
基于改进蝶形反馈型神经网络的海关风险布控方法
2024-01-09 02:49:56王正刚刘忠金瑾刘伟
计算机应用 2023年12期
王正刚,刘忠,金瑾,刘伟
基于改进蝶形反馈型神经网络的海关风险布控方法
王正刚1,2,3*,刘忠1,2,金瑾4,刘伟3
(1.中国科学院 成都计算机应用研究所,成都 610213; 2.中国科学院大学 研究生院,北京 101408; 3.中华人民共和国成都海关 科技处,成都 610041; 4.成都信息工程大学 软件工程学院,成都 610103)(∗通信作者电子邮箱wangzhenggang@customs.gov.cn.com)
针对现阶段我国海关风险布控方法存在效率、准确率较低、人力资源占用过多的问题和智能化分类算法小型化部署需求,提出一种基于改进蝶形反馈型神经网络(BFNet-V2)的海关风险布控方法。首先,运用编码填充(FC)算法实现海关表格数据到模拟图像的语义替换;其次,运用BFNet-V2训练模拟图像数据,由左右两条链路、不同卷积核和块、小块的设计组成规则的神经网络结构,并添加残差短路径干预改善过拟合和梯度消失;最后,提出历史动量自适应矩估计算法(H-Adam)优化梯度下降过程,取得更优的自适应学习率调整方式,并分类海关数据。选取Xception(eXtreme inception)、移动网络(MobileNet)、残差网络(ResNet)和蝶形反馈型神经网络(BF-Net)为基线网络结构进行对比。BFNet-V2的接受者工作特征曲线(ROC)和查准率-查全率曲线(PR)包含了基线网络结构的曲线,与4种基线网络结构相比,基于迁移学习(TL)的BFNet-V2分类准确率分别提高了4.30%、4.34%、4.10%和0.37%。在真实标签数据分类过程中,BFNet-V2的查获误判率分别降低了70.09%、57.98%、58.36%和10.70%。比较所提方法与包含浅层和深度学习方法在内的8种分类方法,在3个数据集上的准确率均提升1.33%以上,可见所提方法能够实现表格数据自动分类,提升海关风险布控的效率和准确度。
卷积神经网络;模拟图像;自适应矩估计;海关;风险布控
0 引言
海关入境检疫和安全(Custom Immigration Quarantine and Security, CIQS)是关乎国家安全的重要组成部分。我国海关现有的风险分析手段不够智能化,导致作业标准无法统一,风险分析结果的可信度难以达到监管要求,亟须一种智能化的方法实现自主风险排查和高风险商品的布控。
海关风险布控根据数据特点研究结构化数据聚类、分类等算法,实现海关数据的自主风险分类。海关数据属于表格数据,这种结构化数据的分类可以参考浅层数据分类方法,如线性回归[1]、决策树[2]、随机森林[3-5]和极度梯度提升(eXtreme Gradient Boosting, XGBoost)树[6]等传统的机器学习方法,但这些方法分类效果有限,泛化性能较差;另一种处理方式是运用多种方法变换数据,借鉴表格数据深度学习算法分类识别表格数据。
Chen等[7]提出针对表格数据的神经网络组件,称为抽象层(Abstract Layer,AbstLay),设计了一种结构再参数化方法压缩经过训练的深度神经网络DANET(Deep Abstract NETwork),在训练阶段大幅降低计算复杂度。Buturović等[8]开发并评估了一种表格卷积(TAbular Convolution, TAC)的方法,通过将表格数据转换为图像,使用二维神经网络分类此类数据。Sun等[9]提出超级字符方法SuperTML(Super Tabular data Machine Learning),对于每个表格数据的输入,首先将特征像图像一样投影至二维嵌入,其次将该图像输入经过微调的二维卷积神经网络(Convolutional Neural Network, CNN)进行分类。该方法可以处理表格数据中的分类数据和缺失值,不需要将它们预处理为数值,大幅提高了表格数据的处理效率。这些方法在对比实验中取得了较好的效果,但DANET应用于医学数据集;TAC和SuperTML只是对表格数据进行了转化,没有运用新的更适应表格数据的CNN结构,泛化能力不足,难以直接用于海关数据风险分析和布控工作。它们的共同特点是将表格数据转换为二维数据,利用CNN的优异性能分类数据。
一些研究表明,神经网络对于结构化数据的分类和异常检测的效果并未很好地展现,因为这种二维图像建立的神经网络结构不能简单地套用图像、视频等领域成熟的模型。由于输入数据对象的不同,需要研究更适应这种转化后的二维图像的神经网络结构,以提高分类指标的准确率。
大多数神经网络如Xception(eXtreme inception)[10]、移动网络(Mobile Network,MobileNet)[11]和残差网络(Residual Network, ResNet)[12]等都由经验法则和直觉构建,随着体系结构不断发展和深化,加入了更多的超参数。蝶形反馈型神经网络(Butterfly Feedback neural Network, BF-Net)[13]在较少样本的海关风险数据分类方面表现优异,能够一定程度地实现海关数据风险自动判别,但当数据集和类的数量持续增大时,BF-Net的性能难以进一步提高,且模型终端小型化部署对模型的参数量和运算速度提出了更高的要求。任务的特点决定了它的主要的应用场景,对于海关风险布控自主分类问题,需要借鉴经典的CNN结构,研究一种高准确度、更低参数量和轻量级的神经网络结构。
