
风电功率预测模型的优选准则和融合策略
2024-01-12 04:39易善军张洋张文军何晶
微型电脑应用 2023年12期
易善军, 张洋, 张文军, 何晶
(1.国网内蒙古东部电力有限公司, 内蒙古, 呼和浩特 010020; 2.国网南京南瑞集团公司(国网电力科学研究院), 江苏, 南京 211106;3.国电南瑞科技股份有限公司, 江苏, 南京 211106)
0 引言
随着我国工业化进程不断加速,消耗更多的自然能源,造成污染并出现了能源危机。目前世界各国开始发展新能源,寻找绿色清洁的能源,减少碳排放量[1]。风能因分布广泛并且无污染受到各国重视,大力发展风力发电,风电在电力系统中占据越来越重要的作用。由于风力作为自然能源,风能随机分布且强度不一致,风电输出功率不稳定,给供电网络的稳定运行带来影响[2]。
针对上述存在的问题,文献[3]综合风电场的地形条件和机组特性,利用物理方法进行建模,通过数值气象预报(NWP)采集到的风速风向数据预测风机的输出功率。这种方法计算方式简单,需要依靠精确的NWP数据,否则预测精度将会有所降低。文献[4]建立了神经网络模型,以风电机组的历史运行数据作为输入,通过算法建立输入与输出的非线性关系,对模型进行训练后输出风电功率,且不需要考虑数据时间上的相关性。但确定神经网络模型的结构较为困难,模型训练速度较慢。
本研究分析影响风电功率预测的主要因素,建立预测模型并分析模型数据特性,根据风电场实际情况和影响因素变化规律,基于相似度模糊推理得到优选预测模型,并加入IOWA算子融合预测模型,保证了预测模型的准确性和实时性。
1 风电功率融合预测模型及数据特性分析
由于风电机组输出功率的非线性变化,使用单个模型在复杂的条件下保持较高的预测精度具有一定困难。为了应对不同情况下的预测功率需求,应用多个模型对多种预测模型进行优选,建立融合的预测模型[3]。按照不同的类型可对预测方法进行分类,本研究的创新点如下。
