
基于堆叠交叉注意力CLIP的多模态情感分析
2024-01-08 08:07汪召凯叶勇汪子文
黑龙江工业学院学报(综合版) 2023年11期
汪召凯,叶勇,汪子文
(安徽农业大学 信息与人工智能学院,安徽 合肥 230036)
在过去几年里,多模态的相关研究非常火热,例如利用多模态方法进行社区划分的相关研究[1],以及多模态情感分析等。情感在我们的日常生活中扮演着重要的角色。它们有助于在以人为中心的环境中进行决策、学习、交流和态势感知。在过去的二十年里,研究人员一直探索如何将认知能力赋予机器,使它们能够像人类一样识别、分析和表达情感的能力,这一认知能力也即是情感分析。情感分析也称为意见挖掘或者情感计算,这一概念的来源最早可追溯到麻省理工实验室Picard教授提出的“情感计算”[2]。情感分析旨在通过用户发表的各类信息分析出用户想要表达的情感极性[3]。但是鉴于情感表达方式的隐蔽性与复杂性,对不同模态的语言序列进行情感建模仍然存在着亟待解决的问题。
早在2011年,阳锋等[4]设计了一个面向微博数据流的,集实时抓取多种模态数据和分析观点倾向性于一体的观点挖掘原型系统MICA(Microblog Item Crawling and Analyzing)。通过分别对图文情感分类器预测的情感得分分配不同的权重并相加来判断情感倾向[5],但该工作采用的手工图文特征,由于其提取特征的方式较为简单,致使多模态特征中包含的图文情感信息不够丰富,并不能有效捕捉情感分布,无法有效提升模型的情感倾向分类能力.后来,采用深度CNN分别提取了更加丰富的图文特征[6],并将它们连接成联合特征送入到分类器学习情感分布。MultiSentiNet[7]使用LSTM和CNN对文本和图像进行编码以获得隐藏表示,然后连接文本和图像的隐藏表示以融合多模态特征。CoMN[8]使用共记忆网络对视觉内容和文本词之间的交互进行迭代建模,以进行多模态情感分析。Yu等[9]针对基于实体的多模态情感分析任务,提出了ESAFN模型来融合文本表示和图片特征。MVAN[10]通过注意力记忆网络模块利用文本和图像特征来进行交互式学习,并使用多层感知机和堆叠池化模块构建多模态特征融合模块。Yang等[11]使用基于数据集全局特征构建的具有情感感知的多通道图神经网络进行多模态情感分析。ITIN[12]引入了一个跨模态对齐模块来捕获区域-词的对应关系,在此基础上,通过自适应跨模态门控模块融合了多模态特征,另外整合了个体模态上下文特征表示,以实现更可靠的预测。
