
乡村振兴背景下区域发展程度预测方法
2024-01-26 02:48解浩周刘婧宜高贤谡汤梦琪
科技和产业 2023年24期
解浩周, 刘婧宜, 高贤谡, 汤梦琪, 丁 曼, 乔 晶
(中国移动通信集团设计院有限公司, 北京 100080)
乡村振兴是中国国家战略之一,实施乡村振兴战略是解决新时代中国社会主要矛盾、实现“两个一百年”奋斗目标和中华民族伟大复兴中国梦的必然要求。为更有效、更有针对性地实现乡村振兴战略,需要对各区域的发展程度进行评估和预测,以制定合理的政策和规划。区域发展程度是一个综合性的概念,涉及经济、社会、环境、文化等多个方面的指标。
在“东西不平衡、城乡不平衡”的发展格局下,各区域由于地理环境、人力资本、设施服务、内生发展动力等基础发展条件方面的差异性,造成不同区域乡村振兴水平呈现参差不齐的情况。因此,如何有效准确地识别区域发展程度,是一个具有重要意义和挑战性的问题。
目前,关于区域发展程度的识别方法主要有两类:一类是基于统计分析的方法,如主成分分析[1]、聚类分析[2-3]、因子分析[3]等;另一类是基于机器学习的方法,如支持向量机[4]、决策树[5]、神经网络[6]等。这些方法都有各自的优点和局限性,但是都存在一个共同的问题,就是如何评估结果的可信程度,即预测结果的置信度。
针对上述问题,提出一种基于置信度评估模型的区域发展程度预测方法。首先构建区域发展程度预测模型,然后基于预测结果及其后验概率设计置信度评估模型,以提升区域发展程度预测模型的识别准确率和泛化能力。
1 数据来源及指标体系建立
《乡村振兴战略规划(2018-2022年)》明确指出,按照“产业兴旺、生态宜居、乡风文明、治理有效、生活富裕”的总要求,科学有序地推动乡村产业、人才、文化、生态和组织振兴。实施乡村振兴,产业兴旺是建设现代化经济体系的重要基础,生态宜居是建设美丽中国的关键举措,乡风文明是现代文明建设的重要保障,治理有效是政治建设的重要保障,生活富裕是社会主义的本质要求。
基于以上对乡村振兴内涵的阐述,徐雪和王永瑜[7]在遵循科学性、可行性、可测性和数据可获得性等原则的基础上,构建包含产业兴旺、生态宜居、乡风文明、治理有效和生活富裕五个子系统,共包含30个具体指标的中国乡村振兴评价指标体系,如表1所示。
在上述指标基础上,徐雪和王永瑜[7]采用熵值法测度评价我国乡村振兴综合指数和各子系统指数,其具有客观赋权的优点,可以避免专家赋权的主观性,能够实事求是地反映各指标在综合指标中的重要性。
基于表1和熵值法,测算得到31个省份(因数据缺失,未包括港澳台地区)2002-2022年乡村振兴30个评价具体指标和综合指数。对于个别年份缺失的数据借鉴徐雪和王永瑜[7]中的处理方法。指标体系中的所有数据主要来源于《中国农村统计年鉴》《中国人口和就业统计年鉴》《中国城乡建设统计年鉴》《中国教育统计年鉴》《中国城乡统计年鉴》《中国社会统计年鉴》《中国民政统计年鉴》《中国第三产业统计年鉴》《中国农产品加工业年鉴》,以及各省份统计年鉴、Wind数据库、中国经济社会大数据研究平台。
