
基于改进YOLOv5算法的钢铁表面缺陷检测
2024-01-02 14:00张世强史卫亚张绍文王甜甜
科学技术与工程 2023年35期
张世强, 史卫亚, 张绍文, 王甜甜
(1.河南工业大学信息科学与工程学院, 郑州 450001; 2.河南工业大学粮食信息处理与控制教育部重点实验室, 郑州 450001; 3.河南工业大学人工智能与大数据学院, 郑州 450001)
钢铁行业是中国国民经济的重要支柱产业之一,然而在钢材实际生产制造过程中,由于各种因素的影响,不可避免地会使个别生产的钢铁表面产生缺陷,例如,氧化轧皮、划痕等不同种类的表面缺陷。钢铁表面缺陷的产生不仅会影响钢材的外观,而且会使其抗腐蚀性、坚固性等性能严重下降,影响正常使用[1]。一旦具有缺陷的钢铁在实际生产建设中被投入使用,会造成不可逆的安全问题和严重的经济损失。因此,探索出一种高效、精确、快速的钢铁表面缺陷检测算法有着重要意义。
一般而言,人工进行钢材表面缺陷检测的方法存在易受人工主观判断、检测环境差、危险系数高等问题,同时基于传统机器视觉检测方法存在易受光线、复杂背景干扰等因素的影响,已经无法满足现代高要求的钢材表面缺陷检测要求。而基于深度学习目标检测算法得益于卷积神经网络能够在训练阶段自动完成对目标特征的提取,让其有着强大的通用性,目前众多学者已对基于深度学习的缺陷检测展开了大量的研究,提出了诸多检测方法。朱洪锦等[2]使用轻量级网络MobileNet改进了主干网络,减少了参数量,加入空洞卷积和Inception结构,提高了模型对小目标缺陷的关注度并加深网络深度。吴昉等[3]针对焊缝缺陷,提出并行残差注意力模块,提升网络模型的表达能力,设计端到端注意力引导感知的网络模型,并在X射线焊缝数据集上验证了模型的有效性,满足了焊缝缺陷的高精度检测。王红星等[4]针对销钉缺陷检测目标小且依赖上下文信息等问题,提出改进的Cascade RCNN(region-based convolutional neural networks)双阶段模型,减少了误报率并使得最终mAP(mean average precision)提升7.8%。程婧怡等[5]在YOLOv3的基础上额外增加一个小感受野的特征图层,并引入DIoU(distance-IoU)损失函数,加强小型缺陷的特征提取和定位,从而解决小型钢材缺陷漏检和缺陷特征不清晰的问题。曹义亲等[6]构建了一种带残差边的特征金字塔结构,并在网络中加入了多头注意力机制等,使模型能够兼顾到更多的特征位置和语义信息,改善了模型特征提取能力不足、模型感受野受限等问题,提高了网络的检测精度。李鑫[7]在模型的骨干网络中加入注意力机制,在模型的颈部网络中增加一个检测层,强化了特征提取能力,并使用深度可分离网络减小模型参数量,在使模型轻量化的同时更加准确、快速地检测出钢材表面缺陷的种类和位置。Guo等[8]为满足检测模型轻量化的要求,使用MobileNet-v3作为YOLOv4的主干网络,并引入反向残差结构和通道注意力机制提高缺陷检测精度。鲁鑫等[9]针对烟条拉线头缺陷检测,提出了一种改进的AAS-YOLO(adaptive anchor size with YOLOv4)算法,轻量化模型结构并减少计算量又提高了模型对缺陷的定位精度和检测速度。
针对钢材数据集表面缺陷目标存在利用特征少、易受噪声影响、目标尺度跨度大和定位精度要求高等问题,现提出一种改进的YOLOv5算法,使得算法对钢材表面缺陷的识别准确率和检测速度得到了提高,并在NEU-DET数据集上验证了算法的有效性。主要在模型中加入CA(coordinate attention)注意力机制的ASPP(atrous spatial pyramid pooling),扩大模型感受野和多尺度感知能力的同时能更好地获取特征信息;模型中加入改进的SK(selective kernel attention)注意力机制,使模型能更好地利用特征图中的频率信息,能够更好地过滤由背景产生的噪声,提升模型的表达能力;将模型损失函数替换为SIoU(SCYLLA-IoU),提升模型检测性能的同时加快模型的收敛。
1 YOLOv5算法介绍
YOLOv5是目标检测算法的一种,具有检测速度快、精度高等优点。YOLOv5在整体模型不变的基础之上,根据其深度和宽度的不同有YOLOv5s、YOLOv5m、YOLOv5l、YOLOv5x四种不同规模的版本。其中YOLOv5s模型深度最小,特征图宽度最小,因此采取YOLOv5s作为所有改进方案的基线模型。YOLOv5s的模型结构如图1所示。
由图1可以看出,YOLOv5s模型主要由输入端、主干网络、颈部网络以及头部网络四部分组成。其中模型的主干网络由切片(Focus)、卷积(Conv)、瓶颈层(C3)和空间金字塔池化(SPP)等模块组成,用于在不同图像细粒度上聚合并形成图像特征。颈部网络采用FPN(feature pyramid networks)[10]+PAN(path aggregation network)[11]结构,用于进行特征融合并将融合后的图像特征传递到头部结构。头部结构对图像特征进行预测,生成边界框并预测类别及置信度。
2 改进YOLOv5s模型
2.1 CA-ASPP模块
YOLOv5s中SPP模块采用不同尺寸的最大池化方式,进行多尺度特征融合,而ASPP[12]在其基础之上加入不同倍率的空洞卷积,确保模型在不丢失分辨率的情况下扩大卷积核的感受野,提升模型性能。ASPP结构如图2所示。
为了加强模型对特征、位置感知的敏感性并防止模型在卷积过程中一些重要特征的丢失,在ASPP中引入坐标注意力机制[13],CA能够使模型更加了解应该关注哪些内容和位置,这能让模型更能有效地提取特征信息,进一步提高检测率。CA结构如图3所示。
CA主要由坐标信息嵌入和坐标注意力生成两部分构成。坐标信息嵌入为能使用精确的位置信息捕捉到空间上的远程交互信息,将全局平均池化(global average pooling,GAP)得到全局信息分解为两个1D的特征嵌入操作。对于输入特征图X∈RC×H×W,分别使用池化核大小为(H,1)或(1,W)沿水平和垂直两个方向对每个通道进行编码。那么第c个通道,高为h,宽为w的输出特征表示为

