
基于级联稀疏查询机制的轻量化火灾检测算法
2024-01-13 12:31张小雪吴思远孙帮勇
光电工程 2023年10期
张小雪,王 雨,吴思远,孙帮勇,*
1 西安理工大学印刷包装与数字媒体学院,陕西 西安 710054;
2 中国科学院西安光学精密机械研究所光谱成像技术重点实验室,陕西 西安 710119
1 引言
火灾是人类日常生活中的主要灾害之一,及时、准确地发现火灾可以为消防灭火、人员救助赢得宝贵时间,有效保障人们生命财产安全。随着成像传感器和智能计算的发展,火灾检测已逐渐发展为宽波段探测和实时信息处理的自动检测过程。
分析火灾检测技术的发展过程可知,火灾检测主要分为两类:基于传感器原理的火灾检测和基于计算机视觉的火灾检测。基于传感器原理的火灾检测主要利用烟雾传感器、颜色传感器或者热传感器进行火焰或者烟雾的识别。应用该类传感器检测火灾时,只有火焰或者烟雾弥散至传感器一定距离范围内且达到浓度阈值才能触发报警,因此无法对早期火灾进行准确预警,不适合用于较大场景或者相对开放的空间。同时,基于传感器的火灾检测方法误检率较高,在实际应用中存在一定缺陷。
近年来,计算机视觉技术快速发展,在火灾检测领域围绕计算机视觉技术可分为基于机器学习和基于深度学习两类检测方法。基于机器学习的火灾检测,肖潇等[1]主要利用模式识别原理进行火焰特征与烟雾特征提取,进而实现火灾检测。火灾检测的关键是对火灾特征的提取和识别,现有机器学习的检测方法大多是通过研究火焰和烟雾的静态特征和动态特征完成检测。其中,静态特征主要包括颜色特征、形状特征、纹理特征和边缘特征等;动态特征主要包括运动特征、形状的变化等。例如,Demirel 等人[2]提出一种对火焰像素在YCrCb 颜色空间进行分类的算法,通过对火焰和非火焰像素进行训练,构建了火焰像素分类器。但是该方法误报率较高,无法运用到实际场景。Qiu等人[3]提出一种边缘检测算法用于分割火焰前景,但主要适用于背景简单的火灾场景,在复杂背景下难以正确分割出火焰。邵婧等人[4]提出基于动态纹理特征分析的火灾检测算法,对较大空间的火灾检测率较高,但难以区分实际火灾区域和颜色与火焰近似的非火灾区域。为了降低误报率,Surit 等人[5]通过提取火焰的静态与动态特征,对接近火焰和烟雾特征的区域进行分析并提出一种误检率较低的火灾检测模型。总体上,大部分基于机器学习的火灾检测方法是针对特定的单一场景提出,所建立的检测模型泛化能力差,容易受火灾区域周围环境的影响,特别是光照、天气等因素,难以适应复杂实际场景的火灾检测需求。
基于深度学习的火灾检测方法在最近几年取得了显著性进展,具有准确性高、成本低、速度快等优势,已被证明可应用于多种现实场景的火灾检测任务。比如,Zhang 等人[6]提出了一种联合的深度卷积网络火灾分类器,首先在全局图像上对火灾特征进行提取,然后在感兴趣火灾区域使用细粒度面片分类器检测火灾面片的精确位置。Dunnings 等人[7]在训练时间不变的情况下,使用降低复杂度的深卷积神经网络Inceptionv1 进行实时火灾区域检测。Sharma 等人[8]在数量较少的火灾数据集上使用VGG16 和ResNet50预训练的卷积神经网络进行火灾数据集的训练,并在全连接层上进行微调以增强这些网络。后来,为了进一步提高火灾检测性能,Akhloufi 等人[9]提出一种Deep-Fire 卷积神经网络算法,在复杂的火灾图像上取得了较高检测精度。任嘉锋等人[10]基于改进的YOLOv3 网络提出火灾检测方法,其针对YOLOv3小目标识别性能不足的问题进行改进,将火灾检测与识别任务转换为多分类识别和坐标回归问题。而缪伟志等人[11]通过改进YOLOv4 网络并将其部署在嵌入式设备上进行森林火灾检测,获得了较低的误检率,不过实时性较差。刘凯等人[12]提出支持向量机算法,建立了实时监测系统对森林火灾进行全天候自动检测,但网络的训练过程较复杂。为了减少模型复杂度,提高检测速度,皮骏等人[13]基于YOLOv5s 的轻量化森林火灾检测方法,进行了分类实验,采用 Shufflenetv2替换主干网络,有效降低了参数量,不过检测精度仍有待提高。以上基于深度学习的火灾检测网络,在与训练集类似的场景下都获得了相对满意的检测结果,但仍存在一些不足:1)模型的泛化能力仍有待提高,难以满足复杂场景中多尺度火灾目标的检测要求;2)对小目标的火灾检测精度低,尤其是远距离的小型火灾目标经常被漏检;3)模型的速度与精度难以达到平衡,在现实场景应用中仍存在缺陷。
