
基于自上而下注意力机制的零样本目标检测
2024-01-03 00:00:00齐鑫伟侍洪波宋冰陶阳
华东理工大学学报(自然科学版) 2024年6期
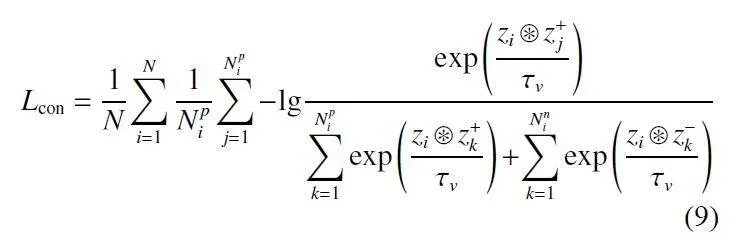


摘要:由于可见类和未见类目标数据分布的差异性,目前基于映射迁移策略的零样本目标检测算法在测试时容易偏向可见类别的目标,且因为不同类别在属性上的相似性,特征分布比较混乱。本文提出一种新的零样本目标检测框架,利用所设计的先验知识提取模块和自上而下注意力机制模块,为检测过程提供任务导向,引导模型在训练期间关注出现的未见类特征,提高模型对不同数据分布的判别性;还设计了一种新的对比约束以提高特征之间的聚类能力;在MSCOCO 标准数据集上进行了大量实验。结果表明,该模型在标准和广义零样本目标检测任务上都取得了显著效果。
关键词:计算机视觉;目标检测;零样本目标检测;自上而下注意力机制;对比约束
中图分类号:TP391.4 文献标志码:A
随着深度学习技术的不断发展,计算机视觉领域已经取得了巨大的进步,各种目标检测算法[1-3] 相继出现,显著地提升了检测性能。然而,这些目标检测算法都依赖于大规模的标注数据,由于实际场景中自然界的目标服从长尾分布[4-6],很多目标的标注数据难以获取,检测器也无法自主地将识别能力推广和优化,导致网络的性能大幅度下降。
为解决上述问题,一些研究[7-9] 提出了零样本目标检测任务(Zero-Shot Object Detection, ZSD),它的灵感源于人类可以通过以往的经验或者知识快速学习新概念,旨在同时定位和识别训练过程中未见过的新目标。目前,大多数ZSD 模型基于一种严格的映射迁移策略[10-13],即在训练阶段利用可见类别数据,结合类别语义嵌入向量,学习视觉特征到语义特征的映射函数,并将其迁移到未见类数据,识别新的目标。还有一些学者[14-16] 使用生成模型来合成未见类目标的特征,并重新训练分类器,将零样本学习过程转换成有监督学习。
然而,由于可见类数据和未见类数据之间数量不同、种类不同,数据分布存在较大差异,而模型训练时只利用可见类样本,这使得测试时容易将未见类目标识别为可见类目标,造成严重的域偏移问题,特别是当面对更具挑战性的广义零样本目标检测(Generalized Zero-Shot Object Detection, GZSD) 任务,需要同时检测出数据中的可见类别目标和未见类别目标时,模型的迁移能力会更差。为此,研究者已经做了大量的工作[17-19],但这些方法大多利用类别之间的连接关系,或者利用图卷积神经网络[20],挖掘类别属性上的关联,弥补训练时未见类别目标信息的缺失。尽管这些工作有一定的效果,它们只是学习一个通用的零样本目标检测器,忽略了检测任务对模型的引导作用,无法突出未见类目标的特征。
本文设计了一种基于自上而下的注意力机制零样本目标检测框架,利用所提出的先验知识提取模块,在训练期间注入未见类别的先验知识,为模型的训练提供任务导向,提高对未见类目标的注意力,并结合对比约束,增强同一类别之间的相似性,提高最终的检测精度。
1 研究现状
1.1 目标检测
目标检测作为计算机视觉领域最基础、最具挑战性的任务之一。近年来,随着深度学习技术的不断发展,已经得到了广泛的关注与进步,各种高效、杰出的算法[1-2, 21] 不断出现,极大地提高了检测的精度与速度。目前的目标检测模型大致分为两种形式: (1) 一阶段模型, 如SSD(Spatial PyramidPooling)[22]、YOLO(You Only Look Once)[23-24] 系列、RetinaNet[2] 等,这类模型同时进行分类和定位,因此检测速度较快; (2) 二阶段模型,如SPP-net(SpatialPyramid Pooling Convolutional Networks)[25]、Faster RCNN(Faster Region-based Convolutional NeuralNetworks)[1]、R-FCN(Region-based Fully ConvolutionalNetworks)[26]、Mask R-CNN(Mask Region-basedConvolutional Neural Networks)[27] 等,这类模型将检测过程分为两步:第1 步生成建议框,确定哪个框里包含检测目标;第2 步对高置信度的建议框进行分类和定位。