
引入双编码器模型的OCT视网膜图像分割
2024-01-13 12:30陈明惠柯舒婷
光电工程 2023年10期
陈明惠,王 腾,袁 媛,柯舒婷
上海理工大学 健康科学与工程学院 上海介入医疗器械 工程技术研究中心教育部医学光学工程中心,上海 200082
1 引言
视网膜病变是一种常见地眼科疾病,大多数眼底疾病是由视网膜病变引起的[1]。研究表明,在大多数眼底疾病中,视网膜形态结构的变化早于患者在视觉上感知到的变化,检测视网膜各层的微小形态变化来分析视网膜形态结构对早期发现眼底视网膜疾病具有关键价值。近年来,视网膜相关的各种医学图像被广泛应用于视网膜疾病的诊断、筛查和治疗中[2-4]。光学相干层析成像(Optical coherence tomography,OCT)可以直接显示视网膜的分层结构状态并获取其相应的厚度,目前已成为一项重要的眼科诊断技术,并被常规用于监测视网膜状态变化[5]。视网膜层厚度和液体分布可用于诊断眼科疾病,自动分割视网膜OCT 图像中的视网膜层可以帮助有效地诊断和监控视网膜疾病,如糖尿病黄斑水肿、青光眼、多发性硬化症等。因此,准确分割视网膜图像中的视网膜层边界是进行病理分析和诊断的关键步骤。然而,视网膜各层的图像有时是复杂的,难以分割。例如,糖尿病可能导致黄斑水肿(macular edema,ME),在检查ME 的视网膜OCT 图像中可以看到部分液体区域,该区域具有低反射强度,是视网膜组织中的低对比度区域[6]。液体区域使视网膜组织变形,这可能导致分割算法失败。因此,快速准确地分割视网膜各层及液体区域是具有挑战性的。
传统的视网膜层分割方法通常基于数学模型,通过分析解剖结构和先前的临床知识来检测视网膜层。Monemian 等[7]提出利用像素的纹理属性来提取层间边界像素的区分特征。Liu 等[8-10]基于水平集的方法对视网膜各层进行自动分割,该方法可以在训练随机森林的过程中获得边界概率图,随着训练次数的不断增加可以将分割结果准确到亚像素精度。Hussain等[11]通过将问题建模为图并运用Dijkstras 最短路径算法,找到三个参考层的近似位置,然后将搜索空间限定为实际层。由于拓扑在边界确定中起到很好的作用,因此可以克服扭曲的影响。这些方法在视网膜层分割中是有效的,但鉴于不同患者OCT 图像内的特征有所差异,传统算法在不同数据集上的效果也都有明显差异,这导致基于传统算法的分割任务鲁棒性不太理想,并且一些算法的相关参数还需要有经验的实验人员去实时调整。
近些年,深度学习的发展尤为迅速,特别是在OCT 视网膜分层中达到了比传统方法更准确的效果。卷积神经网络 (Convolutional neural network,CNN)可自动提取和学习图像特征,已被广泛应用于各种模式的图像处理中,后续出现了许多关于CNN 的变体结构[12-16]。U-Net[17]是最早且最著名的基于自动编码器和解码器的医学图像分割架构之一。杜克大学OCT 实验室在2017 年基于U-Net 的编码器、解码器结构提出了一种新的全卷积深度模型,称为ReLayNet[18],成功地对OCT 图像中各类视网膜层以及液体区域进行了分割。ReLayNet 通过编码器级联进行下采样使模型对特征图进行信息提取分类,从而进行有效的对上下文特征的学习,通过解码器的上采样路径进行信息的整合恢复以生成完整的分割图。后续也有相关工作采取解码器单级联多输出进行分割工作[19]。MDAN-UNET[20]使用多尺度特征和注意力机制来提高现有方法的分割性能,可以基于空间和通道两方面很好地提取全局信息,实验对OCT 视网膜液体区域和视网膜层进行了分割并取得了理想的效果。Ngo 等[21]提出了一种基于特征学习回归网络的自动分割方法,该方法将图像片段的亮度、梯度和自适应归一化强度分数作为学习特征,然后预测相应的视网膜边界像素。然而,这些基于卷积神经网络的方法感受野范围较小,对全局信息关注较少。Chi 等[22]实验表明,空间信息只关注局部信息,而往往忽略了图像中所有像素的全局信息,从而提出了一种新的卷积-快速傅里叶卷积(fast Fourier convolution,FFC),它不仅可以观察到非局部的特征区域,还可以在卷积内部进行跨尺度信息的处理融合。为了减少卷积网络的计算成本,人们探索了U-Net[17]和快速傅立叶变换[23]的组合,其目的是进一步利用图像中不能被常规卷积层很好地提取的全局特征。