(1)基于相似度的模糊推理确定模糊规则的前件、后件和模糊规则。根据激活的模糊规则从模型库中得到优选模型,并加入IOWA算子。将单一模型的预测精度作为诱导值得到融合预测模型,在各时刻上与预测精度紧密相关。
(2)提出风电场集群的无功电压协调控制方法,根据风电功率融合预测模型的预测信息,对风电场集群无功电压控制,维持风电接入区域静态电压稳定。并在并网节点加入静止同步补偿器,防止有功扰动造成电压突变。
风电功率预测方法分类如图1所示。
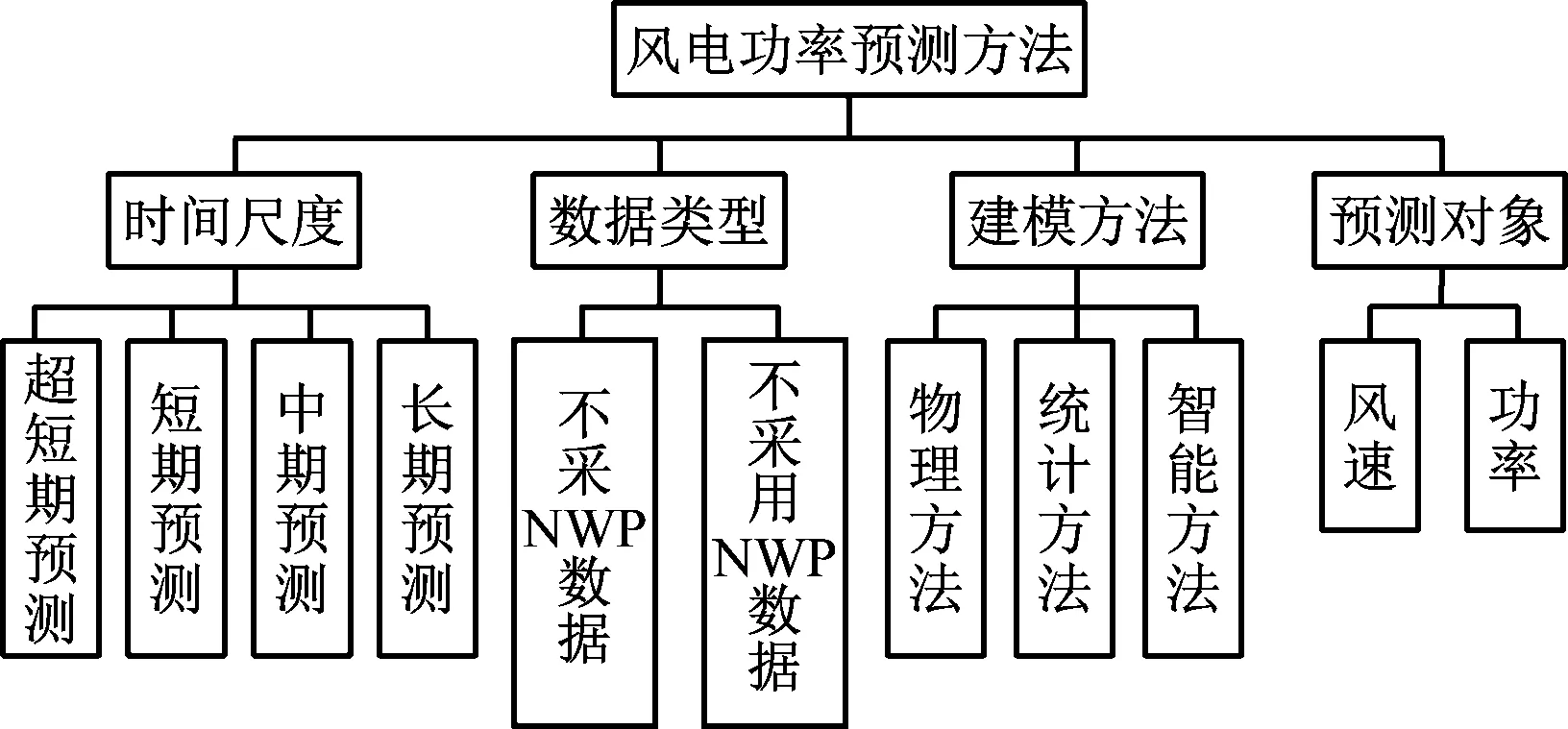
图1 风电功率预测方法分类
其中,统计方法根据采集到风电场数据建立映射关系,使用的数据包括NWP数据、风速风向数据、风电机组历史运行参数和实际测量功率,能够适用风电场实际位置,这种方法进行预测误差相对较小[4]。
同时,功率预测精度也与数据特性有关。风电机组利用风能推动风机叶片转动,带动发电机运行转换为电能输入到电力网络中[5]。输出功率的大小与风速、风电机组的转子直径等因素有关,风电机组的风轮从风能中吸收的功率可表示为
(1)
其中,P表示风电机组的输出功率,Cp表示风机的功率系数,A表示风轮扫掠面积,ρ表示空气密度,v表示风速[6]。风力发电机组的风速-功率特性曲线如图2所示。
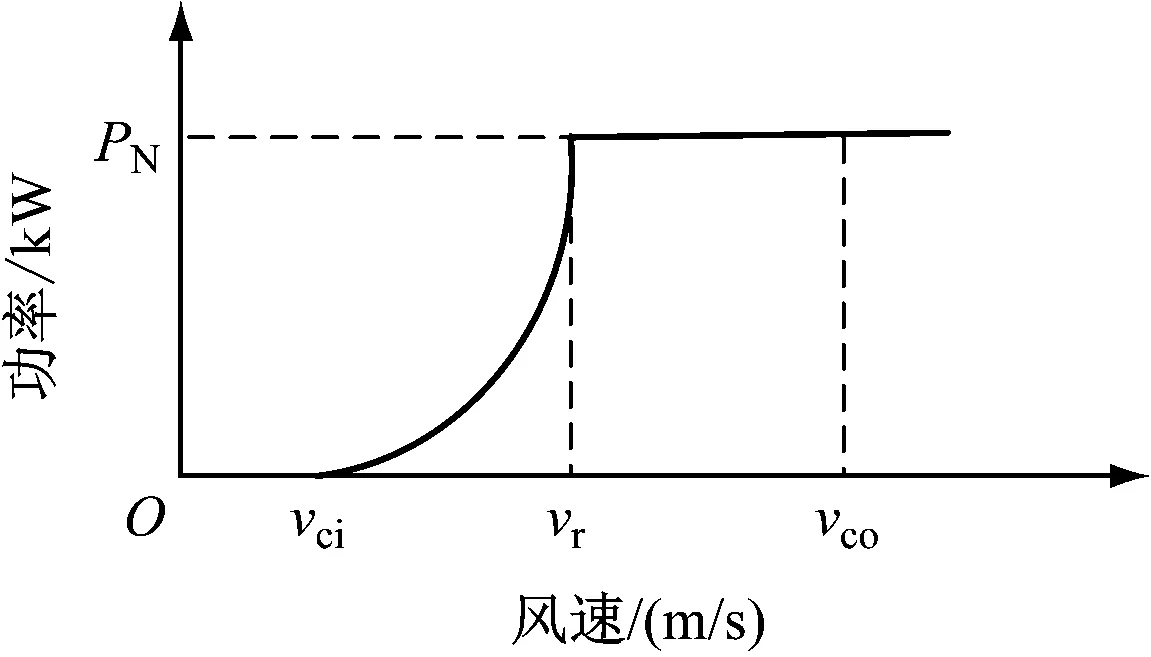
图2 风电发电机组的风速-功率特性曲线
风速-风电功率输出的函数关系可表示为
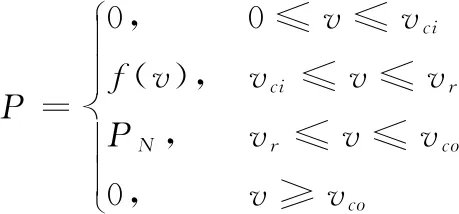
(2)
其中,vci表示风机的切入风速,风速到达vci时风机才能产生有功功率,一般情况下vci的值为0.5~5 m/s。vr表示风机的额定风速,vco表示切出风速[7]。
