
加工时间模糊车间多目标调度与奖惩灰靶决策*
2024-01-16 14:08韩文颖赵明君巴特尔
制造技术与机床 2024年1期
韩文颖 赵明君 春 兰 巴特尔
(①内蒙古工业大学工程训练教学部,内蒙古 呼和浩特 010051;②山西省电力公司超高压变电分公司,山西 太原 030000)
由于客户的多样化需求和企业的内卷化竞争,使得产品定制化、多样化程度越来越高[1]。为了适应市场发展趋势和满足市场需求,具有多样化产品生产能力的柔性生产车间逐渐取代刚性生产车间[2]。对于柔性生产车间,不同的生产调度方案对应不同的生产效率、生产能耗等。因此,研究柔性车间生产调度问题具有重要的经济意义和现实价值。
柔性车间生产调度方法是根据调度问题特点的变化而变化的。最初研究的生产调度问题具有生产规模小、设备柔性度不高的特点,因此使用穷举法、网络图法、数学规划法[3-4]就能够较好地解决此问题。而后随着车间柔性度加深、车间规模扩大,数学规划法的计算量和网络图法的网络规模过大,无法解决大规模车间的调度问题。此时,通过编码的方式,将调度优化问题转化为智能算法寻优问题成为主流方法[5]。文献[6] 针对具有装配操作的柔性车间调度问题,提出了基于变邻域搜索粒子群算法的调度方法,通过实验证明了该方法具有更好性能。文献[7]针对柔性车间调度问题,通过对遗传算法的初始化方法和变异方法进行改进,提出了基于改进遗传算法的调度方法。
上述研究方法都是在确定条件下提出的,但是车间生产过程还受到随机因素和不确定因素的影响,比如机床故障、订单加急、订单插入和加工时间不确定等。文献[8]针对隐性扰动导致的重调度问题,分析了工序间的动态关联性,并采用遗传算法进行求解,通过仿真证明了重调度方法的正确性。文献[9]分析了机床故障和订单插入时的能耗特性,以能耗和完工时间为目标,对生产参数和调度问题进行了综合优化。文献[10]采用区间灰数表征不确定的加工时间,并提出了基于自适应人工蜂群算法的求解方法,有效提高了企业的生产效率。当前关于随机因素和不确定因素下车间调度问题的研究存在以下问题:一是对于多目标优化问题,多以加权综合法进行研究,仅给出单一的调度方法,没有给出可选方案集合;二是对于Pareto 解集,缺少合理的决策方法。
针对上述问题,本文在考虑加工时间模糊前提下,使用模糊集理论建立调度优化模型,提出了邻域动态选择NSGA-II 算法的优化方法;并基于加权灰靶理论决策出了最优染色体。最后通过实际生产案例验证了本文方法的有效性。
1 基于模糊集的车间调度建模
1.1 问题描述
考虑加工时间不确定的柔性作业车间多目标调度问题描述为:车间中放置了M台加工机床,记为{Cm},m∈[1,M];承担了N个工件的加工任务,记为{Jn},n∈[1,N];工件Jn的工序数量记为Ln,其加工工序记为{Onl},l∈[1,Ln]。在柔性生产模式下,每一工件可以由多台机床进行加工,且各机床的模糊加工时间已知。
在本文研究中,柔性车间生产调度的优化目标为