本文针对海关数据特点,提出基于改进蝶形反馈型神经网络(Butterfly Feedback neural Network Version2, BFNet-V2)的海关风险布控方法,包含海关数据语义提取转化方法——编码填充(Filling in Code, FC)[13]、BFNet-V2结构和历史动量自适应矩估计算法(Historical momentum Adaptive moment estimation algorithm, H-Adam)这3个部分,用于实现海关单证数据自主分类。依靠本文方法进行终端部署,海关关员不再需要对海关数据手动建模,而由计算机为每一单商品货物进行风险分类和标注,辅助关员现场风险决策,在大幅提高风险分析效率的同时确保高风险商品布控检查,实现CIQS的巨大进步。
本文主要工作如下:
1)基于数据字段的增加,FC算法实现表格数据语义替换,数据字段得到极大扩充,在将表格数据转化为模拟图像过程中,运用数据直接二维随机填充,增强网络对非近邻表格数据特征的提取能力,实现高效、精准的网络训练。
2)基于海关风险分析数据量极大增加和终端部署要求的变化,提出一种相较于BF-Net[13]性能更优的CNN结构——BFNet-V2。采用具有层次性的神经网络设计方法,由若干“块”状结构按一定规则组成神经网络。利用双链路不同大小的卷积核在更广泛的感受野上提取图像的特征,将原BF-Net中的5×5普通卷积核替换为5×5的空洞卷积[14](扩张率(dilation rate)为2),并添加块输入端到块输出端的直接映射,减轻训练过程中的梯度爆炸和消失,避免深度网络过拟合,进一步减少网络参数量,通过实验验证该网络的效率和分类指标。
3)以海关表格数据分类为任务牵引,研究深度学习中的不同自适应随机优化器算法的梯度下降,引入了历史动量信息,在动量自适应矩估计(Adaptive moment estimation, Adam)算法基础上提出了一种历史动量自适应矩估计算法——H-Adam,并验证了它的有界性,分析了该算法在目标函数梯度下降过程中的作用机制,验证了不同自适应学习率调整算法的收敛性。
1 本文方法
1.1 海关数据转化方法
本文用FC算法[13]清理表格数据。由于数据量增大、数据字段增加,无法生成类似文献[13]中的较小图片,因此,不同于文献[13]中的数据顺序填充方式,本文采用随机编码填充,将每条原始数据的386个字段数据直接生成20×20的图像,算法为每个字段赋予一个图像点坐标,每个图像点坐标赋予R(Red)、G(Green)和B(Blue)三通道像素值,按照从左至右的顺序将字段数据随机填充至像素点中,直至完成数据填充,组合生成模拟图像数据集。
1.2 改进的蝶形反馈型神经网络
1.2.1基本块结构
BFNet-V2是一种运用多链路不同卷积核提取特征,按规律添加残差块,直接映射结构的新CNN结构。在BFNet-V2的基本单元块中设置参数不定的卷积层,所有的块除了卷积维度以外都具有相同的拓扑结构,左链路层与层之间用线性整流函数(Rectified Linear Unit, ReLU)[15]作为激活函数。与BF-Net的区别是右链路由空洞卷积计算,只添加1个卷积层,用空洞卷积代替同维卷积能有效地发挥空洞卷积提取特征的能力,并能部分保留上一层的原始特征进入下一层进行运算。这种基于块的模块化设计具有明显优势,通过超参数设置能够添加或删除相应的卷积层,同时可以按照需求和实验结果调整设置直接映射的策略,从而根据任务需要组成轻量级或一般神经网络。组成BFNet-V2的基本结构块如图1所示。
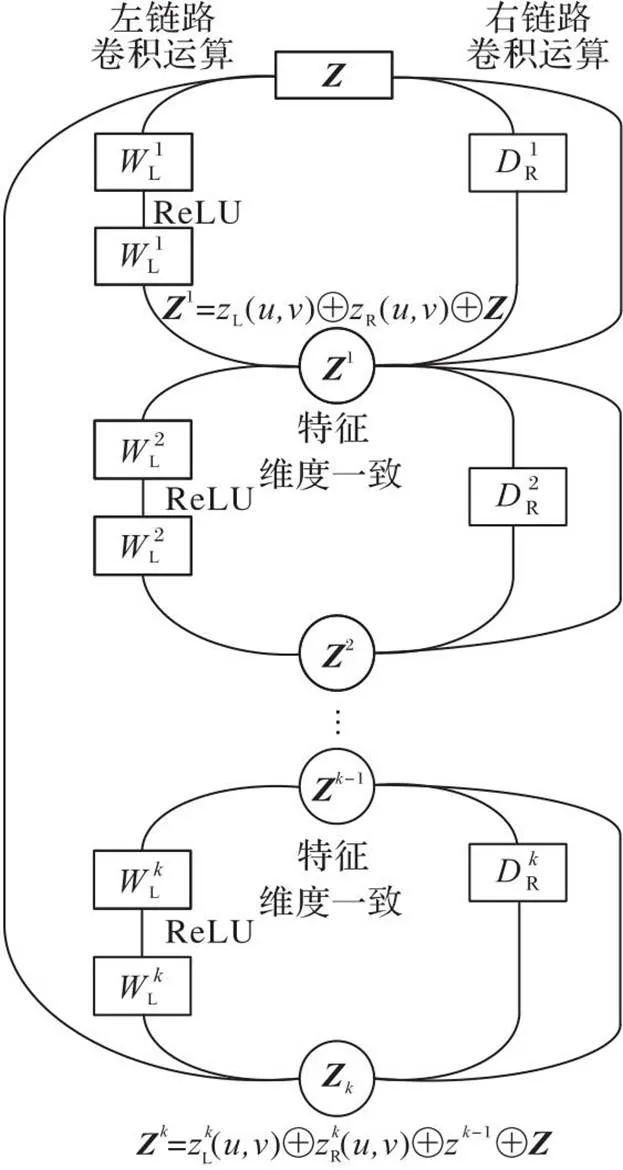
图1 BFNet-V2的基本结构块
BFNet-V2的卷积定义选择同维卷积和空洞卷积两种。由于在训练海关模拟图像时,设置padding=same(卷积方式的设置),左链路卷积运算等效于同维卷积,右链路运算等效于空洞卷积。
同维卷积的表达式如式(1)所示:
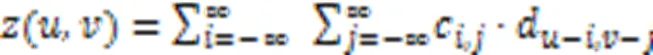
空洞卷积的表达式如式(2)所示:
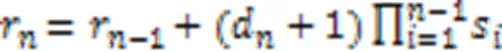
1)块和小块的正向传播。
BFNet-V2的结构由小块和块组成,具体为:若干个小块组成1个块,若干个块组成BFNet-V2网络结构,整个正向传播各层之间添加激活函数。
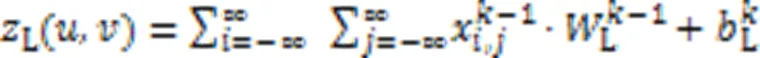
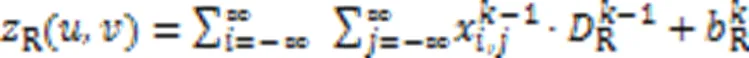
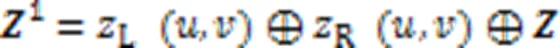
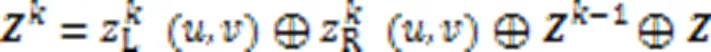
BFNet-V2中特征图像经过块结构计算后,完成特征提取,进入4个神经元梯次减少的全连接层,经过全连接层时,需要将特征图像铺平从而转换为特征向量,作为块的输出。
2)池化层的正向传播。
池化方式选择最大池化,如式(7)所示:
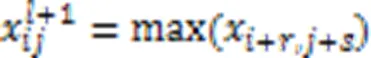
3)全连接层的正向传播。
输入数据传递到全连接层,经过全连接层后,获得分类并输出结果。表达式如式(8)所示:
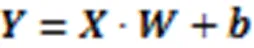
1.2.2改进蝶形反馈型神经网络整体设计
本文训练了一种具有12个基本卷积层的轻量级改进蝶形反馈型神经网络(BFNet-V2),用于海关数据风险标签分类。BFNet-V2的输入数据为3通道RGB模拟图像(图像大小20×20),设置12个卷积层,维度分别为16、32和64。左链路使用较小的感受野和3×3卷积核。右链路使用更大的感受野和5×5空洞卷积核,且只卷积一次。每两个卷积层之间将图像像素直接相加,做一次短路径直接映射。本文训练的BFNet-V2的整体结构如图2所示。