针对以上问题,本文基于YOLOv5s 网络基础框架,提出了一种基于级联稀疏查询机制的轻量化火灾检测网络LFNet。首先,对传统YOLOv5s 的主干网络CSPDarkNet 进行改进,在网络中嵌入了一种轻量化的注意力模块ECA[14](efficient channel attention),建立了新的主干网络模块ECDNet (efficient channel attention darkNet)。ECDNet 能够在不同级别的特征层中提取细粒度更高的特征信息,解决了多尺度火焰特征导致的检测精度低等问题;同时设计了一种新的轻量化级联查询模块CSQH (cascade sparse query head,CSQH)用于预测火焰概率和位置,能够在不增加网络参数量的情况下提高较小火焰目标的检测性能。
2 网络架构与基本原理
针对火灾检测任务,本文设计了一种轻量化的检测网络LFNet,结构上主要包含:主干网络ECDNet、深度特征提取模块FPN+PAN 以及火灾预测模块CSQH。如图1 所示,火灾检测过程中,首先,输入彩色图像在主干网络ECDNet 中进行特征提取,获得不同级别和不同细粒度的烟雾特征;然后,主干网络提取的特征被送入深度特征提取模块FPN+PAN 进行深度特征提取和融合,从而对烟雾特征进行深度处理和提取;最后,在设计的轻量化预测模块CSQH 中引入级联查询机制,计算出不同尺度火焰目标的类别概率和位置。
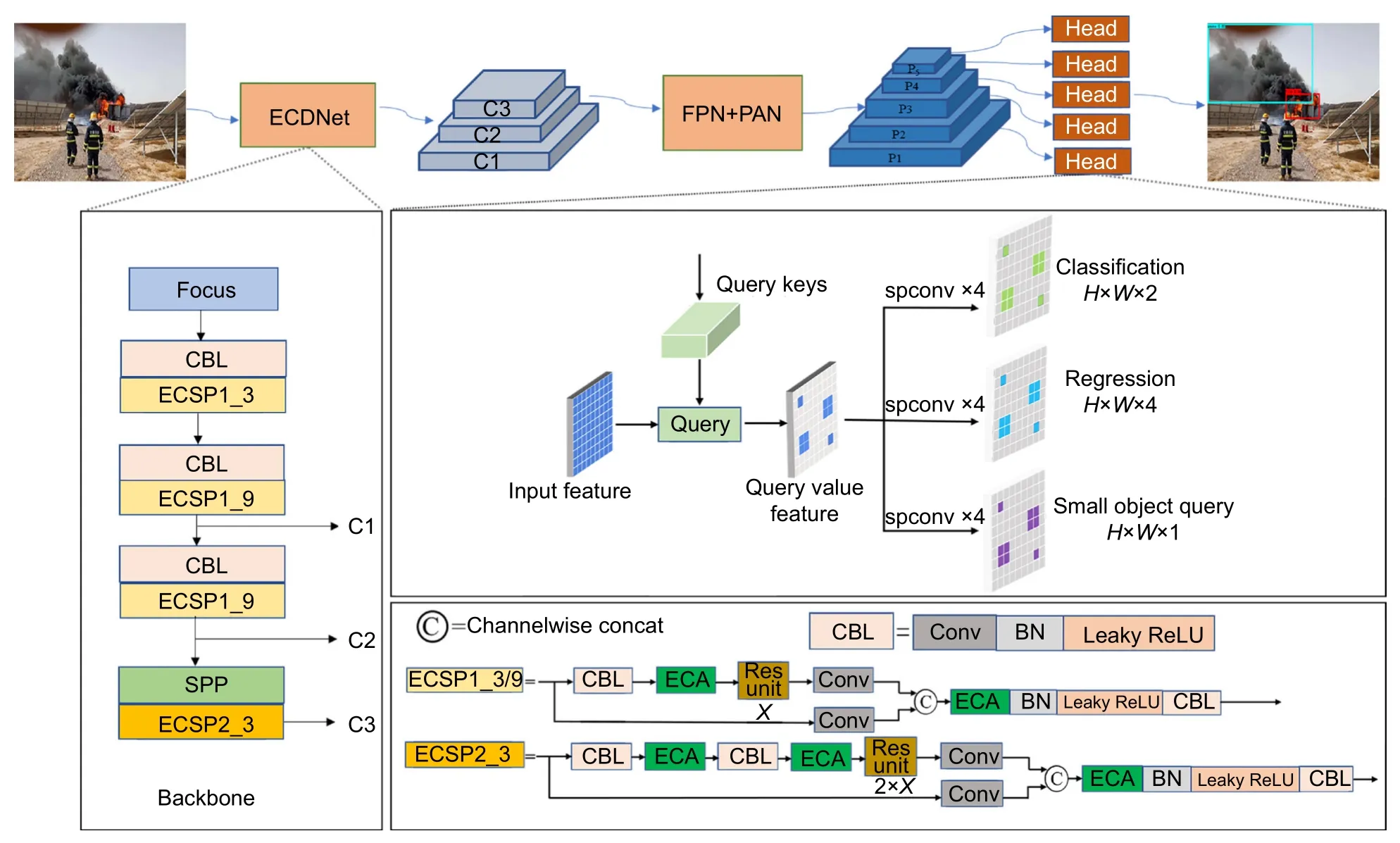
图1 LFNet 网络架构图Fig.1 Network architecture of LFNet
2.1 改进的主干网络模块ECDNet
现有火灾检测系统多基于YOLOv5 主干网络进行特征提取,然而通过大量实验发现,YOLOv5 主干网络中的残差结构易造成部分细粒度特征丢失,使得一些类火和类烟目标被检测为火焰,导致火灾检测系统的误检率偏高。为此,本文对传统的YOLOv5 主干网络中的残差结构进行改进。如图1 所示,主干网络ECDNet 主要包括Focus 模块、CBL 层、ECSP1_3模块、ECSP1_9 模块、SPP (spatial pyramid pooling)模块以及ECSP2_3 模块。首先输入 640×640×3的彩色图像到主干网络ECDNet 中,Focus 模块对进入主干网络的图片进行切片处理得到 320×320×64的特征图,切片操作目的解决图像下采样中的信息丢失问题。接着通过CBL 层和ECSP 模块进行特征提取,其中残差结构ECSP1_3、ECSP1_9 以及ECSP2_3 中嵌入了轻量化注意力模块ECA,有助于提高不同细粒度特征的提取精度,SPP 模块有效地避免了对特征信息的重复提取。为了得到不同级别和不同细粒度的特征图,文中采用步长为2 的3×3 卷积核提取特征,卷积核个数分别为 256、512、1024,选择 C1:80×80×256、C2:40×40×512、C3:20×20×1024 三种不同尺寸的特征图送入深度特征提取模块进行特征融合。
ECSP 模块是一种嵌入了ECA 注意力的轻量化残差模块,能够在增加少量参数的情况下,有效避免网络残差结构中细粒度特征的丢失,从而实现网络特征提取能力的提升。ECA 注意力模块本质是一种未降维的跨通道交互模块,其中,不降维有利于细粒度特征的提取,跨通道交互能够降低模型复杂度并提高检测精度。ECA 模块的结构如图2 所示,H、W代表高和宽,C表示通道维数。若定义K代表跨通道交互的相邻通道数,则其与所采用1×1卷积的卷积核数相同,也与通道维数C成正比。在ECA 模块中,利用非线性函数,当确定通道维数C后,K值就可以自适应地通过式(1)计算:

图2 ECA 注意力模块原理示意图Fig.2 Efficient channel attention module
