
基于不确定性学习的文本无关的说话人确认方法
2024-01-09 04:00:14张玉莲姚姗姗王超畅江
计算机应用 2023年12期
张玉莲,姚姗姗,王超,畅江
基于不确定性学习的文本无关的说话人确认方法
张玉莲,姚姗姗*,王超,畅江
(山西大学 大数据科学与产业研究院,太原 030006)(∗通信作者电子邮箱 yaoshanshan@sxu.edu.cn)
说话人确认任务旨在判断注册语音与测试语音是否属于同一说话人。针对说话人识别系统提取的声纹特征通常会受到与身份信息无关的因素干扰进而导致系统的准确性严重下降的问题,提出一种基于不确定性学习(UL)的文本无关的说话人确认(TISV)方法。首先,在说话人主干网络中引入不确定性同时学习声纹特征(均值)和话语数据的不确定性(方差),以建模语音数据集中的不确定性;其次,通过重采样技巧得到特征的分布表示;最后,在说话人分类损失中引入KL散度正则化约束噪声的分布,从而解决计算分类损失过程中的退化问题。实验结果表明,当训练集为VoxCeleb1和VoxCeleb2开发集时,与基于确定性方法的Thin ResNet34模型相比,所提方法的模型在VoxCeleb1-O测试集上的等错误率(EER)分别降低了9.9%和10.4%,最小检测代价函数(minDCF)分别降低了10.9%和4.5%。可见,所提方法在有噪声、无约束场景下的准确度有所提高。
说话人确认;数据不确定性;分布嵌入;AAM-softmax;KL散度
0 引言
人类具有通过说话声音判别说话人的能力。为了使计算机获得这种能力,基于语音的认证技术应运而生,该技术被称为自动说话人识别(Automatic Speaker Recognition,ASR)。ASR通过分析从说话人声音中提取的语音信号和特征识别说话人的身份,由于它获取语音成本低、用户接受程度高、适合远程身份认证和不涉及用户隐私等优点,近年来备受关注,已快速发展并广泛应用于公安电信反欺诈、刑事调查和移动支付等领域。
说话人确认是说话人识别的任务之一,用于判断给定的两段语音是否属于同一个人。根据应用场景,又可分为文本相关的说话人确认(Text-Dependent Speaker Verification,TDSV)和文本无关的说话人确认(Text-Independent Speaker Verification,TISV)。文本无关指说话人识别系统对说话的内容无任何要求,在训练和识别阶段说话人只需要随意地录制达到一定长度的语音即可;而文本相关指说话人识别系统要求用户必须按照事先指定的文本内容进行发音。由于TISV对语音内容没有施加任何限制,更加方便灵活,具有更好的推广性和适应性,但也比TDSV更具挑战性,因此本文聚焦TISV的研究。
基于深度学习的体系结构可以从大型标记数据集同时学习特征表示和决策框架,不需要再为任何特定的问题手工制作特征。大规模数据集(如用于图像分类的ImageNet[1]、用于人脸识别的LFW(Labeled Faces in the Wild)[2]和用于说话人识别的VoxCeleb[3])的可用性促进了深度学习的进展。作为智能语音领域的热点研究方向,近年来,基于深度神经网络(Deep Neural Network, DNN)的TISV技术在可控场景下已取得了卓越的性能;然而,数据驱动方法无法定义模型在训练过程中学习的信息——是数据集中存在的有用信息,还是不希望被学习的偏差。在实际应用场景中,由于外在和内在的变化(外在的变化包括背景聊天、音乐、笑声、混响、频道和麦克风效果等;内在的变化是说话者本身固有的因素,如年龄、口音、情感、语调和说话方式等),TISV系统性能严重下降。为此,大量的研究者提出了不同的网络架构、池化方式、损失函数等,以提升说话人确认系统的鲁棒性和泛化性。
