
一种基于深度学习的商标检测方法
2024-01-21 13:09庄建军石潇愉
科学技术与工程 2023年36期
庄建军, 石潇愉
(南京信息工程大学电子与信息工程学院, 南京 210044)
互联网的普及和智能手机的大众化使人们的购物方式产生了巨大的变革。在年轻一代中,传统线下购物几乎已经被线上购物所取代。根据中国互联网络信息中心的数据,中国线上购物人数达到8.42亿人,已超过总人数的1/2。一方面,互联网带来的海量产品令人目不暇接,用户无法快速定位自己想要的物品,商标检测方法可以帮助用户实现即拍即搜的效果,获得极大便利;另一方面,大量的商标侵权行为滋生,2022年,中国商标异议裁定数量达1.7×105。巨大的数据量面前,由于商标的图片属性,人工排查侵权行为效率低下,而使用商标检测方法则只需拍摄一张照片即可从数据库中索引到相关产品,随后再由人员进行裁定,极大提高了工作效率。
王一海[1]提出了使用反向传播(back propagation BP)神经网络来进行商标识别,但这种靠全连接层的网络效率过低。Leng等[2]引入主流的目标检测模型YOLOv3,在Flickrlogos-32数据集上取得了73.9%的mAP(mean average precision)。林轶等[3]基于YOLOv3得到一种交通标志的识别方法,与商标识别类似,但是商标所在场景更为复杂。丁明宇等[4]把YOLO(you only look once)与文字识别技术相结合,进行商品参数的提取。总的来看,原有的商标识别方法,其覆盖面不广,使用的模型则相对落后,方法不够有效。
随着科技的不断革新,对商标识别方法提出了更高的要求,需要设计一种更准、更小、更快的模型。纵观当下使用较多的目标检测算法[5],一类是以区域卷积神经网络(region convolutional neural networks R-CNN)系列算法为典型的双阶段(two-stage)检测算法,这类算法的实现需要先进行区域生成,再对区域进行检测达到由粗到细的整个过程。该类算法的第一阶段不但导致了总体计算量的增加,也给训练带来很大的压力。最后,该类模型在普通硬件条件下无法达到实时检测的要求,检测速度较慢。另一类单阶段(one-stage)目标检测算法以YOLO为典型,它们的主要特点是实现了端到端操作,不需要多余的工作就能达到输入图片输出结果的效果。其中YOLOv7是当前最新的版本,相较之前的YOLO版本进步显著,其速度和精度在5FPS-160FPS的范围内达到了业内最高[6]。
