子缺失检测模型,实验结果表明,所提模型对小目标、遮挡目标以及模糊等场景有着较强的鲁棒性,且在保证近似检测精度的同时极大减少了计算量。
1 YOLOv5s模型结构
YOLOv5s 模型由输入端(Input)、主干网络(Backbone)、Neck 模块、输出端(Output)4 个部分组成。YOLOv5s 模型输入端采用Mosaic 数据增强和自适应图片缩放等方法对图像进行预处理。主干部分包括切片模块(Focus)、卷积模块(Conv)、C3 模块和空间金字塔池化模块(SPP)。其中,Focus模块是YOLOv5系列所特有的结构,当进行切片操作时,可确保下采样不会丢失信息;SPP 模块解决了卷积神经网络对图像特征重复提取的问题,提高了产生备选框的速度;C3模块主要起到了精简网络结构,减少计算量的作用。Neck模块部分采用特征金字塔网络(FPN)+路径聚合网络(PAN)的多尺度特征融合结构,FPN 通过上采样操作融合高层特征和底层特征信息;PAN则采用下采样的方式传达信息。
2 改进的YOLOv5s模型结构
2.1 主干网络轻量化
原始的YOLOv5s 模型各模块的层数及参数量如表1 所示。其中C3 模块通过引入1×1 的卷积核来降低整个模型的参数量。通过比较可知,主干网络中C3模块的层数较多且参数量大。为了降低网络计算复杂度,同时考虑小目标难以检测以及有遮挡物、相似目标干扰等问题,本文提出一种融合的轻量级绝缘子缺失检测模型。

表1 各模块层数及参数量Tab.1 Layers and parameters of each module
2.2 CBAM注意力机制
由于所采集的图像存在分辨率和像素值较低以及目标通道特征信息较少等问题,本文在Concat 模块之后嵌入CBAM(Convolutional Block Attention Module)模块[17],使网络能够更好地关注绝缘子缺失部位的特征信息。CBAM 结合了空间(spatial)和通道(channel)的注意力机制,结构如图1 所示。

图1 CBAM整体结构Fig.1 Overall structure of CBAM
CBAM的整体注意力过程表示如下
式中:将中间特征图F∈RC×H×W作为输入,CBAM依次输出一维通道注意力图MC∈RC×1×1和二维空间注意力图MS∈R1×H×W;⊗表示逐元素相乘;C为特征图通道数;H和W分别为特征图的高度和宽度。如图2 所示,通道注意力模块MC(F)为
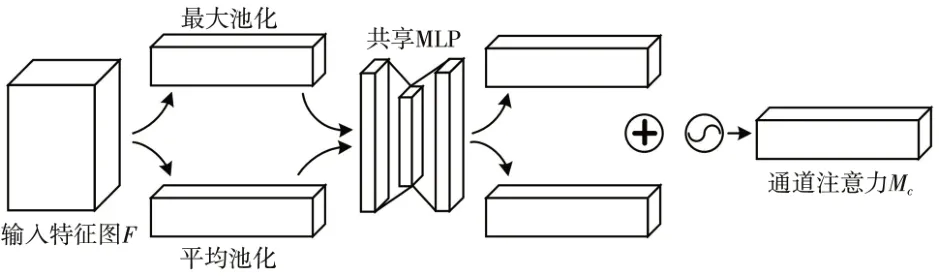
图2 通道注意力模块Fig.2 Channel attention module

图3 空间注意力模块Fig.3 Spatial attention module
