
自适应特征融合级联Transformer视网膜血管分割算法
2024-01-13 12:30梁礼明卢宝贺龙鹏威
光电工程 2023年10期
梁礼明,卢宝贺,龙鹏威,阳 渊
江西理工大学电气工程与自动化学院,江西 赣州 341000
1 引言
视网膜血管图像包含丰富的几何结构,如血管直径、分支角度和长度等,眼科医生可通过观察视网膜血管结构信息来预防和诊断高血压、糖尿病和动脉粥样硬化等疾病。但眼底血管拓扑结构错综复杂,在医学提取上较为困难。因此研究一种能高效且自动的视网膜血管分割算法对临床病理诊断具有重要意义[1-4]。
当下视网膜血管分割方法主要分为传统机器学习和基于深度学习方法。其中传统机器学习方法包括基于形态学处理、基于匹配滤波和小波变换等,此类方法通常不需先验标记信息,而是利用数据之间的相似性进行分析。Marios 等[5]构建一种多尺度线跟踪方法,利用血管方向属性和形态学重建以实现视网膜血管分割,该方法减少了背景图像噪声影响,但无法充分利用血管信息,导致血管纹理模糊。Azzopardi 等[6]设计选择性响应滤波器实现视网膜血管的分割,该方法提高了分割交叉血管的能力,但分割结果易受图像噪声影响。王晓红等[7]采用多尺度二维Gabor 小波变换方法对视网膜图像进行分割,用不同方法提取粗细血管。此类方法先对视网膜图像进行预处理,其次对预处理图像进行阈值处理以实现视网膜血管分割。近年来,基于深度学习的方法被较多学者引入视网膜血管分割任务,并取得优秀的分割效果。深度学习方法是端到端的学习方式,可以自动提取图像底层和高层特征信息,相较于传统分割方法避免了人工特征提取的过程,同时减少了分割主观性,其泛化能力明显优于传统方法。如全卷积网络[8]通过在编码器路径中应用卷积、激活函数和池化层,并在解码器中采用卷积层和上采样,实现像素级语义分割。编解码网络结构UNet[9]性能已在诸多医学语义分割任务中领先,脑肿瘤分割[10]和肾肿瘤分割[11]中U-Net 均取得较好成效。Li 等[12]提出动态通道卷积网络(dynamic-channel graph convolutional network,DCGCN),将视网膜图像通道映射到拓扑空间,并在拓扑图上合成每个通道特征,进而提升视网膜血管的信息利用率。Wang等[13]构建多尺度上下文感知网络(context-aware network,CA-Net),为通道分配不同权重,使网络能够充分捕获血管上下文信息。Yang 等[14]设计强化神经P 型双通道扩张卷积网络(spiking neural P-type dualchannel dilated convolutional network,SDDC-Net)实现视网膜血管分割,将强化神经P 卷积神经元集成到经典编解码结构中,并在编码部分使用扩张卷积以提升感受野。虽然上述方法在视网膜分割任务中总体上取得了较好的血管分割效果,但仍存在一定缺陷,如文献[9]边缘检测能力较弱,易受到病理伪影干扰且网络运行效率较低;文献[12]忽略了全局上下文信息,会在一定程度上丢失血管轮廓信息;文献[13]血管边界检测能力较弱,出现微小血管纹理模糊问题;文献[14]采用扩张卷积扩大感受野,但会造成血管局部特征信息丢失。
