
机器学习驱动难熔高熵合金设计的现状与展望
2024-01-25 12:54高田创高建宝张利军
材料工程 2024年1期
高田创,高建宝,李 谦,张利军*
(1 中南大学 粉末冶金国家重点实验室,长沙 410083;2 重庆大学国家镁合金材料工程技术研究中心,重庆 400044)
随着航空航天、核反应堆、石油化工领域的迅速发展,对高温金属材料的性能提出了更为严苛的要求[1-2]。传统的镍基合金因其熔点偏低,需通过添加W,Mo 等高熔点元素来提升其使用温度,但依然无法满足核反应堆、液体火箭发动机喷嘴、陆地燃气轮机等部件在超高温极端环境下的性能需求[2-3]。因此,迫切需要设计出具有更为优异力学性能和耐高温性能的新型合金。
以难熔元素(如V,Cr,Zr,Nb,Mo,Hf,Ta,W,Re等)为主元素的难熔高熵合金(refractory high-entropy alloys,RHEAs)[4-5],具有传统合金无法比拟的优异性能[6-9],如高强度、高硬度、高断裂韧性、优异的耐疲劳性能、优良的耐腐蚀性、耐磨性、抗高温氧化、抗高温软化以及良好的热稳定性等。2010 年,Senkov 等[10]基于不同的难熔元素制备出具有单相BCC(A2)结构的WNbMoTa 和WNbMoTaV 难熔高熵合金。所制备的NbMoTaW 和VNbMoTaW 合金在1600 ℃高温下的屈服强度仍可保持在405 MPa 和477 MPa,表现出比镍基高温合金更优异的高温力学性能。Juan 等[11]制备了HfMoTaTiZr 与HfMoNbTaTiZr 难熔高熵合金,其在1200 ℃下仍具有超高的屈服强度,分别为339 MPa 和556 MPa。此外,Chen 等[12]设计并利用激光熔覆技术在TC4 基体上沉积AlTiVNbMo 难熔高熵合金涂层,在800 ℃高温下氧化120 h 后的平均氧化增重仅为TC4 基体的10.58%(即4.94 mg/cm2)。难熔高熵合金的高强度、高硬度、抗高温氧化等优异性能,使其在航空、航天、核能等领域具有广阔的应用前景和研究价值。
近年来,高性能难熔高熵合金的开发备受关注,而新型合金成分的设计是重中之重。但难熔高熵合金通常由4 种或4 种以上的难熔金属元素制备而成,具有巨大的未知成分组合空间。尤其是NiTiCrNbTa0.3[13],Al0.5NbTiV2Zr1.5[14],Ti2ZrHf0.5VNb0.5Al0.25[15]等非等摩尔比难熔高熵合金的出现,极大地增加了合金成分的复杂性。面对复杂的高维成分空间,传统的“实验试错法”[7,16-17]无法精确把握性能调控的规律,使得新材料的研发及性能优化周期变得十分漫长。随着近年来集成计算材料工程(integrated computational materials engineering,ICME)和材料基因工程(materials genome initiative,MGI)等计划的深入发展,高通量实验与高性能计算(如相图计算[18-20](calculation of phase diagrams,CALPHAD)、第一性原理计算(firstprinciples calculations,FP)[20-21]、相场模拟[22-24](phasefield modeling,PF)、机器学习[25-27](machine learning,ML)等相结合的数据驱动设计框架已广泛应用于新材料设计研发。由于当前相平衡、热力学实测数据仍偏少,难熔高熵合金的热力学数据库尚未完备,从而导致相关CALPHAD 计算结果与实验数据之间存在偏差。而精准的第一性原理计算虽可以替代部分实验数据,但对于具有复杂成分的难熔高熵合金而言,往往需要巨大的计算资源,很难实现合金成分的高效设计。
机器学习方法通过利用特定的算法对数据进行搜索学习,进而实现数据中关键知识信息的提取,可用于指导合金成分的高效设计[28]。相比于传统的合金设计需要进行大量的试错实验而耗费大量的时间和资源,机器学习可基于小样本数据集实现多组元合金在复杂工艺下的成分设计与工艺优化;在此基础上,利用高维数据进行预测和优化,在获取更全面材料性能信息的同时可显著提高设计的效率和准确性。机器学习驱动合金设计的核心在于建立目标合金“成分-性能”、“成分-工艺-性能”或“成分-工艺-组织-性能”的量化关系,进而用于高效精确地预测相结构的种类[29]和开发高性能难熔高熵合金[30]。与此同时,在数据挖掘过程中,通过机器学习自动识别出对目标性能至关重要的特征变量[30],将有助于深入了解合金材料的特性和行为规律。此外,利用机器学习方法还可以准确预测出原子间相互作用势[31],其计算精度与第一性原理计算结果相当,且仅消耗1/4 的计算时间。
综上所述,机器学习在合金相结构与性能准确预测、可视化特征分析以及加速原子模拟等方面具有显著的优势,有望实现高性能难熔高熵合金的高效开发与设计。因此,本文对国内外学者的研究进展进行全面的调研,从合金相结构预测、合金性能预测、强化机理辅助分析以及加速原子模拟等方面出发,综述机器学习技术在加速难熔高熵合金设计中的应用,最后指出机器学习驱动高性能难熔高熵合金研发的发展方向。
1 机器学习驱动难熔高熵合金相结构预测