由于第1 步筛选出了高质量的候选框,所以二阶段模型在算法精度上更具优势,但检测速度却逊于一阶段模型。此外,随着Transformer 的迅速崛起,为获取上下文信息,出现了许多基于Transformer的目标检测算法,如DETR(DEtection TRansformer)[21]、Deformable DETR[28]等。尽管这些方法取得了不错的效果,但它们都基于大量的训练数据,并且测试数据的目标类别与训练数据一致,无法泛化到未见类别目标的检测。由于Faster R-CNN[1] 精度较高,可扩展性较强,已经被广泛应用到很多领域,所以本文选择Faster R-CNN[1]作为研究的基础网络。
1.2 零样本学习
零样本学习[29](Zero-Shot Learning, ZSL) 是计算机视觉领域的一个经典问题,它主要模仿人类识别新目标的能力,旨在利用可见类别的信息,结合语义嵌入向量如文本描述、类别属性向量、词向量等,将分类能力从特征丰富的源域迁移到目标域,进而识别未见类别的实例。目前,关于ZSL 的研究非常多样化,如基于生成对抗网络的方法[30-33],基于独立属性分类器的方法[34-36] 等。本文主要关注的基于映射函数的方法,即利用所提供的语义信息,学习一个视觉-语义空间的映射函数。根据所映射到的空间的不同,可分为3 种类型:(1)学习将特征从视觉空间映射到语义空间的映射函数[37];(2)学习将特征从语义空间映射到视觉空间的映射函数[38];(3)将视觉特征和语义特征映射到公共的空间[39]。然而,在现实的应用场景中,我们需要的可能不仅仅是物体的类别,还需要对物体进行定位,所以ZSD 便应运而生。
1.3 零样本目标检测
ZSD 作为一个近些年新提出的任务,已经引起了不少的关注。尽管都是用来检测未见类目标,我们不能简单地将ZSL 中的方法进行复制,因为在ZSD 中单个图像可能会出现多个目标,并且还需对目标进行定位,更具挑战性。Rahman 等[7] 首次将ZSL 中的算法应用到目标检测框架,并引入一种新的聚类损失函数来对齐视觉空间和语义空间两个异构空间。Bansal 等[8] 提出了一种背景感知的目标检测器,将未见类目标从背景中分离出来。为减少噪声对分类器的影响,MS-ZSD(Multi-Space Approach toZero-Shot Object Detection)[40] 提出了一种包含视觉-语义映射和语义-视觉映射的多空间视觉语义映射方法,并引入跨模态一致性损失来保持两个模态表示的一致性。Zheng 等[13] 通过修改区域建议网络(Region Proposal Network,RPN) 学习背景向量,从而更好地区分背景和前景。Xie 等[41] 将视觉语言模型CLIP 的泛化能力转移到YOLOv3 模型上,也取得了不错的效果。除了修改模型的架构以外,Rahman 等[42]提出极性损失函数,从优化学习过程的角度,实现视觉特征和语义特征的精准匹配,缓解类不平衡问题。此外,还有许多基于生成模型的方法[9, 14]。本文采用的是基于映射的方法。
2 研究方法
2.1 问题描述
在ZSD 中,本文用Xs和Xu分别表示训练数据和测试数据,对于第 个样本,bi =(bix,biy,biw,bih)用于描述目标边界框的空间坐标和宽高尺寸,yi ∈ Ys用于描述目标的类别。假设可见类别的集合为Ys = {y1,y2,…, ys},未见类别的集合为Yu = {ys+1,ys+2,…, ys+u}其中,可见类别与未见类别不相交,即Ys∩Yu = ∅,Ys ∪Yu = Y,Y表示类别总数。对于每个类别,本文使用一个 维的语义嵌入向量(word2vec[43]) 辅助进行知识的转移,其中,可见类别的语义嵌入向量表示为Vs ∈Rd×s, 未见类别的语义嵌入向量表示为Vu ∈Rd×s,s和 u分别代表可见类别和未见类别的数量,d代表向量维度。ZSD 的任务为利用只包含可见类别标签的训练数据Xs,结合语义嵌入向量V,训练一个目标检测器识别和定位未见类别的目标。
2.2 模型架构
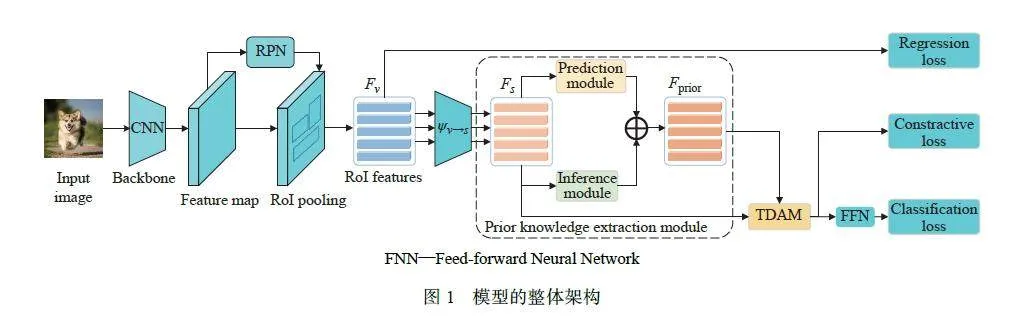
