
融合标签语义知识的价值观多标签文本分类
2024-01-20 02:21:46韩泓霖单丽莉孙承杰刘秉权
中文信息学报 2023年10期
韩泓霖,单丽莉,孙承杰,刘秉权
(1. 传播内容认知国家重点实验室 人民网,北京 100733;2. 哈尔滨工业大学 计算学部,黑龙江 哈尔滨 150001)
0 引言
当代中国正处在百年未有之大变局中,国家、社会和个人三个层面都面临着价值重塑的问题。因此,对主流价值观的传播是对中国特色社会主义的自我理解与自我建构,直接切中中国特色社会主义实践最深层次的问题。2020年3月,国家互联网信息办公室发布《网络信息内容生态治理规定》[1],提出鼓励网络信息内容生产者制作、复制、发布含有“弘扬社会主义核心价值观,宣传优秀道德文化和时代精神,充分展现中华民族昂扬向上精神风貌”等内容的信息,并且引导网络信息内容服务平台“坚持主流价值导向,优化信息推荐机制,加强版面页面生态管理”,这将主流价值观内容的认知和传播推向前台。具体地,如何构建主流价值观理论知识体系和计算模型、如何从多个维度识别并测量主流价值观内容等问题成为科学研究的新趋势,也是实践的迫切需求。
同时,随着互联网行业的飞速发展,网络上的用户和文本数量日益增长,每天有数亿篇文章被发表[2],海量数据触手可及,各种类型的数据层出不穷、丰富多样,极大地改变了人们的生产、生活方式。然而,互联网的自由性、便捷性也使得恶意的负向信息几乎可以无成本地在网络上大量传播,充斥于互联网上。因此,识别这些网文的价值观倾向显得尤为重要。
目前,针对网文的审核,大多数网站还采用人工审核的方式,效率很低,长时间审核后,审核准确率也会下降;极少数采用自动计算的方式帮助审核,但往往仅可以识别出正或负两个粗粒度分类,缺少更细粒度的划分。因此,本文的目标是给定文本,为文本自动标注细粒度的价值观标签,实现文本的价值观倾向分析。例如,图1中的文本的目标是能为其自动标注细粒度的价值观标签“敬业乐群”“爱岗敬业”和“爱国敬业”等。

图1 价值观标注示例该文本贴的价值观标签为: “敬业乐群”“爱岗敬业”“干一行爱一行,专一行精一行的敬业精神”“爱国敬业”
本文将为文本自动标注价值观标签的任务,视为多标签文本分类问题来解决,并定义如下: 用TEXT表示样本空间,C={c1,c2,c3,…,cl}为有限标签集合,即候选标签集,假设TEXT中的样本实例text∈TEXT和C的一个子集Y∈2C相关,这个子集称作该实例text的标注标签(简称标签),同时补集C/Y被认为与text不相关。一个多标签分类器h是一个映射TEXT→Y,对每一个实例text∈TEXT分配一个标签子集Y⊆C,Y中所有的标签就是text的标注标签。
不同于单标签分类和多类别分类问题,多标签分类问题为每条文本数据关联多个标签,从多个标签角度理解概括文本语义,是自然语言处理研究领域的重要子课题之一,在现实生活中有许多实际应用,例如,主题识别[3]、情感分析[4]、问答系统[5]等。在有限的计算资源下,多标签文本分类任务仍面临着许多挑战,首先,对文本进行多标签标注需要耗费大量的人力,标注成本较高,这导致标注数据较少且极易标注不全面,给标签的准确预测带来挑战;其次是类别样本不均衡问题,我们把具有稀少标注样本的标签称为“尾标签”,由于样本稀少,使得“尾标签”自动标注更加困难。针对上述问题,目前研究人员主要聚焦如下问题: 如何提高分类模型结果的召回率,尽可能预测出更多的标签,覆盖人工标注标签;如何处理标签样本分布不均情况、缓解“尾标签”问题。