由图2可知,输出功率变化可分为三个过程:当风速小于vci时,输出功率为0;当风速刚超出vci时,输出功率随风速变化不大,增长速度较慢;当风速大于vci小于vco时,输出功率增长速度较快,出现较小的风速波动时,输出功率的变化幅度较大。超过额定风速后,输出功率保持不变[8]。
2 基于相似度模糊推理和IOWA算子的预测模型
本研究根据相似度模糊推理建立风电功率模型的优选规则,可分为三个步骤。
(1)确定模糊规则前件
通过分析NWP数据,不同区域、不同地理位置的风电场的风速、温度不同,所输出的功率也不一致。且不同时间下,同一个风电场的风速、风向和温度也不同,每个月呈现出新的变化规律。根据前件权重的大小判断对后件的重要程度,规则前件的权重可表示为
(3)
其中,i表示月份,j表示影响输出功率的因素,g表示因素个数,Rij表示相关性。
(2)确定模糊规则后件
本研究提出优选准则为根据所在区域风电场的预测要求和实际情况设定阈值,选取预测准确率超过设定阈值的模型。使用多个评价指标评价模型的预测效果,最后得出综合评价值,选出预测误差最小的模型[9-10]。风电场风电预测准确率可表示为
(4)
其中,PMK表示风电机组在K时刻实际输出功率,PPK表示预测模型预测输出功率,N表示总时段数,Cap表示开机容量。预测模型的预测合格率可表示为
(5)
其中,Bk表示每天的预测合格率为
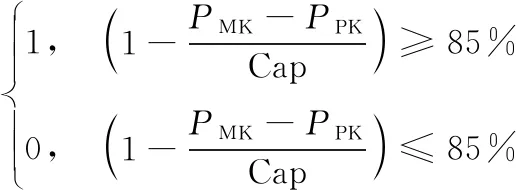
预测模型的准确率r1和合格率r2的值在0~1之间,r1越大表示准确率越高,预测效果也好,相对应合格率也就越高。当r2的值超过设定值时可以满足预测需求。
(3)确定模糊规则
确定出前件和后件后,还需确定规则启动的阈值。为防止阈值过大导致规则不容易启用,过小造成启动的规则数量过多,本研究设定每条模糊规则的阈值为0.5。确定规则前件历史数据的权重,并从模型库中选择最优模型。