本文提出的ZSD 框架如图1 所示,ResNet[44] 作为主干网络,学习图像级的视觉特征,利用RPN 结合池化操作生成建议框(Region of Interest, RoI),最后利用一个分类分支和回归分支完成分类和定位任务。
对于分类分支,利用可见类样本数据,学习映射函数ψ v→s(·),将视觉特征映射到语义空间,即
Fs =ψ v→s(Fv) (1)
其中:Fv ∈ Rn×dv代表视觉特征, 表示RoI 的个数,dv = 1 024表示视觉特征的维度,Fs ∈ Rn×d表示映射到语义空间的特征,d = 300代表语义特征的维度,映射函数ψ v→s(·)通过多层感知机实现。将映射特征Fs传入新提出先验知识提取模块,如图1 虚线框所示,结合特征编码器,生成具有任务导向的先验辅助特征Fprior ∈ Rn×d;利用自上而下的注意力机制模块(Top-Down Attention Module, TDAM) 完成特征的融合,并使用余弦相似度进行类别预测。本文的分类损失Lcls采用交叉熵损失。
对于回归分支,考虑到Faster R-CNN[1] 采用的类不可知方式,具有较强的可移植性,所以本文沿用了Faster R-CNN[1] 中的边界框预测方式,并使用SmoothL1损失进行约束。
为提高相同类别特征之间的聚类能力,本文新增一个对比损失Lcon,对各个分量进行监督,优化网络参数。所以本文多任务损失如下:
Lzsd = Lcls + Lcon +SmoothL1 (2)
2.3 先验知识提取模块
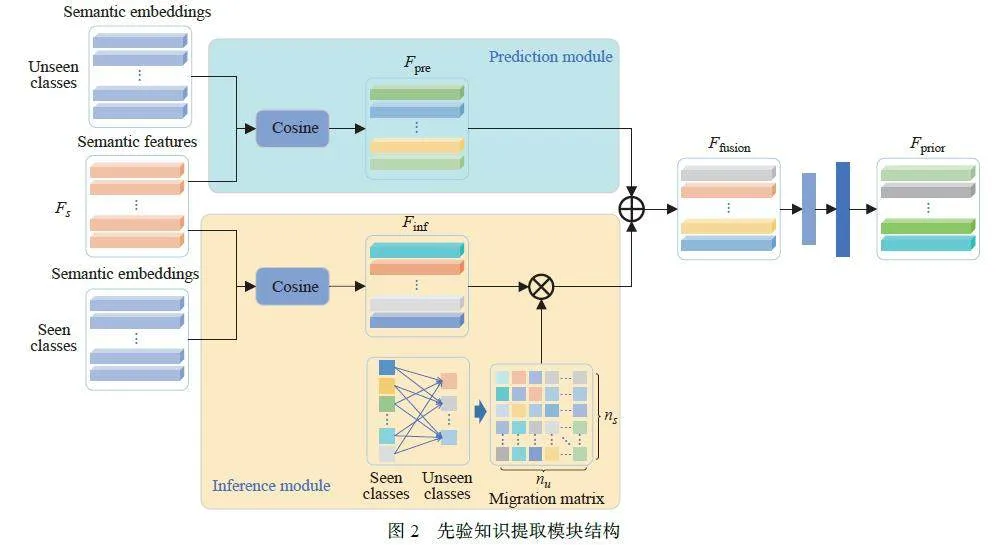
自上而下注意力的关键在于先验知识的获取,通过利用与任务有关的先验知识,引导模型对底层特征的处理,使模型朝着与当前任务相关的方向优化,从而缓解ZSD 测试时向可见类物体偏移的现象,提高未见类别目标的检测精度。基于此,本文设计了一个先验知识提取模块,如图2 所示。
整个先验知识提取模块包含两部分:预测模块和推理模块。在预测模块中,为了使每个RoI 都有与之对应的未见类别的引导信息,本文利用Fs ∈ Rn×d以及未见类的语义嵌入向量Vu ∈ Rd×u,得到一个预测特征Fpre ∈ Rn×u, 其中Fpre = Pcos(S,Vu),Pcos表示两个矩阵之间的余弦相似度,即
其中:A ∈ Rn×k,B ∈ Rm×k,⊗表示克罗内克积,⊘表示哈达玛除法。为排除一些低关联程度信息的混淆和误导,对于维度为 的预测特征,本文选取相似度值最大的5 个类别特征进行保留,并将剩余维度置0。
对于推理模块,首先利用映射后特征S ∈Rn×d并结合可见类别的语义嵌入向量Vs ∈ Rd×s,得到推理特征F′inf∈ Rn×s = Pcos(S,Vs)。为将推理特征映射到与预测特征相同的维度以便后续融合,利用可见类别与未见类的语义嵌入向量生成一个迁移矩阵, 即Wtransfer ∈ Rs×u = Pcos(Vs,Vu)。同样保留5 个最相似的类别特征, 将剩余维度置0, 最终的推理特征Finf =WtransferF′inf,其中Finf ∈ Rn×u。
对于融合特征Ffusion,本文采取加和的方式,即Ffusion = Fpre + Finf Ffusion ∈ Rn×u。为使所得先验知识与映射后的特征相融合,本文利用编码架构,将融合特征编码到和语义特征相同的维度,得到最终的先验特征Fprior ∈ Rn×d,编码器通过多层感知机实现,即Fprior = MLP(Ffusion)。
2.4 自上而下的注意力模块
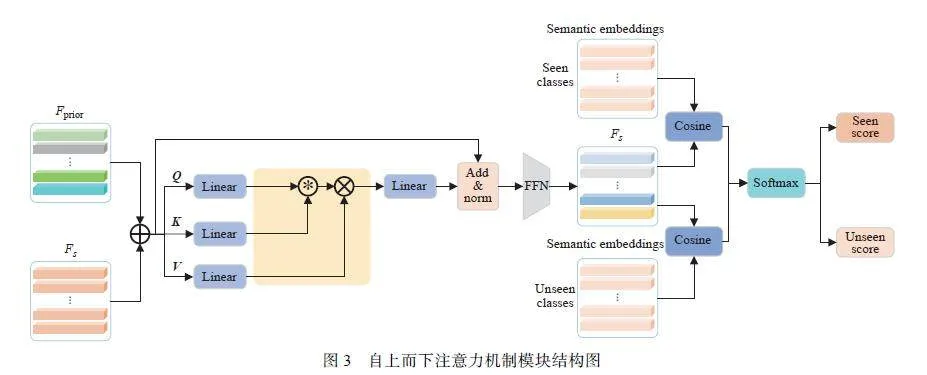
对于语义特征 Fs ,与语义嵌入向量 V 不同,即使属于同一类别,由于目标属性之间的差异,如颜色、大小,它们的特征也千差万别。而且由于训练过程缺乏未见类的知识,这使得测试结果更容易偏向可见类别目标。而自上而下的注意力机制,由于存在先验知识,可以为模型提供任务导向,使模型不再直接忽略训练期间出现的未见类物体的视觉特征,简单将其归为背景信息,而是会提高对未见类别物体的敏感性,选择性地保留和筛选,更加聚焦于和最终检测任务相关的特征,进而缓解域偏移现象的发生,提高检测的准确性。基于此,本文设计了图3 所示的自上而下的注意力机制模块,对语义特征进行动态更新。
首先,为使获取的先验知识和语义特征更好地融合, 本文引入一个可学习的动态参数α,使得Fs = Fs +αFprior。注意力机制模块中的Q、 K、 V向量,通过如下方式计算:
Q = Fs"⊗WQ (4)
K = Fs"⊗WK (5)
V = Fs"⊗WV (6)
其中:WQ ∈ Rd×d,WK ∈ Rd×d,WV ∈ Rd×d,分别通过一个线性层训练而来。由于点积运算容易受向量绝对大小和方向的影响,本文使用余弦相似度代替点积进行相似度的运算,提高模型对数据方向和特征结构的鲁棒性。注意力机制的输出Fatten ∈ Rn×d如下:
Fatten = Softmax(Q⊛ K)⊗V (7)
其中: ⊛ 表示余弦相似度。
为缓解梯度消失问题,本文引入残差连接并伴随层归一化操作,同时在前馈网络中,采用更加平滑的GELU(Gaussian Error Linear Unit)[45] 激活函数。最终模型的输出Fout ∈ Rn×d如下:
Fout = FFN(layerNorm(Fs + Fatten)) (8)
2.5 对比学习
注意力机制通常更加关注局部和上下文特征,从而帮助模型更好地理解图像信息,但它却不会主动提高同一类别之间的相似性。为此,本文引入一个对比损失函数,提高模型的聚类能力,对于第 个区域建议zi,在当前批次下, 将与之类别相同的RoI 作为正样本,记为z+,将类别不同的RoI 作为负样本,记为z-。区域对比损失函数如下:
其中:Npi表示当前批次下,对于zi 而言,和它类别相同的正样本个数;Nni表示类别不同的负样本个数;τv表示超参数;N表示RoI 的总数。
在语义空间中,对于任意两个实例特征,通过施加对比约束,可以充分利用标签信息,拉近类别相同的实例在特征空间中的距离,提高其相似程度和聚类效果,使类内特征更加紧密。此外,为进一步减少向量绝对大小的干扰,与前人研究[46] 不同,本文抛弃了点积的计算方式,利用余弦相似度来衡量类别之间的相似性。
2.6 模型预测
对于目标的预测类别,本文通过计算模型最终输出Fout和语义嵌入向量V的余弦相似度进行判断,即在训练过程中,对于可见类别目标的预测概率ps ∈ Rn×s:
ps = Pcos(Fout,Vs) (10)
在测试过程中,对于未见类别目标的预测概率pu ∈ Rn×u:
pu = Pcos(Fout,Vu) (11)
3 实验部分
3.1 数据集和实验设置
(1) 数据集:本文在MSCOCO 2014[47] 目标检测数据集上评估提出的方法。考虑到未见类的稀有性和多样性,本文采用了可见类/未见类(65/15)[42] 和可见类/未见类(48/17)[8] 的分割方式。
(2) 语义嵌入:对于所用到的语义嵌入信息,本文延续前人研究[48] 的策略,使用来自word2vec[43] 的300 维语义向量用于MSCOCO 数据集。
(3) 实现细节: 重新调整图片大小, 以确保MSCOCO 数据集的最小边长分别为600 和800。本文选择在ImageNet[49] 上预训练的ResNet-101[44] 作为主干网络,提取多尺度特征,并使用学习率为0.001、动量为0.9 的SGD 优化器优化所提出的模型。在对比约束中,对于超参数τv,本文设置为0.01。
(4) 评价指标:对于MSCOCO 数据集,选择平均精度(mAP) 和Recall 作为评价指标。本文在标准(ZSD) 和广义零样本目标检测(GZSD) 设置下进行了实验,并评估了谐波均值(Harmonic Mean, HM)来展示GZSD 的性能,其中, mAP 的 HM 可通过式(12)计算:
HM =2×mAP×mAP/mAP+mAP(12)
3.2 实验比较
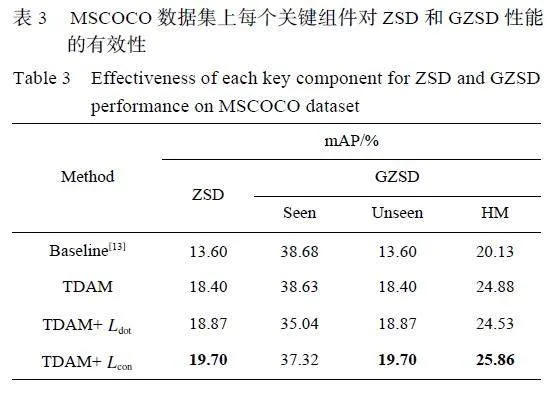
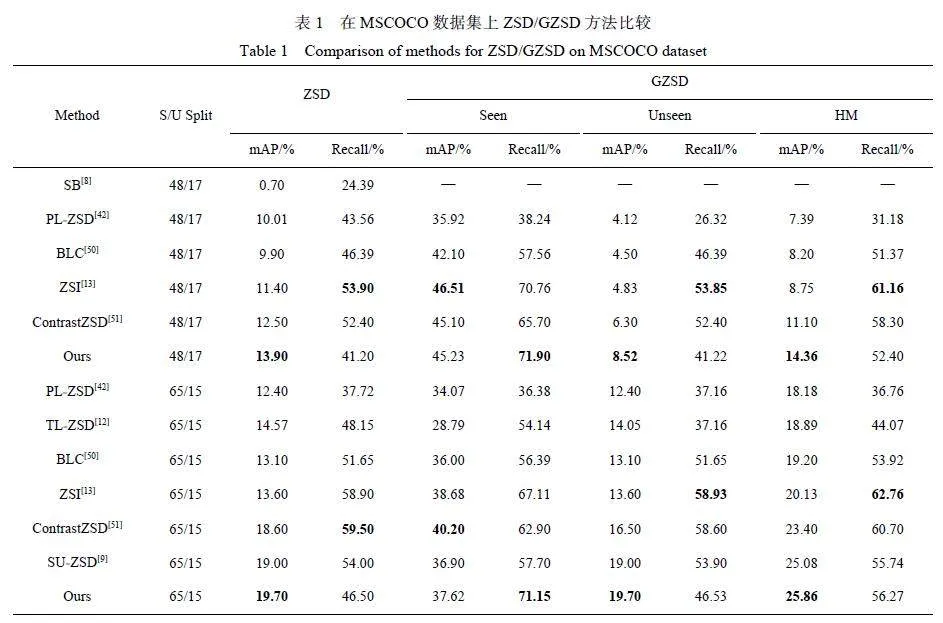
