
双鉴别器盲超分重建方法研究
2024-01-27 06:56于国梁
电子与信息学报 2024年1期
卢 迪 于国梁
(哈尔滨理工大学 哈尔滨 150080)
1 引言
图像超分辨率重建技术一般可分为两种,一种是利用多张低分辨率图像合成一张高分辨率图像,另一种是利用单张低分辨率图像重建高分辨率图像[1,2]。该技术是指使用软件或硬件方法,从具有较少细节的低分辨率图像中重建出具有大量细节对应的高分辨率图像,在老照片修复、视频监视、卫星图像遥感、医学图像等领域应用非常广泛。
图像超分辨率重建方法可分为传统方法和基于深度学习方法。传统方法包括基于重建[3]和基于插值[4]的方法。基于插值的方法计算快捷,但是插值得到的高分辨图像细节非常差,适用于对质量要求不高的场景;基于重建的方法主要包括迭代反投影法[5]和凸集投影法[6]等,该类算法操作运算简单、重建速度相对较快,但是受到可利用先验知识限制,图像重建之后大量细节丢失,效果并不理想。
2015年Dong等人[7]提出超分辨率卷积神经网络(Super Resolution Convolutional Neural Network,SRCNN),利用卷积神经网络对图像进行超分辨率重建,采用双3次线性插值的方法将图像缩放至预设尺寸,然后进行特征提取、非线性映射和重建3个步骤获得超分辨率图像,重建效果比传统方法更好,为基于深度学习的图像超分辨率重建任务奠定了基石。2016年Dong等人[8]又提出了加速超分辨率卷积神经网络(accelerating the Super-Resolution Convolutional Neural Network, FSRCNN),相比于SRCNN, FSRCNN将图像的上采样部分转移到网络末端,使得前面的特征提取均在低维空间上完成,并且在非线性映射之前进行降维操作,极大减少了网络参数量,达到实时性的目的。随着生成对抗网络(Generative Adversarial Networks, GAN)的出现,图像超分辨率重建方法进入了一个新的领域。Park等人[9]提出的特征识别单图像超分网络(single image Super-Resolution with Feature discrimination, SRFeat)是一种基于GAN的超分辨率方法,采用双鉴别网络对图像特征进行判别,其目的在于生成网络能够生成一些与图像结构相关的某些高频信息,而不是高频噪声。另外,生成网络使用远距离的跳跃结构,更加利于信息流通。Zhang等人[10]提出的残差通道注意力网络(Residual Channel Attention Networks, RCAN)具有更深的残差网络结构,通过短连接、长连接和全局连接使得网络更有效率,所提通道注意力机制能够对各通道特征进行自适应调节。Ledig等人[11]提出超分辨率生成对抗网络(Super-Resolution Generative Adversarial Network, SRGAN),采用更深层的残差结构作为生成网络的主体结构,采用感知损失代替均方误差(Mean Squared Error, MSE)损失,增强重建图像真实感,从视觉上看,获得更好的效果。Lim等人[12]基于SRGAN进行改进,提出增强深度残差单图像超分网络(Enhanced Deep residual networks for single Image Super-Resolution,EDSR),删除归一化层,并提出了一种增强版的残差结构,降低了内存使用量,增强了模型的性能。Wang等人[13]提出增强超分生成对抗网络(Enhanced Super-Resolution Generative Adversarial Networks, ESRGAN)是增强版的SRGAN,对SRGAN进行如下改进:(1)去掉归一化层;(2)提出更复杂的残差嵌套稠密块(Residual-in-Residual Dense Block, RRDB)结构作为基本模块;(3)利用相对鉴别器对真假图像进行识别;(4)删除末尾的激活函数来改进感知损失;(5)网络插值替代图像插值。2019年Soh等人[14]提出的自然流行单图像超分网络(Natural and realistic single image Super-Resolution with explicit natural manifold discrimination, NatSR)则在 ESRGAN 的基础上引入了自然流形鉴别器使得其重建图像与原图像的 PSNR得到了巨大的提升。但是NatSR的效果非常不稳定,造成图像超分辨率重建过程中出现图像崩溃现象,且部分重建的图像会具有重复的伪影。2021年腾讯发表了纯合成数据训练的真实世界盲超分算法(training Real-world blind ESRGAN, Real-ESRGAN)[15],该算法基于ESRGAN,给出了一种新型数据集构造方法。传统方法大多采用双3次降采样[16]和传统的退化模型[17],但是,现实世界的退化要复杂得多。为了产生更逼真的结果,Real-ESRGAN网络采用高阶退化模型,对降阶图像复杂度进行加强。同时,将sinc filter引入到数据集构建中,成功地解决了图像中存在的振铃和过冲等问题,并将ESRGAN中VGG鉴别器替换成U-Net鉴别器,逐像素反馈到生成器中,帮助生成器生成更加详细的图像特征。
目前生成对抗网络在超分辨率重建方面的工作主要集中在模拟一个更复杂和更真实的降阶过程或构建一个更好的生成器,例如Real-ESRGAN网络,但很少有工作试图改善鉴别器的性能。鉴别器的重要性不可忽视,它更像一个损失函数,为生成器生成更加真实的高分辨图像指明方向。基于此问题,本文对Real-ESRGAN网络鉴别器进行改进,采用UNet3+[18]结构构建了一种双鉴别器网络(Double Uet3+ Real-ESRGAN, DU3-Real-ESRGAN)。UNet3+结构拥有更少的参数,在提高计算效率的同时,可以从全尺度捕获更多的图像细节。一个鉴别器很难对全局和局部特征都给出精确的反馈,导致合成图像中出现不连贯、边界层次模糊等问题,因此引入双鉴别器结构,一个鉴别器以完整的合成图像作为输入来学习图像纹理细节;另一个鉴别器接受下采样合成图像作为输入,关注图像的边缘特征。
2 Real-ESRGAN算法
Real-ESRGAN采用与ESRGAN相同的生成器网络,如图1所示。

