
基于语义相关性的命名实体识别算法研究
2024-01-20 02:21袁运新樊腾飞聂为之
中文信息学报 2023年10期
袁运新,樊腾飞,聂为之
(1. 天津大学 电气自动化与信息工程学院,天津 300072;2. 天津大学 国际工程师学院,天津 300072)
0 引言
近年来,随着大数据时代的到来,文本数据海量增长,通过自然语言处理来获取文本数据中的有效信息,可以更智能地应对用户需求,给予用户更好的使用体验,因此该技术在电商平台的智能客服系统、社交媒体平台的舆情监控以及购物平台的个性化商品推荐等多个领域有着越来越广泛的应用。在自然语言处理中,命名实体的有效识别,对相关信息的挖掘和分析起着至关重要的作用,其效果对于自然语言处理的后续任务,如关系抽取、问答系统、语义解析等有着直接联系。
命名实体识别技术是自然语言处理领域中的一个重要分支,它是通过对文本数据进行序列标注,并设计有效的命名实体识别算法,从海量的文本数据中抽取出文本中的人名、地名、机构名等具有实体意义的专有名称并加以归类,因此命名实体识别技术可以作为一种多分类任务,实现对海量文本数据中实体的准确识别。由于深度学习模型具有强大的泛化能力,利用神经网络方法使用大量人工标注数据集,能够针对特定数据训练得到高性能的实体识别模型,并取得不错的效果,但是随着大数据时代的不断发展,文本数据中的实体类型变得愈发复杂多样,特别是社交媒体[1]、生物医学[2]等领域,实体组成结构复杂,在不同领域场景下存在实体分类模糊等情况,使得用人工标注的方法标注大量训练数据变得异常困难,耗时、耗力且代价昂贵,已经无法满足用户需求。因此,如何经济、高效地从海量文本数据中获取更多有效的监督数据进行命名实体识别已经成为自然语言处理中的重点研究问题。
针对实体信息的抽取,至今已经有很多优秀的方案和算法被提出,Lample等[3]提出的LSTM-CRF模型和Ma、Hovy等[4]提出的LSTM-CNNs-CRF模型利用句子整体语义信息识别实体,取得较好成果;Cetoli等[5]利用图嵌入网络挖掘句子中字词依赖关系进行命名实体识别,但这些方法往往忽略了实体与句子中其他词语的关联关系,同时也不符合人实际的认知过程。在人工标注实体的工作中,人为识别句子中实体的方式一般是通过句子中相关短语和重要的词进行判断,例如,推理“Jack traveled a lot last month in Swadzxc.”这句话中的实体,可以根据“traveled ...in”这个短语推测单词“in”后应该是一个地点实体,也就是可以选择句子中的短语或者词组来进行推理得到实体。但是通常在文本数据中短语类别繁多且词组构成复杂,这些短语和词组数据若是通过人工标注获取同样显得异常困难。因此,本文拟在现有实体标注数据的基础之上,基于文本信息自身的相关性,并利用句子中的实体和其他词之间的语义关联性,来提高在开放环境下实体识别准确率。基于此思路,本文提出“实体联合器”的概念,“实体联合器”可以看作是实体的伴生词语或伴生实体,往往一同出现,属于固定搭配,在语义表达上有一定的关联性和一致性,这种“实体联合器”可作为额外的监督数据帮助模型进行命名实体识别。同时,实体联合器往往由多个词组成,具有一定的模式化,可以采用无监督的方式,实现对未知文本中“实体联合器”的识别,进而有效减少人工成本,实现对文本数据中实体的准确识别。