商标识别存在以下难点,首先,商标在产品中出现的形式多样,有标志也有文字,因此在样本相对较少的情况下想要得到较高的精度存在着一定的困难,对模型的泛化能力提出了更高要求。其次,电商产品中商标大小差异大,这对模型的多尺度检测能力提出了的严峻挑战。再者,数据集中商标出现的位置及方向不同,这也会对检测造成一定的困扰。鉴于此,兼顾检测精度和检测速度的提升,选用YOLOv7作为基础模型并对其进行针对商标检测的改进。研究成果可做到商标的智能化实时检测,解放人们在分辨商标时付出的劳动力。
1 数据集及其预处理
1.1 数据筛选及图像标注
数据集取自天池平台,从整个数据集中筛选出其中74类商标共6 673张从线上购物平台中截取的图片。其中不但有实物拍摄图,也有商家提供的在干净背景下的独立商标,这有利于模型训练初期对特征的提取,加快收敛速度。挑选出来的图片中只有少部分已被标注的COCO(common objects in context)结构标签,而研究所采用的是VOC(visual object classes)结构的标签,因此通过文件处理将这部分json文件转化为所需的xml文件。剩余图片则通过LabelImg软件进行手动标注,直接获得所需的xml文件。标签文件和对应的图片同名,信息包括各图片中商标的类别名称和位置信息,其中位置信息包括左上坐标(xmin,ymin)以及右下坐标(xmax,ymin)。
为得到训练过程中需要的先验框,训练前使用K-means[7]算法对数据集进行聚类。该阶段可绘制可视化结果,观察得到商标大小的分布,聚类结果如图1所示。
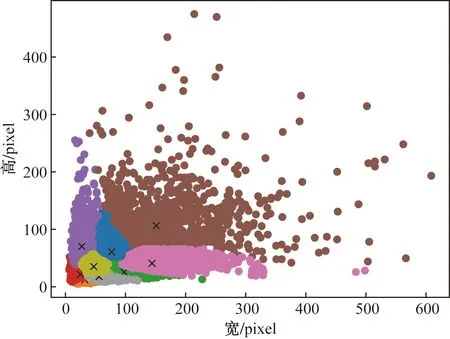
图1 数据集聚类结果Fig.1 Results of data clustering
1.2 数据增强
由于类别较多,每一类商标拥有的样本数并不多。因此采用数据增强来扩充数据集,增强模型的泛化能力。现在比较流行的数据增强方法有Mosaic(马赛克数据增强)和Mixup(混类数据增强)。Mosaic通过图像的缩放和拼接合成新的图像进行训练,Mixup则是将图像设置透明度后重叠成新的图像。两者在不同的数据集上表现不一,因此需要通过实验来决定具体如何使用以达到最好的效果。
从数据集取出10%作为测试集,再将剩余部分以9∶1的比例分为训练集和验证集。得到训练集共5 404张,每一类大致有70张图片可用作训练。为直观表示不同方法对训练结果的影响,本文选择每训练5轮在验证集上进行一次验证,用当前训练结果计算mAP,由此来观察其收敛速度和最终效果。实验方法如表1所示。

表1 数据增强对比方法Table 1 Comparison of data augmentation methods