(1) ZSD/GZSD 性能。如表1 所示,本文将所提出的模型与SB[8]、PL-ZSD[42]、TL-ZSD[12]、BLC[50]、ZSI[13]、ContrastZSD[51] 和SU-ZSD[9] 等方法在MSCOCO 上对ZSD 和GZSD 的性能进行了比较。从表中可以看出,在ZSD 任务中,不管是采用65/15 的划分方式还是48/17 的划分方式,该模型在最具挑战性的指标mAP 上都达到了最佳性能,尤其是在65/15 的划分方式中,分别比PL-ZSD[42]、TL-ZSD[12]、BLC[50]、ZSI[13]、ContrastZSD[51]、SU-ZSD[9] 高出7.30%、5.13%、6.60%、6.10%、1.10%、0.70%,这些提升都表明了模型的有效性。对于更具挑战性的GZSD 任务,虽然未见类和可见类物体同时存在,该模型也有显著的性能提升, 尤其是对于可见类的召回率、未见类的mAP和HM 的mAP 指标,它们都达到了最佳性能。这进一步说明本文所提出的先验知识获取模块可以很好地提取先验知识,为最终的未见类检测任务提供任务导向,同时也表明模型在缓解域偏移、提高未见类类别物体的判别性方面的有效性,可以更好地实现可见类到未见类的知识转移。
由于余弦相似度不受向量尺度变换的影响,在高维空间中仍能捕捉语义特征之间的关联,此外,语义嵌入向量的生成模型[43] 也采用余弦相似度进行特征匹配,所以本文使用余弦相似度代替矩阵乘法进行类别判断。不过,余弦相似度只考虑特征向量的方向,对于一些复杂的特征,可能无法捕捉特征之间的非线性关系和特征匹配情况,这也导致在表1 中,该模型在未见类Recall 指标上表现并不是很优异。但mAP 考虑了模型在不同交并比(Intersection overUnion, IoU) 阈值下的精度,对模型的性能进行了更全面的评估,因此,mAP 可以更有力地衡量一个模型的质量。所以,尽管该方法在召回率指标上表现不是最佳,mAP 指标上的表现仍能说明模型的有效性。
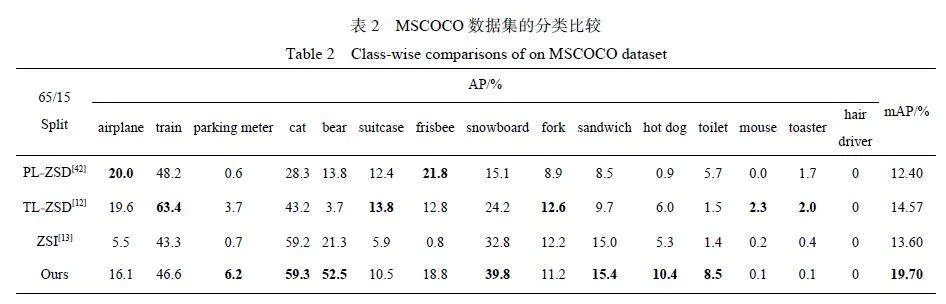
(2) 类别性能。为了进一步展示该模型在MSCOCO 数据集上的优势,本文在表2 上给出了每个类别的精度(AP)和mAP。如表2 所示,在mAP标准下,和其他模型相比,该模型具有显著优势,对于某些类别的AP,也获得了很好的增益,例如bear、snowboard、hot dog 等类别。但由于此方法是利用可见类与未见类之间的相似性来生成先验知识,进而为最终检测任务提供任务导向,所以在类别AP 中,对于那些可见类与未见类相似度较低的类别,例如hair driver等,类别之间的弱关联性大大提高了知识转移的难度,不能很好地生成有价值的先验信息,因此它们的检测效果很差。
(3) 定性分析。为了进一步定性地分析检测性能,本文在图4 中可视化了MSCOCO 数据集上的一些ZSD 和GZSD 的检测结果。从图中可以看出,和ZSI[13] 相比,该模型可以正确地检测出不同场景下的未见类物体,如单类别单物体(如toilet)、单类别多物体(如suitcase、cat)、多类别多物体(如train、snowboard、parking meter),而ZSI[13] 则出现了不同程度的漏检现象。同时,在GZSD 任务中,本文的方法也有不错的检测效果,而ZSI[13] 不仅会出现错误分类的情况(如将frisbee 识别成surfboard、将cat 识别为dog),还会出现漏检现象(如skis、traffic light)。这些例子都证明了该模型在ZSD 和GZSD 任务中的有效性。
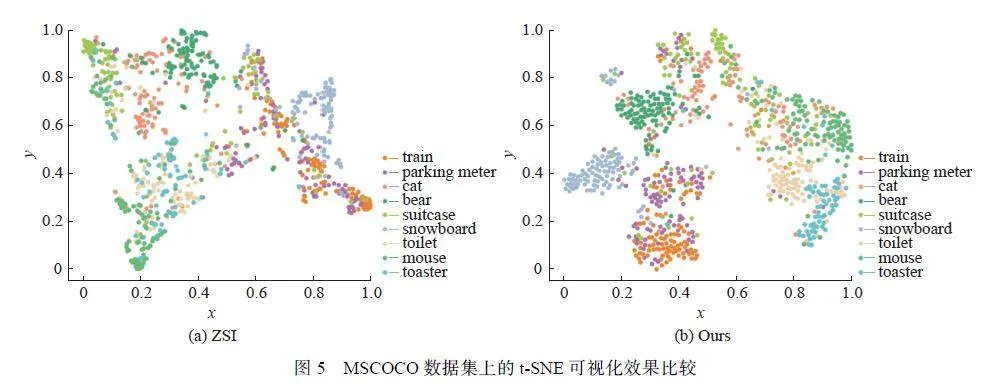
为了进一步证明该模型在特征聚类方面的有效性,本文在MSCOCO 数据集上随机选取了9 个未见类别, 利用t-SNE[52] 对特征进行了可视化, 并与ZSI[13] 进行对比,如图5(a) 和图5(b) 所示。可以发现,ZSI[13] 中未见类的特征整体分布比较混乱,类内距离较大,比如图5(a) 中的“bear”、“train”等类别,这非常容易造成类别的混淆从而出现误分类的现象。相比之下,可以清楚地看到本文的方法在未见类别上表现出更高的类内紧密度,比如“train”、“parkingmeter”、“toaster”等类别。这表明该模型可以更好地捕捉特征的基本数据分布,提高特征之间的判别性,使得相似的类别更加聚集。
3.3 消融实验
