
基于Ray框架的分布式计算研究
2024-01-23 00:44侯伟
现代信息科技 2023年23期
摘 要:文章旨在通过分布式框架Ray来计算数据量比较大的任务,使得任务能够更加高效地完成。指明了Ray通过两种核心概念实现分布式计算:Actor和Task。通过调用Ray庫中的Remote方法并结合init方法指明CPU数量实现分布式计算。实验分为在相同数据量下不同CPU数量处理数据的快慢以及在不同数据量下不同CPU数量处理数据的能力。实验结果表明,数据量越大、CPU数量越多的分布式计算能力越强。因此,分布式计算适用于大数据下的并行计算。
关键词:分布式计算;Ray框架;Actor;Task;大数据;CPU
中图分类号:TP3-0 文献标识码:A 文章编号:2096-4706(2023)23-0065-04
Research on Distributed Computing Based on Ray Framework
HOU Wei
(School of Information and Control Engineering, Liaoning Petrochemical University, Fushun 113001, China)
Abstract: This paper aims to use the distributed framework Ray to calculate tasks with large amounts of data, enabling tasks to be completed more efficiently. It indicates that Ray implements distributed computing through two core concepts: Actor and Task. By calling the Remote method in the Ray library and combining it with the init method to indicate the number of CPUs, distributed computing is achieved. The experiment is divided into the speed of processing data with different CPU number under the same data volume, and the ability of processing data with different CPU number under different data volumes. The experimental results indicate that the larger the data volume and the more CPUs, the stronger the distributed computing power. Therefore, distributed computing is suitable for parallel computing under big data.
Keywords: Distributed Computing; Ray framework; Actor; Task; Big Data; CPU
0 引 言
随着数据规模的扩大和计算复杂度的增加,单机计算能力已经无法满足大规模数据处理和计算的需求,分布式计算逐渐成为一种重要的数据处理和计算方式。分布式计算是将任务分解成多个子任务,分配到多个计算节点上并行执行[1],从而提高任务的执行速度。
分布式计算有很多优点:
1)高效性。可以利用多个计算节点的计算能力,提高任务的执行速度。
2)可扩展性。可以根据需要动态地增加或减少计算节点,以满足不同规模的数据处理和计算需求。
3)高可用性。任务被分配到多个计算节点上执行,因此即使某个节点出现故障或宕机,任务仍可以在其他节点上继续执行[2]。
分布式框架是一种用于实现分布式计算的软件系统,提供一系列分布式计算的基础设施和工具。分布式框架可以使开发者更加轻松地开发和部署分布式应用程序,同时还可以提高分布式计算的效率和可靠性[3]。
