
基于神经网络词嵌入的大数据关注热点和词嵌入概貌比较研究
2024-01-27 13:40:27周爱霞严亚兰查先进
现代情报 2024年1期
周爱霞 严亚兰 查先进








关键词: 大数据; 比较研究; 学术平台; 社会化问答平台; Word2vec
DOI:10.3969 / j.issn.1008-0821.2024.01.004
〔中图分类号〕G203 〔文献标识码〕A 〔文章编号〕1008-0821 (2024) 01-0037-11
习近平总书记在中共中央政治局就实施国家大数据战略进行第二次集体学习时指出: “大数据是信息化发展的新阶段”[1] 。数据快速成倍增长, 从数据到大数据, 不仅是量的积累, 更是质的飞跃[2] 。大数据是数字化转型和数字经济的重要基石[3] 。自大数据(Big Data)作为一个概念被提出以来, 它就受到工业界、学术界、政府等的广泛关注, 大数据已对社会和经济发展产生了重大影响, 并将持续产生更大的影响。
我国学者对大数据开展了广泛的研究并产出了大量的成果。同时, 知乎已成为优秀的社会化问答平台, 大数据在知乎平台上通过问题和回答的方式受到了广泛关注。例如, 在问题“如何准确又通俗易懂地解释大数据及其应用价值?” 下, 答主们围绕大数据的定义、应用场景以及价值等方面, 系统而全面地回答了该问题。又如, 在问题“大数据最核心的价值是什么?” 下, 有一条高赞回答认为, 大数据的核心价值是了解和挖掘用户的行为习惯和爱好。再如, 在问题“普及一下什么是大数据技术?”下, 有一位答主的回答得到了大家的广泛认同, 该答主认为大数据技术是一套完整的“数据+业务+需求” 的解决方案。
Word2vec 是新兴的神经网络词嵌入算法, 也是最近几年人工智能领域自然语言处理技术得以快速发展的根基, 它不仅计算成本低, 而且准确度高,能够同时在语法和语义层面对词语的相似度进行有效的测度。结合不同平台的语料库训练Word2vec模型, 可以结合语义相似词对不同平台的关注热点进行比较, 可以利用降维技术和数据可视化方法对词嵌入概貌进行比较。本研究利用Word2vec 神经网络词嵌入算法, 结合我国学术平台和社会化问答平台对大数据关注热点和词嵌入概貌进行比较分析, 为大数据研究提供新的视角。
1 大数据相关研究和本研究的切入点
大数据一直是学术界的研究热点。随着云计算、移动互联网、物联网等下一代信息技术的快速融合和发展, 数据呈现指数级增长[4] 。在我国, 大数据研究受到越来越多的关注。黄家良等[5] 探讨了如何应用大数据促进虚拟社区的知识共享行为。他们构建了基于大数据的虚拟社区知识共享体系架构, 研究结果表明, 该架构具有较高的可行性和价值意义,可以挖掘虚拟社区的大数据价值从而提高平台的知识共享水平。甄艺凯[6] 针对互联网经济中存在的价格歧视问题, 在转移成本视角下, 通过构建一个三阶段动态博弈, 探究了企业在寡头竞争市场中的大数据“杀熟” 动机, 研究结果表明, 当转移成本较大时, 至少存在一家企业有“杀熟” 动机; 相反, “杀熟” 策略并不会出现在子博弈精炼纳什均衡路径上。张彬等[7] 基于大数据环境, 构建了兴趣知识图谱, 探讨了用户兴趣之间的关系, 研究结果表明, 该模型有效融合扩展了不同类型的兴趣关联知识, 且与单一来源数据相比, 该模型在用户兴趣的查准率和覆盖率上都有所提升, 用户兴趣描绘的准确性和全面性也得到了优化。王旸等[8] 从社会化媒体平台视角出发, 构建了系统化的社会化媒体大数据资源模型, 建立了用户在线活动的“主体—操作—对象” 过程框架, 探讨了社会化媒体平台建立大数据资源观的重要性, 研究结果表明, 相较于现有研究, 该研究提出的模型在完整性、准确性、易理解性、可扩展性等方面都得到了提升。任曙明等[9] 通过构建理论模型, 探讨了大数据应用如何影响企业的创新资源错配, 研究结果表明, 大数据应用主要是通过技术壁垒效应以及知识流动效应影响企业创新资源错配。