式中:σ为sigmoid 函数;MLP(Multi-Layer Perceptron)表示多层感知器;AvgPool 和MaxPool 分别表示对特征图进行平均池化和最大池化操作;分别为平均池化特征和最大池化特征;W0∈RC/r×C,W1∈RC×C/r为MLP的权重。
式中:σ为sigmoid 函数;f7×7为大小为7×7 的卷积运算。
2.3 双向特征金字塔网络多尺度特征融合
随着检测网络层数的不断加深,特征逐渐由低层转向高层。其中,低层特征由于分辨率较大,具有更强的位置信息,适合对目标进行定位;高层特征由于感受野较大,具有更强的语义信息,适合对目标进行分类。然而,在特征转变过程中会造成低层特征信息的丢失,因此需要对不同尺度的特征进行融合,丰富特征的语义信息。不同特征融合网络结构如图4 所示。其中,PAN 和FPN 均未考虑不同分辨率下特征的贡献差异问题。因此,本文采用加权双向特征金字塔网络(WBiFPN)[18]构造双向通道,对特征进行跨尺度连接来实现加权融合。如图4(c)中所示,对于同层级的原始输入和输出节点,WBiFPN 对两者进行了连接,在增加极小计算量的情况下融合更多特征。
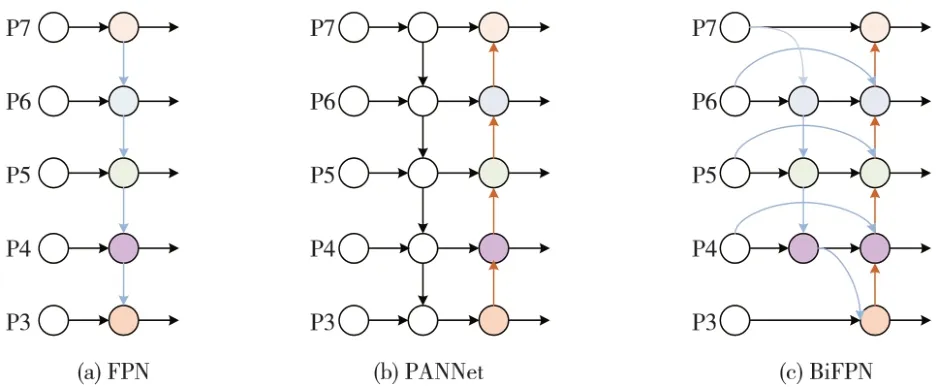
图4 不同特征融合网络结构Fig.4 Network structure of different feature fusion
由于不同的输入特征分辨率不同,所以,对输出特征的贡献程度也不同。WBiFPN 为每个输入特征赋予可学习的权重,令网络可根据输入特征的重要程度自主调整权重。
式中:ωi为可学习的权重,使用ReLU激活函数来保证ωi≥0;O为输出特征;Ii为输入特征;ε=0.000 1是一个很小的值,以保证数值的稳定。以层级6为例,式(6)和式(7)描述了WBiFPN网络的双向跨尺度连接和加权特征融合的过程。
式中:Resize通常指上采样或下采样操作;为自上而下路径第6层的中间特征;为由底向上路径第6层的输出特征;Pin和Pout分别为输入和输出特征。为了满足轻量化的要求,本文使用Add融合模块,在不增加参数量的情况下对特征进行跨尺度加权融合,保证所提取特征的完整性。
2.4 SIoU损失函数
传统的目标检测损失函数仅考虑了真实框和预测框之间的距离、重叠区域和纵横比这几类指标,未考虑预测框收敛时的方向特征。本文使用SIoU 损失函数,其由Angle cost,Distance cost,Shape cost,IoU cost 4 个Cost 函数组成。Angle cost 对损失函数的贡献方案如图5 所示,其中B为预测框,BGT为真实框,若收敛过程将优先最小化α,否则最小化β。
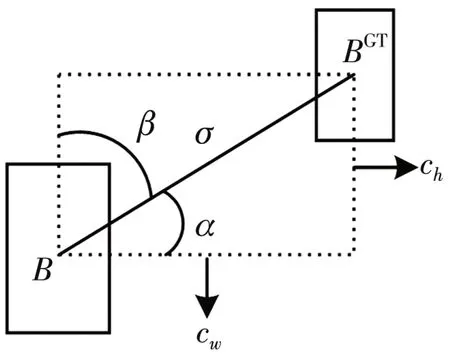
图5 Angle cost示意图Fig.5 Schematic diagram of Angle cost
Angle cost表达式为
Distance cost对损失函数表达式为