为了解决上述问题,本文提出了一种融合标签语义知识的价值观多标签文本分类方法(Multi-Label Classification Combining Value Knowledge, MCVK),首先,通过在分类模型中融合标签的语义知识,获取标签间的相关性,更好地学习标签与文本之间的语义交互信息,缓解因标注不全面带来的副作用,进而提升多标签分类的准确度;其次,通过将候选标签与文本的语义相似度融合到多标签文本分类模型,降低分类模型对标注数据量的依赖,提升了“尾标签”的标注准确率,尤其有利于解决具有零标注样本的新标签的自动标签问题;最后,为了有效地获取、组织和管理价值观标签的语义知识,我们还构建了一个价值观知识图谱。
本文的主要创新点及贡献如下:
(1) 构建了价值观知识图谱,经调研,是首个公开发表的规模最大的价值观知识图谱。包含四级价值观理论知识体系,49个子类,470个价值观标签词汇,7 182个价值观标签的近义词汇,共173 465条三元组。
(2) 构建了一个价值观方向的细粒度多标签文本分类数据集,既包含粗粒度的正、负和中性三类极性标签,也包含细粒度的价值观词汇标签。其中,细粒度的价值观标签共471个,数据集共包含5 916条标注样本。
(3) 提出了一种多标签文本分类方法,通过两种策略利用标签语义知识提升多标签文本分类性能。其一是利用标签语义知识进行文本表示学习,既融合了标签之间的语义相关性,又得到了每个标签对于文本中不同词的重要程度。其二是利用标签语义知识进行候选标签与文本的相似度计算,并将结果融合到多分类模型,从而有效地缓解了“尾标签”问题。
(4) 本文设计了多组实验,与经典的多标签文本分类方法进行比较,在构造的价值观特定领域的数据集上进行实验对比,实验结果表明,本文提出的方法要优于基线算法,验证了所提出方法的有效性。
1 相关工作
多标签文本分类一直是自然语言处理领域一个十分重要的任务,多年来,众多国内外学者在该问题上投入了大量研究,主要可以分为传统机器学习方法和基于深度学习的方法。
传统机器学习方法传统机器学习方法依据解决问题的角度不同,可以分为问题转化和算法适应两种方法。问题转化方法将多标签问题转化为一个或一组单标签问题,使其能够使用已经成熟的算法来解决。例如,Boutell等人[6]提出的二元相关(Binary Relevance, BR)方法为每个标签单独构建一个独立的二分类器,非常直接但完全忽略了标签之间的相互关系。为了捕获标签之间的相关性,Tsoumakas等人[7]提出了标签幂集分解(Label Powerset, LP)方法,基于所有可能的标签组合,将任务转换为针对多个标签组合的多分类问题,但容易产生样本不平衡问题,且增加了模型复杂度。后来,Read等人[8]提出了分类器链(Classifier Chain, CC)方法,将多标签问题转化为链上的二分类问题,链上后面的分类器预测要基于前面的分类结果,当前面的标签预测错误时,该错误会一直沿着链保留并传递下去,影响后面的标签分类结果,且受链的顺序影响较大,失去了并行实现的可能。
