
改进型YOLOv5s的瓷砖表面缺陷检测方法
2024-01-15 05:44:54吴航星张宏怡谭湘琼林海峰
厦门理工学院学报 2023年5期
吴航星,张宏怡,谭湘琼,林海峰
(厦门理工学院光电与通信工程学院,福建 厦门 361024)
目前,瓷砖表面缺陷检测仍然依赖于人工视检的方法,然而这种方法容易受到检验人员经验、情绪及视觉疲劳等因素的影响,从而导致瓷砖缺陷漏检或者误检等问题。因此,开发一种基于机器视觉的自动化瓷砖表面缺陷检测方法,成为瓷砖产业发展的迫切需求。基于机器视觉的缺陷检测方法主要分为传统图像处理方法和深度学习方法两类。传统方法需要人工提取图像特征,利用经过训练的分类器进行缺陷检测和分类[1-3]。由于传统方法需要手动提取特征,其应用场景受限,难以在实际生产环境中得到广泛应用。近年来,深度学习技术在机器视觉领域中取得巨大的进展,成为缺陷检测的新兴方法。相较于传统的图像处理方法,深度学习方法具有自动化特征学习和端到端训练等优势,能够更好地应用于实际生产环境中[4-6]。基于深度学习的缺陷检测算法主要分为以SSD[4]、YOLO(you only look once)系列[5-7]为代表的一阶段检测算法和以Fast RCNN[8]、Mask RCNN[9]为代表的两阶段检测算法。例如,欧阳周等[10]针对瓷砖图像的复杂背景纹理的“成像性”与“聚集性”特征,建立基于视觉注意机制的检测模型,提出一种基于人眼视觉注意机制的显著性目标检测方法,但在检测之前需要对数据在颜色空间进行预处理;陈学仕等[11]提出一种基于Faster RCNN[12]的印刷电路板瑕疵检测算法,在边界框回归定位中使用DIoU 损失函数替换原始的smooth-L1损失函数加速模型的收敛,但是在检测速度上还有待提升;赵楚等[13]针对瓷砖存在极小瑕疵和形态差异大的问题,引入可变形卷积,提出基于Faster RCNN 的瓷砖缺陷检测算法;文献[14-15]提出改进特征融合结构、多尺度特征及损失函数,一定程度上提高模型的检测性能。以上方法虽然可以提高缺陷检测性能,但是基于两阶段检测算法的改进方案普遍存在检测时间较长的问题,且在工业生产中难以部署;相比之下,单阶段检测算法由于其端到端的检测特性,具有更快的检测速度,也更容易部署到其他设备上。另外,上述缺陷检测算法需要将待检测图像缩放或裁剪至固定的尺寸,才能输入检测模型进行缺陷检测,对于高分辨率的图像来说,这种数据处理方式易使一些目标的特征丢失,从而导致漏检的情况。为缩短检测时长,本文采用单阶段目标检测网络框架,在此基础上提出一种改进型YOLOv5网络的瓷砖缺陷检测方法,通过改进锚框匹配算法和特征提取模块来提高模型的检测精度;同时,在模型预测阶段,使用滑窗预测的方法对高分辨率图像进行切片预测,实现模型对高分辨率图像的端到端预测,从而解决目标漏检的问题。
1 YOLOv5算法的网络结构及瓷砖缺陷检测原理
1.1 YOLOv5算法的网络结构
