
基于双重注意力网络的司法分论点生成
2024-01-20 02:22罗准辰巢文涵
中文信息学报 2023年10期
邓 健,周 纤,罗准辰,巢文涵
(1. 北京航空航天大学 计算机学院,北京 100191;2. 中国人民解放军军事科学院 军事科学信息研究中心,北京 100142)
0 背景
在法制社会中,证据是法官判决的前提条件。司法实践中任何诉讼均应以认定事实和适用法律为其内容,其中适用法律以一定事实的存在为前提,而事实认定则有赖于证据证明。因此,在法律案件的审理过程中,需要通过证据链还原案件的真实样貌,使法官能够基于恰当的逻辑基础进行审判,这个过程也被称为证据推理(Evidential Reasoning)[1-2],是法官判案中重要的一环。如图1所示,在被告人杨某的故意杀人案件中,作案工具图这项证据证明了被告人作案工具与供述一致的事实,这些证据事实可以辅助法官推进故意杀人罪名的判决。
然而,在实际的司法实践中,法官在撰写法律判决书时忽视或者回避证据事实推理的现象一定程度上还存在着。尤其是随着文书上网制度的推行,公众在接触到更多刑事判决书的同时,判决书证据说理方面的不足也显露在大众视野中。如图1所示,根据Teng等人[3]的研究,一般刑事判决书中证据部分通常为以下两种表述方法: 左侧利用抽象、笼统的说法或者简单罗列的方法,代替对证据的分析、推理、论证,而右侧证据说理形式则规范组织了证据与其所能证明的证据事实,即分论点(Sub-claim),具有更好的可读性,然而此类规范形式在形式判决书中仅占约5%。
为了进一步完善司法案件中证据事实的推理过程,本文提出了一项新的司法分论点生成任务,基于对已知证据子集的归纳推理,生成合适的分论点作为证据事实以供判案参考。目前,司法领域的文本生成工作主要集中在摘要生成[4-5]或法庭观点生成[6-7],但是这些研究与司法分论点生成存在着较为明显的区别: 首先,司法摘要或者法庭观点是对于案件事实的高度概括、总结性陈述,而司法分论点是一个个的证据事实,属于案件事实中的局部关键信息;其次,以证据为基础的司法分论点能构建一条从事实、证据、分论点、主罪名的完整逻辑链,能够清晰展现出法官在案件定罪中的推理过程,而法庭观点通常属于对于最终判决的概括性解释。
然而,当前的文本生成模型[5,8-9]直接用于司法分论点生成仍然会存在一些问题。司法分论点是基于证据推理出的证据事实,通常与原始的案件事实存在一定的逻辑关系,这意味着我们需要依托于证据以及案件事实内在的关联来挖掘出更恰当的司法分论点。此外,作为成文法国家,法律条文是案件审判中法官判案最基础的依据,其中规定了相应罪名的构成要件,这些信息能够指导司法分论点的生成。因此,法律条文和当前案件事实之间的潜在关系也是一个需要考虑的内容。
针对上述问题,本文提出了一种基于双重注意力网络[10]的司法分论点生成模型,该模型主要由证据注意力模块以及法条注意力模块构成。具体来说,在证据注意力模块中,通过注意力机制挖掘案件事实中与证据相关的碎片事实信息;在法条注意力模块中,我们设计了一个法条注意力模型,利用案件事实信息增强法律条文的上下文表示。之后,相关证据和法律条文的信息被输入进解码器中,逐步生成司法分论点。此外,为了增强生成文本的专业性以及准确性,我们在解码器中使用了复制机制[11]来从原始事实描述中复制词语。最后,为了评估模型效果,我们从在线裁判文书网中构建了一个新的司法分论点数据集(1)https://drive.google.com/file/d/13PF4bvVRmyw1izcEuk-X9GvawO5qC_FlF/view?usp=sharing,在此数据集上的实验表明,我们提出的模型能够生成质量更高的司法分论点文本。