根据样本数据,计算风电场最新月份数据和样本数据的相似度,从而得到新数据和规则的综合相似度。如果综合相似度超过设定阈值,表示该条规则被启用。如果多条规则同时启用,规则的并集为优选预测模型;如果启用规则的数量为一个时,表示这条规则对应即为优选预测模型。
本研究采用IOWA算子融合单一模型,风电机组在t时刻输出功率序列为{yt},使用第i种预测模型得到的预测值为{yit},m1个单一模型在融合模型中的权重为(w1,w2,…,wm1)T,第i种模型在t时刻时的预测精度为

(6)
将ait作为预测值yit的诱导值,构成了二维数组[(a1t,y1t),(a2t,y2t),…,(ait,yit)],将预测精度按照大小进行排序,IOWA算子融合预测值可表示为
(7)
其中,a-i(it)表示融合预测模型在t时刻的预测精度,IOWA算子融合预测模型在各个时间点上预测精度与预测模型联系紧密。以预测误差平方和为准则,预测最优化模型和表示为
(8)
基于IOWA算子的风电功率融合模型预测流程如图3所示。

图3 基于IOWA算子的风电功率融合模型预测流程图
优选模型对历史数据进行训练并得出预测功率,对输出功率进行预测,可用每种单一模型最近时刻的平均预测精度代替后一时刻作为诱导值,按照诱导值的大小对预测值进行排序,然后再计算融合预测模型的预测功率。
3 风电场无功电压协调控制方法
各风电场风速变化不一致,使用的控制方法也不一样,风电场集群无功电压协调控制方法的整体框架如图4所示。
风电功率出现随机波动是造成无功电压问题的重要原因,应用风电功率预测模型到无功电压协调控制中,引入功率波动因子λ,用来表示接入区域的静态电压稳定度。功率向上或向下波动都会导致电压失稳,接入区域的静态电压约束可表示为
