
语后聋双侧人工耳蜗使用者对噪声言语识别阈及音乐感知能力的研究△
2024-01-27 07:07高娜闵世尧张炜徇迟放鲁
中国眼耳鼻喉科杂志 2024年1期
高娜 闵世尧 张炜徇 迟放鲁
(复旦大学附属眼耳鼻喉科医院耳鼻喉科 上海 200031)
人工耳蜗植入是极重度耳聋患者重获听力的唯一途径,通过人工耳蜗植入,极重度耳聋患者可获得安静环境下55%的言语识别能力[1]。既往极重度耳聋患者采用单侧耳蜗植入,随着1996 年德国为成人植入双侧人工耳蜗[2],越来越多的患者重获了双耳听觉,双侧人工耳蜗植入也逐渐在临床应用推广。虽然人工耳蜗在安静环境下有非常满意的表现,但在噪声环境中却难以将言语的目标信号从噪声中分离出来。随着越来越多的双侧耳蜗植入,使用者建立了双耳听觉,提高了声源定位能力及一定信噪比下的言语识别率[3-4];然而,双耳蜗使用者仍普遍存在噪声下言语识别困难的问题[5]。如何评估人工耳蜗使用者在实际生活中噪声下的言语识别能力,目前尚未达成共识。目前国内对噪声的研究多集中在固定信噪比下的言语识别率,对于非稳态噪声下人工耳蜗的效果研究相对较少。本研究比较研究正常听力者、单侧耳聋者、语后聋双侧CI 使用者的音乐欣赏能力及在噪声环境下的言语识别能力。
1 资料与方法
1.1 研究对象与分组
收集2017 年1 月—2021 年2 月收治的不同听觉条件的受试者,分为3 组。
双侧耳蜗使用组:8 例语后聋双侧人工耳蜗使用者(bilateral cochlear implant,BCI),其中男性5 例、女性3 例;年龄9 ~55 岁,平均30.6 岁,均为双侧极重度感音神经性语后聋。双侧均植入澳大利亚Cochlear 公司CI24RE 型人工耳蜗,双侧人工耳蜗使用时间为6 ~35 个月。详见表1。
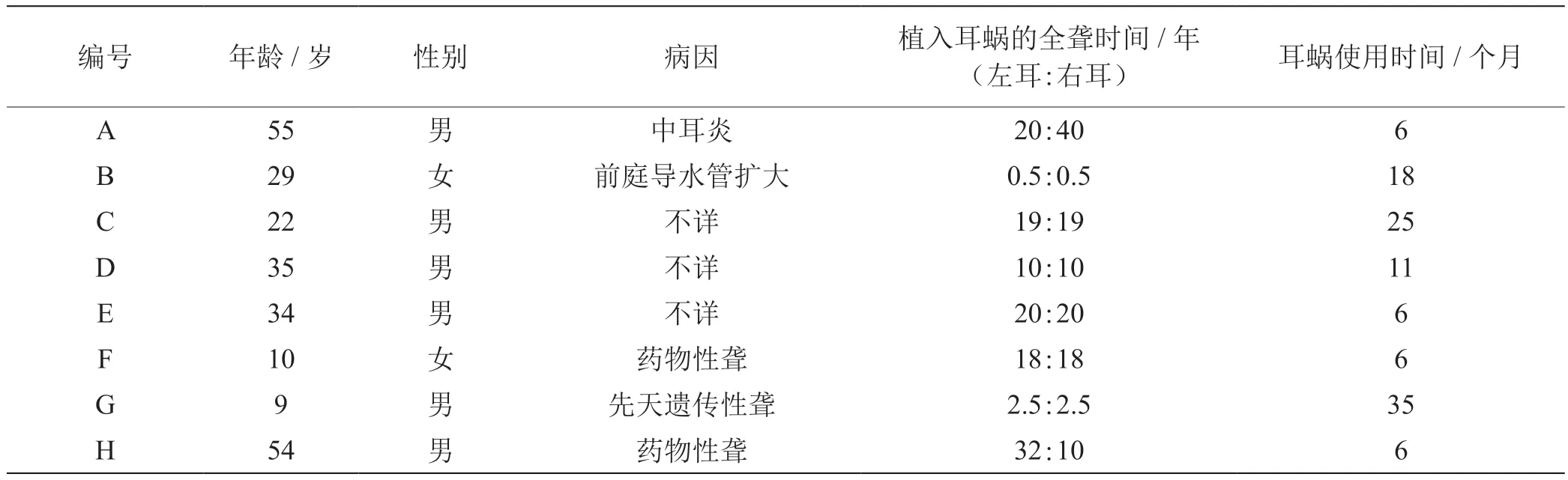
表1 BCI 的基本资料
正常听力组:26 例,双耳平均听阈<20 dB,其中男性15 例、女性21 例;年龄22 ~34 岁,中位年龄28 岁。
单侧耳聋组:40 例,均为极重度耳聋,耳聋侧的平均听阈>80 dB,单侧正常耳的平均听阈<20 dB,其中男性23 例、女性17 例;年龄6 ~62 岁,中位年龄为17 岁。