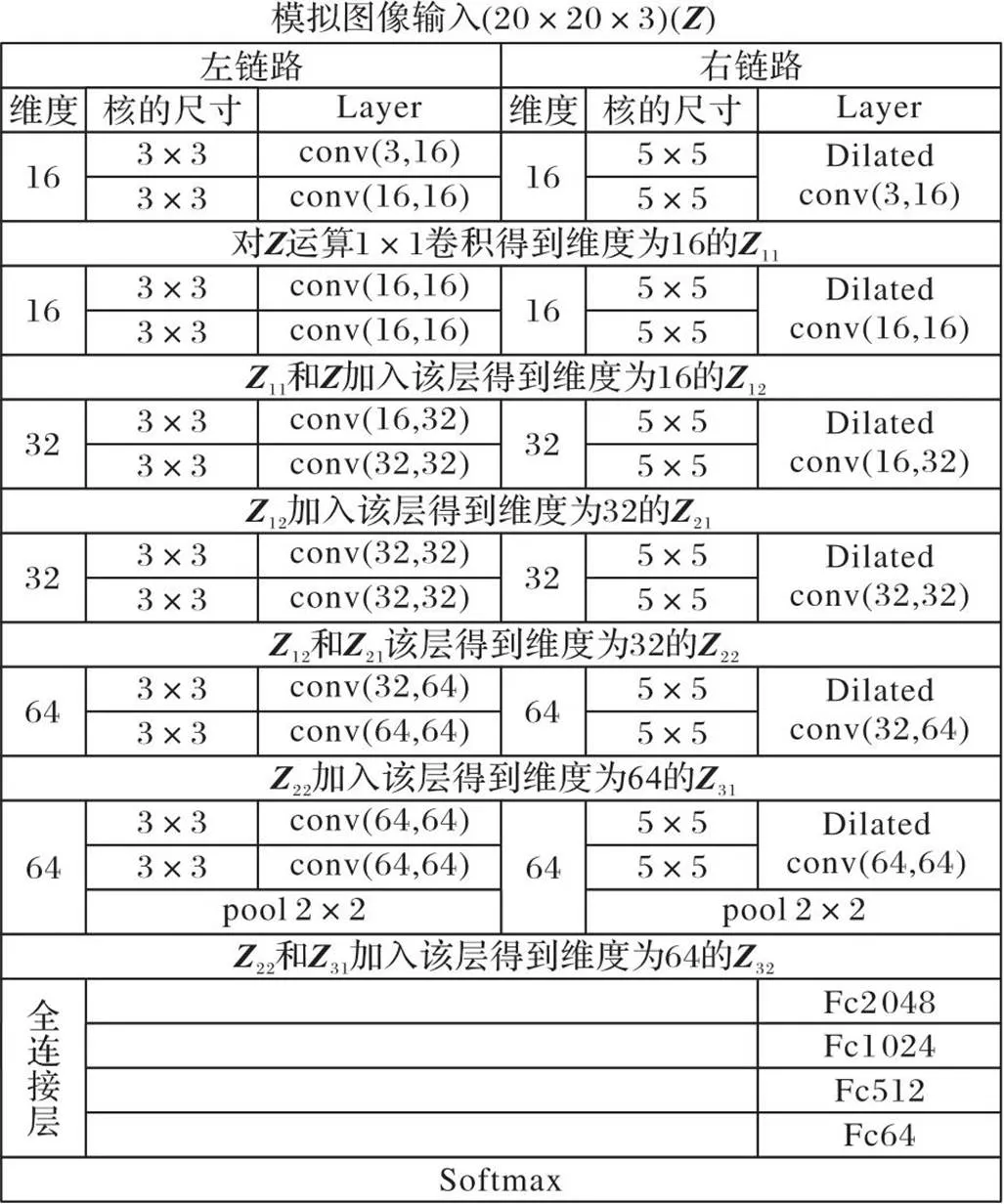
图2 BFNet-V2的整体结构
图2中,11代表小块内第一层卷积得到的特征图,12代表小块内第二层卷积得到的特征图,21代表第一个小块计算后得到的特征图。在最后一个卷积层后接2×2的最大池化层,在不影响分类效果的情况下,缩小特征图像,以减少不必要的参数。引入一组全连接层,由2 048、1 024、512和64这4个不同尺度的全连接层以倒立金字塔的方式搭建,特征向量的尺度以1/2的比例逐次减少,特征按照全连接的方式向下输出。除最后一层外,每经过一个全连接层,特征向量减小一半的尺度,通过逐次降低尺度的全连接层组合方式可以最大限度地避免使用单个或尺度陡然降低的全连接层带来的弊端,同时可以使提取的参数特征更好地逐层向下传输,避免过快降低抽象图像特征维度或直接进行全连接输出导致严重影响分类识别的精度。网络的最后由Softmax激活函数完成分类概率的输出,它的大小等于分类标签数,根据海关数据风险标签分类需求,输出为10类。
1.3 学习率调整策略
虽然Adam[16]在许多任务中快速收敛,但却容易导致算法达到局部极小值。本文的H-Adam与忽略历史动量的Adam不同,H-Adam更新一阶距和二阶距的变量时考虑了历史动量,从而将历史动量信息引入估计的更新。H-Adam在训练过程中累积历史一阶和二阶动量信息均值以更新一阶和二阶动量,并逐渐降低对历史动量的适配程度。H-Adam解决了Adam的泛化性能不佳的问题,允许在凸和非凸设置下收敛,算法1为H-Adam的迭代过程。
算法1 H-Adam。
While 没有达到停止条件do
更新有偏一阶矩估计:
更新有偏二阶矩估计:
End while
H-Adam和Adam之间最显著的区别是Adam的一阶和二阶动量只与前一步的动量有关,而H-Adam的动量与历史动量均存在联系,这意味着过去的动量信息是积累而不是遗忘。由于当参数接近最优点时,参数会变得稀疏和有噪声,H-Adam会逐渐降低一阶和二矩对最新动量的自适应能力;因此,为了保证历史动量的稳定性,本文以历史动量的均值影响当前动量值的更新。H-Adam改变了一阶和二阶矩的更新过程,在每次更新时加入历史的动量信息,变量的更新如式(9)(10)所示:
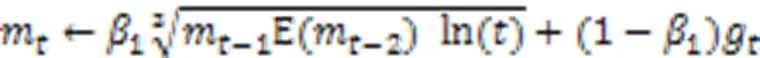
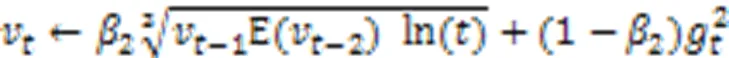
1.3.1有界性
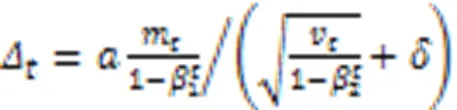
1.3.2梯度适应性
H-Adam中的动量和历史动量的相互作用,会以以下4种情况梯度下降。
由于文献[16]中给出了Adam详细的收敛性证明,在此对H-Adam的收敛性本文无须复述。H-Adam记录了当前动量和历史动量信息,并通过两个动量值和符号的相互作用调整梯度下降方向和步幅,实现目标函数的平滑和平稳过渡,适应高维度空间的复杂目标函数。
2 实验与结果分析
2.1 数据分布与数据集划分
以某省对外贸易活动过程中海关单证数据为研究对象,收集近十年进口冻肉、生鲜、食品、化妆品和红酒等46种商品的报关、舱单和核放单数据132 990条(包含10个风险类别,放行通关或不予处罚的数据),其中02类别数据15 015条数据为随机抽取,构成总的海关数据集。
表1数据集分布
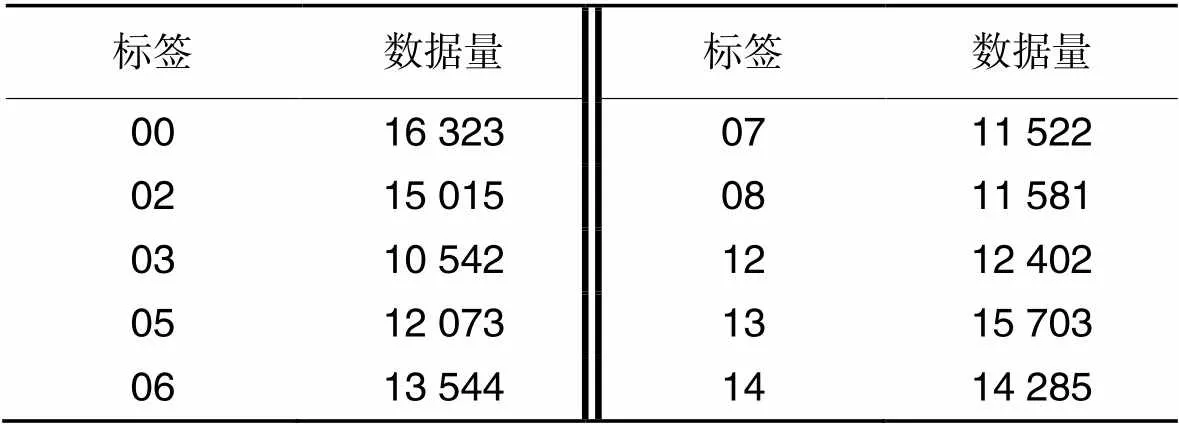
Tab.1 Dataset distribution
2.2 实验数据与仪器
本文实验设备和环境参数:中央处理器(Central Processing Unit,CPU)为AMDRyzen2700X,8核,主频3.70 GHz;随机存取存储器(Random Access Memory,RAM)为32.0 GB;操作系统为Windows 64位;图形处理器(Graphic Processing Unit, GPU)为NVIDIA GTX1080,10 GB GDDR5;运行软件为Python tensorflow 3.7。
2.3 自适应学习率算法对比
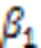
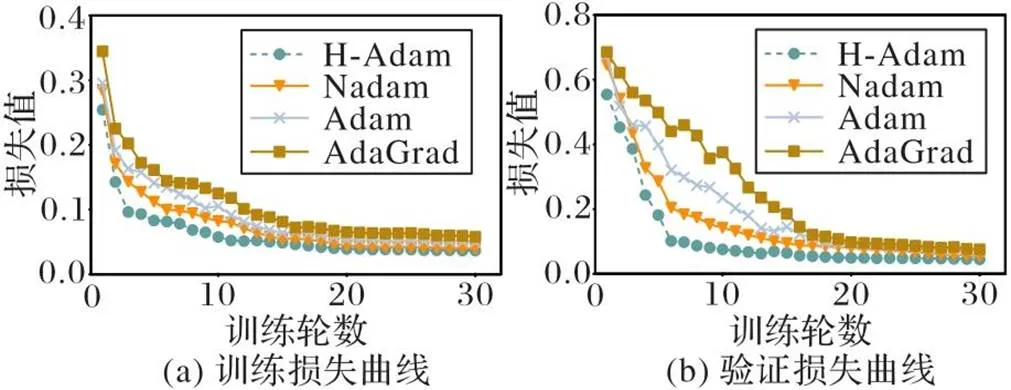
图3 4种自适应学习率调整算法的训练和验证损失曲线
虽然Nadam、H-Adam和Adam的超参数较多,但即使没有进行学习率调优,它们也能获得满意的效果。其中,H-Adam在减少训练和验证损失方面明显优于其他对比算法(包括它的父算法Adam)。
2.4 分类效果对比评价指标
为了实现海关数据的自主分类,并以相同的学习率调整策略训练不同的网络结构分类器。本文计算准确率(ACCuracy rate,ACC)、Kappa系数、绘制受试者工作特征(Receiver Operating Characteristic, ROC)曲线以及它的曲线下面积(Area Under Curve, AUC)和查准率-查全率(Precision Recall,PR)曲线以及它的曲线下面积,该面积等于平均精准率(Average Precision, AP)[22]。
2.5 分类效果对比实验
为了验证BFNet-V2的有效性,本文研究了两种不同的方式训练网络:从头训练(Training from Scratch, TS)[23-24]和迁移学习(Transfer Learning, TL)[25-26]。
