
改进DeepLabv3+网络的图书书脊分割算法
2024-01-09 02:46姬晓飞张可心唐李荣
计算机应用 2023年12期
姬晓飞,张可心,唐李荣
改进DeepLabv3+网络的图书书脊分割算法
姬晓飞*,张可心,唐李荣
(沈阳航空航天大学 自动化学院,沈阳 110136)(∗通信作者电子邮箱jixiaofei7804@126.com)
图书定位是实现图书馆智能化发展的重要技术之一,精确的书脊分割算法成为实现该目标的一大难题。基于以上情况,提出改进DeepLabv3+网络的图书书脊分割算法,以解决图书密集排列、图书存在倾斜角度和书脊纹理极相似等情况下的书脊分割难点。首先,为了提取图书图像更密集的金字塔特征,将原始DeepLabv3+网络中的空洞金字塔池化(ASPP)替换为多空洞率、多尺度的DenseASPP (Dense Atrous Spatial Pyramid Pooling)模块;其次,针对原始DeepLabv3+网络对大长宽比的目标对象分割边界不敏感的问题,在DenseASPP模块的支路加入条形池化(SP)模块以增强书脊的长条形特征;最后,参考ViT (Vision Transformer)中的多头自注意(MHSA)机制,提出一种全局信息增强的自注意模块,以增强网络获取长距离特征的能力。将所提算法在开源数据库上进行对比测试,实验结果表明,与原始DeepLabv3+网络分割算法相比,所提算法在近竖直书脊数据库上的平均交并比(MIoU)提升了1.8个百分点;在倾斜书脊数据库上的MIoU提升了4.1个百分点,达到了93.3%。以上验证了所提算法实现了有一定倾斜角度的、密集的和大长宽比的书脊目标的精确分割。
书脊分割;智能图书馆;DeepLabv3+网络;DenseASPP;自注意机制
0 引言
随着信息化社会的发展,读者数与馆藏量的增加使图书馆传统查找图书的方式无法满足读者高效获取图书的需求,基于图像处理的图书自动定位方法已经成为研究热点。对于在架图书,只有书脊部分可以被观察到,因此每本图书书脊的分割是对图书实现精确定位的前提。本文旨在解决在架图书书脊图像的分割问题,其中主要的挑战是:1)图书摆放数量较多,属于密集对象;2)由于书籍的薄厚不一致,导致书脊具有差别较大的长宽比;3)相同系列书籍的排放,在纹理上具有极高的重复或者相似性,难以区分边界;4)拍摄角度或者图书的倾斜摆放使图像中的书籍呈不同的倾斜角度。
基于传统图像处理的方法主要依靠人工提取特征送入分类器实现,如颜色、纹理和尺度不变特征变换等特征与支持向量机(Support Vector Machine, SVM)的配合使用。对于密集排列图书的分割,最大困难是边缘部分的分割。Tabassum等[1]和康洪雷等[2]直接通过霍夫直线检测或LSD(Line Segment Detection)线段检测提取书脊两侧直线;崔晨等[3]提出了一种基于文本检测的书脊区域粗选方法,利用相似字符提取候选书脊图像的方向梯度直方图特征输入SVM进行判断;Nevetha等[4]提出一种带有若干启发式规则的线段检测器获取书脊边缘。这些传统方法受限于手工提取特征的单一性,容易受到密集排列书脊高纹理区域的相似性和边界模糊性的影响,产生错误的分割线,鲁棒性差。