针对上述问题,本文提出一种基于语义相关性的命名实体识别模型。模型整体框架如图1所示,首先,针对“实体联合器”的识别问题,充分考虑实体联合器组合的模式化及其与句子整体的关联信息,利用图结构对关联信息的表征作用,实现对文本信息中“实体联合器”的有效识别。之后,通过实体联合器与实体的强关联性,构建基于实体联合器表征的实体识别模型,利用实体联合器对实体特征的促进作用,实现实体识别模型鲁棒性的提升,进而提升对文本数据实体识别的准确率。模型主要包含两个子模块: 实体联合器识别模型和实体识别模型,后面会对其进行详细介绍。本文主要贡献如下:
(1) 提出“实体联合器”的概念,并基于此提出一种基于语义关联性的实体联合器识别模型,通过文本关联结构信息实现对无标签句子中实体联合器的获取。
(2) 基于实体联合器表征的实体识别模型,充分利用句子、实体联合器和实体的语义关联性,构建两种有效的约束机制,即实体类型约束和特征一致性约束,加强实体联合器在特征学习过程中的指导作用,实现对实体表征模型的性能提升,从而提高实体识别的准确性。
(3) 本文在公开的数据集CoNLL03和NCBI Disease上评估了模型的性能,并与现在具有代表性的命名实体识别模型进行比较分析,通过实验证明了本文方法的优越性。
1 相关工作
随着深度学习的不断进步和发展,命名实体识别研究的重点已经由原来的基于统计机器学习方法转变为基于深度学习方法。通过神经网络方法利用现有的大量标注数据训练命名实体识别模型,并取得了巨大成功。因此,本节将针对当前主流的命名实体识别算法进行介绍。Hammerton等[6]首次利用长短时记忆网络(Long Short-Term Memory, LSTM)来处理命名实体识别任务,通过引入“门控”机制来控制信息的累计速度,从而解决了递归神经网络(Recurrent Neural Network, RNN)中存在的长距离依赖问题;Collobert等[7]提出的CNN-CRF 模型将神经网络方法和条件随机场结合,在命名实体识别中取得突破性进展;Huang等[8]将双向长短时记忆网络和CRF相结合来学习文本序列的上下文信息,并减少对字词嵌入的依赖。Bahdanau等[9]首次将注意力机制与NLP领域相结合;Tan等[10]探索了将自注意力机制应用在序列标注问题中,学习句子内部信息;ELMo[11]和BERT[12]等预训练语言模型的出现,通过对通用领域的文本进行预训练,在命名实体识别任务中获得显著的性能提升。这些方法的共同点是利用现有的只标注实体的数据集训练模型,但高质量实体识别模型需要大量的人工标注数据。
近年来,关于如何减少人工标注以及高效利用现有的语料库获取额外的监督信息问题越来越受关注。其中面对低资源的命名实体识别研究,主要工作是集中在基于词典的远程监督方法上[13-14],这些方法使用特定领域实体词典学习命名实体模型,不需要额外的人工;Lin等[15]和Shen等[16]利用主动学习方法进行序列标注,要求高效利用人工标注有用的实例进行命名实体识别;迁移学习方法[17-18]利用源域数据和模型完成目标域任务模型构建,降低了目标域模型对标注数据数量的需求;Lan等[19]提出的Connet框架通过利用多源数据进行训练,可以使用少量的监督信息实现命名实体识别;Lin 和Lee等[20]通过人工标注额外的监督信息进行命名实体识别。这些方法在一定程度上解决了人工标注费时费力的问题,并在部分公开数据集上取得了较好的识别效果,但这些方法要么是摆脱训练数据或缺乏明确的标注过程,要么是通过人工标注额外的监督信息来训练模型以减少成本。因此,针对上述问题,本文考虑减少人工标注的同时,高效利用现有语料库数据,通过文本信息自身的相关性获取更多重要的监督数据,帮助模型进行命名实体识别。