可以看出, 我国学者已经针对大数据开展了广泛的研究。为了推动我国大数据研究取得更多的成果, 推动学术界更多结合我国大数据实践和社会需求而展开研究, 有必要回答以下问题: 我国学术平台和社会化问答平台在大数据关注热点上存在什么差异? 我国学术平台和社会化问答平台在大数据词嵌入概貌上存在什么差异? 如何有效地展现和比较关注热点上的差异和词嵌入概貌上的差异? 这些问题构成了本研究的切入点。从研究范式上看, 本研究属于数据驱动的研究, 对于数据驱动的研究, 当数据量足够大时, 数据分析结果不仅仅展现的是现象, 而是具有一定的稳健性和科学价值。本研究遵循数据驱动的研究范式, 通过知乎平台搜集了大数据主题下主流问题的回答, 回答内容包含92 万多字; 通过中国知网平台搜集了12 770篇文献, 这些文献代表了北大核心期刊中大数据研究重要文献的全集; 然后创新地利用Word2vec 神經网络词嵌入方法, 结合我国学术平台和社会化问答平台对大数据关注热点和词嵌入概貌进行了比较分析。
2 研究方法: 神经网络词嵌入
在自然语言处理领域, 词嵌入是一项非常重要的技术。词嵌入表示中最简单和最知名的是独热编码(One-hot Encoding)。独热编码的维度由词库的大小决定, 独热编码在表示词语的时候存在明显的维度灾难, 有多少词语就需要有多少维, 因此对于庞大的语料库来说, 计算量和存储量都是很大的问题[10] 。
Word2vec 模型是由Google 团队于2013 年发明的基于神经网络的词嵌入方法, 在训练向量空间模型的速度上大大优于以往的方法[11] 。Word2vec 有一个很重要的假设: 文本中离得越近的词语相似度越高。基于这个假设, Word2vec 用连续词袋模型(Continuous Bag of Words, CBOW)架构和Skip-gram架构来计算词向量矩阵。CBOW 是用上下文词来预测中心词, 而Skip-gram 是用中心词来预测上下文, 它们有着准确度高、计算成本低的特点, 能够在语义层面和语法层面有效测度词语的相似度[11] 。Python 中的Gensim 库提供了API 接口, 可以使用Word2vec 的这两种框架[12] 。
Word2vec 已被广泛应用于科研和工作中, 可以用来做情感分析[13-14] 、中文分词[15] 、句法依存分析[16-17] 等。谷莹等[18] 利用Word2vec 技术构建了产品特征词集合, 构建了基于在线产品评论的企业竞争情报框架。该研究以汽车行业的评价为数据集进行实验, 研究结果表明, 该方法能够有效识别产品的情报信息, 为企业制定竞争策略和优化产品设计提供依据, 为大数据环境下的企业竞争情报挖掘提供方法。Yilmaz S 等[19] 使用Word2vec 方法构建了词嵌入, 在由用户问题组成的大型语料库上构建了具有不同向量大小的CBOW 和Skip-gram 模型,测试了使用不同的Word2vec 预训练词嵌入的效果。研究结果表明, 不同Word2vec 模型的使用对不同深度学习模型的准确率有显著影响。Ma J 等[20] 通过整合LDA 和Word2vec 生成了从全局视角到局部视角的语料库主题演化图, 发现并揭示了主题的多层次演变, 揭示了主题与主题出现、发展、成熟和衰落的整个生命周期之间的相关关系。
3 数据搜集
3.1 知乎平台数据搜集