YOLOv5是一种基于深度学习的单阶段目标检测算法,由多个卷积神经网络结构和相关的数据处理算法组成。YOLOv5(6.2版本)由特征提取网络、特征融合网络、检测头3个部分构成。其中,特征提取网络通过卷积(Conv)模块、C3(CSP bottleneck with 3 convolutions)模块和SPPF(spatial pyramid pooling fast)模块对输入图像提取不同尺度的特征,使特征图的分辨率下采样到输入图像的1/32;特征融合网络分别将1/8、1/16和1/32下采样率的特征图进行多尺度融合;3个检测头分别对融合网络的3 个融合输出特征图进行解码,输出预测结果,其中,浅层特征图主要负责检测小尺寸目标,深层特征图主要负责检测大尺寸的目标。
1.2 基于YOLOv5算法的瓷砖缺陷检测原理
使用YOLOv5 检测算法进行瓷砖缺陷检测,需要在瓷砖缺陷数据集上进行模型的训练,使得YOLOv5 能够在瓷砖缺陷数据集上获得更佳的性能表现,完成瓷砖缺陷的检测任务。YOLOv5 检测算法首先对输入图像进行预处理,将待检测图像缩放至固定的尺寸(640 px×640 px);然后,输入检测网络,在检测网络的特征提取网络中提取瓷砖的纹理及语义信息,在特征融合网络中融合不同尺度的特征信息,再在三个不同尺度的检测头上设置不同长宽比的锚框以进行密集预测;最后,将网络输出的密集预测结果依次通过置信度阈值和非极大值抑制算法,去除目标周围多余的预测框,最终实现对瓷砖图像的缺陷定位和类别预测。
2 YOLOv5算法的改进
本文对YOLOv5 算法主要进行3 个方面的改进。首先,传统的YOLOv5 算法在模型的训练阶段,通过标准K-Means算法和遗传算法(genetic algorithm, GA)为每个检测头上的网格单元格设置3组不同长宽比的锚框,使模型能够快速收敛。标准K-Means算法中的欧式距离度量无法体现不同维度上的比例信息,传统的YOLOv5算法在极端长宽比的数据集上聚类出的结果不太理想。因此针对此问题提出优化。其次,在C3 模块的残差单元里,不同尺寸的卷积核在层级上进行串接,单个模块的处理能力受限,无法捕捉到不同分辨率特征之间存在的内在联系和依赖关系,需要多个模块协同工作来提取多尺度特征。传统的YOLOv5 只通过多尺度特征融合结构来进行目标的多尺度检测。因此对C3 模块进行优化,提升模型的模块级别多尺度检测能力。最后,传统的YOLOv5算法在模型的推理阶段,通过自适应图像缩放算法将不同尺寸的图像缩放到固定的尺寸,然后将图像输入模型进行检测。对于高分辨率图像而言,在图像中占比较小的目标缩放后只占一个像素甚至失真,容易导致缺陷漏检情况发生。因此,针对此问题进行优化。
2.1 优化自适应锚框匹配算法
基于K-Means 聚类的方式预先获得标签框尺寸的大致分布情况,然后在宽-高的二维空间中对标签框尺寸进行K-Means 聚类,得到k 个簇,计算每个簇在不同维度上的均值,得到k 个聚类中心。在标准K-Means聚类中采用欧式距离(euclidean distance)作为度量标准,即
式(1)中:ρ为点(wb,hb)和点(wc,hc)之间的欧式距离;wb和hb分别表示标签框宽高尺寸;wc和hc分别表示锚框宽高尺寸。