2 模型框架
本文提出了一种基于语义相关性的命名实体识别算法模型(图1),主要包含实体联合器识别模型Cm和实体识别模型Em两个子模型,训练过程通过两阶段训练: 先进行实体联合器识别模型训练,将其输出的结果再次作用于实体识别模型,并进行实体识别模型训练,进而提升对输入文本数据的识别准确度,具体如下: ①实体联合器识别模型: 通过对文本数据的预处理构造句子图Gs,并以中心词节点xi的一阶邻居词节点子图进行分解,将中心词节点所对应的N个词节点子图Gw作为图嵌入网络的输入获取词节点嵌入特征矩阵Fw,设计一个分类器实现了词节点的分类,进而获取句子中的实体联合器; ②实体识别模型: 将实体联合器识别模型的输出结果以及原始文本数据作为实体识别模型的输入,通过词嵌入层,并经由BiLSTM层和Structured Attention层之后获取更全面的语义信息,形成基于注意力表征的句子特征fs和实体联合器特征fc,为了学习与增强实体联合器的特征表示,本文设计了两种约束机制,强化实体联合器在特征学习过程中的指导作用;基于全局注意力机制融合原始句子隐藏层状态特征H和fc,获取实体联合器增强表示的句子特征H′;将H′与H相连接作为CRF的输入进行序列标注,实现了对句子中实体的精准识别。下面对本文方法进行详细介绍。
2.1 数据预处理
该网络模型的输入为文本信息,对于给定的训练数据集中的一个句子x={x1,x2,…,xN},对应标签为y={y1,y2,…,yN},其中,xi表示句子中每个词,yi为每个词xi所对应的标签类别,可以为{O, B-PER, I-PER, B-MISC, I-MISC, …}。由于句子中实体词和非实体词之间存在一定的语义关系,因此本文利用词向量之间的语义相似度,获取句子中和实体语义密切相关的一系列词,并将其作为额外的监督数据帮助模型进行命名实体识别,这些词被定义为: 实体联合器,即实体e可由实体联合器表示:t={(x1,x2…)→e}。高质量的词向量表示对于实体联合器的获取至关重要,为了更准确获取低频词的词向量并充分捕获每个单词内部结构信息,本文采用基于词级别和字符级别的向量,得到每一个词xi所对应的词向量Wi=[wi:ci],其中词级别向量wi从100维Glove[21]预训练词向量中获取,字符级别向量ci利用Xin等[22]所提方法进行学习。通过句子中实体词向量We和其他非实体词向量Wo相互内积得到内积分数Escore=〈We,Wo〉,再利用归一化方法将Escore归一化到区间[0,1],选择归一化分数大于阈值α1(0≤α1≤1)的词作为实体联合器词。如图2所展示的示例,实体词和另外7个非实体词所对应的词向量内积分数Escore的归一化分数分别为“0.66,1,0.81,0.87,0.13,0.77,0”,若取α1=0.7时,则选择“had a pleasant ... with”作为Thomas这个B-PER实体的实体联合器t1={x2,x3,x4,x6}。由于句子中可能存在多个实体{e1,e2,…},因此需要先转换数据格式以确保每个句子中仅仅存在一个实体标注,最终获取的新训练数据包含一个实体和该实体所对应的实体联合器标注数据。