综合上述相关工作,在类别更多、更复杂的分割任务下,单一的设计增加各种机制模块无疑提升了模型的复杂度和硬件需求,同时一个大的有效感受野对于理解图像的整体结构和解决修复问题虽然是必不可少的,但在大掩模的情况下,大但有限的接受场也可能不足以访问能产生高质量修复所需的信息。因为OCT 图像中存在频域特征,而这些特征在现有的空间卷积神经网络中可能会被遗漏。本文利用快速傅里叶卷积从光谱频域中提取和处理全局信息,提出一种基于U-Net 的双编码器分割模型,用于分割OCT 视网膜图像,分割任务包括内界膜 (inner limiting membrane,ILM)、神经纤维层-内丛状层(nerve fiber ending to Inner plexiform layer,NFL-IPL)、内核层(inner nuclear layer,INL)、外丛状层(outer plexiform layer,OPL)、外核层-光感受器内节段髓系(outer nuclear layer to Inner segment myeloid,ONL-ISM)、内感光和外感光层联结(inner segment ellipsoid,ISE)、外节段-视网膜色素上皮细胞层(outer segment to retinal pigment epithelium,OS-RPE)以及视网膜图像存在的一些液体区域。利用频域编码器来提取频域特征,提出FFC-DC 模块处理全局和局部信息,通过逆转换将频域特征转换为空间特征来补全空间编码器可能会忽略的信息。实验发现,基于快速傅里叶卷积的神经网络的性能优于类似的卷积模型,并且表现出比其他分割模型更好的结果。
2 实验方法及原理
2.1 空间编码器、解码器
如图1 所示,本文模型中的空间编码器和解码器与原始的U-Net 相同,空间编码器包含四个卷积块。每个卷积块包含一个3×3 卷积、BN 层、ReLU 层以及最大池化MP 层,编码器通过最大池化层进行下采样四次,对应的解码器上采样也进行四次,其中左右两侧同级别的特征图中间会进行级联操作。空间解码器网络总共具有四个上卷积块,这四个上卷积块接收频域和空间特征,并在这四个上卷积块传递到瓶颈层之前将它们连接起来。然后,使用相同于空间编码器的卷积块来放大来自先前解码器块和跳过连接的特征,经过转置卷积层后解码器块生成最终分割图。

图1 模型结构图Fig.1 Diagram of the model structure
2.2 频域编码器
如图2 所示,与空间编码器相同,在频域编码器中,实验选择应用 FFC 和扩张卷积(Dilated Convolution,DC)模块组成四个FFC-DC 块,频域编码器接收与空间编码器相同的输入并从数据中提取频域特征。FFC-DC 块主要使用DC 模块处理局部特征,使用频域Transformer 来处理全局特征。输入图像x作为局部信息,xl被输入到第一个FFC-DC 块。因为输入图像中没有全局特征,图像像素被认为是局部信息,所以输入进来的第一个xg的值被设置为0。
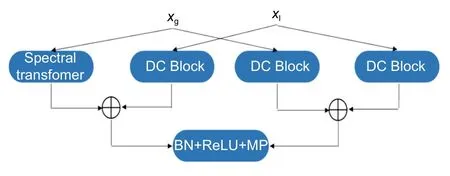
图2 FFC-DC 模块Fig.2 Architecture of the FFC-DC block