YOLOv5 采用自适应锚框匹配算法,通过对数据集中每个目标的尺寸和形状进行K-Means 聚类,得到适配数据集尺寸的锚框。这一算法使得YOLOv5能够更好地满足不同目标的检测需求,提高模型的适应性。K-Means 聚类算法使用欧式距离来确定样本所属的簇,并使用平均IoU 来评估聚类效果。然而,欧式距离在n维空间中计算两点之间的距离,没有考虑n个维度的比例信息,并不适合用于聚类出具有合适宽高比的锚框。因此,在聚类过程中使用欧式距离作为度量函数并不太合适。本文引入CIoU作为K-Means的度量函数, CIoU计算公式为
式(2)~(4)中:boxes 为标签框;centroid 为聚类的质心;ρ为质心与标签框中心点的欧氏距离;c 为锚框与目标框的最小闭包矩形对角线距离;v用来度量长w与宽h比值的相似性;α为权重系数;ε为无穷小数。
CIoU 表示虚线框A 和虚线框B 的交并比与正则项((ρ(boxes,centroid) c2) + αv )的差值,其示意如图1 所示。式(2)中的ρ(boxes,centroid) c2为图1中AB中心点的距离d与最小外包框C对角线的距离c的比值。相比于欧式距离,CIoU 考虑长宽比的一致性,并利用参数v 来表示长宽比的一致性。这种改进使得K-Means 能够有效地提取出具有较高重叠度和合理的长宽比的先验框,从而更好地捕捉数据集中真实的长宽比分布。
基于CIoU 距离度量对数据集标签尺寸进行K-Means 聚类,并比较自适应锚框匹配算法优化前后的结果。不同特征图尺寸的锚框宽高尺寸对比结果如表1所示。表1中的数据表示锚框映射到输入图像分辨率的宽高尺寸。经过K-Means 聚类后,舍弃2 个较大的先验框,先验框的尺寸更集中在中小型目标的范围内。

表1 自适应锚框算法优化前后不同特征图上的锚框尺寸对比Table 1 Anchor frame sizes on feature maps by original and optimized adaptive anchor frame algorithms in Pixel
2.2 优化特征提取C3模块
融合不同尺度的特征是提高检测性能的重要方法之一。图2 展示了原始YOLOv5 和优化后的残差模块的结构对比。在图2(a)中,ResNet 通过2 个1 × 1 的卷积层和一个3 × 3 的卷积层组成瓶颈结构的残差块,其中,1 × 1 的卷积对输入的通道进行降维和升维操作,在低维度使用3 × 3 卷积进行特征提取。当恢复维度后将输出与输入信息进行合并。图2(b)中,Res2Net[16]通过将降维的1 × 1 卷积输出特征在通道维度上分成n等份,每一份特征的尺度大小都相等,但通道是输入特征的1n,定义为xi,i∈{1,2,…,n},其中x1不参与卷积计算,直接传递到下一层1 × 1 卷积输入。其余n- 1 份,首先将1 份特征使用3 × 3 的卷积核进行计算,提取特征信息,将输出结果与下一份特征合并,并使用下一个3 × 3 卷积提取特征。不断重复上述过程直到n- 1 份特征全部计算完毕。每个3 × 3 卷积用fi表示,用oi表示对应的卷积fi的输出,oi如公式(5)所示。最后将所有输出结果进行通道堆叠,作为升维1 × 1 卷积的输入,将原始输入与升维1 × 1卷积的输出合并后,作为整个Res2Net的卷积块输出。