针对上述挑战,本文提出自适应特征融合级联Transformer 视网膜血管分割算法(adaptive feature fusion cascade Transformer retinal vessel segmentation algorithm,AFCT-Net),其主要工作为:①在编码部分设计自适应增强注意模块,提升不同通道之间信息交互能力,同时剔除图像背景噪声信息降低病理伪影干扰,增强血管图像非线性能力;②在编解码底端加入级联群体Transformer 模块,有效聚合上下文血管特征信息,充分捕捉微小血管局部特征;③在解码部分引入门控特征融合模块,捕获编解码层不同尺寸空间特征信息,提升特征利用率及算法鲁棒性。
2 本文算法
2.1 算法设计
针对视网膜血管分割任务面临视盘边界误分割、病理伪影干扰和微小血管分割不完全等问题,本文基于U 型网络构建一种自适应特征融合级联Transformer 视网膜血管分割算法,其结构如图1 所示。AFCT-Net 由特征增强网络、自适应增强编码、门控特征融合解码及底端级联群体Transformer 模块四部分组成。首先对视网膜数据集原图像以滑窗裁剪为特征图像块的方式进行数据集扩充,以保证模型的充分训练与预测;其次进行图像灰度化、直方图均衡化和Gamma 校正等操作进行数据集图像增强,提升血管纹理对比度;再次自适应增强编码对其编码整合,提升不同通道之间信息交互能力和降低计算冗余;此外在网络底端设计级联群体Transformer 模块将编码信息进行多尺度融合,促进血管局部信息的有机提取;最后经门控特征融合部分整合编码信息,实现对血管特征图像的细粒度还原,并通过SoftMax 函数得到血管分割二值图像。

图1 自适应特征融合级联Transformer 视网膜血管分割算法Fig.1 Adaptive feature fusion cascade Transformer retinal vessel segmentation algorithm
2.2 级联群体Transformer 模块
Transformer[15]模型由Google 公司在2017 年提出,并应用于自然语言处理,随后Vision Transformer[16]出现并应用于图像分割领域,其具有较强的全局归纳建模能力,能够有效聚合上下文信息并摆脱模型对大规模数据的增广依赖。Liu[17]等构建级联群体注意模块,可以为具有不同特征的注意力头提供反馈,减少计算冗余,增强抗过拟合能力。为了建立血管特征长短距离依赖,提升微小血管提取能力,本文受文献[17]和文献[18]启发,融合构建级联群体Transformer 模块(cascaded group Transformer module,CGT),其结构如图2 所示。
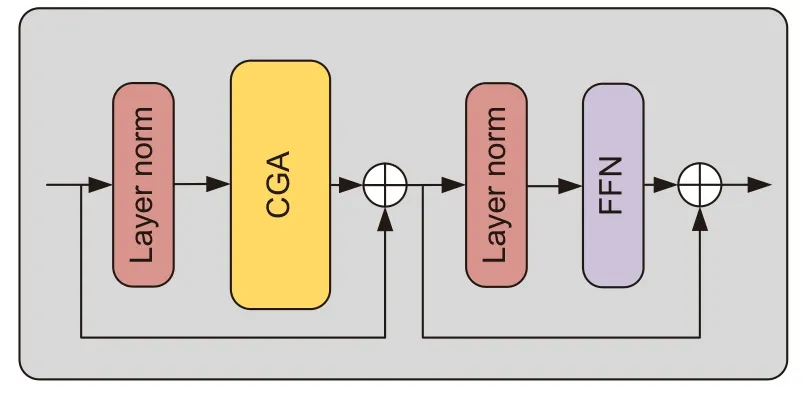
图2 级联群体Transformer 模块Fig.2 Cascade group Transformer module
CGT 模块由级联群体注意模块(cascaded group attention module,CGA)、layer norm 和前馈神经网络(feed forward network,FFN)组成。在视网膜血管分割领域中,图像经过编码后往往很模糊,需借助上下文信息才能增加分割准确性,故上下文建模对于视网膜分割任务至关重要,因此本文算法在编解码底部加入Transformer 模块,又因CGA 模块可以解决因为注意头之间高度相似性引起的计算冗余问题,从而提升网络训练及测试效率,故结合两者优点融合构建为CGT 模块,其中CGA 模块结构如图3 所示。

图3 级联群体注意模块Fig.3 Cascade group attention module
