
基于机器学习的无绝缘轨道电路健康状态综合评价方法
2024-01-06 01:51董寅超赵林海
铁道学报 2023年12期
董寅超,赵林海
(北京交通大学 电子信息工程学院,北京 100044)
ZPW-2000系列无绝缘轨道电路(jointless track circuit,JTC)作为信号系统的重要组成部分,其故障会直接影响列车占用检查和向列车传递相关信息[1]。目前,国内外主要利用检测车对JTC的健康状态进行检测[2]。因此,基于检测车数据研究JTC健康状态综合评价方法,提升JTC动态性能评估的准确性,全面掌握其健康状态发展趋势,对于实现我国铁路“状态修”[3]的发展目标,具有非常重要的研究意义。
在目前相关研究中,文献[4]提出基于数据融合的JTC健康状态综合分析系统;文献[5]提出基于层次分析法和模糊综合评价的JTC健康状态综合评价方法;文献[6]基于模糊综合评价法对JTC的健康状态进行综合评价;文献[7]提出基于熵权法和支持向量数据描述的健康状态评价模型;文献[8]基于层次分析法构建JTC运行质量指数TEI,实现了JTC健康状态的综合评价;文献[9]基于混合整数线性规划对文献[8]中TEI的权重进行了优化。
然而,上述研究仍存在一些不足。文献[4,7]对JTC健康状态的评价结果仅为“健康”和“故障”两个等级,不能区分出JTC性能已下降但还未故障的状态。文献[4,6-9]忽视了JTC轨面不同位置补偿电容故障的差异性;文献[5]考虑了这一差异性,但其所设计的各补偿电容权重系数缺乏理论依据。文献[4-6]和[8]仅使用专家打分法确定指标权重,使评价结果易受专家主观经验的影响。
针对上述研究不足,本文首先基于JTC和检测车的工作原理,确定JTC健康状态评价指标及评价函数。然后,基于JTC仿真模型[10],采用故障注入[11]技术,对JTC常见故障进行仿真,构建JTC各状态下的检测车检测数据集。接下来,使用半监督聚类算法,融合传统层次分析法的专家经验和数据中蕴含的信息,对数据集进行标注。最后,基于XGBoost模型和SHAP计算各评价指标的权重,构造JTC健康分数(Health Index,HI),实现对JTC健康状态的评价。实验表明,本文方法具有准确、合理和泛化性强等优点,克服了现有方法的不足,提高了检测车对JTC的健康评价能力,为实现JTC的“状态修”提供了依据。
1 检测车及其检测数据
1.1 检测车基本工作原理
检测车的系统组成与工作原理见图1。
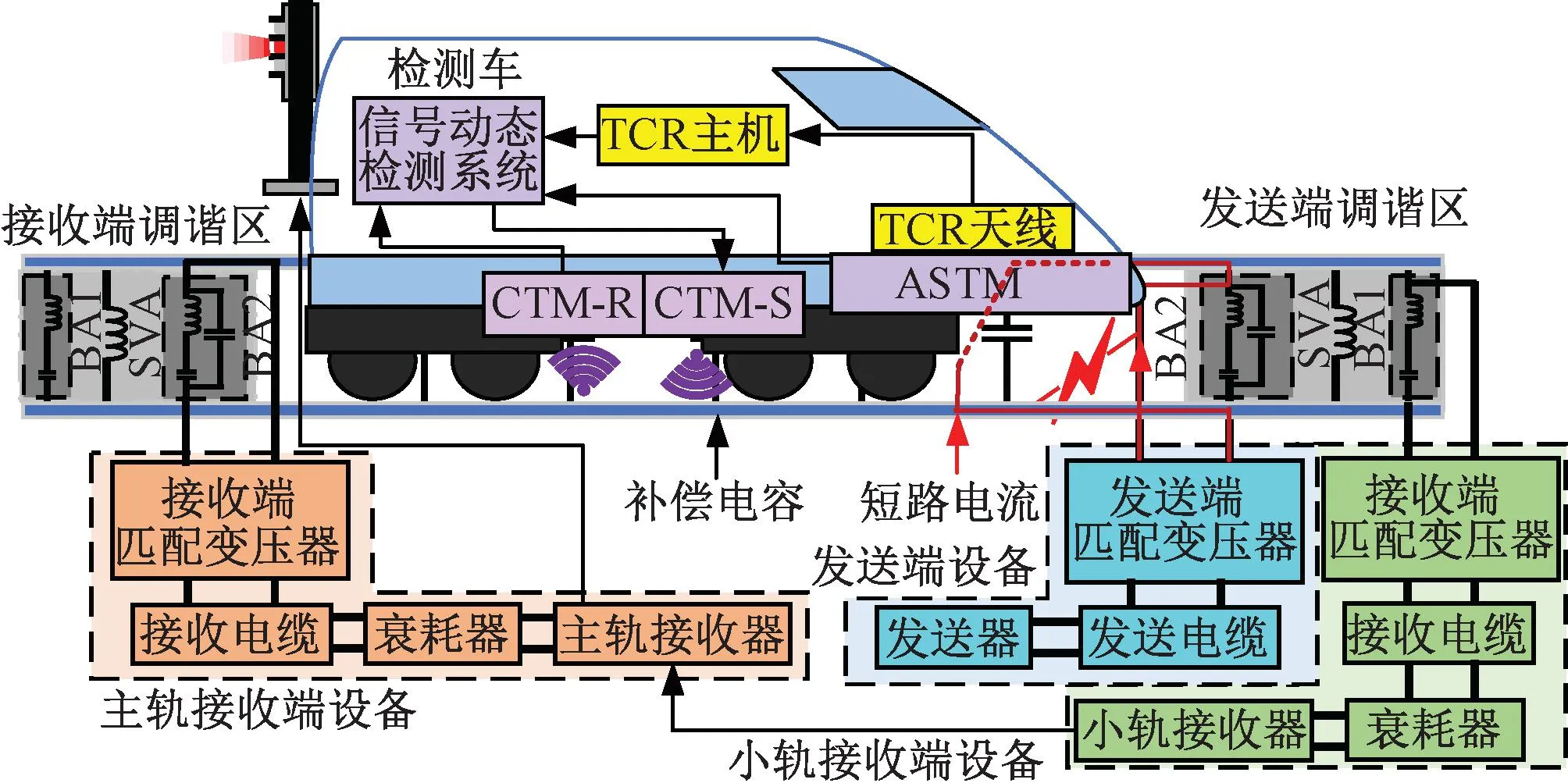
图1 检测车的系统组成与工作原理
JTC信号Ufs(t)由发送器产生,经过发送电缆、发送端匹配变压器和发送端调谐区传送到由钢轨、道床、补偿电容等组成的钢轨传输线路。
Ufs(t)为相位连续的频移键控信号,其时域表达式为[12]
(1)
式中:Afs、fc、Δfp和φ0分别为Ufs(t)的振幅、载频频率、频偏和初始相位;sm(t)为频率为fd、占空比为50%的方波调制信号,通常称fd为低频信息,其取不同值代表对列车不同的控制信息。