一些著名的分布式框架(如Hadoop、Spark、Flink、Ray等)不仅广泛应用于大数据处理、机器学习、强化学习、自然语言处理等领域,还在各个领域实现了巨大的经济和社会价值。因此,分布式计算和分布式框架在当今信息技术领域具有重要的作用和意义[4]。
1 相关概念
1.1 Actor
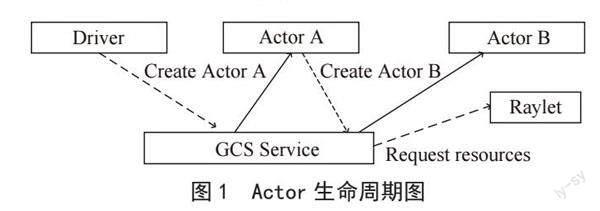
Actor是一种并发执行的状态机,用于实现分布式计算中的状态管理和协调。Actor还是一种轻量级计算单元,可以在不同节点之间传递消息,并且可以动态地创建、销毁和调度。
Actor是Ray框架的基本组件之一,用于解决分布式计算中的状态共享和协作问题[5]。Actor的主要特点包括:
1)状态封装。每个Actor实例都有自己的状态,其他Actor无法直接访问该状态,从而避免了多个Actor之间状态共享的问题[6]。
2)异步执行。Actor方法的执行是异步的,即调用方不需要等待Actor方法的返回结果,从而避免了阻塞和等待。
3)消息传递。Actor之间通过消息传递进行通信,从而实现了分布式计算中的状态共享和协作。
Actor的生命周期图如图1所示。
1.2 Task
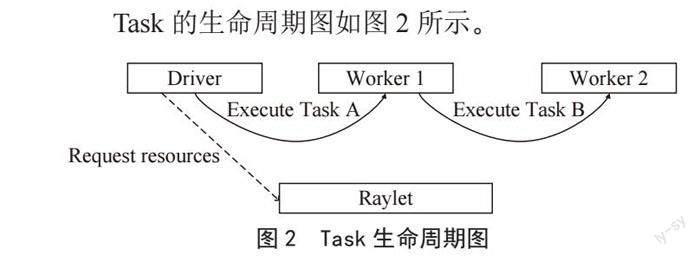
Task是一个独立的计算单元,可以在任何可用的计算资源上运行。Task的执行是无状态的,不依赖于其他任务的状态,因此可以在不同节点之间分配和执行,从而实现了分布式计算。
Ray框架中的Task由调度器分配到可用的计算资源上执行,执行结果通过Ray对象传递给其他Task或Actor。Ray框架提供丰富的Task调度和管理功能(如任务依赖管理、任务优先级管理、资源管理等),用以提高分布式计算的效率和可靠性。
Actor和Task是Ray框架中的两个核心概念,它们共同实现了分布式计算中的状态共享、协作和任务执行。通过使用Actor和Task,开发者可以更加轻松地实现分布式应用程序[7],同时也可以提高分布式计算的效率和可靠性。
Task的生命周期图如图2所示。
2 Ray框架的应用场景和优势
Ray框架可以应用于大数据处理、机器学习、强化学习、自然语言处理等领域的分布式计算任务:
1)大数据处理。Ray框架可以与其他大数据处理框架(如Hadoop、Spark)集成,提高数据处理的效率和可靠性。Ray框架可以通过分布式对象存储(如Amazon S3、Google Cloud Storage)实现数据的高效存储和访问。
2)机器学习。Ray框架可以提供高效的分布式计算与深度学习框架(如TensorFlow、PyTorch)的集成,从而加速模型训练和推理。Ray框架可以提供模型并行化、数据并行化和超参数搜索等功能。
3)强化学习。Ray框架可以提供高效的强化学习框架(如RLlib),从而加快强化学习模型的训练和评估。Ray框架可以提供高效的并行化、分布式经验回放和分布式优化器等功能。
4)自然语言处理。Ray框架可以提供高效的自然语言处理框架(如Hugging Face Transformers),从而加快模型的训练和推理。
总之,Ray框架具有广泛的应用场景,可以用于各种类型的分布式计算任务,从而加速任务的执行速度,提高计算效率和可靠性,降低计算成本[8]。
Ray框架在各种应用场景中具有以下优势:
1)高效的分布式计算。Ray框架支持高效的分布式计算,可以轻松地扩展计算资源,提高任务的执行速度和计算效率。
2)灵活的任务调度。Ray框架提供灵活的任务调度机制,可以根据任务类型和计算资源的状态动态调整任务的执行顺序和分配策略,从而实现计算资源利用率的最大化。
3)高可靠性和容錯性。Ray框架提供高可靠性和容错性机制,可以自动处理资源计算故障和任务异常,保证任务的正确执行和计算结果的可靠性[9]。
4)易用的编程接口。Ray框架提供简单易用的编程接口,支持多种编程语言(如Python、Java、C++等),可以使开发人员轻松编写分布式计算任务。
5)高度可扩展性。Ray框架具有高度可扩展性,可以与其他分布式计算框架(如Hadoop、Spark、Kubernetes等)集成,提供更加完整和强大的分布式计算能力[10]。
总之,Ray框架在各种应用场景中都具有高效、可靠、灵活和易用的优势,可以帮助用户更加轻松地完成分布式计算任务,获得更好的计算性能和效率[11]。
