
基于PCA-GA-BP 神经网络模型对安徽省物流需求量预测
2024-01-25 05:16:28聂轶文
阜阳师范大学学报(自然科学版) 2023年4期
聂轶文,王 韡
(1.阜阳师范大学 信息工程学院,安徽 阜阳 236037;2.安徽电信合肥分公司,安徽 合肥 230031)
0 引言
《安徽省“十四五”物流业发展规划》提到,到2025 年,安徽省物流业关键发展指标将会显著提升,物流设施服务能力大幅改善,“三横四纵多辐”运输通道更加便捷,物流枢纽功能更加完善,物流设施网络更加均衡[1]。新增省级示范物流园区30家左右,创建国家骨干冷链物流基地3-4 个、国家物流枢纽5 个左右。重点物流领域持续增强。供应链稳定性和竞争力不断提高,冷链物流、邮政快递效率和品质大幅改善,航空物流、高铁物流以及新业态新模式快速发展,储备适度、反应迅速、抗冲击能力强的应急物流体系基本建成[2]。
安徽省在加快建设物流强省的过程中,主要有三个抓手:提质增效降本、完善物流网络布局、提高物流智慧化水平。其中物流需求量预测是科学布局物流网络的基础,是有效平衡物流业供需发展的重要依据。区域物流需求系统是非线性变化系统,受到的影响因素多,且中长期预测往往偏差较大,因此在合理选择指标变量,采用更有效的预测方法显得尤为重要[3]。
吕靖[4]从区域经济发展水平、供给水平、冷链物流服务水平三个维度构建了指标体系,并提出了一种基于和BP 神经网络的组合预测模型。王晓平[5]等人从供给、经济发展、冷链水平、人文发展、物流需求五个维度构建指标体系,构造了农产品冷链物流需求的GA-BP 神经网络预测模型,并以北京为实例进行了实证分析,取得了不错的效果。孙启鹏[6]等人认为物流需求是一种派生需求,在理论上建立预测模型是可行的,从市场价格及市场支付能力、物流基本功能要素和物流发生源三个方面对物流量进行了定量描述,并构建了指标体系。
GUO Hongpeng[7]等人建立了三个隐藏层的MLP 神经网络模型,以山西省工业物流需求进行了实例验证,取得了不错的预测效果。QU Licheng[8]等人利用多层监督学习算法训练预测器,以西雅图短期交通流量数据进行训练和预测,预测精度优于传统的一些预测方法。黄建华[9]等人提出了改进GM-BPNN 组合预测方法,利用差分移动平均自回归模型和遗传算法改进模型,以浙江、广东、江苏进行实例验证,提高了物流需求预测的精确度。陆文星[10]等人提出改进后的PSOBP 方法,利用粒子迭代周期増加位置扰动,对粒子群算法进行改进。将改进后的PAPSO 算法对BP 神经网络的初始权值和阈值进行优化,有效的提升了预测精度。冉茂亮[11]等人考虑到数据的非平稳性、强随机性、非线性等特征,利用集成经验模态分解(EEMD)、局部均值分解(LMD)、长短期记忆网络(LSTM)以及局部误差校正(LEC)方法,提出用于短时物流需求预测的EEMD-LMDLSTM-LEC 深度学习模型,取得了不错的预测效果。