其中:|.|odd表示取最邻近奇数操作,m 和o 是常数,本文分别取为2 和1。另外,在特征提取部分的通道数C值设定为32,64,128,256,则通过公式计算可得,本文方法的K值分别为3、3、4、4。利用式(1)自适应确定K值,能够显著降低特征提取过程的运算量。
ECA 注意力模块通过对特征图进行通道维度的注意力加权,可以捕捉到空间上不同位置之间的关联性。如图3 所示,嵌入ECA 注意力模块后可帮助ECDNet 更好地捕捉火灾特征。此外ECA 注意力模块在增强特征表达的同时,可以减少计算资源的消耗,从而提高模型检测性能和实时性。

图3 (a)原图;(b)注意力热力图Fig.3 (a) Original;(b) Attention mechanism heat map
2.2 深层特征提取模块FPN+PAN
深层特征提取模块主要对主干网络输出的不同层级的特征图进行多尺度融合,并将图像特征传递给预测模块。如 图1 所示,深层特征提取采用了FPN+PAN 结合的双金字塔结构。FPN (Feature pyramid network,特征金字塔网络)自顶向下,将高层的语义特征往下传递,得到预测的特征图[15]。而PAN (path aggregation network,路径聚合网络)能够针对FPN 传递的语义特征信息进一步增强和融合[16]。深层特征提取模块通过在特征金字塔网络FPN 的后面增加一个PAN 自底向上的路径,用底层精确的定位信息来增强整个特征层次结构,从而缩短底层特征与高层特征之间的信息路径。因此,主干网络提取的浅层特征,通过FPN+PAN 模块进一步提取后,得到特征图更精确的语义信息和定位信息,这将有利于提高预测模块对于小目标火灾的检测精度。
2.3 预测模块CSQH
为了提高小目标烟雾的检测精度,本文在预测部分Head 中嵌入了用于提高小目标检测精度的轻量化级联稀疏查询机制[17],建立了新的预测模块CSQH。该模块不仅能够提高小火焰目标的检测性能,而且所采用的级联稀疏卷积降低了模型参数量,能够提高模型速度。
CSQH 预测模块的查询操作包括查询键、查询层、查询值。具体实现过程如图1 所示,图像被送入主干和深层特征提取模块,经过FPN+PAN 加工生成了一系列不同分辨率的特征图 Pl(l为特征图的级别)。Pl同时也作为预测模块CSQH 中的查询层(通过实验,本文选择从P3层开始查询),每一层从上一层接收一组小目标的查询键,即小目标的粗略位置,并应用查询操作生成稀疏特征图。然后稀疏检测头和稀疏查询头利用查询键预测对应目标的查询值,即上一层对应目标的检测框位置和类别概率,从而逐渐得到图像中不同尺度的火灾类别概率和具体位置。
如图4 所示,预测模块包含两个级联的查询操作,即:Large->Medium 和Medium->Small,其中Large,Medium,Small 指的是深层特征提取模块所对应的特征图Pl中目标的不同尺度的级别。以Large->Medium 为例。首先,模块在Large 级别层次的图像对小目标进行标记(将规模小于预设阈值s的对象定义为小目标,阈值s为特征层Pl上的最小锚框尺度);其次,在预测推理的过程中,模块选择预测分数小于阈值s的位置作为查询,并将这个位置映射到Medium 的特征图中,具体的映射原理如式(2)所示:
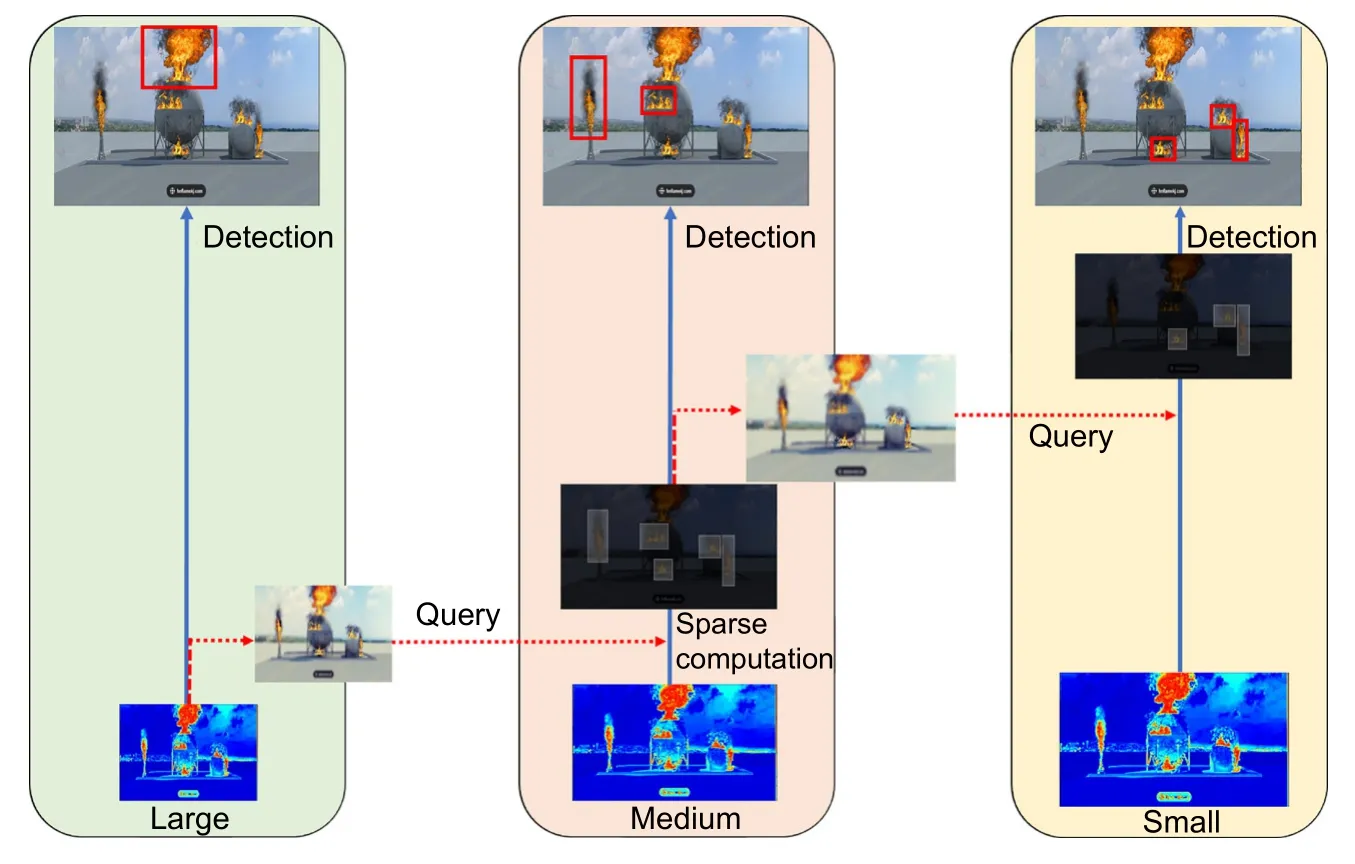
图4 级联查询机制模块原理示意图Fig.4 Cascade sparse query module
火灾检测中目标类别概率通过CSQH 中的Classification 进行预测,如图5 所示,原始图像通过提取特征得到一系列特征图,Classification 层分类时采用全连接层进行目标类别概率计算,经过softmax函数,将输出形式转化为概率形式。softmax函数定义如:

图5 头部预测原理示意图Fig.5 Cascade sparse query head module
其中,xi表示向量x中第i个元素。
目标的位置信息通过Regression 进行预测,目标的具体位置通过坐标偏移量来表示,原理如:
其中:bx、by、bw、bh分别指目标锚框的中心坐标与宽高尺寸,pw和ph代表预设锚框的宽与高,σ指sigmoid 激活函数;tx、ty、tw、th分别是目标框中心相对于预设锚框中心的偏移量;cx和cy代表目标所在的网格距图像左上角距离。最后坐标偏移量与预设锚框进行转换,输出目标框位置。图5 列出了一种火灾检测中的代表图像,检测结果输出以包围框形式输出。
2.4 k-Means++聚类生成锚框
YOLOv5 中锚框的生成采用k-means 聚类方法,在传统的k-means 算法中,初始聚类中心的选择具有随机性,会导致聚类结果不稳定和收敛速度慢的问题。k-means++方法在k-means 聚类基础上,改善了聚类中心的初始化问题。此外,不同的数据集上预设的锚框尺寸各不相同,因此为了生成适用于不同尺度火灾的锚框,利用k-means++聚类方法进行锚框计算。具体聚类过程如下:
a) 从数据集Χ中随机选择一个真实框的宽高作为初始聚类中心c1。
b) 计算每个样本与聚类中心的最小交并比距离D(x),依据概率计算式(5)选择下一个聚类中心,式(5)为:
c) 重复步骤b),直到选出K个聚类中心。
d) 根据选定的聚类中心,计算xi到K个聚类中心的交并比距离,将每个样本分配到最近的聚类中心。
e) 计算每个聚类的新中心,若聚类中心发生变化,更新聚类中心。原理为:
其中μi为聚类质心,即聚类中所有样本的平均值。
f) 重复步骤d)和步骤e),直到所有锚框的宽高不再变化或变化幅度很小,即生成最优结果。
依据锚框数量与平均IOU 曲线,图6 所示。实验最终选择9 个适用于火灾数据集的锚框尺寸,分别为SF-dataset 数据集:(26,33)、(47,68)、(93,69)、(91,128)、(64,241)、(185,126)、(159,259)、(320,247)、(453,459);D-fire 数据集:(10,13),(18,25),(23,54),(42,36),(46,94),(81,59),(88,145),(158,83),(221,205);FIRESENSE 数据集:(15,20),(31,33),(36,64),(67,76),(42,158),(141,87),(90,156),(158,183),(305,267)。三个数据集的聚类结果如图7 所示。

图6 SF-dataset 数据集上聚类实验结果Fig.6 Clustering experiment results on SF-dataset
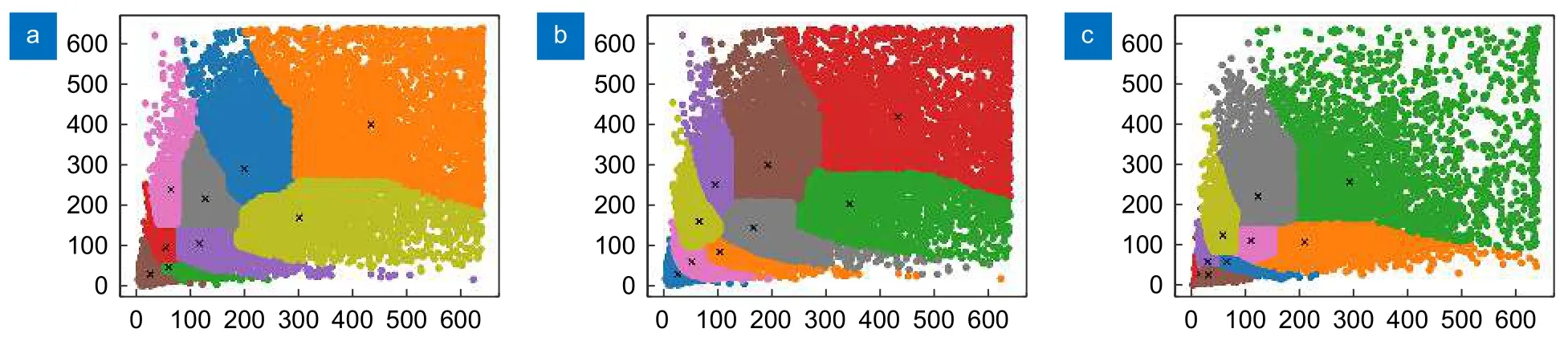
图7 聚类结果。(a) SF-dataset;(b) D-fire;(c) FIRESENSEFig.7 Clustering results.(a) SF-dataset;(b) D-fire;(c) FIRESENSE
因此使用k-means++聚类算法,可保证每个锚框的差异性尽可能大,以满足火灾检测的聚类要求,从而提升模型训练时边界框回归的速度与精度。
2.5 损失函数
有效的损失函数可提高模型的收敛速度与检测精度。实验设计的火灾检测损失函数由置信度损失,类别损失,定位损失三部分加权组合而成:
其中:Losscon代表置信度损失函数,为BCE 二值交叉熵损失函数,Losscla代表类别损失函数,为Quality Focal 损失函数,Lossreg代表边界框回归损失函数,为CIOU 损失函数。a,b,c代表三个可学习的损失函数权。BCE 损失函数用于预测矩形框的可信程度,取值范围0~1,值越大说明矩形框中越可能存在目标,其原理如:
其中:x表示样本,y表示标签,φ表示预测的输出,n表示样本的总数量。
Quality Focal 损失函数用于解决类别中正负样本不平衡分布的问题,其计算原理如:
其中:y为标签,y′为预测结果,指数因子γ减少了易分样本的关注度,特征贡献率因子α用于调节难分和易分2 种样本的特征权重贡献率。
CIOU 损失函数用于预测边界框的回归位置,计算原理如式(10):