图1 Real-ESRGAN生成器网络结构
该网络主要分为3个部分,第1部分浅层特征提取网络,低分辨率图像(Low-Resolution, LR)经过一个卷积+LRELU模块,将输入通道数调整为64。第2部分RRDB网络结构采用两层残差结构,主干部分别由3个残差密集块(Residual Dense Block, RDB)构成。每个RDB都包含5个卷积+LRELU模块。RDB结构相当于残差块与密集块的结合,利用密集连接卷积层,提取出丰富局部特征。第3部分上采样网络,将高度和宽度分别扩大为原图的4倍,输出超分辨率图像(Super-Resolution, SR),实现分辨率的提升。通过学习训练集数据的特征,最后在鉴别器的指导下,将随机噪声分布尽可能拟合为高分辨率图像(High-Resolution, HR)的真实分布,从而生成具有训练集特征的相似数据。
鉴别器由ESRGAN中的VGG风格鉴别器改进为U-Net网络,如图2所示。ESRGAN的鉴别器更多地集中在图像的整体角度判别真伪,而使用U-Net鉴别器可以从像素角度,对单个生成的像素进行真假判断,在保证生成图像整体真实的情况下,更加注重生成图像细节。

图2 Real-ESRGAN鉴别器网络结构
3 DU3-Real-ESRGAN
3.1 网络结构
Real-ESRGAN网络的U-Net 鉴别器结构可以从像素角度对单个生成的像素进行真假判断,在保证生成图像整体真实的情况下,更注重生成图像细节。但U-Net结构主要是encoder-decoder结构。该结构的低层主要是获取细粒度的细节特征(捕获丰富的空间信息),高层主要是获取粗粒度的语义特征(提取位置信息),所以U-Net结构仅有同层之间的连接,使得该网络上下层连接时存在信息代沟现象。将U-Net结构用UNet3+网络替换,能够全尺度角度下捕捉细粒度与粗粒度语义,得到图像更加丰富的细节信息。
UNet3+主要参考了U-Net和UNet++[19]两个网络结构。UNet++是由U-Net结构更改而来的,如图3(a)所示,尽管UNet++采用了嵌套和密集跳跃连接的网络结构(红色三角区域),整合了不同层次的特征,提升了图像的精度,但是它没有直接从多尺度信息中提取足够多的信息。UNet3+主要解决从全尺度上获取信息问题,依旧采用encoder-decoder结构,如图3(b)所示。Encoder结构与 U-Net,UNet++相同,Decoder改进为层数小于等于当前层的特征图经过池化和卷积操作得到64通道特征图(层数相同的一层不做池化操作),层数大于当前层的特征图经过上采样(双线性插值)和卷积同样得到64通道特征图,将这些特征图concat起来,经过卷积、正则化和激活函数之后构成decoder的一层,decoder细节图如图4所示,更好地整合了低级细粒度信息和高级语义特征,且参数量比U-Net和UNet++有所减少。

图3 UNet++和UNet3+网络结构

图4 UNet3+网络decoder结构图
本文采用UNet3+网络,构建了一种双鉴别器结构,提出了DU3-Real-ESRGAN网络,如图5所示。鉴别器1以完整的合成图像作为输入,具有更大的感受野,负责掌握全局视图;鉴别器2接受2倍下采样合成图像作为输入来学习图像边缘细节。双鉴别器不仅可以关注图像纹理,还可以关注边缘等更详细的信息,边界层次更加分明。