1.2 测试方法
测试在复旦大学附属眼耳鼻喉科医院隔音室(长4.5 m × 宽3.5 m × 高2.5 m)进行,本底噪声<30 dB SPL。校准声场后,受试者以舒服的姿势坐于椅子上,在患者正前方置音箱,扬声器与受试者头部水平高度一致,测试材料通过扬声器给声,声压级控制在65 dB SPL。测试材料选用开放式普通话言语识别(Mandarin speech perception,MSP)。MSP 的短句测试包含10 组,每组10 个句子,每个句子7 个单音节词,系统根据患者对句子的识别率,改变噪声信号,调整信噪比,获得MSP 中文短句稳态噪声下基于反转的言语识别阈(speech recognition threshold,SRT)[6]。
音乐感知能力测试:选用闭合式的单音符测试和旋律轮廓识别测试[7]。在单音符测试中,受试者辨认钢琴声的音调(黑键白键均包含),给予3 个65 dB SPL 音符声音信号,其中2 个音符相同,1 个音符不同,受试者需辨认出其中不同的音符,通过多次测试得到单音符的识别率。旋律轮廓识别测试(melodic contour identification,MCI)用以了解患者对音乐旋律的感知能力。测试材料包括5 个音乐音符组成的9 种旋律,每个受试者共进行2 轮测试,最终测试结果取2 次测试得分的平均值。患者在9种音符旋律轮廓中选择所听到的旋律。
测试人员位于隔音室,通过监控对讲进行交流,测试前先对患者进行培训,待受试者完全理解和熟悉后开始正式测试。同时,BCI 受试者分别在人工耳蜗双耳佩戴、右耳佩戴、左耳佩戴下,进行噪声和音乐的识别测试。测试完成情况详见表2。

表2 测试完成情况
1.3 统计学处理
研究使用SPSS 21.0 软件进行数据统计分析,BCI 组、正常听力组、单侧耳聋组的SRT 为非正态分布数据,采用Kruskal-Wallist检验。以P<0.05 为差异具有统计学意义。
2 结果
2.1 噪声下言语识别阈
听力正常组和单侧耳聋组噪声下SRT 分别为-7.22(-7.74~-6.7775)dB、-5.42(-6~-4.4) dB。BCI组双耳、右耳和左耳佩戴时SRT 分别为3(1.245~11.63) dB、8.4(2.55~13.14) dB、5.04(0.75~15.82) dB。