本文贡献主要如下: 首先据我们所知,我们首次提出服务于法律案件证据推理的司法分论点生成任务,并且为此任务构建了一个真实数据集;其次我们提出了一个双重注意力网络模型来挖掘证据、法律和事实信息之间的潜在关联,通过捕获上下文语义来提高分论点生成的整体性能;最后在构建的司法数据集上进行的大量实验证明了本文所提出的模型的效果。
1 相关研究
1.1 司法证据挖掘
本文工作与目前尚未受到太多关注的司法证据有关。Ji等人[12]提出了从法庭记录文件中提取证据信息的任务,其目标为从法庭记录文件中提取证据提供者、证据名称、证据内容、质证和质证意见等关键信息。他们根据上述的信息类型来对文档进行分类,并通过端到端的联合模型来完成证据信息的提取。
随后,Ali等人[13]也从法院判决中提取了证据信息,并将其用于检索类似的司法案件。最近,Teng等人[3]为了解决大多数法律判决书中的证据散乱问题,提出了一种基于BERT[14]和 ESIM[15]的论辩驱动方法来评判证据对之间的距离,从而据此将所有的司法证据分为多个不相交的证据子集。本文工作主要通过案情描述来挖掘证据之间的相关性,并且推导出证据在当前案件中的作用。
1.2 法律文本生成
以前关于法律文本生成的工作主要集中在摘要生成上。Schilder和Molina-Salgado[8]假设法律文件中的某些句子或段落可以概括部分或者整个文件。因此,他们提出了一种基于图的方法,通过对比句子和段落的相似得分来对它们排序。Galgani等人[4]通过引入知识库并提取个别关键句来概括一份法律文件。在他们的另一项工作[9]中,他们根据引文中的关键字筛选出合适的句子作为摘要。之后,Polsley等人[5]提出了一种基于词频和外部知识的法律文件自动摘要工具。
更具体来说,与我们工作最相关的法律文本生成是基于案情描述的法庭观点生成任务。Ye等人[6]首次提出该任务,并设计了一个基于 LSTM 的label-seq2seq模型。Wu等人[16]将此任务应用于民事案件。由于民事诉讼的“不告不理”原则,引入原告的诉求来生成法院观点,从而同意或驳回原告诉求。然后,Yue等人[17]将法庭观点分为判决情况(ADC)和量刑情节(SEC)两部分,并从案件事实中提取相关句子来分别生成。而最近Li 和Zhang[7]通过在他们的模型中利用罪名和法律条文进一步提高了这项任务的性能。我们的司法分论点生成任务作为一项司法辅助工具,通过生成分论点来形成一条支撑最终判决的合理逻辑链,从而为法官以及其他司法从业人员提供参考。
2 方法介绍
2.1 问题定义
本节我们会对司法分论点生成问题给出一个准确的定义。给定法律判决书中的一个由m个证据组成的集合E={E1,E2,E3,…,Em},长度为n的案件描述文本F={f1,f2,f3,…,fn},以及p条相关的法律条文L={L1,L2,L3,…,Lp},我们的司法分论点生成任务是生成合适且符合逻辑的司法分论点C={c1,c2,c3,…,cq}。
2.2 模型概述
给定一个实际的司法案件,我们需要从事实描述、证据和案件相关法律条文中挖掘三者之间的潜在信息,以产生合理的司法分论点。其中,证据是用来佐证案件经过的真实性,它与案件经过的某一部分事实有关。而法律条文是寻找请求权基础与判断法律关系最可靠的路径,指明了各个罪名的犯罪构成要件,结合具体案件经过能将条文以更具说服力的分论点形式将案件事实涵摄于法条的事实构成之下,形成合理的推理结构。考虑到证据和法律文章之间的差异,我们设计了基于双重注意力网络的司法融合模型来对案件经过、证据和法律条文之间的特征进行建模,从而获取更有价值的法律上下文特征信息。