算法适应方法改进传统的单标签分类算法,通过对单标签分类问题的研究学习为多标签分类任务提供经验,进而直接解决多标签分类问题。Clare等人[9]提出了多标签决策树(Multi-Label Decision Tree, MT-DT)方法,利用决策树的思想处理多标签数据,并通过计算熵的信息增益方式,递归构建决策树。André等人[10]提出排名支持向量机(Ranking Support Vector Machine, Rank-SVM)方法,基于SVM的思想,优化线性分类器以最小化经验排序损失。Zhang等人[11]提出了多标签K最近邻(Multi-LabelK-Nearest-Neighbor, ML-KNN)方法,基于KNN的思想,对于每一个实例,先获取距离最近的K个实例,再通过最大后验(Maximum a Posteriori, MAP)概率推理得到该实例的预测标签集合。
基于深度学习的方法随着深度学习飞速发展,深度神经网络在多标签文本分类任务上也取得了很好的效果。Zhang等人[12]提出了多标签学习的反向传播(Backpropagation for Multilabel Learning, BP-MLL)算法,该算法来源于传统的反向传播[13](Backpropagation, BP)方法,使用一种新的误差函数提取特征,预测单个样本时,对应该样本的标签要比未对应该样本的标签排名高,从而实现多标签分类。Liu等人[14]提出了大规模多标签卷积神经网络(Extreme Multi-Label Convolutional Neural Network, XML-CNN)模型,为了获取文档中不同部分更细粒度的特征,在CNN[15]模型上加入了动态的最大池化策略,使模型能够处理大的标签空间。Kurata[16]考虑了标签之间的联系,在模型的初始化参数上优化模型。为了更好地捕获标签间更高阶的相关性,Chen等人[17]将CNN和RNN[18]结合,由CNN抽取语义信息,再经过LSTM[19]以生成的方式预测标签。
在实际应用中,标签通常是有语义信息的,但之前的多数研究仅将标签视为了一个类别,或者仅考虑标签之间的层次关系,而没有考虑标签本身具有的语义信息。因此,Wang等人[20]便考虑了标签的语义信息,对标签语义和上下文语义进行建模。Du[21]通过之前训练得到的词向量模型,将标签转化为词嵌入,映射到同一特征空间,交互学习标签和文本中单词的语义表示,获得每个单词和标签的匹配分数,但却没有考虑依靠标签语义进一步学习特定文档的文本表示。因此,本文主要提出了一种融合标签语义知识来帮助文本表示的方式,同时结合标签-文本相似度计算的方式来实现价值观领域的多标签分类任务。
2 知识图谱与数据库构建
2.1 价值观知识图谱的构建
为了构建价值观知识图谱支持文本价值观多标签分类,首先,需要挖掘多维度和多粒度的价值观知识,构建科学的知识体系,设计合理的数据模式(图2)。其中,价值观理论知识体系是典型的专家知识,为四层的层次结构,顶层是中国文化和中国精神两个大类。第二层,中国文化又分为三个子类,中国精神又分为46种精神子类,例如,“长征精神”“奥运精神”等,前两层的大类和子类统称为价值观概念。第三层为每个子类包含的价值观内涵,形式为具体的价值观描述词汇,称为价值观核心主词,例如,“自强不息”“大公无私”等,共计正向词254个。人工为每个正向词标注了一个负向词,共216个,例如,“自暴自弃”“自私自利”等。最后一层即第四层为更细粒度的价值观词汇,称为核心词,用于解释对应第三层核心主词的语义内涵。为了丰富核心主词和核心词的语义知识,我们还收集了释义、出处、例句、主体、层级和极性等属性知识,其中主体指价值观主体,共有七种,为“个人”“家庭”“团体”“组织”“社会”“国家”“世界”,层级指六种社群,其值域为“个人”“家庭”“社会”“国家”“世界”和“自然”。