如图1 所示,Kruskal-Wallist检验显示,正常听力组噪声下的SRT 值显著优于单侧耳聋组(P=0.001),单侧耳聋组显著优于双侧耳蜗组(P=0.002),差异具有统计学意义。双耳蜗佩戴时噪声下SRT 虽然平均值低于单耳佩戴,但差异无统计学意义。
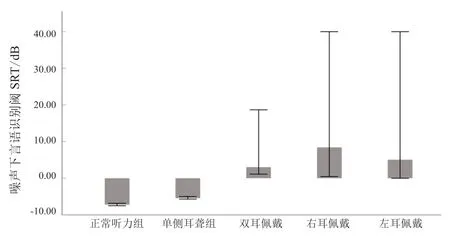
图1 不同听觉条件受试者噪声下的SRT 比较
图2 为噪声状态下8 例BCI 在双耳佩戴、右耳单耳佩戴、左耳单耳佩戴时的噪声下SRT。其中E、F、G、H 受试者在双耳佩戴时SRT 低于单耳佩戴时,其余受试者在双耳佩戴时SRT 高于单耳佩戴时,个体差异大。非参数配对检验显示,双耳佩戴与单耳佩戴时差异无统计学意义(右侧vs双侧:P=0.208;左侧vs双侧:P=0.484;右侧vs左侧:P=0.575)。
2.2 音乐音符识别
图3 显示,正常听力组、单侧耳聋组和6 例双侧耳蜗组的音乐音符识别率分别为100%(96%~100%),92% (76%~96%),82% (80%~87%)。正常听力组显著优于单侧耳聋组(P=0.001)和双侧耳蜗组(P<0.001),单侧耳聋组与双侧耳蜗组差异无统计学意义(P=0.834)。

图3 不同听觉条件下受试者音乐音符识别
图4 显示 6 例BCI 完成了音乐音符测试,其中3 例在双耳佩戴时的音乐音符识别优于单耳佩戴。
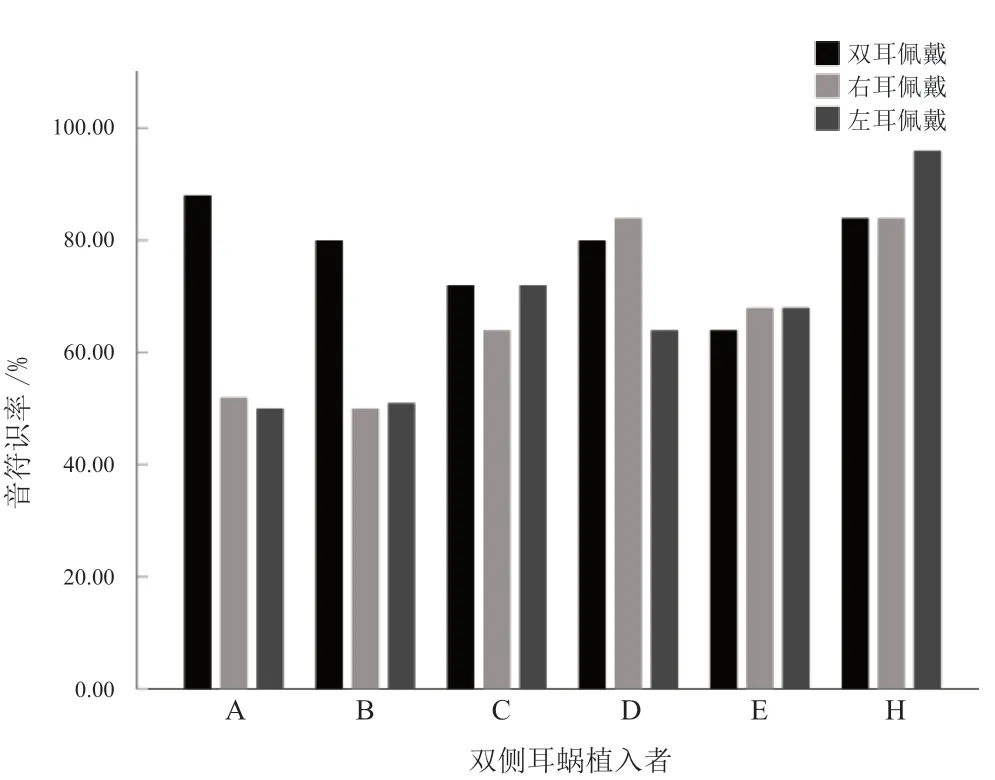
图4 BCI 的音乐音符识别
2.3 音乐旋律轮廓识别
图5 显示,4 例BCI 完成音乐轮廓的测试。这4例BCI 既往均有音乐欣赏经验,其中3 例在双耳佩戴时的音乐轮廓识别优于单耳佩戴。
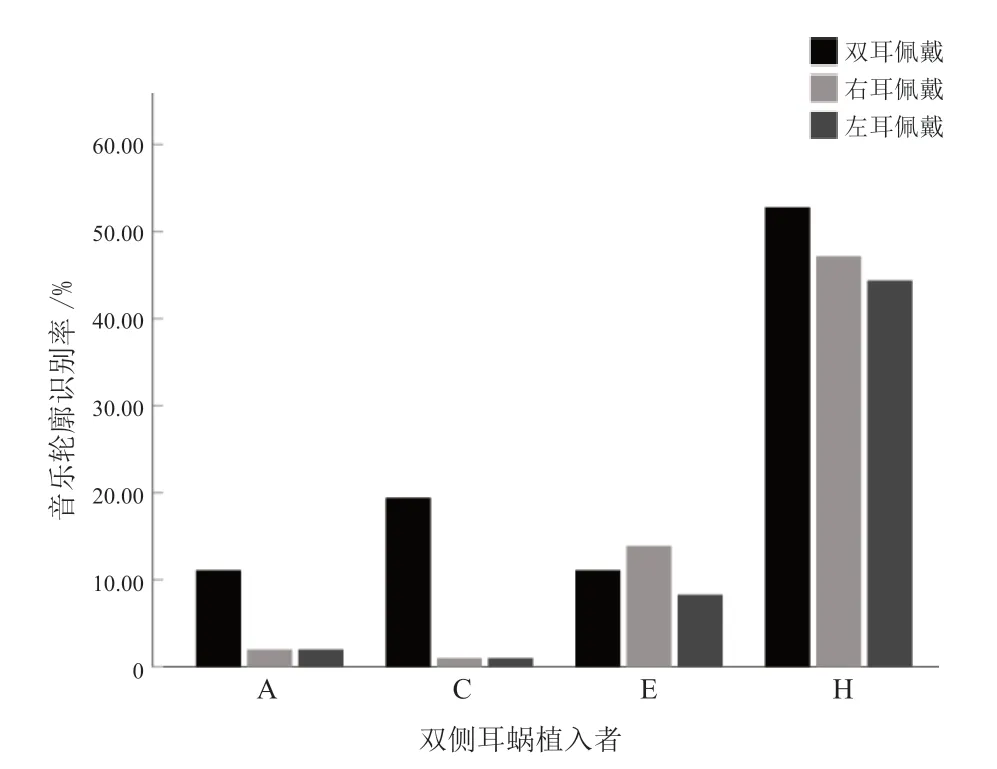
图5 BCI 的音乐轮廓识别
3 讨论
近年来,国内外研究[8-10]表明双侧人工耳蜗植入不仅能提高声源定位能力,同时也能提高噪声下的言语识别能力。随着耳蜗植入者对生活质量的要求不断提高,噪声下的言语识别能力及音乐欣赏能力逐渐受到重视。背景噪声形式包括稳态噪声和非稳态噪声,非稳态噪声包含多人言语及音乐背景噪声。