CGA 首先将视网膜血管特征分解,将不同的血管语义信息提供给每个注意头,从而明确分解头部之间注意力计算,解决计算冗余问题;其次QKV 层学习具有丰富信息的血管特征投影来提高模块能力,在Q 投影之后应用交互层以捕获视网膜血管局部与全局特征信息;最后将每个头部的输出添加到后续头部以逐步细化视网膜血管特征,其数学表达式可表述为
其中:Xi=[Xi1,Xi2,......,Xin],1≤j≤h,h是头部总数,是映射输入特征分割到不同子空间的投影层,是将级联输出特征投影变回与输入一致维度的线性层。
此类级联设计有两个优点:一是将不同的血管语义提供给每个注意头,以提高其多样性;二是级联注意力头可以增加网络深度,从而在不引入任何额外参数情况下提高模型容量。编解码底部引入级联群体注意模块,使其在高维空间中有更多通道来学习表示,以此防止血管信息特征丢失,减少冗余参数,加快推理速度,提高模型效率。
2.3 自适应增强注意模块
注意力机制在图像分割领域取得了较大成功,Hu 等[19]设计挤压激励模块(squeeze excitation,SE)模块,加强了高低分辨率特征之间的语义联系,排除了非血管噪声干扰。针对眼底视网膜血管图像多通道特性及非血管背景噪声干扰问题。本文受文献[19]启发设计自适应增强注意模块(adaptive enhanced attention module,AEA),其结构如图4 所示。
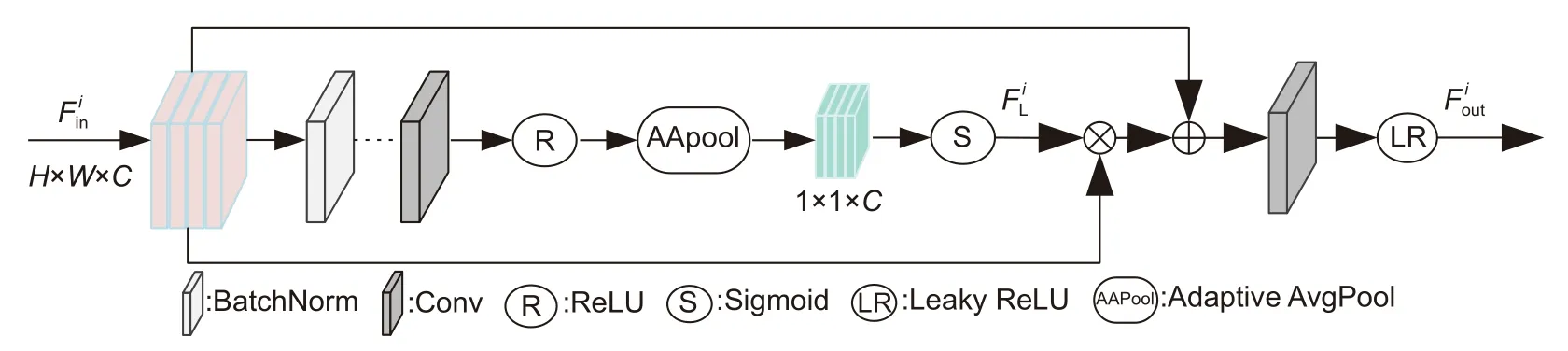
图4 自适应增强注意模块Fig.4 Adaptive enhanced attention module
其中:S表示Sigmoid 操作,λ表示自适应平均池化(adaptive AvgPool),σ表示ReLU 激活函数,Con表示卷积操作,BN表示BatchNorm 操作,δ表示Leaky ReLU 操作,表示第i层输入特征图,表示第一次Sigmoid 之后得到的特征图,表示第i层输出特征图。
2.4 门控特征融合模块
在视网膜血管分割任务中,血管特征利用率对分割结果至关重要。Ni 等[20]提出特征聚合网络,该网络可以融合不同解码层的高级特征提高特征利用率,以减少血管语义信息损失。为了充分利用编解码部分特征以提升血管分割光滑度,本文引入门控特征融合模块[21](gated feature fusion module,GFF),其结构如图5 所示。

图5 门控特征融合模块Fig.5 Gated feature fusion module
GFF 模块由复位门和选择门组成,输入端xi是未解码图像,需要复位门来抑制视网膜图像非血管背景噪声,而选择门能够将ei和di的语义信息融合。该模块首先自适应选择di的有用特征,实现xi和di的语义融合以整合编解码部分血管特征信息;其次经过卷积和Sigmoid 激活后分别得到Ri和Ti值,其计算公式如下:
其中:WR和WT分别表示以di和xi的串接为输入的卷积过程,S表示Sigmoid 函数,Ri和Ti分别表示复位栅极值和选择栅极值。
特征信息经过复位门后与原始图像xi特征相乘再与di拼接并卷积得到整合特征ei;通过选择门实现整合特征(ei)与原始分割特征(di)之间自适应互补特征融合。ei表示经过选择门的特征与原始特征融合卷积后的特征,其数学表达为
其中:W表示卷积过程,可以使重新整合的特征与输入di具有相同维度,fout表示输出特征图。
3 实验结果分析