3 Ray实现分布式方法
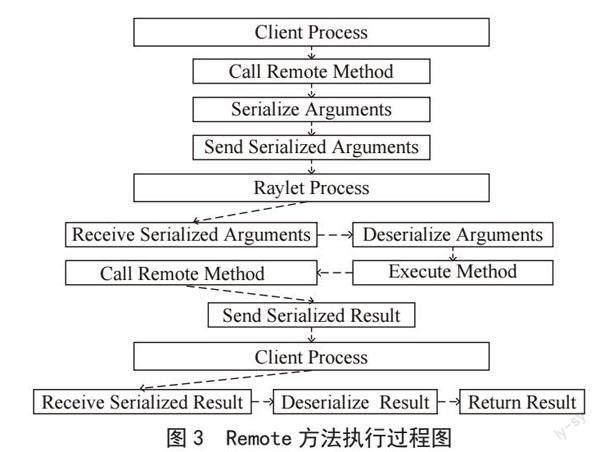
在Ray框架中,Remote方法的执行过程大致如下[12]:
1)当用户调用Remote方法时,Ray会将要执行的函数及其参数打包成一个任务对象。
2)Ray将任务对象发送给一个调度程序,该调度程序会分配一个可用的Ray worker进程,并将任务对象发送给该进程。
3)Ray worker进程在接收到任务对象后会反序列化任务对象,并执行其中包含的函数及参数。
4)如果函数需要其他Ray actor的参与,Ray worker进程会向Ray driver发送一个请求,请求该actor的引用。
5)Ray driver接收到请求后,会将actor的引用发送给请求方的Ray worker进程。
6)Ray worker进程继续执行任务,并在任务完成后将结果发送回调度程序。
7)调度程序接收到结果后,将其序列化并发送回Ray driver。
8)Ray driver将结果返回给用户,并删除该任务对象。
需要注意的是,在执行过程中Ray会自动处理任务的依赖关系和数据流程,以及任务执行的并行性[13]。此外,Ray还提供一些调试工具,帮助用户更好地理解任务的执行过程和调试问题。Ray框架中远程方法执行的简单流程图如图3所示。
首先,客户端进程调用远程方法并将参数序列化。然后,客户端进程将序列化的参数发送到Raylet进程。Raylet进程接收序列化的参数,反序列化参数,执行方法并将结果序列化。Raylet进程将序列化的结果发送回客户端进程。最后,客户端进程接收序列化的结果,反序列化结果,并将结果返回给调用方[14]。
4 实验测试
采用Python工具开展实验,采用随机森林算法对音乐数据进行处理。引入Ray库,然后调用Remote方法进行实验[15]。
为了验证分布式计算在大数据计算中的优势,本文实验由两部分组成。第一部分实验控制数据量不变,看不同CPU数量下并行计算的速度,CPU数量为自变量,整个实验的响应时间为因变量。该实验是在随机森林音乐推荐算法的基础上完成的,该算法的数据量为20 000条音乐音频文件,通过随机森林进行分类。数据来源于百度的飞桨平台。由于20 000条数据量不是很大,我们让该实验轮询四次,相当于计算80 000条数据,然后得到整个实验的计算时间。如图4所示为轮询四次(range=4)得到的duration对比图。
如图5所示,横坐标表示并行计算下CPU内核数,纵坐标表示响应整个任务所花费的时间,以秒为单位。可以看出随着内核数的增加,整个并行计算所花费的时间随之减少。
第二部分实验是为了显现不同数据量下整个并行计算的优点,本文又做了轮询两次实验数据的实验,如图6所示,轮询三次实验数据的实验如图7所示,轮询五次实验数据的实验如图8所示,通过实验组的对比来观察并行计算与数据量之间的关系。
通过如图9所示的各实验组的对照实验可以看出:在大任务量的情况下,增加CPU内核进行并行运算的效果更好,整个时间缩短的幅度更大[16];在小任务量的情况下,整个并行计算的影响效果不明显。因此,在海量数据的互联网背景下,我们应该充分考虑分布式计算的必要性[17]。
5 结 论
Ray框架在分布式计算领域具有很高的影响力,未来的发展方向主要集中在以下几个方面:
1)模型优化和自动调参。Ray框架在机器学习、强化学习等领域应用广泛,未来将进一步深化这些领域的研究,通过模型优化和自动调参等技术提高模型的性能和可靠性。
2)低延迟计算和实时处理。Ray框架在大数据处理、自然语言处理等领域也有广泛的应用,未来将进一步加强对低延迟计算和实时处理的研究,提高计算效率和实时性能。
3)更好的资源管理和调度。Ray框架的资源管理和调度机制已经非常灵活和高效,未来将进一步深化和完善这些机制,提高资源利用率和任务执行效率。
4)更加易用的编程接口和工具支持。Ray框架在易用性方面已经取得了很大的进步,未来将加强对编程接口和工具的支持,提供更加友好和易用的分布式计算环境。
总之,Ray框架未来的发展方向主要集中在提高计算性能和效率、深化领域支持和加强易用性等方面,进一步推动分布式计算技术的发展和应用。
参考文献:
[1] 李梓杨.大数据流式计算环境下的弹性资源调度策略研究 [D]. 乌鲁木齐:新疆大学,2022.