在ZPW-2000A型无绝缘轨道电路中,信号特征参数Afs、fc、Δfp和fd具有不同的取值。根据振幅大小不同,Afs可分为1级电平到5级电平,其范围依次为161~170、146~154、128~135、104.5~110.5、75.0~79.5 V;载频频率fc有1 700、2 000、2 300、2 600 Hz共4种基准载频,且在实际应用中又派生出“-1型载频”和“-2型载频”,分别在基准载频的基础上加1.4 Hz和减1.3 Hz;频偏Δfp为11 Hz;低频fd有18个取值,为10.3+1.1×n,n=0,1,2,…,17。
当检测车进入JTC区段时,其第一轮对将JTC信号分路,形成短路电流,同时在TCR天线中形成感应电压信号,再通过TCR主机解出该信号中的低频信息,实现地-车间信息传输。
检测车搭载有信号动态检测系统,能够在列车运行中对JTC的状态进行检测[13]。其中,信号动态检测系统从轨道电路信息接收单元(track circuit reader, TCR)主机中获取数据,实现对JTC信号传输特性、频谱特性和干扰信号的检测;牵引回流检测天线(ASTM)接收两条钢轨上的牵引回流;补偿电容检测发送天线(CTM-S)持续向轨面发射特定频率的检测信号,使得钢轨-轮对组成的回路内产生感应电流,并在补偿电容检测接收天线(CTM-R)中生成相应的感应电压信号,通过该信号的幅值包络实现对补偿电容的检测。
1.2 检测车检测数据
检测车与JTC有关的检测信息主要包括检测车所处的公里标以及各公里标处的检测车速度、JTC信号载频和低频、50 Hz不平衡牵引回流干扰幅值、4种载频对应的感应电压幅值和补偿电容反馈信号幅值等。
由检测车的工作原理可知,检测车数据能够反映JTC的健康状态,具体表现在以下三个方面:
1)信号频率
JTC信号载频和低频发生偏移,会导致TCR设备不能正常解码。载频和低频的偏移量可以从检测车数据中直接提取。
2)干扰信号
JTC信号传输过程中,会出现频率为50 Hz的不平衡牵引回流干扰、相邻区段的邻区段干扰和相邻线路的邻线干扰[9],会影响TCR设备的正常工作。干扰信号的强度可以通过检测车数据中不同载频的感应电压幅值反映。
3)组件参数
相关研究[10,14]表明,补偿电容值、调谐单元故障情况、钢轨间的道砟电阻等组件参数的变化,会影响JTC信号的传输。这些参数可基于检测车的感应电压幅值数据,通过相关算法[15-17]进行提取。由调谐单元的原理[12]可知,邻区段干扰与调谐单元故障直接相关,因此,调谐单元故障情况也可通过邻区段干扰表征。
2 评价指标的选取与状态数据集的构建
2.1 评价指标的选取
2.1.1 信号频率评价指标及阈值选取
对于JTC信号载频和低频,定义载频偏移度Ofc和低频偏移度Ofd评价指标的计算式为
(2)
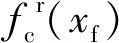
ZPW-2000A型JTC信号载频偏移和调制低频偏移的允许范围分别是±0.15、±0.03 Hz[12],以此为标准分别设置指标Ofc和Ofd的评价阈值分别为
(3)
2.1.2 干扰信号评价指标及阈值选取