合金的微观结构特性包括相的种类、数量和形态,对目标合金的性能具有显著的影响。最初,Kozak等[5]将高熵合金定义为等原子比的单相多元合金,而后续大量的研究[32-33]表明,分散在难熔高熵合金中的第二相可以显著提高合金的力学性能[34],双相或多相高熵合金在某些方面展现出比单相高熵合金更为优异的性能。因此,高性能合金设计的关键在于获得特定的组织结构以满足性能的需求。
有别于传统的CoCrFeNi,AlCoCrFeNi,FeMn-CoCr 等FCC 相高熵合金,难熔高熵合金通常是由具有BCC 结构的难熔金属元素(V,Cr,Nb,Mo,Ta,W等)组合而成,基体相为BCC 固溶体相。一般来说,采用CALPHAD 方法可以快速计算出合金的相结构,进而指导合金设计[35-37]。但目前缺乏准确的难熔高熵合金体系热力学数据,尚难以实现对难熔高熵合金相结构的准确计算。机器学习模型可从合金成分出发,通过构建合金成分与相结构之间的定量化关系,从而实现对难熔高熵合金相结构的分类和预测[38-40],用于辅助合金设计。如图1 所示,机器学习方法驱动高熵合金相结构预测的主要步骤包括:数据收集、数据清洗、特征筛选、模型构建以及目标输出。数据集可由实验结果或CALPHAD 计算数据组成,包括合金成分、工艺参数、相结构等信息。其中,合金的相结构按照种类不同可以划分为非晶相(AM)、固溶体相(SS)、金属间化合物相(IM)或SS+IM 双相等;按照相的数量可以分为单相(single)固溶体或多相(multi)固溶体;而按照晶体结构的不同还可进一步细分为BCC, FCC,HCP 以及IM 相。在机器学习辅助相结构预测过程中,对输入的特征变量进行筛选可起到去除冗余信息、降低模型复杂性、减少过拟合风险、提高模型精度的作用。通过与专家经验或先进算法相结合,选择出最佳的特征变量与模型算法组合,是构建高精度高熵合金相结构分类模型的关键。

图1 机器学习指导合金相结构预测的流程图Fig.1 Flow chart for machine learning assisted alloy phase prediction
1.1 机器学习结合专家经验
为了设计高熵合金的相结构,研究者们通常采用多种经验参数来预测高熵合金相结构的形成,包括热力学参数:ΔHmix,ΔSmix,Ω;原子尺寸参数:δr,γ;以及电子参数:VEC,e/a,ΔχPauling与ΔχAllen等(详见表1[41-47])。目前常用的相结构经验判据汇总如表2 所示[41-42,44-49]。一般根据分类图谱信息,选择2~3 个不同类型的经验参数作为分类判据,但尚未有统一的研究标准。传统的经验判据具有很强的局限性,且不同判据的预测精度各有差异,所适用的合金体系也不同,只能用于判断单一的相结构类型。而机器学习常以经验参数作为特征变量,在构建难熔高熵合金相结构预测和分析模型方面具有广泛应用。

表1 难熔高熵合金的材料特征参数Table 1 Feature variables for refractory high-entropy alloys

表2 用于高熵合金相结构预测的经验判据汇总Table 2 Summary of empirical rules for phase structure prediction of high-entropy alloys
(1)辅助构建高准确度相结构经验判据。传统的经验判据通常需经大量的绘图分析而得,耗费的时间多且易受人为因素的影响。而机器学习可利用自身算法优势,在大量的数据中快速评估每个特征变量对合金相结构预测的影响情况,并筛选出关键的特征变量[25,50-53]。Pei 等[51]在1252 组高熵合金相结构数据的基础上,通过建立高斯过程分类模型,实现对具有单相与多相结构合金的精确分类,模型预测准确性高达93%(如图2 所示)。而在对数据集特征变量进行相关性分析时,作者们发现体模量、摩尔体积、熔点与成分是影响合金相结构的关键特征(图2(a))。根据部分混合熵对固溶体相形成的作用,利用4 个关键特征得到相结构分类的新参数γ(式(1)),并提出以γ≥1 作为形成单相固溶体的评判标准,相比于其他经验判据具有更高的预测准确率(图2(b)),但对于多相结构合金的预测准确度仍有待提高。

图2 机器学习模型辅助构建合金相结构预测标准[51](a)关键特征变量筛选;(b)新的γ 判据结合原子尺寸差参数δr对合金相结构的预测准确度Fig.2 ML model-assisted construction of alloy phase prediction criteria[51](a)key feature variable screening;(b)phase prediction accuracy of the new rule γ together with the lattice misfit rule δr
式中:ΔGN表示N主元体系的吉布斯自由能;ΔG2表示子二元系的吉布斯自由能。
(2)相结构定量化特征分析。合金相结构受到多种因素的影响,因此深入了解不同特征变量之间的相互作用关系,有利于精准把握相结构变化规律,为合金设计提供有效的指导[51,53-54]。利用机器学习模型可对FCC 和BCC 相形成的概率进行预测。在此基础上,Beniwal 等[52]利用函数模型定量化描述了VEC 等特征变量对相形成的影响规律(图3)。对FCC 与BCC 合金分类的准确度分别为93%和84%。而通过计算权重因子(βi)的大小还可得到不同特征变量的贡献(图3(c)),其中金属半径差(δrmet)、共价半径差(δrcov)、弹性模量差(δE)、平均内聚能(Ecoh)对相的影响较大,且对于FCC 与BCC 结构分别呈现出相反的关系。该模型预测的相结构与实验数据具有较高的吻合度,能够直接定量估计特征对相概率的贡献,从而深入了解机器学习模型在高熵合金相结构选择中的决策过程。