图5 DU3-Real-ESRGAN网络结构
3.2 损失函数
DU3-Real-ESRGAN训练过程分为两个阶段。首先利用L1损失对模型进行预训练。接着,将得到的预训练模型作为生成器的初始化,结合L1损失、感知损失和对抗损失训练模型。
L1损失(均方误差):目标值与预测值之差绝对值的和,表示预测值的平均误差,如式(1)所示
其中,fi代表生成器生成图像的像素值,yi代表真实图像的像素值,n为测试样本的数量。
感知损失:生成器生成的SR图像与真实的HR图像输入VGG19网络分别提取特征,然后在提取的特征图上使用均方误差损失,如式(2)所示
其中,θ是网络参数,IHR是真实的HR图像,是重建出来的SR图像,W和H分别是图片宽和高,可以看成常数。φi,j指的是第i个maxpooling层前的第j个卷积的特征图。
对抗损失
其中,E(*)代表分布函数的期望值,Pdata(x)代表真实样本的分布,Pnoise(z)是定义在低维的噪声分布。
4 实验与结果分析
4.1 实验配置
使用DIV2K数据集进行训练,选用该数据集的1 000张HR图像,作为训练集的图片。退化模型参考Real-ESRGAN的退化模型,更好地模拟真实世界中的低分辨模糊情况,增强降阶图像的复杂度,同时引入sinc filter,解决了图像中的振铃和过冲现象。将1 000张HR图像输入到退化模型中得到1 000张LR图像,作为训练集的LR图像,结果如图6所示。

图6 DIV2K数据集HR图像与LR图像对比图
在以往的图像超分重建任务中,通常使用人工模拟的退化图像作为测试图像。但是,人工模拟的退化图像很难反映真实世界中的LR图像,现实中的LR图像通常是不同退化过程的复杂组合。因此,本文选择使用真实世界的图像,作为实验的测试集,分别为Set5, Set14, BSD100和Urban100。Set5有5张图像,Set14有15张图像,BSD300有30张图像,Urban有50张图像。Set5图像纹理比较单一,Set14大多是人脸及动植物图像,BSD100的图像类别比较丰富,纹理也比较复杂,Urban100主要是建筑类别图像,纹理同样复杂且图像较大。
实验环境为Intel(R) Core(TM) i7-10875H CPU和NVIDIA GeForce RTX 2 070,深度学习框架为PyTorch,调用并行计算架构和英伟达神经网络库对显卡进行加速,版本分别为10.1和7.6。网络输入图像为256×256大小的RGB图像,批量大小设置为64,训练最大迭代数设置为20 000,使用Adam优化器。
4.2 实验结果分析
选取SRGAN, EDSR, ESRGAN, Real-ESRGAN与本文提出的DU3-Real-ESRGAN进行比较,同时又构建了U3-Real-ESRGAN模型,只采用图5中的鉴别器1。图像质量客观评价方法PSNR和SSIM的结果如表1所示,其中加粗部分为对比算法中的最优结果。DU3-Real-ESRGAN模型的PSNR和SSIM值在Set5数据集上低于Real-ESRGAN,高于U3-Real-ESRGAN,而在其他测试数据集中都具有更好的表现,且单鉴别器的U3-Real-ESRGAN比Real-ESRGAN除Set5数据集外都有更好的PSNR和SSIM值。

表1 PSNR/SSIM值对比
具有高PSNR和SSIM的超分变率重建图像,它在纹理细节上并不一定与人眼视觉习惯相符,不能很好反映人的视觉感受,同时采用PSNR和SSIM图像质量评价指标需要Ground Truth作为参考图像,对于现实中实际场景的复原,很多时候并不存在Ground Truth,因此,本文除了采用PSNR和SSIM评价指标外,还采用了更为有效的图像重建质量指标NIQE[20]进行定量评估。NIQE表示图像的感知质量,其值越小表示感知质量越好。
NIQE评价指标结果如表2所示,其中加粗部分为对比算法中的最优结果。DU3-Real-ESRGAN模型的NIQE值在Set5数据集上相比Real-ESRGAN,U3-Real-ESRGAN增加了0.333 6, 0.237 9,而在其他测试数据集上相比Real-ESRGAN分明减少了0.024 5, 0.444 2, 0.529 7,单鉴别器的U3-Real-ESRGAN相比Real-ESRGAN除Set5数据集外NIQE结果都有显著的降低。Set5数据集与其他数据集不同之处是纹理结构简单,实验结果表明在处理纹理复杂图像时,本文提出的方法的效果优于其他算法。