与这些工作不同,本文从数据的不确定性角度出发,提出一种基于不确定性学习(Uncertainty Learning, UL)的文本无关的说话人确认方法。
本文的主要工作内容如下:
1)不同于目前常用的说话人确认模型将说话人特征表示为潜在空间中的点估计,为了应对真实环境存在的噪声等干扰,本文方法为说话人特征提供了分布估计的方式。分布的均值代表最可能的说话人特征,即理想的声纹特征;而分布的方差是对不确定的噪声进行估计,代表声纹特征受说话人无关信息干扰的程度。
2)本文方法学习的分布表示可以直接用于各种分类损失和传统的相似性度量,并使用KL(Kullback-Leibler)散度[4]正则化约束噪声的分布,解决计算分类损失时的退化问题。
实验结果表明,与现有的确定性模型相比,本文方法提高了说话人确认系统的性能。这一改进在有噪声、无约束的场景下更显著,表明具有数据不确定性学习的模型更加适用于真实的复杂环境和实际场景。
1 相关工作
1.1 文本无关的说话人确认
1.1.1传统方法
1.1.2深度学习方法
基于DNN的说话人嵌入提取系统通常由3个部分组成:帧级特征处理、话语(说话人)级特征处理和训练损失。帧级特征处理提取局部短跨度的声学特征,可以通过时延神经网络(Time-Delay Neural Network,TDNN)或卷积神经网络(Convolutional Neural Network, CNN)完成;话语级特征处理基于帧级特征形成说话人的表示,即用池化层收集帧级信息以形成语句级别的特征表示,例如统计池[7]、最大池化[8]、注意力统计池[9]和多头注意力统计池[10]等,通过使用统计池、自注意力和可学习字典编码(Learnable Dictionary Encoding, LDE)[11]等方法,神经网络能从话语中提取更有意义的低维向量;常用的训练损失有交叉熵损失和三元损失,基于交叉熵损失的方法[6]侧重减少训练数据中所有说话者的混淆,基于三元损失的方法[12]聚焦增大相似说话人之间的差距。此外,为了进一步增强说话人嵌入的判别力,一些更复杂有效的网络架构和损失函数[13-19]被提出。
1.2 不确定性学习
深度学习算法可以将高维数据映射到低维向量,得到特征表示;然而,在诸如自动驾驶、人脸识别等应用中,深度学习模型的结果并非总是可信的。因此,算法如果能够判断模型给出的结果是否可信,即对模型的结果给出一个置信度,那么系统就可以根据这个置信度作出更好的决策,并有可能避免灾难。如图1所示是一个判别数据对的相似度的系统,判别系统给出的相似度结果都是90%,由于系统对给出的判断具有一定程度的“不确定性”,一个置信度为10%,另一个为90%,人们需要类似置信度分数这类的“不确定性”指标辅助以作出更好的决策。
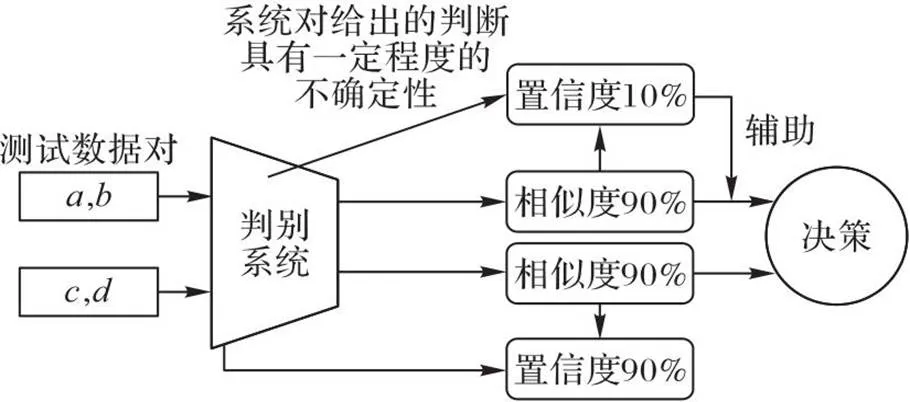
图1 不确定性示意图
长期以来,为了帮助解决可靠性评估和基于风险的决策问题,不确定性的性质和处理方法已被广泛研究。近年来,深度学习中的不确定性研究也备受关注。针对深度不确定性学习,不确定性可以分为在DNN中捕获参数噪声的模型不确定性和测量给定训练数据中固有噪声的数据不确定性。目前许多计算机视觉任务,如语义分割[20-21]、目标检测[22]、行人再识别[23]和人脸识别[24-25]都将深度不确定性学习引入中枢神经网络,提高模型的鲁棒性和可解释性。