图2 价值观知识图谱的数据模式
价值观知识图谱的构建采用典型的人机合作模式,通过专家标注、审核和校对保证知识的准确性,又通过机器自动知识抽取和自动标注提升知识获取的效率。综合运用机器自动抓取、网页内容解析、去噪、信息抽取等技术从在线词典中自动抽取词的属性信息,并运用知识去重、聚合和补全等技术对获取的知识进行融合。
最后,再人工设计规则进行知识校验和纠错,将最终的知识条目存储到数据库。具体构建流程如图3所示,其中梯形框是人工过程,矩形框是机器自动完成过程。
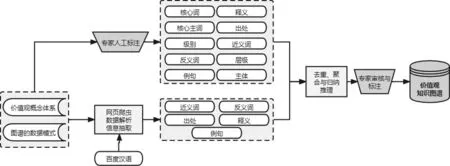
图3 价值观知识图谱的构建流程图
图4给出了价值观核心主词“守礼知节”在知识图谱中的部分属性以及关联的其他实体和逻辑关系。特别地,矩形框表示实体,带箭头的线条表示关系或属性,椭圆形表示属性值。
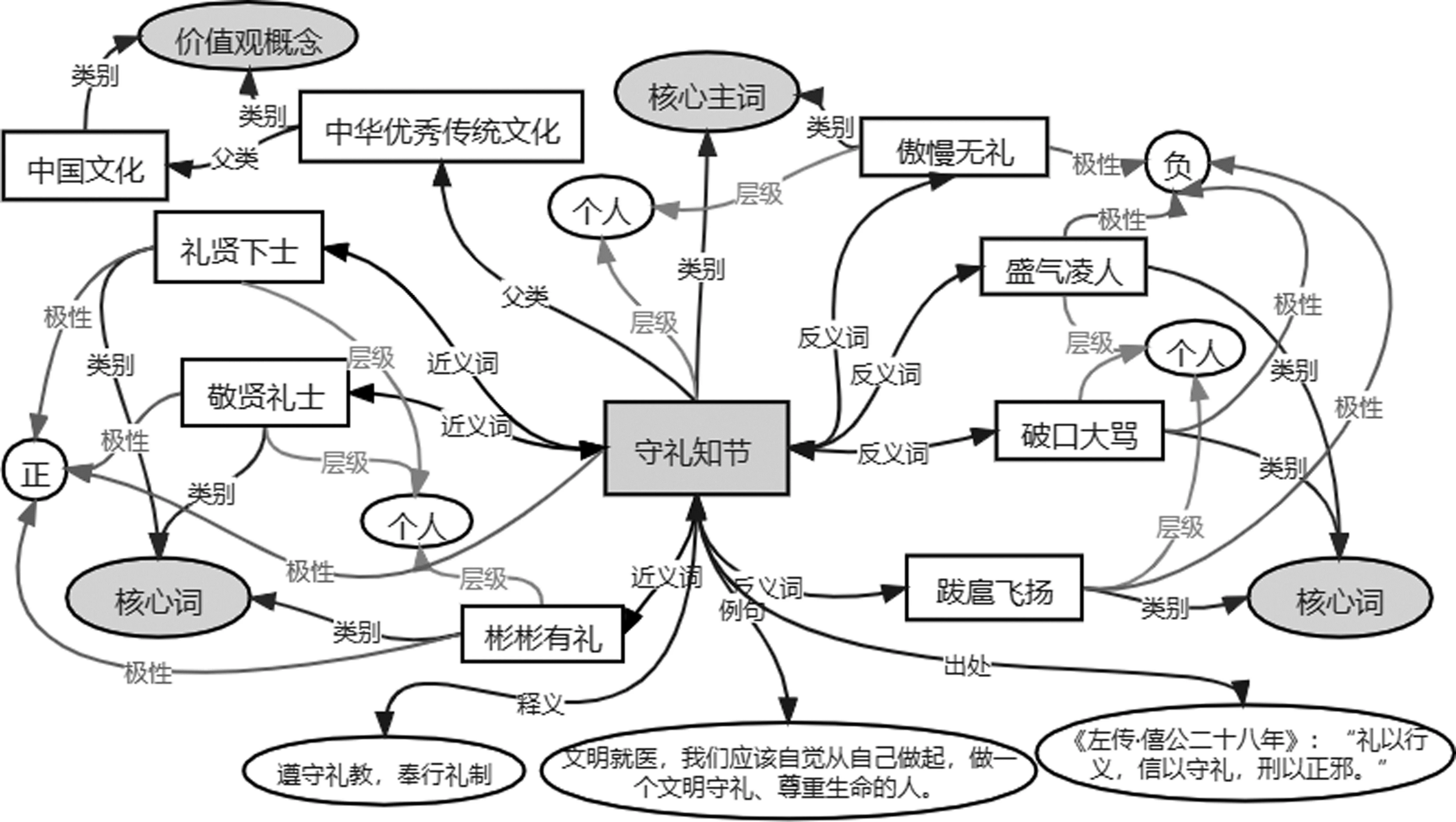
图4 核心主词“守礼知节”在知识图谱中的关联节点以及属性示例
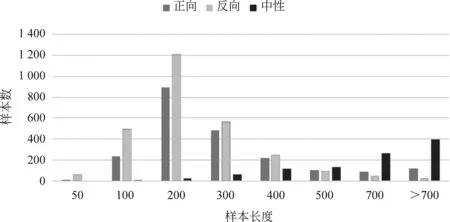
图5 不同长度的样本数量分布图如横坐标为100表示样本包含字数大于50且小于或等于100个字的样本数量

图6 不同标签样本数统计图例如,横坐标为10表示样本个数大于5且小于或等于10的标签数量
我们选取基础词表中的第三层知识,即价值观核心主词作为文本分类的正向候选标签词,负向候选标签词来源于正向标签词的反向词;使用第四层更细粒度的核心词作为候选标签词的近义词属性,用于丰富候选标签词的语义知识。
2.2 多标签文本分类标注数据集的构建
本文构建了一个价值观领域的多标签文本分类数据集。数据集包含5 916条样本,共471个价值观候选标签。具体包括254个正向标签,2 153条正向样本;216个负向标签,2 757条负向样本;1个中性标签,1 006条中性样本。平均每条样本标注1.53个标签,每个标签有19.20条样本。
标注文本数据来源于权威性的官方主流网站: 人民网、新华网、中国新闻网、人民公安报等。正向数据为新闻篇章中有代表性的段落,负向数据为新闻篇章中描述不良行为的段落,中性数据多为新闻报道中对某一事件、通知或规定的客观陈述。我们采用文本和候选标签字符串相似度计算以及人工审核确认相结合的方式,为文本标注标签,并对标注数据集按照6∶2∶2的比例划分为训练集、验证集和测试集,具体数量统计如表1所示。
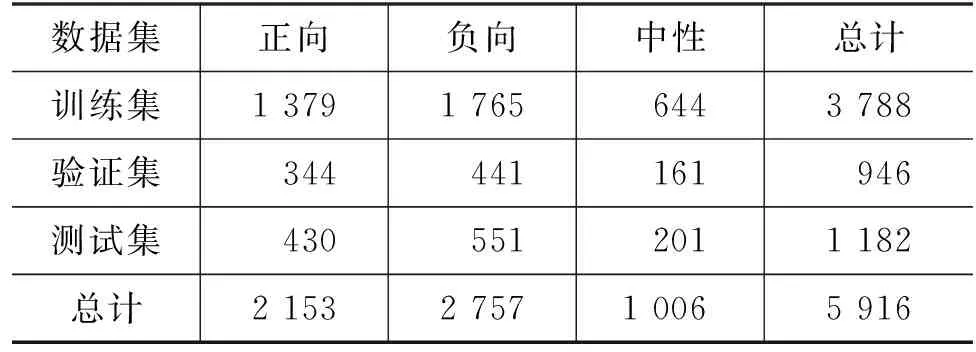
表1 正负中类别划分后的数据集数量
据调研统计,我们的数据集是国内首个价值观方向的包含正负向数据的细粒度多标签文本数据集。同时,我们还统计了数据集的样本长度属性,如图 5所示,以及各个标签所具有的样本个数,如图 6所示。
由统计结果可见,样本长度主要集中在100~300字;绝大多数的标签有5~15个样本;总体来看,数据集的样本长度比较适宜,数据集标签粒度比较精细,覆盖价值观范围广并且比较全面,但有超过30个正向和超过100个负向标签的标注样本数不超过10个,对这些样本稀少的“尾标签”进行正确自动标注比较困难。
3 融合标签语义知识的多标签分类方法(MCVK)