表2 NIQE值对比
本文还对不同算法的主观视觉效果进行了对比测试,图像来自Set5, Set14, BSD100和Urban100测试集。对于Set5数据集,各算法对比结果如图7所示 ,SRGAN, EDSR与ESRGAN算法图像质量较为模糊,特别是图7(a)草丛、图7(b)文字的边缘处等具有较多细节的部分,而Real-ESRGAN, U3-Real-ESRGAN与DU3-Real-ESRGAN算法整体图像的清晰度有了较大的提升,图7(a)草丛、天空、马路色彩对比度更加鲜明,图7(b)文字显得更加立体,图像更符合人眼视觉感受。

图7 Set5数据集对比图
BSD100数据集图像类别较多,纹理也比较复杂,各算法对比如图8所示。SRGAN, EDSR与ESRGAN算法较为模糊,还产生了较多的伪影与噪声,图8(a)树枝细节基本辨认不出,图8(b)动漫图像含有大块斑点,图像质量非常低。Real-ESRGAN, U3-Real-ESRGAN与DU3-Real-ESRGAN在去除噪声与伪影等方面都有很高的表现。然而,图8中Real-ESRGAN重建图像纹理细节较少,图像显得不够逼真,U3-Real-ESRGAN和DU3-Real-ESRGAN生成图像具有更多的细节,信息更加丰富。U3-Real-ESRGAN算法虽然生成了更多细节,但边缘细节处模糊,边缘层次不分明,而DU3-Real-ESRGAN采用双鉴别器结构,在关注整体特征的同时,还关注局部边缘细节,强化了图像边缘,线条更加锐利,清晰度更高。

图8 BSD100数据集对比图
Set14数据集多为人脸和动植物图像,各算法对比如图9所示。
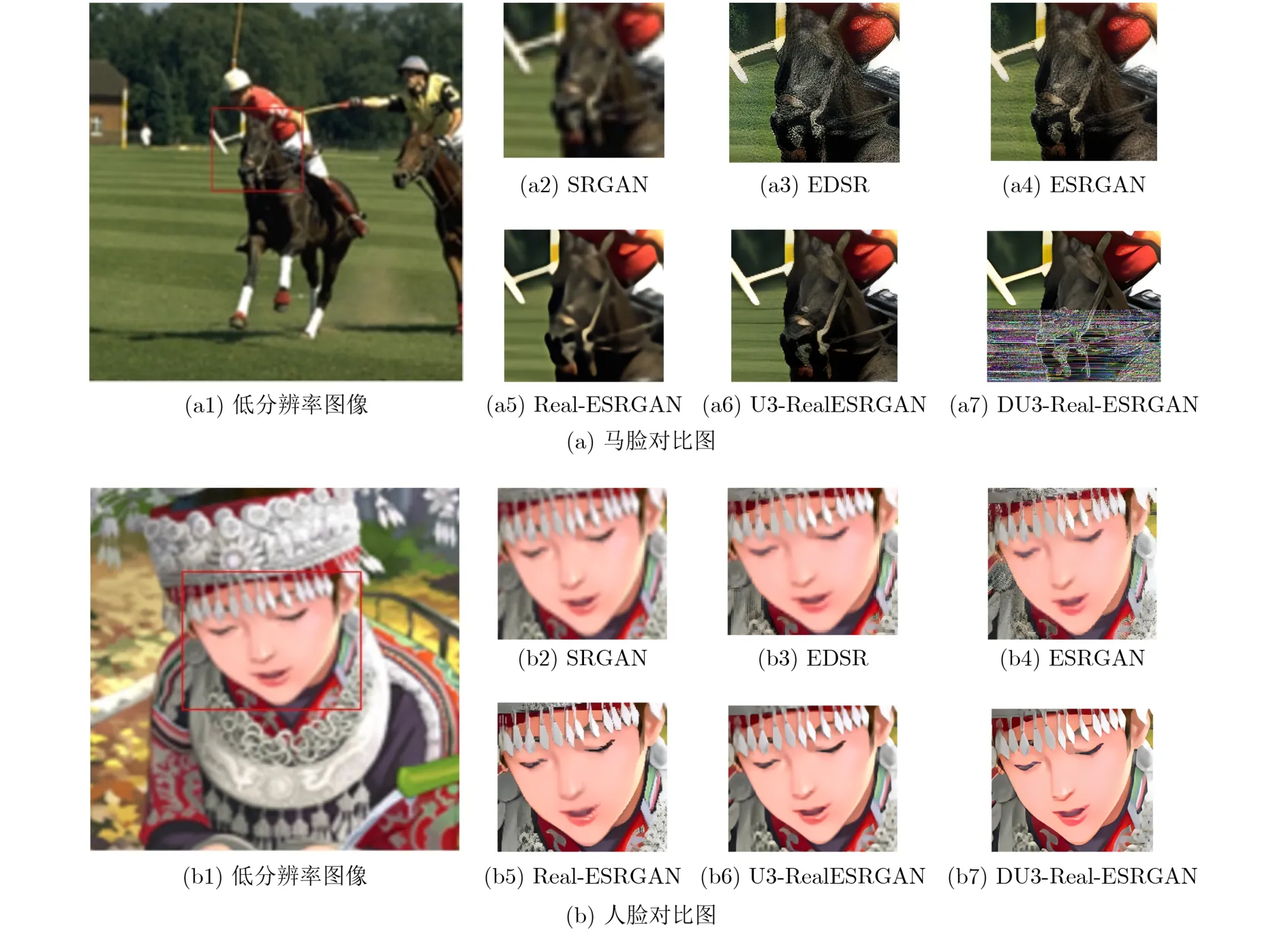
图9 Set14数据集不同算法对比
SRGAN处理这种图像依然表现不佳,图像质量依旧模糊。EDSR, ESRGAN图像清晰度虽然有了较大提升,但图像中依旧含有少量噪声,图9(a)中马脸仍有少量的斑点,图9(b)中人脸睫毛不够清晰。而U3-Real-ESRGAN与DU3-Real-ESRGAN处理的图像质量更高、边缘更加分明,图9(a)中毛发更加细腻,图9(b)中睫毛细节更加分明。
Urban100数据集主要是建筑类别图像,纹理复杂且图像较大,各算法对比如图10所示。DU3-Real-ESRGAN整体清晰程度明显高于其他算法,SRGAN, EDSR只能看出图10(a)中门框窗户与图10(b)中墙面条纹大致线条轮廓,模糊程度较高。