图2为数据增强阶段的实验结果,可以看出,Mosaic数据增强对训练的影响最大,极大地加快了收敛速度,并且最后的结果出现明显提升。而Mixup则表现不佳,单独使用时甚至降低了训练效果。初步分析是因为网购的实物图由于各种活动信息导致元素杂乱,使用Mixup会让杂乱加剧,导致关键信息变得模糊,降低了提取效果。但是在和Mosaic共同使用时可以达到一定的提升效果。
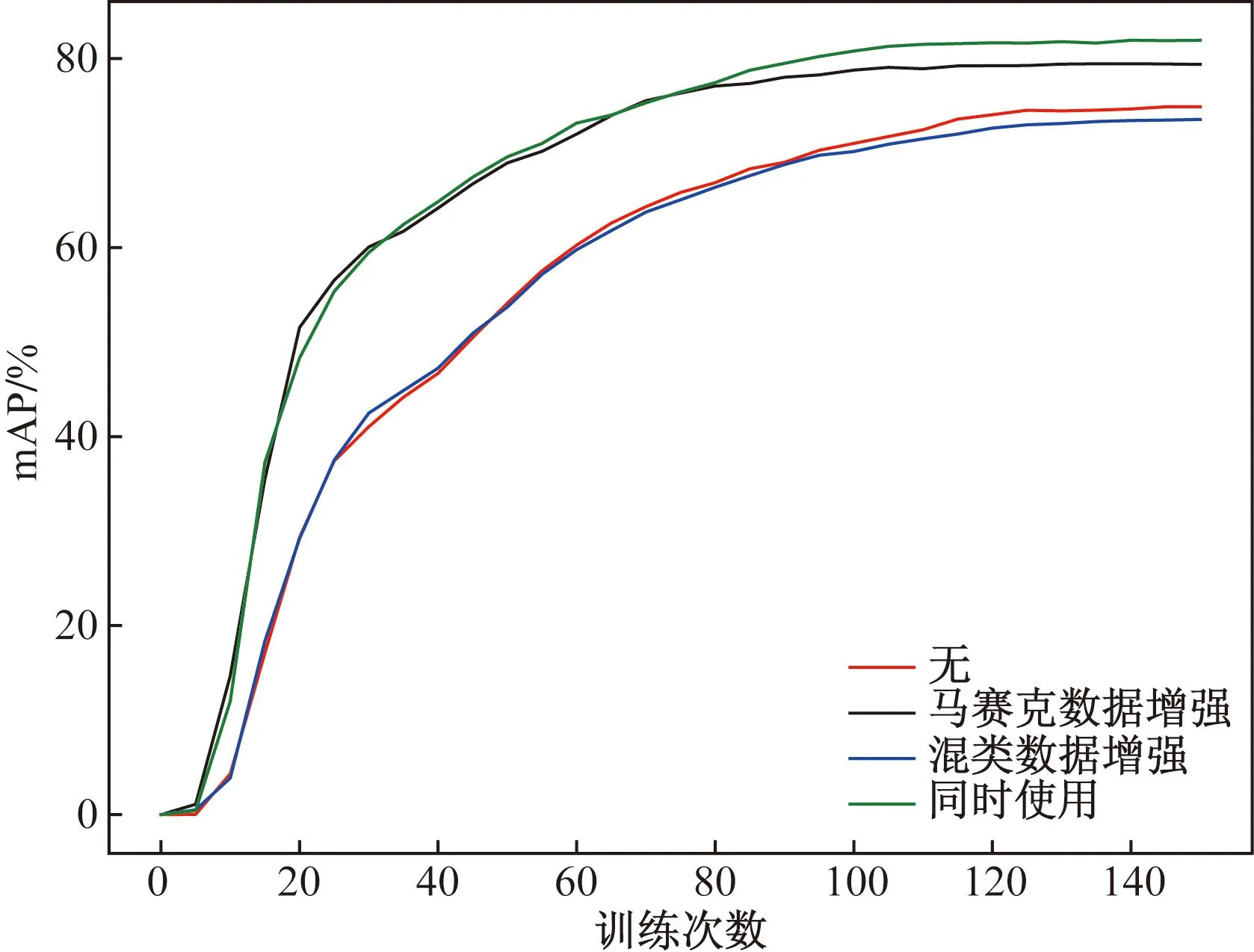
mAP为各类商标平均检测精确度的平均值图2 数据增强实验结果Fig.2 Result of data augmentation experiments
根据实验结果,最终选择Mosaic和Mixup共同使用以达到更快地收敛速度和更高的精度。数据增强可以很好地避免模型训练过程中过拟合现象的出现,有效地提高了模型的泛化能力,也缓解了样本数量较少的问题。
2 YOLOv7的改进
2.1 YOLOv7算法
YOLOv7由YOLOv1逐步改进而来,从开始建立起将图片分成S×S的网格(S为网格的数量),再由每个网格负责预测的想法[8],到改进成为anchor-based模型[9]。YOLOv3版本中,首次在网络中加入Neck部分,采用特征金字塔(feature pyramid network FPN)来解决小目标检测问题[10];YOLOv4版本中,加入大量的tricks以提高性能[11],其中,Mosaic数据增强的使用,增加了数据量,使得背景多样化,一定程度上降低了过拟合的危害;YOLOv5版本中,在Yolox中提出anchor-free模型,并且将检测头解耦,但这也带来了参数量增加模型变大的问题;美团发布的YOLOv6版本更多的是在硬件上的加速。YOLOv7版本更专注于推理速度,在精度和速度上都超过目前主流的目标检测器,模型总体结构没有发生变化,但是改进了网络中各个具体模块,如将CSP(cross stage partial network)替换成了创新的多分支堆叠结构,SPP(spatial pyramid pooling)中也加入CSP结构以扩大感受野。因此,采用tiny版本的YOLOv7作为基础模型进行针对性改进。
2.2 模型改进策略
YOLOv7算法已经在公用数据集上达到SOTA,但是具体到特定数据集中,则尚存在改进空间,在提高其精度的同时减少模型的参数。74类商标中绝大部分都存在样式多样的情况,并且有图案也有文字,这对模型的泛化能力提出了较高的要求。其次,商标的大小各异,有的出现在衣领上,目标很小,而有的则出现在是衣身上,目标很大,因此需要提高模型的多尺度特征融合能力。针对以上问题,模型做出下述改进,并且取到了较好的结果。
