
基于边缘增强和特征融合的伪装目标分割
2024-01-31 06:13李明岩吴川朱明
液晶与显示 2024年1期
李明岩, 吴川*, 朱明
(1.中国科学院 长春光学精密机械与物理研究所, 吉林 长春 130033;2.中国科学院大学, 北京 100049)
1 引言
伪装原本是指动物用来隐藏自己或欺骗其他动物的一种方法,而伪装能力通常会影响这些动物的生存概率。随着仿生学技术的发展,伪装技术也常被人类应用于某些场合,例如现代军队所使用的迷彩。与显著目标检测(Salient Object Detection, SOD)相比,伪装目标通常与背景具有高度相似性,因此伪装目标检测(Camouflage Object Detection, COD)更加具有难度。
传统的方法主要关注图像的底层特征(如颜色、纹理、梯度等)来评估物体与背景的差异,基于三维凸度[1]、灰度共生矩阵[2]、Canny边缘检测器[3]、光流[4]等方法进行伪装目标检测。这些方法往往只考虑图像的一部分特征,难以适用于所有场景。近年来,深度学习的方法在许多领域展现出优异的性能,为一些传统方法难以处理的问题提供了新的解决方案[5]。在图像领域,通过卷积神经网络(Convolution Neural Network,CNN)提取出的深度特征的表示能力要远强于图像的底层特征,因此,研究人员开始尝试用深度学习的方法来解决伪装目标分割的问题。Le等人建立了一个新的伪装图像数据集用于基准测试,并提出了一个端到端网络,其中包括一个分割分支和另一个分类分支。分类分支用于预测图像包含伪装对象的概率,随后用于增强分割分支中的分割性能[6]。Fan等人提出了SINet模型,该模型包含两个模块:搜索模块定位伪装目标,识别模块精确检测伪装目标,同时建立了首个大规模伪装目标数据集[7]。Mei等人在伪装目标分割任务中引入了干扰的概念,开发了一种新的干扰识别和去除的干扰挖掘方法,帮助对伪装目标的准确检测[8]。Zhai等人将特征映射解耦为两个特定的任务:一个用于粗略地定位对象,另一个用于准确地预测边缘细节,并通过图迭代推理它们的高阶关系[9]。Li等人提出联合训练SOD和COD任务,利用相互矛盾的信息同时提高两个任务的表现[10]。
以上模型在多个伪装目标数据集上已经取得了较好的效果,但仍存在一些问题:模型的全局建模能力不足,在存在多个伪装目标且与背景高度相似时,模型容易出现漏检和误检的问题。其次,这些模型舍弃了较低层次的特征,而较深层次的特征在进行数次下采样后分辨率迅速下降,虽然减少了计算量,但同时也丢失了大量的边缘等细节信息,这也导致了模型的精度下降。最后,这些模型大多使用了极其复杂的特征融合策略,大幅提高了模型的复杂度与推理时间。