3.1 实验环境与数据集
仿真平台为PyCharm,使用Python3.9.0 程序语言在Pytorch 框架搭建而成,计算机配置为11th Gen Intel(R) Core(TM) i7-11800H CPU,16 GB 内存,NVIDIA GeForce RTX 3060 GPU,采用64 位windows11 操作系统,眼底图像数据集来自公共数据集DRIVE、CHASE_DB1 和STARE。DRIVE 数据集中包括图像像素为565 pixel×584 pixel 的20 幅训练集图片和20 幅测试集图片。CHASE_DB1 数据集包括28 张视网膜样本图像,前20 个样本图像用于训练,其余8 个样本图像用于测试,每幅图像的大小为999 pixel×960 pixel,二值视野 (FOV) Mask 和分割Ground truth 通过手工方法获得。STARE 数据集包含20 幅眼底图像,图像分辨率为605 pixel×700 pixel,由于该数据集没有设置训练集及测试集,故采用五折交叉验证的方法进行实验。另外,三个数据集中均包括病变眼底图像与正常眼底图像,血管结构复杂多变且对比度低,每张图像包含两位专家手工标注的金标准图像,表明以上数据集对视网膜血管分割任务具有一定挑战性,故选用以上三个数据集进行实验并将第一位专家的金标准图作为实验参考标准。
3.2 实验数据预处理
由于数据集在采集时存在血管前景与非血管背景对比度低等问题,为了充分捕获视网膜血管特征信息及提升分割准确率,需对数据集图像进行预处理。如图6 所示,本文首先对数据集进行图像灰度化处理,减小内存占用降低计算冗余,突出目标区域;其次归一化眼底视网膜灰度图像,避免视网膜图像像素亮度分布不均匀;再次对灰度图像进行限制对比度直方图均衡化,减少光照不均匀对视网膜分割的干扰;最后将图像进行Gamma 校正,提升图像视盘部分和血管部分对比度,增强较暗血管部分可视度。

图6 视网膜图像预处理Fig.6 Retinal image preprocessing
3.3 图像扩充与参数设置
在网络训练中需要大量数据来拟合模型参数,而DRIVE、CHASE_DB1 和STARE 数据集较小,较小训练集样本不足以代表整个数据集统计特征,会导致模型在新数据上表现不如预期,模型训练会出现过拟合现象且泛化能力不足,需对数据集进行扩充。本文对图片以滑窗方式进行裁剪,以64×64 的滑窗将预处理之后的眼底图像以及金标准图像裁剪为10000 个特征图像块,损失函数采用交叉熵函数,初始学习率设置为 0.0005,batch_size 设置为6,number of epoches 设置为20,训练过程采取早停机制,若连续10 轮无最佳权重保存,则停止训练,本文算法在STARE 数据集中训练时间为每轮1 min 16 s,测试时间为52 s;在DRIVE 数据集中训练时间为每轮1 min 17 s,测试时间为2 min 48 s;在CHASE_DB1 数据集中训练时间为每轮1 min 17 s,测试时间为3 min 53 s。预处理图像局部特征图像块和训练集对应的金标准局部特征图像块,如图7 所示。

图7 血管局部特征图像块Fig.7 Local feature image blocks of blood vessels
3.4 评价指标