其中:B和Bgt为预测框和真实框,ρ为预测框与真实框中心点的距离,d为包围预测框和真实框的最小包围框的对角距离。w和h为预测矩形框的宽和高,wgt和hgt分别为真实矩形框的宽与高。υ为归一化了预测框和真实框的比例差值,η为权衡长宽比例的平衡因子。实验通过采用类别损失与边界框回归损失相结合的Quality Focal-CIOU 损失函数,从而实现较快的训练收敛和预测框定位。
2.6 模型压缩Slimming
减少模型的参数量和计算量可以通过多种方法实现,例如优化主干网络,模型压缩等。但是考虑到模型实时性,仅仅关注参数量与计算量是不够的,还要关注模型在优化之后的推理速度,有些优化方案虽然减少了参数量与计算量,但模型的推理速度也在相应增长,这将导致模型的实时性变差。因此实验在对比了多种优化方案后选择使用Slimming 剪枝算法[18]对模型进行压缩。
Slimming 剪枝算法利用BN (batch normalization)层的γ参数来衡量当前通道的重要程度,并使用L1损失来稀疏化γ值。BN 层作为一种能加速网络收敛及提高网络性能的标准方法,被广泛应用于深度学习中,其基本公式如:
其中:zin和zout分别是BN 层的输入和输出,µB表示本批次该层输入的均值,σB表示本批次该层输入的方差。BN 层会对卷积后的输出特征乘上γ因子,即缩放因子来调整其分布,如果γ因子很小,那么这个通道的输出值也会很小,进而就代表着该通道对于后续网络的贡献就很小,在剪枝时就会删减这些不重要的通道,保留较为重要的通道,从而实现模型的压缩。Slimming 剪枝算法的定义公式如:
其中:(x,y)是训练的输入和目标,为网络中的可训练参数,前一项代表卷积神经网络中的训练损失函数,g(·)是缩放因子上的惩罚项,λ是两项的平衡因子。
在显示研究中,L1 为正则(g(s)=|s|),被广泛地用于稀疏化。该剪枝算法包含三个步骤:稀疏正则化,剪枝,微调,其中,稀疏正则化就是在模型训练时利用L1 损失来标记通道的重要程度,剪枝则是根据通道的重要程度进行修剪,而修剪不重要的通道可能会造成模型短暂的性能降低,因此在剪枝后还需要进行模型的微调。本文在进行模型稀疏正则化时仅利用原始训练集对模型进行稀疏训练,而在微调阶段时才利用数据增强后的训练集进行稀疏训练,实现高效的轻量化算法。
3 实验与分析
3.1 实验设置
本文在检测网络训练过程中,主要实验参数设置如下:Batch size 为64,学习率为0.001,循环迭代轮次为300,采用Pytorch 框架,实验GPU 为NVIDIA GTX 3090。
3.2 数据集
实验中选用了三个火灾数据集,分别为D-fire 数据集、FIRESENSE 数据集以及SF-dataset 数据集。Dfire 为公开的数据集,由21527 张不同尺度的火灾烟雾图片组成,包括森林中远距离的火灾烟雾,郊外不同尺度的火灾烟雾以及草坪远距离的小型火灾目标,数据集链接地址为:https://github.com/gaiasd/DFireDatase;FIRESENSE 为公开的数据集,由49 个视频组成,包括日常生活类火物体背景下的火灾烟雾以及浓烟背景下的火灾烟雾,数据集链接地址为:https://www.kaggle.com/datasets/chrisfilo/firesense。考虑到D-fire 数据集和FIRESENSE 数据集中场景比较单一,特别是缺少室内外建筑的多样化火灾场景,本文建立了SF-dataset 数据集。SF-dataset 数据集包含多种挑战性火灾场景,由18218 张火灾烟雾图片组成,包括室外火灾烟雾以及室内火灾烟雾等。本文将三种数据集分别按8:1:1 比例划分为训练集、验证集、测试集,具体分配如表1 所示。训练过程中,首先对火灾数据集进行数据预处理,通过读取数据集的XML文本来获得训练图像的存储路径以及图像中目标的标记像素坐标和目标类别。此外,为了使网络能够更好地学习到火灾的目标特征,需要对数据集进行数据增强。本文对训练图像采用了翻转、旋转角度、随机颜色、对比度增强、亮度增强等数据增强手段。

表1 三个数据集的训练集,验证集,测试集的详细统计数据Table 1 Numbers of training set,validation set and testing set for the three datasets