这些学者从不同的角度,采用不同的方法进行了预测,都取得了不错的预测效果。但是区域物流需求的影响因素很复杂,物流需求预测指标变量的选取没有统一的标准,每一变量之间或多或少存在重叠、相关的关系。变量太多会增加问题的复杂性,一般希望在分析的过程中涉及的变量尽可能少,而包含的信息量尽可能多。因此利用主成分分析法,降低模型输入维数,提取出物流需求特性的主成分。本文尝试选择更多的指标,利用PCA 进行降维处理,尽量提取出影响物流需求量的关键信息,以求构建的模型预测更加可靠。
1 预测模型的建立
1.1 主成分分析法
主成分分析法(PrincipalComponentsAnalysis,简称PCA)是一种常用的降维方法,将多指标转化为少数几个综合指标(主成分),提取出的新的主成分是原指标变量的一组线性组合,这些主成分通过方差依次递减的顺序进行排列,其中具有最大的方差,称为第一主成分,次大的方差变量为第二主成分,依次类推,n 个变量就有n 个主成分[12]。
设观测到m 组n 维的数据样本矩阵为:
(1)计算维度上的相关系数矩阵。
(2)解特征方程|λI-R|=0,求出特征值λi与特征向量ei。
(3)计算累积贡献率。
特征值描述的就是对应主成分方向上的方差,通过计算累积贡献率达到85%以上的特征值λ1,λ2,…,λp,就可以提取出前p 个主成分。
(4)提取主成分Fi。
式中:Fi表示第i个主成分。
1.2 遗传算法优化的BP 神经网络的建立
(1)隐含层神经元数量k
根据柯尔莫哥洛夫定理可知可以确定隐含层神经元的个数k,
ninput、noutput分别为为输入层和输出层数目,a取值为1-10 之间[13]。
(2)传递函数、学习率等网络参数的设定
Sigmoid 函数基本上都能实现非线性输出,这里隐含层传递函数选择tansig 函数和输出层采用purelin 线性函数[14]。
BP 神经网络不断优化的本质就是将每次输出结果与期望输出进行比较,不断的进行反向传播调节对权值和阈值更新,而调整方法就是梯度下降法。学习率η决定了下降的步长ηdf(x)/dx,步长太大就可能会出现震荡,结果无法收敛。
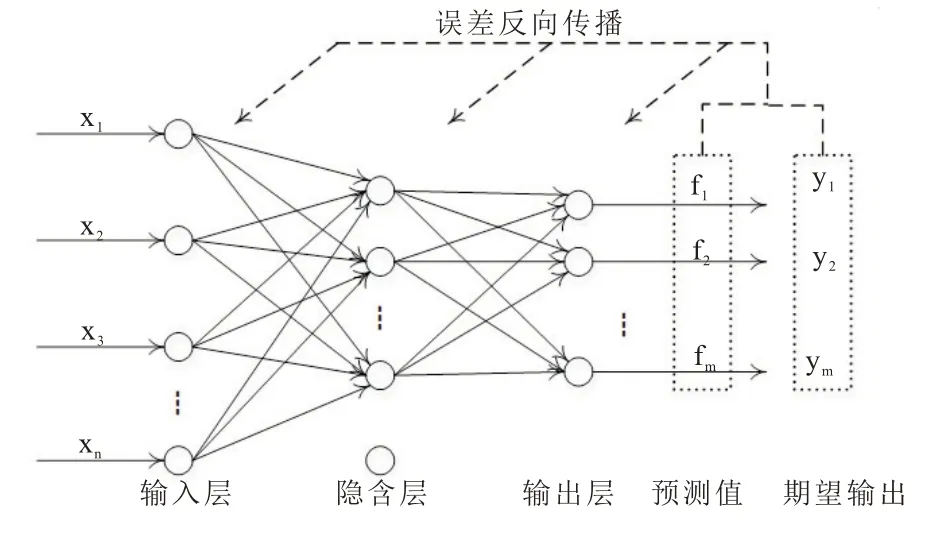
图1 BP 神经网络拓扑结构
GA-BP 神经网络的基本思想是:在利用BP神经网络进行预测时,一般会随机初始化权值和阈值,但拟合结果不是很理想。这里利用遗传算法的全局寻优能力和快速收敛速度的优点,可以获得比较好的初始权值和阈值。然后将优化后的权值和阈值输入BP 神经网络,达到预定训练次数或目标精度则终止训练并输出结果[15]。遗传算法优化BP 神经网络算法的流程如图2 所示。