近年来,卷积神经网络(Convolutional Neural Network, CNN)在计算机视觉领域,包括图像分类[5]、目标检测[6]和语义分割[7]等取得了较好的表现。分割的准确性由局部特征(颜色和强度)和全局特征(纹理和背景)决定。在不同的CNN变体中,对称编码器-解码器体系结构命名法U-Net[8]具有突出的细分潜力。它主要由一系列连续的卷积层和下采样层组成,通过收缩路径捕获上下文语义信息,然后在解码器中,用编码器的横向连接对粗粒度深特征和细粒度浅特征映射进行上采样,以生成精确的分割映射。为了进一步提高分割性能,随后出现了多种U-Net的变体,如UNet++[9]和Res-UNet[10]。但是这种体系结构的感受野大小存在限制,使深度模型无法捕获足够的上下文信息,导致在边界等复杂区域分割失败。为了缓解这个问题,Chen等[11]提出了DeepLab网络,引入了一种使用上采样滤波器的新型卷积操作,即膨胀卷积,以扩大滤波器的视野,吸收更大的上下文而不增加计算量。其次,该网络为了能够捕捉更精细的细节,采用条件随机场细化分割结果。在此基础上,为了提取目标的多尺度特征,Chen等[12]又提出DeepLabv2,该网络使用空洞金字塔池化(Atrous Spatial Pyramid Pooling, ASPP)模块实现对多尺度对象的分割,ASPP模块通过探测具有不同采样率的多个膨胀卷积的特征映射获取多尺度的信息表示。随后,DeepLabv3[13]设计了一个带有膨胀卷积的编码器-解码器架构,以获得更清晰的对象边界,利用深度可分离卷积提高计算效率。Chen等[14]提出了DeepLabv3+网络模型,通过添加一个简单有效的解码器模块扩展DeepLabv3,以提高分割性能。Deeplab系列网络经过一系列优化,得到了令人满意的分割效果,成为目前语义分割领域的主流网络之一;但由于局部性和权值共享的归纳偏差[15],它们不可避免地在学习远程依赖性和空间相关性方面存在约束,导致复杂结构的次优分割。
与CNN相比,ViT(Vision Transformer)网络[16]具备了学习长距离特征和全局信息的能力,在图像分割任务上表现突出;尽管ViT可以捕捉全局上下文信息和长距离信息,但在捕捉低级像素信息方面较弱,无法较好完成精确的分割任务。为了避免ViT的高内存需求,Swin Transformer[17]提出了一种具有非重叠窗口的局部计算的分层ViT。结合高效的CNN和强大的ViT,研究人员又提出了如Trans-UNet[18]和TransDeepLab[19]等网络。此类方法使用Transformer重构一个经典的CNN,但增加了模型的复杂性。文献[20]中证明,ViT网络的优越性表现一部分原因是引入了多头自注意(Multi-Headed Self-Attention, MHSA)机制,而MHSA能够对输入的特征全局建模。
综合考虑CNN和ViT的优势,本文提出了改进DeepLabv3+网络的图书书脊分割算法,此算法兼具了CNN出色的低级像素处理能力和ViT对全局信息建模的能力,在书籍分割中表现出了优异的效果。
本文的主要工作如下:
1)针对分布密集的目标,使用DenseASPP(Dense Atrous Spatial Pyramid Pooling)结构取代ASPP网络。在密集目标分割任务上有更好的效果。
2)引入条形池化(Strip Pooling, SP)模块,保留书脊的长条形特征。
