
基于卷积神经网络的多尺度特征融合去噪算法∗
2024-01-23 13:38郭业才
计算机与数字工程 2023年10期
许 雪 郭业才 李 晨
(1.南京信息工程大学电子与信息工程学院 南京 210044)(2.无锡学院电子信息学院 无锡 214105)
1 引言
图像去噪是计算机视觉中的一项重要工作,在图像采集过程中,由于成像环境和设备的限制,噪声常常是不可避免的。因此,去除噪声是必不可少的一步,不仅对视觉质量,而且对其他计算机视觉任务也是如此。传统的去噪方法有利用自然图像的先验信息进行图像去噪[1~2],应用优化算法迭代求解模型[3~4]也被众多学者提出。然而,这些方法耗时较长,不能有效去除噪声。随着深度学习的兴起,卷积神经网络(CNN)被应用于图像去噪任务,并取得了高质量的效果,比如DnCNN[5]、FFDNet[6]、IRCNN[7]等算法。另一方面,早期的研究噪声假设是独立、均匀分布的,加性高斯白噪声(Additive White Gaussian Noise,AWGN)是一种常用的合成噪声,人们现在意识到,噪声以更复杂的形式呈现,它们具有空间变异和信道依赖性。因此,最近的一些工作在真实图像去噪方面取得了进展,XU 等提出的GIDNet[8]提出一种外部先验引导内部先验学习的方法;Zhou 等提出的PD[9]去噪网络,仅使用与合成像素无关的噪声数据进行训练,训练出的模型可以适应真实噪声;CBDNet[10]中作者根据图像处理芯片ISP 的工作原理和异方差高斯噪声提出了一种噪声模型。
但仍有一些问题有待解决,部分网络对真实噪声进行去噪任务后,得到的图像中仍有大量噪声残留,或者存在去噪后的图像过于平滑,细节丢失严重等问题,依旧得不到较好的视觉效果。从以往的研究中发现,多尺度的特征提取和融合可以改善以上问题,所以本文提出一种基于卷积神经网络的多尺度特征融合去噪算法,渐进式的训练分层融合的特征,跨尺度的捕获特征之间的联系,还将具有空洞卷积的U-Net[11]加入每一个分层之中,扩大感受野,且不增加额外的参数,减少了图像细节的丢失和不必要的计算成本。
2 网络设计
通过对文献[12]和文献[13]的学习,本文提出的算法结构主要由密集残差块DCR 和具有空洞卷积的D-UNet 组成,算法结构如图1 所示。噪声图像xi作为网络输入,去噪后的干净图像yi作为网络的输出,Conv卷积核大小为3×3,输入噪声图像xi经过池化操作得到4 个大小不同的分层,分别是256×256、128×128、64×64 和32×32,表示为(a=1,2,3,4),为第1层的输入,经过卷积层之后得到浅层特征(a=1,2,3,4),为第1 层的浅层特征,再依次经过DCR 块与D-UNet 后得到第1 个分层特征,第1 个分层特征经过上采样Upsampling后得到F1,表示为