受Wang等人[20]利用标签信息的注意力机制思想的启发,本文为了充分利用价值观候选标签自身的语义信息和标签近义词知识,重新学习文本表示,使用了两种策略构造模型。我们提出了一种融合标签语义知识的多标签分类方法,模型结构框架如图7所示。模型通过两种策略融合标签语义知识提升多标签文本分类的性能,见图7中由价值观知识图谱射出的两条连线。第一种策略是利用标签语义帮助进行文本表示学习,如图中标注①处。基于注意力机制,融入标签语义知识,获取标签对于文本中每个词的重要程度,经变换和文本嵌入相乘得到该文本的表示学习向量,再经全连接层得到不同标签的预测结果;第二种策略是融合标签语义知识进行标签与文本的相似度计算,并将结果融合到主模型输出结果辅助进行分类,如图中标注②处。本文将上述方法称为融合价值观语义知识的多标签分类(Multi-Label Classification Combining Value Knowledge, MCVK)。
3.1 标签语义知识帮助文本表示学习
具体来讲,一段文本text可以经过分词表示为n个词的序列,text={w1,w2,w3,…,wn},其中,wi∈dim为某个词的向量表示,候选标签集表示为C={c1,c2,c3,…,cl},其中,ci∈dim为每个标签的词向量表示,l是候选标签总个数。
对于待分类文本,直接在预训练词向量表中查询文本分词后对应的词向量wi构成矩阵即可表示文本,对于标签词,任一标签ci可经过分词转换为k个细粒度的子词,再使用预训练词向量模型获得所有子词的标签嵌入wj,然后对所有子词嵌入取平均,即得到每个标签的向量表示,如式(1)所示。本文使用基于人民日报数据训练好的Word2Vec预训练模型[22]获得词向量。
(1)
这样可以将文本和标签表示映射到同一空间,且使用预训练词向量模型可以很好地利用标签的语义信息,而不仅仅将标签视为一个二元类别,从而隐式地学习了标签之间的相关性,有利于提升分类的性能。
为了捕获标签和文本中各个词的隐藏语义关系,我们基于注意力机制,计算得到所有标签和文本中不同词的语义相似性,获得词-标签注意力得分矩阵A,如式(2)所示。
A=CTtext
(2)
为了更好地捕获文本段落中的连续单词(称作短语)信息,我们将词-标签注意力得分转换为短语和标签的注意力得分。具体地,我们考虑长度为2*r+1的短语,文本首尾长度不足以截取短语的占位补足,通过卷积的方式,并引入相似度度量方法的非线性变换,获取到了短语-标签的注意力得分矩阵U,如式(3)所示。
U=relu(conv1d(Ai-r: i+r))
(3)
同时,通过最大池化操作抽取对于每个短语的最重要标签权重,再经Softmax获得该篇文本的所有短语的注意力权重值β,如式(4)所示。
β=Softmax(max-pooling(U))
(4)
在得到文本中所有短语的权重之后,对文本段落中的每个词进行加权,可以很简单的得到加权后的文本序列表示V,如式(5)所示,即利用了标签语义知识帮助文本表示学习。
V=mul(text,β)
(5)
3.2 融合语义知识进行标签与文本的相似度计算
为了给价值观多标签分类提供更多的补充知识,帮助模型提升价值观内容智能认知的能力,我们利用了价值观知识图谱中候选标签的近义词属性,将标签及其近义词列表和待预测文本进行相似度计算,为每个候选标签计算一个相似度得分MatchScore,如式(6)所示。
MatchScore=sim(concat(label,synonyms),text)
(6)
其中,label表示候选标签,synonyms表示该标签的所有近义词集合,concat为对标签及其近义词的字符串连接操作,sim为计算两个字符串的相似度操作,本文使用了Levenshtein 相似度。