2.2.1 SimBiFPN
为了达到模型轻量化的目的,从Neck层入手,将PANet替换成了在主打轻量化的模型EfficientDet[12]中被提出的双向特征金字塔网络(bi-directional feature pyramid network BiFPN),并且做出了一定的改进。
由于各个不同的输入特征对于最后的输出所产生的贡献是不等的,He等[13]在普通金字塔的基础上加入了简单的注意力机制,在各个特征输入上加入权值,从而让网络自行选择更加重要的输入特征。随后去除了金字塔上下边缘的节点,由于这些节点只有一个输入边,对特征融合的贡献度相对较小,因此这对最后的结果不会产生太大的影响,却能减少参数量。并且除了进行不同特征图之间的特征融合,该结构还创新性地增加了同一特征图上前后不同层的特征融合。由于新增的连接处于同一条路,因此并不会增加太多的计算成本。处理过后的特征图不仅拥有更高层次的语义信息,同时也融合了较低层次的位置信息。原版BiFPN结构如图3所示。原文中还提到使用符合缩放方法来确定该结构的重复次数。考虑到尽量节省资源,只重复一次。

P1~P7为特征提取层中不同的输出层图3 BiFPN结构Fig.3 BiFPN structure
权重计算公式为
(1)
式(1)中:ωi、ωj为不同节点的权重大小,归一化后与输入特征Ii相乘;O为加权后的输出特征;ε为一个很小的数,取值为10-4,用于防止出现分母为0的情况导致权重爆炸。
为了使该结构能够完美融入YOLO,对其进行一定的改动。将其输入输出节点均减少为3个,并且更改了通道设置,从原本的全过程通道保持一致变为了有通道增减的融合机制。这样会造成两个边缘节点权值不多,且根据K-means聚类得到的结果可以发现本数据集中等大小的商标占据了相当一部分数量。因此这样做是相对科学的。将简化后的结构命名为SimBiFPN,其结构如图4所示。给出加权信息最多的P4输出计算公式[式(2)、式(3)][14]。该方法首先通过逐通道卷积,再进行逐点卷积。在使用相同计算量和参数量的情况下,深度可分离卷积能让神经网络层数做的更深。Resize操作表示使用1*1卷积进行通道数的改变以及上下采样。

为第n个输入层;为第n个输出层;Conv为卷积;Wmn为第m轮加权的第n个权重;Add为矩阵相加;SpConv为深度可分离卷积;UpSampling2D为2D维度的上采样;DownSampling2D为2D维度的下采样图4 SimBiFPN结构图Fig.4 SimBiFPN construction