这些研究大多采用不同的模型来分别处理以及提取图像和文本的特征,再加上图像和文本在模态上天然具有较大的差距,一般融合模型很难捕获到跨模态之间的互补信息。为了充分利用多模态信息,实现更有效的模态交互。基于此,我们提出了基于堆叠交叉注意力CLIP(SCA-CLIP)框架,由于CLIP提取的特征本身是对齐的,且特征之间有很强的关联性,后续利用设计的堆叠交叉注意力机制和多头注意力机制来对特征进行交互融合以及信息的提取。在MVSA-Single、MVSA-Multiple数据集上进行了验证,与这两个数据集中的最新的多个基线模型相比,SCA-CLIP实现了更好的性能,通过一组消融实验的研究,展示了SCA-CLIP在多模态融合方面的优势。
1 方法
在本节中,详细阐述了用于多模态情感分析的堆叠交叉注意力机制的CLIP多模态情感分析模型(SCA-CLIP)的细节,模型的整体架构如图1所示,首先利用CLIP提取图像文本特征,由于提取到的特征本身就是对齐的以及强相关的,之后利用设计堆叠交叉注意力机制对特征信息进行充分模态交互与融合信息,最后利用BERT的中维护的可学习的常量来学习特征信息进行最后的情感分类。
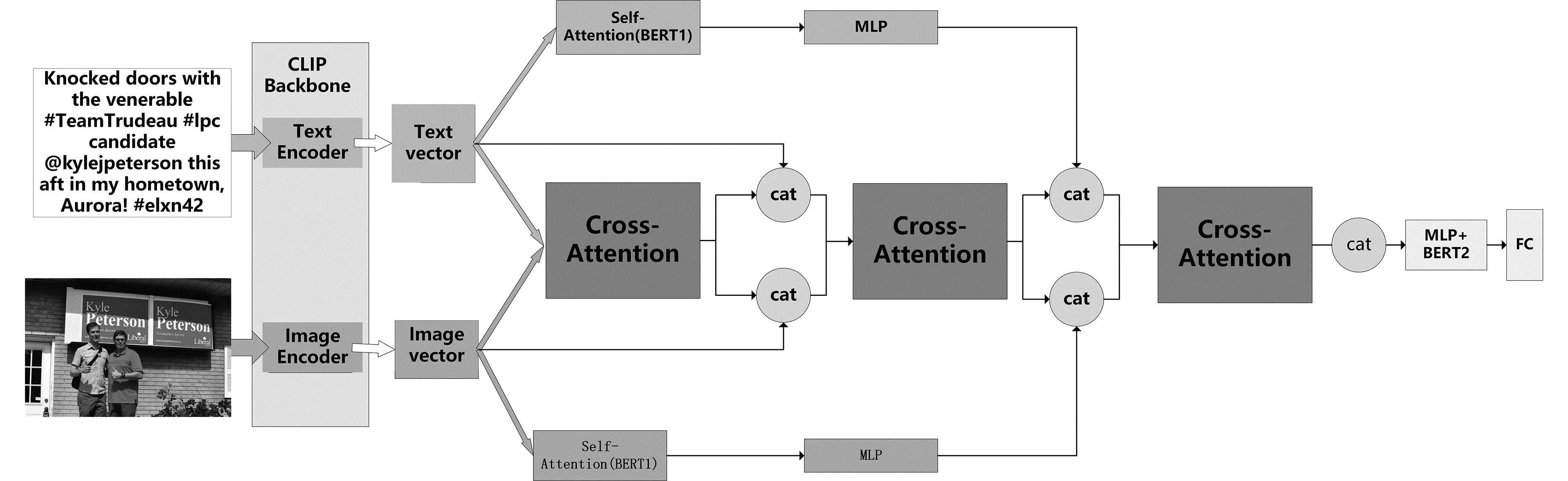
图1 基于堆叠交叉注意力机制的CLIP多模态情感分析模型(SCA-CLIP)的总体框架
1.1 CLIP模块
对比预训练模型(CLIP)[13]的架构为经典的双塔结构,由图片编码器和文本编码器组成。对于每个图像-文本对,图像和文本编码器将图文对映射到同一特征空间。对于给定一批N个图像-文本对,CLIP的训练目标是最大化配对图像和文本特征编码的余弦相似度,同时最小化未配对图像和文本特征编码的余弦相似度。
CLIP在推理的过程中,对于具有K类的分类任务,它首先利用k类标签值来构造k模板提示,例如“a picture of {class value}”,这些k模板提示将会通过文本编码器进行编码映射到k文本嵌入中,对于给定的任何图像将会被映射到图像嵌入。最后CLIP计算图像嵌入和那些k文本嵌入之间的余弦相似度,将具有最大相似性的类值视为该类的预测。
CLIP模型训练使用的是WIT数据集,该数据集包含从互联网中收集的4亿个图文对。根据文献[13]所展示的结果,其在多个数据集中取得了显著的成果。