眼底视网膜图像分为两类:血管前景类和非血管背景类。血管前景类即需要检测分割的目标血管,称作正类;非血管背景类即其他剩余部位,称作负类。为了更清晰地展现出本文算法性能优异性,将本文算法视网膜分割结果与专家手工分割结果进行对比。对于血管前景像素特征,本文算法分割结果与专家手工分割值相同的比例称为真阳率(TP),相反则称之为假阳率(FP);对于非血管背景像素特征,本文算法分割结果与专家手工分割值相同的比例为真阴率(TN),相反为假阳率(FN)。
本文计算准确率 (accuracy,Acc)、灵敏度(sensitivity,Sen)、F1 分数(F1-score,F1)、特异性(specificity,Spe)和受试者工作特性曲线(area under curve,AUC),其具体公式分别为
3.5 不同分割算法之间对比
3.5.1 分割结果图客观分析
为了更好地体现本文算法在视网膜血管分割工作中的分割性能,在公开数据集 DRIVE、CHASE_DB1 和STARE 上进行验证,并同文献[9]及文献[22-24]算法进行比较,均采用相同环境进行训练以及测试。将本文分割结果与U-Net 和Attention U-Net 和Dense U-Net 和FR U-Net 进行对比,其中文献[9]为U-Net算法、文献[22]为Attention U-Net 算法、文献[23]为Dense U-Net 算法以及文献[24]为FR U-Net 算法。
图8 第一行、第二行为DRIVE 数据集中图像,第三行第四行为CHASE_DB1 数据集中图像,第五行、第六行为STARE 数据集中图像。由第一行健康视网膜图像知,本文算法和Dense U-Net 对病理信息有较好抑制效果,U-Net 对主血管分割时出现血管断裂问题,Attention U-Net 和Dense U-Net 出现微小血管分割不完全问题,FR U-Net 受到病理伪影影响严重,将病理信息作为血管分割,假阳性过高;由第二行病变视网膜图像可知U-Net、Dense U-Net 及FR U-Net出现微小血管分割断裂和血管缺口,U-Net 和Attention U-Net 出现丢失大量微小血管信息,因此灵敏度较低;根据第三行、第四行分割图像可以看出算法对主血管均有较好分割效果,重点关注微小血管分割情况,除本文算法外其他算法均出现不同程度误分割和未分割情况;由第五行STARE 数据集分割图像中可以看出本文算法较其他算法分割的微小血管数量较多且不易断裂,并能准确区分背景与目标,根据第六行STARE 数据集病理图像分割结果可以看出,UNet、Dense U-Net 和FR U-Net 错将病理信息分割为血管信息,且受病理信息影响血管周围较杂乱,而本文算法能够剔除病变斑点,减少血管缺失问题。
实验说明,本文算法在血管分割方面表现良好,能系统地捕捉血管形态结构信息,并且有更少假阳性血管,使视网膜血管分割图更清晰同时噪声更小,表明本文算法的有效性以及合理性。
3.5.2 分割局部图客观分析
为了更加直观展示本文算法与文献[9]及文献[22-24]算法的分割差别,图9 详细展示了各算法视网膜局部分割图,从DRIVE 数据集、CHASE_DB1 数据集和STARE 数据集中分别随机取出一幅图进行局部放大进行细节对比。

图9 不同算法视网膜血管局部分割图像Fig.9 Image of retinal blood vessel local segmentation by different algorithms