3.3 评价指标
本文使用训练的LFNet 网络对测试图像进行了一系列实验,以验证所提出方法的有效性。实验采用模型精度 (Precision)、召回率 (Recall)、准确率(Accuracy)、类别精度 (AP)、类别平均精度(mAP)、模型参数(Parameter)、检测速度(FPS)等指标进行评价,各项指标定义如:
其中:TP (true positives)为正样本被检测正确的数量;FP (false positives)为负样本被检测为正样本的数量;FN (false negatives)为背景被错误检测为正样本的数量;C表示类别数。
3.4 对比实验
为了验证提出的LFNet 网络的有效性,实验使用检测精度(Precision)、召回率(Recall)等指标在三个火灾数据集上与经典的检测算法进行了对比实验。对比方法包括3 类:3 种传统的火灾检测方法[2,19-20];3种现有的基于深度学习的火灾检测方法Fire-YOLO[21]、EFDNet[22]、Pruned+KD[23]以及3 种主流的通用型目标检测方法YOLOX-Tiny[24]、PicoDet[25]、YOLOv7[26]进行比较。此外,为了验证网络模型的轻量化,利用模型参数(Parameter)、检测速度(Speed)等指标在SFdataset 数据集上与主流的轻量化检测算法进行了对比实验。对比方法包括两类:5 种现有的基于深度学习的轻量化火灾检测方法:M-YOLO[27]、Fire-YOLO[21]、EFDNet[22]、Y-Edge[25]、Pruned+KD[23]以及5 种主流的轻量化目标检测方法 PPYOLO-Tiny[28]、YOLOXTiny[24]、PicoDet[25]、PP-YOLOE[29]、YOLOv7[26]。
表2 为不同对比方法在不同火灾数据集上以mAP、Precision、Recall 以及Accuracy 为客观指标的实验结果。通过实验结果,可以发现,对于相同的方法,无论在mAP、Recall、Precision 以及Accuracy 指标上,SF-dataset 数据集训练的模型的性能均优于Dfire 和FIRESENSE 数据集,这主要是由于涵盖了更多具有挑战性的检测场景,有助于网络训练获得更好的学习能力。在SF-dataset 数据集上,LFNet 网络实现了最佳的mAP、Recall、Precision 以及Accuracy,分别为71.76%、54.98%、89.12%以及98.5%。而在三个数据集上,相比于其他的方法,传统方法的各种性能指标均处于最低,这主要是由于传统火灾检测方法侧重于颜色,运动以及纹理等手工特征来检测火灾,不能完全提取火灾的特征,从而导致检测精度较低。相比之下,本文方法可以有效地提取火灾的特征,实现最佳的检测性能。
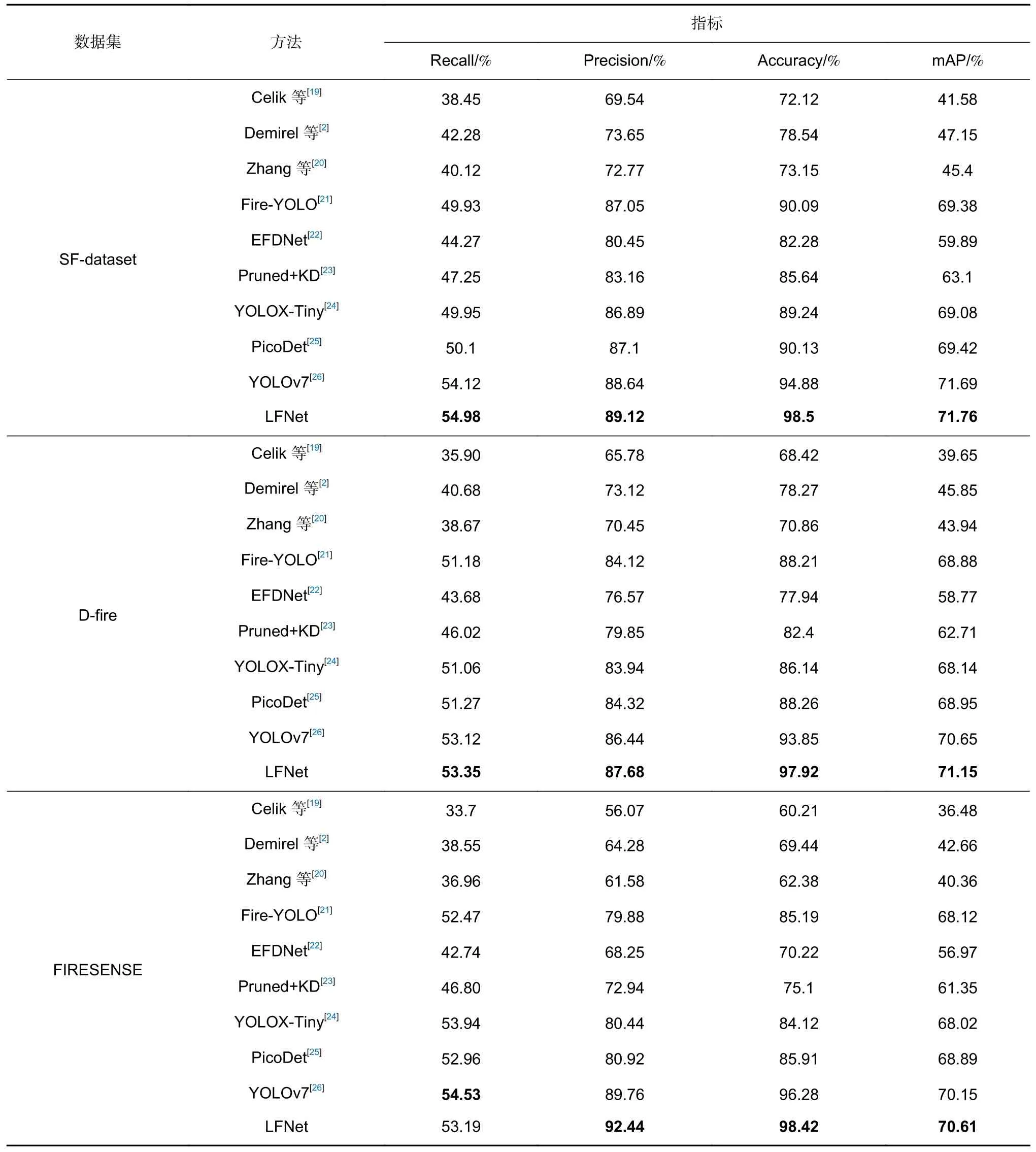
表2 不同数据集上不同方法的精度对比实验结果Table 2 Experimental precision results of different comparative methods on different datasets
表3 为不同方法在SF-dataset 数据集上以mAP、Speed、Flops、Parameter 以及Infer time 为指标的实验结果。如表3 所示,本文方法实现了71.76%的mAP,在所有方法中实现了最佳的检测性能。在Flops、Speed 以及Infer time 方面,PicoDet 达到了最优的效果,但其mAP 为69.42%,比本文方法低2.34%,比次优方法YOLOv7 低2.27%。通过实验结果可以看出,尽管本文方法在检测速度以及模型参数方面没有实现最优,但比大多数方法表现更好,实现了实时的火灾检测。因此综合检测性能的角度考虑,本文方法在各项检测精度中最优,同时模型参数大小合适,处理速度较快,是一种轻量化,低延时和高精度的火灾检测算法。此外,为了进一步验证本文方法的有效性,本文将LFNet 方法与几个具有代表性的方法进行了可视化的对比检测实验。