本文将不确定性学习引入说话人确认任务的中枢神经网络。本文主要关注数据的不确定性,通过使网络模型同时学习声纹特征(均值)与不确定的噪声(方差),以实现同一说话人的语句提取的声纹特征距离更近,不同说话人的声纹特征距离更远。
2 本文方法
2.1 确定性的说话人识别
经典的确定性的说话人确认模型的网络框架如图2所示。在训练阶段,训练一个闭集的分类模型,分类头的维数等于训练数据集中的说话人数,使用残差网络(Residual Network, ResNet)[26]提取帧级特征,再使用自注意力池(Self-Attentive Pooling, SAP)[27]将帧级特征聚合成话语级特征,最后计算采用了非线性softmax的分类头与真实标签的交叉熵损失,图2中采用的损失函数是AAM-softmax(Additive Angular Margin-softmax)[28]。训练完成后,去除分类头,将模型作为说话人特征的提取器,提取话语对的说话人特征,然后进行相似度打分。

图2 确定性的说话人确认模型
2.2 基于不确定性学习的说话人识别
2.2.1语音数据集中的不确定性
2.2.2分布表示
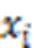
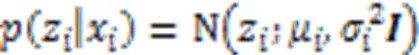
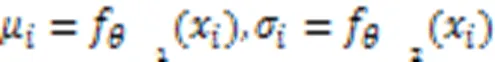

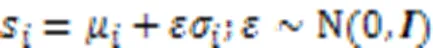
2.2.3训练损失

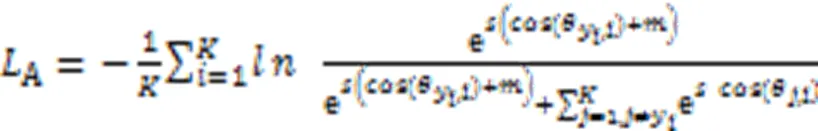
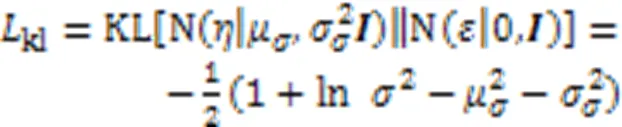
2.2.4DNN实现
整个声纹不确定性模型的框架如图3所示。
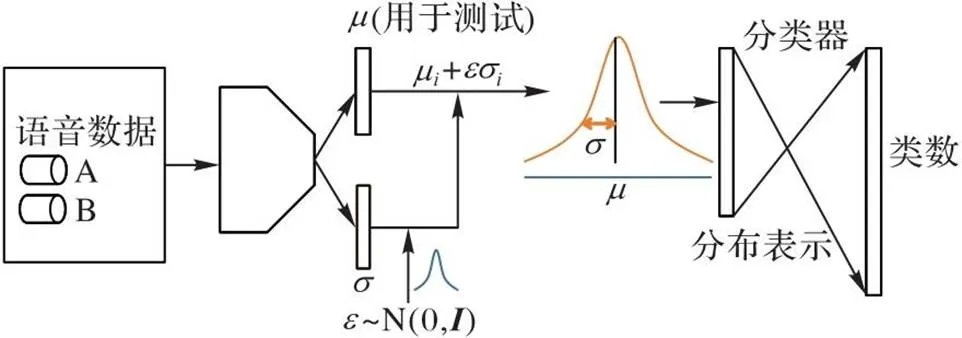
图3 基于UL的TISV方法的模型架构
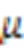
3 实验与结果分析
3.1 数据集及评价指标
3.1.1数据集
本文使用目前主流的VoxCeleb1和VoxCeleb2数据集[31],VoxCeleb1和VoxCeleb2是没有重复交集的两个说话人识别数据集,它们均来自YouTube网站中的视频。VoxCeleb1包含1 251位名人的10多万句话语,VoxCeleb2包含超过6 000位名人的100多万句话语。这两个数据集的性别比例都较均衡(VoxCeleb1包含55%男性,VoxCeleb2包含61%男性)。数据集中的演讲者跨越了不同的种族、口音、职业和年龄,并且所有话语都受现实世界的噪声干扰,包括背景聊天、笑声、重叠语音和房间声学等。
本文包含两组实验:一组使用VoxCeleb1开发集作为训练集,包含除测试集以外的1 211位说话人的21 819条语音,采用VoxCeleb1-O作为测试集;另一组使用VoxCeleb2开发集作为训练集,包含除测试集以外的5 994位说话人的1 092 009条语音,采用VoxCeleb1-O、VoxCeleb1-E和VoxCeleb1-H这3个数据集作为测试集。以下对3个测试集进行介绍:
1)VoxCeleb1-O:包含37 720组采样自VoxCeleb1中的40位说话人的测试对,其中18 860组测试对为真。
2)VoxCeleb1-E:是VoxCeleb1-O的扩展,包含采样自VoxCeleb1的1 251位说话人的581 480组测试对。
3)VoxCeleb1-H:包含采样自VoxCeleb1的1 251位说话人的552 536个测试对。因为每组测试对中说话人的国家和性别都相同,所以更难。
数据增强可以增加训练数据的数量和多样性,有效减少过拟合,提升模型的性能,本文在语音处理中采用了两种流行的增强方法——加性噪声和房间脉冲响应(Room Impluse Response, RIR)模拟。加性噪声使用来自MUSAN语料库的语音片段[32];RIR从文献[33]中发布的中小房间的模拟滤波器进行采样得到。
3.1.2评价指标
本文使用了两个评价指标:
1)等错误率(Equal Error Rate, EER)[34]。是错误接受率和错误拒绝率相等时的阈值,能够衡量说话人确认系统的性能,EER越小,说明模型性能越好。本文将EER作为主要评价指标。
2)最小检测代价函数(minimum Detection Cost Function,minDCF)[34]。旨在系统对错误接受率(False Accept Rate, FAR)和错误拒绝率(False Reject Rate, FRR)两种错误判别设定不同的权重,minDCF越小越好。minDCF计算公式如式(6)所示:
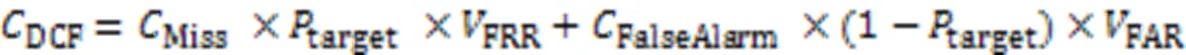
3.2 基线网络架构及本文的网络架构
本文以确定性模型为基线,采用残差网络[35-36]作为帧级特征提取器,使用Thin ResNet34提取帧级特征。Thin ResNet34与原始的ResNet34相同,有34层,但在每个残差块中只使用1/2的通道以减少计算成本。SAP作为池化层,将帧级特征聚合为话语级表示,通过自动计算每一帧的重要性选择重要的帧级特征,利用注意力机制将更多的注意力集中到为话语级说话人识别提供更多信息的帧。在池化层之后,引入一个维度为256的全连接层,作为256维的说话人嵌入提取层。最后,设置一个维数为训练集说话人数的分类头,使用AAM-softmax分类损失,即式(4)。
表1基线Thin ResNet34和本文方法的网络架构
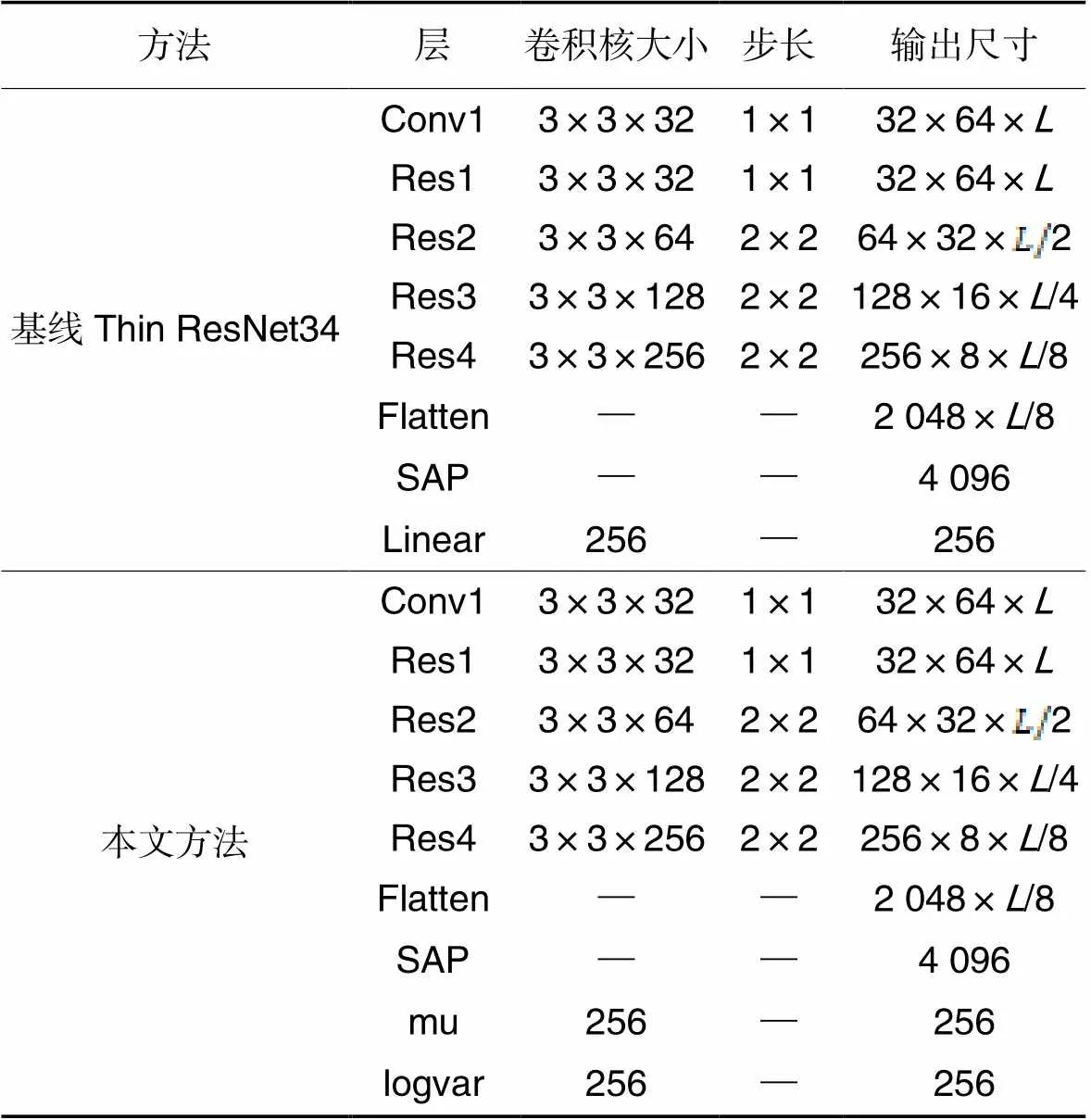
Tab.1 Network architectures of baseline Thin ResNet34 and proposed method
注:为输入序列的长度。
3.3 模型输入及训练策略
本文实验在Linux下的PyTorch 1.11.0环境运行,使用8张Tesla P100显卡进行训练,每张显卡显存为16 GB,实验batchsize设置为256。以长度为3 s的随机片段提取的梅尔频率倒谱系数(Mel-scale Frequency Cepstral Coefficient, MFCC)特征作为训练样本,使用窗长为25 ms,窗移为10 ms的汉明窗进行滑动分帧处理,每帧提取64维MFCC特征,不进行语音活动检测。作为最后的增强步骤,对大小为64×300的对数梅尔谱图应用了SpecAugment[37],在时域随机掩码0~10帧,在频域随机掩码0~8个通道。