知乎已经成为一个高质量的问答社区。在知乎平台上, 提问者的信息是匿名的, 以鼓励高质量问题的提出, 当提问者发布一个问题后, 基于平台的邀请机制, 会优先邀请同样感兴趣该话题的用户来回答问题, 做到有问必有答[21] 。结合知乎平台和大数据主题, 本研究在知乎平台上选取了15 个代表性主流问题。表1 是问题和问题描述。
利用Python 程序爬取了表1 中15 个问题下的回答, 这些回答代表了知乎平台中大数据主题下主流问题的回答, 反映了实践界的声音, 这些回答内容包含92 万多字, 用于后续的文本挖掘。
3.2 中国知网平台数据搜集
中国知网是目前中国最大的学术论文数据库,是中国知识基础设施工程(China Knowledge Infra⁃structure, CNKI)的组成部分, 为各行业的理论创新和知识生产提供了工具[22] 。在中国知网平台首页上, 先点击学术期刊, 再点击高级检索, 期刊来源选择“北大核心”, 检索字段是“篇名”, 输入“大数据” 进行精确检索。自2012 年以来,“大数据” 一词越来越多地被人们提及, 所以时间范围设置为2012 年至今, 由于中国知网每次最高只可检索出6 000篇文献, 但是通过分别限定时间段为“2012—2017 年” “2018—2021 年” “2022—2023 年”即可扩展显示数量, 分别得到5 662篇、5 920篇、1 188篇, 共计12 770篇中文文献。利用中国知网的自定义导出文献功能, 将检索结果以xls 格式导出,每次导出文献上限为500 篇, 通过多次文献导出,总共导出文献12 770篇, 这些学术文献代表了中国知网平台北大核心期刊中大数据研究的重要中文文献的全集, 所有文献的摘要用于后续的文本挖掘。
4 学术平台和社会化问答平台大数据比较分析
中国知网平台中以大数据为主题的北大核心期刊的中文文献代表了我国学术界的声音, 知乎平台中大数据主题下主流问题的回答代表了社会化问答平台的声音。本文利用Python 程序对数据进行预处理, 并借助神经网络词嵌入方法分别对预处理后的两个语料库进行Word2vec 模型训练, 再结合训练好的Word2vec 模型, 利用最相似词语分析对我国学术平台和社会化问答平台的大数据关注热点进行比较, 利用降维技术和数据可视化方法对所有词语的词嵌入概貌进行比较。
4.1 数据清洗和数据分析过程
利用Python 程序进行数据清洗。数据清洗的具体过程如下: 第一, 对于中国知网平台导出的xls 格式数据, 对分次导出的12 770篇学术文献进行合并以及摘要的读取, 得到有效摘要12 765个, 对于在知乎平台15 个问题下分別爬取的回答进行数据合并; 第二, 通过正则表达式的编写, 清洗摘要和知乎回答中的非词语符号; 第三, 借助Python 的Jieba库, 对摘要和知乎回答进行分词处理, 在分词时,根据本研究的研究主题, 在Jieba 的自定义词组中添加了“大数据” “大数据时代” 等词语; 第四, 将哈工大停用词表、四川大学机器智能实验室停用词表以及百度停用词表进行整合得到新的中文词表,结合新的中文词表, 对摘要和知乎回答进行清洗,在此过程中, 反复结合清洗效果, 在停用词表中增加了更多对文本特征没有任何贡献的字词, 将最终形成的停用词表用于清洗摘要和知乎回答。
利用Python 程序进行数据分析。数据分析的具体过程如下: 第一, 通过调用Gensim 库下的Models 模块中的Word2vec 类, 对清洗后的中国知网摘要所形成的语料库进行训练; 第二, 通过调用Gensim 库下的Models 模块中的Word2vec 类, 对清洗后的知乎回答所形成的语料库进行训练。