1.2 BERT模块
BERT是基于Transformer的双向语言编码表示模型,不同于具有循环网络的RNN,其中的Transformer完全基于注意力的序列转换模型,它取代了循环或者卷积网络而使用多头自注意力的编码解码结构来对文件进行表示,比循环或卷积神经网络具有更快的训练速度。近年来注意力机制成为多种任务序列建模的重要组成部分,但它没有形成输入和输出序列中的远距离依赖关系,文献[14]所提出的Transformer模型架构如图2所示,其输入与输出之间的全局依赖关系完全基于注意力机制来构建。

图2 Transformer编码器
编码器中输入序列经过向量、位置编码后进入自注意力层,编码器采用多头注意力使模型具有注意多个位置的能力,从而在自注意力层实现多个表征子空间以表征序列多方面的语义信息。解码器比编码器增加了掩蔽多头注意力,确保某位置预测只依赖于之前的已知输出,最后结果通过softmax函数输出概率。
1.3 交叉注意模块

图3 交叉注意力模块
图3为单层交叉注意力模块,其中的Feature表示输入或输出特征的一个表示,然后利用交叉注意力模块来对模态信息进行充分交互以及融合。具体实现过程如下所述。对于输入的图像和文本,本文应用预训练的CLIP模型将图像文本嵌入到512维的嵌入向量T,V。CLIP内部包含两个模型分别是Text Encoder和Image Encoder,其中Text Encoder用来提取文本的特征,采用的是NLP中常用的text transformer模型,其表达式如式(1)所示。
T=CLIPText(text)
(1)
式(1)中,text表示传入的文本信息,CLIPText表示使用CLIP模型的文本编码器对信息进行编码,T表示编码后得到的信息特征。
Image Encoder用来提取图像的特征,采用的是常用的CNN模型或者vision transformer,本文采用的是vision transformer,其表达式如式(2)所示。
V=CLIPImage(image)
(2)
式(2)中,image表示传入的文本信息,CLIPImage表示使用CLIP模型的图片编码器对信息进行编码,V表示编码后得到的信息特征。