(1)车间模糊完工时间最小。
(2)机床模糊总负载最小。
(3)瓶颈机床模糊负载最小。
柔性车间生产调度的任务为
(1)为各工序的生产顺序进行排序。
(2)为各工序安排加工机床。
根据车间生产实际,对柔性车间多目标调度问题作以下假设和设定:
(1)在初始时刻,机床为完好状态。
(2)工序加工过程为连续不中断的,即不考虑机床故障等突发情况。
(3)不设置工件的加工优先级,即所有工件的加工优先级一致。
(4)将工件的物流时间考虑在了加工时间内,无须另外考虑材料的物流时间。
1.2 模糊数与去模糊化
三角模糊数和梯形模糊数是模糊集理论中常见的模糊数,前者多用于表征加工时间模糊性,后者多用于表征交货期模糊性。因此本文采用三角模糊数表示模糊加工时间。本文中设定上标“ ⊗”的参数为三角模糊数。基于三角模糊数的模糊加工时间记为T⊗=(t1,t2,t3),其中t1、t3分别为最小加工时间、最大加工时间,t2为最可能加工时间。三角模糊数的隶属度函数和运算规则具有明确定义,可参考文献[11]。
在三角模糊数的研究中,鲜有关于去模糊化的研究。为了后文比较方案的性能优劣,需对三角模糊数进行去模糊化,本文采用期望值法对模糊数去模糊化。对于T⊗=(t1,t2,t3),去模糊化为
式中:ET⊗为模糊数T⊗的均值;E1、E2分别为模糊数在区间[t1,t2]、(t2,t3]的均值;f(x)、g(x)分别为模糊数在区间[t1,t2]、(t2,t3]的隶属度函数。
1.3 模糊调度模型
根据设定的3 个调度优化目标,分别建立优化目标模型。
(1)车间模糊完工时间最小
车间完工时间应以最后一道工序完工时间为准,则车间模糊完工时间最小的目标函数为
式中:f1为车间模糊完工时间最小的目标函数;为工序Onl的模糊完工时间。
(2)机床模糊总负载最小
首先设置一个标识参数xnlm,并定义
则机床模糊总负载最小的目标函数为
式中:f2为机床模糊总负载最小目标函数;为工序Onl在机床Cm上的模糊加工时间。
(3)瓶颈机床模糊负载最小
瓶颈机床是指负载最大的机床,设置瓶颈机床负载最小这一目标,本质是以负载均衡为目标,则:
式中:f3为瓶颈机床模糊负载最小目标函数。
柔性车间调度在优化过程中需满足以下约束:
(1)同一工件的工序需满足前后加工顺序。
(2)任一机床在同一时间最多加工一道工序。
(3)每一道工序必须且只能加工一次。
(4)加工过程连续不间断。
上述约束条件的对应公式描述为
2 邻域动态选择NSGA-II 调度算法
针对柔性车间多目标调度优化问题,本节提出了基于邻域动态选择NSGA-II 算法的调度方法。
2.1 邻域动态选择NSGA-II 算法
NSGA-II 算法[12-13]本质是在遗传算法中引入了非支配排序的选择方法。
在标准NSGA-II 算法中,选择过程为:首先依据非支配层排序依次保留非支配层1、非支配层2,直到保留数量超过设定规模时结束;而后计算最后一层非支配层中染色体的拥挤度,保留拥挤度较大的若干染色体,直至染色体数量达到设定规模。拥挤度的计算方法:端点处的染色体拥挤度设置为+∞,其余染色体计算方法为