2.5.1策略设置和训练参数
学习率调整策略采用H-Adam。训练结束条件采用Keras中的EarlyStopping函数[15]自动调整学习率,当准确率或损失值到达一定值,则停止训练。在算法中定义学习率,并经过一定epoch后,效果不再提升,该学习率可能已经不再适应该结构,因此需要在训练过程中通过H-Adam调整学习率,进而提升网络结构效果。
2.5.2训练方式和停止条件
按照训练网络的设计,将10个分类的训练集和验证集在输入不同网络结构之前进行归一化处理,使图像的像素值在[0,1]区间。在训练神经网络时需要将训练样本从文件夹中源源不断地输入训练数据缓冲区,再将训练样本分批输入网络进行训练,所有结构均采用同样的训练方式:每次从训练数据中选出一批数据,然后对每批数据进行学习,简称小批量(Mini-batch)学习[27],Mini-batch设置为50。
当全部训练数据完成训练后,计算一次训练迭代次数(epoch)。当epoch达到设置的最高次数或者网络误差低于设定值时,网络训练结束,此时保存训练网络结构,输入测试数据,验证完成训练的网络结构性能。
所有网络结构分别在训练集的所有数据样本上训练100次(100 epoches),直到自适应学习率调整算法直接提前结束训练或达到规定epoch后停止训练。损失函数选择交叉熵损失函数[28]。
交叉熵计算方式如式(12)所示:
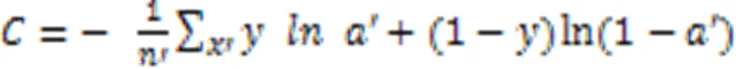
2.6 分类对比实验结果与分析
在TS过程中,删除卷积层之间的池化层,只在全连接层之前添加2×2池化,全连接层不变。在TL过程中,首先以ImageNet数据集[29]为源域对BFNet-V2进行预训练,设置网络停止条件,保存训练好的网络参数,完成BFNet-V2的预训练过程。其次,在海关数据集这个目标域上进行迁移学习,得到训练和测试曲线。其他4种网络结构调用tensorflow[30]的官方预训练模型,池化层、全连接层和学习率都与TS的网络结构保持一致。
2.6.1两种训练方式的BFNet-V2训练曲线
图4和图5是两种训练方式的BFNet-V2损失(Loss)和准确率(ACC)曲线,虽然二者训练曲线差别不大,但TL的ACC曲线明显优于TS,这从一个侧面反映了海关数据模拟图像虽然是一种无规律二维马赛克图像,但它与ImageNet数据集中的现实图像同样存在着某种未知的关联。
2.6.2不同网络迁移学习Loss和ACC曲线
本文将BFNet-V2与Xception[10]、MobileNet-V2[11]、ResNet50[12]和BF-Net[13]这4种网络结构进行对比。
图6和图7分别是5种网络基于两种训练方式的Loss曲线和ACC曲线。从图6(a)和图7(a)可以看出,Xception的损失曲线较平缓,在网络结构初始化时,Xception的训练集准确率接近75%,验证集准确率超过45%,Loss曲线在第5个epoch后已经较好地收敛,在20次左右达到平稳;同时,ACC曲线显示此时训练集的ACC超过90%,验证集的ACC达到89%,验证集的ACC低于ResNet50,与MobileNet-V2相当。
轻量和快速是MobileNet-V2的特点,在网络结构初始化时,网络的训练集准确率接近75%,但是验证集准确率不高,在20%左右,说明网络此时处于过拟合状态;随着迭代次数的增加,网络逐渐学习,随着参数的调整和迭代次数的增加,网络的验证集准确率逐渐提高,从图6(b)和图7(b)可以看出,当网络训练次数达到15时,验证集的准确率趋于平稳,达到80%。训练集和验证集的准确率都达到较高的水平。网络的损失值也出现了相匹配的情况。由于MobileNet-V2轻量级的特点,网络在第22次迭代后达到收敛。
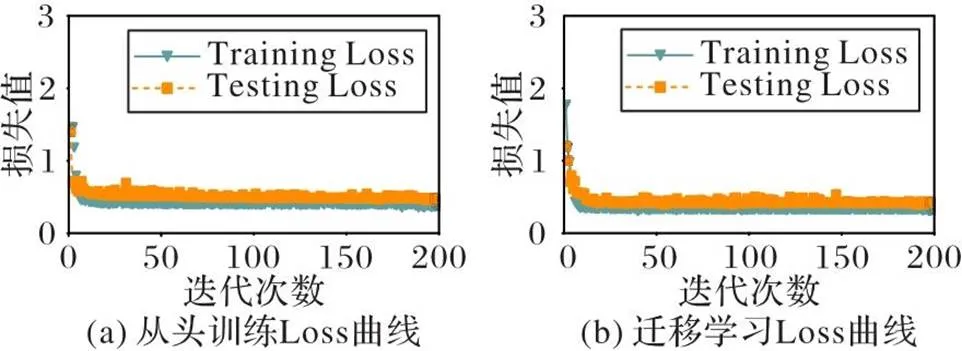
图4 BFNet-V2的Loss曲线(一个epoch)
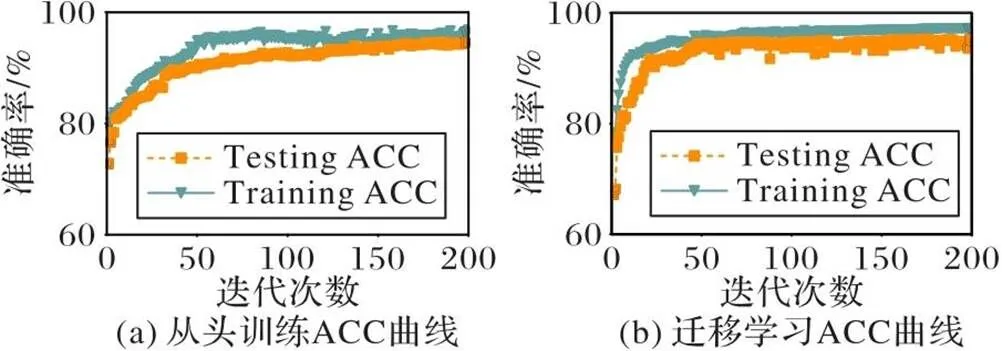
图5 BFNet-V2的ACC曲线(一个epoch)
从图6(c)和图7(c)可以看出,ResNet50训练迭代次数为27时,验证集的准确率达到最高且趋于稳定,当ResNet50训练16个epoch后训练集的准确率超过90%,验证集的准确率也能达到85%,训练误差也是下降到0.5以下,基本达到网络训练的输出结果。
从图6(d)和图7(d)中可以发现,BF-Net经过18次训练网络就收敛并停止训练,ACC超过93%。
从图6(e)和图7(e)可以看出,基于迁移学习的BFNet-V2在全部epoch的Loss曲线和ACC曲线上的表现明显优于其他4种网络,Loss曲线波动较小,在第6个epoch后训练集的ACC已经达到90%以上,且验证集的ACC也达到90%,网络没有出现过拟合现象,收敛快,经过不到20次的epoch就停止了训练,且验证集的ACC已接近94%,体现了BFNet-V2的优异性能。

图6 各种网络基于TL的Loss曲线

图7 各种网络基于TL的ACC曲线
2.6.35种网络的PR曲线和ROC曲线
图8、9是5种网络结构的ROC曲线和PR曲线。纵向比较,不论用TS还是TL方式,BFNet-V2的曲线弧度更大,平滑度较好,且基本能够包裹其他网络结构的曲线,泛化能力较强,可以找到较好的分类样本阈值。其次是BF-Net结构、Xception结构和ResNet50,它们的分类效果在伯仲之间,MobileNet-V2结构的AUC和AP值最低。横向比较,在训练方式方面,所有网络结构的TL方式的验证结构均好于TS,说明TL方式在海关数据集上有效;也说明训练模拟图像数据集每种分类的图像数量中等,TS的方式特征学习能力不如TL,此实验结果与其他图像数据集如ImageNet、COCO(http://mscoco.org/)等的实验趋势也是一致的。