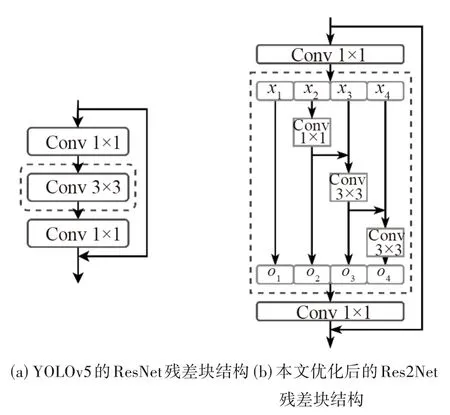
图2 残差模块结构对比图Fig.2 Structure of residual elements compared
Res2Net是在传统的ResNet基础上进行优化的一种方法,旨在提升特征提取网络的多尺度表征能力。它通过对原始残差单元中的3 × 3 卷积在通道上进行分组,构建具有阶梯制的残差连接。通过引入Res2Net 残差单元到YOLOv5 的C3 模块中,替换原始的残差单元,使YOLOv5 更充分地提取缺陷目标的多尺度特征。这样一来,不仅可以在模块级别上提取多尺度特征,丰富初始模型的多尺度检测能力,而且有利于小目标在浅层融合语义特征。
2.3 优化高分辨率图像缺陷检测方式
在模型预测过程中,YOLOv5 采用图像自适应缩放算法,通过最小化黑边提高模型的推理速度,实现更有效地图像缩放。具体流程如下:(1) 根据原始图像的大小和模型输入端的图片大小计算图像缩放比例;计算原始图像与目标尺寸的长-长比例、宽-宽比例,取最小比值为缩放比例。(2) 根据最小比值等比缩放原始图像。(3) 计算黑边填充的数值。由于网络执行5次下采样操作,因此将最短边的像素数量填充到最近的32的倍数(25=32),以保证在网络深层特征图的尺寸为整数。
对于一些高分辨率图像,YOLOv5若采用自适应图像缩放算法对图像缩放到固定的尺寸,对于那些在图像中占比较小的目标,导致在缩放后的图像中只占一个像素甚至失真,造成图像中目标漏检情况的发生。由于瓷砖缺陷尺寸属于小目标范畴,而图片分辨率为8 192 px×6 000 px,因此,在预测时若采用将全图缩放至640 px×640 px 进行预测的方法,将无法检测出缺陷,造成大量的缺陷漏检。因此,本文采用滑窗预测算法[17],对高分辨率图像进行滑窗预测,最后将所有预测结果映射到原图,从而有效解决此问题,实现YOLOv5对高分辨率图像的端到端预测。
3 实验结果与分析
本实验在Ubuntu20.04操作系统下进行,GPU为NVIDIA GeForce RTX 3090,单张24 GB显存。使用CUDA11.1.1 和CUDNN8 进行GPU 加速。Batch-Size 参数设置为32,Image-Size 设置为640 px×640 px,训练300次迭代。
3.1 数据集分析与处理
本实验采用2021 广东工业智造创新大赛智能算法赛提供的瓷砖缺陷检测数据集。经统计,瓷砖缺陷数据集共5 388 张图片,其中1张没有标签。分别有尺寸为8 192 px×6 000 px 的图像3 962 张,尺寸为4 096 px×3 500 px 的图像1 435 张;瓷砖缺陷共6 个类别,分别是边异常、角异常、白边、浅色块、深色块和光圈。图3为原始数据标签尺寸统计结果。从图3可见,数据集中的缺陷标签非常小,且更多地分布在图像的4个角上,缺陷存在极端长宽比的情况。