3)参考ViT中的MHSA机制搭建自注意机制,并应用至CNN,增强特征的上下文信息。
1 本文算法
本文算法的网络结构如图1所示,其中为膨胀率。
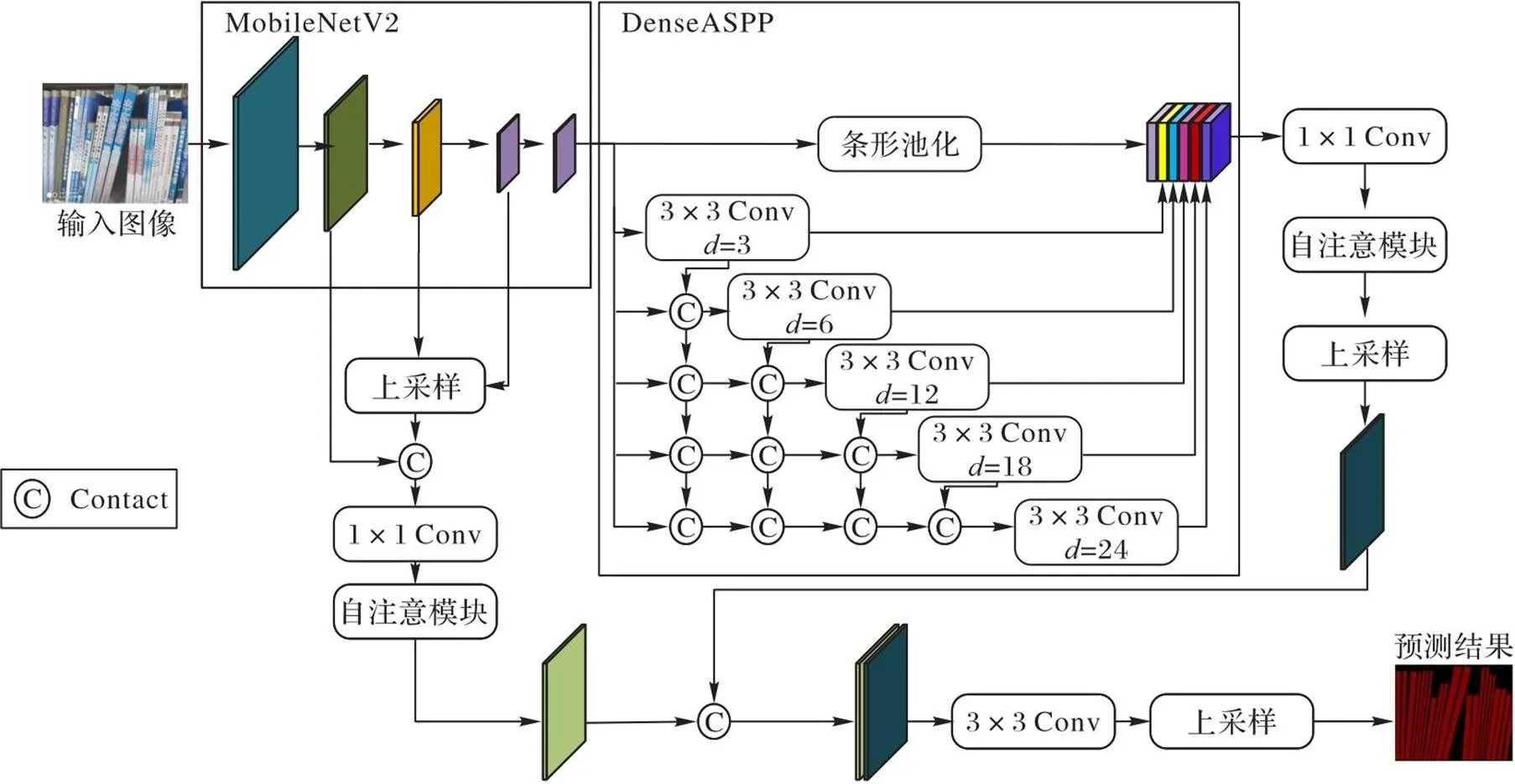
图1 本文算法的网络结构
本文网络遵循DeepLabv3+的原始框架,骨干网络选用MobileNetV2。将书籍图像输入MobileNetV2进行特征提取,对MobileNetV2的中间3层的特征图进行上采样融合,将融合结果作为浅层特征。同时,将MobileNetV2的最后一层输出送入DenseASPP模块。在编码阶段,本文利用DenseASPP模块取代ASPP模块,以产生更大的接受域,生成更密集的图像特征。对于书脊长宽比较大的情况,在DenseASPP模块中引入条形池化模块保留长条形的图像特征。最后,DenseASPP模块产生的特征经过1×1卷积操作实现通道压缩,送入自注意模块得到深层特征。在译码阶段,对浅层特征层利用1×1卷积调整通道数,送入自注意模块,与深层特征进行拼接,随后进行两次卷积和一次上采样操作,得到最终的预测结果。
1.1 DenseASPP模块
针对书籍图像这种密集型分割任务,本文引入DenseASPP模块以生成更密集的特征。它的结构如图1所示,空洞卷积层以级联方式组织,膨胀率小的层在上部,膨胀率大的层在下部,每一层的膨胀率逐层增加。将每一层的输出、输入的特征图和较低层的所有输出拼接(Contact),并将这些拼接的特征图送入下一层。DenseASPP模块的最终输出是由多空洞率、多尺度的卷积生成的特征图。通过一系列的空洞卷积,较后层次的神经元获得越来越大的感受野,避免了ASPP[12]的核退化问题。与ASPP相比,DenseASPP模块将所有空洞卷积层堆叠在一起,并进行紧密的拼接。这种变化主要带来以下两个好处:
1)更密集的特征金字塔。
密集抽样规模 DenseASPP模块可以对不同规模的输入进行采样,使用紧密的连接实现不同膨胀率的不同层次的集成。

2)更大的接受域。
膨胀卷积在ASPP中并行工作,而4个分支在前馈过程中不共享任何信息。相反,DenseASPP模块中的空洞卷积层通过跳层连接共享信息。小膨胀率和大膨胀率的层之间相互依赖,其中前馈过程不仅构成了一个更密集的特征金字塔,也产生了一个更大的过滤器感知更大的上下文。
1.2 条形池化
在DenseASPP模块中引入条形池化模块,如图2所示。它的核心思想是在空间维度上应用了一个长条状的池化卷积核,从而增强捕获长距离信息的能力,保留书脊的长条形特征。它的水平、竖直方向的池化计算公式分别为:
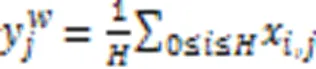
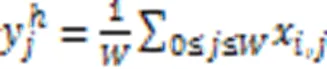
结合图2,利用式(1)(2)对输入张量中的某一像素所在行和列的局部特征值进行平均条形池化,得到虚线框内最前面的两个横纵条形块两部分,对它们分别进行一维卷积操作,将得到的结果进行上采样至输入张量大小,然后进行特征融合,经过卷积、Sigmoid环节后与输入张量按像素相乘得到输出张量。在上述过程中,实现了输出张量中的每个位置均与输入张量中的位置建立关系。输出张量中以虚线框最右侧的正方形连接到与它具有相同水平或垂直坐标的所有位置,实现了长条信息的保留。