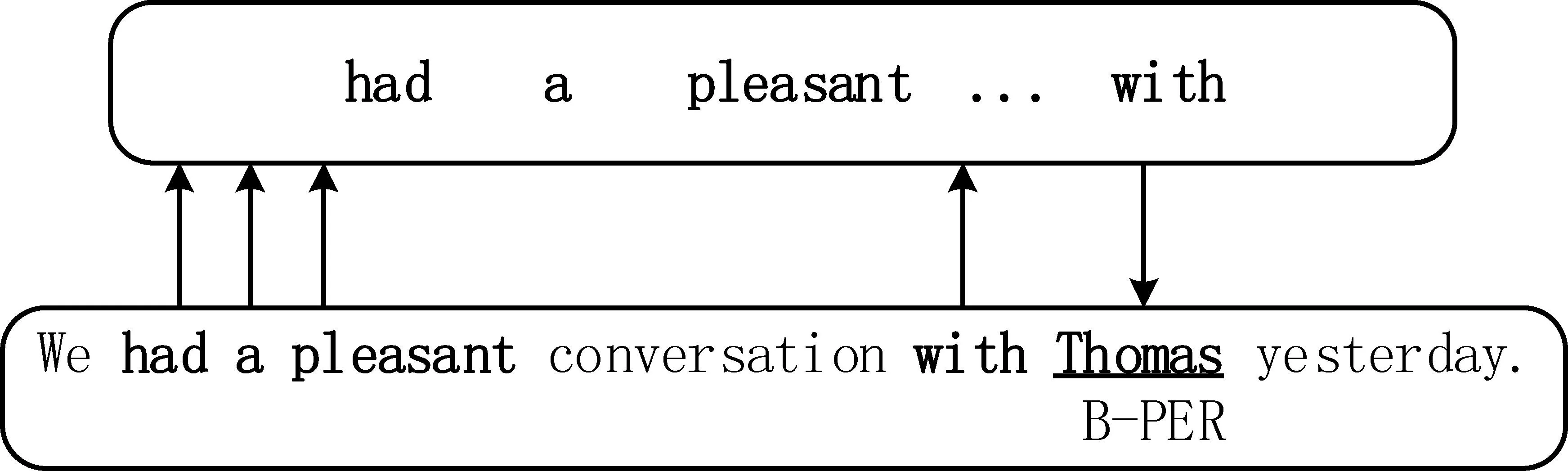
图2 实体联合器示例
2.2 实体联合器识别模型
通常情况下,句子中实体联合器词个数多于实体词个数,所以句子中实体联合器一般比实体含有更加丰富的结构信息,同时由于实体联合器往往为固定的搭配,彼此的关联性更紧密,而图嵌入网络能够很好地捕获这些结构信息,因此本文探索了引入图嵌入网络并基于子图之间的关联性,充分利用句子中实体联合器的结构信息,通过文本关联结构信息实现实体联合器的抽取。实体联合器识别模型如图3所示,主要包括图构造和图嵌入两部分,下面进行具体介绍。
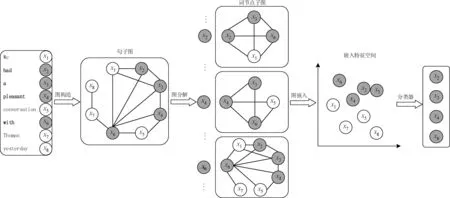
图3 实体联合器识别模型结构图
2.2.1 图构造
由于原始句子是没有图结构的纯文本,并且自然语言语句中包含歧义现象,在图构造过程中会存在语句与图的映射之间在语义上形成一对多的关系,因此本文基于输入的文本序列信息,利用词与词之间的语义相似度关系,通过顺序边和语义边进行融合,构造一张图Gs=(V,E)保存这个句子的语义信息和结构信息,其中,V是词节点x1,x2,…,xN的集合,E是边的集合,具体边构造方式如下: ①顺序边: 按照句子中词节点x1,x2,…,xN的顺序依次连接,保证了词节点间的结构顺序,允许利用句子的上下文信息; ②语义边: 根据句子中词节点xi和xj对应的词向量Wi和Wj相互内积得到内积分数Escore=〈Wi,Wj〉,其中1≤i,j≤N且i≠j,利用归一化方法将Escore归一化到区间[0,1],选择归一化分数大于阈值α2的词节点xi和xj进行连接,保存了语义相关的词与词之间的结构信息。
2.2.2 图嵌入
为了进一步对句子图的词节点进行分类,依次选取词节点xi作为中心词节点,并取其一阶邻居子图将句子图Gs分解为N个词节点子图Gw,并添加一个节点特征,从而区分词节点子图的中心词节点和其他词节点;然后利用图神经网络(GNN)[23]嵌入词节点子图Gw,捕获中心词节点的一阶邻居子图的结构信息,并将这些结构信息聚合到中心词节点xi,获取每一个中心词节点的嵌入特征fi,得到词节点嵌入特征矩阵Fw={f1,f2,…,fN},最终通过一个分类器,获取每一个中心词节点的分数Si,如式(1)所示。
Si=Softmax(Q2relu(Q1Fw))
(1)
其中,Q1,Q2分别为可学习参数矩阵。
为了对句子图中的词节点进行分类,进而获取句子中的实体联合器词,将标注为实体联合器的词节点作为真实标签,并引入交叉熵损失函数,如式(2)所示。
Lgraph=-∑S′ilog(Si)
(2)
其中,S′i代表当前样本所属类别的one-hot编码。
2.3 实体识别模型
为了将实体联合器作为额外的监督数据,联合句子帮助模型进行实体识别,增强模型的泛化、迁移能力,通过特征增强和序列标注两个阶段联合训练实现对句子中实体的精准识别。其中,特征增强阶段采用经典的BiLSTM网络提取句子中词语的语义表征,并引入两种注意力机制分别关注句子和实体联合器中的局部和全局语义信息,通过利用两种约束机制对实体联合器特征进行增强表示,即设计两种损失函数分别对实体类型和特征一致性进行约束,确保实体联合器在特征学习过程中的指导作用;序列标注阶段利用条件随机场(CRF)[24]作为解码器获取实体。