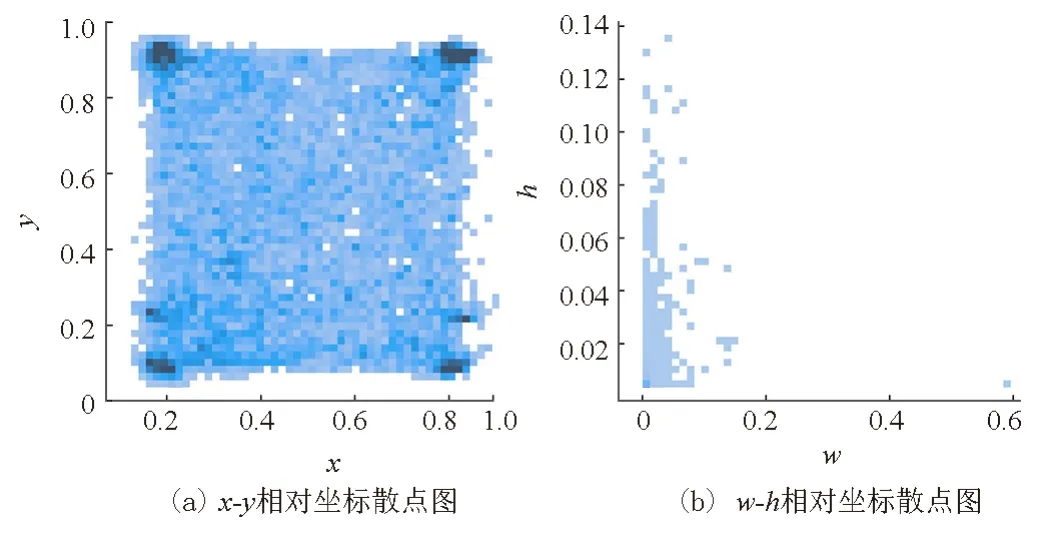
图3 原始数据的标签位置和尺寸统计结果Fig.3 Statistical results of label position and size of raw data
由于缺陷的平均绝对尺寸为21.8 px,且图像分辨率过大,为减少数据计算量,在模型训练的过程中,在数据预处理阶段需要将训练数据自适应缩放到统一的640 px×640 px。缺陷特征和标签同时缩小一个数量级,会导致数据集中的大部分目标在输入网络之前只有2~3个像素,甚至无法参与训练。因此,对数据集进行切片处理,保留有标签的图像块,过滤切片后标签与原始标签的比例小于0.1 的图像块和没有标签的图像块,切片尺寸为640 px×640 px,边缘重叠比率为20%。切片后的数据集共23 185 张图片,按照64%、20%、16%的比例划分训练集、验证集和测试集。切片后类别与标签尺寸统计结果如图4 所示。在没有改变数据类别分布的情况下,使更多的小目标参与到模型的训练,同时标签在图像中的位置分布更加随机。
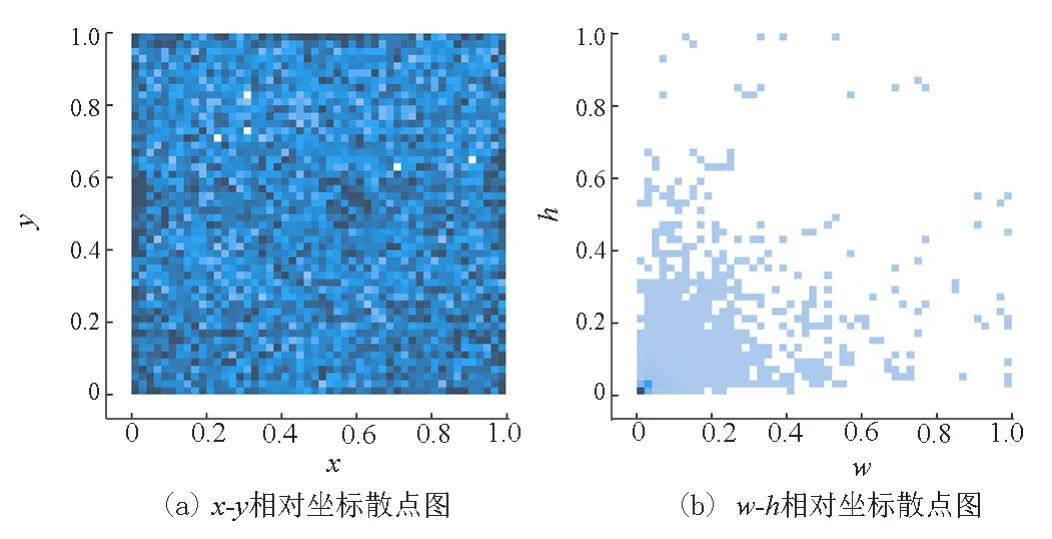
图4 图像切片后的标签位置和尺寸统计结果Fig.4 Statistical results of label position and size after image slicing
3.2 评价指标
实验采用目标检测算法中常用的评价指标,包括精度(precision,P)、召回率(recall,R)、平均精确率均值(mean average precision,mAP),其中,除了计算50%交并比阈值下各个类别的平均精确率均值(mAP50),还考虑了在50%至95%交并比阈值范围内,以5%步长共计10组阈值上的平均mAP(mAP50-95)。精度、召回率和交并比精度均值分别表示为
式(6)~(8)中:TP 为正例中模型的正确预测;FP 为负例中模型的错误预测;FN 为正例中模型的错误预测;AP为P-R曲线的积分面积;mAP为各个缺陷类别的AP均值。
3.3 实验结果对比分析
通过引入CIoU 作为自适应锚框匹配中KMeans 的距离表示,所有标签的平均CIoU 和锚框数量K的关系曲线如图5所示。
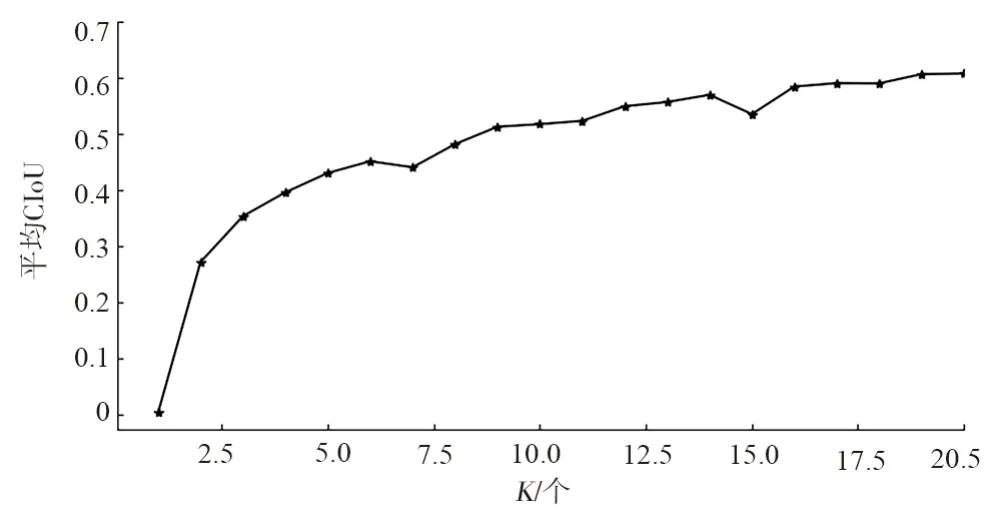
图5 平均CIoU与锚框数量K的关系曲线Fig.5 Average CIoU vs. number K of anchor frames
由图5可见,真实框的平均CIoU 与锚框数量K之间呈正相关关系。当初始锚框数量K为9 时,平均CIoU 约为0.5。随着锚框数量K的增加,平均CIoU缓慢增长。然而,随着K的增加,模型的复杂度也会增加,并且带来更多的负训练样本。