式中:cw为预测框和真实框的水平距离;ch为预测框和真实框的竖直距离。可以看出,当α→0时,Distance cost 的贡献程度随之变小;而当时,贡献程度则越来越大。
Shape cost表达式为
IoU cost表达式为
最后,回归损失函数表达式为
总的损失函数表达式为
式中:Lcls为Focal loss;Wbox,Wcls分别为框和分类损失权重,可用遗传算法进行选择。图6 为改进的YOLOv5s模型结构图。

图6 改进的YOLOv5s模型结构图Fig.6 Improved YOLOv5s model structure diagram
3 实验结果与分析
3.1 数据集设置
本文所使用的数据集一部分来自于中国电力线绝缘子数据集(CPLID)[11],另一部分利用背景融合、随机旋转、添加噪声等数据增强的方式对数据集进行扩充。图像中包含完整的绝缘子串以及有缺失部分的故障绝缘子。数据集共包含4 618 张图片,训练集、测试集、验证集按照8∶1∶1的比例划分。
3.2 深度学习环境配置
本文所提方法是在pytorch框架上实现的。操作系统为Ubuntu,CPU 为24 核AMD EPYC 7642 48-Core Processor,内 存80 G,GPU 为NVIDIA GeForce RTX 3090,显存24 G。
3.3 参数设置
对输入图像进行Mosic 增强,增加训练数据的多样性,提高模型的泛化能力。初始学习率Ir0=0.001,采用余弦退火策略更新学习率,终止学习率Irf=0.2;优化器选用SGD,动量momentum=0.937,避免网络出现局部最优解的情况;输入图像的尺寸、batch_size和训练轮数分别为640*640,16和300。
3.4 评价指标
本文选用mAP@0.5 和mAP@0.5:0.95 作为模型检测精度的评价指标,mAP@0.5 为IOU=0.5 时的平均精度均值,mAP@0.5:0.95表示IOU 从0.5 到0.95,步长 为0.05 时mAP 的平均值。其中,IOU 为交并比,mAP综合考虑了模型的精确率P(Precision)和召回率R(Recall);使用浮点运算数(GFLOPS)作为模型计算量的评价指标;使用参数量(Parameters)作为衡量模型大小的指标;使用每秒处理图像的数量(FPS)来评价模型的检测速度。选用评价指标计算公式为
式中:A为真实框;B为预测框;TP为正例被正确判断为正例的数量;FP为负例被错误判断为正例的数量;FN为正例被错误判断为负例的数量;AP为P-R曲线所围成的面积;mAP为各类别AP的平均值,mAP越高,表示模型的精确度越好。
3.5 消融实验
为验证本文所提 4 种改进策略的有效性,使用上述数据集进行消融实验,分别测试每种改进以及混合使用的效果。消融实验结果如表2 所示,其中表2 第 1 行为原始YOLOv5s的实验结果。

表2 消融实验结果Tab.2 Ablation experiment results