CLIP得到的特征向量维度均为[batchsize,512],然后扩展维度为[batchsize,1,512]。对于文本相对图片的注意力权重矩阵。用V的转置点乘T得到相似矩阵,之后利用std函数进行标准化处理,最后通过一层Sigmoid激活函数,得到相对应的注意力权重,具体如式(3)所示。
VT=sigmoid(std(VT⊙T))
(3)
式(3)中,VT表示图片特征的转置,T表示文本特征,VT表示文本相对图片的注意力权重矩阵。
得到文本相对图片的注意力权重后,利用sum函数将权重与文本特征相乘再逐行相加,得到最后的文本相对图片的注意力向量。Tatt表示最终的注意力向量,具体如式(4)所示。
Tatt=sum(VT*T)
(4)
对于图片相对于文本的注意力权重的获取,与文本相对图片的流程基本一致具体如式(5)所示。
TV=sigmoid(std(TT⊙V))
(5)
式(5)中,TT表示文本特征的转置,V表示图片特征,TV表示图片相对文本的注意力权重。
得到图片相对文本的注意力权重后获取注意力向量,过程与得到文本相对图片的注意力向量一致。Vatt表示最终的注意力向量,如式(6)所示。
Vatt=sum(TV*V)
(6)
最后,在进行第一次交叉注意得到Tatt和Vatt后再与T和V向量拼接做交叉注意,之后将结果与自我注意即BERT中的可学习向量得到的向量信息继续拼接后再次做交叉注意,之后将最终得到的融合向量拼接再输入到BERT中通过BERT中维护的可学习变量提取到情感分析所需的信息,最后经过FC层得到情感预测结果。
2 实验结果与分析
2.1 数据集
本文在两个公共多模态情感分析数据集上评估我们的模型,即MVSA-Single和MVSA-Multiple[15]。MVSA-Single由从Twitter收集的5129个图像-文本对组成。每对都有注释标记,注释分别为图像和文本分配一种情绪(正面、中性和负面)。MVSA-Multiple包含19600个图像-文本对。每对由三个注释标记,每个注释对图像和文本的情感分配是独立的,这些注释均为人工标注。
为了公平比较,我们按照文献[7]中的方法对两个数据集进行预处理,其中不一致的图像标签和文本标签对被删除,预处理后的结果展示如图4所示。具体来说,如果一个标签是正面(或负面)而另一个是中性,本文将这对的情感极性视为正面(或负面)。因此,得到了新的MSVA-single和MSVA-multiple数据集用于实验,如表1所示。首列表示使用的数据集种类,后面的各列表示在相对应的数据集中该类标签的样本数目,最后一列表示该数据集的样本总数。