随着特征图上总锚框的数量增加,如何将它们分配到不同尺度的检测头上成为一个亟待解决的问题。对比存在2 种可行的解决方案,第1 种是在3 个检测头上各增加一个锚框,这意味着每个尺度的特征图上分配4个锚框;第2种是增加一个更小尺度的目标检测头,同时保持每个检测头上的先验框数量不变。
为了对实验进行评估,设置4 组实验:第1 组是对照组,即不进行任何改变;第2 组改变距离度量方法;第3组改变锚框数量;第4组改变检测头的数量。实验结果如表2所示。
根据表2,可以得出以下结论:
1)在检测头上锚框数量不改变的情况下,第2组实验的性能优于第4组实验。第2组实验的检测精度、召回率、mAP50 和mAP50-95 都有明显提升,检测精度从73.8%提升至79.4%,提高5.6%;召回率从69.0%提升至76.5%,提高7.5%;mAP50 从72.6%提升至78.9%,提高6.3%;mAP50-95从34.1%提升至41.6%,提高7.5%。而第4 组实验的性能提升较小,检测精度从73.8%提升至77.2%,提高3.4%;召回率从69.0%提升至73.9%,提高4.9%;mAP50从72.6%提升至75.4%,提高2.8%;mAP50-95从34.1%提升至38.0%,相比较于初始模型提高3.9%。
2)增加高分辨率检测头会增加模型的参数量(Params)和浮点运算量(FLOPS)。参数量从7.0 M提升至7.2 M,提高0.2 M;每秒浮点运算从15.8 G提升至18.6 G,提高2.8 G。
3)在检测头数量不变的情况下,第3 组实验(使用CIoU 度量的K-Means 聚类算法)的性能显著提升。检测精度从73.8%提升至78.5%,提高4.7%;召回率从69.0%提升至76.3%,提高7.3%;mAP50从72.6%提升至78.7%,提高6.1%;mAP50-95从34.1%提升至41.3%,提高7.2%。
综上所述,根据实验结果可知,9个锚框比12个锚框在性能上更佳,且没有增加模型的参数量和计算量。另外,使用CIoU度量的K-Means聚类算法能有效提高模型对瓷砖缺陷的检测性能。
为验证将Res2Net残差块应用在不同深度的特征图上是否对模型的检测性能有影响,本文设置多组对比实验,实验结果如表3所示。表3中:“√”表示在对应下采样率的C3模块中应用Res2Net残差块。所有实验均经过锚框优化且锚框数量K=9。

表3 Res2Net残差块应用在不同下采样层的性能对比Table 3 Performance of Res2Net unit applications in different downsampling layers compared
由表3的结果可知,Res2Net残差块会带来更多的参数量和计算量。另外,Res2Net残差块应用在特征提取网络中的不同层均对模型的检测性能存在不同程度的影响。其中,将残差块应用到1/32 下采样层的C3 模块中,各项评价指标都有所提升,模型对缺陷的检测精度从79.4%提升至80.0%,提高0.6%;召回率从76.5%提升至78.1%,提高1.6%;mAP50 从78.9%提升至80.5%,提高1.6%;mAP50-95 从41.6%提升至42.6%,提高1.0%。实验结果表明,Res2Net 残差块更适用于处理检测任务的深层全局信息,能有效提高瓷砖缺陷的检测性能。