特征增强阶段对于输入的带有实体和实体联合器标注的新训练数据,通过词嵌入层获取每一个词xi所对应的词向量Wi,并输入到BiLSTM层提取句子中每个词xi所对应的隐藏层状态特征hi;为了更多地关注句子局部的语义信息,通过引入结构化注意力机制(Structured Attention)[25]学习多组权重向量来拟合句子中不同成份的重要性,深入捕获句子和实体联合器语义信息,获取基于注意力表征的句子特征fs和实体联合器特征fc,从而增强句子和实体联合器的语义特征表示,并有效去除文本冗余信息。计算方式如式(3)、式(4)所示。
其中,H代表了句子中所有词的隐藏层特征矩阵,C代表了句子中所有实体联合器词的隐藏层特征矩阵,U1和和U2代表了计算句子和实体联合器注意力分数的可学习参数矩阵,αs和αc分别代表了句子和实体联合器特征的注意力权重。
为了把关联实体的类型作为监督来指导实体联合器特征表示,采用了经典的交叉熵损失函数实现对实体类型约束,如式(5)所示。
LC=-∑logP(type(e)|fc)
(5)
其中,type(e)表示实体e的标签类别。
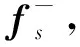
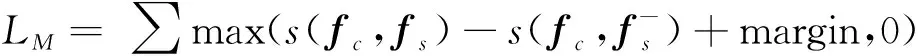
(6)
其中,margin为边界阈值,s(·)为特征相似度度量函数,本文采用欧氏距离来计算两两特征之间的距离。
为了进一步融合原始句子的隐藏层特征H和基于注意表征的实体联合器特征fc,获取基于实体联合器增强表示的句子特征H′,通过引入全局注意力机制(Global Attention)[26],关注当前单词与句子中其他单词的相关性,得到该单词在句子层面的特征表示,深入学习句级别的语义信息,如式(7)所示。
(7)
其中,v,W1,W2为可学习参数矩阵,α为实体联合器增强的句子特征的注意力权重。将原始句子隐藏层特征H和H′相连接(H+H′)作为CRF层的输入。
序列标注阶段本文所使用的CRF已经被广泛应用在最优的命名实体识别模型中[3-4]。CRF主要是通过在两个连续标签之间添加转移分数来增强标签之间的依赖性,以及在解码过程利用维特比算法计算最佳标注序列,从而帮助模型进行更好的判别分类。对于输入文本序列x的标注序列y的分数Score(x,y),如式(8)所示。
(8)
其中,Pi,yi表示第i个词对应的第j个标签的得分,Tyi,yi+1表示标签yi到yi+1的转移分数。
则标注序列y的概率为:
(9)
在训练阶段,采用极大对数似然估计进行目标优化,如式(10)所示。
(10)
最终进行解码获取最高分数的序列标注结果,如式(11)所示。
(11)
综合上述分析,序列标注模型的损失函数如式(12)所示。
L=LCRF+λLC+βLM
(12)
其中,λ,β为训练超参数。
因此基于语义相关性的命名实体识别算法步骤如算法1所示。

算法1: 基于语义相关性的命名实体识别算法输入: 输入文本x和实体标签y,实体联合器t输出: 文本中每个词对应的实体标签y*(1) 初始化实体联合器识别模型Cm和实体识别模型Em的参数;(2) 固定Em的模型参数,基于式(2)优化实体联合识别模型Cm的参数(3) 重复(2)的步骤,优化式(2)(4) 将实体联合器识别模型的输出t*以及x作为实体识别模型的输入(5) 固定Cm的模型参数,基于式(12)优化实体识别模型Em的参数(6) 重复(4)-(5)的步骤,优化式(12)(7) 返回文本中每个词对应的实体标签y*