为了使两个语料库下的训练结果具有可比性,在训练模型的程序设计时, 使Word2Vec()的超参设置保持一致, 例如, sg = 0, 表明算法选择为CBOW 模型, min_count= 2, 这使得频率低于2 的词语在模型训练时会被忽略; vector_size= 100, 这表明每个词语的输出词向量为100 维; window= 5,即窗口大小为5, 这使得当前词与预测词之间的最大距离为5; workers = 1, 这表明训练模型在单一线程下进行。
4.2 大数据关注热点比较分析结果和讨论
通过Word2vec 模型训练而学习得到的词语向量是稠密的向量, 词语之间的相似性是利用余弦相似度进行测量, 相似性能够反映词语在语义上的差异。在学习出来的词语向量空间中, 与某个词语聚集在一起的词语在语义上相似性大, 例如, 与“大数据” 最相似的词语反映了语义上与“大数据”最相似的词语, 也就是说, 每当提到大数据时, 更可能也提到这些词语, 从而使得这些词语具有代表性并成为大数据的关注热点。在对中国知网文献摘要进行Word2vec 模型训练后, 共计得到17 935个词语, 每个词语的维度为100 维。在对知乎回答进行Word2vec 模型训练后, 共计得到11 424个词语,每个词语的维度为100 维。本文将结合最相似词语分析对学术平台和社会化问答平台的关注热点进行比较。
4.2.1 与“大数据” 最相似的前20 个词语的比较
表2 显示了中国知网文献摘要与知乎回答中与“大数据” 最相似的前20 个词语。
从表2 可以看出, 学术界和实践界在大数据关注热点上存在差异。从表2 的左半部可以看出, 学术界的研究焦点集中在大数据的数据挖掘、数据分析、技术、剖析、应用领域、内涵、数据管理等,与大数据最相似的词语显得学术化和规范化。确实,关于大数据的数据挖掘、数据分析、技术等, 官思发等[23] 从大数据驱动科学萌芽、大数据分析方法以及分析即服务3 个方面入手, 探讨了国内外大数据分析研究的现状。研究结果表明, 在大数据分析领域存在专业分析工具匮乏、数据建模、数据存储、资源调度以及弱可用性这五大重要问题, 同时针对以上问题, 还提出了研发大数据分析平台、优化数据分析模型、部署云存储技术、弹性调度资源以及提升数据可用性这5 个解决方法。邢云菲等[24] 使用时空大数据挖掘技术, 以“天和核心舱发射” 话题为例, 基于知识图谱理论探究了社交网络中的舆情演化模式与规律。研究结果表明, 舆情主体的不同属性反映了多联的关系模式, 时间序列的不同显著影响社交网络舆情主体在空间上的关系。关于大数据技术, 孟秀丽等[25] 探讨了大数据技术对众包物流平台及其接包方决策的影响。研究结果表明, 服务价格正向影响服务平台和接包方的质量控制水平与大数据技术水平; 采取大数据技术策略的服务平台, 平台自身的质量控制水平会得到提高, 而对于接包方而言, 其质量控制水平不受大数据技术策略的影响。杨晓刚等[26] 探究了一种基于大数据技术的用户小数据管理模式。研究结果表明, 大数据技术和传统数据管理技术的结合有助于更加高效地管理小数据, 大大提升了面向用户个体的信息服务质量。
从表2 的右半部分可以看出, 实践界的大数据关注热点集中在大数据的概念和概述上, 如层面、概念、理解、体现、定性、意义、基石、概述、洞悉, 并试图探究大数据技术的应用, 如实践、软件产品、深入人心, 实践界也比较关注大数据的发展, 如新一轮、大数据时代。
4.2.2 与“数据” 最相似的前20 个词语的比较分析
对中国知网文献摘要和知乎回答进行词频统计, 前10 个高频词如表3 所示。
词频在一定程度上能反映关注焦点, 但是, 词频并不能反映文本语义信息。基于表3, “数据” 是同时在中国知网文献摘要和知乎回答中除“大数据” 外频次最高的词语。作为表2 的补充, 表4 显示了与“数据” 最相似的前20 个词语。