浅层特征图的感受野比较小,包含的是位置信息,而语义信息不足,易受到干扰,因此只适合检测小目标;而在深层特征图中,其感受野逐渐变大,包含丰富的语义信息,但是细节信息丢失严重。使用了简化的双向特征金字塔网络后,很好地提升了网络的特征融合能力,对于形状大小各异的商标具有了更好的识别能力。
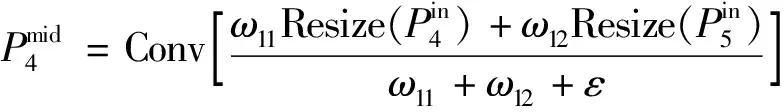
(2)
(3)
y=(αw1⊙αf1⊙αc1⊙αs1⊙W1+
αw2⊙αf2⊙αc2⊙αs2⊙W2+…+
αwn⊙αfn⊙αcn⊙αsn⊙Wn)*x
(4)
2.2.2 注意力机制
在商标识别的过程中,会遇到同一商标出现多种艺术形态的情况,这时候就需要模型更多地去关注关键性语义信息,防止预测结果被无关的细节改动影响。因此引入带有注意力机制的动态卷积。
近年来,针对动态卷积的研究较多,较新的是全维度动态卷积(omni-dimensional dynamic convolution,ODConv)[16]。动态卷积主要受益于注意力机制的使用,因此选择在网络中添加ODConv进行尝试。
动态卷积有两个基本元素:卷积核和用于计算注意力的注意力函数。它对多个卷积核进行线性加权,权值与输入挂钩,使得动态卷积依赖于输入特征。ODConv具有多维注意力机制,使用并行策略将卷积核空间的4个维度均带上权值,分别是输入输出通道数、空间核尺寸和卷积核个数,计算公式如式(4)所示。
采用的YOLOv7结构中,在Neck和head之间有一个Conv连接块对网络影响不大且处于关键位置,因此考虑将这3个Conv改为ODConv模块。加入动态卷积使网络具有注意力机制,强化有用信息,抑制无关信息,根据不同的输入来调整参数,加强了特征提取能力,使模型更加关注整体语义信息。
2.2.3 小目标检测
当前市场上存在许多的商品将商标打在后面的衣领下,该类商标往往十分细小,属于小目标。因此需要为模型提供像素级建模的能力,以提升其对小目标的检测能力。
Funnel激活函数FRelu[17]在近两年被提出,与传统的激活函数实现方式不同,它的实现形式如式(5)所示。
y=max[x,T(x)]
(5)
式(5)中:函数T(x)表示二维空间的条件;y为输出特征张量;x为输入特征张量。
该激活函数的实现非常简单,并且计算开销的增加几乎可以忽略不计。在使用了空间条件后,该激活函数具备了像素级的建模能力。其具体实现方式如图5所示。
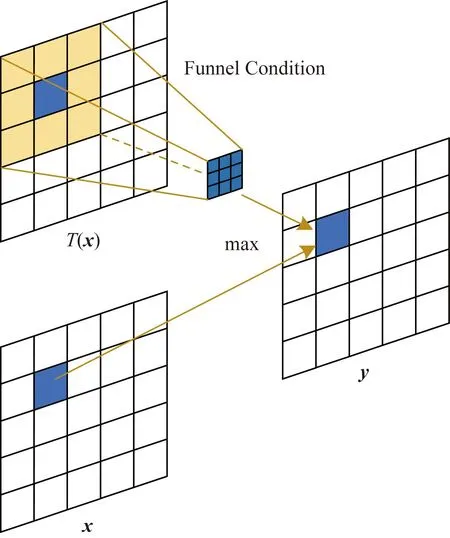
图5 Funnel激活函数Fig.5 FRelu activation function