2.4 实体识别测试阶段
对于无标签文本数据的实体识别,由于不能依赖实体标注信息获取实体联合器,首先将输入的无标签句子通过先前训练好的实体联合器识别模型,准确获取无标签句子中与实体高相关性的实体联合器,并将其作为额外的监督数据联合无标签句子共同通过实体识别模型,增强模型泛化、迁移能力,进而高效实现对无标签句子中实体的精准识别。无标签文本数据的实体识别过程如图4所示。
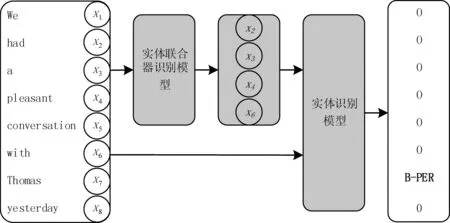
图4 无标签文本数据的实体识别过程
3 实验
3.1 数据集和评价指标
为了充分地对本文模型性能进行评测,采用经典的命名实体识别数据集CoNLL03[27]、NCBI Disease[28]。其中,CoNLL03是通用领域数据集,由1 393篇英文新闻文章组成,包含22 137个句子,通过人工标注四种实体类型: 地名(LOC)、组织机构名(ORG)、人名(PER)、混合型(MISC),参考经典方法[4]中的数据集划分方式。NCBI Disease为生物医学领域数据集,由793篇文章中的题目和摘要组成,通过人工标注6 892个疾病(DISEASE)实体,训练集、验证集、测试集分别取593、100、100篇文章中的句子组成。对于命名实体识别任务,采用精确率(P),召回率(R)和F1值(F1)评估实体识别的效果,若人工标注的实体类别和预测的实体类别完全一致,则认为识别正确。
3.2 实验设置
参考流行方法[3-4],使用BiLSTM-CRF作为本文模型的基本网络框架,对于输入的文本数据,利用公开的100维预训练词向量Glove[21]以及Xin等[22]所提方法训练字符向量,实体联合器识别模型和实体识别模型所使用的学习率分别为1e-4和1e-3,并利用Adam对其参数进行优化;α1和α2阈值都设置为0.7;GNN和BiLSTM的隐藏层设置分别设置为64和200。
3.3 模型整体性能对比
为了验证本文所提方法的有效性,本文在CoNLL03和NCBI Disease数据集上与其他现存的先进方法进行性能对比实验。实验结果如表1和表2所示。由于所使用的数据集属于不同领域,我们将对比模型分为两类: ①对于通用领域CoNLL03数据集采用以下对比模型: Ma和Hovy等[4]提出的BiLSTM-CRF网络充分利用句子上下文语义信息进行实体识别;Yang和Zhang等[29]公开的一个序列标注工具包NCRF++;Qian等[30]基于图网络学习局部和非局部上下文语义表示来改善实体识别模型性能;Reimers等[31]和Souza等[32]引入预训练模型进行命名实体识别任务。②对于生物医学领域NCBI Disease数据集采用以下对比模型: Zhao等[33]通过联合多种词嵌入方式,使用卷积神经网络捕获相邻标签之间的信息进行命名实体识别;Yoon等[34]提出了CollaboNet模型协同多个NER模型,解决数据缺乏和实体类型错误分类问题;Ling等[35]提出了一种基于知识增强的LSTM-CRF模型,用于疾病命名实体识别领域;Wang等[36]通过多任务学习框架MTM-CW,以共同使用不同类型的训练数据改善模型性能;Derbel等[37]通过捕获单词间依赖关系并结合BiLSTM网络对生物医学领域文本进行实体提取。
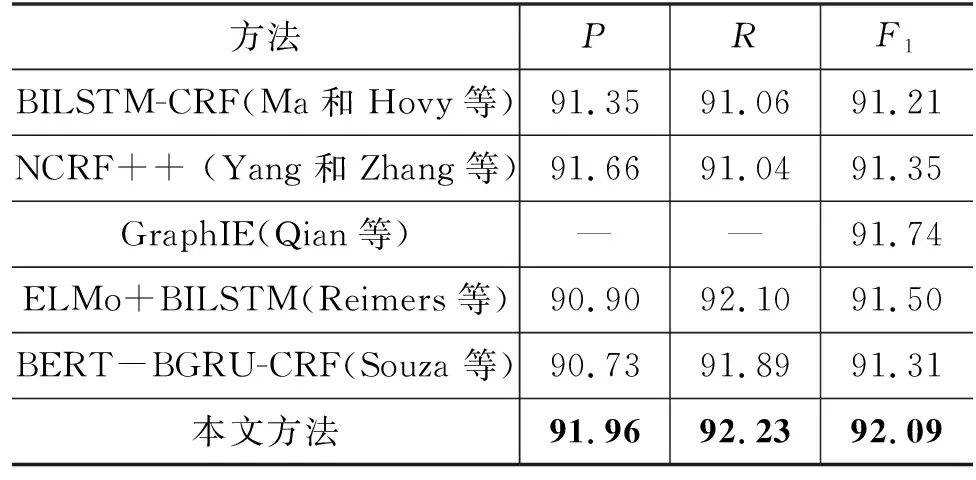