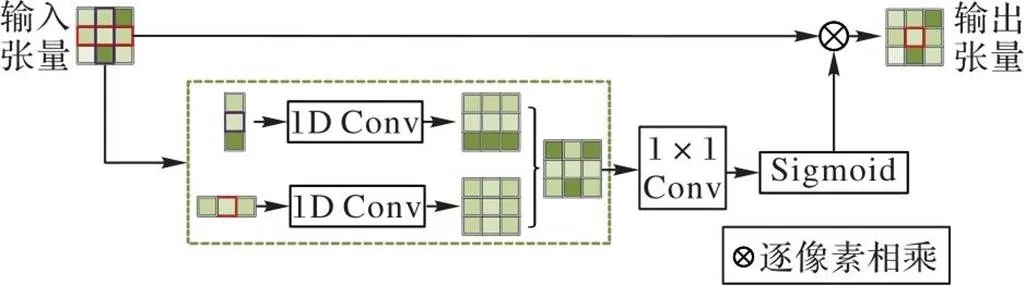
图2 条形池化过程
1.3 自注意模块
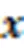
图3 自注意模块
2 实验与结果分析
2.1 数据集
2.2 实验设计
在实现细节上,算法基于PyTorch库实现,并在单个NVIDIA RTX 3060 GPU上进行训练,处理器为12th Gen Intel Core i5-12400F,批次大小为4(资源限制),初始学习率为0.05,使用随机梯度下降法(Stochastic Gradient Descent,SGD)作为优化方法。采用Dice损失和交叉熵损失作为目标函数,采用L2范数进行模型正则化。使用旋转和翻转技术作为数据增强方法,使得训练集多样化。分割模型训练分为两个部分:1)不考虑正负样本的平衡关系进行全网络训练,训练的损失如图4所示;2)当训练到损失值基本不下降后,即1 800次左右,将正负样本损失比重设置为1∶8,启用focal loss继续训练。本文采用平均交并比(Mean Intersection over Union, MIoU)指标评价在测试集上的分割效果。
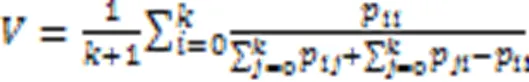
其中:为类数,包含一个背景;表示真实标签,表示预测标签;为真正例(预测标签与真实标签相同,均为书脊区域);为假负例(预测结果为非书脊区域,真实标签为书脊区域);为假正例(预测结果为书脊区域,真实标签为非书脊区域);表示预测区域与手工标记区域的平均交并比。
2.3 评估结果
2.3.1本文算法的有效性验证
为了验证本文算法的有效性,对以上改进操作逐一进行实验测试。实验基于DeepLabv3+的原始网络展开,骨架网络选用MobileNetV2,学习率为0.002 5,使用相同的线性衰减率,训练次数为3 000,且不启用focal loss训练,对全测试集(包含近竖直测试集与倾斜数据集)进行统计。
1)DenseASPP有效性验证。
在DeepLabv3+网络框架中分别使用DenseASPP模块与ASPP模块得到分割结果分别为91.2%,89.3%。使用DenseASPP模块替换ASPP模块后,该网络分割的准确率提高了1.9个百分点,验证了DenseASPP模块的优势。
为了降低模型的复杂度,本文选用大小为3的卷积核和不同膨胀率构成空洞卷积层,不同层之间进行级联,DenseASPP模块的网络层数对分割效果的影响,实验结果见表1。
表1DenseASPP模块的网络层数对分割效果的影响

Tab.1 Influence of number of network layers of DenseASPP module on segmentation effect
从表1可知,当网络层数较低或者较高时,对准确率均存在一定的影响。当网络层数较低时,细节信息较少,特征不明显,因此准确率不高;当网络层数较高时,会出现过拟合的现象,导致准确率降低。
2)自注意模块有效性验证。
实验分别在Xception和MobileNetV2两种骨架网络上进行,保留DeepLabv3+网络原始框架(DenseASPP模块代替ASPP模块),只增加自注意模块,结果如表2所示。