在FFC-DC 模块中特征图被四个分支所处理,分别为局部到局部、局部到全局、全局到局部、全局到全局,每条路径都可以捕捉到不同感受野的互补信息。这些路径之间的信息交换在内部执行。快速傅里叶卷积FFC 块接收输入的全局和局部信息xg、xl,然后将xg和xl输入到三个DC 模块和频谱Transformer 中,提取全局和局部空间特征以及频域范数,从而进行频域特征提取。最后,将批归一化、非线性激活函数和最大池化合并应用于特征,以生成下一个FFC 块的全局和局部特征x'g、x'l。
2.2.1 DC 模块
以往的工作通常采取常规卷积来处理局部特征,与传统卷积相比,扩张卷积具有特殊的优点[24]。它可以随着扩张参数的改变而随意生成不同的感受野,并获得更丰富的上下文信息且不增加模型复杂度。扩张卷积产生的特征图可以与输入的特征图具有相同的尺度,同时每个输出卷积会具有更大的感受野,因此它可以获取更高级别的语义信息。DC 块的结构如图3所示,在DC 块中,特征分别被输入1×1 和3×3 两个常规卷积,所提取的特征信息会输入到3×3 扩张卷积中。通过这种方式,DC 块可以获得不同大小的感受野。最后,将所有特征送入1×1 卷积,以降低信道的维度。该方法可以使提出的模型更有效地进行局部的特征提取。
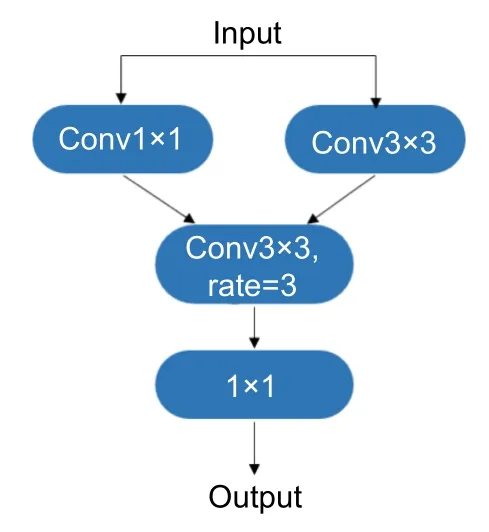
图3 DC 卷积模块Fig.3 Architecture of the DC block
2.2.2 频域Transformer
如图4,频域Transformer 首先将核大小为1 的卷积块应用于产生x''的xg。然后基于预定值α将x''的通道分成两部分,其中α百分比的频道被设定为全局信息,而1-α百分比的通道被设定为局部信息。分割的全局特征和局部特征分别输送到傅里叶单元GFU (global Fourier unit)、LFU (local Fourier unit)以提取频域特征x"g,x"l。

图4 频域TransformerFig.4 Architecture of the spectral Transformer
如图5 所示,其中GFU 和LFU 结构相同,LFU主要目的是捕捉半全局信息,将输入图分为四份处理,然后进行傅里叶变换,这样可以处理四分之一空间内的关联特征。傅里叶单元接收x"的一部分作为输入,然后对这些特征应用傅里叶变换以获得实部和虚部a+bi∈C。将实部和虚部a、b叠加,然后输入到核大小为1 的卷积层,将激活层和批归一化层应用于卷积层的输出。输出分成两部分,即实部和虚部a'、b',随后其会经过傅里叶逆变换将提取的频域特征转换回空间特征。最后,x与全局和局部傅里叶单元x"g、x"l的输出相加。

图5 傅里叶单元Fig.5 Architecture of the Fourier unit
2.3 损失函数
本文提出的框架是一种端到端的深度学习方法。交叉熵损失函数被经常应用到深度学习图像分割中。然而,医学方面的图像分割目标通常占据图像很小一部分的区域,交叉熵损失函数对于这类任务并不是最好最理想的。经过实验验证,选择结合了Dice 系数损失和加权交叉熵损失的新损失函数来代替交叉熵损失函数,损失函数公式如:
使用λdice、λce作为每个损失期的加权系数时,总损失额将变为:
其中:N是像素数,p(k,i)∈[0,1]和g(k,i)∈{0,1}分别表示第k个类别的预测概率和真实标签;k是类别数,是类权重,在本文中,根据以往实验经验地设定了 ωk=1/k,表示为类别数的倒数。
3 实验与结果
3.1 数据集和实验设置