针对以上问题,本文提出了一种基于边缘增强和多级特征融合的伪装目标分割模型。首先,选择ResNet-50作为骨干网络,提取多级深度特征。其次,设计了一个边缘提取模块,选择融合细节信息丰富的两个较低层级特征,通过网络的不断学习,得到精确的边缘先验。同时,通过引入多尺度特征增强模块和跨层级特征聚合模块,分别在层内和层间增强特征表示,弥补多尺度表征能力不足的问题。之后,设计了一种简单但有效的层间注意力模块,利用相邻层的差异性,有选择地筛选出各层级间有用的信息,在保持层内语义完整的同时滤除背景噪声,再与边缘先验引导结合,输出精确的预测图。最后,为了增强网络的学习能力,本文采用加权二元交叉熵损失与加权IOU(Intersection-Over-Union)损失两部分作为损失函数,对3个不同尺度的输出预测同时进行深度监督;采用单独的加权二元交叉熵损失对边缘预测图进行监督,边缘的真值可以使用Canny边缘检测方法从标注图中得到。本文方法在4个伪装目标公开数据集CHAMELEON[11]、CAMO[6]、COD10K[7]、NC4K[12]上与先进的方法进行对比实验。实验结果表明,本文方法在所有数据集的4个常用的评价指标上均优于其他方法,同时能够满足实时性的需要,表明本文方法在伪装目标分割任务上具有优异的性能。
2 本文方法
如图1所示。对于一幅输入图像I∈RH×W×3(其中H为图像高,W为图像宽,通道数为3),采用ResNet-50作为特征提取网络[13],获得不同尺度的特征fi,i∈{1,2,3,4,5}。首先,使用一个边缘提取模块来显式地建模边缘特征,以此指导网络学习并提升检测性能。然后,将获得的多级特征通过多尺度特征增强模块(Multi-scale Feature Enhanced Module, MFEM)筛选出更具辨识度的特征。增强后的特征图每3个层级为1组,同时输入到跨层级特征聚合模块(Cross-level Fusion Module, CFM),有选择地结合不同尺度下的有效特征。通过注意力模块给有价值的信息以更高的权重。最后与边缘信息加以结合,得到最终的伪装目标分割预测图。
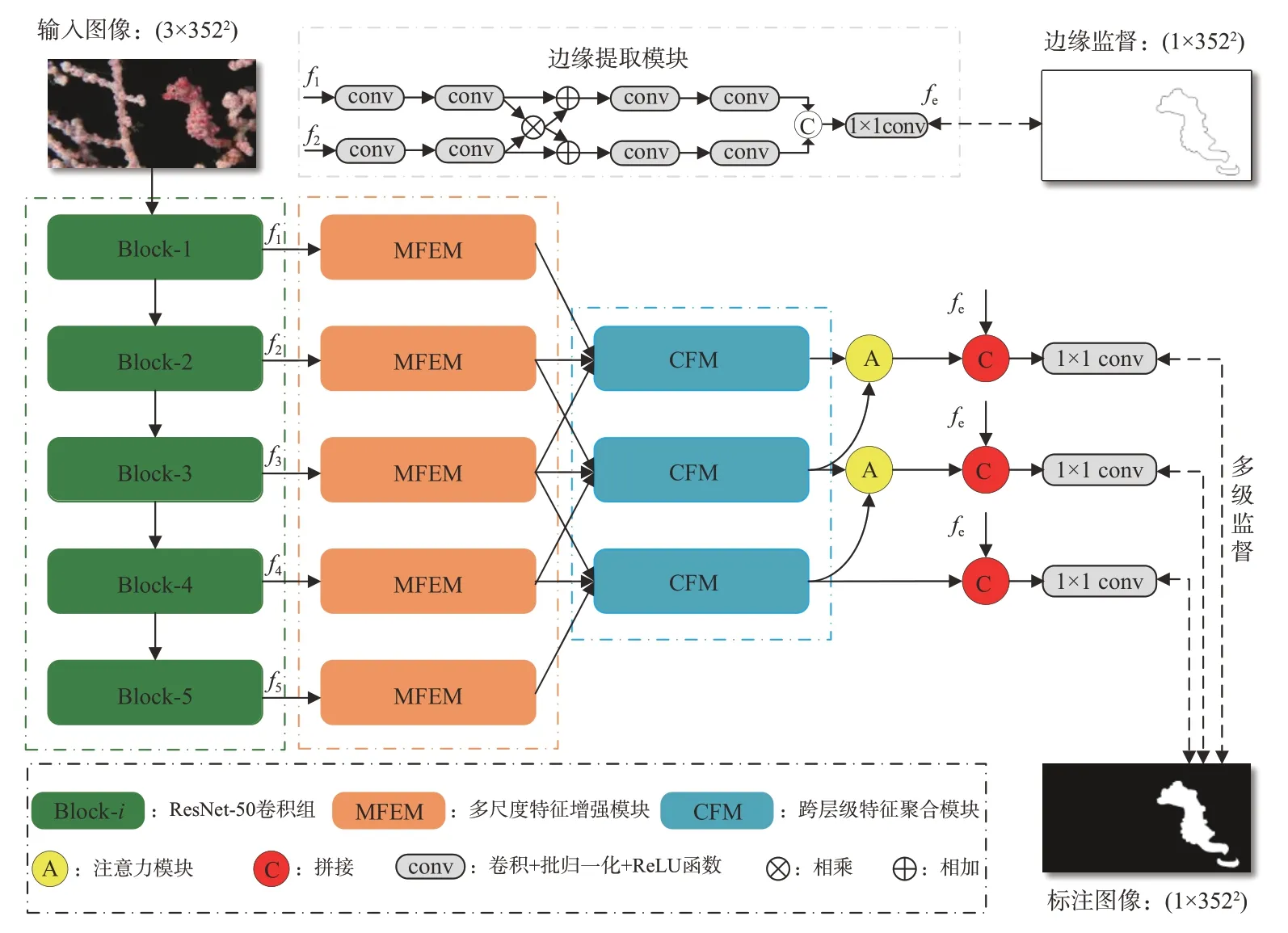
图1 网络结构图Fig.1 Network structure diagram
2.1 边缘提取模块
早期的一些相关工作[14-15]已经证实了边缘信息有助于提升计算机视觉任务的性能。在伪装目标分割任务中,由于目标与背景的高度相似性,难以清晰地辨别伪装对象与周围环境之间的边界。现有的研究表明[16],通常只有低级特征保留了大量的边缘细节信息,而在经过多个下采样操作后,细节信息会丢失。因此,本文设计了一个边缘提取模块,如图1所示。自ResNet-50中提取出最低两层的特征分别经过两个包含3×3卷积、批归一化(Batch Normalization, BN)及ReLU激活函数的卷积组,用来保证两组特征的通道数一致。然后通过逐元素相乘的方式得到融合的特征表示。将融合后的特征分别与卷积后的特征相加,用来抑制背景噪声和增强感兴趣区域。增强后的特征再次分别输入两个卷积组,通过拼接和一组1×1卷积进行降维,得到全局边缘引导特征图fe。最后,将边缘特征图通过双线性上采样的方式恢复到与原图相同的尺寸,用来监督学习边缘表示。目标边缘的真值图可以通过对二值标注图进行Canny边缘检测得到。