从表4 左半部分可以看出, 在中国知网文献摘要中, 数据与数据类型密切相关, 如结构化、异构、庞杂、格式。数据还与数据的处理与分析关联密切, 如整理、收集、清洗、采集、储存、获取、整合, 反映了学术界聚焦数据分析研究以推动数据价值的实现。关于数据分析与价值, 张俊瑞等[27]分析了商业大数据, 探究了大数据对数据资产合理估值的作用, 进一步完善了数据交易市场的基础设施建设。张冬等[28] 通过分析主流媒体疫情信息数据探究了新冠疫情网络舆情数据中网民情绪波动、关注度与主流媒体华语引导之间的关系, 具体方法是通过对这些数据进行情感分析及可视化, 分析结果表明, 主流媒体的报道对网民情绪缓解有积极作用。
从表4 右半部分可以看出, 在知乎回答中, 数据与数据处理有关联, 如提取、存储空间、驾驭、流转, 说明在社会化问答平台中, 数据处理成为关注的焦点。数据还与数据的体量有关联, 如体量、速度、庞大、几何级数、大小。此外, 社会化问答平台还试图探究数据的性质, 如来源、类型、种类、数据类型、可变性、多种多样。
4.3 大数据词嵌入概貌比较分析结果和讨论
4.3.1 词嵌入概貌的可视化
在进行词转向量建模时, 维度设置为100, 因此, 基于中国知网文献摘要训练的17 935個词语的向量和基于知乎回答训练的11 424个词语的向量都是100 维。例如, 下面是基于中国知网文献摘要训练的模型中词语“大数据” 100 维的值。
与词语“大数据” 的向量维度类似, 所有词语的向量维度都是100 维。词向量可视化可以更直观地展现出学术平台和社会化问答平台在大数据词嵌入概貌上的差异。在对这两个平台的词嵌入进行可视化之前, 需要分别将基于中国知网文献摘要训练的17 935个词语和基于知乎回答训练的11 424个词语进行降维处理。具体可以利用t-SNE(t-distrib⁃uted Stochastic Neighbor Dmbedding)算法。t-SNE 是一种用于降维的机器学习算法, 主要用于将高维数据可视化展示。它可以将高维数据降为二维或者三维这种低维数据, 并在低维空间里保留了原始数据的局部特征, 使得高维空间数据中距离相近的点转换到低维中仍然相近, 从而能在可视化时直观地展现出来[29] 。Scikit-learn, 也称为Sklearn, 是Py⁃thon 的一个第三方库, 集成了许多经典的机器学习算法[30] 。Sklearn.manifold 是Scikit-learn 库下的一个子模块, 它提供了多种降维方法, t-SNE 就是其中之一, t-SNE 在对高维数据降维的同时保留了数据的局部结构和特征[31] 。通过调用t-SNE 的Fit_transform()方法, 将训练模型中的所有词语从100维降到2 维。例如, 基于中国知网文献摘要训练的模型中, 词语“大数据” 降维后的向量值如下:
array([-68.00372,-0.3688781],dtype=float32)
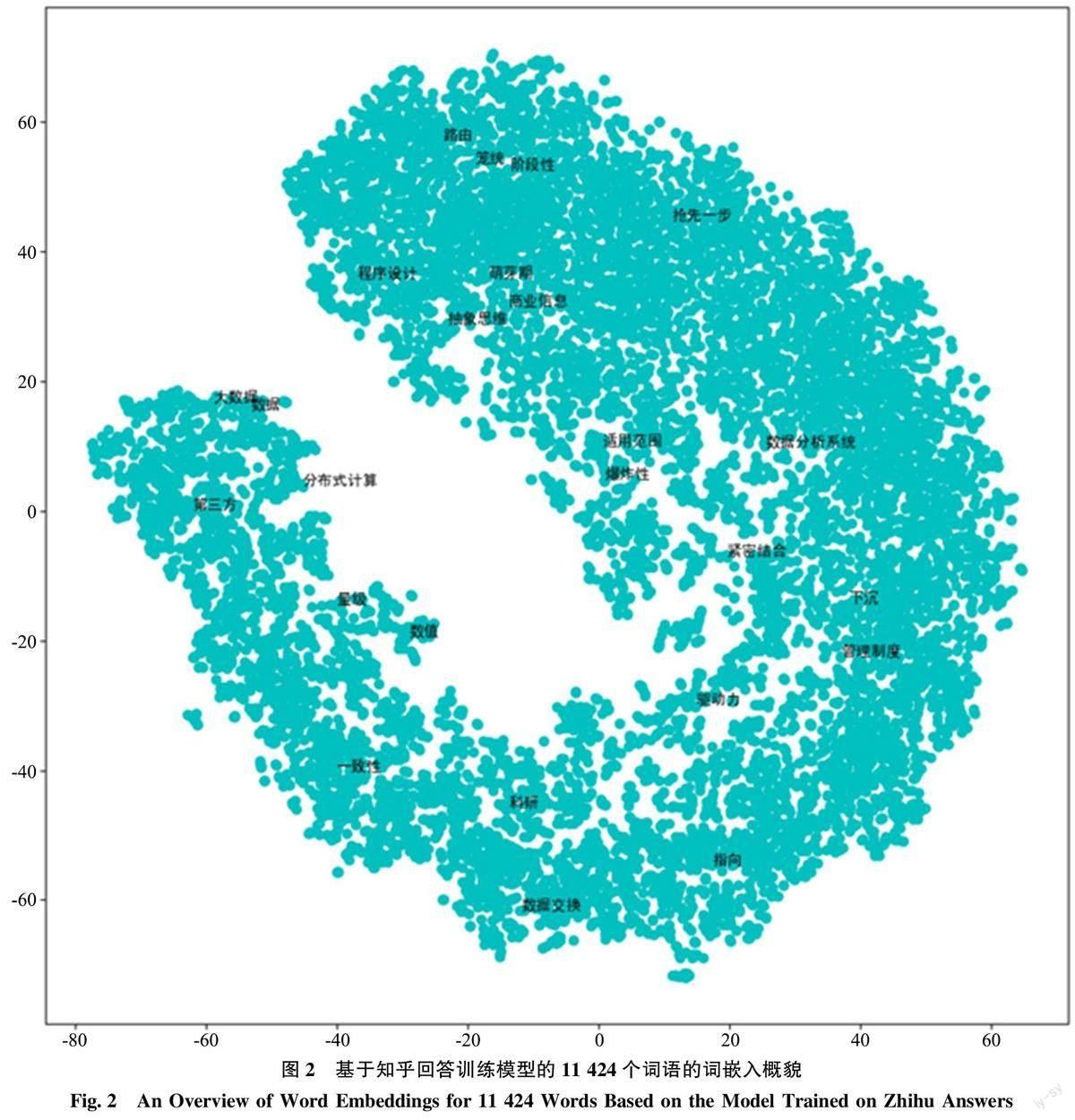
再利用Matplotlib.pyplot 模块编写Python 程序,将降维后的数据进行可视化显示。对于中国知网文献摘要训练模型中的17 935个词语, 将每个词语的二维值的第一个值设为x, 将第二个值设为y。由于该数据集体量较大, 数据点比较密集, 所以在设置词语的显示时, 为了保证词语不重叠以及可视化的美观性, 只能显示少量词语。考虑到前面针对“大数据”“数据” 这两个词进行了比较, 因此,先设定显示这两个词, 然后, 设定从17 935个词语中随机选取23 个词语, 这样, 一共显示25 个词语, 生成的图如图1 所示。对于知乎回答训练模型中的11 424个词语, 进行类似的处理, 生成的图如图2 所示。