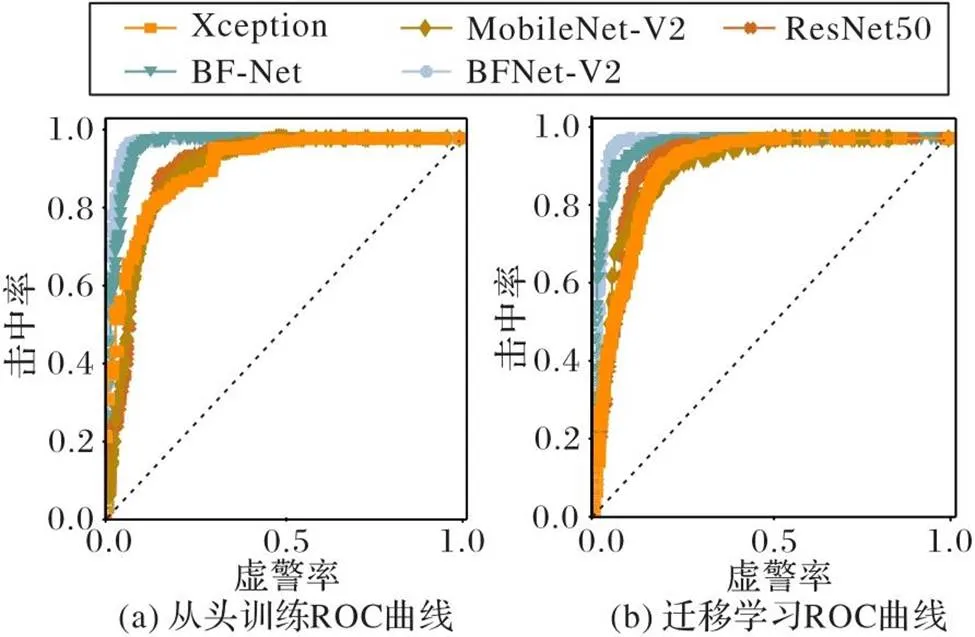
图8 5种网络的ROC曲线
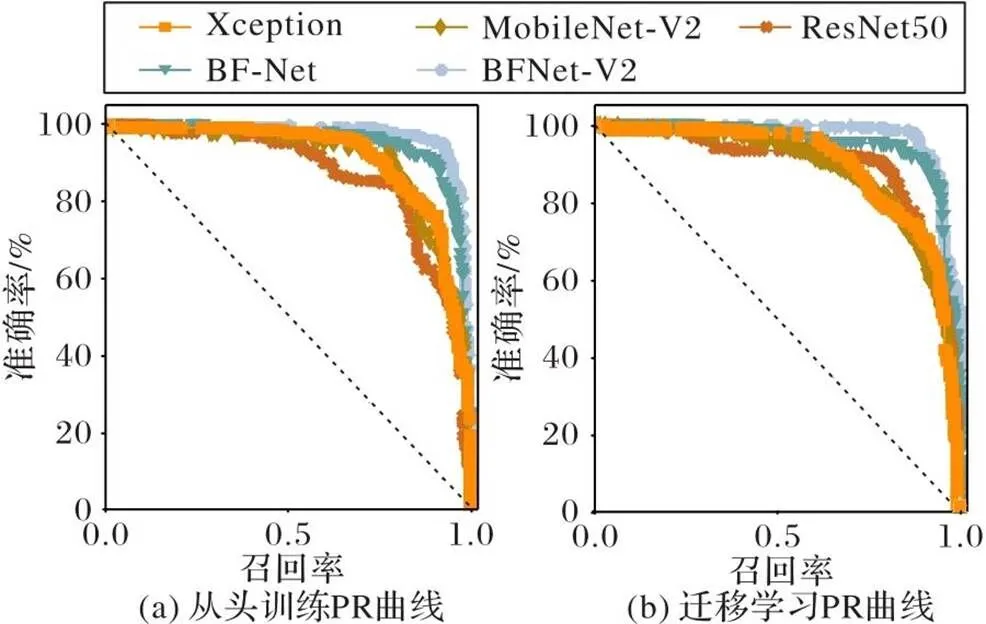
图9 5种网络的PR曲线
由于ROC曲线兼顾正例与负例,所以适用于评估分类器的整体性能。由于真实测试样本不均衡,从图9可以看出,BFNet-V2的虚警率值[0,0.2]的阶段曲线较陡,对应较高的击中率值,曲线接近左上角,说明BFNet-V2在不同标签的正例和负例分类较均衡。由于PR曲线的两个指标都聚焦于正例,能够展示不平衡数据的分类情况。BFNet-V2的准确率[0.8,1]的阶段曲线较陡,对应较高的查全率,曲线接近右上角,说明BFNet-V2在测试不均衡样本数据集的优势。
2.6.45种网络结构实验结果的分类指标
表2列出5种网络结构的验证数据指标的平均值。验证结果表明,从头训练方面,BFNet-V2在4个指标上取得了最好的效果,但参数量多于MobileNet-V2,因此BFNet-V2使用较浅的网络超越了其他深层网络的分类效果,且卷积核的参数量没有显著增加,相较于BF-Net进一步减少。TL方式的训练显示了同样的结果,MobileNet-V2的性能被其他网络结构超越。以5种网络结构的迁移学习分类准确率为例,BFNet-V2相较于Xception、MobileNet-V2、ResNet50和BF-Net分别提高了4.30%、4.34%、4.10%和0.37%。
表2验证数据集指标平均值
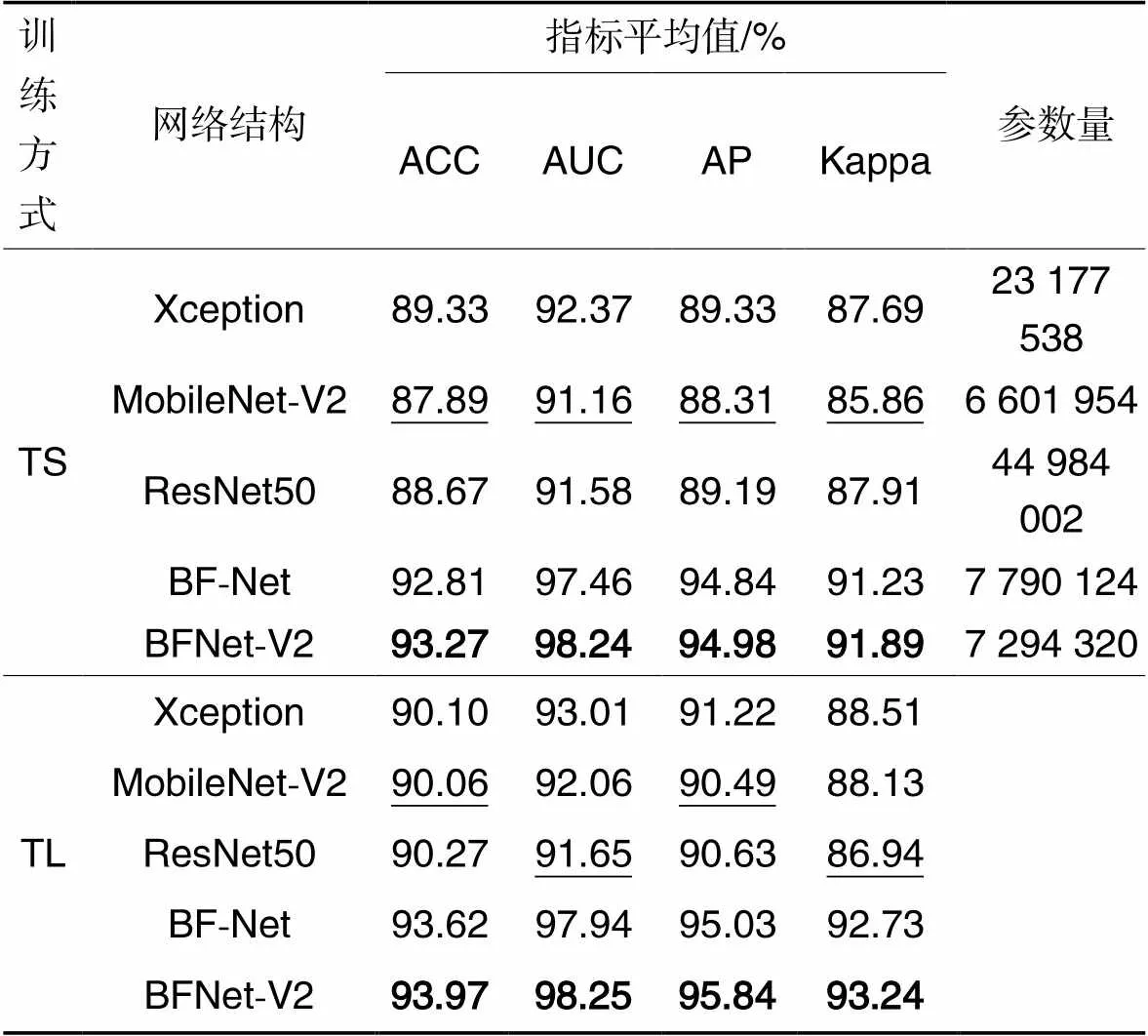
Tab.2 Mean index values on validation dataset
注:由于TL方式冻结卷积层,只训练全连接层,这里没有讨论结构的参数量;加粗的是最大值,下画线为最小值。
表3是对4 504张02标签验证模拟图像的运行结果(单位:s)。BFNet-V2与Xception相比耗时减少了37.83%,与BF-Net相比耗时减少了12.50%,与MobileNet-V2相比耗时增加了15.65%,与ResNet50相比耗时减少了21.33%。分析5种网络结构所需要的训练时间,MobileNet-V2所需时间最短,但结合前面的运行结果(表2),MobileNet-V2的ACC并非最优;ResNet50各项指标表现较均衡;Xception的ACC值处于中等水平,但是运行时间销最大;BF-Net和BFNet-V2的运行时间和网络参数量略高于MobileNet-V2,BFNet-V2在ACC、PR曲线、ROC曲线和Kappa系数等指标方面均取得了较好的结果。根据Kappa系数的定义,另外3种网络结构可以达到82%~89%的Kappa系数指标,按照Kappa系数的评价标准可以定性为几乎完全一致,但BF-Net和BFNet-V2的Kappa系数超过90%,且BFNet-V2结构的Kappa系数大于BF-Net结构,分类结果的一致性检验效果更好。
表3基于迁移学习的网络训练时间对比 单位:s

Tab.3 Comparison of network training time based on transfer learning unit:s
2.6.5海关数据风险分类的两项任务指标
海关数据风险分类任务主要有两方面:一是识别高风险商品,进入查验环节;二是避免将低风险商品识别为高风险商品,进行查验。由于风险标签00和02是放行,属于低风险商品,则需要计算放行标签被预测为查获标签时占所有放行标签数据的比例;风险标签03~14属于查获的类型,对应高风险商品,需要计算标签03~14的商品被预测为00和02时,占所有查获标签的比例。这两个比例均越低越好。显然,由于关系到CIQS,第2个比例更重要。
由表4可知,对于放行误判,BFNet-V2的误判率均为最低,只有极少量数据被误判为查获,其余4种网络结构的误判率基本小于10%。以TL训练方式为例,BFNet-V2的放行误判率相较于Xception、MobileNet-V2、ResNet50和BF-Net分别降低了68.78%、76.21%、72.25%和6.31%。BFNet-V2能够尽可能多地直接过滤低风险商品,提高风险判别速度和工作效率。
对于查获误判,从表4中可以看出,BFNet-V2的误判率接近1%,ResNet50、Xception和MobileNet-V2的误判率较高。以TL训练方式为例,BFNet-V2的查获误判率相较于Xception、MobileNet-V2、ResNet50和BF-Net分别降低了70.09%、57.98%、58.36%和10.70%。BFNet-V2可以迅速标记绝大部分高风险商品,直接将单证转移到人工查验环节,提升口岸风险防控的能力。
表45种网络结构的误判率对比 单位: %
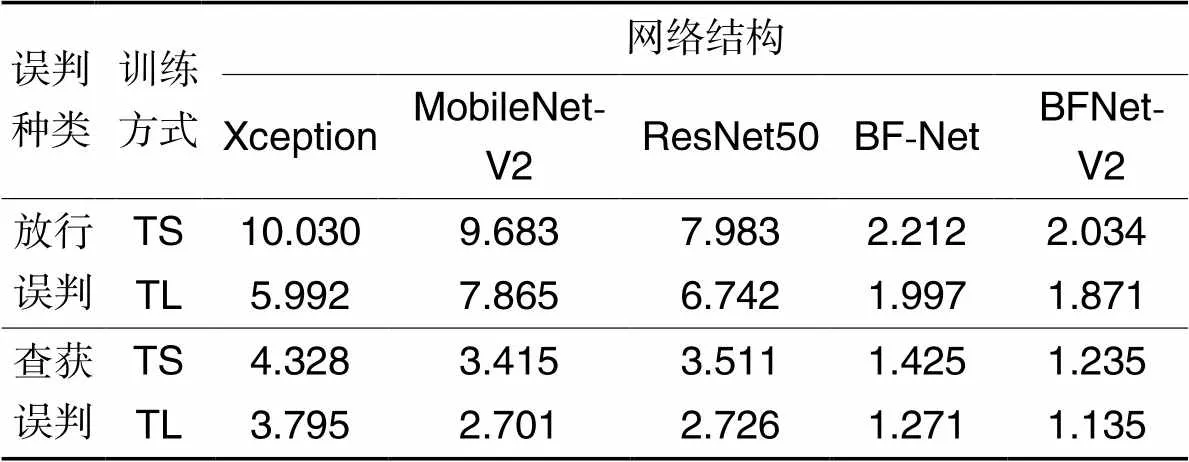
Tab.4 Comparison of misjudgment rate among five network structures unit: %