式中:di为染色体xi的拥挤度;j为目标函数编号;分别为染色体xi的紧邻个体适应度值。分析式(7)可知,拥挤度越大,则染色体分布越稀疏、多样性越好。
标准NSGA-II 算法的选择方法问题在于:①在最后一层非支配层选择时,是一种静态选择方法,选择过程中没有动态更新拥挤度,导致染色体分布不均匀,即染色体多样性较差;②拥挤度计算仅以本层染色体为依据,忽略了邻域内的分布情况,是一种片面的衡量标准。
针对上述问题,本节提出了邻域动态选择策略,实施方法为:依据非支配层排序依次保留染色体,直到保留数量超过设定规模时结束;而后,从最后一支配层动态删除染色体,首先删除拥挤度最小的个体,而后动态更新染色体拥挤度,重复删除过程,直至染色体数量与设定规模一致。在动态选择策略中,基于邻域范围计算染色体的拥挤度为
式中:di为邻域范围的拥挤度;Pnei为邻域内染色体数量; ϑnei为染色体xi的邻域;xq为邻域内染色体;为染色体xq在第j个目标上的取值。
对比式(7)和式(8)可知,式(7)仅考虑的最后一层支配层染色体分布的拥挤度,而式(8)考虑了包括其他支配层在内的邻域范围,是一种更加全面的计算方式。有利于在整体分布上挑选出多样性较好的染色体。
2.2 基于改进NSGA-II 算法的调度优化方法
基于邻域动态选择NSGA-II 算法的车间调度优化方法主要包括编码、交叉、变异和选择等关键步骤,其中选择方法在2.1 节已经明确,在此仅对编码、交叉和变异进行分析和改进。
(1)编码。根据车间调度任务,将染色体编码为双链形式,一条为工序选择,对应工序的生产顺序;另一条为机床分配,对应各工序的加工机床。以3 个工件和3 个机床为例,某一染色体编码如图1所示。
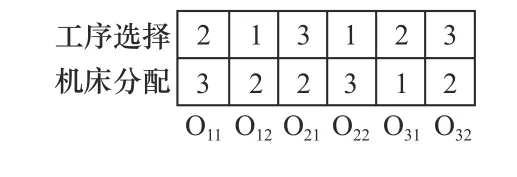
图1 染色体编码
图1 “工序选择基因链”中,数字“2”第一次出现表示工序O21,第二次出现表示工序O22,其余数字含义与此一致。“机床分配链”中,各基因位分别为O11、O12、O21、O22、O31、O32的加工机床。
(2)交叉。机床分配链的编码方式使2 个父代染色体的对应基因位可以互换,因此采用传统单点交叉法即可。工序选择链需遵守“各工序必须加工1 次且只能加工1 次”的约束,因此采用POX交叉法[14],具体实现方法如图2 所示。
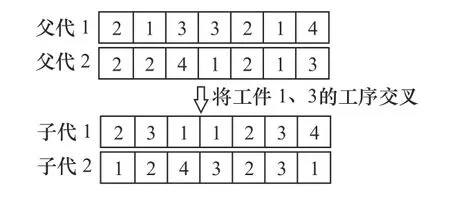
图2 交叉操作
图2 中父代工件2 和4 的各工序基因不变,将工件1 和3 的各工序基因交叉,得到子代染色体。
(3)变异。对于机床分配链,随机选择2 个基因位,将其变异为其他可用机床即可。对于工序选择链,采用切割基因段并右移循环变异的方法,如图3 所示。
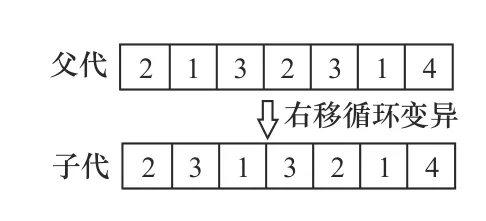