4.3.2可视化比较分析
图1 和图2 中的点分布反映了词语之间的相似度, 每个点代表1 个词语, 数据点密集程度越高,表明相似的词语越多, 反之, 表明相似的词语较少。从图的形状上来看, 图1 和图2 有着明显的差异。在图1 中, 词语集中分布在图形的中间, 图1 的形状好似一个倾斜的矩形。在图2 中, 中间的空白表明两边的词语存在较大的距离, 相似度小, 图2 的形状好似一个向左倾斜的U 型。
从“大数据” “数据” 两个词语在图中所处的位置来看, 图1 和图2 有着明显的差异。在图1 中,“大数据” 和“数据” 都分布在图的左侧, “大数据” 在图的上方, “数据” 在图的下方, 且“大数据” 与“数据” 距离较远, 说明这两个词语相似度较小, 它们的周围都遍布着较多的点, 表明各自拥有较多相似的词语。在图2 中, “大数据” 和“数据” 都处在U 型左线条的高处, 并且这两个词语的距离较近, 表明这两个词语的相似度较高, 在它们的周围都遍布着较多的点, 表明各自拥有较多相似的词语。此外, U 型线右线条上聚集着更多的点, “大数据” “数据” 两个词语与U 型线右线条上的点中间存在一个空白区域, 这表明没有词语在中间发挥直接连接作用。
图1 和图2 是分别基于中国知网文献摘要和知乎回答两个语料库训练的模型, 在对词语的向量降维后进行可视化显示而生成的, 它们的差异直接反映了大数据词嵌入概貌在学术平台和社会化问答平台上存在的整体差异。为了更好地探究哪些词语具有相似性和哪些词语不具有相似性, 可以更改随机种子的状态, 反复执行Python 代码, 则会随机抽样得到不同的数据以展现不同的词语, 从而进一步显示在我国学术平台和社会化问答平台上大数据相关词语分布上的差异。
5结语
有理由认为, 中国知网平台中大数据的中文文献能够反映我国学术界的声音, 知乎平台中大数据主题下主流问题的回答能够反映社会化问答平台的声音。本研究创新地利用Word2vec 神经网络词嵌入方法, 结合最相似词语分析对学术平台和社会化问答平台的大数据关注热点进行了比较, 利用降维和可视化方法, 对两个平台词语的词嵌入概貌进行了比较, 研究结果展现了学术平台和社会化问答平台在大数据方面的差异。未来可以从以下方面开展更多的研究: 第一, 本研究结合学术平台和社会化问答平台对大数据进行了比较分析, 未来可以结合更多平台对大数据进行比较分析。第二, 大数据研究起源于国外, 未来可利用Word2vec 对国内外学者所做的大数据研究进行比较分析。第三, 大数据推动了数据驱动的人工智能的快速发展, 数据驱动的人工智能研究和实践正在经历从以模型为中心向以数据为中心的轉移, 未来可结合这个转移更多探讨大数据的资源特征。
猜你喜欢
人间(2016年28期)2016-11-10 11:51:06
美与时代·美术学刊(2016年8期)2016-11-09 02:37:40
新闻前哨(2016年10期)2016-10-31 17:28:25
商场现代化(2016年22期)2016-10-18 20:13:24
商场现代化(2016年22期)2016-10-18 20:06:05
今传媒(2016年9期)2016-10-15 22:27:04
新闻世界(2016年10期)2016-10-11 20:13:53
科技视界(2016年20期)2016-09-29 10:53:22
中国记者(2016年6期)2016-08-26 12:36:20