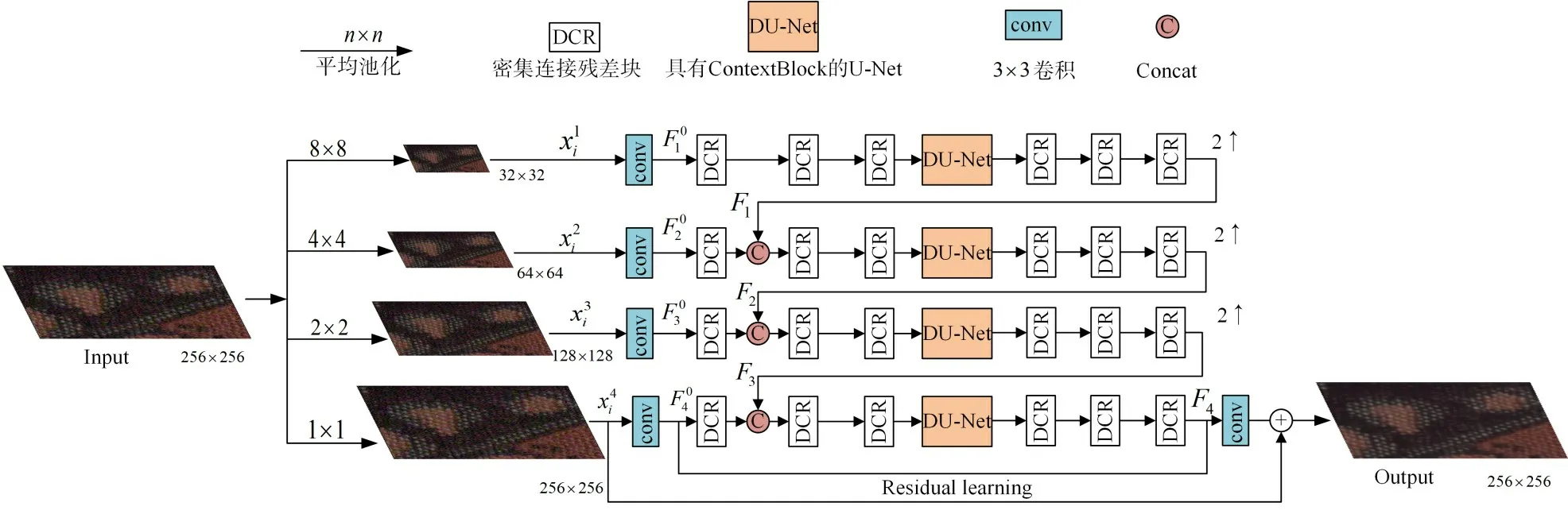
图1 本文算法结构图
其中HDCR表示DCR 块的复合函数操作,HD-UNet表示D-UNet的复合函数操作。
此时F1特征图大小与第2 层的特征图大小一样,将F1融合到第2个分层中得到,这样设计可以跨尺度的捕获特征之间的联系,充分利用先前的特征。
则第2个分层特征F2可以表示为
其中HDCR,2表示D-UNet 前面未被使用过得2 个DCR块操作。
以此类推出F3,在第4 分层中,所有的DCR 块操作结束之后,当前特征与进行第一次残差学习得到特征F4,再与网络输入的噪声图像xi进行双残差学习得到最终的输出结果yi。两次残差学习避免了梯度消失问题,两次残差学习之间的卷积层增强了第一次残差学习后的特征。
2.1 DCR
DCR块是密集连接残差块,在本文的算法中主要提取池化后每一分层的特征,每两个卷积层组成一个DCR 块,可充分提取层次空间特征,每一个特征图之间密集连接起来,不仅保留了先前的特征还保存了局部密集特征,其中局部特征融合LFF可以减少特征数量,局部残差学习LRL提高网络表达能力和性能,DCR块内部结构如图2所示。
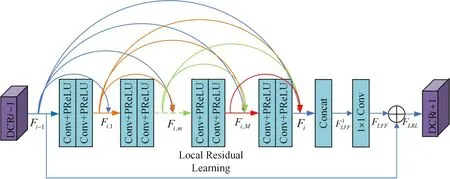
图2 DCR块内部结构
由图2可知,Fi-1和Fi作为第i个DCR模块的输入和输出,其中第i个DCR模块的第m个卷积层的输出可以表示为
其中,σ表示激活函数,Wi,m表示第m个卷积层的权重。
无需BN和池化,每两个卷积层组成一个块,再将前面各块的输出和当前块的输出连接起来一起作为下一个块的输入,其中每个卷积层后面只有一个PReLU,更有利于特征的保留,用局部融合特征融合前面的DCR 块和当前DCR 块中的卷积层,将第i-1 个DCR 的特征直接连接到第i个DCR 上,局部融合特征描述为
其中,M=6,Concat表示特征拼接层。
2.2 D-UNet
D-UNet 的输入为各分层的上一个DCR 块的输出,D-UNet 具有4 层编码结构、4 层解码结构和两个1×1 卷积层,来计算原始输入与最后输出的特征。每个编码层具有两个卷积核大小为3×3 的卷积层用来提取尺度特征,上一个编码层经过2×2的池化层后,数通道数相应扩大2 倍,以减少从一层到另一层的信息丢失。如图3 所示,第一个编码层的通道数为32,第二个编码层的通道数为64。在编码器和解码器之间的最小尺度中引入空洞卷积块,在不改变分辨率的情况下进一步增加感受野。
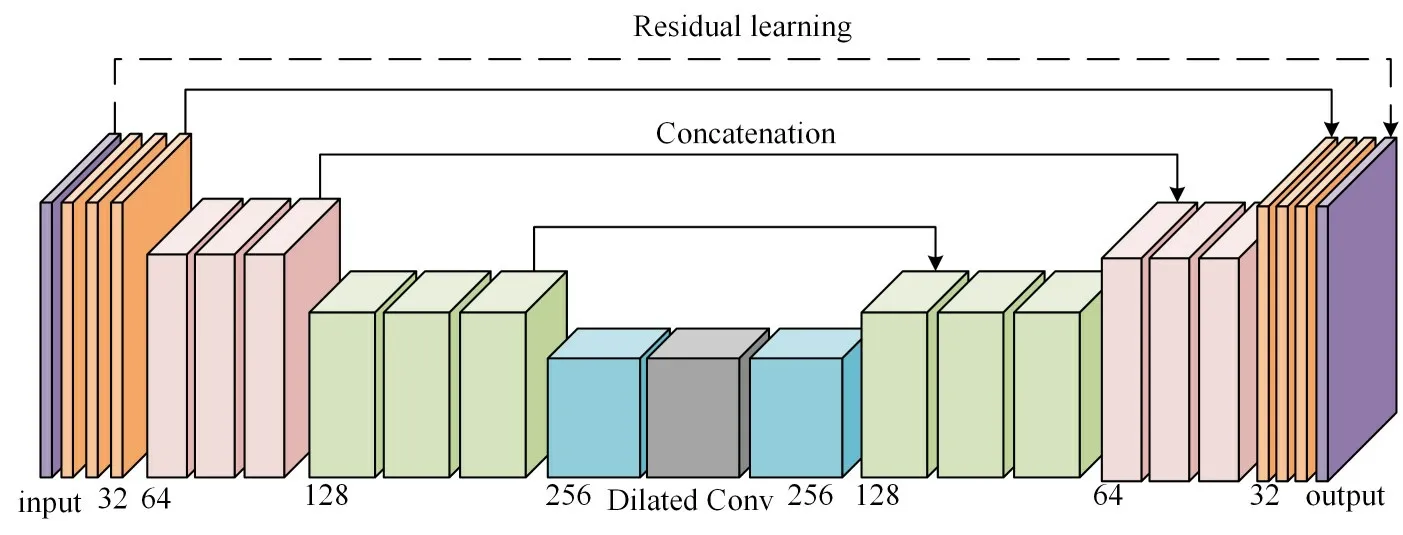
图3 D-UNet内部结构