目标图像存在差异是神经网络结构提取更多差异特征的先决条件。BFNet-V2的双链路不同接收域训练策略能最大限度地提取特征图的组合特征。通过神经网络反馈训练作用于分类输出Softmax,在一定程度上避免了欠拟合;而两个卷积层之间的直接映射、小块与小块之间的直接映射,以及块与块之间的直接映射使得上一层卷积核提取的特征可以直接作用于后面的卷积运算,该策略极大地提高了网络的稳定性,改善了复杂深度神经网络产生的过拟合和梯度消失现象。在使用BFNet-V2参数训练的过程中,在海关数据集上,采用两种训练方式均可以达到较好的海关数据分类效果,基本没有出现过拟合、梯度消失和分类失败的现象,实现了以较少的隐层达到较高的分类指标值。
2.7 不同方法的对比实验
将本文方法(BFNet-V2+H-Adam方法)与8种数据分类方法进行对比,涵盖表格数据分类领域最优和经典的方法,评估指标为准确率。8种对照方法为:
1)随机森林(Random Forest,RF)[3]。通过Pythonscikit-learn包中的RandomForestClassifier建立初始随机森林方法,超参数树数为300时,树的深度设置为15,直接对表格数据分类。
2)支持向量机(Support Vector Machine, SVM)[31]。采用Libsvm分类器。
3)XGBoost[6]。改进的梯度提升算法,求解损失函数极值时使用牛顿法,将损失函数泰勒展开至二阶;另外在损失函数中加入正则化项。
4)一维卷积神经网络(One-Dimensional Convolutional Neural Network,1D-CNN)[32]。表格数据实现统一编码后,直接输入1D-CNN进行分类,用一维卷积核在表格数据字段上滑动以提取数据特征,对表格数据进行分类。
5)DANET[7]。是一个深度神经网络家族,用于表格数据分类和回归。在DANET中,引入一个特殊的快捷路径从原始表格特征中获取信息,帮助不同级别的特征交互。
6)TAC[8]。使用表格数据创建应用于固定基础图像的图像过滤器,运用ResNet结构实现对表格数据的分类。
7)SuperTML[9]。对预训练的CNN在非结构化数据上进行二维嵌入和优化,将表格数据的机器学习问题转化为图像分类问题,以迁移学习表格形式的结构化数据实现表格数据的分类。
8)BF-Net+AdaGrad方法[13]。该方法实现表格数据到图像数据,再到神经网络识别训练的过程。
实验数据集为Adult data set[33]、LETOR 4.0 Datasets[34]和Cardiovascular Disease5[35]。
表5展示不同方法在3个不同数据集上的实验结果。各方法在不同数据上呈现出相似的结果,以LETOR 4.0 Datasets上的数据为例进行分析。
首先,RF方法的效果基本低于其他8种方法。一方面,与其他所有方法相比,RF方法较难适应不同性质、不同场景的表格数据字段;另一方面,且RF方法本质是树形结构,对于小数据或者低维数据,分类效果并不理想,对于高维数据,也难以与深度学习方法相比,RF通常需要在不同的参数和随机种子之间反复尝试以提高分类精度。两种基于特征工程的机器学习方法(SVM和XGBoost)显著优于RF方法,但受限于有限的特征泛化能力,容易收敛于更优的局部最优解。因此,这两种方法的准确率低于1D-CNN。1D-CNN明显低于DANET、TAC和SuperTML这3种表格数据转换的深度方法,1D-CNN效果弱于2D-CNN的原因是2D-CNN不仅能够提取转换图像中相邻字段的特征,同时能够提取不同图像位置的特征,因此无法获取更丰富的语义信息。本文方法在表格数据固有噪声的情况下充分提取了无法认知的表格数据语义信息,并进一步学习了不同字段信息语义之间的关联,在3个数据集上的准确率提升均在1.33%以上,表明该方法的优越性和良好的泛化能力。
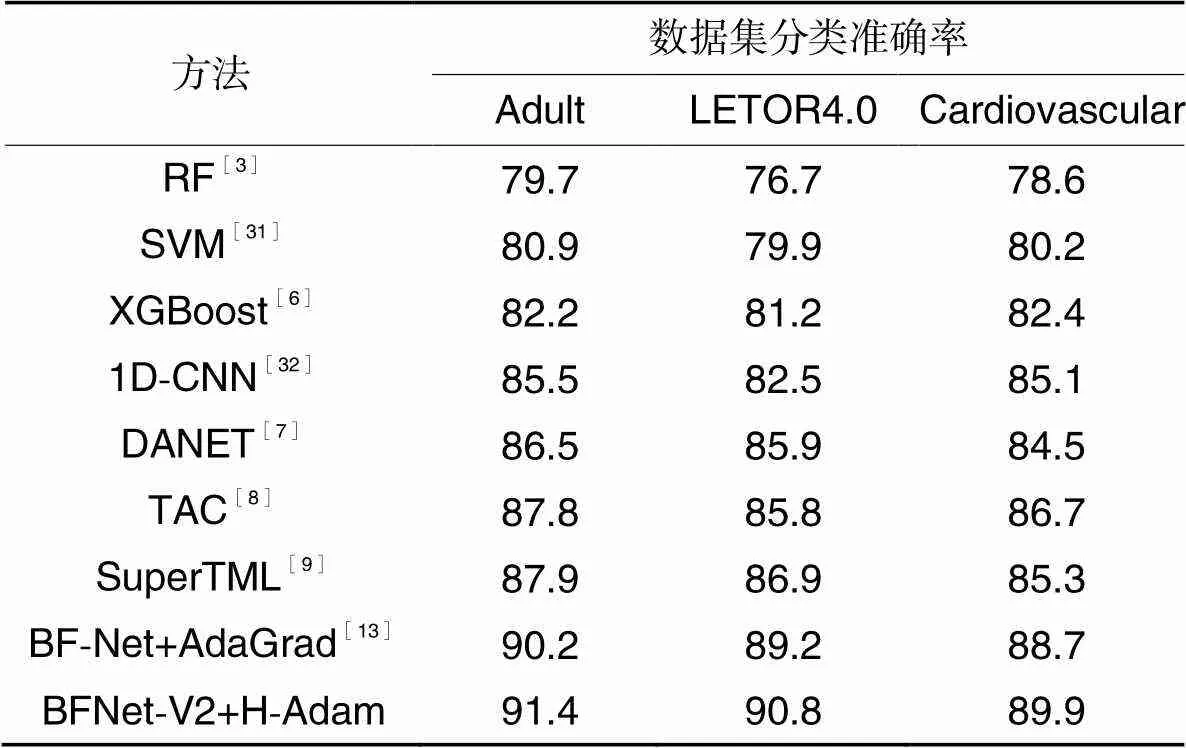
表5 不同方法的准确率对比 单位: %
本文方法(BFNet-V2+H-Adam)在网络结构上具有优势,运用空洞卷积,并优化自适应学习率调整过程,模型容易收敛于更优的局部最小值。在包含海关数据集的4个不同数据集上都取得了最优分类性能。
3 结语
本文针对海关传统风险分析方法存在的问题,提出一种智能化海关风险布控方法。运用FC算法将表格类型的海关数据转化为模拟图像数据。运用提出的BFNet-V2+H-Adam方法得到不同数据的风险分类标签。BFNet-V2包含双链路两种卷积核提取特征、块状和不同的短路径映射,具有轻量级、高效等良好的网络特性;同时,以H-Adam作为优化器,加快算法收敛,避免算法收敛至局部最小值。在同等设备环境和参数条件下,在与CNN和自适应学习率调整算法的对比实验中取得了较好的实验指标效果。与包含浅层和深度学习方法的8种分类方法进行比较,验证了基于改进蝶形反馈型神经网络的海关风险布控方法在海关数据分类上的优势。该方法能够有效简化海关关员的风险判别过程,有效保障我国CIQS。下一步可以将该方法推广至更多的一线海关查验现场,切实提高海关查获率,减少关员查验工作量。
[1] ALITA D, PUTRA A D, DARWIS D. Analysis of classic assumption test and multiple linear regression coefficient test for employee structural office recommendation[J]. IJCCS (Indonesian Journal of Computing and Cybernetics Systems), 2021, 15(3): 295-306.