(9)
其中,PU、PD表示向上、向下波动状态的有功出力临界值,PN表示正常状态下的风电有功出力,PCAP表示接入容量,λu、λd表示向下和向下的波动因子。为防止有功扰动造成输变电网络电压突然增加或减小,控制方法根据各t+1时刻的预测功率信息,将t~t+1时间内可能出现的功率波动作为t时刻的约束条件,保证风电集群的静态电压稳定度处于正常范围。DSTATACOM的配电网结构如图5所示。
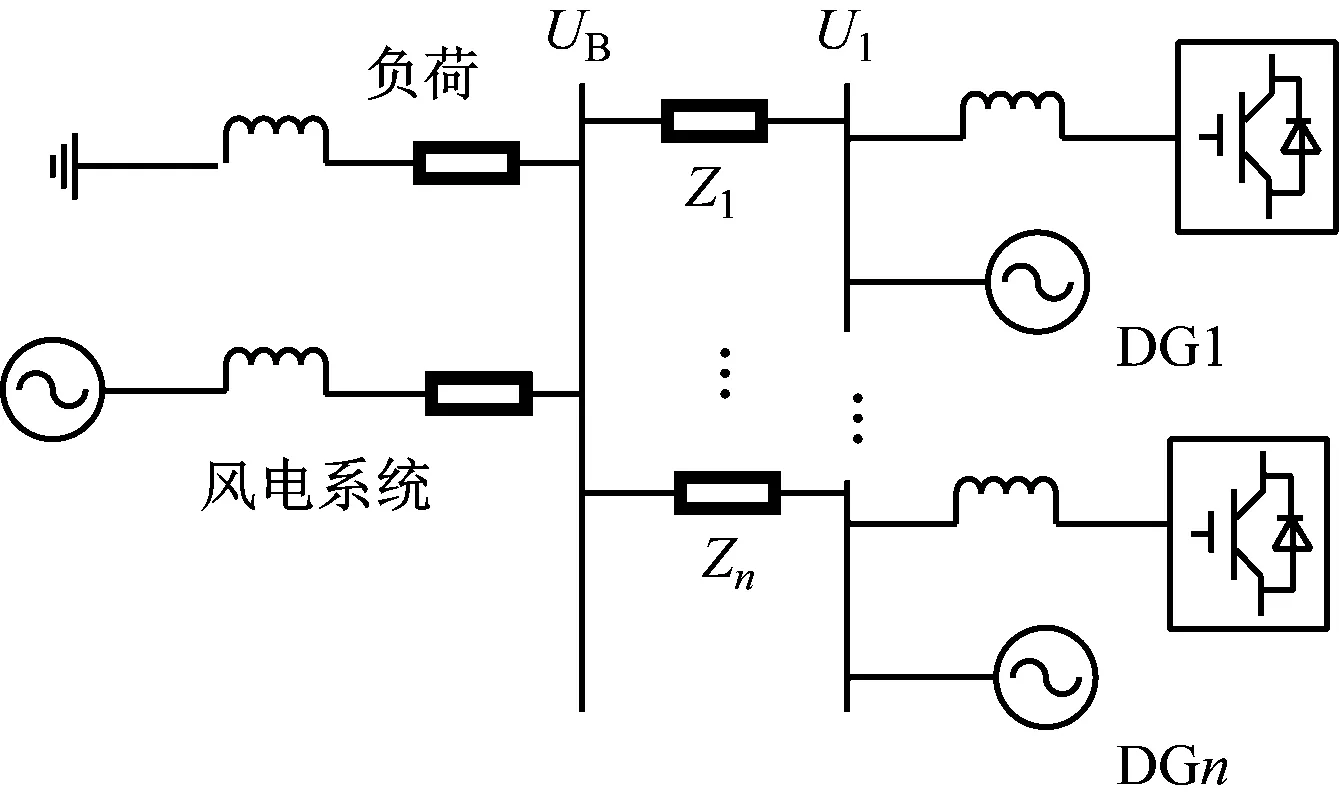
图5 DSTATACOM配电网结构
DSTATACOM输出端的电压随输出电流成一定比例变化,无功功率根据系统电压采用斜率控制。静止同步补偿器斜率的存在能够通过很小的电压调节额定无功功率的大幅度减小,防止出现电压波动的情况。
4 应用测试
为了验证本研究风电功率预测模型的性能,分别使用文献[3]预测模型、文献[4]预测模型和本研究融合预测模型进行实验,比较3种预测模型的预测精度和预测误差。训练样本为风电场历史数据中的风速、风向、温度和风电功率数据,训练样本为650组,检验样本为70组,训练样本中历史风速数据如图6所示。

图6 历史风速训练样本
设定预测模型预测时间为1 h,使用3种预测模型得到的预测功率如图7所示。
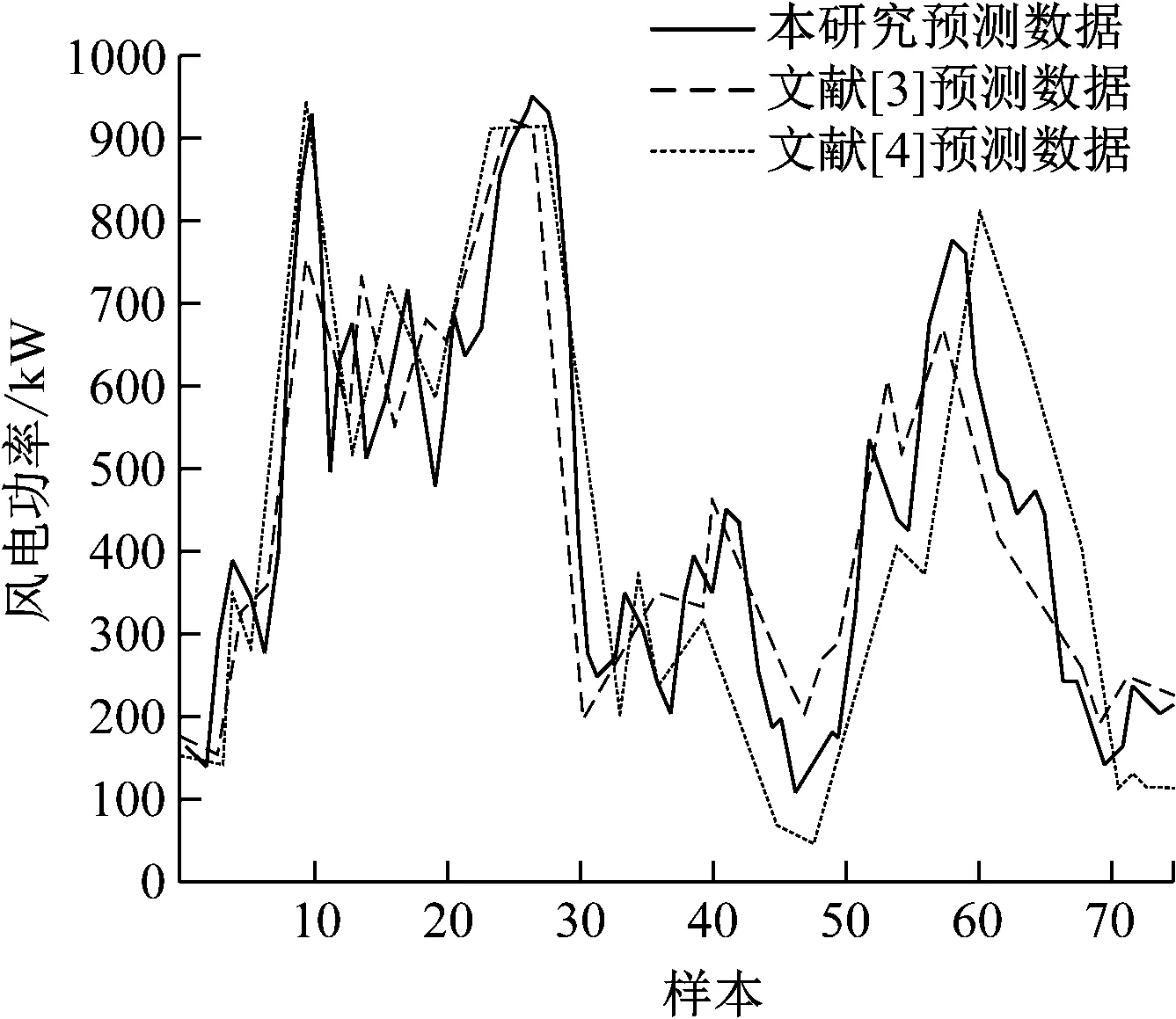
图7 预测功率结果
根据图7中预测功率的大小与实际功率进行比较得到预测模型的误差评价指标如表1所示。

表1 预测模型的误差评价指标
本研究预测模型的准确率r1的值为99.17%,合格率r2的值为97.58%。经过模型优选和融合后得到的预测效果比其他未经过优选的预测模型预测效果好,说明本研究模型优选和融合提高了预测精度。其中,平均百分比误差指标反映了模型的总体平均性能,MAPE为3.22%。标准误差表示预测模型的离散程度,本研究标准误差为5.426%,越小说明预测误差与平均值之间的差异越小。