(4)
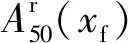
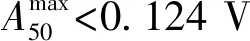
(5)
对于邻区段干扰和邻线干扰,可通过干扰信号的幅值和持续的长度描述。分别选取JTC区段内各公里标处的邻区段干扰信号和邻线干扰信号与本区段信号的幅值平方和之比作为评价指标Rlq和Rlx,即有
(6)

通过对待评价数据所在线路的检测车数据中无故障JTC的Rlq和Rlx取值进行统计分析,即可确定相应阈值。
2.1.3 组件参数评价指标及阈值选取
道砟电阻rd使得感应电压幅值由发送端到接收端呈现出递减趋势,且递减程度会随着rd的增大而降低[10],见图2,图中,xC1、xC2、…分别代表补偿电容C1、C2、…处公里标。
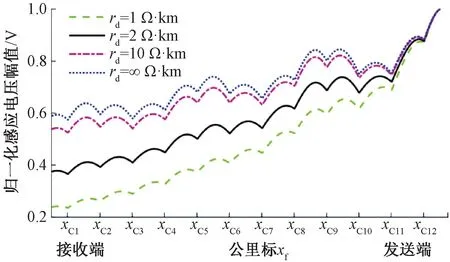
图2 道砟电阻对感应电压的影响
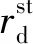
(7)
不同位置处的补偿电容发生断线故障对最小短路电流幅值的影响程度不同[19],见图3。

图3 补偿电容断线位置对短路电流的影响
为了设计基于位置的补偿电容评价指标,本文首先定义补偿电容状态向量C
C=[c1…ci…cNC]T
(8)
式中:NC为JTC区段内的补偿电容个数。
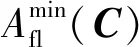
(9)
式中:Ith为钢轨最小短路电流值[18]。
2.2 评价函数的设计
本文所提指标都是定量指标,参考现有研究[4-9],将JTC健康状态定量评估类别划分为5个,各类别与分数的对应关系如表1所示。