3.3 多标签预测
最终,我们将学习到的文本表示序列经过两个全连接层和一个非线性层,得到深度学习模型下每个标签的预测结果概率P,如式(7)所示。最后再与融合价值观知识的标签-文本语义相似度得分MatchScore进行加权求和,输出最终的预测结果O,如式(8)所示。
其中,α为两个预测结果之间的权重参数。经过多轮测试得到相对应的取值。
我们的模型使用BCEWithLogitsLoss作为损失函数,它在多标签分类任务中被广泛使用,可分割为Sigmoid和BCELoss函数,如式(9)所示。
(9)
其中,lossi表示第i个标签的损失loss,共l个标签,yi为该标签的标准结果,xi为该标签的预测结果,σ(xi)即Sigmoid操作。最后对BCEWithLogitsLoss所有标签的损失求和即为该轮训练的模型损失。
4 实验与分析
4.1 评价指标
本任务为多标签分类任务,我们选用微平均(Micro-Average)、宏平均(Macro-Average)和平均精度均值(Mean Average Precision, MAP)作为模型性能的评价指标。其中,公式中的P、R、F分别指预测结果的精确率(Precision)、召回率(Recall)和F1值(调和平均值),且全部为针对预测的前k个结果计算,即Precision@k、Recall@k和F1@k。
进一步地,微平均指对预测的每个样本取平均,具体可分为Micro-P、Micro-R、Micro-F,定义如式(10)~式(12)所示。
TP表示模型返回的k个结果中正确的个数;FP表示模型返回的k个结果中错误的个数;FN表示标准正确结果中没有被模型前k个返回的个数。“__”表示对所有样本取平均。
宏平均指对于预测的结果,针对每个标签类别取平均,具体可分为Macro-P、Macro-R、Macro-F,定义如式(13)~式(15)所示。
其中,Pi、Ri、Fi分别指预测结果第i个标签的P、R、F1值,L表示标签总个数。
平均精度均值(MAP)表示多个文本的平均精度,AP(Average Precision,)衡量模型的所有正确结果是否都有较高的排序,考虑了模型输出的所有正确结果。具体定义如式(16)、式(17)所示。
其中,k表示模型输出的结果个数;nums表示模型的输出结果中正确的个数,即在标准结果中的个数;rel(j)是一个指示函数,当前的第j个输出结果是正确的时为1,否则为0。式(17)中,text表示某个待预测文本;AP(text)表示文本text预测的所有正确的标签的平均精度。
最后,由于数据集候选标签数量较多,存在语义相似情况,例如,“自强不息”和“刚健自强”“不怕牺牲,不畏艰险”和“不屈不挠”等。同时,文本数据的标签标注也存在漏标问题,给预测结果的评价带来挑战。因此,为了保证评价结果的合理性,我们将模型预测标签与标准答案标签作语义相似度计算,当两词的语义相似度超过0.7时,认为预测正确。
我们采用基于12GB新闻语料、20GB百度百科语料以及90GB小说语料训练的64维中文Word2Vec模型计算标签相似度,如表2所示。
4.2 实验设置
实验基于PyTorch深度学习框架,使用基于人民日报数据训练好的Word2Vec预训练模型[22]获得文本及标签的嵌入表示,词向量维度dim=300,抽取文本段落中连续的单词时取r=30,文本的最大长度限制为max_len=512,长度不足的补全,长度超过的在末尾截断,训练过程中使用的优化器为Adam[23],学习率为0.001,Dropout设定为0.3。