如图2所示,我们设计了两种类型的注意力模块,以更好地获得司法上下文特征。其中,主要使用预训练语言模型对两个注意力模块中的不同输入进行编码,得到相应的编码向量。在证据注意力模块中,我们将证据与案件经过拼接在一起输入预训练语言模型中进行编码,以获得证据增强的案件经过表示。此外,在法律注意力模块中,我们分两个阶段实现了法条向量的获取以及法律和案件经过之间的注意力表示。最后,将两个注意力模块的输出融合后作为Transformer解码器的输入,通过逐步解码从而得到符合逻辑的司法分论点。

图2 模型整体架构由一个基于双重注意力模块的编码器,以及带有复制机制的堆叠Transformer解码器构成。
2.3 证据注意力模块
在司法程序中,任何诉讼均以认定事实和适用法律为其内容,而事实的认定是否真实,则有赖于证明。因此,证据对于案件事实的认定起着核心作用。而证据事实是人们基于证据所作出的关于案件的陈述,准确地说,系由对证据的描述出发经由合理推导而形成的对事实的陈述。鉴于证据和案件事实之间的关联性,我们设计了一个证据注意力模块,通过结合证据和事实描述之间以及证据和证据之间的信息来增强证据的表示,从而有效挖掘案件事实中潜在的证据关联信息。
如图2左侧所示,我们将所有证据和事实描述拼接在一起获得的证据与案件事实文本[E1,E2,…,Em,F]作为预训练语言模型的输入。这样处理的原因之一在于一个分论点对应的证据数量通常少于3个,而单个证据的长度较短。因此,将它们与长文本的案件经过拼接在一起的话,不会因为编码器的输入长度限制而被迫截断太多的案件经过,从而保留绝大部分的事实信息。
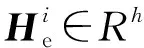
最后,可以得到最终的证据增强的案件经过表示He∈Rm×h。通过这样的处理,我们既可以保留证据与案件事实之间的交互信息,也可以保留不同证据的交互信息。
2.4 法条注意力模块
司法案件的相关法律条文是司法实践中律师办案与法官判案最基础的依据,其中包含了许多有助于生成司法分论点的信息。法律条文是抽象性、高度概括性的对于一项罪名的权威解释,通常包含罪名相应的构成要件,而如何将案件事实涵摄于法条的事实构成之下也能为证据推理提供引导。不过与证据不同的是,法律条文通常比较长,不能像证据一样拼接在一起来作为整体输入,不然会极大程度上压缩案件经过的空间。因此,我们设计了另外一个法条注意力模块来挖掘法条对当前案件事实的具体适用逻辑,从而指导司法分论点的生成。
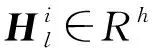
在获得了法律条文的表述和事实描述之后,我们需要发掘法律条文在当前案件中的具体适用,即探索法律条文中定义的构成要件与案件事实之间的潜在联系。我们首先使用点积计算Hf∈Rn×h和Hl∈Rp×h的相似度如式(1)所示。
(1)
然后,我们使用这个交互向量矩阵来获得法条信息增强的案件事实表示。在这里,我们在Q上应用一个Softmax函数来衡量事实描述中不同部分与法律条文的相关程度,如式(2)所示。
αi=Softmax(Q)
(2)
最后法条信息增强的案件事实表示中的每一行HL∈Rp×h就是事实表示的加权和,如式(3)所示。
(3)
2.5 解码器
为了充分利用证据增强的事实表示He∈Rm×h和法条增强的事实表示HL∈Rp×h,我们将它们拼接后得到最终表示如式(4)所示。