3.1 噪声下的言语识别能力比较
针对普通话,国内研究显示双侧人工耳蜗植入能提高在安静和噪声条件下的双音节识别率、广东话声调识别,噪声环境下的单音节词、双音节词及短句的识别率等,但大多集中在固定信噪比的稳态噪声[3,11-12],比如在信噪比(+8dB)噪声环境下,双侧耳蜗植入者的SRT 明显优于单侧植入者,信噪比越高,言语识别率得分越高[13-14]。
为了模拟生活中常见的非稳态噪声环境,本研究采用MSP 材料测试,通过SRT 以更好地体现噪声变化时日常生活中的实用听力情况。结果显示,噪声下BCI 的噪声识别能力弱于单侧耳聋者和正常听力者。虽然噪声环境下人工耳蜗双耳佩戴时SRT均值低于单耳佩戴,但本研究样本量较少,人工耳蜗存在较大个体差异,差异无统计学意义。
Wolfe等[15]开发了滤波程序以降低环境噪声对人工耳蜗使用者的影响,这种主动降噪方式对使用者的言语分辨率有一定益处,但并没有解决全部问题。提示除了噪声对信号的干扰以外,还存在其他机制导致SRT 的降低。
对人工耳蜗植入者语音识别能力的荟萃研究表明,工作记忆、视觉记忆的能力与训练后的语音识别能力呈正相关,而年龄与这两者均有一定关联[16]。本研究所涉及的样本年龄分布方差较大,是评估言语识别的潜在混杂因素,大型多中心的样本可能对减少该偏倚有帮助。
3.2 音乐识别能力比较
音乐的辨识主要集中在音调、节奏、音色及旋律者4 个要素。研究发现,虽然患者进行了双侧人工耳蜗植入,但是部分患者仍无法辨别音乐音符和旋律,8 例BCI 患者中只有6 例能配合完成音乐音符测试,4 例完成音乐旋律测试,且4 例患者在耳聋前均有一定的音乐欣赏基础,提示语后聋BCI 的音乐感知能力仍比较差[17-18],这与既往研究[17]相似,只有大约1/3 的植入者能辨识出封闭环境中的音乐旋律。