图3 用于FCC 与BCC 相结构预测的机器学习简化模型[52](a)采用logistic 函数描述VEC 参数对形成FCC 和BCC 相的影响;(b)使用Skew-normal 函数分析FCC 和BCC 相形成概率与logistic 函数的残差;(c)简化数学模型中每个特征的权重系数(βi)Fig.3 Simplified ML model for FCC and BCC phase prediction[52](a)logistic function used to model the dependence of FCC and BCC occurrence probability on VEC;(b)skew-normal function of VEC used to model the peak residuals obtained after logistic fit of phase probabilities with VEC;(c)weight-factors(βi) of each feature in reduced mathematical model
综上,系列的经验参数全面提炼了高熵合金的本征特性,进一步结合机器学习等强大的数据处理方法,有益于实现难熔高熵合金相结构的精确预测和设计。
1.2 机器学习结合先进算法
尽管经验模型可以为高熵合金中相结构的预测提供便捷的方法,但其具有较大局限性、单一性、不准确性,几乎所有的经验模型只能完成一种类型的相结构预测(即:固溶体与非固溶体或单相与多相),而且对于不同合金体系而言,其预测准确度也差异较大。而机器学习模型能够实现多类相结构的预测,快速分辨出复杂的结构信息,具有较高的准确性与普适性[25,29,38-40,50,53,55]。对于AM,SS 与IM 相[25]以及BCC,FCC,HCP 与IM 等混合相[29]的预测准确率能达到90%以上。进一步结合遗传算法、主动学习、深度学习、集成学习等先进算法,对于加速机器学习模型的开发、实现模型的智能化构建和合金相结构的精确设计具有显著的效果。
(1)智能化特征筛选。筛选出最佳的特征变量与模型算法搭配组合,是实现高准确度相结构预测的关键。利用不同的先进算法可自动高效地完成特征筛选与模型超参数优化工作,构建出预测效果优异的相结构预测模型[56-59],常用的方法包括遗传算法、主动学习和主成分分析等。
遗传算法(genetic algorithm,GA)是一种模拟生物进化过程的搜索和优化算法。图4(a)展示了一种利用遗传算法从大量备选方案中高效地选择机器学习模型和特征变量的系统框架[58],利用该方法构建的模型能有效辨别出BCC,FCC 和BCC+FCC 相高熵合金,分类准确度较传统的经验参数方法提高了10%以上(图4(b))。此外,对于具有最大分类不确定性的边界高熵合金,可进一步结合主动学习策略,将经过实验表征后的相结构信息反馈回数据集中,实现模型的迭代优化,提高了模型预测的精度[58]。

图4 先进算法提高机器学习模型准确度的应用实例(a)采用遗传算法(GA)搜索材料描述符和机器学习模型的最佳组合的流程图[58];(b)9 个应用不同材料描述符子集筛选方法的机器学习模型预测性能对比[58];(c)一种用于提高高熵合金的相结构预测性能和识别关键设计参数的深度学习方法[60];(d)DNN-BO 和DNN-Augment150 模型相结构预测结果的混淆矩阵对比[60]Fig.4 Applications of advanced algorithms improving the accuracy of ML models(a)flowchart of genetic algorithm (GA) strategy to search for the best combination of materials descriptors and ML model[58];(b)comparison of the performance of nine ML models using each materials descriptor subset selected by the different methods[58];(c)a deep learning-based method for enhancing the performance and identifying key design parameters for phase prediction of HEAs[60];(d)confusion matrices showing the phase prediction results of two models: DNN-BO and DNN-Augment150[60]
