
基于机器学习算法的餐饮企业客户流失预测
2024-01-11 05:56孙克争高小虎
黑龙江科学 2023年23期
王 妍,孙克争,高小虎
(江苏商贸职业学院,江苏 南通 226011)
0 引言
客户流失是餐饮企业普遍面临的问题。客户流失会导致餐饮企业营业额下降,严重的客户流失会导致餐饮企业因入不敷出而倒闭。在餐饮行业中,维系一个老客户的成本远低于挖掘一个新用户的成本,且老用户在复购时是为企业进行无形的宣传,拉动新客户,从而减少了宣传成本[1]。可见,老客户流失会对餐饮企业造成不小的损失,减少老客户流失对餐饮企业发展尤为重要。餐饮企业需预测有可能流失的客户,在客户流失前分析其流失原因,找寻提高客户留存率的方法,制定相应挽留策略。
随着大数据技术与网络信息产业的发展,机器学习技术为数据分析提供了更加便捷的分析工具,餐饮企业可根据客户基本信息及消费产生的订单信息,构建客户流失特征,提前识别将要流失的客户,根据客户流失的重要特征制定相应的挽留策略,降低客户流失率,提高经济效益。白瑞瑞使用逻辑回归、决策树、随机森林、XGBoost模型,分析在携程网预定酒店客户的流失情况的预测效果[2]。王兴丽使用单一分类算法与集成分类算法,预测电信客户的流失情况,发现集成算法在电信客户流失预测中的效果较好[3]。张静怡建立决策树模型,利用历史交易数据预测证券市场的客户流失情况,证明该模型可较精确地预测潜在客户的流失[4]。张叶航使用随机森林算法建立车险客户流失预测模型,发现该模型可输出客户流失概率,有效实现客户细分,帮助车险公司挽留客户[5]。
本研究构建客户流失特征,分别建立决策树与支持向量机模型,对客户的流失情况进行预测,分析判断两种模型的预测能力与准确度,以期利用其指导餐饮企业制定挽留客户策略,减少餐饮企业的损失。
1 决策树算法与支持向量机模型的建立
1.1 决策树算法
决策树的结构是树状结构,由一个根节点、一些内部节点及一些叶节点构成。根节点为样本集,叶节点对应分类结果,内部节点则为特征或属性,从根节点到每个叶节点的路径都对应一个判别序列。决策树算法是通过递归过程生成泛化能力强的决策树,其基本执行流程为分而治之。构造决策树的关键是选择适当的特征对样本进行拆分,常用的算法及选择特征准则有CART(基尼系数)、ID3(信息增益)及C4.5(信息增益比值)。决策树中的剪枝是为了避免过拟合,提高其泛化能力。尽管很多分类算法的分类能力都超过了决策树算法,但是决策树算法的可视化分类规则功能是其他算法无法替代的,常被用于分析特征影响最大,如较具样特征的客户流失概率会更高,等等。
决策树的优点在于结果比较清晰易懂,能够实现可视化分析,更加易于提取规则。决策树可并行处理数值型与类别型数据,在大型数据库中同样适用,模型大小与数据库大小无关。决策树的缺点是在特征数量多但样本数量少的情况下,易出现过拟合现象,且不关注数据集中特征的关联性。使用ID3算法计算信息增益时,结果往往受数值特征的影响。
1.2 支持向量机算法
支持向量机是特征空间中间隔最大的线性分类器,其中包含核函数,这使得支持向量机成为实质上的非线性分类器。支持向量机的学习要点是间隔最大化,可将间隔最大化转化为求解凸二次规划问题,等价于正则化的损失函数最小化问题。支持向量机是一种监督学习的数据挖掘算法,也是一种二分类算法,经转化后也适用于多分类问题,在非线性分类方面具有显著优势,常用于处理二元分类问题。在机器学习领域中,支持向量机算法可用于分类、异常值检测、模式识别及回归分析,SVR是支持向量机算法在回归方面的运用。支持向量机算法在文字识别、人脸识别、行人检测及文本分类等领域都具有较好的应用效果。
支持向量机可对非线性分类进行建模,当发生过拟合时,支持向量机具有很强的鲁棒性,在高维空间中鲁棒性更强。其最终决策函数仅由少数的支持向量决定,计算的复杂性越强所需要的支持向量越多,这与样本空间的维数无关,可避开维数灾难。
2 数据预处理
使用某餐饮企业的客户用餐数据,将其分别整理为客户信息表与订单详情表。客户信息表记录了3361位客户的基本信息,每条客户信息都包括客户ID、姓名、年龄、性别等34个特征,其特征说明详见表1。订单详情表记录了8783条客户消费记录,每条记录有21个特征,其特征说明详见表2。