为研究各个组件的作用,本文进行了细致的消融实验来进行定量分析,表3 示出了MSCOCO 数据集上基于mAP 的ZSD 和GZSD 性能。可以发现,和基线模型相比,本文所设计的自上而下的注意力机制模块效果显著,mAP 提升4.80%,这说明通过为最终的检测任务提供任务引导,可以很好地提高模型对未见类目标的注意力,增大模型对可见数据和未见类数据分布的区分性,缓解域偏移现象。在施加对比约束后,模型检测效果进一步提升,这说明本文的方法在优化特征分布、提高聚类效果方面的有效性。此外,为进一步验证所提出的对比约束的合理性,本文与前人[46] 所提出的点积计算方式进行对比,从表3 中可以看出,尽管二者都可以进一步提升检测精度,前者的效果更加显著,这说明了余弦相似度更适合语义特征之间权值的计算,在进行对比约束时也更加有效。
4 结 论
本文提出了一种基于自上而下注意力机制的零样本目标检测框架,探索充分利用未见类的语义知识引导模型对目标进行分类和定位。该模型通过结合先验知识提取模块和自上而下注意力机制模块,为检测任务提供任务导向,引导模型对底层特征的处理,增强模型对可见类和未见类数据分布的区分性;同时利用对比约束,增强映射特征的判别能力,进而更好地对齐视觉空间和语义空间,提高模型的性能。实验结果表明,该模型在各种基准的标准和广义零样本目标检测任务中都取得了满意的检测结果。
参考文献:
[ 1 ]REN S, HE K, GIRSHICK R, et al. Faster R-CNN:Towards real-time object detection with region proposalnetworks[J]. IEEE Transactions on Pattern Analysis andMachine Intelligence, 2016, 39(6): 1137-1149.
[ 2 ]LIN T Y, GOYAL P, GIRSHICK R, et al. Focal loss fordense object detection[J]. IEEE Transactions on PatternAnalysis and Machine Intelligence, 2020, 42(2): 318-327.
[ 3 ]沈震宇, 朱昌明, 王喆. 基于MAML 算法的YOLOv3 目标检测模型[J]. 华东理工大学学报(自然科学版), 2022,48(1): 112-119.
[ 4 ]JI Z, FU Y, GUO J, et al. Stacked semantics-guided attentionmodel for fine-grained zero-shot learning[J]. Advancesin Neural Information Processing Systems, 2018, 31: 5995-6004.
[ 5 ]JIANG C, XU H, LIANG X, et al. Hybrid knowledgerouted modules for large-scale object detection[J].Advances in Neural Information Processing Systems,2018, 31: 1559-1570.
[ 6 ]XU H, JIANG C, LIANG X, et al. Spatial-aware graphrelation network for large-scale object detection[C]//2019 IEEE/CVF Conference on Computer Vision and PatternRecognition (CVPR). Long Beach, CA, USA: IEEE,2019: 9290-9299.
[ 7]RAHMAN S, KHAN S, PORIKLI F. Zero-shotobject detection: Learning to simultaneously recognize andlocalize novel concepts[C]//14th Asian Conference onComputer Vision (ACCV). Perth, AUSTRALIA: Springer,2018: 547-563.
[ 8 ]BANSAL A, SIKKA K, SHARMA G, et al. Zero-shotobject detection[C]//15th European Conference on ComputerVision (ECCV). Munich, Germany: Springer, 2018:397-414.