主成分分析法(principal component analysis,PCA)是一种重要的特征选择方法,广泛用于大数据集的降维处理,增加特征筛选的可解释性,同时最大程度地保留原始数据的信息。利用PCA 和相关性分析方法筛选出的VEC,δ,Δχ,ΔS,ΔH和Tmelt6 个特征变量可实现高熵合金SS,IM 与SS+IM 相结构的准确预测,所构建的K 近邻与随机森林分类模型测试准确度分别高达92.31%与91.21%[59]。而另一方面,核主成分分析法(Kernel principal component analysis,KPCA)通过向传统的PCA 中融入特定的非线性核函数,可实现数据特征的升维处理。Zhang 等[55]提出了利用KPCA 进行特征变量选择和优化的方法,基于4 个特征变量(HE,HL,Smix与δ)和KPCA 的支持向量机模型预测准确率高达97.43%。但无论是特征降维或特征升维,其根本目的仍是对特征进行筛选,以使得纠缠的数据集在低维或高维空间中呈现出更明显的可分类性。
(2)批量化数据强化。高质量数据集的构建能较好地弱化非关键信息的影响,利于机器学习模型准确地把握合金相结构形成的规律,起到提高预测准确率的作用。为解决数据量少的难点,Lee 等[60]采用基于深度学习的优化、生成和解释方法(图4(c)),利用条件生成对抗网络得到与原始样本数据分布相接近的新数据,对训练数据集进行强化处理,当每种相的增强样本数量为150 时,模型的预测准确度从84.75%显著提高到了93.17%(图4(d)),有效克服了因数据不足而造成的预测偏差问题。
(3)集成化模型预测。集成学习是一种基于多机器学习器组合的学习策略[61],相较单一学习器而言更具泛化性和准确性,常见的方法包括自举法(bagging)、提升法(boosting)、堆叠法(stacking)和投票法(voting)等[61-63]。其中,Yan 等[62]构建的梯度提升模型对于单相固溶体与非单相固溶体的分类准确度高达96.41%。Qu 等[61]基于堆叠法构建出的多个K 近邻分类模型,与单个K 近邻模型相比,测试集的预测精度从90%提高到93.137%,对单一相(BCC,FCC,HCP和IM)的预测精度均在97%以上。不同的集成方法效果各有千秋,相比而言,集成学习策略具有较高的预测精度,同时也避免了在单个机器学习器中的过拟合风险。
基于上述报道可以发现,多样的优化算法与策略已广泛应用于高性能模型的构建,从数据强化、特征筛选、模型优化等方面显著提高模型的预测性能和泛化能力。
2 机器学习驱动难熔高熵合金力学性能预测
在难熔高熵合金的设计过程中,合金的力学性能指标一直是关注的重点。以合金性能为导向的机器学习方法,在合金弹性性能、硬度、屈服强度等方面的定量化高效设计中具有广泛的应用空间。
2.1 弹性性能
合金的力学和热力学性质通常与弹性常数直接相关[64],例如材料在不同应力下的弹性应变通常取决于弹性常数的大小。对于立方结构的难熔高熵合金而言,存在着3 个独立的弹性常数,即C11,C12与C44[63-64]。此外,利用弹性常数可进一步计算合金的基本特性,包括体积模量(B)、剪切模量(G)、杨氏模量(E)、泊松比(ν)和德拜温度等[65]。为获得难熔高熵合金的弹性特性,研究学者们进行了大量的理论研究和实验工作。但由于缺乏高效的数据获取方法,无法深入理解体心立方弹性常数的规律。而更多的理论计算和实验测定通常需要消耗大量的计算资源与实验成本。通过对有限的实验数据或第一性原理计算结果进行建模学习,机器学习可实现难熔高熵合金弹性性能的快速精确预测[66-70]。Bhandari 等[64]仅用370 组第一性原理计算获得的数据作为数据集,利用梯度提升回归模型实现了对合金弹性常数C11,C12和C44的建模预测,其中训练集数据与预测数据的相关系数(R2)值均在0.98 以上(见图5)。

图5 机器学习模型对难熔高熵合金弹性性能预测结果[64](a)C11;(b)C12;(c)C44Fig.5 Prediction results of elastic properties of RHEAs based on ML models with training and testing datasets[64](a)C11;(b)C12;(c)C44
值得关注的是,优良的耐蚀性能使得难熔高熵合金成为潜在的新型生物材料,但金属植入体与人骨之间刚度的不匹配问题是导致植入体失效的主要原因。为保证合金的生物相容性,研究者们正致力于寻找出弹性模量(E)较低的合金体系。Ozdemir 等[69]应用K近邻模型对TixTayHfzNbmZrn合金成分进行优化设计,成功获得两种成分不同的低弹性模量合金(Ti23Ta10Hf27Nb12Zr28和Ti28Ta10Hf30Nb14Zr18),所设计的最佳合金弹性模量分别为(83.5±2.9) GPa 和(87.4±2.2) GPa。Hayashi 等[65]则利用遗传算法优化的机器学习模型获得了50 组候选合金成分,其中ScTiVZrNb 合金的弹性模量仅为45 GPa,为医用难熔高熵合金的高效开发设计提供了可供参考的方法。
2.2 硬度