(4)
为了提高生成的分论点的准确性和专业性,我们在解码器中引入了类似于Vinyals等人[11]的复制机制,从而能够从案件描述中选取有价值的词语来进一步提高分论点的生成质量,例如其中的时间、人名、地点等关键词语。我们可以计算注意力分布βi并获得上下文向量,如式(5)~式(7)所示。
(8)
(9)
其中,Wc和Ws是可学习的参数,σ是Sigmoid函数。而事实描述中的词语的概率分布是对应词的注意力权重之和,如式(10)所示。
(10)
最终我们可以得到一个单词w在当前时间步长的概率分布,如式(11)所示。
P(w)=Pgen*Pvocab(w)+(1-Pgen)Pcopy(w)
(11)
2.6 训练
如图2所示,我们模型的编码器是基于预训练的语言模型,而随机初始化的Transformer 解码器没有经过预训练,这意味着解码器必须从头开始训练。受摘要生成工作[18]的启发,两个优化器可以帮助缓解编码器和解码器之间的不匹配,因此我们为这两个块分别设置了单独的优化器。
3 实验
3.1 数据集构建
根据中国裁判文书网(2)http://wenshu.court.gov.cn中所有公开的法律判决文件构建了一个新的司法数据集,我们选择了法律案件中符合图1中证据推理类的法律文书进行实验。对于此类司法判决书,一个分论点通常和相关的证据在同一行并由“证明”或“证实”分隔开,因此我们可以通过正则匹配等方式自动提取证据子集和相应的分论点。“证明”或“证实”之前的部分是证据子集,“证明”或“证实”之后是相应的司法分论点。其中不同分论点对应的证据子集之间不存在重合部分,即证据与分论点之间是多对一的映射关系。
我们总共筛选出50 000多份法律案件的判决书文件,数据集各方面的数量和长度统计如表1所示。从中可以发现,一篇判决书中约有9个分论点,而每个分论点对应的证据数量都比较少,一般小于3,这表明大多数司法判决书文件对所有证据的划分归类比较精细。
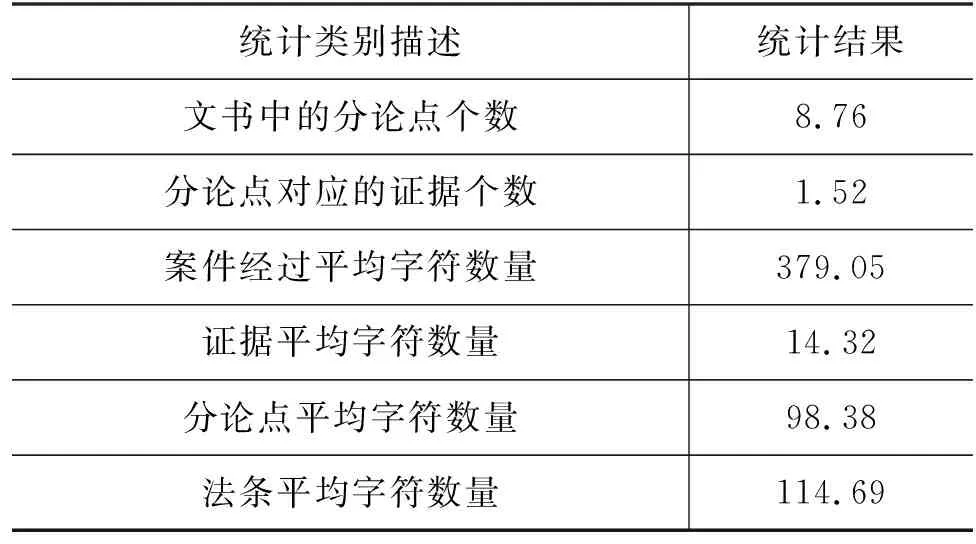
表1 构建的数据集统计结果
从统计结果可以发现,司法判决书中的事实描述往往比较详细,导致案件描述的平均长度达到了379。但是,为了减少司法判决书撰写时的工作量,一些法官往往直接从事实描述中提取较长的一段作为分论点,使得分论点的平均长度达到98.38。关于法律条文,本文主要使用《中华人民共和国刑法》中涉及的法律条文,其中法律条文的平均长度为114.69。但需要注意的是,每个实验样本仅包含司法文书中提到的相关法律条文,其他无关条文将不会输入模型进行处理。最后,证据的平均长度只有14.32,这是因为大部分证据都是名词,例如,一份文件的名称或证词,即使加上一些修饰词,也不会太长。此外,我们将数据集按照8∶1∶1的比例随机分为训练集、验证集和测试集。
3.2 实验设置
3.2.1 基线模型
我们将本文提出的模型与几种相关的文本生成方法进行了比较,如下所示:
(1)Seq2Seq: 序列到序列模型[19-20]是NLG 任务的经典模型。我们将证据和事实描述连接起来作为模型输入。
(2)Seq2Seq+law: 我们将证据、事实描述和相关法律条文连接起来作为Seq2Seq的输入。
(3)BART: BART[21]是一种预训练语言模型。我们同样将证据和事实描述连接后作为输入。
(4)AC-NLG: AC-NLG由Wu等人[16]提出,用于根据原告的主张和事实描述生成合适的法庭视图。我们将其原输入中的原告主张替换为证据,而原输入中的事实描述仍然保持一致。