通过分析可知,去除C3模块之后模型的浮点运算数是2.8 GFLOPS,仅为原始模型的17.2%,参数量为1.22 M,是原始模型的18.1%,精确度下降了约1.6%。实验表明去除C3模块可以有效减小模型的计算量和参数量,达到轻量化的目的,但是也带来了一些精度上的损失。接下来在去除C3模块的基础上对检测精度进行提升。由表2 可以看出,每一处改进之后模型的检测精度都会有提高,且计算量与参数量没有增大。综合来看,当 4 处改进同时进行时的效果最佳,精确度相较原始模型降低约0.8%,浮点运算数依然为2.8 GFLOPS。结果表明,计算量和参数量明显降低,精确度损失极小,符合本文所提出轻量化检测的目标。
3.6 鲁棒性检测实验
为了更直观地展示所提模型的性能,本文选取了小目标、遮挡目标以及模糊 3 个特殊场景进行检测,检测结果如图7 所示,左边为原始YOLOv5s 检测结果图,右边为改进后的YOLOv5s 检测效果图。由图7(a)可以看出,原始YOLOv5s 漏检了图像上占比较小的绝缘子部分,改进后的模型可以顺利检测出小目标;图7(b)是在有遮挡物的场景中,原始YOLOv5s没有检测出杆塔遮挡下的绝缘子,由于本文引入WBiFPN 结构,使得模型能够在融合了不同层次语义信息的全局特征中进行学习,从而使模型在预测时能更好地区分背景和目标,提高了在有遮挡物情况下目标的识别率。因此,改进之后的模型可以很好地检测出有遮挡物的绝缘子;图7(c)中,原始YOLOv5s 误将图像右上角的一排树木看作绝缘子,在存在相似目标的场景中,本文所提YOLOv5s 模型能精确地识别绝缘子。实验表明,原始YOLOv5s 模型在复杂多样的检测场景下出现了较多的漏检以及误检的情况,而本文所提模型对此类特殊场景有很好的鲁棒性,检测效果明显优于原始YOLOv5s模型。
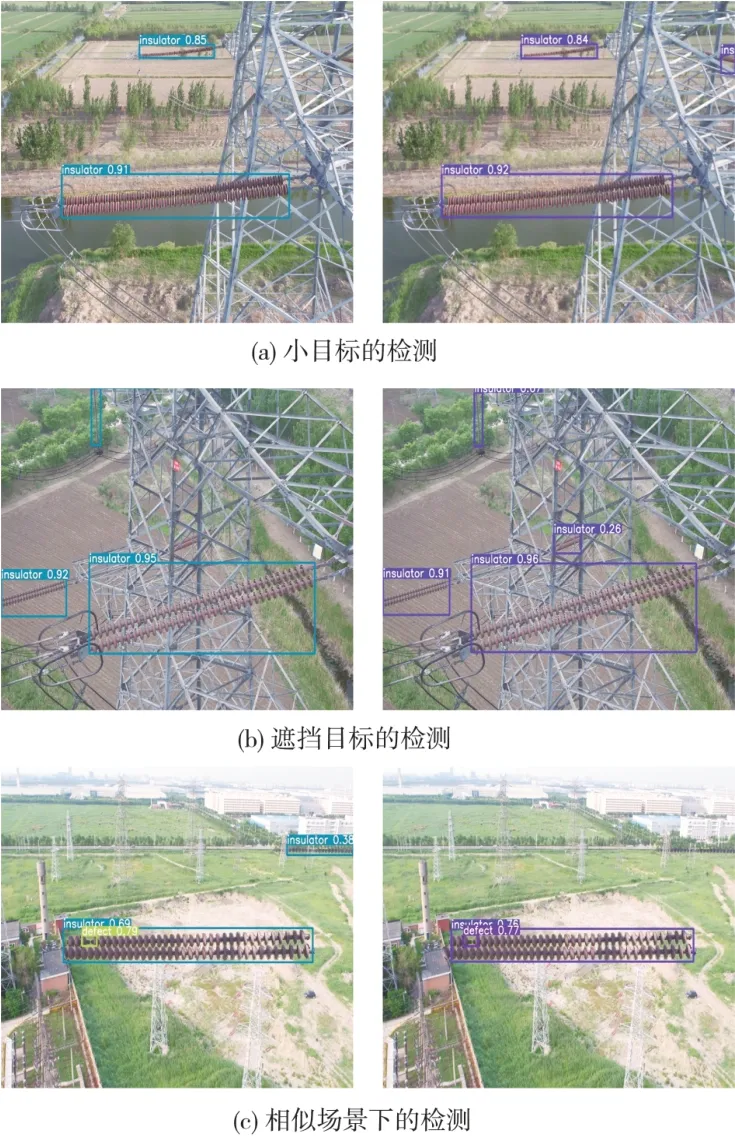
图7 特殊场景检测结果对比图Fig.7 Comparison of detection results in special scenes
3.7 对比实验
为了证明所提模型的优越性,本节将从模型轻量化、注意力机制以及检测性能 3 个角度设计对比实验。首先,在主干网络中分别对shuffle-NetV2,ghost,mobileNetV3 3 种轻量级模型进行对比,试验结果如表3 所示。
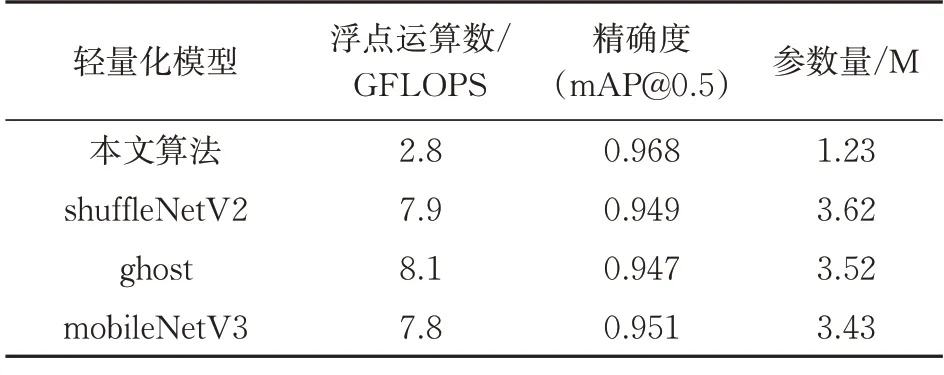
表3 不同轻量化模型的性能对比Tab.3 Performance comparison of different lightweight models