数据驱动的机器学习能够构建输入数据和输出目标之间的复杂非线性关系,可快速建立起合金成分与组织结构、硬度性能之间的关系模型[71-73],广泛应用于高性能难熔高熵合金在复杂工艺下的成分设计[74-77]。利用反向传播神经网络建立的综合模型平均预测精度高达95.9%,描述了Al,Cr,Co,Cu,Mn,Fe,Ni,W 元素以及烧结温度对合金硬度的影响规律,有效实现高硬度合金烧结工艺与成分之间的精确调控[75]。进一步结合相结构预测、性能预测与关键实验验证方法,Huang 等[78]同时对CrMoNbTi 系难熔高熵合金的相结构与硬度进行了设计。图6 展示了一种综合考虑相结构和硬度的合金设计方法,所设计的5 个成分不同的CrMoNbTi 合金均为BCC 单相固溶体结构,硬度预测结果与实验真实值的误差均在10%以内。

图6 机器学习方法驱动的BCC 单相CrMoNbTi 难熔高熵合金硬度优化策略[78](a)合金硬度模型的建立;(b)机器学习固溶强化模型和物理固溶强化模型对合金硬度预测结果的对比;(c)CrMoNbTi 目标合金硬度预测值与实验值对比;(d)目标合金XRD 结果;(e)目标合金微观组织Fig.6 Hardness optimization strategy for BCC single-phase CrMoNbTi RHEAs driven by ML methods[78](a)ML modeling of alloy hardness;(b)comparison between the ML-SSH model and physical SSH models on hardness prediction;(c)comparison of predicted and experimental hardness of CrMoNbTi target alloys;(d)XRD result of target alloy;(e)microstructure of target alloy
该方法进一步证实了合金性能与组织结构协同优化的可行性,同时也为实现高性能难熔高熵合金的高效设计提供了方法指导。但目前难熔高熵合金性能设计大多只能满足单一的性能需求,对于突破强度-伸长率、硬度-导电率等具有强制约关系的性能仍有待进一步的研究。
2.3 屈服强度
作为一种新型的结构材料,屈服强度是难熔高熵合金设计和应用中的重要参数之一。尤其是面对愈发极端复杂的超高温环境,对合金的高温强度提出了更为严苛的要求。如何突破现有性能的限制,实现高性能合金的开发一直是研究的重点内容。在机器学习指导高强度合金设计方面,已逐步形成了全成分筛选、成分优化以及相结构优化等设计策略,助力高性能难熔高熵合金的高效设计。
(1)全成分筛选。利用机器学习强大的数据预测能力,可对Al-Cr-Nb-Ti-V-Zr 体系全成分范围内166个虚拟合金的高温屈服强度进行预测,所设计Al5Cr5Nb38Ti32V5Zr15,Al8Cr11Nb32Ti20V20Zr9,Al5Nb24Ti40-V5Zr26和Al4Cr3Nb21Ti40V4Zr284 种新型合金具有优异的力学性能,其中Al5Nb24Ti40V5Zr26合金在800 ℃高温下的屈服强度高达880 MPa[79]。
(2)基准合金成分优化。调整合金成分配比是提升合金性能的有效方法,Giles 等[80]提出了一种基于机器学习和优化的智能计算框架,通过对基准合金的成分进行优化调整,可实现难熔高熵合金屈服强度的大幅度提高。以HfNbTaTiZr 合金为例,优化成分后得到的Hf0.171Nb0.114Ta0.295Ti0.105Zr0.315合金的室温屈服强度提高了80%;而Hf0.093Nb0.189Ta0.347Ti0.32Zr0.051合金在1000 ℃下的屈服强度也相对提升了37%。可以发现,增加Ta 和Ti 元素的含量有利于提升合金的高温强度。该方法也可清楚地描述出各元素含量对性能的影响概率,对于理解合金强韧化机理具有重大意义。
(3)相结构优化。结构决定性能,对合金相结构进行优化设计是获得高性能合金的关键。基体中析出的Laves 相颗粒会对合金的强度产生有利的影响。但在高温下,当合金中第二相的体积分数过大时,会变得比基体相更软而降低合金的高温强度[81],协同提升难熔高熵合金室温和高温力学性能的关键在于优化析出相的含量。图7 展示了一种机器学习与经验法则、CALPAHAD 建模相结合的合金设计策略[82],可同时实现合金相结构与屈服强度的优化设计。首先采用机器学习模型对Al-Cr-Nb-Ti-V-Zr 系合金室温与高温强度进行训练学习(图7(a)),筛选出高强度合金的成分分布区间。随后通过经验参数判据和CALPHAD 计算相图进一步分析合金相组成(图7(b)),保留单相结构合金。所设计出的目标合金基体相为BCC 固溶体相,只在晶界处有少量(<10%)第二相析出,在20 ℃和600 ℃下的屈服强度优于大部分文献数据且预测误差都低于20%。
机器学习方法在提升难熔高熵合金屈服强度方面效果显著,但对于提升合金塑性的研究却鲜有报道。受固溶强化效应的影响,难熔高熵合金通常表现出极高的强度,但室温下合金的压缩应变通常在10%以下,表现出脆性断裂的特征,严重限制了难熔高熵合金的实际应用。因此,提升合金塑性,开发出优异力学性能的高强韧难熔高熵合金将是未来合金设计工作的重点。
3 机器学习驱动难熔高熵合金强化机理分析