2.2 多尺度特征增强模块
伪装目标通常具有较大的尺度范围。每个单独的卷积层只能处理一种特定的尺度,为了从单个层级获取多尺度信息以表征尺度的变化,受Inception-V3[17]启发,设计了一个多尺度特征融合模块(MFEM),如图2所示。对于每个输入的特征fi,每个MFEM包含4个并联的残差支路和一个主路。在每个残差支路中,首先使用一个1×1卷积将特征的通道数降为64。接下来的两层分别为(2i-1)×1和1×(2i-1)大小的卷积核,i∈{1,2,3,4}。这两层卷积的串联等效于两个(2i-1)×(2i-1)大小的卷积核的串联,在不影响模块表征能力的同时能够减少计算的损耗。在支路的最后是一个膨胀率为(2i-1),i∈{2,3,4}的3×3卷积层,增大感受野以捕捉细粒度特征。最后,将4个支路的特征拼接在一起并通过卷积来保证通道数一致,拼接后的特征与主路相加后,通过ReLU函数来获得输出特征
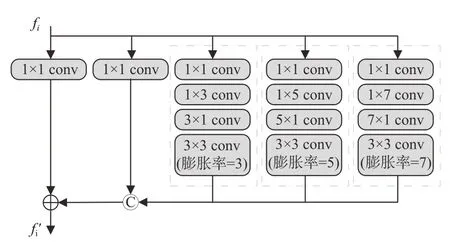
图2 多尺度特征增强模块Fig.2 Multi-scale feature enhanced module
2.3 跨层级特征聚合模块
在跨层级特征融合的过程中,如何有效地保持层内语义的一致性及利用层间的相关性是构建伪装目标分割网络的关键。为此,本文提出了一个跨层级特征聚合模块(CFM),如图3所示。给定一组特征fi-1,fi,fi+1,i∈{2,3,4},首先将较高层的特征fi+1与中间层特征fi分别经过一个卷积组后进行逐元素相乘,其中fi+1在卷积前进行一次双线性上采样操作以保证维度大小相同。将聚合后的特征再次进行上采样与卷积操作并与较低层特征相乘,得到i∈{2,3,4}。之后,将初步融合后的特征由较高层到较低层逐级进行拼接操作。最后,将拼接后的特征矩阵分别经过一个3×3大小的卷积组和一个1×1大小的卷积核,将通道数减少为原始通道数,得到最后的输出特征ffusei,i∈{2,3,4}。整个过程定义如式(1)~式(5)所示:
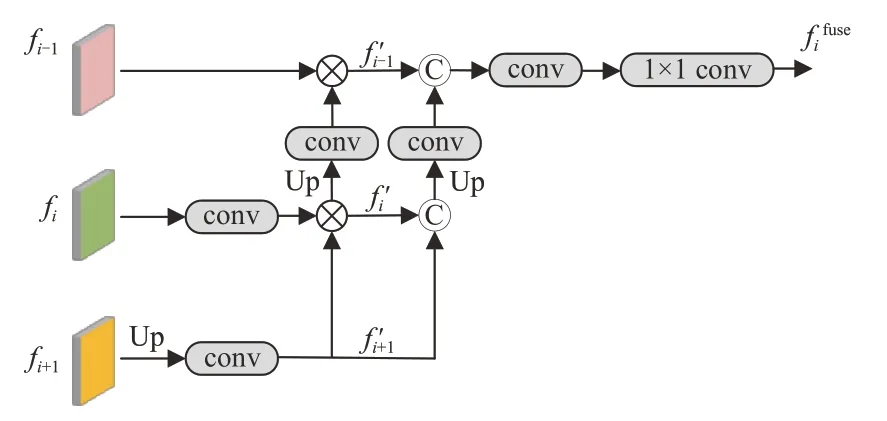
图3 跨层级特征聚合模块Fig.3 Cross-level fusion module
其中:Conv↑(· )表示一个2倍的双线性上采样接一个包含3×3卷积、批归一化和ReLU函数的卷积组,Cat(· )表示对括号内的两个元素进行拼接操作,Conv1(· )是一个单独的1×1卷积核。接着,将输出特征传入注意力模块进行筛选。