这种激活函数是专门为计算机视觉任务而设计的,从图5中可以看到,激活函数的条件值变成了一个依赖于空间上下文的二维漏斗状条件,可以为提取精细空间信息作出贡献。
3 实验及结果
3.1 实验平台及数据
深度学习的训练是一个相当耗时的过程,因此使用GPU进行加速运算来提高迭代效率很有必要。采用的实验平台是个人计算机,具体配置如表2所示。

表2 实验环境配置Table 2 Experimental environment configuration
模型训练时从0开始训练,batchsize设置为8,采用adam优化器[18],动量设置为0.937,初始学习率为10-3,并且使用余弦退火[19],无权值衰减。最终训练模型时的损失下降情况如图6所示。可以看出,在150轮模型已经区域收敛,因此决定将训练轮数定为150。
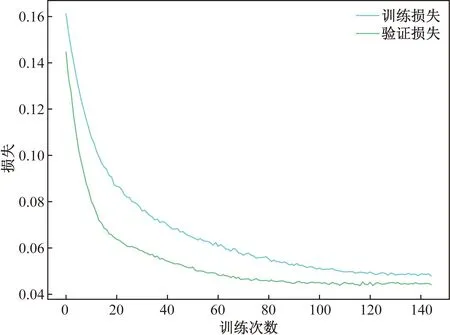
图6 损失下降情况Fig.6 Loss decline
3.2 评价指标
目标检测类任务通常采用mAP作为评价模型性能的指标,代表着对目标的类别信息以及位置信息的预测准确程度。位置信息通常采用各类IoU来进行计算。该指标中包括了查全率R和查准率P,AP的值就是由P-R曲线与坐标轴围成的面积计算得来的,平均各类的AP得到mAP,计算公式为
(6)
式(6)中:c为商标类别数;Pc(R)为第c类查准率关于查全率的曲线。
此外,还关注模型的浮点运算次数(GFLOPs)和参数量,用于衡量模型的计算复杂度。
3.3 结果与分析
对YOLOv7网络采用3种改进策略,为此单独及综合考察3种策略带来的预测效果。为区分不同模型,对其进行命名,如表3所示。
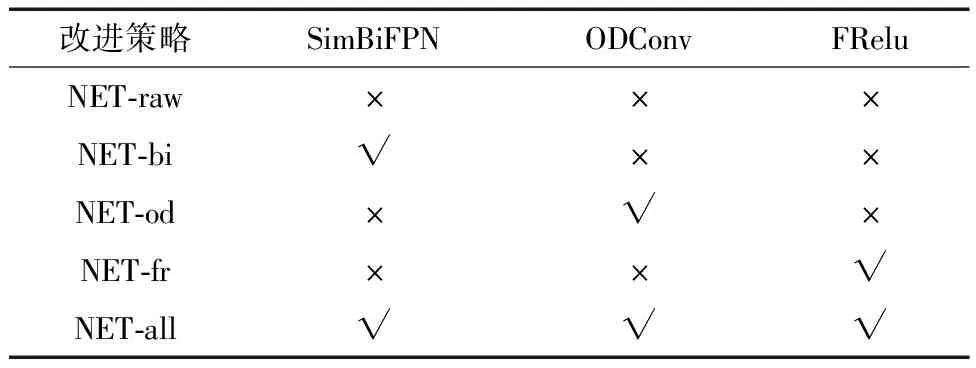
表3 模型改进策略Table 3 Strategies of model improvement
如图7所示,根据消融实验得出这5个模型在相同条件下训练150轮后的mAP,并且计算其各自的浮点计算次数和参数量,对比数据发现3种策略单独并未起到太大的效果,只是在保持结果基本不变的情况下减少了模型的浮点计算次数以及参数量。当三者共同使用时,mAP到达了85.84%,相较于原始模型提升了约2个百分点,并且将参数量和浮点运算次数控制在相对较低的水平。
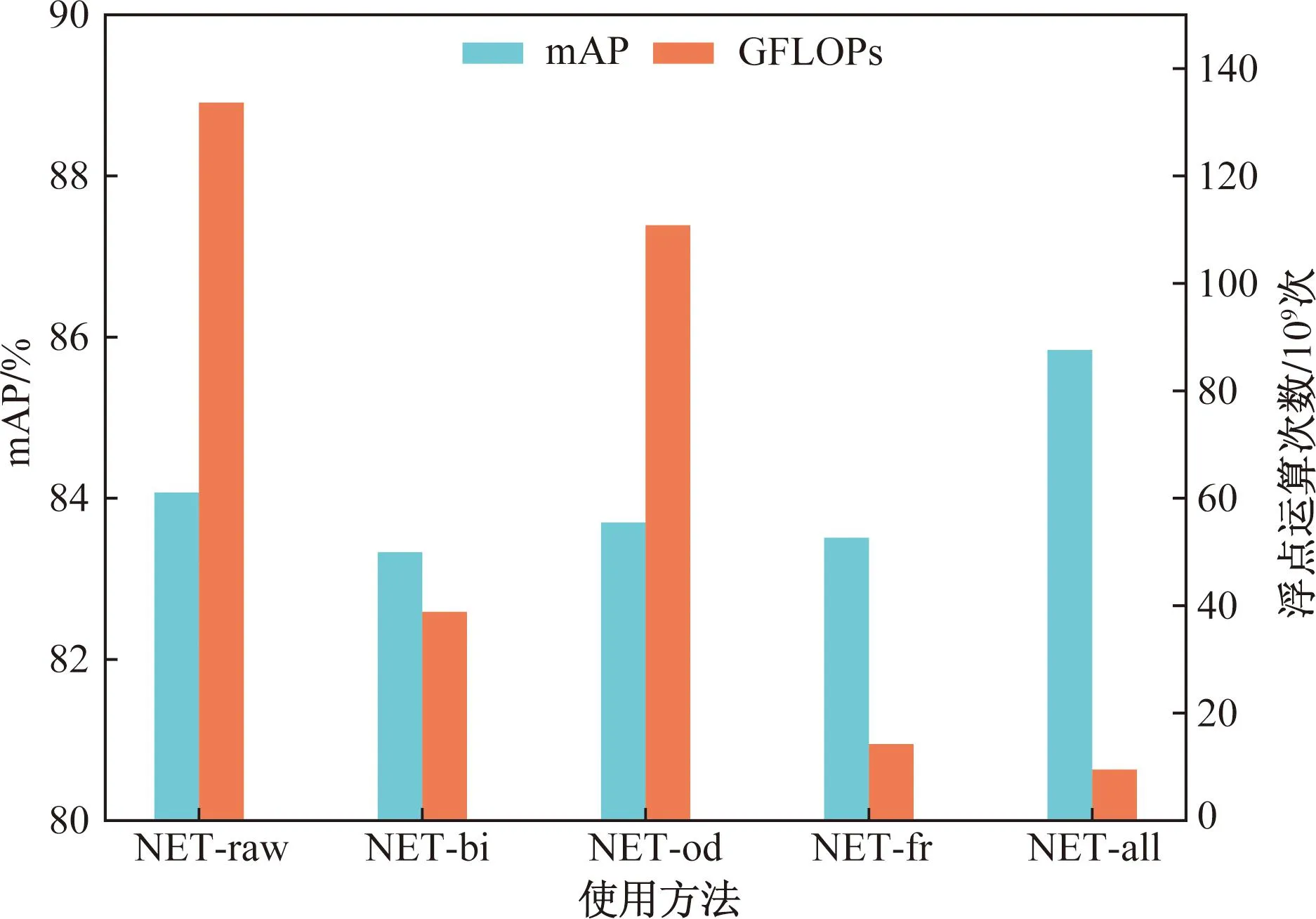
图7 消融实验对比Fig.7 Comparison of ablation experiments