典型的难熔高熵合金具有简单的晶体结构,且主要以体心立方结构为主。难熔高熵合金通常由4 种或四种以上的元素组成,合金中不同半径的高浓度原子往往会引起的严重晶格畸变[83],这些畸变会形成显著的固溶强化效果[84],从而起到提升合金性能的作用。然而,合金具有巨大的组成空间,衍生出系列可用于描述合金性质的特征变量,如热力学参数、尺寸参数、模量参数等。因此,如何快速识别出控制固溶强化的潜在因素以加速高性能难熔高熵合金的设计是一个巨大的挑战。而采用机器学习方法可以辅助进行合金强韧化机理的高效分析,主要分为建模前的特征分析以及建模后对模型进行的可解释性分析。
3.1 特征分析
特征筛选是机器学习中特征工程的一个重要步骤,可从原始数据中提取出与合金性能最相关的特征变量,并提高机器学习模型的预测准确性、降低模型复杂度。常用的特征选择方法包括过滤法、包装法与嵌入法等。皮尔逊相关系数分析是机器学习建模前常用的一种特征过滤方法,可用来度量两个特征变量之间线性关系的强度和方向;包装法则是将特征筛选包装进模型的评估过程中,通过构建特征变量子集反复训练机器学习模型,根据模型预测效果评分来选择特征变量,包括递归特征消除和遗传算法等;嵌入法则是将特征选择嵌入到模型的训练过程中,通过模型得到各个特征的权值系数,从而实现特征重要性的定量化评估,包括Lasso 回归、决策树、随机森林等模型。
为获得更佳的模型预测性能,通常采用多种筛选方法相组合的方案。利用相关系数计算、特征重要性分析、前沿搜索和特征子集筛选相结合的四步特征选择方法,可快速从142 个特征中确认出原子量平均偏差(ADAW)、列平均偏差(ADC)、比体积平均偏差(ADSV)、价电子浓度(VEC)和平均熔点(Tm)5 个描述符作为与铸态高熵合金硬度相关的关键特征[26]。针对难熔高熵合金的硬度预测问题,Li 等[76]将特征重要性和基因的概念引入到遗传算法中作为特征选择方法,改进的遗传算法在精度、稳定性和效率等方面明显优于传统算法。
此外,基于机器学习的特征筛选方法还可用于物理模型的辅助开发。图8 为机器学习辅助构建高熵合金固溶强化模型的具体流程,借助特征工程技术和机器学习建模评估方法可筛选出影响高熵合金固溶强化的关键变量:电负性差(δXr)和剪切模量(G)(图8(a),(b)),并发展了一个基于电负性差的固溶强化模型(Δσss=ξ·Z·G·δXr)用于预测单相高熵合金的强度[85]。如图8(c),(d)所示,该模型与传统的固溶强化模型(S-模型、V-模型、T-模型)相比具有更高的精度,且更简洁易用,并对HfNbTaTiZr 和MoNbTaWV 难熔高熵合金中具有高固溶强化效应的潜在成分区间进行了预测。

图8 基于机器学习的高熵合金固溶强化建模及其应用[85](a)基于相关系数与特征重要性的两步特征筛选法;(b)基于不同机器学习模型的特征筛选;(c)不同固溶强化模型的预测误差对比;(d)机器学习固溶强化模型预测HfNbTaTiZr 和MoNbTaWV 系合金的强化区域Fig.8 ML-based modeling of high-entropy alloys solid solution strengthening (SSS) and its applications[85](a)two-step feature filtering by correlation and importance;(b)feature screening based on ML modeling;(c)comparison of prediction errors between ML algorithms and physics-based models;(d)predicted strengthening regions in HfNbTaTiZr and MoNbTaWV alloy systems based on the proposed ML-SSS model
利用特征工程技术可完成关键特征的快速筛选工作,能有效降低复杂高维数据集的特征维度并保留关键信息,是获得高性能机器学习模型的关键。
3.2 可解释性分析
在机器学习领域中,决策树、逻辑回归等模型具有较强的可解释性,它们能够提供可读性高的规则或者参数,使得用户可以理解模型的决策过程。但更多的机器学习模型(例如神经网络、支持向量机等)具有较为复杂的映射机制属于黑箱模型,一般无法直接评估输入特征在目标量预测过程中的作用,也无法理解输入变量间的相互关系。因此,迫切需要一种对这些已建立的模型进行解释的方法。
对模型的预测结果进行可视化绘图是最直接的分析手段。通过适当的绘图技巧将数据信息转化为图像,可使人们能够更直观地理解和分析数据,对于合金成分设计、强韧化分析等方面具有重要作用。从CoxCryTizMouWv合金的成分-硬度图谱(图9(a))以及特征-硬度图谱(图9(b))中可清晰地看出,合金硬度总体上随着Cr,Mo 含量的增加和W 含量的降低而增加,进而判断出最硬的高熵合金可能具有与Co0.2-0.3Cr0.3-0.5Ti0.05-0.1Mo0.2-0.35W0.05相近的成分,与之对应的最大硬度出现在Tm最低且Ω略小于中值时[73]。
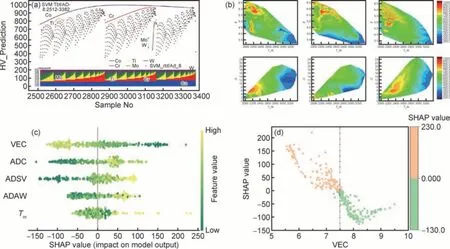