图2 GA-BP 神经网络流程图
2 安徽省物流货需求量预测
2.1 数据收集
在区域物流需求量预测前,首先需要进行数据收集和处理。本文数据来源主要出自《安徽省统计年鉴》、《中国统计年鉴》、《安徽省国民经济和社会发展统计公报》等相关网站,因普查数据修订、统计指标的修订等原因,个别指标在不同年份会略有差别,因此,本文所有数据均是采用截止至2021 年的核算数。
货运量:指在一定时期内,各种运输工具实际运送的货物(旅客)数量。它是反映运输业为国民经济和人民生活服务的数量指标,也是制定和检查运输生产计划、研究运输发展规模和速度的重要指标[16]。
能源生产/消费总量:其中包含煤炭和电力的生产/消费[17],煤炭换算为电力的生产和消费,换算标准为1 kg 标准煤=8.141 千瓦时。
陆路交通长度:该指标是公路交通和铁路交通总运营里程之和[18]。

表1 (a)2000-2019年安徽省货运量及其影响因素
2.2 主成分分析法提取主成分
因原始数据指标过多,利用SPSS 软件中的因子分析方法对原始数据提取主成分进行降维,各指标量纲差距较大,这里采用相关系数进行提取,为了更好的对提取出的主成分进行解释,采用最大方差法对初始因子载荷矩阵进行旋转[19]。
经检验,KMO 系数为0.79,Bartlet 球形度检验显著性系数p 远小于0.05,故适合进行因子分析。基于特征值大于1 提取的各成分累积载荷比如表2 所示。
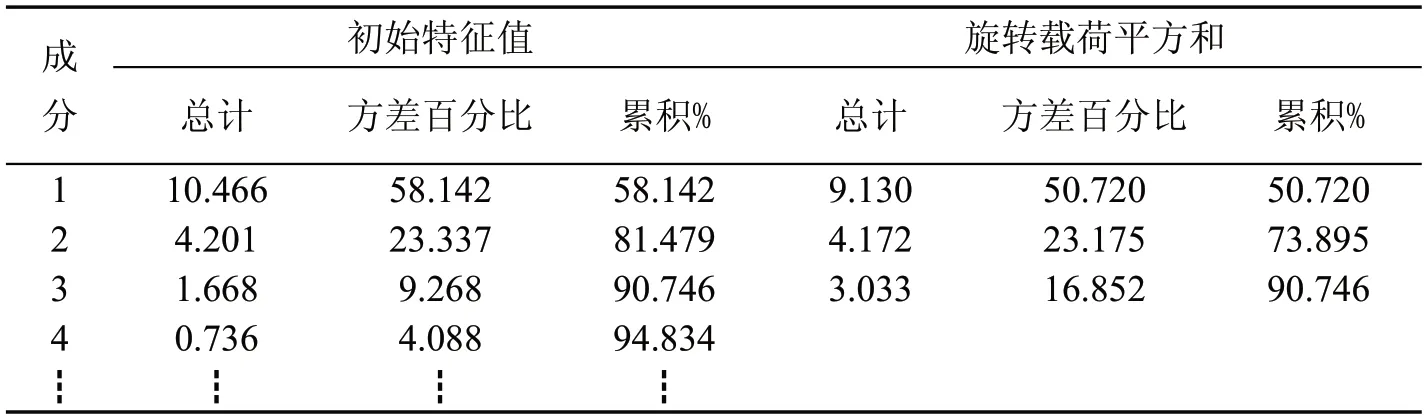
表2 基于特征值提取出的主成分
从上表可以看出,提取出了3 个主成分,各主成分的表达式如下:
转换得各主成分得分见表3。
2.3 初始权值和阈值进行优化
这里设置进化代数为100 次,种群规模为50。交叉概率和变异概率进行多次测试比较,选择更优者。
如图3 所示,通过多次寻优,种群进化100代,平均均方误差为0.112 9,最佳均方误差为0.000 4,BP 模型获得比较好的初始权值和阈值。
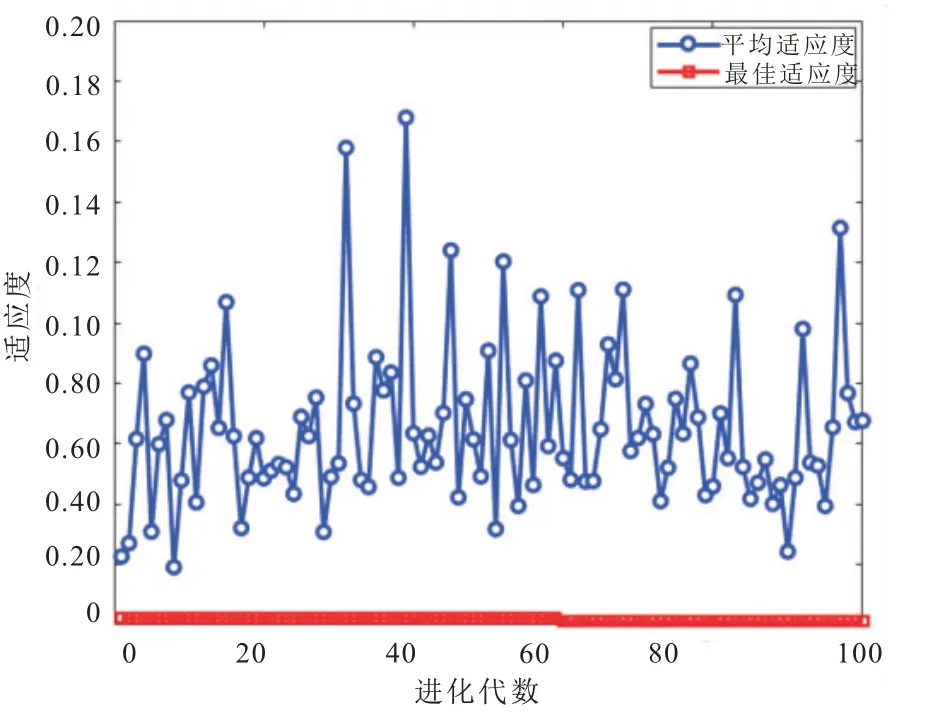
图3 遗传算法优化后的适应度
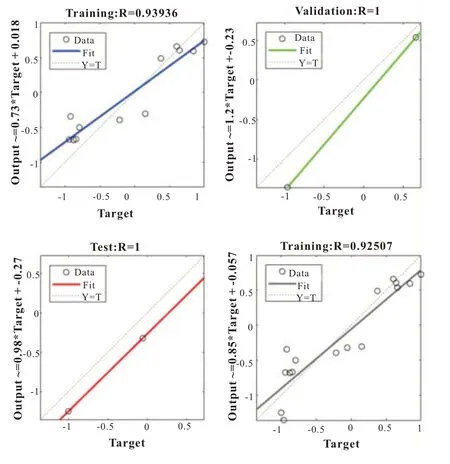
图4 货运量预测各实验数据相关系数
其中,W10、B10为分别为隐含层到输入层的权值和阈值,W20、B20分别为输出层到隐含层的权值和阈值。
2.4 GA-BP 模型预测
将遗传算法寻优得出的初始权值和阈值输入模型进行训练和测试,训练目标误差为0.001,经过多次调试学习率设置为0.01,隐含层神经元数目为5[20]。
从图中4 可以看到,训练集、验证集、测试集和总体相关系数分别为0.93936、1、1、0.92507,表明训练好的BP-GA 模型很好。