图4 对数据集预处理后的一些样本展示
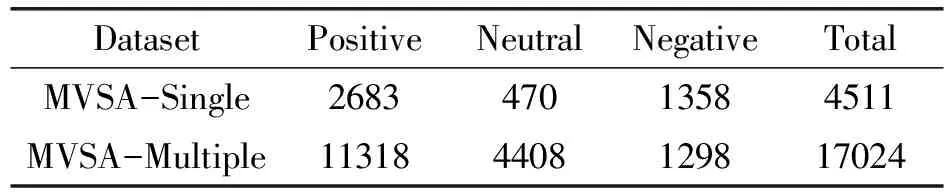
表1 数据集处理之后的统计
2.2 实现细节
在本文的实验中,数据集按照8:1:1的分割比例随机分为训练集、验证集和测试集。提出的SCA-CLIP由Adam优化。Learning rate设置为5e-5,weight_decay设置为1e-4。考虑到两个数据集中的样本数量不同,本文将MVSA-Single的batch size设置为32,将MVSA-Multiple的batch size设置为128。本文的框架由PyTorch[16]实现。本文使用准确率和F1-score作为评价指标,其中准确率的公式如式(7)所示。
(7)
F1-score的公式如式(8)-式(10)所示。
(8)
(9)
(10)
式(8)-式(10)中,Precision表示精准率即代表对正样本结果中的预测准确程度。Recall表示召回率即表示所有被预测为正的样本中实际为正的样本的概率。TP是被判定为正样本,事实上也是正样本的样本数,FP是被判定为负样本,事实上也是负样本的样本数。TN是被判定为正样本,但事实上是负样本的样本数。FN是被判定为负样本,但事实上是正样本的样本数。
2.3 基线模型
对于MVSA数据集,本文列举了如下的六个基线方法。
(1)MultiSentiNet[7]:利用CNN获取图像的对象和场景深度语义特征,利用视觉特征引导注意力LSTM提取重要词特征;所有这些特征都被聚合起来进行情感分析。
(2)CoMN[8]:考虑图像和文本之间的关系,提出了一种具有注意机制的迭代共记忆模型;该网络多次探索视觉和文本信息的交互作用,分析用户的情绪。
(3)MVAN[10]:提出了一种基于多视图注意的交互模型,该模型构建了迭代的场景-文本共记忆网络和迭代的对象-文本共记忆网络,以获取用于情感分析的语义图像-文本特征。
(4)MGNNS[11]:提出了一种多通道情感感知图神经网络(MGNNS)用于图像文本情感检测。他们首先编码不同的模式来捕获隐藏的表示。然后,他们引入多通道图神经网络来学习基于数据集全局特征的多模态表示。最后,利用多头注意机制实现多模态深度融合,预测图文对的情感。