模型训练使用Adam优化器,模型学习率均为2×10-3,使用余弦退火(Cosine Annealing)学习率调节算法[38],AAM-softmax损失函数中scale设为30,margin设置为0.2。为了防止过拟合,对模型中的所有参数使用了2×10-5权重衰减。
3.4 实验结果对比
表2、3展示了基线Thin ResNet34和本文方法在测试集上的评估结果。
表2训练集为VoxCeleb1开发集时,VoxCeleb1-O测试集上的评估结果
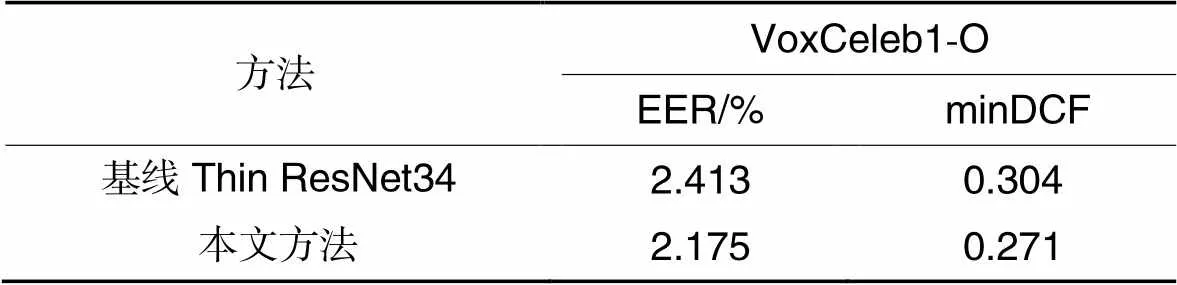
Tab.2 Evaluation results on VoxCeleb1-O test set after training on VoxCeleb1 development set
相较于确定性架构,本文方法的模型性能有明显提升,如表2所示,训练集为VoxCeleb1开发集时,在VoxCeleb1-O测试集上EER从2.413%降到了2.175%,EER相较于基线减小了9.9%,minDCF相较于基线减小了10.9%;如表3所示,训练集为Voxceleb2开发集时,在VoxCeleb1-O、VoxCeleb1-E和VoxCeleb1-H上EER相较于基线分别减小了10.4%、5.3%和3.0%,minDCF相较于基线分别减小了4.5%、5.3%和2.9%。实验结果验证了对语音数据集中的不确定性建模的必要性,说明它有助于说话人确认模型的性能提升。
表3训练集为VoxCeleb2开发集时,VoxCeleb1-O、VoxCeleb1-E和VoxCeleb1-H测试集上的评估结果
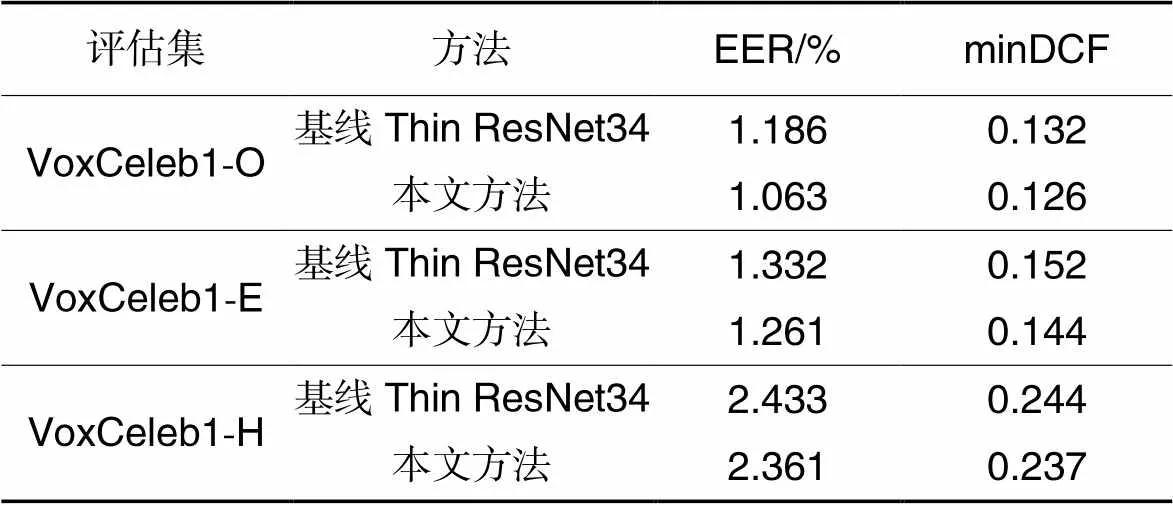
Tab.3 Evaluation results on VoxCeleb1-O、VoxCeleb1-E and VoxCeleb1-H test sets after training on VoxCeleb2 development set
3.5 参数分析
表4超参数取不同值,不同训练集和测试集上所提方法的评估结果

Tab.4 Evaluation results of proposed method on different test sets and development sets with different hyperparameter λ values
3.6 消融分析
表5消融实验结果
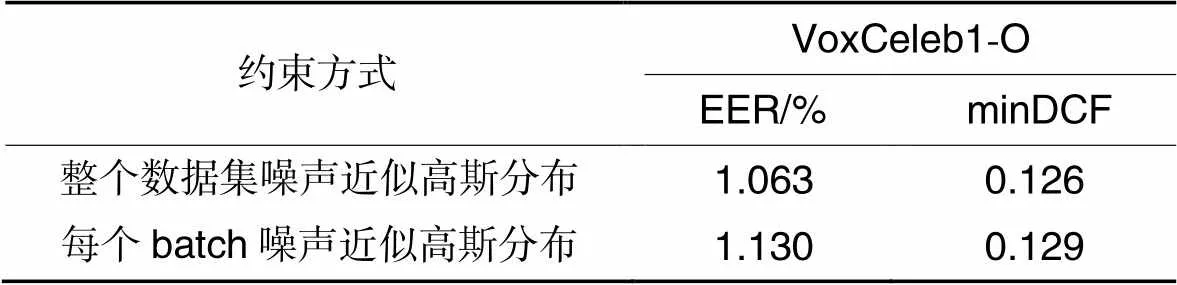
Tab.5 Ablation experimental results
4 结语
本文提出了一种基于不确定性学习的文本无关的说话人确认方法,该方法通过使网络模型同时学习声纹特征(均值)与不确定的噪声(方差),可以对与说话人确认相关的数据集中与身份信息无关的数据进行不确定性建模,并使用KL散度正则化方法约束噪声的分布,解决了建模中出现的退化问题。使用VoxCeleb数据集训练和评估了所提出的方法在说话人确认任务上的性能,实验结果表明,该方法的性能超过了基于确定性的基线模型。下一步将考虑在说话人确认中引入表示解纠缠,使声纹特征与不相关的特征解纠缠。