我们使用BLEU[22]、ROUGE(3)https://pypi.python.org/pypi/lawrouge/和BERT SCORE[23]来评估我们模型的性能,它们是广泛应用于NLG任务中的自动文本评估指标。
3.2.2 实施细节
在实验中,我们使用Pytorch和Roberta的“chinese-roberta-wwm-ext”版本来实现BERT编码器,所有输入的长度限制为512。对于解码器,我们堆叠使用了六个Transformer 解码器层,每个 Transformer 解码器有768个隐藏单元。每个解码器层中的编码器-解码器多头注意力,其输入是来自编码器的事实描述的证据、法条融合表示,以及来自前一个解码器层的输出(或是第一层的分论点输入)。
对于不同的优化器,我们在编码器和解码器中设置了不同的参数。我们为编码器设置了 learnRate=2e-3和warmUpSteps=2 000,而解码器为learnRate=0.01和warmUpSteps=1 000。
(1)Seq2Seq和BART我们将事实描述和证据连接成一个长文本,并将事实描述的字符数量限制为300,证据的字符数量限制为75。对于BART,我们使用“fnlp/bart-base-chinese”模型,并在当前数据集上进行微调。
(2)Seq2Seq+law基于Seq2Seq,我们将《中华人民共和国刑法》中与当前案件相关的刑法条文与事实描述和证据相连接作为模型输入,法条字符数量限制为120,其余参数细节与Seq2Seq保持一致。
(3)AC-NLG对于AC-NLG,原始输入是事实描述和原告的主张,输出是法庭观点。我们将原告的主张替换为证据文本,以此适应我们的分论点生成任务,并利用本文的数据集重新进行训练,学习率设置为2e-3。
3.3 实验结果与分析
表2展示了使用BLEU、ROUGE和BERTSCORE评估不同模型生成的分论点的结果。从结果可以看出,我们提出的模型在BLEU和ROUGE上的性能优于其他基线。而对于BERT SCORE,我们的模型的P值很高,但R值和F1值都相对较低,这表明我们的模型生成的大部分分论点都是由一些关键词汇组成的,从而尽可能涵盖更多的关键内容。
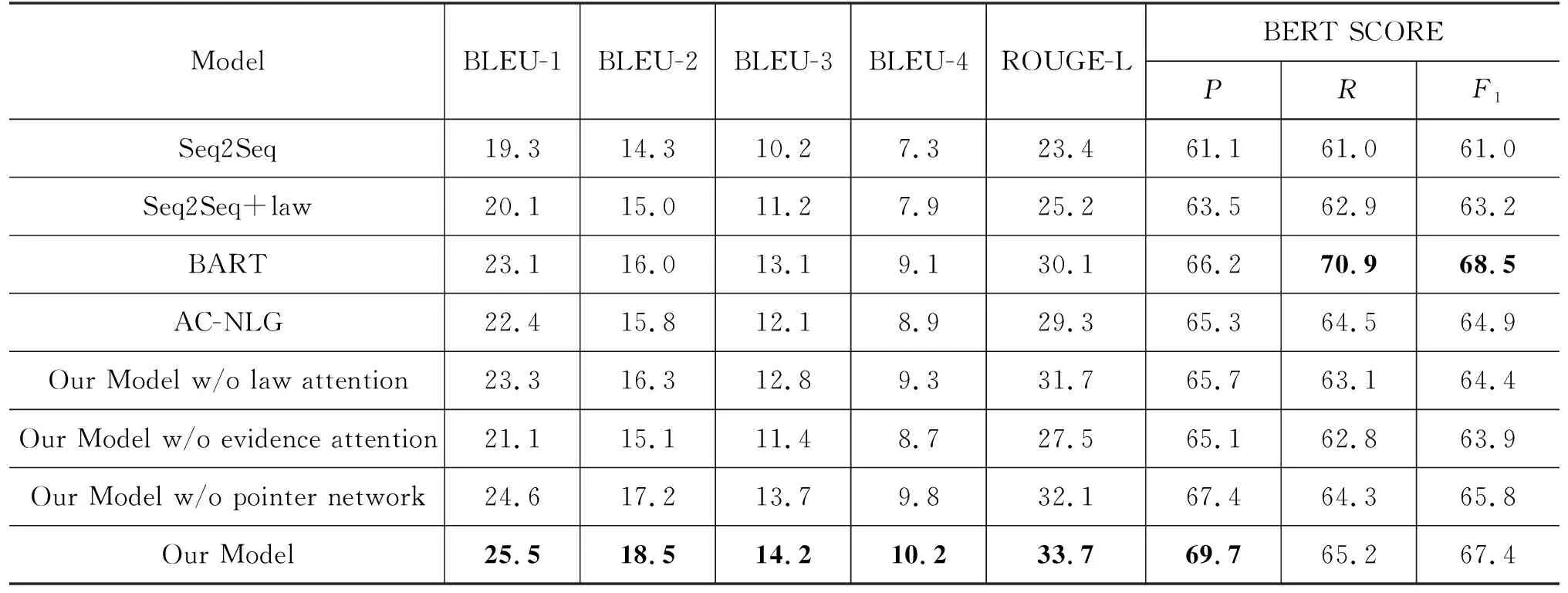
表2 实验结果 (单位: %)
由于模型参数和结构的差异,Seq2Seq最终生成文本的各项指标性能都比BART略差。而与AC-NLG相比,由于Seq2Seq通过连接文本来构造输入,而不是计算事实描述和证据之间的注意力来增强表示,因此AC-NLG生成的分论点整体质量会更高。此外,在添加法律条文后,Seq2Seq的性能在一定程度上有所提高,这表明法律条文确实包含有助于生成分论点的信息。另外,与法院支持或驳回被告主张的法条意见不同,证据推理中的分论点始终是受证据支持的,这可能导致AC-NLG无法充分利用其模型内部两个相反作用的解码结构,从而最终效果低于我们的模型。最后,相对于BART 和 Seq2Seq主要依靠编码器的双向性来挖掘输入之间的潜在关联,我们的模型可以通过证据注意力模块和法条注意力模块更有效地发现并融合事实描述、法律规章和证据三者之间的联系,从而生成更合理的分论点。
3.4 消融实验
本文模型中由几个基本组成部分:
(1) 法条注意力模块: 我们引入了相关法律条文信息输入模型,因为法律规章包含一些判断犯罪行为的构成要件信息,这些构成要件可能与法官在对证据进行分类和整理时的想法是一致的。因此,相关法律条文在一定程度上有助于分论点的产生。