图8 为 LFNet、EFDNet、Y-Edge、M-YOLO、Fire-YOLO、YOLOXTiny、PicoDet、PP-YOLOE 以及YOLOv7 方法分别在三种火灾数据集上不同场景下可视化的火灾检测效果。其中图8 主要包含建筑物火灾和浓烟同时存在的检测场景以及空旷的室外不同程度的火焰同时存在的检测场景;图9 主要包含森林中远距离不同尺度的火灾同时存在的检测场景以及草坪上远距离火焰和近距离的小火焰同时存在的检测场景;图10 主要包含日常生活中火灾与类火物体同时存在的检测场景以及雾霾与火灾同时存在的检测场景。从可视化的检测结果来看,本文方法无论是对于远距离的小火灾还是不同尺度火灾变化的场景,都能实现一个最佳的检测效果。

表3 SF-dataset 上不同方法的速度对比实验结果Table 3 Experimental speed results of different comparative methods on SF-dataset

图9 D-fire 数据集比较实验检测结果。(a) Images;(b) Ours;(c) EFDNet;(d) Y-Edge;(e) M-YOLO;(f) Fire-YOLO;(g) YOLOX-Tiny;(h) PicoDet;(i) PP-YOLOE;(j) YOLOv7;Fig.9 Comparison experiment detection results for the D-fire dataset.(a) Images;(b) Ours;(c) EFDNet;(d) Y-Edge;(e) M-YOLO;(f) Fire-YOLO;(g) YOLOX-Tiny;(h) PicoDet;(i) PP-YOLOE;(j) YOLOv7;

图10 FIRESENSE 数据集比较实验检测结果。(a) Images;(b) Ours;(c) EFDNet;(d) Y-Edge;(e) M-YOLO;(f) Fire-YOLO;(g) YOLOX-Tiny;(h) PicoDet;(i) PP-YOLOE;(j) YOLOv7Fig.10 Comparison experiment detection results for the FIRESENSE dataset.(a) Images;(b) Ours;(c) EFDNet;(d) Y-Edge;(e) M-YOLO;(f) Fire-YOLO;(g) YOLOX-Tiny;(h) PicoDet;(i) PP-YOLOE;(j) YOLOv7
3.5 消融实验
本文使用YOLOv5s 作为BaseNet,并采用五种策略在SF-dataset 上测试最有效的火灾检测精度。为了验证这些策略的性能,本文方法使用不同的设置进行了消融实验:1)改进YOLOv5s 的主干网络模块为ECDNet;2)使用FPN+PAN 作为深层特征提取模块;3)使用CSQH 预测模块替换YOLOv5s 的预测头部分;4)使用Quality-CIOU 作为网络的损失函数;5)利用Slimming 剪枝算法对网络进行压缩。
实验结果如表4 所示,尽管BaseNet 的mAP 达到67.89%,但其性能仍不能满足火灾检测的要求,例如对于一些有类火物体存在的场景以及远距离不同尺度的火灾场景,而且其模型参数大小达到了27.6 M。与BaseNet 相比,改进的主干网络ECDNet 的mAP达到了68.89%,在不增加模型参数的情况下,获得了1%的提高。在网络ECDNet 的基础上添加FPN+PAN,模型参数大小仅增加0.1 M,但模型mAP 从68.89%增加到70.15%,Recall 从50.96%增加到51.53%。由此可见,使用FPN+PAN 的特征融合方式有效提高了模型的检测性能。而当将网络的BaseNet的预测头部分替换成CSQH 时,模型的检测速度达到了91 f/s,mAP 提高了0.46%,特别是对于远距离小尺度火灾的检测性能,有了明显的改进。最后网络在分别使用了 Quality Focal-CIOU 损失函数和Slimming 剪枝算法后,模型的检测精度、模型参数大小以及检测速度均有了一定的提升,模型的mAP最终实现了71.76%,模型参数大小仅为12.6M,速度达到了98 f/s。因此综合实验结果的各项指标,可以看出每种策略对于LFNet 的有效性和优越性。