2.4 注意力模块
通过简单的拼接或相加的方式融合的特征往往是复杂且低效的,大量的噪声及低置信度的信息混杂在一起会对网络的学习造成巨大的困难。为此,设计了一个简单的注意力模块,对CFM融合后的特征进一步结合并筛选,模块结构图见图4。首先将两组相邻层级的特征fi,fi+1,i∈{2,3}进行卷积处理,再分别通过一个1×1卷积将通道维度由C降为1。即:
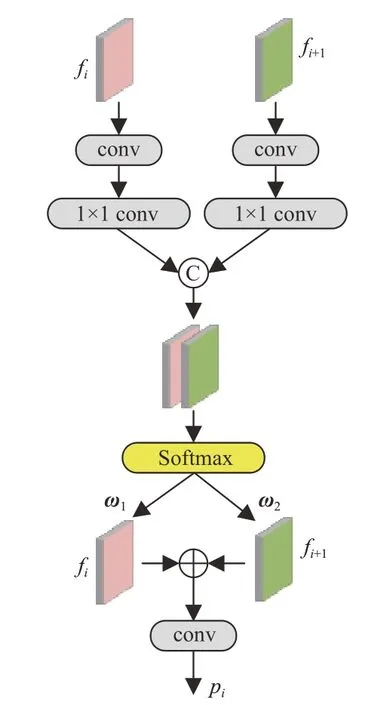
图4 层间注意力模块Fig.4 Cross-layer attention module
其中:h、w分别表示特征的高度、宽度两个维度的大小,c为通道数。将处理后的矩阵拼接并在通道维度上进行Softmax函数计算,可以得到两个不同的权重矩阵将两个权重矩阵分别与对应的特征图相乘,可以得到:
f(x,y)表示该特征矩阵上对应于(x,y)位置的元素。其中,ω值越大,表示该位置的信息越应该被保留,反之则被舍去。最后,将两个特征相加,并经过卷积平滑操作,得到最终的输出结果:
采用这种注意力机制可以有效地筛选出各级特征中更有效的信息,抑制噪声,增强不同尺度特征的表示能力。需要注意的是,由于f4是由较高3个层的特征聚合得到,在卷积的过程中已经被过滤掉了大量的细节和噪声信息,因此将f4不经过注意力机制筛选而直接输出,即:
最后,将p2、p3、p4分别与全局边缘引导fe拼接,经过1×1卷积降维后,上采样回原图尺寸,得到最终的预测图P2、P3、P4。其中P2作为最终的预测结果用来评估网络性能。
2.5 损失函数
在伪装目标分割过程中,使用了加权二元交叉熵损失[18](weighted binary cross entropy loss,wBCE)及加权交并比损失[18](weighted intersection-over-union loss, wIOU)两部分作为损失函数。加权二元交叉熵函数的公式如式(11)所示:
其中:yi是二元标签0或1,zi为输出属于yi标签的概率,wi为权重向量。加权交并比损失的公式如式(12)所示:
其中:P为预测值,G为真实标注值。两种损失函数分别计算全局损失和像素级损失。与标准的损失函数不同,加权损失更侧重于给较难的像素更大的权重,而不是给每个像素相同的权重。
基于上述分析,使用联合损失函数对P2、P3、P43个预测图及边缘预测图fe进行深度监督。整体的损失函数可以表示为:
其中:Eg表示边缘标注值,可以通过对二元标注图进行Canny边缘检测得到。pg表示二元标注图。没有对边缘使用LwIOU损失函数监督是因为边缘预测图的前景区域与背景区域差别过大,可能导致损失函数下降不稳定。λ1和λ2用来平衡两个不同损失函数对整体损失的贡献,其中λ1设置为5,λ2设置为1。
3 实验与分析
3.1 数据集