图5分别展示了经过MobileNetV2骨架特征提取后,自注意模块使用前后,对书脊上下文特征的影响。相较于图5(a),图5(b)得到的书脊特征更清晰。综上,依据表2和图5的结果,不论采用哪种的特征提取网络骨架,在引入自注意模块后,准确率均上升,验证了自注意模块可以关联全局信息,在分割任务中发挥重要的作用。
表2引入自注意模块前后的实验结果对比 单位:%

Tab.2 Comparison of experimental results before and after introduction of self-attention module unit:%

图5 加入自注意模块前后的特征可视化对比
3)条形池化模块有效性验证。
利用DeepLabv3+网络原始框架(DenseASPP模块代替ASPP模块),比较有无条形池化模块在书脊分割上的差异,以验证条形池化模块的应用价值。引入条形池化模块前后,深层特征和浅层特征融合得到的特征可视化结果如图6所示。

图6 加入条形池化模块前后的特征可视化对比
相较于图6(a),图6(b)在加入条形池化模块后,使书脊的长条特征得到了增强,但受环境的影响,如书架横栏等,也会被条形池化模块增强特征,因此可能会出现一些无关特征。在总体框架中可利用自注意模块抑制无关特征,这也验证了自注意模块的重要性。
2.3.2不同算法对比结果
在进行不同网络分割算法的比较时,将书脊库划分为近竖直书脊数据库和倾斜书脊数据库,其中训练集采用倾斜、近竖直混合数据进行训练。为了考察书脊的倾斜给各类算法带来的影响,分别在近竖直与倾斜两组测试数据库上进行对比。不同网络分割算法的对比测试结果见表3。
表3不同网络分割算法在开源数据库上的测试结果
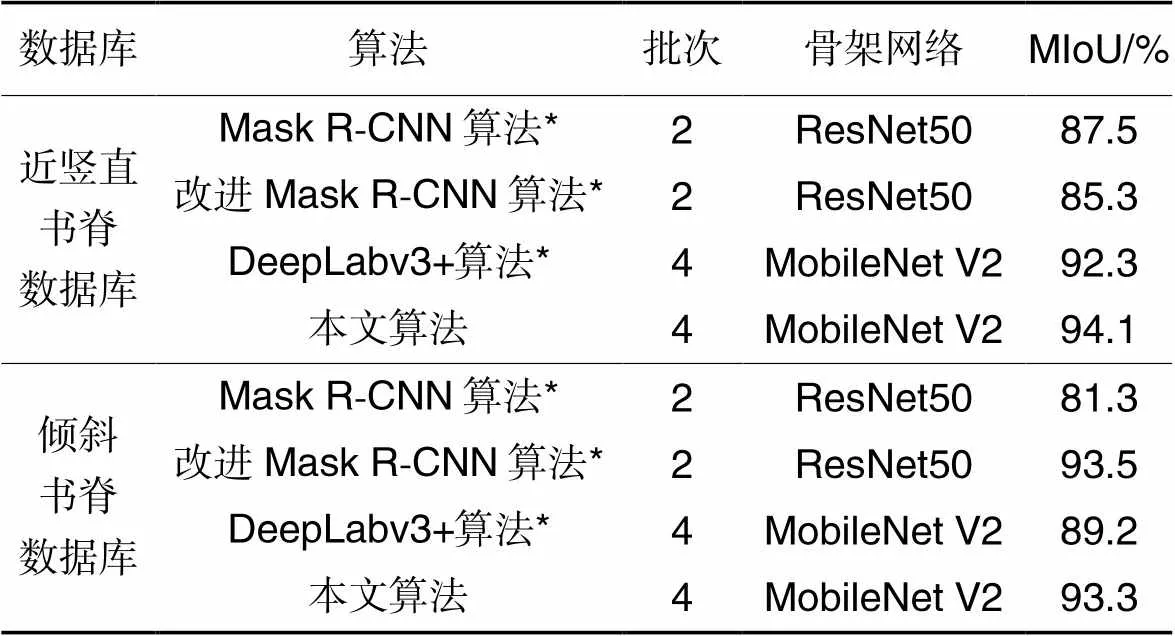
Tab.3 Test results of different network segmentation algorithms on open-source database
注:*代表相应文献提供开源代码和默认参数在本文数据集上进行重新训练得到的测试结果。
1)近竖直书脊测试结果。
从表3可以看出,本文算法在近竖直书脊数据库上表现较好。其中,Mask R-CNN(Mask Region-based CNN)使用了区域生成网络(Region Proposal Network, RPN),该网络只能生成规模、尺寸不同的矩形框,但由于书籍的密集性导致此类方法的分割效果不佳。DeepLabv3+网络没有对单个目标设计全卷积特征提取网络,这使得该算法在对长宽比例差异大的对象进行检测和分割时效果较差,而且在目标密集分布的情况下更突显。本文对DeepLabv3+网络进行改进,虽然在一定程度上增加了模型的复杂度,但同时大幅增强了分割算法对书脊特征的表征能力,在近竖直书脊数据库上的测试结果也验证了本文算法对于书脊分割的优势。
2)倾斜书脊测试结果。
从表3中在倾斜书脊数据库的测试结果可以看出,Mask R-CNN在倾斜书脊方面的应用效果较差。改进Mask R-CNN算法[22]采用Mask R-CNN与旋转特征提取方法(Rotation Feature Extraction, RFE)结合的算法,使用旋转区域生成网络(Rotation Region Proposal Network, RRPN)替换RPN,除了大小、比例外,引入一个角度参数优化Mask R-CNN。该方法可有效地避免RPN带来的角度适应性问题,取得了优于本文算法的检测准确率,但它大幅增加了学习参数的数量,提高了模型的复杂度,在近竖直书脊数据库上表现较差。