图3 右移循环变异
图3 中随机截取基因段1323,将其右移一位循环变异为3132,并嵌入原位置得到子染色体。
3 考虑奖惩的加权灰靶决策方法
车间调度多目标优化研究中,一般仅给出优化方案的Pareto 集,但是未给出决策方法,本节针对这一问题展开研究。
3.1 考虑奖惩的决策矩阵
将由K个可选方案组成的集合记为{Sk},k=1,2,···,K,可选方案Sk对第j个优化目标的函数值记为yk j,则由yk j构成了效用矩阵Y。
为了统一标准,在做决策时需对效用矩阵进行归一化处理。当前研究中一般将效用矩阵Y归一化为0~1 间的实数[15-16],但是这是一种只奖不惩的处理方法,导致决策的不合理性。针对这一问题,本节设计了奖惩算子,当效用值yk j好于均值时,归一化为[0,1] 间实数;当效用值yk j差于均值时,归一化为[-1,0]间实数。实施奖惩方法为
式中:rk j∈[-1,1]为决策因子;y¯j为效用矩阵Y第j列元素的均值。
由决策因子rk j构成了考虑奖惩的决策矩阵R:
3.2 基于靶心距的决策方法
式中: εk为方案rk与靶心的距离(简称靶心距);wj为指标权值,j∈[1,J]。计算各可选方案的靶心距,靶心距越小说明调度方案越优。
式(11)中权值一般依据专家经验给出,但是这种方法的主观性太强。本文基于信息熵计算各指标权值,赋权思路为:当指标的信息熵较小时,说明该指标的规律性越强,则在决策中的权重越大;当指标的信息熵较大时,说明该指标的规律性越弱,则在决策中的权重越小。则优化目标j的熵权值为
式中:pk j为第k个可选方案中第j个指标的占比;ej为第j个指标的信息熵。
将式(12)计算得到的熵权值代入到式(11)中计算靶心距,靶心距最小的调度方案为最优调度方案。
4 实验与分析
4.1 实验设置
以合作单位某冲压车间的生产任务为例,对本文的调度和决策方法进行验证。该冲压车间中布置了8 台冲压机床,承担了8 个工件共28 道工序的生产任务,各工序的可用机床及模糊生产时间见表1。

表1 可用机床及模糊加工时间min
4.2 结果对比与分析
针对4.1 节的柔性冲压车间多目标生产调度问题,同时使用标准NSGA-II 算法、邻域动态选择NSGA-II 算法、混沌映射NSGA-II 算法[17]、双层遗传算法[18]进行调度优化。后两个算法参数设置同原文一致,前两个算法参数设置为:种群规模为40、最大迭代次数为300、交叉概率0.5、变异概率0.1。以上各算法搜索的Pareto 前沿解分布如图4 所示。
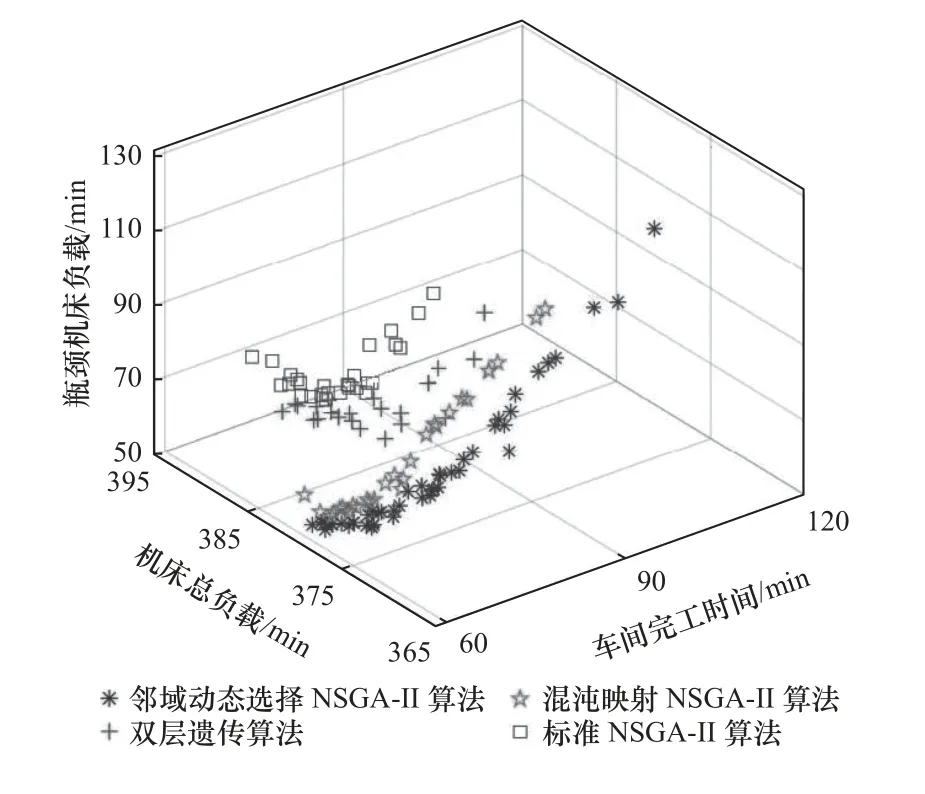
图4 Pareto 解集分布
由图4 可以直观看出,邻域动态选择NSGA-II算法搜索的Pareto 前沿解相对于其他Pareto 解集处于支配地位,即邻域动态选择NSGA-II 算法的优化结果更好。为了更加有力地比较各Pareto 解集的优劣性,计算解集的C测度。