使用测算得到的31省份2002-2022年30个乡村振兴评价具体指标作为样本特征,针对样本特征数据量纲不一致,采用Min-Max归一化对样本特征数据进行预处理。使用由熵值法计算得到的31个省份2002-2022年乡村振兴综合指数作为样本标签,其中,综合指数高于平均值的样本为正样本,表示该地区发展较好,低于平均值的样本为负样本,表示该地区发展欠佳。
2 置信度评估模型搭建
置信度评估模型搭建流程如图1所示。

图1 置信度评估模型流程
在获取数据后,首先使用机器学习分类模型对预处理后得到的样本特征和标签进行训练,得到区域发展程度预测模型。

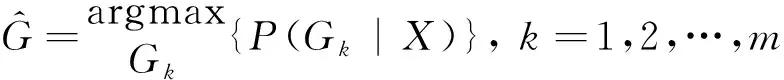
(1)
理想情况下,p为一个独立向量以产生正确的预测结果。然而研究表明在实际情况下,p通常呈均匀分布,因此p可被用作构建置信度评估模型的特征。
因此,为了进一步提高区域发展程度预测模型的准确度,构建置信度评估模型以计算分类模型对每个区域预测结果的置信程度。
置信度评估模型的数学表达式为
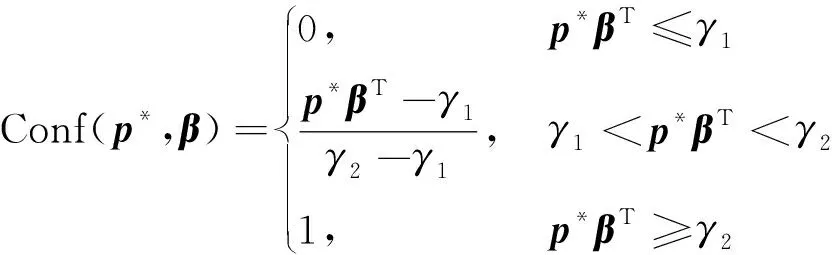
(2)
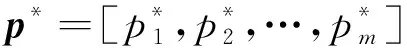
β被设计为一个可通过有监督算法学习的参数。将训练得到的区域发展程度预测模型分类结果用作Conf(p*,β)的训练数据,分类结果表示为
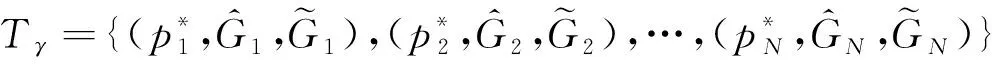
(3)
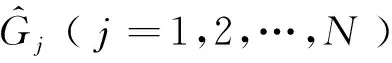
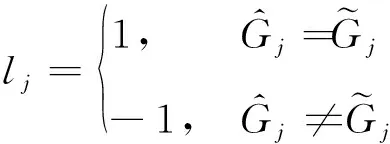
(4)
更新后的分类结果数据集表示为
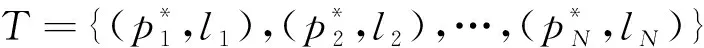
(5)
考虑到更高的Conf(p*,β)对应于更准确的预测,以及被正确预测或错误预测的样本过多导致T不平衡的问题,定义有效置信度为
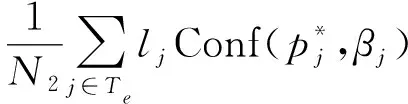
(6)
式中:EC∈[-1,1];Tc仅由正确的分类结果数据(l=1)组成;Te仅由错误的分类结果数据(l=-1)组成;Tc和Te的样本数分别为N1和N2。基于式(6),参数β的优化过程可被表示为
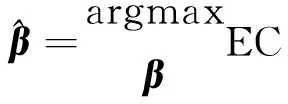
(7)

(8)
3 实验结果及分析
3.1 模型训练
实验将数据集按照80%、10%、10%的比例分为训练集、验证集和测试集,超参数γ1和γ2分别选为0和1,阈值α选为0.5。具体实验方法为:首先使用训练集训练区域发展程度预测模型,然后将模型在验证集上的预测结果的后验概率矩阵以及根据式(4)更新后的预测结果分别作为新的样本特征和标签训练置信度评估模型,最后在测试集上分别测得区域发展程度预测模型的准确率和经过置信度评估模型修正后的预测模型的准确率,以验证置信度评估模型的有效性。