因2009 年陆路货运量抽样调查方法进行了调整,从图5 也可以看出2009 年真实货运量出现了较大的跳跃,从而把测试集和整体平均绝对百分比误差水平拉高。剔除异常值后重新进行计算,如图6 所示。

图5 货运量预测结果
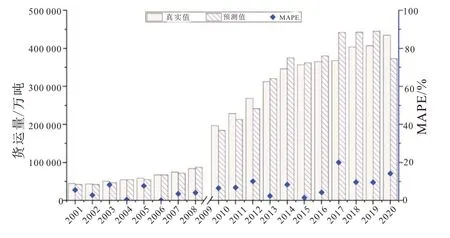
图6 剔除异常值后的货运量预测结果
剔除异常值(2009 年)后的平均绝对百分比误差,训练集的平均绝对百分比误差为6.38%,4 组测试集的平均绝对百分比误差为7.78%,总体平均绝对百分比误差为6.6%。通过结果可知本文构建的GA-BP 神经网络应用于物流量预测的精度基本满足实际要求,预测结果较为理想。
3 结论
通过对安徽省物流需求量预测的实例验证,可以得出如下结论:(1)本文中选择的18 个原始经济发展指标数据利用主成分分析对数据进行降维处理后,提取出的主成分仍然包含了原始数据的绝大部分信息,没有造成原始数据的失真,而模型训练速度却得到了大幅提升。(2)在样本量较少的情况下,本文构建的GA-BP 神经网络取得了不错的预测精度,同时因为样本数量较少,也会对一些异常值更为敏感,导致预测结果出现较大的波动,因此需要分析这些异常值产生的原因,适当的剔除这些异常值。(3)初始权值、阈值的设定对BP神经网络预测结果的好坏会有很大的影响,本文利用遗传算法的优点快速找到局部最优解,从而得到初始参数,并获得了不错的预测结果。本文中的学习率等网络参数是通过不断调试来设定的,这些参数会影响到模型的训练效率和结果。在以后的探究中可以考虑通过一种动态调整的方法来调整这些超参数,从而获得更快的训练速度和更好的预测精度。另外2020 年因为疫情的影响,各项经济指标波动较大,故本文数据只取用了2020 年以前的数据,而对于突发事件条件下的物流需求预测是继续努力研究的方向。
猜你喜欢
成都信息工程大学学报(2022年3期)2022-07-21 09:35:04
沈阳师范大学学报(教育科学版)(2021年2期)2021-02-01 07:00:46
沈阳师范大学学报(教育科学版)(2021年2期)2021-02-01 07:00:46
制造技术与机床(2019年9期)2019-09-10 07:36:54
西南交通大学学报(2018年6期)2018-12-18 02:22:28
石油地球物理勘探(2017年2期)2017-11-23 06:02:04
河北遥感(2017年2期)2017-08-07 14:49:00
中央民族大学学报(自然科学版)(2017年1期)2017-06-11 07:13:32
自动化学报(2017年7期)2017-04-18 13:41:02
统计与决策(2017年2期)2017-03-20 15:25:24