4.3 对比模型
为了验证我们提出算法的有效性,我们选择FastText[24]、Transformer[25]和BERT[26]三种十分经典的模型作为对比算法。
FastText[24]使用浅层网络却往往能取得和深度网络相媲美的精度,通过词袋模型和n-gram方式表征语句,还使用了子字信息,通过隐藏表征学习类别间的共享信息,得到文本分类标签。
Transformer[25]使用Encoder-Decoder结构,在文本分类任务中,只使用了Encoder部分,通过Attention机制,捕获文本的上下文信息,最后经全连接层输出分类预测结果。
BERT[26]采用masked语言模型对双向Transformer进行预训练,以生成双向语言表征,后续只需要添加一个额外的输出层进行微调,就可以在各种下游任务中取得的较好结果。
在实验中,我们还比对了TextRCNN[27]方法,该方法在样本数据充足、标签数量较少的情况经常能取得很好的结果,但在本实验的数据集上,结果十分糟糕,分析原因,这可能是因为该方法模型结构较为复杂,每个标签都需要大量的训练数据来捕获标签特征。
4.4 实验结果与分析
4.4.1 对比实验结果及分析
在我们构建的价值观数据集上,分别测试了我们的模型MCVK和三个对比模型,并取top@3和top@1的两种结果计算评估指标,表3是对比实验结果。
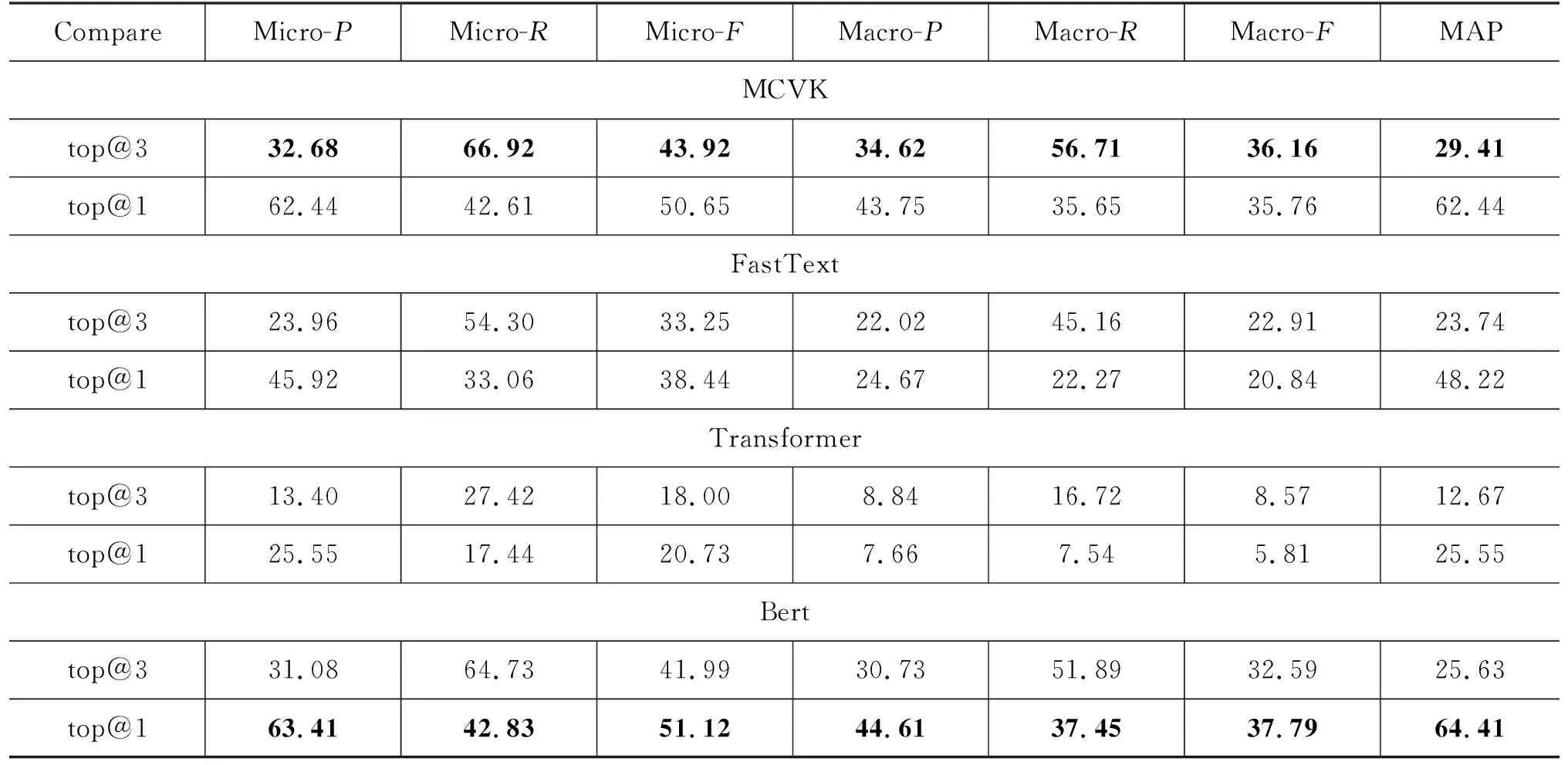
表3 对比实验结果 (单位: %)
由实验结果可以看出我们的模型的有效性。在比较top@3和top1的结果时,我们发现模型在top@1的预测精确率还是有一定保障的,对于共471个价值观细粒度标签,我们的模型最终在top@1指标上能达到62.44%的精确率,在top@3上达到66.92%的召回率。同时,随着预测个数的增多,top@3的精确率明显下降,但相应地,召回率有了明显的提升,这是符合常识的。
我们的MCVK模型的预测结果明显优于FastText和Transformer模型。其中,FastText模型优于Transformer模型,这表明FastText可以较好地处理少样本问题,但其并没有利用标签语义信息,使其帮助文本表示,仅将标签视为一个类别,这也是导致其结果低于我们的MCVK模型的原因,在微平均F1值上平均低了11.44%。
我们的模型在所有的评价指标上均远远超过了Transformer模型,这可能是因为Transformer模型较为复杂,且没有用类似BERT模型的大规模数据进行预训练,只用Transformer来处理我们的标注数据较少的数据集能力还是较弱,较深层的神经网络往往需要更多更庞大的数据来学习训练。相比之下,FastText模型则十分简单,使用了浅层网络,因此在我们的数据集上结果较为不错。
和BERT模型相比,我们的MCVK方法在top@1上的结果略显不足,平均低了1.18%,但随着预测标签的数量增多,我们的模型效果逐步超过了BERT模型,在top@3上的结果上平均高出了3.11%,尤其是宏平均结果,提升明显。这表明在价值观方向的数据集上,BERT模型在单分类任务上的结果较好,但在多标签任务上,我们的模型要略优于BERT模型,可以更好地缓解标签分布不均的问题。
4.4.2 消融实验结果及分析
我们还针对第二种融合标签知识的方式——标签-文本相似度计算进行了消融实验,表4是消融实验结果。