图10 Urban100数据集不同算法对比
ESRGAN与Real-ESRGAN虽然稍微清楚一些,但图10(a)中各窗户之间会有一些不真实的黑色伪影,图10(b)中生成的墙面条纹太假,与现实相差甚远。U3-Real-ESRGAN清晰度相比其他算法有了提高,图10(a)中边框边缘处线条不够锐化,边界层次不分明,图像整体呈现模糊现象,而DU3-Real-ESRGAN生成的边界更加分明,各部分轮廓对比度更高,生成图像感知更加真实。
5 结论
以Real-ESRGAN为基础,本文提出了DU3-Real-ESRGAN网络结构,在鉴别器网络中引入Unet3+网络,搭建双鉴别器架构,在全尺度上捕捉细粒度的细节和粗粒度的语义,去除了噪声与伪影,同时充实了图像的细节。对Set5, Set14,BSD300, Urban100等数据集上的图像进行测试,与Real-ESRGAN, SRGAN, EDSR和ESRGAN等超分网络对比,除Set5数据集外,DU3-Real-ESRGAN网络超分图像PSNR, SSIM和NIQE值均取得了较好的指标,生成图像的质量更好。Set5中图像主要为人脸和动植物图片,与其他数据集中图像主要不同之处是纹理较为简单,因此DU3-Real-ESRGAN网络处理纹理复杂图像的效果优于其他算法,在去除噪声与伪影的同时恢复更丰富的细节信息和分明的图像边缘,得到视觉效果更好的超分辨率重建图像。同时,还构建了单鉴别器U3-Real-ESRGAN网络,与单鉴别器Real-ESRGAN相比,UNet3+结构鉴别器生成图像具有更多纹理细节,信息更加丰富。与双鉴别器DU3-Real-ESRGAN对比可知,普通单鉴别器只关注图像整体细节的识别,相比之下双鉴别器结构对输入下采样图像进行识别,迫使鉴别器关注更多的图像边缘信息,区域轮廓更加分明,边缘线条更加锐化,清晰度更高。
猜你喜欢
通信学报(2022年10期)2023-01-09
软件(2020年3期)2020-04-20
国防科技大学学报(2019年4期)2019-07-29
数学物理学报(2019年3期)2019-07-23
摄影之友(影像视觉)(2018年12期)2019-01-28
家庭影院技术(2018年9期)2018-11-02
Coco薇(2017年8期)2017-08-03
自动化学报(2017年5期)2017-05-14
成都信息工程大学学报(2017年6期)2017-03-16
系统工程与电子技术(2016年5期)2016-11-02