表1 CoNLL03数据集上的模型性能对比 (单位: %)

表2 NCBI Disease数据集上的模型性能对比 (单位: %)
在CoNLL03数据集上,本文方法相比于最优的GrpahIE具有更优的性能,在F1值上提升了0.35%;而相比于采用预训练模型的ELMo+BILSTM,在F1值上提升0.59%,并且本文方法相较于对比模型的精确率和召回率都有一定的提升;在NCBI Disease数据集上,相比于最优的MTM-CW算法,本文模型在F1值上提升了1.2%,相较于利用知识增强思想的KE-LSTM-CRF模型,本文方法在F1值提升了2.04%,除此之外,相关对比方法一般是针对生物医学领域的实体识别。对比实验结果表明,本文方法通过将实体联合器作为额外的监督数据,联合句子进行命名实体识别,能够有效提高模型的泛化、迁移能力,在不同领域的数据集上相对于其他对比模型都取得最优的结果,并且针对小数据集提升效果更加明显。
3.4 网络模型结构分析
表3给出了本文所提出实体联合器识别模型性能分析对比实验结果。在CoNLL03和NCBI Disease数据集上,对于实体联合器识别任务,采用实体联合器识别模型所获取的F1比BiLSTM-CRF分别提升7.22%和10.1%;对于实体识别任务,本文方法引入实体联合器识别模型,相较于没有实体联合器识别模型作用的基准模型BILSTM-CRF,具有更优的性能,在这两个数据集上分别提升0.88%和1.54%。实验结果表明,本文所提出的实体联合器识别模型能够充分利用句子和实体联合器之间的关联信息,通过图结构对关联信息的表征作用,准确获取文本数据中的实体联合器。同时,本文方法将所获取的实体联合器作为额外的监督数据和句子共同作用于实体识别模型进行命名实体识别,能够基于实体联合器与实体的强关联性提升模型的鲁棒性,充分利用句子、实体联合器和实体的语义关联性,进而提高模型对于文本数据实体识别的准确性。
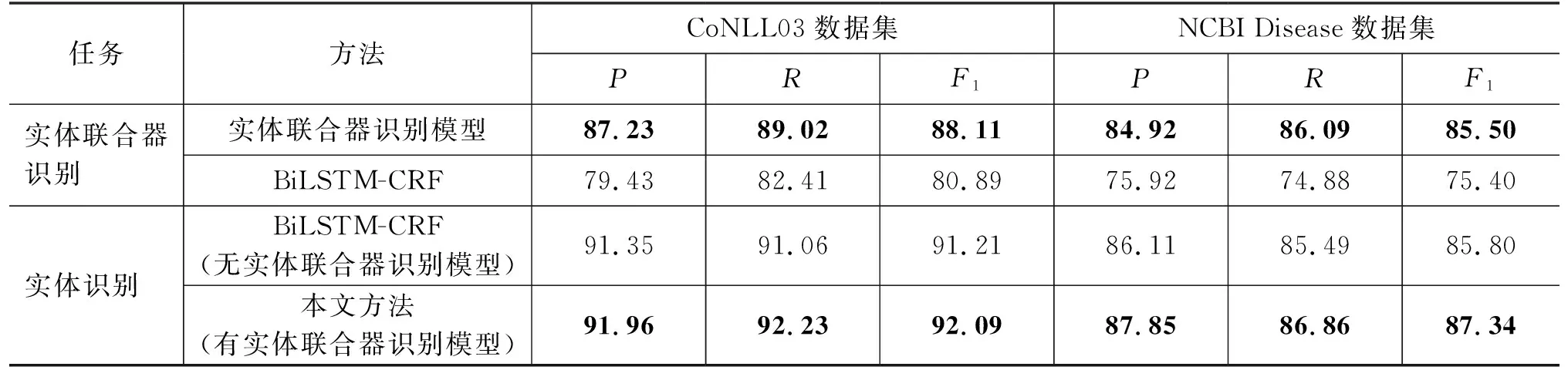
表3 实体联合器识别模型性能分析实验结果 (单位: %)
本文针对实体识别模型的目标优化函数设计了三个重要的损失函数项,通过对不同损失函数项所对应网络结构的调整,分析了不同损失函数组合对模型性能的影响。表4给出了本文模型在CoNLL03和NCBI Disease数据集上不同损失函数组合的实验结果。通过分析表4可知,单独采用LCRF损失函数得到的F1值要低于多损失函数联合优化的性能。其中,加入LC损失后,在CoNLL03数据集上F1值提升0.48%,NCBI Disease数据集上F1值提升了1.08%;加入LM损失后,在CoNLL03和NCBI Disease数据集上F1值分别提升了0.27%和0.63%;两者都加入时,在CoNLL03和NCBI Disease数据集上F1值分别提升了0.8%和1.67%。该结果表明,所设计的实体类型约束和特征一致性约束,强化了实体联合器在特征学习过程中的指导作用,进而提高模型实体抽取能力。

表4 消融实验结果 (单位: %)
3.5 模型通用性分析