[1] DENG J, DONG W, SOCHER R, et al. ImageNet: a large-scale hierarchical image database[C]// Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2009: 248-255.
[2] HUANG G B, MATTAR M, BERG T, et al. Labeled faces in the wild: a database for studying face recognition in unconstrained environments [EB/OL]. [2019-02-25]. http://vis-www.cs.umass.edu/papers/eccv2008-lfw.pdf.
[3] NAGRANI A, CHUNG J S, ZISSERMAN A. VoxCeleb: a large-scale speaker identification dataset[EB/OL]. [2018-05-30]. https://arxiv.org/pdf/1706.08612.pdf.
[4] JOYCE J M. Kullback-Leibler divergence[M]// International Encyclopedia of Statistical Science. Cham: Springer, 2011: 720-722.
[5] DEHAK N, KENNY P J, DEHAK R, et al. Front-end factor analysis for speaker verification [J]. IEEE Transactions on Audio, Speech, and Language Processing, 2010, 19(4): 788-798.
[6] HANSEN J H L, HASAN T. Speaker recognition by machines and humans: a tutorial review[J]. IEEE Signal Processing Magazine, 2015, 32(6): 74-99.
[7] SNYDER D, GARCIA-ROMERO D, POVEY D, et al. Deep neural network embeddings for text-independent speaker verification[C]// Proceedings of the INTERSPEECH 2017. [S.l.]: International Speech Communication Association, 2017:999-1003.
[8] NOVOSELOV S, SHULIPA A, KREMNEV I, et al. On deep speaker embeddings for text-independent speaker recognition[EB/OL]. [2018-04-26]. https://arxiv.org/pdf/1804.10080.pdf.
[9] OKABE K, KOSHINAKA T, SHINODA K. Attentive statistics pooling for deep speaker embedding [EB/OL]. [2019-02-25]. https://arxiv.org/pdf/1803.10963.pdf.