(5)CLMLF[17]:介绍了一种基于多层transformer的对比学习融合方法。提出了基于标签的对比学习和基于数据的对比学习两种对比学习任务,以帮助模型学习情感分析的共同特征。
(6)ITIN[12]:开发了一种图像-文本交互网络,以对齐图像区域和单词之间的信息,并使用跨模态门控模块保留有效的区域-单词对,以实现有效的融合特征。将单模态特征与跨模态融合特征相结合,实现情感分类。
所提出的模型与基线之间的实验结果比较如表2所示。基线方法的结果是已发表论文中展示的最佳结果。
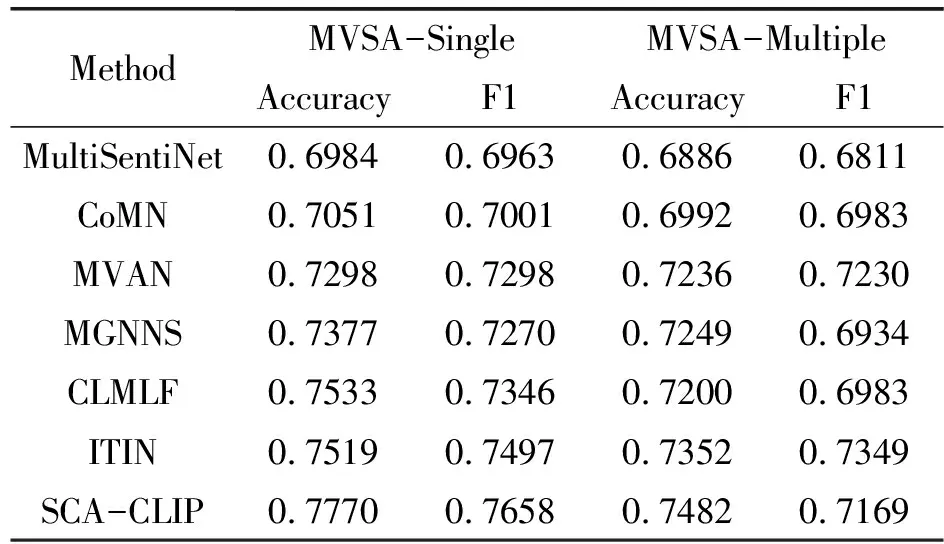
表2 在MVSA数据集上各种方法的比较
在MVSA-Single数据集上,本文的模型在准确率和F1分数方面分别优于现有的最佳模型2.37%和1.61%。对于MVSA-Multiple数据集,本文的模型在准确率上提升了1.3%,在F1分数上取得了具有竞争力的性能。总体而言,这些结果证明了所提出的SCA-CLIP在多模态情感分析中的优势。性能的提升得益于SCA-CLIP的优越性。首先,通过CLIP来提取对齐的图像文本特征,同时利用BERT自注意提取特征,之后再利用堆叠交叉注意来融合特征,最后通过BERT学习融合特征以进行情感分类。
为了进一步分析该模型在不同类别中的判别力,图5和图6显示了不同数据集下SCA-CLIP模型的混淆矩阵。由图5和图6可知,SCA-CLIP模型对Positive和Negative类别的判别力较强,而对Neutral类别的判别力较弱,这意味着它对模棱两可案例的判别力较弱,而对有明显情感倾向案例的判别力较强。由于MVSA-multiple中类别的不平衡性较高,导致对负面类别的判别结果较低。
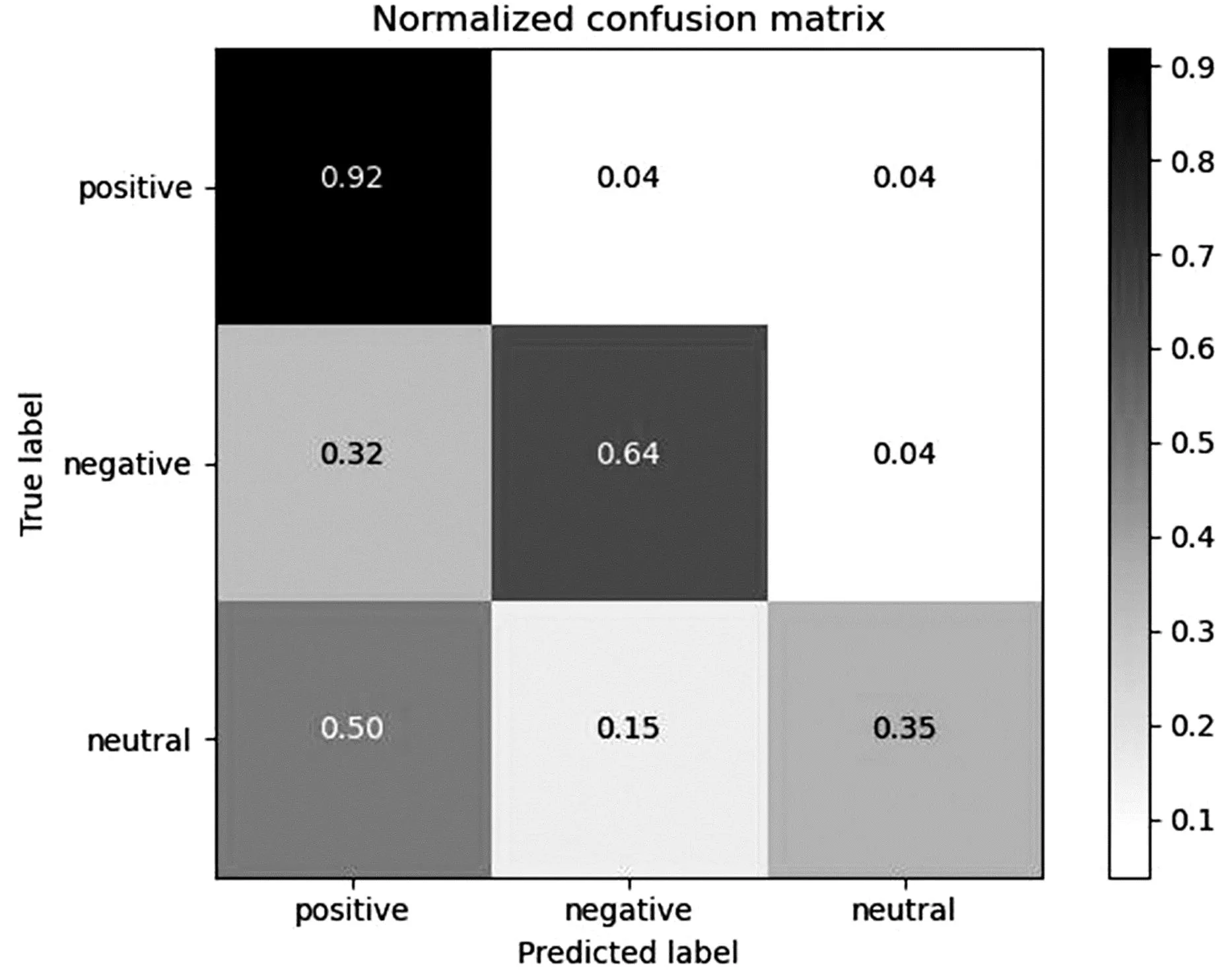
图5 MVSA-Single数据集的混淆矩阵
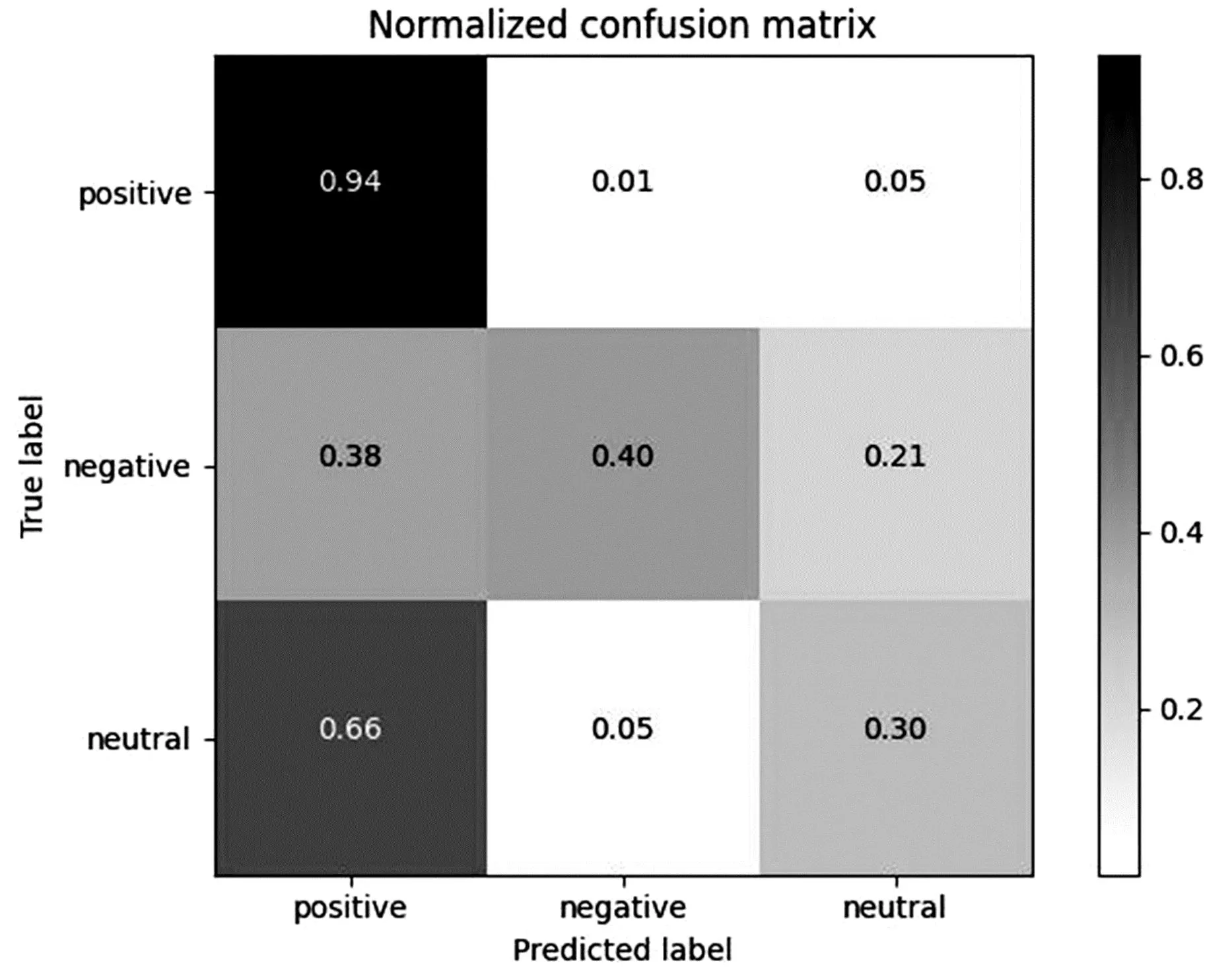
图6 MVSA-Multiple数据集的混淆矩阵
2.4 消融实验
为了进一步验证每个提出模块的有效性,对两个MVSA数据集进行了几次消融实验,在本文的模型中,最后学习融合特征的BERT为BERT2。在SCA-CLIP模型上只留下CLIP、只留下BERT2、去除BERT2、去除交叉注意、去除所有BERT,分别表示为“SCA-CLIP onlyCLIP”“SCA-CLIP onlyBERT2”“SCA-CLIP w/o BERT2”“SCA-CLIP w/o CrossAtt”“SCA-CLIP w/o AllBERT”,这些研究结果如表3所示。