综上所述,本文算法在书脊分割上有较好的表现。与原始DeepLabv3+网络分割算法相比,在相同的特征提取网络和相同训练次数下,所提算法在近竖直书脊数据库上的平均交并比(MIoU)提升了1.8个百分点;在倾斜书脊数据库上的平均交并比提升了4.1个百分点,达到了93.3%。在相同操作系统下,相较于Mask R-CNN系列,训练参数更少,但性能大幅提高。在相同数据集下,文献[21]测试了不同分割算法下的分割效果。其中FCN(Fully Convolutional Network)模型结构包括FCN32s、FCN16s等结构,32s即从32倍下采样的特征图恢复至输入大小,16s则从16倍下采样恢复至输入大小。理论上,该数字越小,网络使用的反卷积层进行上采样的操作越多,对应的模型结构更复杂,理论分割效果更精细。具体的测试结果为:FCN16s、FCN32s、SegNet、U-Net和DeepLabv3的分割效果(采用MIoU指标)分别为0.816 0、0.819 3、0.866 0、0.875 0和0.918 6。其中DeepLabv3表现效果最佳,进一步验证了其他分割算法对长条形特征目标的适用性较差,突出了Deeplab系列网络的优越性。
图7为不同算法的分割效果。DeepLabv3+网络的分割效果如图7(a)所示,它在密集目标中效果较好,但存在边界分割不清的问题。如图7(b)所示,Mask R-CNN在近竖直的目标上表现一般,且遭遇倾斜目标时容易被相邻目标干扰,甚至出现大量漏检现象。本文算法分割效果如图7(c)所示,该算法对密集、具有一定倾斜的目标分割效果较稳定,尤其对于相邻目标的掩膜预测有更高的隔离性,不会出现其他算法中相邻目标相互影响的情况,有效地提高了分割的准确率。

图7 不同算法的分割效果
3 结语
本文提出了一种DeepLabv3+改进网络的图书书脊分割算法,用于分割密集排列且带有一定倾斜角度的书脊图像。本文还提出了一个即插即用的增强全局信息的自注意模块;使用DenseASPP模块替换ASPP模块提取更密集、更广范围的书脊特征;在DenseASPP模块的支路上插入条形池化模块,增强书脊的长条特性。实验结果表明,本文算法可以增强原网络对密集、大长宽比和倾斜目标的分割效果,相较于其他算法具有较大的优势。同时本文算法也可以扩展到航拍的规则目标分割、密集目标分割等场景。下一步将进一步研究提升分割算法对拍摄角度差异的适应性。
[1] TABASSUM N, CHOWDHURY S, HOSSEN M K, et al. An approach to recognize book title from multi-cell bookshelf images [C]// Proceedings of the 2017 IEEE International Conference on Imaging, Vision & Pattern Recognition. Piscataway: IEEE, 2017:1-6.