[10] ZHU Y, KO T, SNYDER D, et al. Self-attentive speaker embeddings for text-independent speaker verification[C]// Proceedings of the INTERSPEECH 2018. [S.l.]: International Speech Communication Association, 2018: 3573-3577.
[11] CAI W, CAI Z, ZHANG X, et al. A novel learnable dictionary encoding layer for end-to-end language identification[C]// Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2018: 5189-5193.
[12] LI C, MA X, JIANG B, et al. Deep Speaker: an end-to-end neural speaker embedding system[EB/OL]. [2017-05-05]. https://arxiv.org/pdf/1705.02304.pdf.
[13] KWON Y, HEO H-S, LEE B-J, et al. The ins and outs of speaker recognition: lessons from VoxSRC 2020[C]// Proceedings of the 2021 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2021: 5809-5813.
[14] DESPLANQUES B, THIENPONDT J, DEMUYNCK K. ECAPA-TDNN: emphasized channel attention, propagation and aggregation in TDNN based speaker verification[EB/OL]. [2020-08-10]. https://arxiv.org/pdf/2005.07143.pdf.
[15] WU Y, ZHAO J, GUO C, et al. Improving deep CNN architectures with variable-length training samples for text-independent speaker verification[C]// Proceedings of the INTERSPEECH 2021. [S.l.]: International Speech Communication Association, 2021: 81-85.
[16] LIU T, DAS R K, LEE K A, et al. MFA: TDNN with multi-scale frequency-channel attention for text-independent speaker verification with short utterances[C]// Proceedings of the 2022 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2022: 7517-7521.
[17] KIM S-H, NAM H, PARK Y-H. Temporal dynamic convolutional neural network for text-independent speaker verification and phonemic analysis[C]// Proceedings of the 2022 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2022: 6742-6746.
[18] 陈晨,肜娅峰,季超群,等. 基于深层信息散度最大化的说话人确认方法[J]. 通信学报, 2021, 42(7): 231-237.(CHEN C, RONG Y F, JI C Q, et al. Speaker verification method based on deep information divergence maximization[J]. Journal on Communication, 2021, 42(7): 231-237.)
[19] 姜珊,张二华,张晗. 基于 Bi-GRU+BFE模型的短语音说话人识别[J]. 计算机与数字工程, 2022, 50(10): 2233-2239.(JIANG S, ZHANG E H, ZHANG H. Speaker recognition under short utterance based on Bi-GRU+BFE model[J]. Computer and Digital Engineering, 2022, 50(10): 2233-2239.)
[20] ISOBE S, ARAI S. Deep convolutional encoder-decoder network with model uncertainty for semantic segmentation[C]// Proceedings of the 2017 IEEE International Conference on INnovations in Intelligent SysTems and Applications. Piscataway: IEEE, 2017: 365-370.
[21] HU P, SCLAROFF S, SAENKO K. Uncertainty-aware learning for zero-shot semantic segmentation[J]. Advances in Neural Information Processing Systems, 2020, 33: 21713-21724.
[22] CHOI J, CHUN D, KIM H, et al. Gaussian YOLOv3: an accurate and fast object detector using localization uncertainty for autonomous driving[C]// Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE,2019: 502-511.
[23] YU T, LI D, YANG Y, et al. Robust person re-identification by modelling feature uncertainty [C]// Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2019: 552-561.
[24] SHI Y, JAIN A K. Probabilistic face embeddings[C]// Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE,2019: 6901-6910.
[25] CHANG J, LAN Z, CHENG C, et al. Data uncertainty learning in face recognition[C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2020: 5709-5718.
[26] HE K, ZHANG X, REN S, et al. Deep residual learning for image recognition[C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE,2016: 770-778.
[27] CAI W, CHEN J, LI M. Exploring the encoding layer and loss function in end-to-end speaker and language recognition system[EB/OL]. [2018-04-14]. https://arxiv.org/pdf/1804.05160.pdf.
[28] DENG J, GUO J, XUE N, et al. ArcFace: additive angular margin loss for deep face recognition [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE,2019: 4690-4699.
[29] KINGMA D P, WELLING M. Auto-encoding variational Bayes[EB/OL]. [2018-04-14]. https://arxiv.org/pdf/1312.6114.pdf?source=post_page.
[30] ALEMI A A, FISCHER I, DILLON J V, et al. Deep variational information bottleneck[EB/OL]. [2019-10-23]. https://arxiv.org/pdf/1612.00410.pdf.
[31] NAGRANI A, CHUNG J S, XIE W, et al. VoxCeleb: large-scale speaker verification in the wild[J]. Computer Speech & Language, 2020, 60: 101027.
[32] SNYDER D, CHEN G, POVEY D. MUSAN: a music, speech, and noise corpus[EB/OL]. [2019-10-23].https://arxiv.org/pdf/1510.08484.pdf.