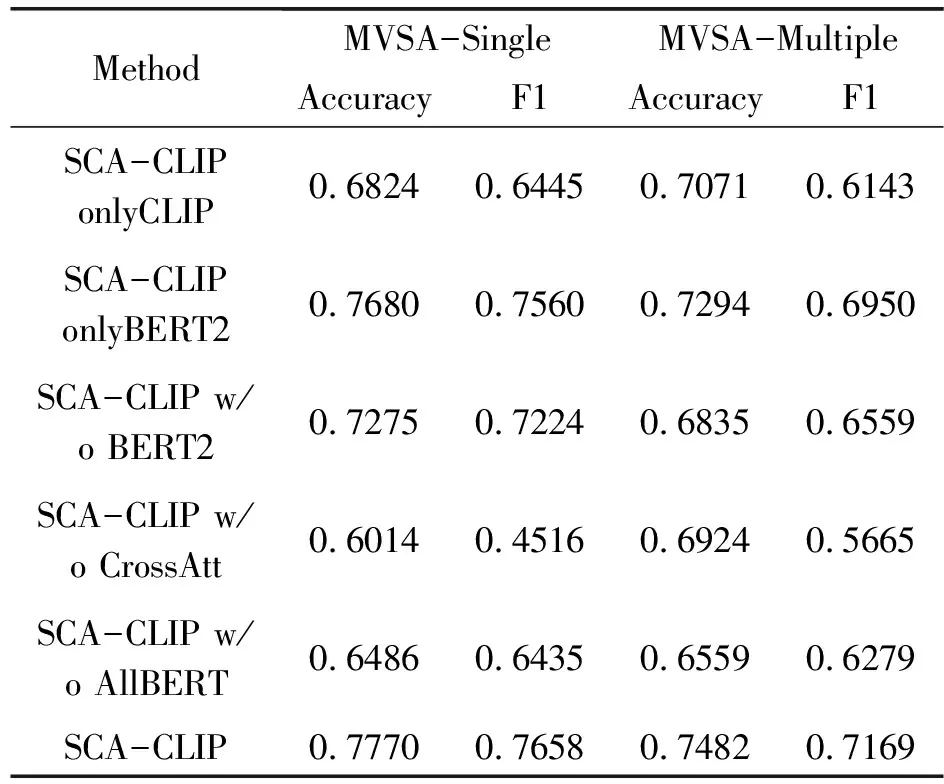
表3 在MVSA数据集上的消融实验结果
从表3这些结果中,可以观察到如下内容。
由各个模块组成使得提出的SCA-CLIP在两个数据集上实现了最佳性能。移除任何一个模块都会导致预测的结果不理想。
SCA-CLIP onlyCLIP比SCA-CLIP结果差,证明了堆叠交叉注意和多头注意在特征提取和特征融合方面的有效性。
SCA-CLIP onlyBERT2比SCA-CLIP w/o BERT2的结果好,证明了单流方法在学习特征方面的有效性,能够充分学习到更多有用的信息。
SCA-CLIP w/o AllBERT表现得比SCA-CLIP w/o CrossAtt好,证明了交叉注意在特征融合以及特征学习的有效性。从以上的分析中,可以得出结论,每个提出的模块都是不可或缺的,它们共同为最终的性能做出了必要的贡献。
此外,进一步分析可以得到,大多数模型采用不同的模型来提取文字和图像特征,提取的特征不具有相关性,而且图像和文字的模态差距天然很大,因此后续的特征信息融合很困难。而CLIP的预训练模型是基于对比训练的,CLIP提取的特征是高度相关的,包含更多的有效信息。从SCA-CLIP onlyBERT2的结果可以验证,直接拼接CLIP提取的特征,利用BERT的自我注意机制提取分类信息,可以获得较高的准确率。从SCA-CLIP onlyBERT2和SCA-CLIP的结果对比可以分析出,所提出的叠加交叉注意力模块充分利用了模态信息,实现了模态之间的充分交互与融合,汇聚了更多有用的分类信息,最后利用BERT提取分类信息,得到了最优的分类结果。
最后,图7展示了SCA-CLIP模型在不同参数值下的性能,以分析超参数敏感性。实验分析了SCA-CLIP模型的超参数敏感性,包含Dropout, Learning rate。在两个数据集的实验中,模型参数的dropout, learning rate均设置为(0.3,0.00005)。

(a)准确率与learning rate之间的关系