[2] 康洪雷,牛连强,冯庸,等.基于视觉的错序在架图书检测系统[J].软件工程,2018,21(4):18-22.(KANG H L, NIU L Q, FENG Y, et al. A vision-based system to detect books with incorrect sequence on shelf [J]. Software Engineering, 2018, 21(4):18-22.)
[3] 崔晨,任明武.一种基于文本检测的书脊定位方法[J].计算机与数字工程,2020,48(1):178-182,251.(CUI C, REN M W. A spine location method based on text detection [J]. Computer and Digital Engineering, 2020, 48(1): 178-182,251.)
[4] NEVETHA M P, BARSKAR A. Automatic book spine extraction and recognition for library inventory management [C]// Proceedings of the 3rd International Symposium on Women in Computing and Informatics. New York: ACM, 2015:44-48.
[5] UÇKUN F A, ÖZER H, NURBAŞ E, et al. Direction finding using convolutional neural networks and convolutional recurrent neural networks [C]// Proceedings of the 2020 28th Signal Processing and Communications Applications Conference. Piscataway: IEEE, 2020:1-4.
[6] CAI W, HU D. QRS complex detection using novel deep learning neural networks [J]. IEEE Access, 2020, 8: 97082-97089.
[7] SAXENA N, K B N, RAMAN B. Semantic segmentation of multispectral images using Res-Seg-net model [C]// Proceedings of the 2020 IEEE 14th International Conference on Semantic Computing. Piscataway: IEEE, 2020:154-157.
[8] ZHANG Z, LIU Q, WANG Y. Road extraction by deep residual U-Net [J]. IEEE Geoscience and Remote Sensing Letters, 2018, 15(5): 749-753.
[9] ZHOU Z, SIDDIQUEE M M R, TAJBAKHSH N, et al. UNet++: a nested U-Net architecture for medical image segmentation [EB/OL]. (2018-07-18)[2022-12-18]. https://arxiv.org/pdf/1807.10165.pdf.
[10] CAO K, ZHANG X. An improved Res-UNet model for tree species classification using airborne high-resolution images [J]. Remote Sensing, 2020, 12(7): 1128.
[11] CHEN L-C, PAPANDREOU G, KOKKINOS I. Semantic image segmentation with deep convolutional nets and fully connected CRFs [EB/OL]. (2014-12-22)[2022-12-18]. https://arxiv.org/ pdf/1412. 7062.pdf.
[12] CHEN L-C, PAPANDREOU G, KOKKINOS I, et al. DeepLab: semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected CRFs [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2018, 40(4):834-848.
[13] CHEN L-C, PAPANDREOU G, SCHROFF F, et al. Rethinking atrous convolution for semantic image segmentation [EB/OL]. (2017-06-05)[2022-12-18]. https://arxiv.org/pdf/1706.05587.pdf.
[14] CHEN L-C, ZHU Y, PAPANDREOU G, et al. Encoder-decoder with atrous separable convolution for semantic image segmentation [EB/OL]. (2018-08-22)[2022-12-18]. https://arxiv.org/pdf/1802.02611.pdf.
[15] XIE Y, ZHANG J, SHEN C, et al. CoTr: efficiently bridging CNN and Transformer for 3D medical image segmentation [C]// Proceedings of the 2021 International Conference on Medical Image Computing and Computer-Assisted Intervention. Cham: Springer, 2021: 171-180.
[16] DOSOVITSKIY A, BEYER L, KOLESNIKOV A, et al. An image is worth 16×16 words: Transformers for image recognition at scale [EB/OL]. (2020-10-22)[2022-12-18]. https://arxiv.org/pdf/2010. 1192 9v2.pdf.
[17] LIU Z, LIN Y, CAO Y, et al. Swin Transformer: hierarchical vision Transformer using shifted windows [EB/OL]. (2021-08-17)[2022-12-18]. https://arxiv.org/pdf/2103.14030v2.pdf.
[18] CHEN J, LU Y, YU Q, et al. TransUNet: Transformers make strong encoders for medical image segmentation [EB/OL]. (2021-02-08)[2022-12-18]. https://arxiv.org/pdf/2102.04306v1.pdf.
[19] AZAD R, HEIDARI M, SHARIATNIA M, et al. TransDeepLab: convolution-free Transformer-based DeepLabv3+ for medical image segmentation [EB/OL]. (2022-08-01)[2022-12-18]. https://arxiv.org/pdf/2208.00713.pdf.