图9 机器学习模型可视化分析(a)CoCrTiMoW 系难熔高熵合金的成分-硬度图谱[73];(b)CoCrTiMoW 系难熔高熵合金的描述符-硬度图谱[73];(c)基于SHAP 方法的特征重要性分析[26];(d)SHAP 值随VEC 特征值的变化关系[26]Fig.9 Visual analysis of ML models(a)composition-hardness correlation map of CoCrTiMoW RHEAs[73];(b)descriptor-hardness correlation map of CoCrTiMoW RHEAs[73];(c)feature importance analysis via SHAP[26];(d)SHAP value changes with VEC[26]
SHAP(Shapley additive explanation)则是一种可用于解释机器学习模型预测结果的算法,该算法基于博弈论中的Shapley 值,可用于评估每个特征对预测结果的贡献,在阐明特征变量和硬度、强度等合金性能的关系方面效果显著。Yang 等[26]利用SHAP 分析了合金硬度的影响因素,结果如图9(c),(d)所示。图9(c)为“蜂群图”,它描述了模型中每个特征的重要性以及特征值对模型输出的影响。其中SHAP 值越正表示该特征有利于提高合金的硬度,而水平覆盖范围越广,则说明该特征对预测结果的影响越大,即该特征越重要。从图9c 中可看出,价电子浓度(VEC)在预测高熵合金硬度方面具有重要作用,而平均熔点对预测结果的影响最小。当VEC 小于7.5 时,对合金硬度有着积极的影响,VEC 越小越有利于获得较高的硬度(图9(d))。而难熔高熵合金的屈服强度也受到测试温度的影响,合金发生高温软化而强度逐渐降低[80]。同时,热力学参数Ω与平均熔点Tm共同影响着合金的综合性能(强度与延展性),当Ω<~15 时对合金屈服强度的提升有明显的积极作用[80],而较低的Tm和较大的Ω值则不利于获得优异的综合性能[30]。
发展机器学习模型解释工具和方法,深入理解材料数据机器学习模型的映射关系,有助于加速机器学习在辅助材料本征机理研究以及合金成分优化设计等方面的应用。
4 机器学习加速难熔高熵合金原子模拟
机器学习除了可以进行难熔高熵合金的相结构、性能预测和辅助强韧化机理分析外,通过学习难熔高熵合金的势函数可以有效加速原子模拟计算。原子间势是用于描述势能与原子位置相关性的函数,在高熵合金的研究中,分子动力学模拟可以模拟原子间相互作用力的变化,从而计算出材料的热力学和力学性质。但由于高熵合金具有多种元素和复杂的微观结构,需在模拟中考虑大量的原子及其相互作用,计算复杂度很高。传统的原子间相互作用势计算方法包括Lennard-Jones 势、嵌入原子法和反应力场[86]等。与这些传统的势函数相比,机器学习势函数采用灵活而非固定的函数形式,通过输入原子的坐标、速度、能量等信息,模型可直接预测原子的势能值。其次,机器学习势能模型使用由第一性原理方法计算所得的数据集进行训练、验证和测试,高质量的机器学习势可接近量子力学方法计算的精度,并且能够描述复杂的合金体系[86]。如图10 所示,常用的机器学习势包括神经网络势(neural network potential,NNP)[87]、高斯近似势(Gaussian approximation potential,GAP)[88]、谱近邻分析势(spectral neighbor analysis potential,SNAP)[89]和矩张量势(moment tensor potential,MTP)[31,90-93]、低秩势(low-rank interatomic potential,LRP)[94-95]等,结合蒙特卡洛模拟(monte-carlo simulations,MC)、分子动力学模拟(molecular-dynamics simulations,MD)等方法,可实现合金有序无序相变、位错演变、应力应变曲线等热力学和力学性质的高效模拟计算,有效地加速难熔高熵合金的相结构预测、位错能量计算以及合金性能的研究[86]。
表3[87-97]总结了机器学习在难熔高熵合金原子模拟中的应用实例,以LPR,MTP 等为代表的机器学习原子势在合金相结构模拟、位错计算、性能分析等方面得到了广泛的应用。研究表明:难熔高熵合金优异的力学性能与合金中各元素有序-无序的复杂相变有关,对合金中有序-无序转变进行模拟预测可为研究难熔高熵合金的性能提供重要的指导。Liu 等[96-97]在利用机器学习计算合金比热和短程序参数时发现MoNbTaW 的有序-无序转变温度远低于MoNbTaVW。因此,预计在1000~2000 K 范围内,MoNbTaW 主要为固溶体,而MoNbTaVW 中应该含有大量的析出相。实验结果证实了预测的可靠性,且在该温度范围内MoNbTaW 具有更高的韧性[96-97]。而在进一步的研究中,Kostituchenko 等[95]利用LPR 机器学习势模型与弛豫结构中的晶格畸变效应,发现晶格弛豫对于稳定MoNbTaW 固溶体结构起到了重要作用。而且合金中的有序析出相也与部分元素较强的位置偏好性有关[94]。
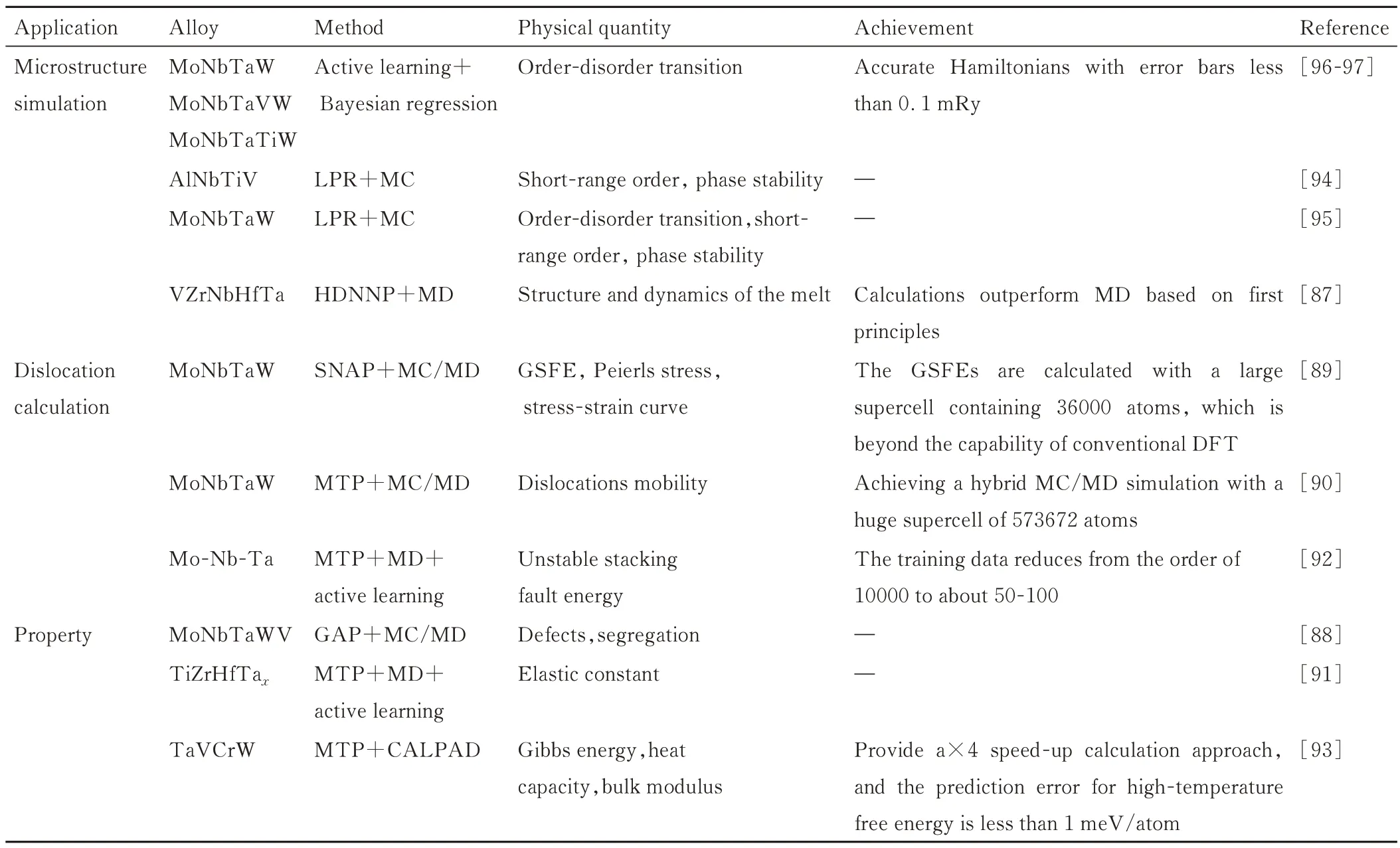
表3 机器学习在难熔高熵合金原子模拟中的应用总结Table 3 Summary of ML applications in atomistic simulations of RHEAs