为了验证上述2种优化方法对瓷砖表面缺陷检测的综合性能影响,在瓷砖瑕疵数据集上对模型进行训练和测试。实验的初始算法为YOLOv5s(6.2版本)检测模型,所有实验设置相同的参数和训练技巧,实验结果如表4所示。

表4 不同改进方法的实验结果Table 4 Experimental results of different improvement methods%
从表4 中可以看到,基于CIoU 度量的K-Means 算法对数据集进行锚框匹配后,模型的精度从73.8%提升至79.4%,提高5.6%;召回率从69.0%提升至76.5%,提高7.5%;mAP50 从72.6%提升至78.9%,相比较于初始模型提高6.3%;mAP50-95从34.1%提升至41.6%,相比较于初始模型提高7.5%。在此基础上,在C3 模块中引入Res2Net 卷积块后,模型的精度从79.4%提升至80.0%,提高0.6%;召回率从76.5%提升至78.1%,提高1.6%;mAP50 从78.9% 提升至80.5%,提高1.6%;mAP50-95 从41.6%提升至42.6%,提高1.0%。综上所述,本文提出的自适应锚框匹配算法和C3模块的优化方案在瓷砖缺陷检测任务中取得良好的效果。
为了验证本文改进方法对瓷砖表面各个类别瑕疵的检测性能,将优化后的算法与其他检测模型进行比较,采用AP 和mAP50 来评估各个类别的性能。进行模型推理时,在类别预测正确的情况下,预测结果与原始标签的IoU大于0.5视为正确预测,小于0.5 则视为错误预测。实验结果如图6 所示。综合评估指标显示,本文算法在检测性能上优于其他6 种算法,并且对各个类别的检测性能更加均衡。这证明本文算法在满足对瓷砖缺陷高精度要求的同时,能够更好地检测各类瑕疵。
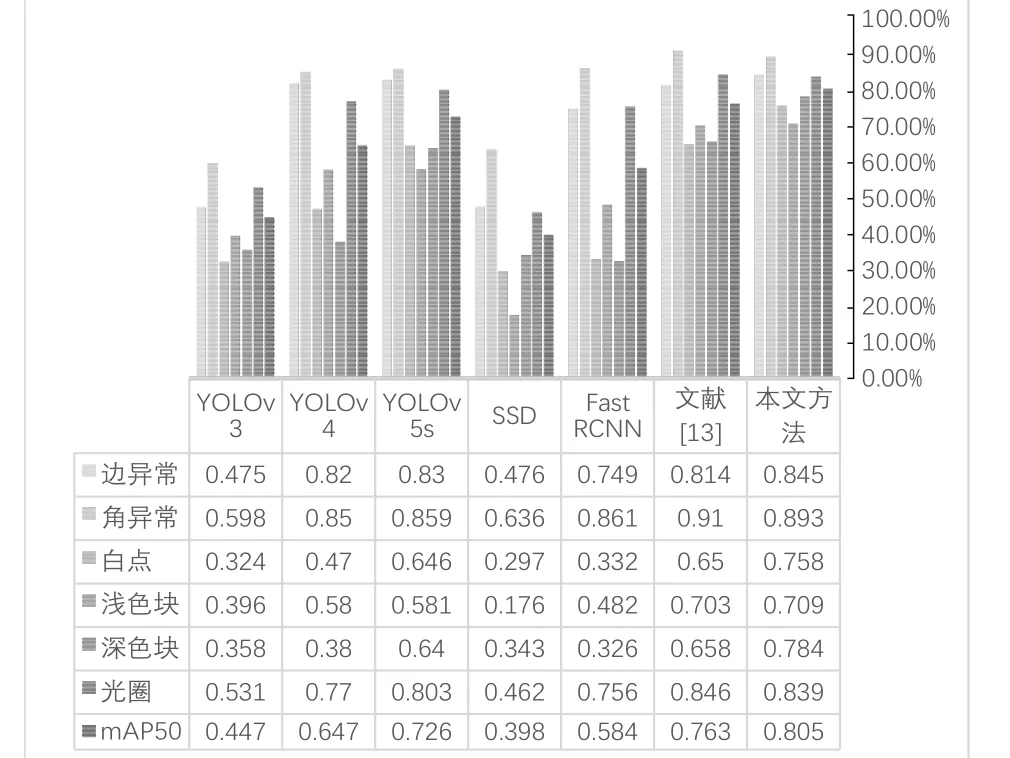
图6 不同算法对瓷砖各个瑕疵的检测性能对比Fig.6 Detection performance of different algorithms on individual defect of ceramic tiles compared
为了直观展示本文算法的有效性,图7 展示改进前后网络在瓷砖切片图像上的检测效果。从图7中可以清楚地看出,本文算法相较于传统的YOLOv5模型,在瓷砖缺陷检测方面具有更好的表现。本文算法能够检测出更多YOLOv5漏检的瓷砖缺陷,例如更细粒度的深色块类型的缺陷和边异常类型的缺陷。此外,对于角异常类型的缺陷,传统的YOLOv5只能检测出角异常的局部区域,而本文算法能够检测出更完整的角异常类型缺陷。

图7 改进前后算法的检测效果对比Fig.7 Detection effects of original and improved networks compared