表1 JTC健康状态类别与分数对应表
对于成本型指标,指标取值越小得分越高。定义Z型评价函数FZ(u,aZ,bZ)为
FZ(u,aZ,bZ)=
(10)
Z型评价函数曲线见图4。
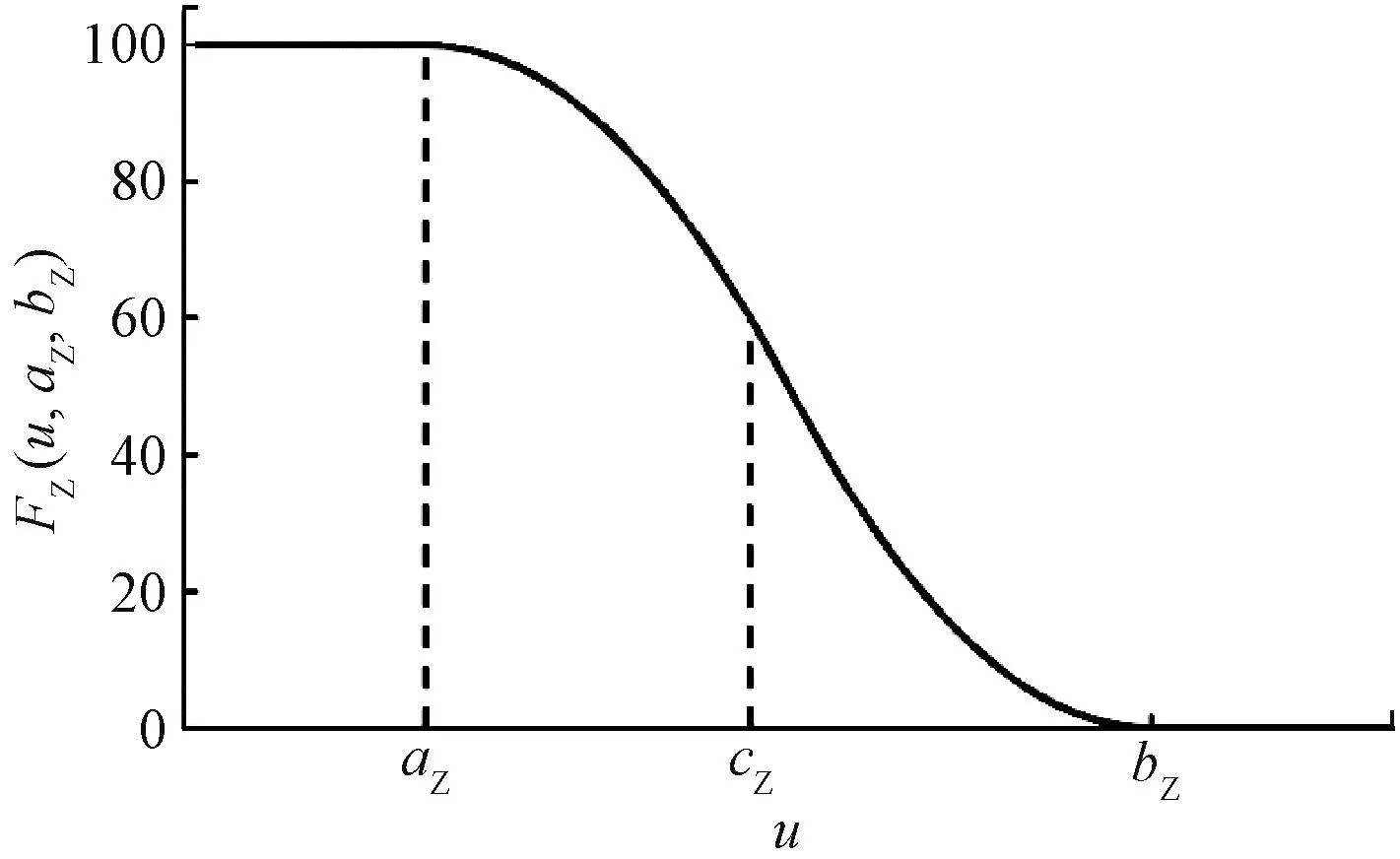
图4 Z型评价函数曲线
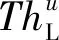
对于效益型指标,指标取值越大得分越高。定义S型评价函数FS(u,aS,bS)为
FS(u,aS,bS)=
(11)
S型评价函数曲线见图5。

图5 S型评价函数曲线
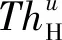
通过各指标的最大阈值和最小阈值可以计算式(10)、式(11)中的参数,进而得到各指标的评价函数。
2.3 JTC状态数据集的构建
根据现场调研与文献研究[21-22],本文对频率偏移、道砟电阻偏小和补偿电容断线等JTC典型故障及其故障组合情况下的数据进行仿真,并根据第2节中确定的评价指标和评价函数,进行指标提取和评分,构成JTC状态数据集D0,即对D0中的样本si,有
si=[sfc,isfd,is50,islq,islx,isk,iscap,i]T
(12)