[20] SRINIVAS A, LIN T-Y, PARMAR N, et al. Bottleneck Transformers for visual recognition [C]// Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Washington, DC: IEEE Computer Society, 2021: 16514-16524.
[21] 曾文雯,杨阳,钟小品.一种用于在架图书书脊语义分割的山字形网络[J].图像与信号处理, 2020, 9(4): 218-225.(ZENG W W, YANG Y, ZHONG X P. A mountain-shaped network for semantic segmentation of books spines on-shelves [J]. Image and Signal Processing, 2020, 9(4): 218-225.)
[22] 曾文雯,杨阳,钟小品. 基于改进Mask R-CNN的在架图书书脊图像实例分割方法[J].计算机应用研究, 2021,38(11):3456-3459,3505.(ZENG W W, YANG Y, ZHONG X P. Improved Mask R-CNN based instance segmentation method for spine image of books on shelves [J]. Application Research of Computers, 2021, 38(11):3456-3459,3505.)
Book spine segmentation algorithm based on improved DeepLabv3+ network
JI Xiaofei*, ZHANG Kexin, TANG Lirong
(,,110136,)
The location of books is one of the critical technologies to realize the intelligent development of libraries, and the accurate book spine segmentation algorithm has become a major challenge to achieve this goal. Based on the above solution, an improved book spine segmentation algorithm based on improved DeepLabv3+ network was proposed, aiming to solve the difficulties in book spine segmentation caused by dense arrangement, skew angles of books, and extremely similar book spine textures. Firstly, to extract more dense pyramid features of book images, the Atrous Spatial Pyramid Pooling (ASPP) in the original DeepLabv3+ network was replaced by the multi-dilation rate and multi-scale DenseASPP (Dense Atrous Spatial Pyramid Pooling) module. Secondly, to solve the problem of insensitivity of the original DeepLabv3+ network to the segmentation boundaries of objects with large aspect ratios, Strip Pooling (SP) module was added to the branch of the DenseASPP module to enhance the strip features of book spines. Finally, based on the Multi-Head Self-Attention (MHSA) mechanism in ViT (Vision Transformer), a global information enhancement-based self-attention mechanism was proposed to enhance the network’s ability to obtain long-distance features. The proposed algorithm was tested and compared on an open-source database, and the experimental results show that compared with the original DeepLabv3+ network segmentation algorithm, the proposed algorithm improves the Mean Intersection over Union (MIoU) by 1.8 percentage points on the nearly vertical book spine database and by 4.1 percentage points on the skewed book spine database, and the latter MIoU of the proposed algorithm achieves 93.3%. The above confirms that the proposed algorithm achieves accurate segmentation of book spine targets with certain skew angles, dense arrangement, and large aspect ratios.
book spine segmentation; intelligent library; DeepLabv3+ network; DenseASPP (Dense Atrous Spatial Pyramid Pooling); self-attention mechanism
This work is partially supported by Key Projects of Liaoning Provincial Department of Education (LJKZZ20220033).
JI Xiaofei, born in 1978, Ph. D., associate professor. Her research interests include video analysis and processing, pattern recognition.
ZHANG Kexin, born in 1996, M. S. candidate. Her research interests include image processing, video analysis and processing.
TANG Lirong, born in 2000, M. S. candidate. His research interests include image processing, video analysis and processing.
TP391.1
A
1001-9081(2023)12-3927-06
10.11772/j.issn.1001-9081.2022121887
2022⁃12⁃22;
2023⁃03⁃21;
2023⁃03⁃22。
辽宁省教育厅重点攻关项目(LJKZZ20220033)。
姬晓飞(1978—),女,辽宁鞍山人,副教授,博士,主要研究方向:视频分析与处理、模式识别;张可心(1996—),女,辽宁锦州人,硕士研究生,主要研究方向:图像处理、视频分析与处理;唐李荣(2000—),男,四川南充人,硕士研究生,主要研究方向:图像处理、视频分析与处理。
猜你喜欢
计算机工程与应用(2023年22期)2023-11-27
科学技术与工程(2023年3期)2023-03-15
软件导刊(2022年3期)2022-03-25
小学生学习指导(中年级)(2021年5期)2021-05-18
阅读(高年级)(2020年8期)2020-11-06
活力(2019年19期)2020-01-06
计算机技术与发展(2019年1期)2019-01-21
文体用品与科技(2016年7期)2016-06-15
文体用品与科技(2016年3期)2016-03-24
中国工程咨询(2015年6期)2015-02-16