[ 9 ]HAYAT N, HAYAT M, RAHMAN S, et al. Synthesizingthe unseen for zero-shot object detection[C]//15th AsianConference on Computer Vision (ACCV). Kyoto, Japan:Springer, 2020: 155-170.
[10]DEMIREL B, CINBIS R G, IKIZLER-CINBIS N. Zeroshotobject detection by hybrid region embedding[EB/OL].(2018-5-16)[2018-5-17]. https://doi.org/10.48550/arXiv.1805.06157.
[11]LI Z, YAO L, ZHANG X, et al. Zero-shot object detectionwith textual descriptions[C]//33rd AAAI Conference onArtificial Intelligence. Honolulu, HI: AAAI, 2019: 8690-8697.
[12]RAHMAN S, KHAN S, BARNES N. Transductive learningfor zero-shot object detection[C]//2019 IEEE/CVFInternational Conference on Computer Vision (ICCV).Seoul: IEEE, 2019: 6081-6090.
[13]ZHENG Y, WU J, QIN Y, et al. Zero-shot instancesegmentation[C]//2021 IEEE/CVF Conference on ComputerVision and Pattern Recognition (CVPR). TN, USA:IEEE, 2021: 2593-2602.
[14]HUANG P, HAN J, CHENG D, et al. Robust regionfeature synthesizer for zero-shot object detection[C]//2022 IEEE/CVF Conference on Computer Vision andPattern Recognition (CVPR). New Orleans, LA, USA: IEEE,2022: 7612-7621.
[15]SARMA S, KUMAR S, SUR A. Resolving semanticconfusions for improved zero-shot detection[EB/OL].(2022-12-12) [2023-2-15]. https://doi.org/10.48550/arXiv.2212.06097.
[16]ZHU P, WANG H, SALIGRAMA V. Don't even look once:Synthesizing features for zero-shot detection[C]//2020IEEE/CVF Conference on Computer Vision and PatternRecognition (CVPR). Seattle, WA, USA: IEEE, 2020:11690-11699.
[17]LI Y, LI P, CUI H, et al. Inference fusion with associativesemantics for unseen object detection[J]. Proceedings of the AAAI Conference on Artificial Intelligence, 2021, 35(3):1993-2001.
[18]LV W, SHI H, TAN S, et al. Cross-domain constrained networkfor zero-shot object detection[EB/OL]. (2022-10-31)[2022-12-1]. https://doi.org/10.21203/rs.3.rs-2208626/v1.
[19]YAN C, ZHENG Q, CHANG X, et al. Semantics-preservinggraph propagation for zero-shot object detection[J].IEEE Transactions on Image Processing, 2020, 29: 8163-8176.
[20]KIPF T N, WELLING M. Semi-supervised classificationwith graph convolutional networks[EB/OL]. (2016-9-9)[2016-10-24]. https://doi.org/10.48550/arXiv.1609.02907.
[21]CARION N, MASSA F, SYNNAEVE G, et al. End-to-endobject detection with transformers[C]//European Conferenceon Computer Vision. Cham: Springer, 2020: 213-229.
[22]LIU W, ANGUELOV D, ERHAN D, et al. SSD: Singleshot multibox detector[C]//Computer Vision–ECCV 2016:14th European Conference. Amsterdam, Netherlands:Springer, 2016: 21-37.
[23]REDMON J, FARHADI A. YOLOV3: An incremental improvement[EB/OL]. (2018-4-8) [2018-5-20]. https://doi.org/10.48550/arXiv.1804.02767.
[24]ZHU X, LYU S, WANG X, et al. TPH-YOLOv5:Improved YOLOv5 based on transformer prediction headfor object detection on drone-captured scenarios[C]//2021IEEE/CVF International Conference on Computer VisionWorkshops (ICCVW). Montreal, BC, Canada: IEEE, 2021:2778-2788.
[25]HE K, ZHANG X, REN S, et al. Spatial pyramid pooling indeep convolutional networks for visual recognition[J]. IEEETransactions on Pattern Analysis and Machine Intelligence,2015, 37(9): 1904-1916.
[26]DAI J, LI Y, HE K, et al. R-FCN: Object detection viaregion-based fully convolutional networks[EB/OL]. (2016-5-20)[2016-6-21]. https//doi.org/10.48550/arXiv.1605.06409.
[27]HE K, GKIOXARI G, DOLLáR P, et al. MaskR-CNN[C]//2017 IEEE International Conference on ComputerVision (ICCV). Venice, Italy: IEEE, 2017: 2980-2988.
[28]ZHU X, SU W, LU L, et al. Deformable DETR: Deformabletransformers for end-to-end object detection[EB/OL].(2020-10-8)[2020-11-30]. https://doi.org/10.48550/arXiv.2010.04159.
[29]XIAN Y, LAMPERT C H, SCHIELE B, et al. Zero-shotlearning: A comprehensive evaluation of the good, the badand the ugly[J]. IEEE Transactions on Pattern Analysis andMachine Intelligence, 2018, 41(9): 2251-2265.
[30]XIAN Y, LORENZ T, SCHIELE B, et al. Feature generatingnetworks for zero-shot learning[C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition(CVPR). Salt Lake City, UT: IEEE, 2018: 5542-5551.
[31]YAN C, CHANG X, LI Z, et al. Zeronas: Differentiablegenerative adversarial networks search for zero-shot learning[J]. IEEE Transactions on Pattern Analysis and MachineIntelligence, 2021, 44(12): 9733-9740.