为了进一步证明本文所提出的实体联合器作为额外监督数据能够增强模型的实体识别能力,图5和图6给出了本文方法和基准模型BiLSTM-CRF在不同比例大小的CoNLL03和NCBI Disease数据集上模型性能对比实验。通过实验结果分析可知,在两个数据集上都呈现相似的结果,对于不同比例大小的训练集,本文方法的F1值相较于基准模型BiLSTM-CRF都有所提升。从图中结果也可以看出,本文方法在CoNLL03和NCBI Disease数据集上,分别使用15%和20%的训练数据便可达到BiLSTM-CRF模型使用60%的效果,并且使用50%的训练数据便可获得BiLSTM-CRF模型使用全部训练数据的结果。该结果表明,利用本文方法将实体联合器作为额外的监督数据训练模型不仅可以使用更少的人工标注数据减少人工成本,而且对于增强小数据集上模型性能具有促进作用。
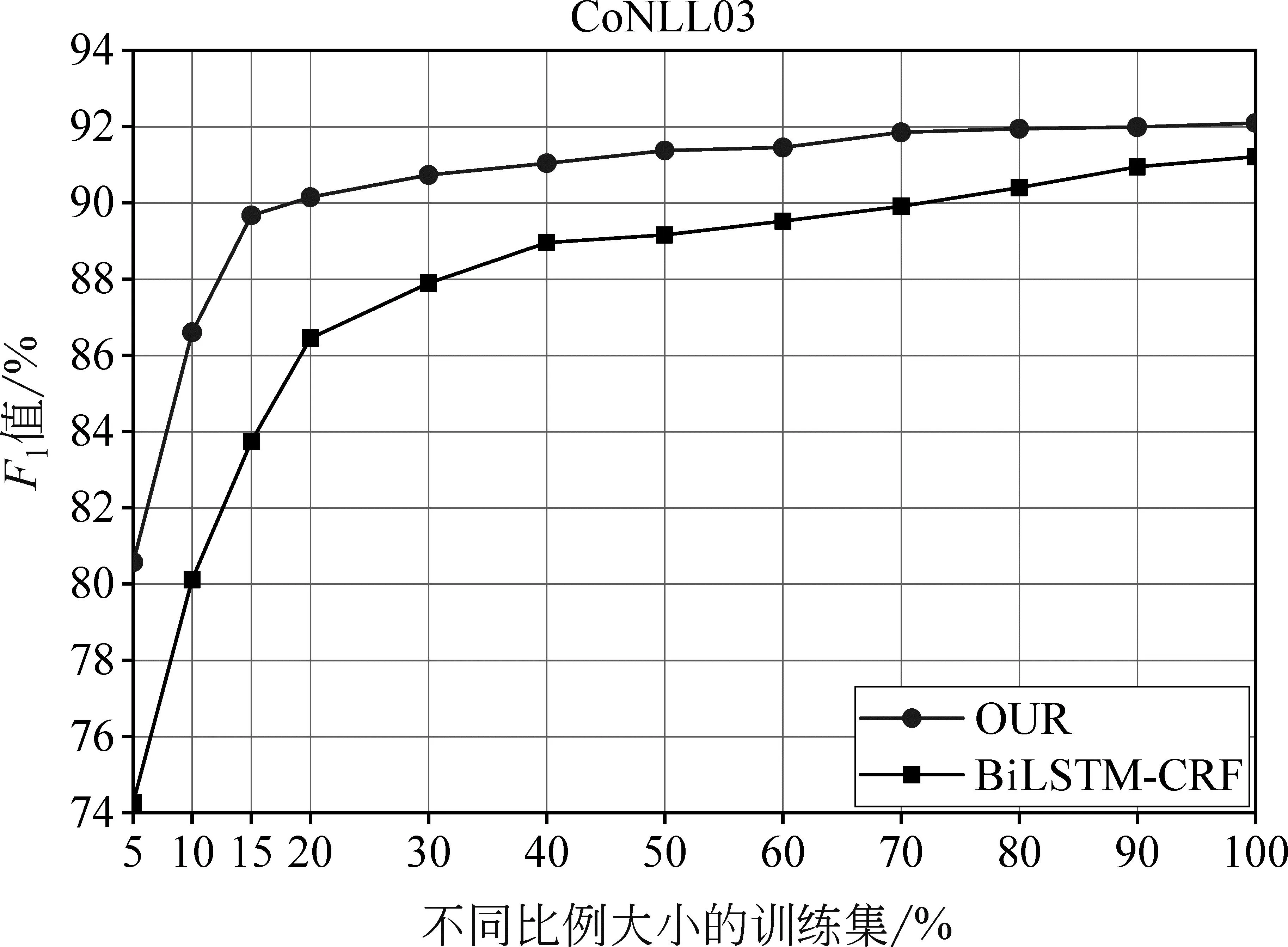
图5 不同比例的CoNLL03训练集上模型性能对比
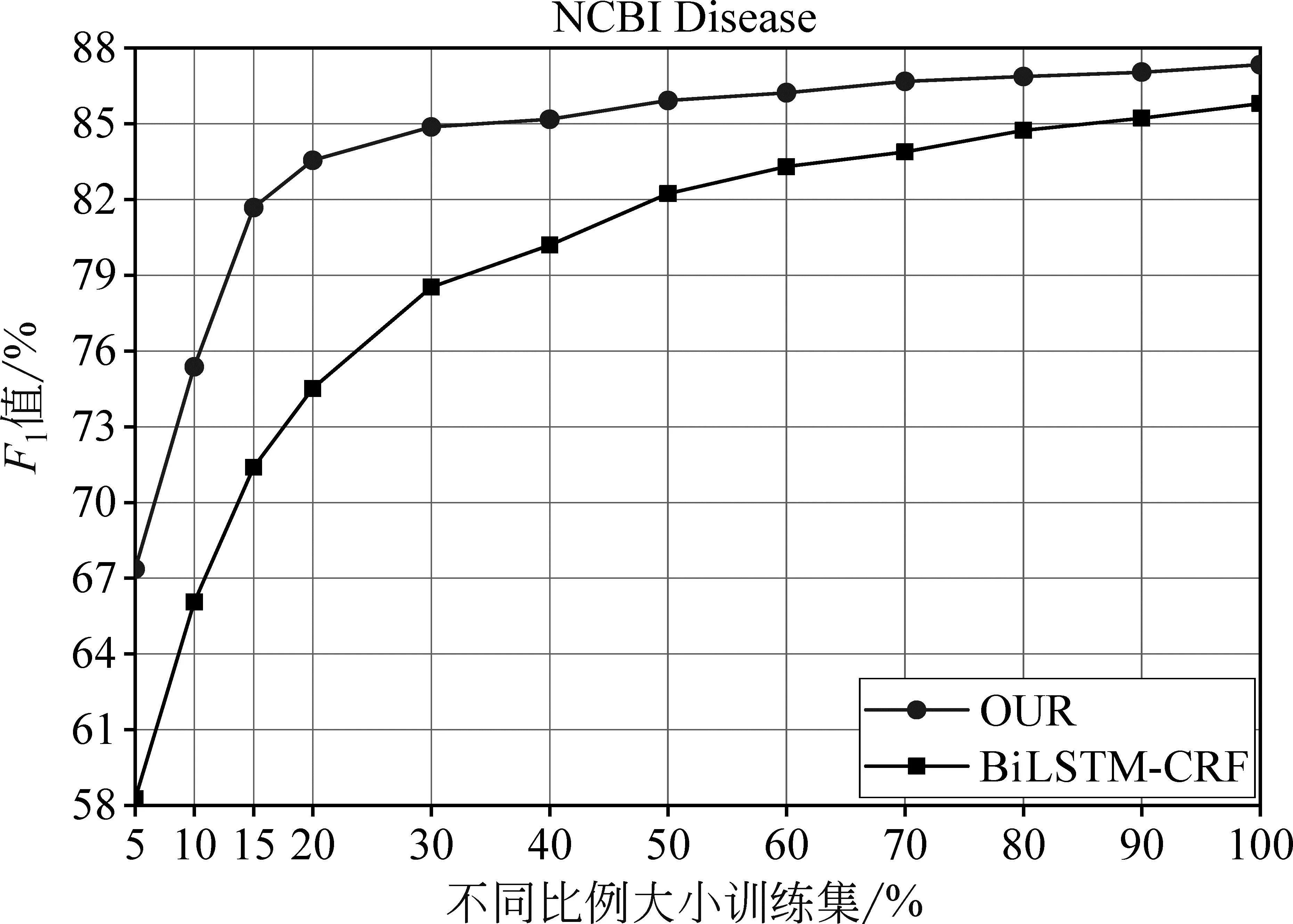
图6 不同比例的NCBI Disease训练集上模型性能对比
3.6 定性对比分析
图7展示了本文所提出方法在命名实体识别任务上的定性对比实验结果。如图7中所展示的4个示例,通过使用本文模型能够正确识别其中三个示例,而利用BiLSTM-CRF模型仅能正确识别一个示例,从而直观地证明了本文所提方法的有效性。通过示例2和示例3对比分析可以发现,对于BiLSTM-CRF模型识别文本数据中的实体存在识别实体标签不完全和顺序不一致问题,而本文方法通过将实体联合器作为额外的监督数据,能够有助于模型正确识别文本数据中的实体,解决了上述问题,进而证明了本文方法的合理性;但是进一步分析发现,本文方法的实体识别效果仍具有改进空间,比如示例4中所识别实体标签类别相较于BiLSTM-CRF模型虽然更完善,但是与真实实体标签类别还不完全一致,推测原因可能是由于实体联合器的识别效果对于模型性能存在一定影响,不过对于存在的相关问题还需进一步分析模型的实体识别结果,从而探索更优化的算法模型。
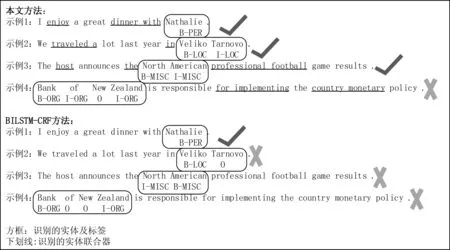
图7 命名实体识别案例
4 结束语
本文提出了一种基于语义相关性的命名实体识别算法。首先经济高效地利用现有语料库,通过文本自身信息的语义相关性引入“实体联合器”作为额外的监督数据,帮助模型进行命名实体识别。在此基础上,提出了基于语义关联性的实体联合器识别模型,充分利用句子和实体联合器的关联信息,通过图结构强化关联信息的特征表示,从而有效识别无标签句子中的实体联合器,并将其作用于实体识别模型,通过特征融合机制将实体联合器和句子进行融合,充分捕获实体联合器和句子的语义信息,同时构建两种损失函数,强化实体联合器在特征学习过程中的指导作用,增强模型泛化、迁移能力,进而提高模型对文本数据中实体识别的准确性。通过在两个流行数据集上的评测,证明了所提方法在命名实体识别任务中的优越性和网络结构合理性。
猜你喜欢
中学生数理化(高中版.高考理化)(2021年2期)2021-03-19
数学年刊A辑(中文版)(2020年2期)2020-07-25
数学物理学报(2019年6期)2020-01-13
中国外汇(2019年18期)2019-11-25
东方女性(2018年3期)2018-04-16
散文诗(2017年17期)2018-01-31
数学物理学报(2017年5期)2017-11-23
哲学评论(2017年1期)2017-07-31
领导决策信息(2017年9期)2017-05-04
领导决策信息(2017年9期)2017-05-04