由表3 可知,本文所提算法的精确度为96.8%,浮点运算数为2.8 GFLOPS,均优于其他3种轻量级模型。实验结果验证了本文所提算法在保证较高目标识别精确度的同时具有较低的计算量。其次,在改进YOLOv5s 模型中分别引入CBAM、CA(Coordinate Attention)、SE(Squeeze-and-Excitation)和ECA(Efficient Channel Attention)4 种注意力机制进行对比研究,具体结果如表4 所示。

表4 不同注意力机制下改进YOLOv5s模型的性能对比Tab.4 Performance comparison of improved YOLOv5s model under different attention mechanisms
分析数据可知,由于选用的都为轻量级注意力机制,因此,在浮点运算数和参数量方面差别较小。由于CBAM注意力机制可以同时关注到空间和通道信息,抓取重点特征,抑制一般特征,因此,融合了CBAM注意力机制的改进YOLOv5s模型的目标识别精确度明显优于其他 3 种注意力机制。
为了进一步评估所提模型的有效性,使用上述数据集分别对YOLOv3,Faster-RCNN,SSD,YOLOv5s、改进的YOLOv5s进行对比实验,结果如表5 所示。通过对比可以看出,本文模型因减少了神经网络的深度,检测精度相较于原始YOLOv5s下降了0.8%,但仍高于YOLOv3和SSD等模型。在计算量、参数量和推理速度方面表现出极大的优越性,实验结果验证了所提模型的有效性。

表5 与现有目标检测模型性能对比结果Tab.5 Performance comparison results with existing target detection models
4 结论
本文提出了一种基于改进的YOLOv5s 轻量级绝缘子缺失检测模型。为了弥补主干网络轻量化所带来的精度损失,在Neck部分融合了轻量级CBAM 注意力模块,并采用WBiFPN 机制有效提高了模型对重点信息的感知能力,最后利用SIoU损失函数提高模型的收敛速度。实验结果表明,本文所提模型很好地解决了现有绝缘子故障检测模型存在的计算量大、复杂度高以及对小目标漏检和误检的问题;在保证近似检测精度的情况下,极大减小了计算量和复杂度,使得该模型更适用于实际工作场景。后续将针对因相机抖动而导致图像模糊难以检测的问题进行深入研究。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09
疯狂英语·新策略(2019年10期)2019-12-13
当代陕西(2019年10期)2019-06-03
数学小灵通·3-4年级(2017年9期)2017-10-13
传媒评论(2017年3期)2017-06-13
第二课堂(课外活动版)(2016年2期)2016-10-21
电力建设(2015年2期)2015-07-12
电测与仪表(2014年6期)2014-04-04
电气传动自动化(2014年6期)2014-03-20
河南科技(2014年23期)2014-02-27