3 基于机器学习的综合评价方法设计
3.1 综合评价流程
基于以上所选的评价指标,设计一种基于机器学习的JTC健康状态综合评价方法,见图6。

图6 JTC健康状态综合评价方法
首先,本文基于半监督聚类算法进行数据标注,生成带健康状态标签的JTC状态数据集;然后,训练XGBoost模型并基于SHAP计算各评价指标的权重,对于待评价的检测数据,进行指标提取和评分后,使用直接加权平均的方法构建HI,并基于表1中健康状态类别,实现综合评价。考虑铁路现场环境的复杂性,若评价结果出现偏差,则通过铁路现场实测结果对训练集进行补充,对XGBoost模型进行增量训练,以实现对指标权重的更新。
3.2 基于半监督聚类的数据标注
基于半监督聚类的数据标注算法流程见图7,其主要包括基于AHP的约束信息构建、基于局部密度的聚类中心初始化和通过成对约束集指导聚类三个步骤。

图7 基于半监督聚类的数据标注算法流程
Step1基于AHP的约束信息构建
层次分析法[23](analytic hierarchy process, AHP)作为一种常用的评价方法已经被用于JTC的健康状态评价[5,8],本文基于AHP构建算法所需的约束信息。
利用AHP计算指标权重向量wahp,进而对D0进行评价,并根据表1进行健康状态类别的划分。对D0中不同类别的样本,各随机抽取2 000个,组成数据集D,用于后续的数据标注以及指标权重确定。
采用分层抽样法[24]按照各类别样本的比例从D中抽取nS的样本构建Seed集,记为DS,即
DS={(si,e(si)]|i=1,…,|DS|c}
(13)
式中:e(si)为si基于AHP得到的健康状态类别,运算符|·|c用于计算集合DS的元素个数。
随后,根据DS构造must-link约束集Dml和cannot-link约束集Dcl。从DS中任选两个样本(si,e(si))和(sj,e(sj)),按照式(14)构造约束对,直到|Dcl|c和|Dml|c达到预设值Npw。
(14)
Step2基于局部密度的聚类中心初始化
考虑原始K-means算法的初始聚类中心是随机选取的,会影响聚类效果[25]。因此,本文结合局部密度[26]进行聚类中心的初始化,并在此基础上进行约束半监督聚类。
对于Seed集DS中的样本点(si,e(si)),通过高斯核函数定义其局部密度ρi为
(15)
式中:dc为截断距离[26];dwe(si,sj)为si和sj之间的加权欧氏距离,针对本文的健康评价问题,选择基于AHP获得的指标权重向量wahp作为距离计算权重,则基于局部密度的聚类中心初始化算法可用如下伪代码表示:
基于局部密度的聚类中心初始化算法
输入:Seed集DS,截断距离dc,指标权重wahp
输出:初始聚类中心集合DZ
1. 利用式(15)计算DS中各样本的局部密度;
2. 按照局部密度从大到小对样本进行排序;
3. 将局部密度最大的样本s1加入集合DZ;
4. while 样本si的局部密度大于等于平均局部密度
5. ifdwe(si,sj)≥2dc,sj∈DZ
6. 将样本si加入DZ;
7.i=i+1;
8. return 聚类中心集合DZ
Step3通过成对约束集指导聚类
对于D中每个样本(si,e(si)),在不违反成对约束的条件下进行划分,则有
(16)
式中:ϑ为距离(si,e(si))最近的聚类中心的类别。
Step4更新聚类中心
对zj∈DZ,重新计算聚类中心zj
(17)
式中:Dj为数据集D中以zj为中心的簇。通过交替更新样本类别和聚类中心,直到DZ中聚类中心的变化量小于给定阈值或迭代次数达到最大值。
Step5合并聚类
按照簇的类别进行合并,将si的类别记为yi,即可得到带健康状态标签的JTC状态数据集DL
DL={(si,yi)|si∈D}
(18)
采用分层抽样法[24]从DL中随机抽取80%的数据作为训练集DLT,采用交叉验证[25]的方式进行模型的训练和超参数优化;20%的数据作为测试集DLE用于模型性能评估。
3.3 指标权重的确定及HI的构建
3.3.1 基于XGBoost和SHAP的指标权重确定
XGBoost(eXtreme gradient boosting)[27]是一种基于树的梯度提升集成学习算法。该算法在梯度提升决策树(gradient boosting decision tree,GBDT)[28]的基础上进行了多项优化,具有训练速度快、精度高、易于调参和泛化性能好等优点[29]。SHAP(SHapley additive exPlanations)[30]是一种利用博弈论中的Shapley值[31]的与模型无关的可解释性方法,可以实现对模型特征重要度和特征依赖等的解释。基于XGBoost和SHAP的指标权重计算过程示意见图8。