利用高效、高质量的机器学习势能模型,有助于提高难熔高熵合金模拟的规模和速度,进而从原子尺度深入理解难熔高熵合金相结构演化规律以及性能调控机理。广义层错能(GSFE)是描述塑性变形行为的关键量,它决定了位错的核心结构和位错运动开始所需的最小应力,即Peierls 应力,而不同的位错运动情况会对合金的强度和延展性产生显著的影响。一般来说,不同类型的位错模拟对原子数目的要求不同,对于三维的体位错(如螺型位错或堆垛层错),可能需要包含数千到数万个原子的大型原胞,原子数量大的模拟结果准确性和可靠性更高。考虑到计算的复杂性和计算成本的要求,传统的第一性原理计算可满足包含5000~10000 个原子的模拟。但在对MoNbTaW 难熔高熵合金的研究过程中,基于SNAP 模型的MC/MD 混合模拟可在一个包含36000 个原子的大型原胞中对GSFEs 进行计算[89],而基于MTP 势的MC/MD混合模拟甚至能在一个包含573672 个原子的超大原胞中研究短程有序对位错迁移率的影响[90]。结果证明,利用机器学习模型所获得的原子间作用势与第一性原理计算的结果精度相当一致,但所消耗的计算资源更低,特别是对于成分复杂的难熔高熵合金,有利于将更多的计算资源用于更大规模的原子模拟中。
5 结束语
以数据驱动的机器学习驱动难熔高熵合金设计方法,能有效地减少材料设计与开发的时间和成本,真正实现高性能难熔高熵合金的高效设计。本文从以下四个方面对机器学习驱动难熔高熵合金设计的研究成果进行了详细的综述,包括:(1)机器学习模型结合经验参数与先进算法可实现难熔高熵合金相结构和晶体结构精准设计;(2)机器学习回归模型对难熔高熵合金弹性性能、硬度、强度等进行预测,为高性能难熔高熵合金成分设计提供指导;(3)利用机器学习算法实现关键特征提取,探索不同物理参数对难熔高熵合金性能的影响,深入理解合金强化机理;(4)基于机器学习算法的原子间势能模型,可加速原子势能函数计算效率,实现合金有序无序相变、位错演变、弹性常数等热力学和力学性质的高效模拟计算。
机器学习为难熔高熵合金的研发开辟了新道路,但目前大部分实验数据存在着多源异构、残缺不全和格式不统一等问题,严重限制了机器学习的广泛应用。而现阶段所探索的难熔高熵合金在室温下多以脆性断裂为主,暂未有高强度高拉伸塑性合金体系的相关报道。同时,难熔高熵合金大量的高密度元素(如W,Ta,Mo 等)导致合金具有较高的密度,如:WNbMoTaV 和TiZrHfNbTa 难熔高熵合金的密度分别为12.36 g/cm3和9.94 g/cm3,远高于一般的铁基和镍基高温合金,严重限制了难熔高熵合金在各领域的应用。为此,未来可从以下三方面来实现高性能难熔高熵合金的高效设计与开发。
(1)整合多来源数据,构建高质量数据集。机器学习模型的预测精度与数据质量息息相关,高质量数据集利于模型更好地学习数据特征和模式,从而提高模型的准确性和泛化能力。因此,利用人工智能、机器学习、数据库等数据分析和管理手段,开发出高效的数据处理系统,对实验、CALPHAD 或DFT 计算、动力学模拟等多来源的数据进行评估、清洗、集成、储存和维护,是实现高性能难熔高熵合金设计的基础。
(2)采用集成计算方法构建“成分-工艺-组织-性能”定量化关系模型,指导合金的高效设计。利用机器学习高效的建模分析,可快速构建出难熔高熵合金“成分-组织”或“成分-性能”之间的定量化关系。基于CALPHAD 数据库的热力学计算和先进的多尺度计算技术,可实现难熔高熵合金成分和热处理工艺的设计。此外,相场模拟也可以用来模拟难熔高熵合金在制备和使用过程中微观结构的演变,进一步将相场模型与精准的CALPHAD 数据库结合起来,有助于实现微观结构演变的定量化模拟。因此,通过集成计算热力学、计算动力学、相场模拟、机器学习和高质量实验数据集,有望实现难熔高熵合金“成分-工艺-组织-性能”定量化关系的构建,进而指导高性能难熔高熵合金的设计。
(3)结合多目标优化策略,实现具有优异综合性能的新型难熔高熵合金的设计。传统难熔高熵合金密度较高,且当前的难熔高熵合金设计方面多以提升合金硬度、强度等单一性能为主,难以满足复杂环境下的实际应用需求。因此,亟需开发出新型高综合性能的难熔高熵合金。一方面,在传统难熔高熵合金的基础上引入大量的Al,Ti,V,Zr 等低密度元素,所形成的新型轻质难熔高熵合金既保留了优异的室温和高温力学性能,又使得密度大幅度降低(5~7 g/cm3)。另一方面,基于建立的“成分-工艺-组织-性能”的定量化关系,结合逐层筛选、多目标转单目标、Pareto 前沿优化等多目标优化策略,通过选择低密度、可制造性好、高强度、高韧性、优良的抗氧化性和抗腐蚀、抗磨性等作为目标,有望实现高性能难熔高熵合金的多目标设计。
猜你喜欢
黄河之声(2022年10期)2022-09-27
环球时报(2022-07-13)2022-07-13
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
环球时报(2022-03-14)2022-03-14
粉末冶金技术(2021年3期)2021-07-28
电影(2018年8期)2018-09-21
中国有色金属学报(2018年2期)2018-03-26
中学生数理化·八年级物理人教版(2017年11期)2017-04-18
焊接(2016年8期)2016-02-27