[2] 吴泽伦.基于HADOOP的数据挖掘算法并行化研究与实现 [D].北京:北京邮电大学,2015.
[3] 高殿荣,王益群,刘继刚.自适应有限元方法及其在液压技术中的应用前景 [J].液压气动与密封,2001(5):2-4.
[4] 赵康,馬陈燕,王道军.基于Ray并行分布式框架的深度强化学习计算平台 [J].软件,2022,43(11):179-183.
[5] 张生顺.针对Ray框架的分布式计算调度仿真平台 [D].成都:电子科技大学,2023.
[6] 刘瑞奇,李博扬,高玉金,等.新型分布式计算系统中的异构任务调度框架 [J].软件学报,2022,33(3):1005-1017.
[7] 朱光辉.分布式与自动化大数据智能分析算法与编程计算平台 [D].南京:南京大学,2021.
[8] KRAWCKE N. Talking boiler trends with Ray Wohlfarth [J].Plumbing & Mechanical,2023,41(2):38.
[9] MORITZ P,NISHIHARA R,WANG S,et al. Ray: A distributed framework for emerging AI applications [R/OL].arXiv:1712.05889 [cs.DC].[2023-02-10].http://export.arxiv.org/abs/1712.05889.
[10] BENIWAL A,BAFNA R K. A Case of Anterior Lenticonus Managed With Ray Tracing Aberrometry [EB/OL].[2023-02-06].https://kns.cnki.net/kcms2/article/abstract?v=j6HAoO1nZAzQFufqG4fTHAkT4g8xBUVqCIxq2FGkqi0rxSSLC53pBCHJKFMZv4ZtwvTUWBssjwLI0ntYj_hyQsDD9SL0Co4BHWSy7eWwsSObUKXOJ_wvekt9j3KutnqU-kodlUII66Uu_fQhR9RvMN5BVNzKIpltLUAXIveV_ro=&uniplatform=NZKPT&language=CHS.
[11] 黄增强.面向机器人模拟与强化学习的分布式训练平台设计与实现研究 [D].杭州:杭州电子科技大学,2021.
[12] 胡求.分布式深度集成学习及其结构搜索算法与系统 [D].南京:南京大学,2022.
[13] 刘畅.手机阅读实时推荐系统中协同过滤引擎的设计与实现 [D].北京:北京邮电大学,2018.
[14] 李妍.基于FlexRay总线飞行控制计算机核心单元设计 [D].南京:南京航空航天大学,2017.
[15] 李静,王健.基于FlexRay总线的分布式测控系统 [J].微型电脑应用,2014,30(11):38-40.
[16] 郑越.大规模场景渲染下的分布式光线跟踪算法研究 [D]. 长沙:湖南大学,2019.
[17] 陈悫,张凤登,张晓霞,等.分布式FlexRay线控转向系统可靠性及容错技术研究 [J].工业控制计算机,2014,27(1):63-66+69.
作者简介:侯伟(1997.06—),男,汉族,安徽六安人,硕士研究生在读;研究方向:分布式计算、计算机视觉。
猜你喜欢
软件导刊(2016年12期)2017-01-21
软件导刊(2016年11期)2016-12-22
科学与财富(2016年15期)2016-11-24
新闻世界(2016年10期)2016-10-11
科技视界(2016年20期)2016-09-29
中国记者(2016年6期)2016-08-26
电脑知识与技术(2016年20期)2016-08-19
系统工程与电子技术(2016年2期)2016-04-16