[32]SU H, LI J, CHEN Z, et al. Distinguishing unseen fromseen for generalized zero-shot learning[C]//2022 IEEE/CVFConference on Computer Vision and Pattern Recognition(CVPR). New Orleans, LA, USA: IEEE, 2022: 7875-7884.
[33]YANG J, SHEN Q, XIE C. Generation-based contrastivemodel with semantic alignment for generalized zero-shotlearning[J]. Image and Vision Computing, 2023, 137:104758.
[34]HUYNH D, ELHAMIFAR E. Fine-grained generalizedzero-shot learning via dense attribute-basedattention[C]//2020 IEEE/CVF Conference on ComputerVision and Pattern Recognition (CVPR). Seattle, WA,USA: IEEE, 2020: 4482-4492.
[35]ZHANG Z, YANG G. Exploring attribute space with wordembedding for zero-shot learning[C]//2022 InternationalJoint Conference on Neural Networks (IJCNN). Padua,Italy: IEEE, 2022: 1-8.
[36]CHEN S, HONG Z, XIE G S, et al. MSDN: Mutuallysemantic distillation network for zero-shot learning[C]//2022 IEEE/CVF Conference on Computer Vision and PatternRecognition (CVPR). New Orleans, LA, USA: IEEE,2022: 7602-7611.
[37]XIAN Y, AKATA Z, SHARMA G, et al. Latent embeddingsfor zero-shot classification[C]//2016 IEEE Conferenceon Computer Vision and Pattern Recognition (CVPR).Las Vegas, NV, USA: IEEE, 2016: 69-77.
[38]MENG M, ZHAN X, WU J. Joint discriminative attributesand similarity embeddings modeling for zero-shot recognition[J]. Neurocomputing, 2020, 399: 117-128.
[39]ANNADANI Y, BISWAS S. Preserving semantic relationsfor zero-shot learning[C]//2018 IEEE/CVF Conference onComputer Vision and Pattern Recognition. Salt Lake City,UT, USA: IEEE, 2018: 7603-7612.
[40]GUPTA D, ANANTHARAMAN A, MAMGAIN N, et al.A multi-space approach to zero-shot object detection[C]//2020 IEEE Winter Conference on Applications of ComputerVision (WACV). Snowmass, CO, USA: IEEE, 2020:1198-1206.
[41]XIE J, ZHENG S. Zero-shot object detection through vision-language embedding alignment[C]//2022 IEEE InternationalConference on Data Mining Workshops (ICDMW).Orlando, FL, USA: IEEE, 2022: 1-15.
[42]RAHMAN S, KHAN S, BARNES N. Polarity loss for zeroshotobject detection[EB/OL]. (2018-11-22) [2019-4-1].https://doi.org/10.48550/arXiv.1811.08982.
[43]MIKOLOV T, SUTSKEVER I, CHEN K, et al. Distributedrepresentations of words and phrases and their compositionality[J]. Advances in Neural Information Processing Systems,2013, 26:3111-3119.
[44]HE K, ZHANG X, REN S, et al. Deep residual learning forimage recognition[C]//2016 IEEE Conference on ComputerVision and Pattern Recognition (CVPR). Las Vegas,NV, USA: IEEE, 2016: 770-778.
[45]HENDRYCKS D, GIMPEL K. Gaussian error linear units(GELUs)[EB/OL].(2016-6-27)[2016-7-8]. https//doi.org/10.48550/arxiv.1606.08415.
[46]KHOSLA P, TETERWAK P, WANG C, et al. Supervisedcontrastive learning[J]. Advances in Neural InformationProcessing Systems, 2020, 33: 18661-18673.
[47]LIN T-Y, MAIRE M, BELONGIE S, et al. Microsoft coco:Common objects in context[C]//Computer Vision–ECCV2014: 13th European Conference. Zurich, Switzerland:Springer, 2014: 740-755.
[48]RAHMAN S, KHAN S, BARNES N. Improved visualsemanticalignment for zero-shot object detection[C]//34th AAAI Conference on Artificial Intelligence. NewYork, USA: AAAI, 2020: 11932-11939.
[49]RUSSAKOVSKY O, DENG J, SU H, et al. Imagenet largescale visual recognition challenge[J]. International Journalof Computer Vision, 2015, 115: 211-252.
[50]ZHENG Y, HUANG R, HAN C, et al. Background learnablecascade for zero-shot object detection[C]//15th AsianConference on Computer Vision (ACCV). Kyoto, Japan:Springer, 2020: 107-123.
[51]YAN C, CHANG X, LUO M, et al. Semantics-guided contrastivenetwork for zero-shot object detection[J]. IEEETransactions on Pattern Analysis and Machine Intelligence,2022, 46(3): 1530-1544.
[52]VAN DER MAATEN L, HINTON G. Visualizing datausing t-SNE[J]. Journal of Machine Learning Research,2008, 9(11): 2579-2605.
(责任编辑:李娟)
基金项目: 国家自然科学基金(62073140, 62073141, 62103149); 国家重点研发计划(2020YFC1522502, 2020YFC1522505)
猜你喜欢
软件(2016年4期)2017-01-20 09:38:03
计算机应用(2016年12期)2017-01-13 20:26:21
中国新通信(2016年22期)2017-01-13 09:18:56
科教导刊·电子版(2016年28期)2017-01-10 22:25:23
无线互联科技(2016年13期)2017-01-10 02:49:09
现代电子技术(2016年22期)2016-12-26 15:42:37
电子技术与软件工程(2016年19期)2016-12-19 19:21:36
中国科技纵横(2016年17期)2016-11-30 21:49:24
科学与财富(2016年28期)2016-10-14 23:45:18
电脑知识与技术(2016年5期)2016-04-14 13:48:16