每个解码层具有两个卷积层,与编码器的卷积层一样,卷积核大小为3×3。每两个解码层中间有一个上采样因子为2 的卷积层,每次上采样之后通道数相应缩小2 倍。如图3 所示,第一个解码层的通道数为256,第二个解码层的通道数为128。为了进一步防止信息丢失,解码层同时与对应特征图大小一样的编码层相连接,也充分利用了先前的特征信息。最后通过1×1 层卷积得到DU-Net 的输出,除了该层卷积之外,其他卷积层的激活函数均为LReLU,该激活函数在不引入大量额外参数的情况下增加了模型的灵活性。
多尺度信息对于图像去噪任务非常重要。因此,网络中经常采用下采样操作。但是当空间分辨率太小时,图像结构被破坏,信息丢失,不利于特征的重建。为了在不进一步降低空间分辨率的情况下增加感受野并捕获多尺度信息,本文设置在编码器和解码器之间的最小尺度中引入空洞卷积块。与空间金字塔池化[14]相反,空洞卷积块使用具有不同膨胀率的几个膨胀卷积,而不是下采样。如图4所示,它可以在不增加参数数量或不损坏结构的情况下扩大感受野。然后将不同感受野提取的特征进行融合,四个扩张率分别设置为1、2、3 和4。为了进一步简化操作并减少运行时间,首先使用1×1卷积来压缩特征通道。压缩比设置为4。在融合设置中,采用1×1 卷积使输出通道数与原始输入特征的通道数大小相等,并在输入和输出特征之间采用局部残差连接以防止信息阻塞。

图4 Dilated Conv内部结构图
本文采用l1损失函数,给定一批训练图像对的数量为N,即,目标是使经过网络后的去噪图像与原始干净图像更为接近,l1损失函数表示为
其中,xi是输入的噪声图像,yi是原始干净图像,W表示所有参数的集合。
3 实验结果与分析
3.1 数据集与参数设置
使用SIDD[15]数据集进行真实噪声图像去噪模型训练,该数据集的训练集包含200 对干净图像和噪声图像,将其随意分割成256×256 的图像块,得到48000 对图像用于网络训练,验证集1280 张图像。总共进行4000 次迭代,学习速率最初设置为10-4,2000 次迭代之后,每过500 次迭代将学习速率减半进行微调。采用β1=0.9,β2=0.999 的Adam[16]优化器对模型进行优化。在真实噪声图像数据集SIDD、DND[17]和NC12[18]进行测试。NC12 包括12 幅噪声图像,真实干净的图像无法获取,本文只提供其去噪结果图进行视觉比较。
该网络在Python3.6,Pytorch[19]1.7.1 框架中实现,并用英伟达GeForce GTX 1080 Ti进行训练。本文采用峰值信噪比PSNR(Peak Signal to Noise Ratio)和结构相似性SSIM(Structural Similarity)[20]对改进后算法的去噪结果进行分析。
3.2 实验结果