观察图9 知,在第一行DRIVE 数据集图像分割细节图中,U-Net 出现主血管分割断裂问题。Attention U-Net 主血管分割受到病理伪影影响较大,非血管背景像素分辨不明。Dense U-Net 出现微小血管未分割及血管分割断裂问题。FR U-Net 和本文算法分割效果较好,但本文算法相较于FR U-Net 算法主血管与微细血管能够平滑连接。在第二行CHASE_DB1数据集图像分割细节图中,重点将微小血管进行细节放大对比,观察对比图发现U-Net、Attention U-Net、Dense U-Net 和FR U-Net 均出现血管纹理信息缺失问题,微小血管分割出现不同程度断裂或未分割问题。在第三行STARE 数据集图像分割细节图中,U-Net和Attention U-Net 出现血管分割断裂问题,且除本文算法外其他算法均出现微细血管分割不完全问题。最后放大观察血管周围细节图可以看出U-Net、Dense U-Net 和FR U-Net 受病理信息影响较严重,血管周围较杂乱,而本文算法和Attention U-Net 能够剔除病理斑点,更好地分割血管信息。
综上所述,本文算法相较于其他算法有较大改进,能充分捕捉血管语义信息,从而在病变较严重且对比度较低的眼底图像中分割出更多微小血管,分割血管情况总体与金标准一致,说明本文算法在视网膜血管分割任务中的稳健性。
3.5.3 性能指标比较
为了定量分析实验结果,以此评估本文算法,从评估指标进行数据分析,均采用同一实验环境进行对比实验,其实验结果分别如表1、表2 和表3 所示。表1 统计了不同算法在DRIVE 数据集各项指标,表2统计了不同算法在CHASE_DB1 数据集各项指标,表3 统计了不同算法在STARE 数据集五折交叉验证各项平均指标,其中标粗为最优指标。图10 和图11分别展示了不同算法在DRIVE 和CHASE_DB1 数据集P-R 曲线及ROC 曲线对比图。AUC 指标与ROC相关,AUC 范围为 0~1,AUC 值越接近1,模型预测能力就越好,而AUC 值越低,表示预测模型错误分类率越高。图12 展示了本文算法在DRIVE 数据集以及CHASE_DB1 数据集上的训练过程损失趋势。DRIVE 数据集训练损失值维持在0.095 左右,CHASE_DB1 数据集损失值维持在0.085 左右,波动幅度较小,表明网络已趋于收敛。本文算法在DRIVE 数据集及CHASE_DB1 数据集经过三次训练,但结果相差甚微,故选用三次测试中指标较高的一次作为实验结果。

表1 DRIVE 数据集不同算法性能指标/%Table 1 Performance metrics of different algorithms for the DRIVE dataset/%

表2 CHASE_DB1 数据集不同算法性能指标/%Table 2 Performance metrics of different algorithms for the CHASE-DB1 dataset/%
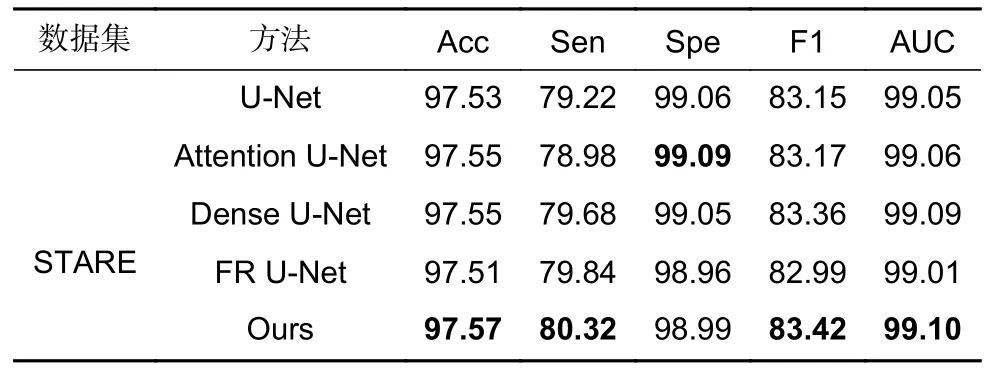
表3 STARE 数据集不同算法性能指标/%Table 3 Performance metrics of different algorithms for the STARE dataset/%
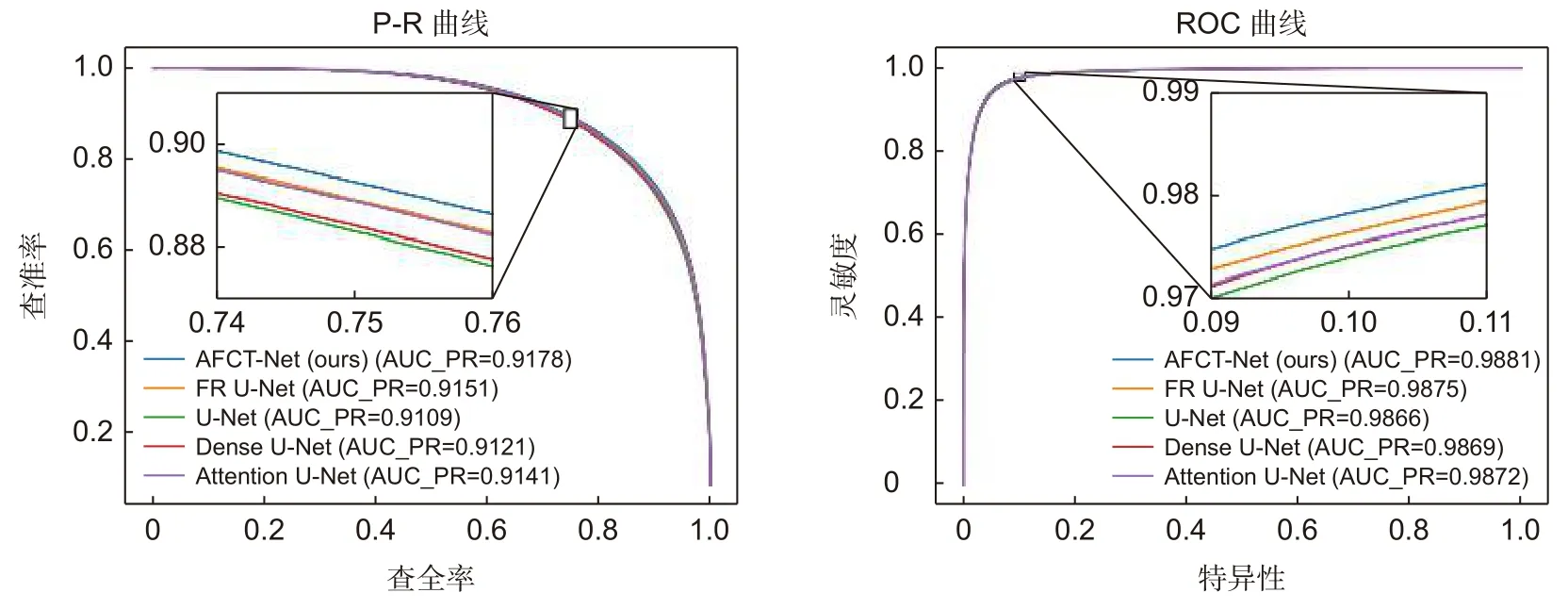
图10 不同算法在DRIVE 数据集P-R 曲线与ROC 曲线对比图Fig.10 Comparison between P-R curve and ROC curve of different algorithms in DRIVE dataset