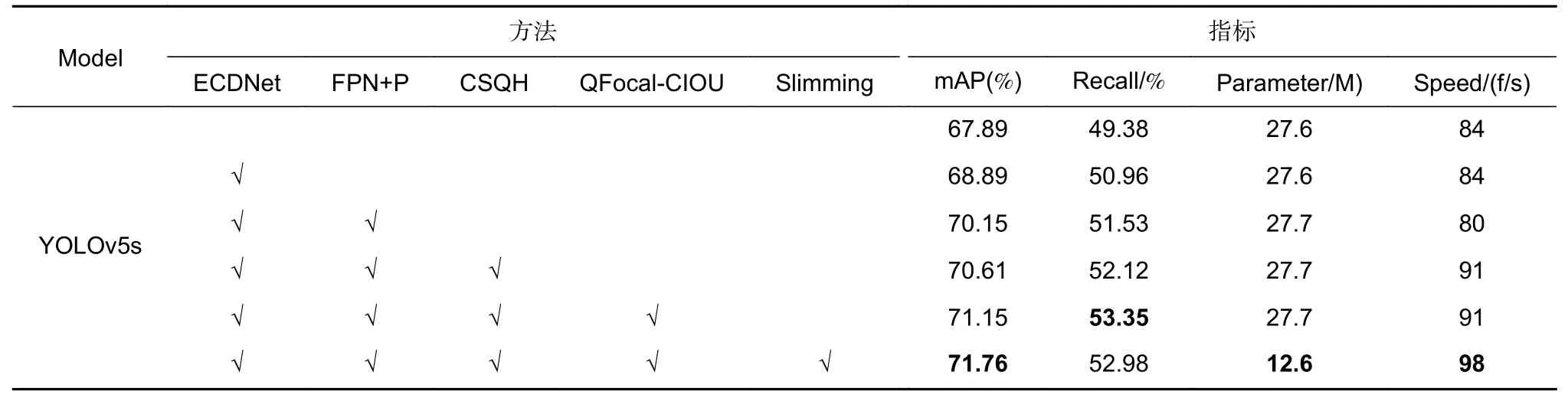
表4 消融实验的实验结果Table 4 Experimental results of Ablation experiments
3.6 参数实验
为了验证不同大小的训练数据集样本比例、Batch size、不同模型输入尺寸以及迭代次数epoch 对于所提出的LFNet 网络火灾检测精度的影响,实验在SF-dataset 数据集上进行了多个参数测试,实验结果如图11 所示。

图11 在SF-dataset 数据集上训练数据集样本比例、Batch size、模型输入尺寸以及迭代次数epoch 实验结果(a)训练数据集样本比例;(b) Batch size;(c)模型输入尺寸;(d)迭代次数epochFig.11 Parameters experiment of percentage of training samples,batch size and patch size on the Santa Barbara dataset(a) Percentage of training dataset samples;(b) Batch size;(c) Model input size;(d) Epoch
图11(a)显示了不同大小训练数据集样本比例对于模型精度的影响,在给定占比50%的训练数据集样本的条件下,本文方法的mAP 指标已达到69.53%;在一定的范围内,当不断提高训练样本占比时,在80%的训练数据集样本占比条件下,本文方法的mAP 达到了71.76%。
图11(b)给出了不同Batch size 大小对于模型精度的影响,选定的Batch size 分别为8,16,32,64,128。从图中可以看出,不同Batch size 条件下的mAP 指标存在一定差异,总体波动在2%之内。
图11(c)给出了不同的模型输入尺寸对于模型精度的影响。从图示结果可以看出,不同的模型输入尺寸与模型精度成正比,模型输入尺寸越大,模型精度也随之提高,但同时也伴随着模型参数大小的增加,这主要是由于随着模型输入尺寸的增加,网络能够捕捉更多的空间信息。因此,综合模型的检测精度与模型参数大小,本文最终选择了640×640 作为模型输入尺寸,在参数量足够小的同时提高模型精度,实现了速度与精度的相对平衡。
图11(d)给出了不同迭代次数(epoch)对于模型精度的影响,图示可以看出不同epoch 对于mAP 指标的影响有一定的影响,波动在2%之内。综合考虑模型速度与精度,本次迭代次数选用300。
4 结论
本文提出了一种基于级联稀疏查询机制的轻量化火灾检测算法,有效缓解了当前火灾检测算法面临的多尺度火灾的检测精度低,对小目标的漏检率较高以及速度与精度难以达到平衡等主要问题。本文采用轻量化的主干网络ECDNet 在不同级别的特征层中提取细粒度更高的特征信息,解决了多尺度火焰特征导致的检测精度低等问题;通过引入轻量化的CSQH 模块提高对小目标的检测性能;利用Slimming 剪枝算法来进一步减少模型参数量,使模型获得更好的性能提升。实验通过自建数据集以及公开的火灾数据集训练并搭建火灾检测模型。实验结果表明,在模型参数大小合适,速度较快的情况下,本文方法无论是在自建的火灾数据集还是公开的火灾数据集均达到了一个最优的检测效果,这将有利于基于计算机视觉的火灾检测方法在工业的应用。
猜你喜欢
电子制作(2018年11期)2018-08-04
电子测试(2017年15期)2017-12-18
雷达学报(2017年6期)2017-03-26
文理导航·趣味课堂(2016年6期)2016-09-09
测绘科学与工程(2016年5期)2016-04-17
电子设计工程(2015年6期)2015-02-27
电子设计工程(2015年3期)2015-02-27
河南科技(2014年14期)2014-02-27
华东师范大学学报(自然科学版)(2014年6期)2014-02-27
故事作文·高年级(2009年7期)2009-08-20