为了进一步验证方法的有效性,将改进模型与其他常用模型进行对比试验,实验结果如表4所示。相较于原模型,本文算法将mAP提高了近两个点的同时,极大地降低了参数量和浮点计算次数,分别降低了41%和92.9%。且经过实验得到该算法的FPS在60帧以上,达到了实时检测的水平。
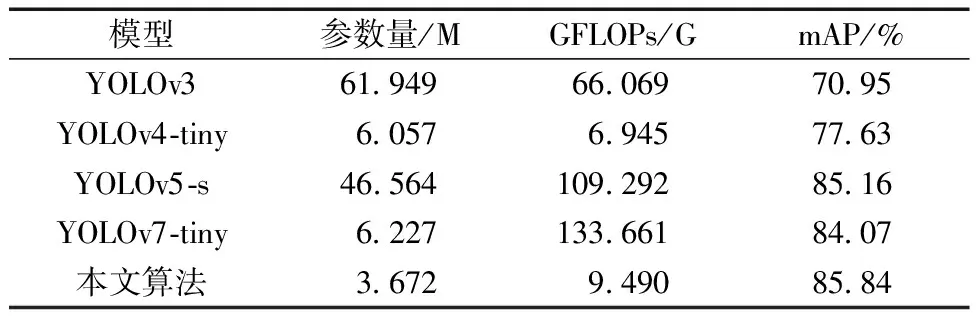
表4 不同检测算法对比Table 4 Comparison of different detection algorithms
在实际表现方面,挑选相对复杂的图片让原始模型和改进模型进行预测,对比发现,改进后的模型识别出了原版未检测到的领口商标,这得益于FRelu的使用,让模型具备了像素级建模能力,提升了小目标检测准确率。改进后的算法识别出了更多的镜像商标,此处得益于ODConv的使用,其中的注意力机制使模型更加注重关键特征,不会因为简单的变形就导致无法识别。
4 结论
从提高线上购物效率及打击商标侵权场景中的关键性技术出发,提出一种基于YOLOv7的商标检测算法。得出如下结论。
(1)在数据方面,采用Mosaic和Mixup两种数据增强方式共同使用的方法以提高模型的泛化能力。
(2)在模型本身方面,为了适应商标识别的特点,增强算法性能,做以下改进措施:一是通过改进金字塔结构,将PANet更改为SimBiFPN,提升了模型的多尺度特征检测能力;二是修改关键节点的卷积成为ODCov来给模型加入注意力机制,以便于提取关键语义信息;三是更新激活函数为FRelu,使算法具备像素级建模能力。根据实验结果可以看出,采用的方法在明显提高精度的同时控制了参数量和浮点运算次数。改进模型在检测任务中可以成功识别出大部分细小商标和扭曲变形商标,算法的泛化能力具有一定的保障,且算法运行的FPS在60帧以上,能够实现快速检测的目的。
(3)该研究尚有进一步改进的空间,未来将在识别速度、识别精度以及泛化能力上继续提升算法性能。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02
疯狂英语·新策略(2019年10期)2019-12-13
成都信息工程大学学报(2019年4期)2019-11-04
阅读与作文(英语初中版)(2019年8期)2019-08-27
电子制作(2019年11期)2019-07-04
当代陕西(2019年10期)2019-06-03
小学生学习指导(低年级)(2018年11期)2018-12-03
北京航空航天大学学报(2018年1期)2018-04-20
数学小灵通·3-4年级(2017年9期)2017-10-13
现代防御技术(2016年1期)2016-06-01