首先,分别使用逻辑回归、支持向量机(support vector machian,SVM)、随机森林和XGBoost四种算法训练四个区域发展程度预测模型,以下是关于上述四种算法的简要描述。
逻辑回归[8]:是一种广义线性模型,是一种用于解决二分类问题的机器学习方法,其本质是假设数据服从某一分布,然后使用极大似然估计做参数的估计。
SVM[9-10]:是一类按监督学习方式对数据进行二元分类的广义线性分类器,其决策边界是对学习样本求解的最大边距超平面。
随机森林[11]:是利用多棵树对样本进行训练并预测的一种分类器,并且其输出的类别是由个别树输出的类别的众数而定。
XGBoost[12]:对梯度提升算法的改进,求解损失函数极值时使用了牛顿法,将损失函数泰勒展开到二阶,另外损失函数中加入了正则化项。旨在实现高效,灵活和便携的模型训练。
然后使用多层感知器(MLP)训练置信度评估模型。MLP是一种前馈神经网络,它由输入层、隐藏层和输出层组成。输入层接收输入数据,隐藏层负责处理数据,输出层输出处理后的结果。MLP是在不同领域复杂问题的优化中应用最广泛的进化算法之一。与许多其他启发式算法相比,它具有更好的全局搜索能力。
3.2 性能分析
3.2.1 模型效果对比
为了验证置信度评估模型对区域发展程度预测模型分类准确度的提升作用,以及其泛化能力的优越性,对四种区域发展程度预测模型及其对应构建的置信度评估模型分别进行了对比实验,实验结果如图3所示。
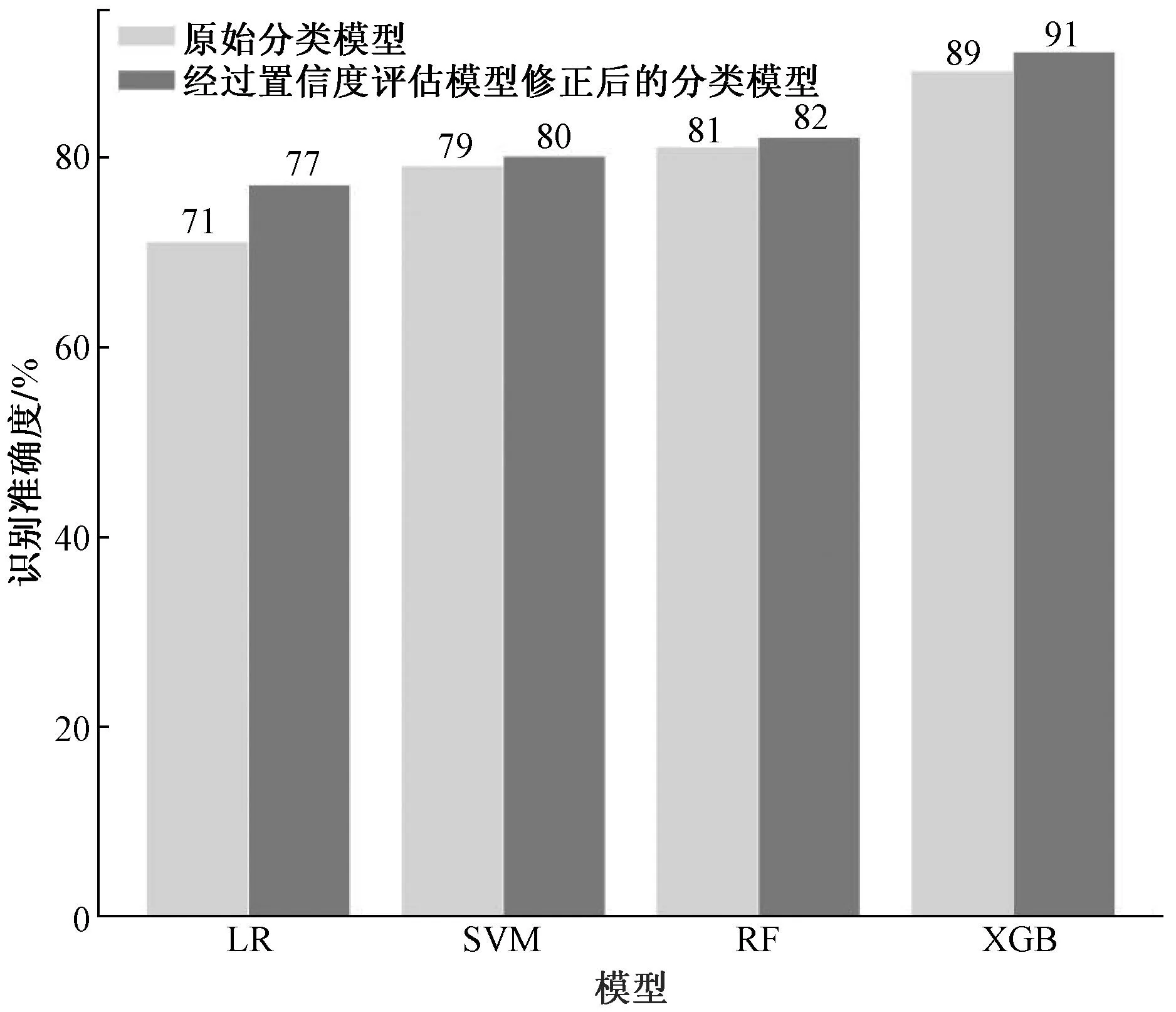
图3 置信度评估模型在不同分类模型上的性能对比
由图3可知,所有构建的置信度评估模型均使原区域发展程度预测模型的准确度产生了不同程度的提升。同时,在未使用置信度评估模型的四种区域发展程度预测模型中,XGBoost具有最高的分类准确度。
3.2.2 最佳模型特征解释
使用SHAP值对训练区域发展程度预测模型时表现最好的XGBoost模型进行全局特征解释,一方面展示重要性较高的特征,另一方面展示特征对模型输出的贡献,全局解释图如图4所示。
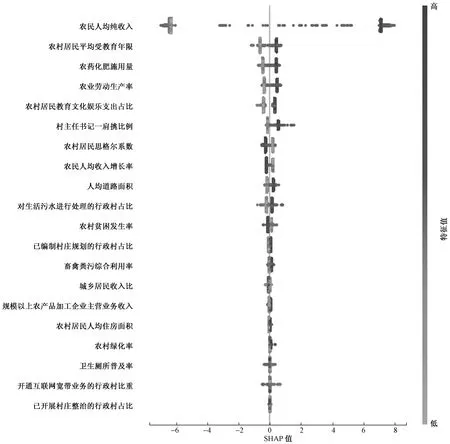
图4 区域发展程度预测模型全局解释
由图4可知,对模型预测结果影响最大的特征是农民人均纯收入,其余产生主要影响的特征有农村居民平均受教育年限、农药化肥施用量、农业劳动生产率、农村居民教育文化娱乐支出占比、村主任书记“一肩挑”比例、农村居民恩格尔系数、农民人均收入增长率等。继续分析上述主要特征可明显发现,除去农村居民恩格尔系数和农民人均收入增长率,其余特征对预测结果的影响均是正向的,即农民人均纯收入越高、农村居民平均受教育年限越长、农药化肥施用量越多、农村居民恩格尔系数越低,该区域发展相对越好,这也从另一角度验证了方法、模型和实验设计的合理性。
3.3 区域发展对策建议