文献[3]预测模型的准确率r1为95.24%,平均百分比误差达到6.58%,相当于本研究MAPE值的两倍,反映出文献[3]预测模型的整体平均性能比本研究预测模型较差,平均误差指标(MAE)为15.12,表示预测误差的平均幅值较大。文献[4]预测模型的均方根误差指标(RMSE)为24.365%,远高于本研究,说明预测功率和实际功率之间偏差的分散程度较大,得到预测样本风电功率的值偏大或偏小,预测精度不高。标准误差高达12.341%,比本研究预测模型高出6.915,说明文献[4]预测误差离散程度较大。
5 总结
本研究分析影响风电功率预测的主要因素,采用相似度模糊推理的方法建立模糊规则,选择优选预测模型。以风速、风向、温度为输入变量序列,输出风电功率的值。加入IOWA算子,融合预测模型提高预测精度。并提出风电场集群无功电压协调控制方法,根据得到的预测功率,控制风电集群的电压水平和稳定性。本研究提出优选方法缺乏长期、大量的历史数据训练,还需增加数据样本建立更加全面的模糊规则,扩展本研究方法的适用性。
猜你喜欢
成都信息工程大学学报(2022年2期)2022-06-14
中学生数理化·中考版(2020年12期)2021-01-18
中学生数理化·中考版(2020年12期)2021-01-18
中学生数理化·中考版(2018年12期)2019-01-31
电子制作(2018年17期)2018-09-28
通信电源技术(2016年4期)2016-04-04
电测与仪表(2015年21期)2015-04-09
电测与仪表(2015年11期)2015-04-09
风能(2015年9期)2015-02-27
风能(2015年7期)2015-02-27