表1 客户信息表特征Tab.1 Description of customer information table features

表2 订单详情表特征Tab.2 Description of order details table characteristics
在对数据集进行预处理时,首先要检查数据集中是否存在重复值,以免影响特征值的计算,导致模型预测出错。客户信息表中客户ID是唯一主键,经检查此表中不存在重复记录。订单详情表中订单ID是唯一主键,经检查此表中不存在重复记录。
建构客户流失特征时,主要使用订单详情表中的数据,发现存在一张桌子同时被不同用户使用的情况,即两个订单的桌子ID与开始使用时间相同,属于异常值数据。经检查,发现异常值的比重极小,不会对数据分析结果产生影响,故直接删除异常值。
客户信息表中存在大量的缺失值,因其特征项较多,客户在开户时预留信息不完整。而订单详情表中的数据大都由系统自动生成,数据较为完整,但也有部分缺失值。经研究发现,并不是每一项客户信息表与订单详情表中的特征数据都可用于预测客户流失,故提取关键特征,将客户信息表中的客户ID、最后一次登录、客户状态特征以及订单详情表中的客户ID、消费人数、消费金额特征以客户ID为主键进行合并,使用pandas库中的dropna函数对缺失值进行处理。经上述处理,共得到2547条完整的客户记录可用于模型的训练与预测。
客户流失大体上表现为4个方面:到店用餐次数越来越少、长时间未到店用餐、人均消费额较低、总消费额越来越低。基于此,构建6项客户流失特征数据:用户ID(USER_ID)、总用餐次数(frequence)、最近一次用餐距当前的天数(recently)、人均消费额(average)、总消费额(amount)及客户流失标签(TYPE),其中客户流失标签分为非流失、准流失、已流失三种。详见表3。
3 实证研究
选择Anaconda软件为实证研究平台,因其拥有众多流行的数据分析Python库,其中就包含决策树算法与支持向量机算法。构建的客户流失预测流程详见图1。
为对比决策树模型与支持向量机模型对客户流失的预测能力,需保证用于训练及测试的数据一致,且使用相同的模型评价方式。可用数据记录共2547条,删除已流失的客户数据637条,将非流失与准流失数据按4∶1的比例划分为训练集与测试集,其中1528条数据记录为训练集数据,382条数据记录为测试集数据。使用sklearn库构建决策树模型与支持向量机模型,分别对其进行训练,使用测试集数据对训练完毕的两种模型进行预测,并自定义评价函数,使用评价函数计算模型的混淆矩阵、精确率及F1值。两种模型的各项评价指标详见表4。

表4 两种模型的各项评价指标Tab.4 Each evaluation index of the two models
决策树模型与支持向量机模型的精确率和F1值都很高,说明两种模型的预测效果都很好,对客户非流失与准流失的分类能力相对均衡。设置客户的流失标签为准流失与非流失,在模型的训练与测试中,用0表示准流失,1表示非流失,分别用两种模型预测测试集中客户的流失状态。根据餐饮企业对客户流失预测的要求,对准流失客户的预测结果更加重要,即把客户流失标签为0的客户全预测为0更为重要。在测试集的382位客户中,有167位非流失客户与215位准流失客户,决策树模型预测的准流失客户数为195位,准确率为0.907,而支持向量机模型预测的准流失客户数为209位,准确率达到0.972,说明支持向量机模型可更好地预测准流失客户,能够更精准地为餐饮企业锁定客源损失目标。
对于本研究中的测试集而言,决策树模型的总预测精确度为0.913,支持向量机模型的总预测精确率为0.951,支持向量机模型的精确率更高。由于测试集数据较多,仅展示了两个模型对测试集中前10位客户的流失状态预测结果。其中,决策树模型对4位非流失客户只预测对1位,说明决策树算法的模型稳定性较差。支持向量机模型对6位准流失客户预测正确5位,对于4位非流失客户全部预测正确,说明支持向量机模型的稳定性较好,可认为支持向量机模型更适用于客户的流失预测。详见表5。
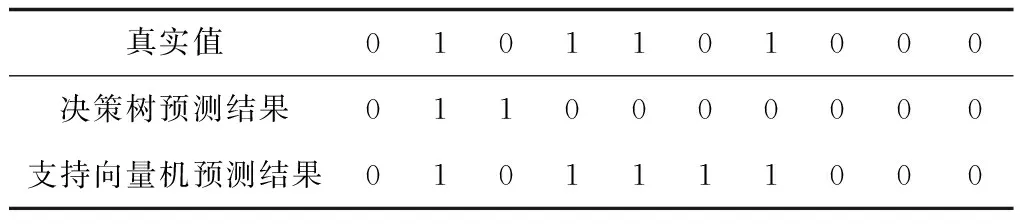
表5 两种模型对测试集前10位客户流失状态的预测结果Tab.5 Predicted results of the two models for the loss situation of first 10 customers in the test set
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
食品研究与开发(2020年12期)2020-06-05
环球市场(2020年26期)2020-01-19
成都信息工程大学学报(2019年3期)2019-09-25
智富时代(2019年4期)2019-06-01
智富时代(2019年4期)2019-06-01
电子制作(2018年16期)2018-09-26
环球市场(2017年31期)2017-03-09
中央民族大学学报(自然科学版)(2016年4期)2016-06-27