为了进一步解决YOLOv5在高分辨率图像上的漏检问题,并实现对高分辨率图像的端到端缺陷检测,本文采用文献[17]中提出的滑窗算法。该算法通过对高分辨率图像进行滑窗推理,对每个窗口进行独立的检测,并将所有推理结果映射回原始高分辨率图像上。本文算法在瓷砖高分辨率图片上进行缺陷检测的结果如图8所示。从图8中可以观察到,采用滑窗算法进行缺陷检测,本文方法能够检测到高分辨率瓷砖图像中的极小缺陷。这进一步验证本文算法在解决YOLOv5在高分辨率图像上漏检问题方面的有效性,并展示其在端到端缺陷检测任务中的能力。

图8 本文方法在瓷砖高分辨率图片上进行缺陷检测的结果Fig.8 Results of defect detection on high-resolution pictures of tiles using this method
4 结论
为了解决瓷砖质检过程中瓷砖缺陷漏检和检测精度低的问题,提出一种改进型的YOLOv5网络瓷砖表面缺陷检测方法。首先,该方法引入基于CIoU 度量的适应锚框匹配算法。通过对数据集标签进行聚类,重新获取9个更适合数据集的先验框。这样可以降低极端长宽比缺陷漏检的风险,提高检测性能。其次,在特征提取网络的C3模块中引入Res2Net残差块。这个改进使得网络在模块级别上能够提取更细粒度的多尺度特征,从而提高模型的检测精度。最后,在模型推理阶段,采用在线滑窗检测算法,对高分辨率图像进行滑窗预测,实现对整个高分辨率图像的端到端预测。这样可以更好地处理高分辨率图像上的缺陷,并提高检测的准确性。实验结果表明,本研究提出的自适应锚框匹配算法和C3模块的优化方案能够有效提高YOLOv5算法在瓷砖缺陷检测方面的性能。瓷砖表面缺陷检测的精度由73.8%提升至80.0%;召回率由69.0%提升至78.1%; mAP50 由72.6%提升至80.5%;同时,与其他主流算法相比,本研究具有更好的检测效果和鲁棒性。这些改进措施有效地解决瓷砖缺陷漏检和检测精度低的问题。
未来的工作可以考虑使用注意力机制和其他有效的策略进一步优化模型,以避免模型对背景中的小目标产生误检,并进一步提高缺陷检测的准确率。另外,还可以探索如何优化高分辨率图像的滑窗预测过程,以降低检测时长,提高效率。
猜你喜欢
信号处理(2022年11期)2022-12-26 13:22:06
计算机与生活(2022年11期)2022-11-15 16:17:48
计算机工程与科学(2022年8期)2022-08-20 01:39:22
中南民族大学学报(自然科学版)(2022年3期)2022-05-08 03:51:12
雷达学报(2020年3期)2020-07-13 02:27:16
现代装饰(2019年10期)2019-10-17 02:04:20
小学生学习指导(中年级)(2018年4期)2018-09-06 09:34:16
太空探索(2015年8期)2015-07-18 11:04:44
浙江大学学报(工学版)(2015年1期)2015-03-01 01:17:19
航天返回与遥感(2014年4期)2014-07-31 17:47:42