[2] CHARBUTY B, ABDULAZEEZ A. Classification based on decision tree algorithm for machine learning[J]. Journal of Applied Science and Technology Trends, 2021, 2(1): 20-28.
[3] HUSSEIN A S, KHAIRY R S, NAJEEB S M M, et al. Credit card fraud detection using fuzzy rough nearest neighbor and sequential minimal optimization with logistic regression[J]. International Journal of Interactive Mobile Technologies, 2021, 15(5): 24-42.
[4] ANTONIADIS A, LAMBERT-LACROIX S, POGGI J-M. Random forests for global sensitivity analysis: a selective review[J]. Reliability Engineering & System Safety, 2021, 206: 107312.
[5] LIAW A, WIENER M. Classification and regression by random forest[J]. R News, 2002,2(3): 18-22.
[6] 申明尧,韩萌,杜诗语,等. 融合XGBoost和Multi-GRU的数据中心服务器能耗优化算法[J]. 计算机应用, 2022, 42(1): 198-208.(SHEN M Y, HAN M, DU S Y, et al. Data center server energy consumption optimization algorithm combining XGBoost and Multi-GRU [J]. Journal of Computer Applications, 2022, 42(1): 198-208.)
[7] CHEN J, LIAO K, WANY, et al. DANETs: deep abstract networks for tabular data classification and regression[C]// Proceedings of the 36th AAAI Conference on Artificial Intelligence. Palo Alto:AAAI Press, 2022: 3930-3938.
[8] BUTUROVIĆ L, MILJKOVIC D. A novel method for classification of tabular data using convolutional neural networks [EB/OL]. (2020-03-08)[2023-01-12]. https://www.biorxiv.org/content/10.1101/2020.05.02.074203v1.full.pdf.
[9] SUN B, YANG L, ZHANG W, et al. SuperTML: two-dimensional word embedding for the precognition on structured tabular data [C]// Proceedings of the 32th IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops. Piscataway: IEEE, 2019: 2973-2981.
[10] CHOLLET F. Xception: deep learning with depth wise separable convolutions[C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2017: 1800-1807.
[11] SANDLER M, HOWARD A, ZHU M, et al. MobileNetV2: inverted residuals and linear bottlenecks [C]// Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2018: 4510-4520.
[12] WANG G, YU H, SUI Y. Research on maize disease recognition method based on improved ResNet50[J]. Mobile Information Systems, 2021, 2021: 9110866.1-9110866.6.
[13] 王正刚,刘伟,金瑾.一种海关数据风控类型识别方法,海关智能化风险布控方法,装置,计算机设备及存储介质: CN202110232188.2[P]. 2022-09-16.(WANG Z G, LIU W, JIN J. A customs data risk control type identification method, customs intelligent risk control method, device, computer equipment and storage media: CN202110232188.2 [P]. 2022-09-16.)