我们在4个通用的伪装目标标准数据集上进行实验:CHAMELEON[11]是一个小样本的伪装目标数据集,其中包含76张图像,每张图像至少有一个伪装目标;CAMO[6]包含1 000张用于训练的图像和250张用于测试的图像,数据集涵盖了大量自然及人工场景下的伪装目标;COD10K[7]是迄今为止最大的基准数据集,它包含5个大类和69个子类,共有3 040张训练图像和2 026张测试图像;NC4K[12]是规模最大的伪装目标测试数据集,包含4 121张图像,可用来评估模型的泛化能力。仿照之前的工作[7],本文将CAMO的训练集和COD10K的训练集结合,作为完整的训练数据集(其中包含4 040张图片),并在余下的数据集上测试模型的性能。
3.2 评价指标
本文使用了4个广泛使用的评价指标:结构性度量(Sα)[19]、E指标(EØ)[20]、带权重的F指标[21]及平均绝对误差(MAE)[22]。
结构性度量(Sα)评估预测结果及标注图像之间的区域级和对象级结构相似性,如式(16)所示:
其中,So和Sr分别表示对象级和区域级的结构相似性。根据其他研究中的经验[19],这里的α设置为0.5。
E指标(EØ)使用一个矩阵(ØFM)联合计算图像级的统计信息和像素级的匹配信息,可以同时衡量预测的整体完整性和局部精确性,如式(17)所示:
其中:w表示图像宽度,h表示图像宽。
带权重的F指标定义一个加权精度(Pw)和加权召回率(Rw)来衡量预测的准确性和完整性:
其中,β2是一个平衡系数,根据其他研究中的经验[21],β2设置为0.3。
平均绝对误差(MAE)用来衡量预测结果与标注图像之间的像素级差异,其被广泛应用于各类分割任务:
为了进行公平的对比,我们使用相同的代码,对不同数据集的4种评价指标进行计算。
3.3 实验细节
本文模型基于Pytorch框架构建,在NVIDIA GeForce RTX 2080TiGPU上进行所有实验。使用在ImageNet上预训练的权重文件初始化ResNet-50骨干网络的参数,其他参数由网络默认生成。在训练之前,所有训练图像及标注图像均被调整为352×352大小,并且不使用任何数据增强策略。批量大小设置为8并在训练过程中使用了Adam优化器,初始的学习率设置为1e-4,并且每30次迭代后,学习率除以10,网络共训练60轮,大约需要5.5 h。在测试过程中,测试图像同样被调整为352×352大小,随后输入网络。预测图通过双线性上采样操作缩放到原始大小以评估结果。
3.4 实验结果及对比
将本文方法与现有的11种COD方法进行比较,包括BASNet[23]、EGNet[24]、CPD[16]、F3Net[18]、PraNet[25]、SINet[7]、PFNet[8]、C2FNet[26]、SINetV2[27]、LSR[12]、UGTR[28]。为了公平比较,我们直接使用作者在网络上开源的预测图,用相同的公式进行评估。如果缺少预测图,则使用作者提供的预训练完成的模型生成预测图。本文总结了在4个数据集上不同基线模型的定量结果。从表1可以看出,本文方法在不同的数据集上都优于其他模型。