表4 消融实验结果 (单位: %)
通过消融实验的对比结果能看出,融合标签-文本相似度得分后,我们的模型结果有了明显提升,所有指标平均提升 13.57%,尤其是宏平均结果提升最多,即受标签样本分布不均的影响减弱。融合价值观标签知识进行文本语义相似度方法完全不受样本分配不均的影响,这对于少样本标签的预测有很大的帮助。
4.4.3 尾标签实验结果及分析
我们还针对具有较少标注样本的“尾标签”进行了实验,表5是选取具有划分前数据集样本数小于等于10的标签进行实验的结果,选取的标签数占所有标签的32.70%。

表5 具有样本数小于等于10的“尾标签”结果 (单位: %)
由结果可以看出,我们的模型在融合了价值观知识标签,进行标签-文本语义相似度计算后,尾标签的结果均有很大的提升,可以较好地缓解“尾标签”问题。尤其是宏平均结果,最终top@1的F1值平均提升了10.59%,top@3的F1值平均提升了10.65%。
5 结语
在当前全媒体融合时代,针对传播内容的主流价值观精准传播的迫切需求,面向基于主流价值观内容精准认知的任务,本文提出了一种融合标签语义知识的文本价值观多标签分类方法MCVK。本文首先构建了包含价值观理论知识体系和扩展语义知识的价值观知识图谱,并构建了一个价值观分析方向的细粒度多标签文本分类数据集,最终设计实验验证了本文方法在数据集上解决文本价值观多标签分类问题的有效性。
本文方法采用了两种方式融合标签语义知识,第一,在进行文本表示学习时使用了标签本身的语义信息,隐式地获得标签之间的相关性;第二,利用标签在价值观知识图谱中相关联的价值观知识,将其融入标签与预测文本的相似度计算中,较好地缓解了“尾标签”样本不足的问题,实验结果表明,我们的方法可以较好地解决价值观多标签分类问题,最终在top@1结果上能达到62.44%的精确率,在top@3上达到66.92%的召回率,融合标签知识相似度得分后,所有指标平均提升 13.57%,较好地利用了知识图谱知识。
本文在篇章级通过价值观标签的自动标注实现了文本的价值观分析,对于来源广、解析难、传播快和影响大的网络多媒体信息,实现主流价值观的内容认知和精准传播,对于净化网络空间、维系和谐稳定的社会环境具有重大的现实意义;也为未来价值观计算方向的深入研究和发展创立了良好的开端。然而,价值观分析是十分复杂的问题,往往涉及不同的价值观主体,未来可以对文本中价值观主体进行识别,针对不同的价值观主体进行更精准的分析;另外,聊天和微博等短文本的价值观分析由于上下文信息有限,给价值观分析带来更大的挑战。这些都需要更多的研究工作来应对和解决。
猜你喜欢
小天使·一年级语数英综合(2022年4期)2022-04-28 08:42:36
建材发展导向(2021年6期)2021-06-09 05:58:06
开放教育研究(2020年2期)2020-03-31 01:54:14
车迷(2018年11期)2018-08-30 03:20:32
海峡姐妹(2018年3期)2018-05-09 08:21:02
现代语文(2016年21期)2016-05-25 13:13:44
公民与法治(2016年10期)2016-05-17 04:12:58
现代企业文化·综合版(2016年6期)2016-05-14 16:38:34
学习月刊(2015年9期)2015-07-09 05:33:44
计算机工程(2015年8期)2015-07-03 12:20:27