[33] KO T, PEDDINTI V, POVEY D, et al. A study on data augmentation of reverberant speech for robust speech recognition[C]// Proceedings of the 2017 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2017: 5220-5224.
[34] DODDINGTON G R, PRZYBOCKI M A, MARTIN A F, et al. The NIST speaker recognition evaluation — overview, methodology, systems, results, perspective[J]. Speech Communication, 2000, 31(2/3): 225-254.
[35] CHUNG J S, NAGRANI A, ZISSERMAN A. VoxCeleb2: deep speaker recognition[EB/OL]. [2018-04-14]. https://arxiv.org/pdf/1806.05622.pdf.
[36] CAI W, CHEN J, LI M. Exploring the encoding layer and loss function in end-to-end speaker and language recognition system[EB/OL]. [2018-04-14].https://arxiv.org/pdf/1804.05160.pdf.
[37] PARK D S, CHAN W, ZHANG Y, et al. SpecAugment: a simple data augmentation method for automatic speech recognition [EB/OL]. [2019-12-03].https://arxiv.org/pdf/1904.08779.pdf.
[38] LOSHCHILOV I, HUTTER F. SGDR: stochastic gradient descent with warm restarts[EB/OL]. [2018-04-14]. https://arxiv.org/pdf/1608.03983.pdf.
Text-independent speaker verification method based on uncertainty learning
ZHANG Yulian, YAO Shanshan*, WANG Chao, CHANG Jiang
(,,030006,)
The speaker verification task aims to determine whether a registration speech and a test speech belong to the same speaker. A Text-Independent Speaker Verification (TISV) method based on Uncertainty Learning (UL) was proposed to address the problem that the voiceprint features extracted by speaker recognition systems are usually disturbed by factors unrelated to identity information, thereby leading to serious degradation of the system accuracy. Firstly, uncertainty was introduced in the speaker backbone network to simultaneously learn the voiceprint features (mean) and the uncertainty of the speech data (variance), so as to model the uncertainty in the speech dataset. Then, the distribution representation of the features was obtained by a resampling technique. Finally, the degradation problem in the calculation process of classification loss was solved by constraining the distribution of the noise through the introduction of KL (Kullback-Leibler) divergence regularization into the speaker classification loss. Experimental results show that after training on VoxCeleb1 and VoxCeleb2 development sets and testing on VoxCeleb1-O test set, compared with the certainty method-based model Thin ResNet34,the model of the proposed method has the Equal Error Rate (EER) reduced by 9.9% and 10.4% respectively, and minimum Detection Cost Function (minDCF) reduced by 10.9% and 4.5% respectively. It can be seen that the accuracy of the proposed method is improved in noisy and unconstrained scenarios.
speaker verification; data uncertainty; distribution embedding; AAM-softmax (Additive Angular Margin-softmax); KL (Kullback-Leibler) divergence
This work is partially supported by National Natural Science Foundation of China (61906115), Shanxi Province Science Foundation for Youths (20210302124556).
ZHANG Yulian, born in 1997, M. S. candidate. Her research interests include voiceprint recognition.
YAO Shanshan, born in 1989, Ph. D., associate professor. Her research interests include voiceprint recognition, multimedia big data search.
WANG Chao, born in 1995, M. S. candidate. His research interests include voiceprint recognition.
CHANG Jiang, born in 1988, Ph. D., lecturer. Her research interests include speech sentiment analysis.
TN912.34; TP391.42
A
1001-9081(2023)12-3727-06
10.11772/j.issn.1001-9081.2022121902
2022⁃12⁃29;
2023⁃03⁃07;
2023⁃03⁃08。
国家自然科学基金资助项目(61906115);山西省青年科学基金资助项目(20210302124556)。
张玉莲(1997—),女,山西晋城人,硕士研究生,主要研究方向:声纹识别;姚姗姗(1989—),女,山西晋中人,副教授,博士,CCF会员,主要研究方向:声纹识别、多媒体大数据检索;王超(1995—),男,山西大同人,硕士研究生,主要研究方向:声纹识别;畅江(1988—),女,山西运城人,讲师,博士,主要研究方向:语音情感分析。
猜你喜欢
法律方法(2022年2期)2022-10-20 06:41:56
阅读(快乐英语高年级)(2019年5期)2019-09-10 07:22:44
电子制作(2019年14期)2019-08-20 05:43:38
中国外汇(2019年7期)2019-07-13 05:45:04
电子制作(2019年9期)2019-05-30 09:42:10
小说界(2018年5期)2018-11-26 12:43:42
通信产业报(2018年32期)2018-11-24 10:37:58
系统工程与电子技术(2016年4期)2016-08-24 07:46:22
浙江大学学报(工学版)(2015年1期)2015-03-01 01:17:11
外语学刊(2010年2期)2010-01-22 03:31:09