(2) 证据注意力模块: 我们使用证据注意力模块来确定证据和事实描述之间的潜在关联。考虑到分论点实际上相当于是对于这些证据的一个总结归纳,因此它们之间语义等层面的联系将会有助于最终司法分论点的生成。
(3) 复制机制: 由于分论点中经常会涉及到具体的实体,如被害人或被告人的姓名、案件发生的时间地点等,如果模型直接在词汇表中搜索单词可能会导致一些实体错误的出现,所以我们选择引入复制机制来尽量避免此类错误的发生。
因此,我们对上述关键结构进行了消融实验,对于法条注意力模块与证据注意力模块的消融实验,我们分别取消了法条、证据的输入,仅以剩余另一个模块的输出作为整体的融合特征,而对于复制机制我们则取消了Pvocab和Pcopy的计算,直接将解码器输出用来解码。消融研究的结果如表2所示。从中可以看出,移除法条注意力模块会略微降低模型的性能。而如果去掉证据注意力模块,生成的分论点质量的下降幅度更大,这证明证据中包含了更多与分论点相关的有价值信息。此外,关于复制机制的实验还表明,在解码器中引入复制机制可以在一定程度上提高文本质量,可能是由于减少了模型生成错误实体对象的概率。
3.5 用例分析
图3显示了我们的模型生成的两个分论点,它们依赖于同一案件中的不同证据子集,其中证据更关注的事实部分也用不同的颜色突出显示(根据模型中的注意力矩阵得到)。可以发现,对于第一组证据“鉴定意见”而言,事实描述中的“被告人”“毒品”和“检测到甲基苯丙胺”等词语的注意力权重相对较高,说明基于该证据进行推理时会依赖于这几个关键信息,从而使模型能够得出“被告人持有的毒品被检测到甲基苯丙胺”的结论。对于第二组证据“证人王某的证言”,事实描述中的“时间”“地点”和“逮捕”等受到的关注度更高,从而模型可以据此推断出这项证据是为了证明被告人被捕的时间和地点。除此之外,我们也可以发现涉及贩毒的法律条文会更加关注案件描述中的“克”“天津”“检测到甲基苯丙胺”等与毒品相关的词汇,这也证明了法条注意力模型的价值。

图3 基于案件经过、法律条文和证据子集生成司法分论的示例案件经过中,深色阴影部分为与证据子集1交互时注意力权值更高的词语,浅色阴影为与证据子集2交互的注意力权值更高的词语,而加粗的词语为法律条文更关注的部分。
4 总结
在本文中,我们在司法领域提出了一种新颖的分论点生成模型,以解决当前大多数法律文件中缺少分论点的问题,从而提高判决书的完整性和可读性。本文设计了一个证据注意力模块和一个法条注意力模块来融合事实描述、证据、相关法律条文。而为了提高生成的司法分论点的质量,我们堆叠使用了多个Transformer解码结构,并且在解码时使用类似于指针网络的复制机制来从原文本中复制部分关键词语。除此之外,本文还为此任务构建了一个相应的司法判决书的分论点数据集,并且在此数据集上的实验结果也证明了本文模型的有效性。
猜你喜欢
小学生必读(低年级版)(2021年10期)2022-01-18
小学生必读(低年级版)(2021年11期)2021-03-09
小学生必读(低年级版)(2021年12期)2021-03-04
家庭影院技术(2019年8期)2019-12-04
法律方法(2019年3期)2019-09-11
西夏学(2016年2期)2016-10-26
作文周刊·高一版(2016年6期)2016-05-09
中共党史研究(2014年1期)2014-04-27
语文知识(2014年11期)2014-02-28
中共党史研究(2013年11期)2013-04-27