图8 基于XGBoost和SHAP的指标权重计算过程示意

模型的生成主要包括模型初始化、构造最优决策树和模型更新3个部分。模型训练完成后,基于训练集计算各指标的Shapley值,进行相应的处理即可得到各指标的权重。具体流程如下:
1)模型初始化
对于训练集
DLT={(si,yi)|i=1,2,…,|DLT|c}
(19)
对yi进行one-hot编码有
(20)
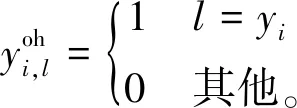
对各类别模型的初值进行初始化有
(21)
2)构造最优决策树
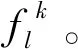


(22)
式中:sample(DLT,nx,nf)表示从训练集DLT中有放回地随机抽取比例为nx的数据样本,并无放回地随机选取这些样本比例为nf的部分指标,生成新的数据集。
Step2选择最优切分指标s*和最优切分点t*。
对于本文的多分类问题,损失函数为
(23)

(24)
(25)
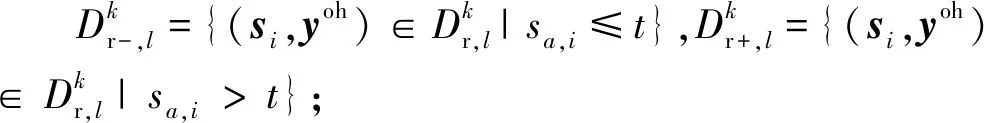
(26)

(27)
Step3生成子节点。
对所有未遍历过的节点进行分裂,直到决策树深度达到预设的最大深度d,停止迭代,并令未分裂的节点成为叶节点,计算所有Na个叶节点的权重wa,i为
(28)
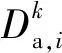
3)模型更新

(29)
当模型迭代次数达到设置的最大迭代轮数M时,则生成了图8中的XGBoost模型。
4)指标权重计算

(30)

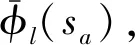
(31)
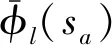
(32)

(33)