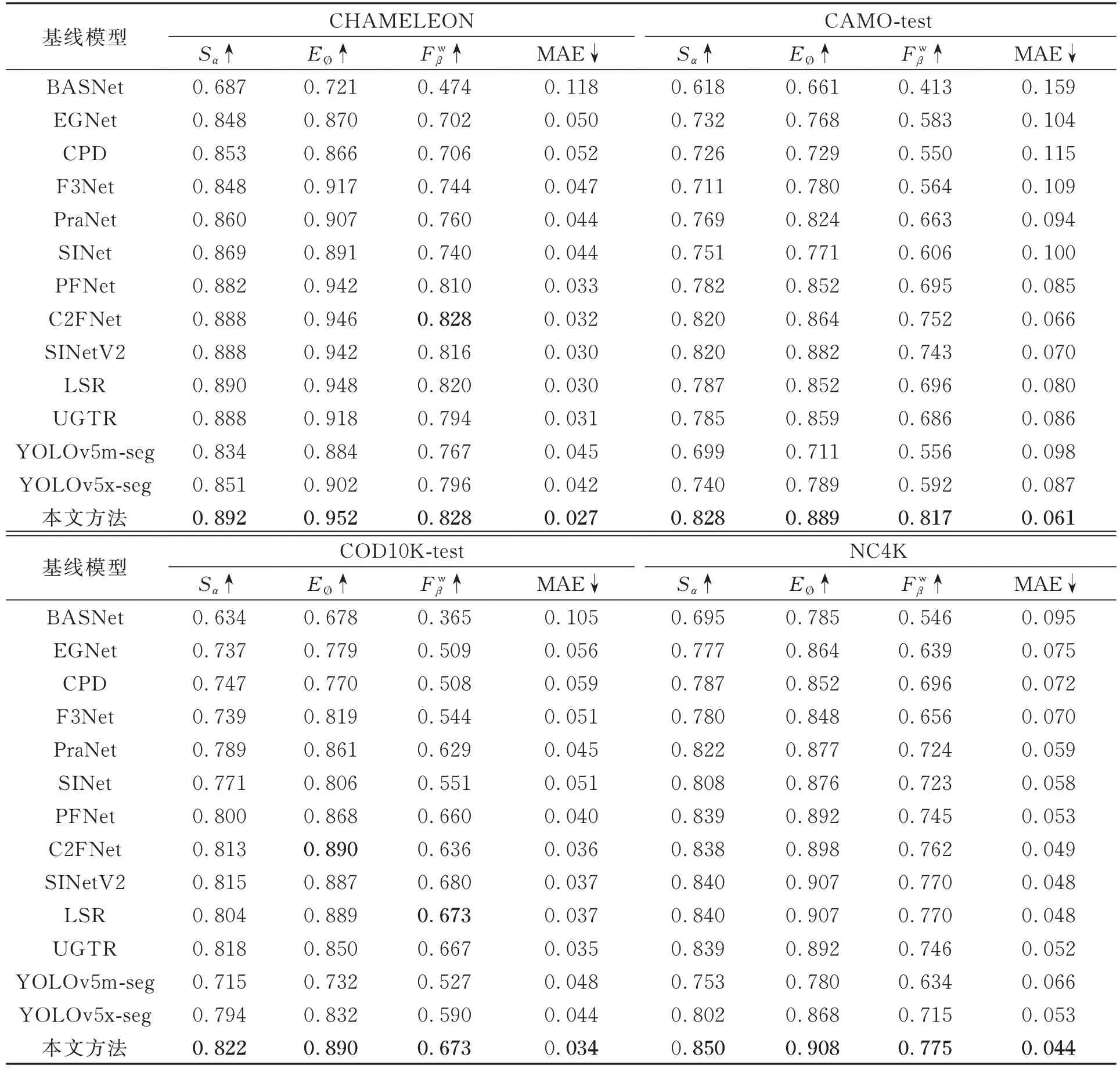
表1 不同模型在4个数据集(CHAMELEON,CAMO-test,COD10k-test,NC4K)上对4种评价指标的定量结果Tab.1 Quantitative results of different models for four evaluation metrics on four dataset(CHAMELEON,CAMO-test,COD10k-test,NC4K)
为了进行更广泛的对比,本文使用在目标检测领域的YOLOv5模型进行分割对比实验。在训练开始前,所有图片参照官方代码库(https://github.com/ultralytics/yolov5)的设置被重新调整为640×640大小,其他参数使用默认设置。实验选取与本文方法参数量相近的YOLOv5m-seg模型(22.67M)与性能最优的YOLOv5x-seg模型,结果见表1。本文方法在模型大小相近的情况下性能远远领先YOLOv5m-seg模型,与YOLOv5x-seg模型相比有着巨大的优势。
图5展示了本文方法与其他模型的视觉对比结果。可以看出,在不同的具有挑战性的场景下(第1~2行大尺寸伪装目标,第3~4行小伪装目标,第5~6行模糊边缘),本文方法都能产生优于其他模型的预测图。在目标被部分遮挡的情况下(第7行),该方法也能准确定位目标区域并产生精确的边缘细节。因此,本文方法相比于其他方法在伪装目标分割任务中具有更优秀的性能。另外,本文提供了本文方法与其他11种模型的P-R曲线和F曲线,如图6所示。

图5 本文方法与其他方法的视觉对比Fig.5 Vision comparison of our method with other methods

图6 10种不同方法在4个基准数据集上的P-R曲线和F曲线,本文方法为红色实线。P-R曲线越接近右上角,F曲线越接近坐标系上部,表示模型的性能越好。Fig.6 P-R curves and F-measure curves of 10 different methods on four benchmark datasets. Our method is shown with a solid red line. The closer the P-R curve is to the upper right corner and the higher the F-measure curve is, the better the performance of the model is.