根据实验得到的结果可知,对区域发展程度影响较大的因素较多,不同指标和区域发展程度的相关性也不尽相同。因此,针对发展程度相对较好和欠佳的区域,可从不同方面提出促进其发展的对策和建议。
对于发展较好的区域。第一,发挥比较优势,充分利用资源、技术、人才等优势,推动产业升级和创新发展;第二,加强要素流动和集聚,吸引更多的人才、资金和技术向该区域流动,促进要素的高效配置和集聚;第三,加强创新发展,鼓励加大科技创新投入,培育新兴产业和高技术企业,提升经济增长质量和效益;第四,构建高质量发展的动力系统,加强基础设施建设,提升交通、能源、信息等基础设施水平,为经济发展提供有力支撑;第五,增强经济和人口承载能力,加强经济发展优势区域的建设,提升其经济和人口承载能力,为周边区域提供更多就业机会和发展空间。
对于发展欠佳的区域。第一,壮大龙头企业,培育一批省、市、县级龙头企业,发挥其引领驱动作用;第二,搭建融合载体,引导资源集聚、企业集中、功能集合,引导农业与加工流通和服务业等渗透交叉、融合发展;第三,创响乡土品牌,发掘农业多种功能和乡村多重价值,强化市场营销与绿色引领的对接,发掘乡土资源“新绿金”;第四,支持创新创业,创建一批农村创新创业和实训孵化基地,运用现代信息技术,发展农村电商、数字农业和智慧农业;第五,加强教育和人才培养,加大教育事业投入,提升人才培养质量,为该区域提供更多人力资源支持。
4 结论
为提高地区发展程度的识别准确率及泛化性能,在基础分类模型基础上构建了置信度评估模型。模型以分类模型的后验概率和预测效果为样本,减少被错误分类的区域样本数量,提高区域发展程度预测模型的准确度,从而在对区域发展提出对策和建议时提供更可靠的分析依据。
经过实验与分析,得到如下结论。
1)在中国乡村振兴评价指标体系数据集上的实验验证了所构建的置信度评估模型对各种分类预测模型准确度均具有提升效果,表明置信度评估模型提升分类预测模型准确度的有效性和高泛化性。
2)使用SHAP全局解释图对表现最好的分类预测模型进行特征解释,筛选出重要性较高的特征并对其对模型输出的贡献进行分析。
3)发展较好的区域可从发挥比较优势、加强要素流动和集聚、加强创新发展、构建高质量发展的动力系统和增强经济和人口承载能力等五方面进一步促进发展。发展欠佳的区域可以壮大龙头企业、搭建融合载体、创响乡土品牌、支持创新创业、加强教育和人才培养等五个方向作为切入点带动区域发展。
猜你喜欢
核科学与工程(2021年4期)2022-01-12
家庭影院技术(2021年5期)2021-07-21
数学小灵通(1-2年级)(2021年4期)2021-06-09
意林(2021年2期)2021-02-08
中学生数理化·七年级数学人教版(2019年4期)2019-05-20
计算机应用(2018年5期)2018-07-25
中学生数理化·七年级数学人教版(2018年6期)2018-06-26
初中生世界·七年级(2017年9期)2017-10-13
轴承(2015年2期)2015-07-25
断块油气田(2014年6期)2014-03-11