(b)准确率与dropout之间的关系图7 在MVSA-single,MVSA-multiple数据集上的参数实验结果
如图7所示,实验中将dropout值分别设置为(0.1,0.3,0.5,0.7,0.9),learn rate的值分别设置(0.00001,0.00002,0.00003,0.00005,0.0001)。可以观察到当dropout为0.3,learning rate为0.00005时,MVSA-Single数据集和MVSA-Multiple数据集都取得了最高的准确率,分别为77.70%,74.82%。同时两个数据集的曲线变化趋势基本保持一致,都是在开始的一段范围内变化不大,最后下降很多。我们可以得出结论SCA-CLIP模型对于两个超参数均略微敏感。
3 结论
社交媒体多模态情感分析是一项非常具有挑战性的任务。在本文中,为多模态情绪预测任务提出了一个利用基于堆叠交叉注意力机制CLIP的网络框架(SCA-CLIP)。具体而言,首先采用预训练模型CLIP来提取图像和文本的特征,由于CLIP预训练模型使用的是图文对进行对比学习,所以提取的图像文本特征本身就是对齐的和强相关的。之后我们利用设计的堆叠注意来充分对模态交互以及特征融合,最后利用BERT中维护的可学习常量来学习最后情感分析所需的信息,进行有效情感预测。通过实验结果的比较表明,本文的模型显著提高了多模态数据集中的情感分类性能。尽管本文获得了很好的结果,但该模型仍然具有较大的局限性。由于有些帖子的图片和文字不相关,这就导致了情感表达实际上是依赖于独立的特征,这可能会限制SCA-CLIP的性能。因此,在未来的工作中,可以在模型的扩展性方面展开进一步的研究工作。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09
疯狂英语·新策略(2019年10期)2019-12-13
当代陕西(2019年10期)2019-06-03
数学小灵通·3-4年级(2017年9期)2017-10-13
传媒评论(2017年3期)2017-06-13
第二课堂(课外活动版)(2016年2期)2016-10-21
湖北经济学院学报·人文社科版(2015年8期)2015-12-29
上海电机学院学报(2015年4期)2015-02-28
计算物理(2014年2期)2014-03-11
河南科技(2014年23期)2014-02-27