本文方法与其他方法在模型复杂度、参数量和实时性上也进行了对比。所有算法在相同的硬件环境下(RTX2080Ti显卡)进行实验。其中浮点运算次数(Floating Point Operations,FLOPs)可用来衡量算法复杂度,为21.26G;模型参数量(Parameters,Params)为29.47M;FPS(Frame Per Second)为44.2。为了公平比较,所有模型均使用352×352的图片计算。如表2所示,本文方法在提升准确性的同时也保证了实时性能。

表2 不同模型的速度和模型复杂度分析Tab.2 Speed and model complexity analysis on multiple models
3.5 消融实验
为了验证每个模块的有效性,本文设计了一系列消融实验,对边缘提取模块、多级特征增强模块(MFEM)、跨层级特征聚合模块(CFM)、注意力模块等逐步解耦,以验证其有效性,实验结果见表3。为了验证损失函数及对应的超参数对网络性能的影响,本文对一系列不同的超参数设置进行了定量评价。
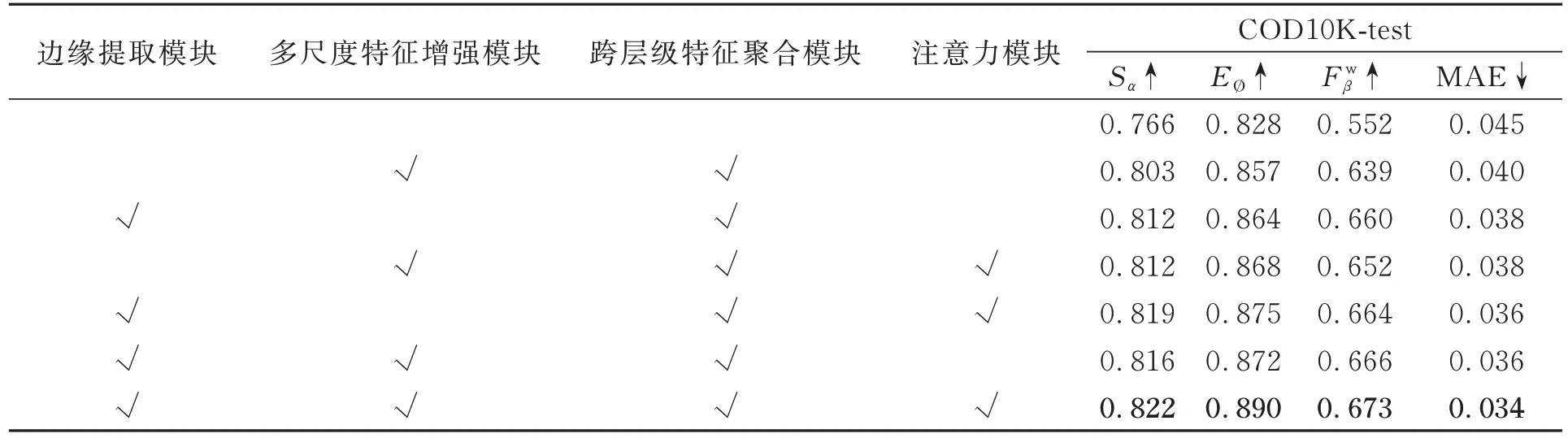
表3 不同模块的有效性分析Tab.3 Effectiveness analysis of different modules
基线模型选择一个类似U-net[29]结构的分割网络,编码器部分为ResNet-50网络,解码器逐级上采样并与较浅层特征结合,逐渐恢复到原尺寸。从表3可以看出,不同的模块对模型的性能提升都有贡献:在U-net架构基础上加入多尺度特征增强模块和跨层级特征聚合模块后,模型的4个评价指标、MAE分别提升了4.8%、3.5%、15.7%、11.1%,证明模型的层内和层间多尺度特征表达能力有了一定加强;在此基础上加入边缘提取模块,4个指标进一步提升了1.6%、1.8%、4.2%、10%,说明边缘先验信息在该分割任务中做出了重要的贡献;在加入注意力模块后分别提升了0.006、0.018、0.007,MAE指标则下降了0.002。
图7为逐步解耦各个子模块后的可视化效果对比。从图7(d)可以看出,在去除了边缘提取模块后,预测结果的边界存在大量的冗余,一些较复杂的边缘结构难以被清晰地分割,说明边缘提取模块对目标边界像素的提纯至关重要。多尺度的特征更有利于定位复杂场景下的伪装物体,在分别去掉多尺度特征增强模块(图7(e))和跨层级特征聚合模块(图7(f))后,模型不能准确地找到目标所在的位置,出现了目标区域模糊不清、目标结构被错判和伪装区域连通性的问题。从图7(c)和图7(g)可以看出,注意力模块对融合后的特征进一步去噪,使网络更关注于预测目标区域,对背景区域进行抑制,目标细节更明显,置信度较低的噪声干扰被去除。