图12 DRIVE 数据集和CHASE_DB1 数据集中训练损失曲线图Fig.12 Plot of training loss curves in DRIVE dataset and CHASE_DB1 dataset
在DRIVE 数据集中,FR U-Net 灵敏度高于本文0.13%,Attention U-Net 特异性高于本文0.06%,但本文算法准确率、F1 指数、ROC 曲线下面积均为最优。在STARE 数据集中,除特异性外本文算法其余指标均为最优。在CHASE_DB1 数据集中Attention UNet 特异性高于本文0.11%,Attention U-Net 和Dense U-Net 有较好抗过拟合性能,适合视网膜分割及其他训练数据相对匮乏的任务,但Attention U-Net 参数量较大,网络较为复杂,需要训练以及测试时间较长。FR U-Net 利用多分辨率卷积交互机制进行水平和垂直扩展,对特异性有一定提升,但本文算法其他指标均优于FR U-Net。说明本文算法性能提升明显、分割效果理想。
3.5.4 与近年先进算法对比
为了进一步说明本文算法在视网膜血管分割中的作用,将本文所提算法与近年来相关算法进行比较,如表4、表5 和表6 所示,其中标粗为最优指标,其数据均来自原文。
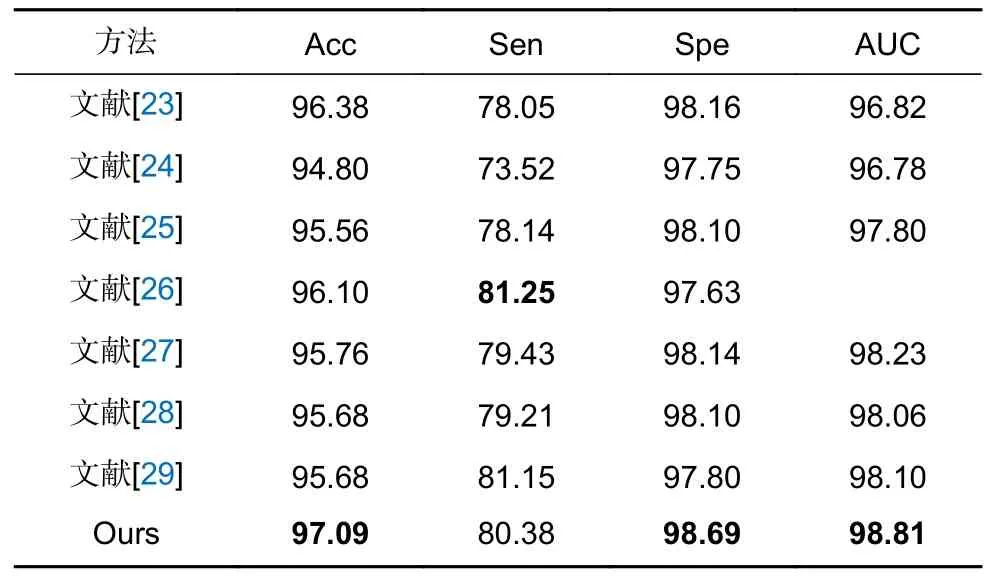
表4 DRIVE 数据集对比结果/%Table 4 Comparison results of DRIVE dataset/%
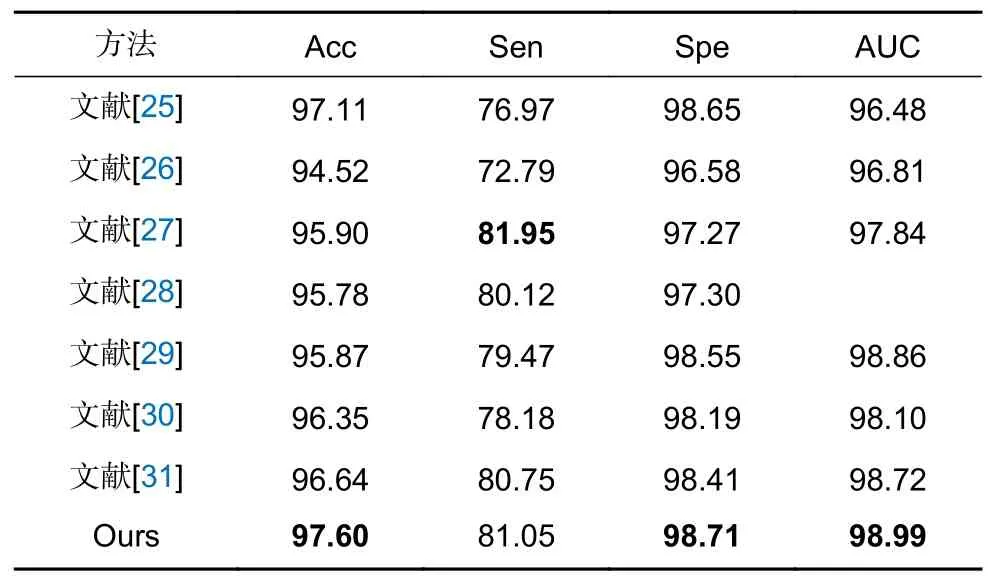
表5 CHASE_DB1 数据集对比结果/%Table 5 Comparison results of CHASE_DB1 dataset/%

表6 STARE 数据集对比结果/%Table 6 Comparison results of STARE dataset/%
由表4 可知,在DRIVE 数据集中文献[28]算法通过定向滤波器捕获微小血管,灵敏度高于本文算法0.22%,但本文算法其他指标均优于文献[28]算法,准确率及特异性均有明显提升,其余算法分割结果均低于本文算法。说明本文算法能准确分割视网膜血管,总体稳健性较强。由表5 可知在CHASE_DB1 数据集中文献[26]灵敏度高于本文算法0.9%,文献[27]通过非线性连接模式,使低级特征和高级语义特征集成更加高效,灵敏度有一定提升,但本文算法其他指标均优于文献[27]。文献[25]将Transformer 引入到跳跃连接中,对特征进行重新编码,但其指标均低于本文。说明本文算法性能优越鲁棒性强,在视网膜分割任务中可靠性高。由表6 可知在STARE 数据集中文献[29]以及文献[30]灵敏度高于本文算法,文献[29]开发多尺度多项特征学习模块来有效聚合上下文信息,提升分割微细血管的能力。文献[30]通过注意力模块捕获全局信息,并通过特征融合过程增强特征,灵敏度为最优值,但本文算法其他指标均为最优,且在DRIVE 和CHASE_DB1 数据集中指标均高于文献[29]和文献[30],表明本文算法泛化能力较强。
3.6 消融实验分析