为了验证提出算法在真实噪声图像上的去噪效果,将其与BM3D[21]、FFDNet[6]、NC[18]、CBDNet[10]和PD[9]和AINDNet[22]卷积神经网络去噪算法进行对比实验,本文在SIDD、DND 和NC12 三个真实数据集上进行可视化结果对比,图5、图6 和图7 分别为以上对比算法与本文提出算法的去噪结果图。

图5 在数据集DND上的去噪结果对比

图6 在数据集SIDD上的去噪结果对比

图7 在数据集NC12上的去噪结果对比
各个算法在DND 和SIDD 数据集上的去噪效果如图5 和图6 所示,BM3D、NC、CBDNet 和PD 算法去噪后的图像中仍有或多或少的噪声残留。如图7 所示,FFDNet 在SIDD 数据集上的表现过于平滑,细节丢失严重,AINDNet 在对噪声进行处理时会腐蚀边缘,产生伪影。而本文的算法可以有效地去除平滑区域的噪声,保留清晰的细节。图8 为智能手机拍摄的夜晚图片,智能手机相比专业相机来说,在成像时会产生更多的噪声,可以看出,BM3D与FFDNet 算法的结果图中细节模糊,其他算法都有噪声残留,相比较而言,本文算法的去噪效果依旧优于对比算法。

图8 智能手机拍摄的图像
由于NC12 数据集的干净图像无法获得,所以本文只提供在数据集DND 和SIDD 上的PSNR 和SSIM值。如表1所示,选取的对比算法既有传统去噪算法,又有近几年基于深度学习的优秀算法,所有对比算法的PSNR 和SSIM 值都从数据集的官方网站上获得,可以看出本文算法的评价指标值均高于对比算法。
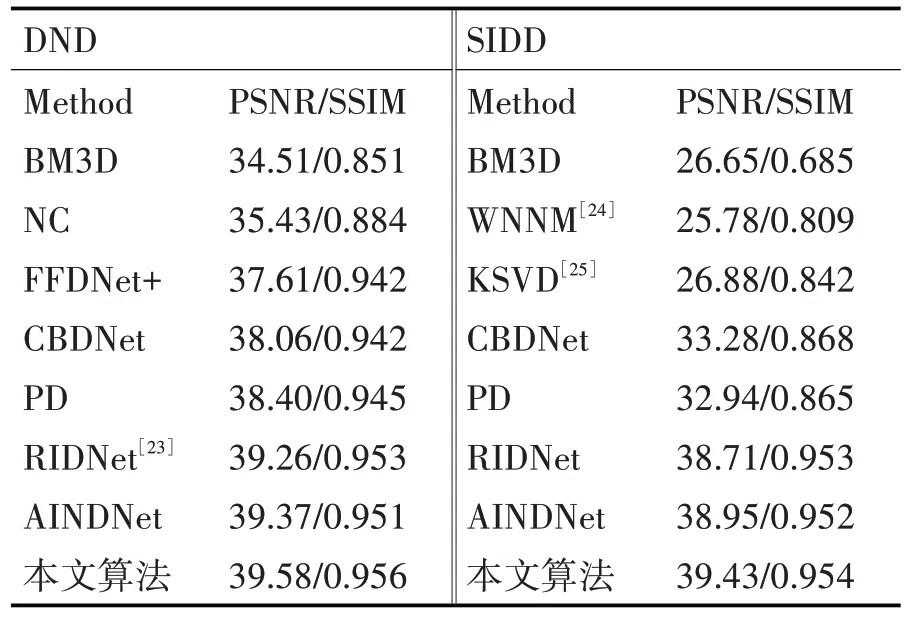
表1 各种算法在DND和SIDD数据集上的PSNR/dB和SSIM值对比
4 结语
本文提出了一种基于卷积神经网络的多尺度特征融合去噪算法,该算法首先对输入使用池化操作得到分层,经过密集连接残差块DCR 提取分层特征,再利用具有空洞卷积的U-Net对提取到的分层特征进行处理,空洞卷积在不改变图像分辨率的前提下新一步扩大感受野,有助于从先前网络提取的特征中去除噪声,再将分层特征进行上采样后反馈到下一分层中进行渐进训练,灵活的运用图像的全部特征,保留更多的图像细节,得到较好的去噪效果。
猜你喜欢
网络安全与数据管理(2022年3期)2022-05-23
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2020年10期)2020-11-14
内蒙古民族大学学报(社会科学版)(2020年2期)2020-11-06
自动化学报(2019年6期)2019-07-23
电子制作(2019年11期)2019-07-04
北京航空航天大学学报(2018年1期)2018-04-20
太空探索(2016年5期)2016-07-12
河南科技(2015年8期)2015-03-11
时代英语·高三(2014年5期)2014-08-26