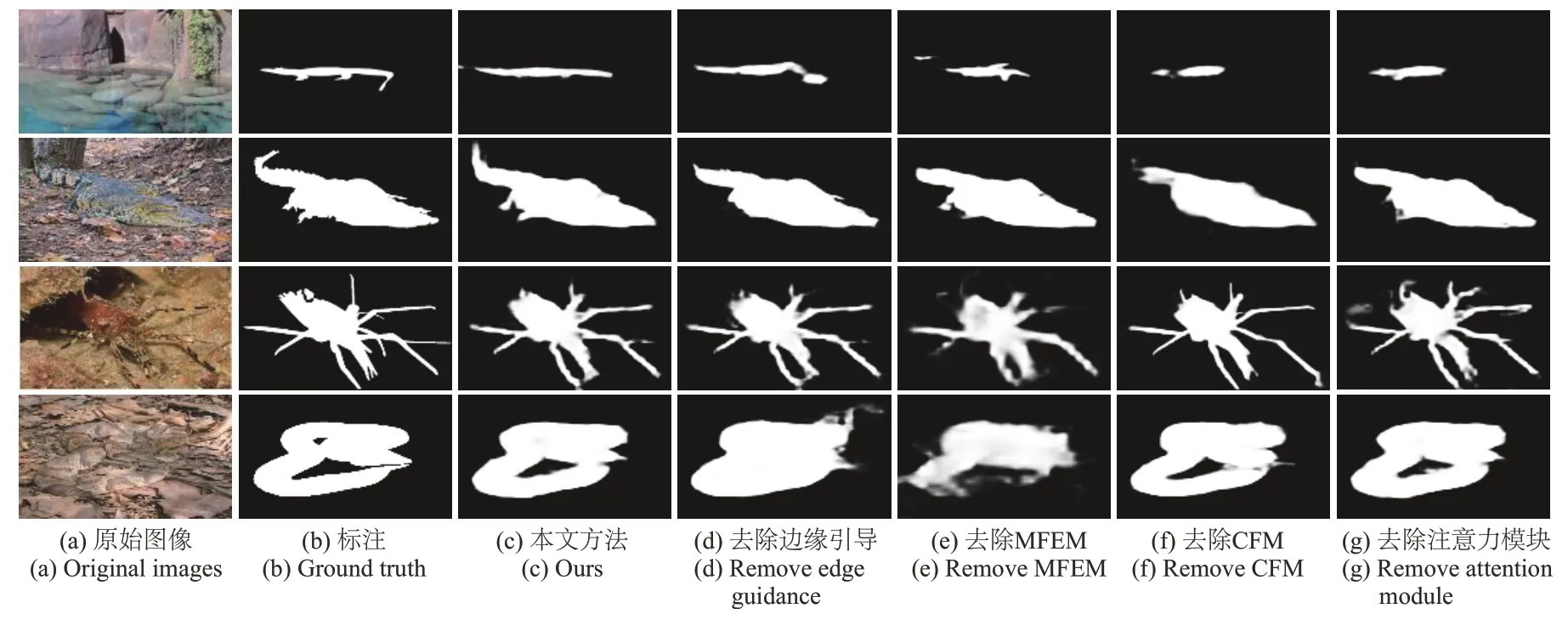
图7 去除不同模块的视觉比较Fig.7 Vision comparison of removed different modules
为了分析联合损失函数各参数对网络的影响,按照不同的比例设置两部分损失函数的超参数(其中λ1为边缘损失Ledge的比重,λ2为预测损失Lpred的比重),进行对比实验。根据表4,模型在给边缘损失较大权重时表现更好,在λ1=5、λ2=1时效果最好。这表明在网络不变的情况下,准确的边缘先验能够极大地提升网络的有效性。

表4 两种损失函数的比重对网络性能的影响Tab.4 Effect of the proportion of the two loss functions on network performance
4 结论
本文提出了一种基于边缘增强和特征融合的伪装目标分割网络。首先设计了一种边缘提取模块,有效利用低级特征,产生精确的边缘先验。其次,采用多尺度特征增强模块和跨层级特征融合模块,分别提取层内和层间的有效多尺度信息。之后,设计了一种简单有效的层间注意力模块,对充分融合的特征进行再次筛选,去除冗余的背景噪声干扰。最后,将各层预测与边缘先验结合,生成最后的预测图,并采用联合损失函数对不同尺度的预测图进行联合监督。本文方法在4个伪装目标基准数据集上进行实验,在4种不同的评价指标上都优于其他方法。在视觉对比中,本文方法分割出的预测图能够更好地识别复杂场景下的伪装物体,更好地保留了目标轮廓,细节信息更清晰。因此,本文方法对伪装目标分割有更好的效果。
猜你喜欢
数学小灵通·3-4年级(2021年5期)2021-07-16
内蒙古民族大学学报(社会科学版)(2020年2期)2020-11-06
今日农业(2019年15期)2019-01-03
通信产业报(2016年44期)2017-03-13
太空探索(2016年5期)2016-07-12
广西民族大学学报(自然科学版)(2015年3期)2015-12-07
读者·校园版(2015年19期)2015-05-14
时代英语·高三(2014年5期)2014-08-26
雕塑(2000年2期)2000-06-22
雕塑(1999年2期)1999-06-28