本研究中语后聋BCI 的MCI 平均值为23.61%,范围11.1%~52.80%,与既往研究中儿童单侧耳蜗植入者的MCI 测试比较,MCI 平均值为33.3%,范围9.3%~98.1%[19],虽然个体差异很大,但双侧耳蜗佩戴并未提高音乐的欣赏能力。既往对语前聋及语后聋的BCI 使用差异研究,语前聋的语言训练结果显著优于语后聋者。Walia等[20]认为这可能是对电刺激和声刺激的编码在皮质中的差异导致,语后聋者习得BCI 声信号的过程也与电刺激诱导的突触重塑相关,这种重塑在幼年时期较高效,而在成年后相对缓慢。基于以上原因,本研究有限地研究了相对稳定的语后聋BCI 的识别能力,对于语前聋及相关的突触重塑和编码,仍然需要进一步的探索。
本研究中仅有音乐基础的BCI 可完成相关的音乐测试,可见音乐基础更有助于人工耳蜗植入后的音乐欣赏,这也与既往研究相似,对音乐的熟悉程度在一定程度上会影响试验结果[21],音乐训练可提高音乐感知能力[22],这也为耳蜗使用者提高音乐欣赏提供参考。
由于人工耳蜗电极数量的限制,以及电流在外淋巴液中的弥散,电刺激产生的声音信息频谱分辨率是较低的。因此复杂的音乐环境,BCI 可能无法准确提取信息。Thompson等[23]的研究指出,音乐鉴赏能力除了对声学信息的识别外,还与个人的心理社会因素有关。其他对于语前聋患者与语后聋患者音乐鉴赏能力的研究也提示生命早期的训练可能对高级中枢整合信号的能力有益处[24],具备音乐基础者在植入后会具备更好的鉴赏能力。这也与我们的研究结果相符。
综上所述,语后聋BCI 双耳佩戴耳蜗与单耳佩戴时的噪声下言语识别能力相似,均弱于单侧耳聋者及正常听力者。语后聋BCI 对音乐感知能力与既往音乐基础有关,BCI 双耳佩戴时音乐感知能力优于单耳佩戴时,与单侧耳聋组相似,远低于正常听觉人群。
猜你喜欢
家庭科学·新健康(2023年9期)2023-10-01
家庭科学·新健康(2022年1期)2022-02-02
中国听力语言康复科学杂志(2021年6期)2021-12-21
紫禁城(2020年5期)2021-01-07
减速顶与调速技术(2020年2期)2020-11-16
家庭科学·新健康(2016年11期)2016-11-23
海南医学(2016年8期)2016-06-08
中国卫生标准管理(2015年6期)2016-01-14
中外医疗(2015年16期)2016-01-04
听力学及言语疾病杂志(2015年5期)2015-12-24