实验选择在杜克大学[25]和温州医科大学的混合临床视网膜OCT 数据集上训练和评估上节提出的方法。数据来自谱域OCT 系统,系统的参数为中心波长1300 nm,带宽135 nm,纵向分辨率为5.5 μm,横向分辨率为13 μm,信噪比109 dB。该OCT 数据集包括来自11 个OCT 扫描子集,这些扫描对应的所需标签由两名专家注释。过程中选取前7 个子集的扫描用于训练,后选取两个子集用于验证,最后两个子集的扫描作为测试集,并将其与之前的相关工作进行了比较。实验基于公共PyTorch 平台。在训练过程中,经验地将原始图像裁剪到224×224 输入进网络以加快训练阶段,因为收敛速度快的优点,则选取ADAM作为优化器,批大小为10,学习率设置为0.0005,权值衰减为0.0001,训练的最大周期为100,其中训练周期数是根据所有模型的最佳验证精度选择的。经过实验验证将λdice和λce的值都设置为1。
3.2 比较方法与评价指标
实验将提出的模型与U-Net 和专门用于视网膜分层的RelayNet 进行了比较评估,所有实验都在同一数据集上进行训练和验证。为了评估网络分割性能,本实验采用了 Dice 系数[26]和平均交并比(mean intersection over union,mIoU)[27]来评估模型对OCT 图像分割的性能,二者都是衡量分割结果和原始标签相似度的度量指标。Dice 相似系数表示预测和真实标准两个样本之间的相似度,取值范围在[0,1],Dice 系数越接近1,表示模型性能越好。平均交并比(mIoU)表示多类分割中每个类别分割正确区域与真实标签、预测值两个集合之比。Dice、mIoU 的计算公式如:
其中:TP(true positive)表示分割结果中正确分割的目标区域的像素个数;FP(false positive)表示实际为背景像素但在分割结果中被错误分割为目标区域的像素个数;FN(false negative)表示目标区域被错误分割为非目标区域的像素个数;k表示类别的总数。
3.3 实验结果
表1 显示了三种模型分割结果,表示不同视网膜层和液体经过实验所获得的分割指标,整体上本文模型在Dice 和mIoU 上都要优于U-Net、ReLayNet,就视网膜层而言,除内界膜的提升较为明显外,其他指标上的差别并不突出,这是因为每一层的视网膜面积狭小,在没有因病变或外力因素所导致特别大的形变下分割出的效果并没有太大差别。而在液体分布范围广且分散的情况下,本文模型液体分割性能指标Dice 系数相较于U-Net,ReLayNet 模型分别提高了10%和34%。在同等硬件条件下,双编码模型用时比U-Net 慢了2 s,但和ReLayNet 相比基本差不多。

表1 不同方法在数据集上的分割结果Table 1 Results of each method on dataset
图6 是黄斑水肿(macular edema,ME) OCT 图像,主要比较了本文模型和U-Net 的分割生成图,从视觉上验证了表中数据的真实性,在本身视网膜结构复杂狭窄的情况下,双编码器模型分割出的结果都近乎相似,在区域范围较大、较分散的液体区域,双编码器又能很好地利用图像的光谱频域信息进行转换,成功捕捉到遗漏的空间信息,识别并预测出其所包含的区域。本文选取了小部分聚集的液体区域的情况(对应于图6(a))、原始标签液体区域呈现为一连串长条形的情况(对应于图6(b))、液体区域呈分散且不规则状的情况(对应于图6(c))作分析,在图6(a) OCT 样张中,对于小部分聚集的液体区域,U-Net 只能识别到上方一角,而本文模型识别出来的区域要远大于U-Net。图6(b)样张中原始标签液体区域呈现为一连串的长条形,U-Net 分割结果呈不相连的块状区域,没有将目标区域信息很好地连接,而本文模型的分割结果没有出现断连,将液体整体区域都分割出来,使其更接近原始标签。图6(c)样张中的液体区域呈分散、不规则状,这对于分割任务难度更大,本文模型较U-Net 分割出更多的液体区域,证明双编码器对于细节局部特征的处理更加优秀,也验证了该方法对于单编码器信息遗漏补全的可行性。结合数据和生成图,本文模型的实验结果最接近于专家注释的真实标签,而U-Net、ReLayNet 整体效果都不如双编码器的分割效果好,尤其对于液体分割的结果不太理想,在某些区域无法正确地分割液体。