3.3.2 加权平均构建健康分数
首先,基于XGBoost模型,按照式(30)~式(33)计算指标权重向量wxgb;然后,采用直接加权的方法,对于给定的JTC区段,获得各指标的分数向量s,最后根据式(34)计算健康分数HI
HI=sTwxgb
(34)
4 实验验证
4.1 功能验证
选取检测车在某线路上检测到的典型JTC区段为实验对象,验证本文所提JTC健康状态综合评价方法各步骤的功能。该JTC在补偿电容、牵引回流干扰和低频频率方面存在一些问题,但现场反映仍能够正常工作,其检测数据见图9。
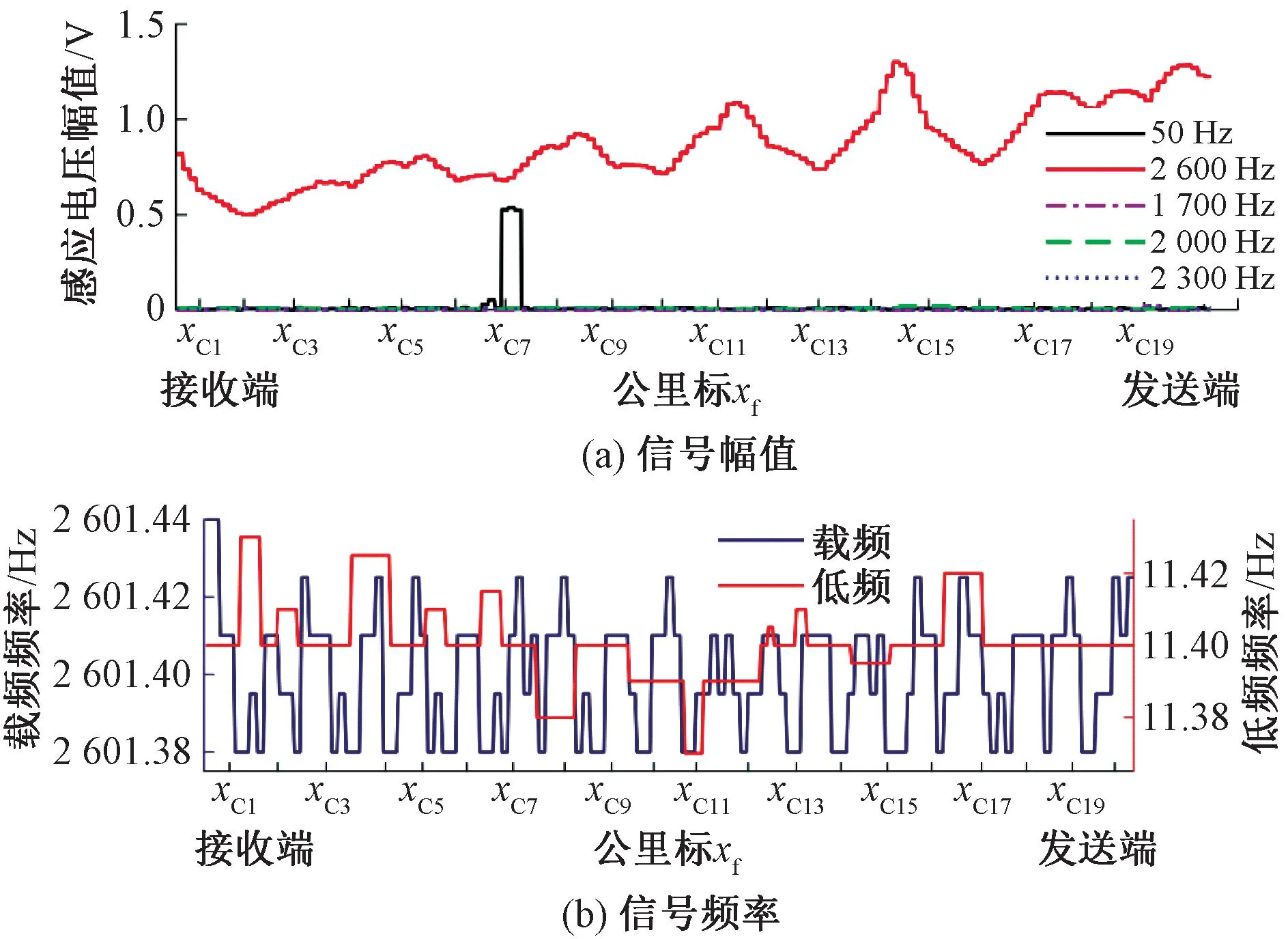
图9 典型JTC区段实际检测数据
由图9可知,在信号频率方面,该区段JTC信号的低频发生偏移,载频正常;在干扰信号方面,区段内补偿电容C7和C8之间存在较大的牵引回流干扰,邻线干扰和邻区段干扰较低;在组件参数方面,该区段内补偿电容C3和C17发生断线故障,道砟电阻正常。
4.1.1 干扰信号指标阈值确定
对277组该线路上无故障JTC的指标Rlq和Rlx数据进行统计,结果见图10。由图10可见,98.2%的JTC的Rlq小于0.46%,98.2%的JTC的Rlx小于0.73%,以此为标准分别设置指标Rlq和Rlx的评价阈值为

图10 邻区段干扰和邻线干扰指标频率分布
(35)
4.1.2 基于半监督聚类的数据标注
首先,采用AHP计算评价指标的权重向量wahp
wahp=[0.07 0.27 0.03 0.15 0.15 0.08 0.25]T
(36)
用于约束信息DS、Dml和Dcl的构建。
然后,根据3.2节中的步骤,采用基于半监督聚类的数据标注算法,对D进行标注与划分,得到带健康状态标签的训练集DLT和测试集DLE。其中,半监督聚类算法的初始参数由基于簇内凝聚度[25]的贝叶斯超参数搜索算法[32]确定。最终选定,DS的比例nS为8.54%,Npw为2 600。
4.1.3 健康分数的构建与评价
根据3.3.1节中的步骤训练XGBoost模型,用于指标权重的确定。其中,XGBoost模型的参数由基于10折交叉验证[25]的贝叶斯超参数搜索算法[32]确定。最终选定,学习率η为0.49,决策树最大深度d为13,节点分裂所需的最小增益值σ为8,子节点最小样本权重和c为0.60,行采样比例nx为89.8%,列采样比例nf为79.1%,正则化系数λ为0.59,正则化系数γ为0.07,模型迭代次数M为171。
基于训练完成的XGBoost模型,按照式(30)~式(33)计算指标权重向量wxgb
wxgb=[0.04 0.34 0.02 0.16 0.16 0.05 0.22]T
(37)