为了更好地验证本文算法所提各个模块性能,在DRIVE、CHASE_DB1 和STARE 数据集上均进行消融实验,其中STARE 数据集采用五折交叉验证的方法进行消融实验,其结果如表7、表8 和表9 所示。其中S1 表示U-Net;S2 表示在S1 解码部分加入门控特征融合模块;S3 表示在S2 编码部分加入自适应增强注意模块;S4 表示在S3 编码底端加入级联群体Transformer 模块,即本文设计算法。

表7 DRIVE 数据集消融实验分析/%Table 7 Analysis of ablation experiments on the DRIVE dataset/%
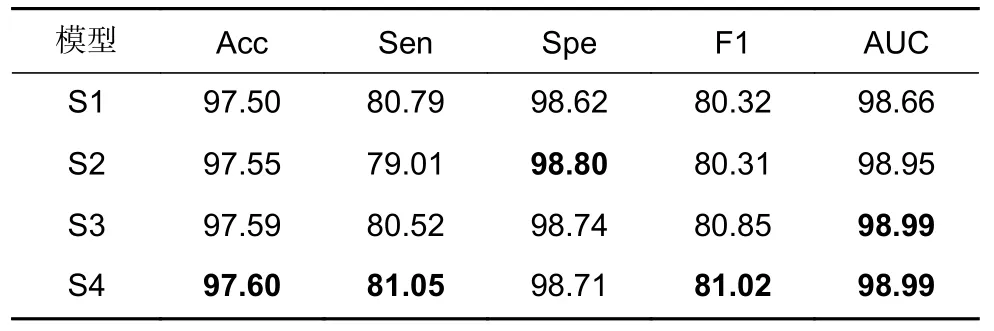
表8 CHASE_DB1 数据集消融实验分析/%Table 8 Analysis of ablation experiments on the CHASE-DB1 dataset/%

表9 SATRE 数据集消融实验分析/%Table 9 Analysis of ablation experiments on the STARE dataset/%
在DRIVE 数据集消融实验中S2 各项指标相较于U-Net 网络均有提升,在S3 中Spe 与AUC 达到最优,ACC 指标也较好,但Sen 较低,在S4 中整体指标达到最优,ACC 和Sen 均达到最优;在CHASE_DB1 数据集消融实验中S2 除Sen 和F1 指数外其他指标均有不同程度提升,S3 中除Spe 外其他指标均有提升,但Sen 指标仍低于U-Net 算法,S4 中整体达到最优;在STARE 数据集消融实验中,S4 除Spe外指标均达到最优,但ACC 及AUC 提升较小。
综上所述,GFF 能处理好视网膜分割任务中多尺度问题,提升正确分割微小血管的能力,但会对Sen有一定影响;加入AEA 模块后除DRIVE 数据集中Sen 指标降低外其他指标均有提升,说明AEA 模块能够消除背景噪声并降低病理伪影干扰;最后加入CGT 模块,Sen 指标相较于未加入CGT 模块均有较大提升,表明CGT 模块能够增加捕获微小血管局部特征的能力。消融实验表明AFCT-Net 有效且合理。
4 结束语
眼底视网膜血管分割是医学领域一项重要研究,是人工分析向自动诊断跨越的重要过程,本文针对视网膜血管分割中存在末端微小血管缺失、病理伪影干扰及血管前景与非血管背景对比度低等问题,提出自适应特征融合级联Transformer 视网膜血管分割算法。首先AEA 模块可以将不同通道特征信息充分利用,提高分割结果准确率且降低计算冗余;其次GFF 模块将编解码语义信息融合,提升特征复用率,增强血管光滑度;最后CGT 模块在编解码底层充分聚合上下文血管语义信息,使主血管与微小血管能够平滑连接。本文在分割对比度较低病理图像时仍出现血管轻微断裂问题,未来如何精确分割病灶处血管仍是视网膜血管分割需要进一步解决的问题。
猜你喜欢
现代仪器与医疗(2022年2期)2022-08-11
速读·下旬(2021年11期)2021-10-12
中医眼耳鼻喉杂志(2021年1期)2021-07-22
中医眼耳鼻喉杂志(2021年2期)2021-07-21
大东方(2019年12期)2019-10-20
科学与财富(2017年22期)2017-09-10
商情(2017年1期)2017-03-22
电子制作(2016年15期)2017-01-15
湖南中医药大学学报(2016年1期)2016-12-01
系统工程与电子技术(2016年2期)2016-04-16