图6 本文模型与U-Net 的分割结果比较。(a)小部分聚集液体区域的分割对比;(b)长形相连接液体区域的分割对比;(c)分散无规则分布液体区域的分割对比Fig.6 Some qualitative results of ours compared to U-Net.(a) Segmentation and comparison of small areas of liquid accumulation;(b) Segmentation and comparison of long forms and connected liquid regions;(c) Segmentation and comparison of randomly distributed liquid regions
3.4 消融实验及不同α 的对比
如表2 消融实验所示,分析了频域Transformer中预定值α和FFC-DC 模块对实验结果的影响,其中表中第一行表示在频域解码器中只存在常规卷积块时的实验分割结果。数据表明,随着FFC-DC 模块的加入,实验结果的Dice 系数获得了明显提高,特别是对于视网膜中液体分割的准确度,这表明频域编码器的设计的确对于空间解码器所遗漏的部分空间信息有着良好的补全效果,对于分散形状不一的液体区域具有很好的识别。因此有无FFC-DC 模块,在液体分割上效果明显。

表2 关于FFC-DC 和α 的消融实验Table 2 Ablation study on the FFC-DC blocks and α
表2 探索了实验在不同α值下的分割性能,结果显示,当α值为0.25 时,液体分割性能最佳,Dice系数达到了90%;当α值为0.5 时,整体性能最佳,模型在液体分割上的Dice 系数达到了89%,而在视网膜层分割上与其他实验组不相上下。实验表明,局部和全局特征都可通过本文模型学习到有价值的信息。通过设置α的值,所提出的模型能够将全局和局部特征关联起来,以实现最佳性能。
4 结论与讨论
本文提出了一种基于U-Net 的端到端双编码器分割模型,用于分割OCT 图像中的视网膜层和液体区域。区别于U-Net 的单一编码器,主要利用傅里叶卷积的提取和转换特点,提出频域编码器作为第二个编码器分支,进而从OCT 图像中提取光谱频域特征,包括具有依赖于组织和视网膜层的高频非均匀斑点,频域中的特征提取使本文的网络能够对每一层中的斑点分布进行建模和学习。频域编码器作为本文模型的第二编码器提取OCT 光谱特征,比单编码器的UNet、ReLayNet 多了频域特征,所以在视网膜层的内界膜层得到较好的分割效果,因为内膜层面积稍微大一点,病变影响显著。而液体区域体现了其高光谱频域特征,特别是液体区域呈分散、不规则状的图像中更加明显,这在图6(c)也得到了很好的验证。
实验将提出的模型与经典模型进行了比较,结果表明,本文模型都取得了最优分割效果,整体的Dice 系数和mIoU 相较于U-Net 均提高2%,相较于ReLayNet 分别提高8%和4%,尤其在液体分割上其分割Dice 系数比U-Net 高出10%,比ReLayNet 高出34%,Dice 系数达到了89%,证明了频域编码器的可行性以及双编码器对于视网膜图像分割的优越性。
猜你喜欢
舰船科学技术(2022年22期)2022-12-13
数学物理学报(2022年4期)2022-08-22
数学物理学报(2022年2期)2022-04-26
金桥(2018年4期)2018-09-26
成都信息工程大学学报(2018年3期)2018-08-29
雷达学报(2018年3期)2018-07-18
电子设计工程(2017年20期)2017-02-10
火控雷达技术(2016年1期)2016-02-06
电子器件(2015年5期)2015-12-29
电测与仪表(2015年3期)2015-04-09