基于各指标的评价函数,得到各指标的得分sfc、sfd、s50、slq、slx、sk和scap分别为97.09,60.00,85.88,99.55,99.99,100.00,63.31。其中,区段内存在牵引回流干扰,得分s50为85.88分;补偿电容C3和C17发生断线故障,且低频偏移较大,二者得分scap和sfd分别为63.31分和60分。
对s=[sfcsfds50slqslxskscap]T,基于式(34)和式(37)计算得到健康分数HI=77.62,基于表1得到健康状态类别为“中”。考虑图9中的JTC接收端电压高于相应阈值,且TCR设备能够正常解码,列车仍能够正常运行,故本评价结果为“中”是合理的。
4.2 性能验证及合理性验证
4.2.1 性能验证
由于铁路现场JTC发生严重故障导致无法正常运行的情况较少,为了保证性能验证数据集的完备性,本文基于通过仿真与标注得到的测试集DLE验证方法的性能。测试集DLE由2 000个样本组成,其中,不同健康状态的样本个数如表2所示。

表2 测试集中各健康状态的样本个数
利用测试集DLE对模型进行测试,获取分类结果的混淆矩阵[25]Q={Qij}(1≤i,j≤NL),其中的元素Qij为实际类别为i且被预测为类别j的样本个数。基于混淆矩阵Q,可以定义Kappa系数[33]KP为
(38)

模型在测试集DLE的Kappa系数KP为0.919,根据相关研究[33],KP在[0.810,1.000]范围内,模型的性能较好,且模型的OA较高,为93.6%,说明模型具有良好的泛化性能。
随后,将“不合格”类别算作故障,将其他4种类别算作正常,将多分类问题转化为二分类问题,设:
NNF表示实际为正常而预测为故障的样本个数;NNN表示实际为正常而预测为正常的样本个数;NFN表示实际为故障而预测为正常的样本个数;NFF表示实际为故障而预测为故障的样本个数。
则模型的虚警率[25]FP、漏警率[25]FN和准确率[25]AC可以定义为
(39)
测试集DLE上的FP、FN和AC分别为3.5%、0.77%和98.55%。模型的FP和FN较低,且AC较高,说明模型具有较高的准确性。
4.2.2 指标权重合理性验证
对于测试集DLE,分别根据本文所提方法、AHP[23]、熵权法[34]和组合赋权法[35]得到的权重计算健康分数HI,并按照HI从高到低进行排序,则第i种方法的兼容度[36]Ri定义为
(40)

第i种方法的差异度[36]δi为
(41)

分别计算4种方法的兼容度和差异度,如表3所示。

表3 不同指标权重确定方法对比
根据“兼容度最大,差异度最小”原则[36],本文所提的指标权重确定方法是最合理的。
4.2.3 算法在补偿电容不同位置故障情况下的结果分析
以图3所示的补偿电容C2和C6分别断线的情况为例进行分析,将本文所提方法与文献[5]和文献[9]所提方法进行对比,补偿电容得分情况如表4所示,评价结果情况如表5所示。

表4 补偿电容得分情况对比

表5 评价结果情况对比
5 结论
ZPW-2000系列JTC是我国铁路信号设备的重要基础设备,其安全可靠的运行对保障行车安全、提高行车效率至关重要。因此,为了克服现有JTC健康状态综合评价方法的不足,本文提出基于机器学习的JTC健康状态综合评价方法。首先,基于JTC的工作原理和检测车的数据分析,构建能够反映JTC健康状态的评价指标和评价函数;然后,基于JTC仿真模型,使用故障注入技术对JTC常见故障模式下的数据进行仿真,构成JTC状态数据集,并基于半监督聚类算法进行数据标注;最后,基于XGBoost模型和SHAP计算各评价指标的权重,构造JTC健康分数HI,实现JTC健康状态的综合评价。
实验表明,本文方法能够细化评价等级、考虑故障补偿电容位置的影响、降低传统评价过程中的主观性,可有效提高检测车对JTC的健康评价能力,为实现“状态修”提供依据。
猜你喜欢
汽车实用技术(2022年14期)2022-07-30
大众标准化(2022年10期)2022-02-06
当代陕西(2020年17期)2020-10-28
铁道建筑(2020年8期)2020-09-04
减速顶与调速技术(2018年1期)2018-11-13
人大建设(2018年5期)2018-08-16
电信科学(2017年6期)2017-07-01
电源技术(2015年1期)2015-08-22
电源技术(2015年7期)2015-08-22
河南科技(2014年15期)2014-02-27