C测度又称为集覆盖测度,假设存在2 个Pareto 解集A 和B,则C(A,B) 表示集合B 被集合A 所支配解的占比:
式中:num{}为计数函数;a≺b表示解a支配b。
将邻域动态选择NSGA-II 算法、混沌映射NSGA-II 算法、双层遗传算法、标准NSGA-II 算法搜索的Pareto 解集分别记为集合A、B、C、D。Pareto 解集的C测度值见表2。
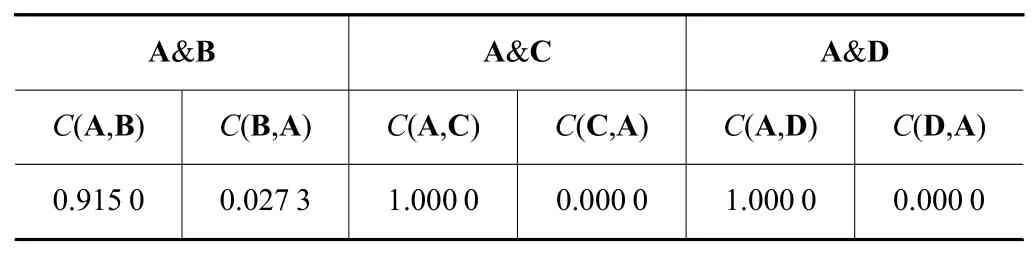
表2 C 测度值
由表2 可以看出,C(A,B)>C(B,A)、C(A,C)>C(C,A)、C(A,D)>C(D,A),这意味着解集A 相对于解集B、C、D 具有支配地位,因此邻域动态选择NSGAII 算法的优化算法好于另外3 种算法。这是因为该算法在选择染色体时,考虑了邻域范围内染色体分布,且使用了一种动态删除和选择方法,较好地维持了染色体多样性,因此算法的优化能力好于其他算法。
4.3 决策结果与最优调度方案
从邻域动态选择NSGA-II 算法优化的Pareto 解集中,基于考虑奖惩的加权灰靶决策方法选择最优染色体,计算的熵权值为w=(0.400,0.333,0.267),靶心为rbest={0.8134,0.9326,0.7318}。根据靶心距得到的最优染色体见表3。

表3 最优染色体
将决策得到的最优染色体进行解码,得到最优调度方案如图5 所示。
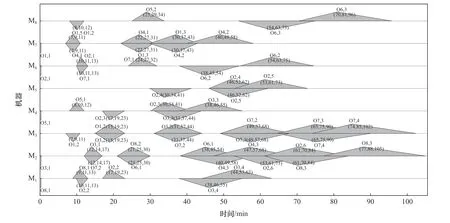
图5 最优调度方案
分析图5 可知:①图中调度方案考虑了加工时间不确定性,符合本文的研究背景和研究立意;②图5 给出的调度方案满足工序加工的时间约束、逻辑约束等,是一种可行的调度方案。结合图4 和图5可知,本文提出的柔性车间多目标调度和决策方法是有效的,且具有一定的优越性。
5 结语
本文针对加工时间模糊条件下的车间生产调度问题,基于模糊集理论建立了调度优化模型,提出了基于邻域动态选择NSGA-II 算法的求解方法;针对最优方案选择问题,提出了奖惩灰靶决策方法。经验证得出以下结论:
(1)动态邻域选择NSGA-II 算法的优化能力更强,其搜索的Pareto 解集相较于对比算法处于支配地位。
(2)奖惩灰靶决策方法能够从可行解集中选择出信息熵意义下的最优解,是一种有效的决策方法。
猜你喜欢
智能制造(2021年4期)2021-11-04
吉林大学学报(理学版)(2020年3期)2020-05-29
科学之谜(2019年3期)2019-03-28
小学生学习指导(中年级)(2018年11期)2018-11-29
科学之谜(2018年8期)2018-09-29
自动化学报(2018年7期)2018-08-20
农村农业农民·B版(2018年11期)2018-01-28
中国老区建设(2016年12期)2017-01-15
周口师范学院学报(2016年5期)2016-10-17
恋爱婚姻家庭·养生版(2016年9期)2016-09-07