[14] WEI Y, XIAO H, SHI H, et al. Revisiting dilated convolution: a simple approach for weakly-and semi-supervised semantic segmentation [C]// Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2018: 7268-7277.
[15] DAUBECHIES I, DeVORE R, FOUCART S, et al. Nonlinear approximation and (deep) ReLU networks[J]. Constructive Approximation: An International Journal for Approximations and Expansions, 2022, 55(1): 127-172.
[16] JAIS I K M, ISMAILI A R, NISA S Q. Adam optimization algorithm for wide and deep neural network[J]. Knowledge Engineering and Data Science, 2019, 2(1): 41-46.
[17] HAWKINS D M, YOUNG S S, RUSINKO A Ⅲ. Analysis of a large structure-activity data set using recursive partitioning[J]. Quantitative Structure-Activity Relationships, 1997, 16(4):296-302.
[18] WARD R, WU X, BOTTOU L. AdaGrad stepsizes: sharp convergence over nonconvex landscapes, from any initialization[J]. Journal of Machine Learning Research, 2020, 21: 1-30.
[19] WEN Z, YANG G, CAI Q. An improved calibration method for the IMU biases utilizing KF-based AdaGrad algorithm[J]. Sensors, 2021, 21(15):5055.
[20] LI L, XU W, YU H. Character-level neural network model based on Nadam optimization and its application in clinical concept extraction [J]. Neurocomputing, 2020, 414: 182-190.
[21] ZHU Z, HOU Z. Research and application of rectified-nadam optimization algorithm in data classification [J]. American Journal of Computer Science and Technology, 2021, 4(4): 106-110.
[22] GU J, WANG Z, KUEN J, et al. Recent advances in convolutional neural networks [J]. Pattern Recognition, 2018,77: 354-377.
[23] YU S, CHENG Y, SU S, et al. Stratified pooling based deep convolutional neural networks for human action recognition[J]. Multimedia Tools and Applications, 2017, 76: 13367-13382.
[24] KIM Y, PANDA P. Revisiting batch normalization for training low-latency deep spiking neural networks from scratch [J]. Frontiers in Neuroscience, 2021,15: 101-113.
[25] KARRAS T, AITTALA M, HELLSTEN J, et al. Training generative adversarial networks with limited data [J]. Advances in Neural Information Processing Systems, 2020, 33: 12104-12114.
[26] SHALLU, MEHRA R. Breast cancer histology images classification: training from scratch or transfer learning [J]. ICT Express, 2018, 4(4): 247-254.
[27] DOKUZ Y, TUFEKCI Z. Mini-batch sample selection strategies for deep learning based speech recognition[J]. Applied Acoustics, 2021, 171: 107573.
[28] ZHANG Z, SABUNCU M. Generalized cross entropy loss for training deep neural networks with noisy labels [EB/OL]. (2018-07-15)[2022-12-25]. https://arxiv.org/pdf/1805.07836.pdf.
[29] DENG J, DONG W, SOCHER R, et al. ImageNet: a largescale hierarchical image database[C]// Proceedings of the 22th IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2009: 248-255.
[30] PANG B, NIJKAMP E, WU Y N. Deep learning with TensorFlow: a review [J]. Journal of Educational and Behavioral Statistics, 2020, 45(2): 227-248.
[31] YANG J, SUN L, XING W, et al. Hyperspectral prediction of sugarbeet seed germination based on Gauss kernel SVM[J]. Spectrochimica Acta Part A: Molecular and Biomolecular Spectroscopy, 2021, 253: 119585.
[32] OZCANLI A K, BAYSAL M. Islanding detection in microgrid using deep learning based on 1D-CNN and CNN-LSTM networks[J]. Sustainable Energy, Grids and Networks, 2022, 32: 100839.
[33] RONNY K, BARRY B. Adult data set [DB/OL]. (2003-06-15)[2022-12-14] . https://archive.ics.uci.edu/ml/machine-learning-databases/adult/adult.data.
[34] PENG J, MACDONALD C, OUNIS I. Learning to select a ranking function [C]// Proceedings of the 32th European Conference on IR Research. Berlin: Springer, 2010: 114-126.
[35] ULIANOVA S. Cardiovascular disease dataset[DB/OL]. (2005-03-08)[2022-12-14]. https://www.kaggle.com/datasets/sulianova/cardiovascular-disease-dataset.
Customs risk control method based on improved butterfly feedback neural network
WANG Zhenggang1,2,3*, LIU Zhong1,2, JIN Jin4, LIU Wei3
(1,,610213,;2,,101408,;3,’,610041,;4,,610103,)
Aiming at the problems of low efficiency, low accuracy, excessive occupancy of human resources and intelligent classification algorithm miniaturization deployment requirements in China Customs risk control methods at this stage, a customs risk control method based on an improved Butterfly Feedback neural Network Version 2 (BFNet-V2) was proposed. Firstly, the Filling in Code (FC) algorithm was used to realize the semantic replacement of the customs tabular data to the analog image. Then, the analog image data was trained by using the BFNet-V2. The regular neural network structure was composed of left and right links, different convolution kernels and blocks, and small block design, and the residual short path was added to improve the overfitting and gradient disappearance. Finally, a Historical momentum Adaptive moment estimation algorithm (H-Adam) was proposed to optimize the gradient descent process and achieve a better adaptive learning rate adjustment, and classify customs data. Xception (eXtreme inception), Mobile Network (MobileNet), Residual Network (ResNet), and Butterfly Feedback neural Network (BF-Net) were selected as the baseline network structures for comparison. The Receiver Operating Characteristic curve (ROC) and the Precision-Recall curve (PR) of the BFNet-V2 contain the curves of the baseline network structures. Taking Transfer Learning (TL) as an example, compared with the four baseline network structures, the classification accuracy of BFNet-V2 increases by 4.30%,4.34%,4.10% and 0.37% respectively. In the process of classifying real-label data, the misjudgment rate of BFNet-V2 reduces by 70.09%,57.98%,58.36% and 10.70%, respectively. The proposed method was compared with eight classification methods including shallow and deep learning methods, and the accuracies on three datasets increase by more than 1.33%. The proposed method can realize automatic classification of tabular data and improve the efficiency and accuracy of customs risk control.
Convolutional Neural Network (CNN); analog image; adaptive moment estimation; customs; risk control
This work is partially supported by Innovative Talents Support Program of Sichuan Science and Technology Department (2020JDR0330).
WANG Zhenggang, born in 1984, Ph. D. candidate, senior engineer. His research interests include computer software and theory, artificial intelligence.
LIU Zhong, born in 1968, Ph. D., research fellow. His research interests include computer software and theory, machine certification.
JIN Jin,born in 1988, Ph. D., lecturer. Her research interests include artificial intelligence, parallel computing.
LIU Wei, born in 1968, M. S., professor of engineering. Her research interests include database, data mining.
TP391.1
A
1001-9081(2023)12-3955-10
10.11772/j.issn.1001-9081.2022121873
2022⁃12⁃21;
2023⁃03⁃01;
2023⁃03⁃08。
四川省科技厅创新人才支持计划项目(2020JDR0330)。
王正刚(1984—),男,四川成都人,高级工程师,博士研究生,主要研究方向:计算机软件与理论、人工智能;刘忠(1968—),男,四川乐山人,研究员,博士生导师,博士,主要研究方向:计算机软件与理论、机器证明;金瑾(1988—),女,四川成都人,讲师,博士,CCF会员,主要研究方向:人工智能、并行计算;刘伟(1968—),女,四川成都人,正高级工程师,硕士,主要研究方向:数据库、数据挖掘。
猜你喜欢
现代临床医学(2022年1期)2022-02-12 02:04:26
艺术品鉴(2020年7期)2020-09-11 08:05:26
文化创新比较研究(2020年14期)2020-01-02 19:25:56
文化创新比较研究(2020年10期)2020-01-02 02:10:07
文化创新比较研究(2020年13期)2020-01-01 06:17:02
中国外汇(2019年19期)2019-11-26 00:57:34
中国外汇(2019年20期)2019-11-25 09:54:54
广州文博(2016年0期)2016-02-27 12:48:43
北京信息科技大学学报(自然科学版)(2016年6期)2016-02-27 06:31:53
管理现代化(2016年3期)2016-02-06 02:04:41