(1)
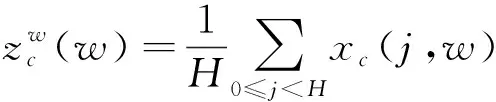
(2)
两个特征向量zh、zw,一个用于获取长距离依赖

图1 YOLOv5s网络结构Fig.1 YOLOv5s network structure

图2 ASPP网络结构Fig.2 ASPP network structure
关系,一个用于保留特征精确的位置信息,使网络能更准确地定位重要特征。
为了利用坐标信息嵌入产生的特征,在坐标注意力中,将式(1)、式(2)中产生的聚合特征zh、zw进行拼接,然后传入变换函数F1中,经过激活函数σ后得到水平和垂直两个方向的中间特征表示f∈RC/r×(H+W),其中r表示下采样比例。公式为
f=σ[F1([zh,zw])]
(3)
然后将中间特征f沿分别沿着水平和垂直两个空间维度将其拆分为两个独立的特征图张量fh∈RC/r×H和fw∈RC/r×W,再利用两个1×1卷积Fh和Fw将fh和fw变换到和输入X同样的通道数,得到结

图3 CA网络结构Fig.3 CA network structure
果表达式为
gh=σ[Fh(fh)]
(4)
gw=σ[Fw(fw)]
(5)
最后对gh和gw扩展作为注意力权重,CA最终输出表达式为

(6)
CA简单灵活即插即用,在几乎不增加模型参数量的情况下提升网络的精度。因此将其加入ASPP中,即CA-ASPP,并替换原YOLOv5s中的SPP模块,在提高模型感受野的同时使模型对特征方向、位置感知更加敏感。CA-ASPP网络结构如图4所示。
2.2 MS-SK模块
为了提升模型的表达能力,在模型中引入改进的轻量级通道注意力机制SK[14]。具体而言,SK由多分枝操作(Split)、特征融合(Fuse)和特征相加(Select)三部分构成。SK的基础结构如图5所示。
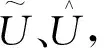

(7)

图4 CA-ASPP网络结构Fig.4 CA-ASPP network structure

图5 SK网络结构Fig.5 SK network structure
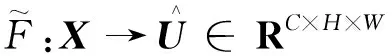
(8)


(9)
然后通过GAP来嵌入全局信息,来生成通道信息S∈RC。具体而言,S的第c个元素通过空间维度H×W来计算缩小U,公式为
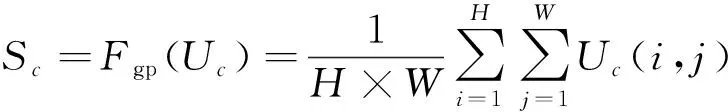
(10)
式(10)中:Fgp为全局平均池化。为了实现对特征的精确和自适应指导,通过全连接层来实现创建压缩特征Z∈Rd×1,公式为
Z=Ffc(S)=δ[Β(WS)]
(11)
式(11)中:δ为ReLU激活函数;Β为批归一化;W∈Rd×C。在特征Z的指导下,跨信道软注意能够自适应地选择不同空间尺度的信息。公式为

(12)

Select对各个卷积核的通道注意力进行融合,得到最终的特征图V,表达式为

(13)
对于一般通道注意力而言,都是以GAP来计算每个通道的标量值,并用来作为其对应通道的注意力权重,例如SE[15],CBAM[16]等。输入特征图X∈RC×H×W,得到通道注意力结果m∈RC×1×1。如公式(14)所示。但是GAP简单地去均值这种做法无法充分的获取每个通道的多样性的信息。
m=GAP(X)
(14)
文献[17]在频率分析的基础上,证明了GAP是离散余弦变换DCT(discrete cosine transform)的零频分量,并表明在通道注意力中仅使用GAP信息(既零频分量)会丢失其他频率分量的特征信息,因此引入了多频谱通道注意力(multi-spectral channel attention,MSCA)。为了能更好地利用特征图中不同频率的信息,MSCA将特征图按通道数均分,使用不同频率分量分别计算出各个通道频率分量的结果,MSCA网络结构如图6所示。为改善SK中存在的上述问题,将SK中的GAP替换为MSCA,提出一种改进的SK称为MS-SK。


(15)

图6 MSCA网路结构Fig.6 MSCA network structure
式(15)中:ui、vi为Xi频率分量的2维指数;Xi,h,w为输入的第h和w个通道;Freqi为C′维的向量。将所有组的向量Freqi拼接,就得到多频谱向量F,即
F=cat([Freq0,Freq1,…,Freqn-1])
(16)
多频谱通道注意力计算过程表达式为
m=sigmoid[fc(F)]
(17)
式(17)中:fc( )为全连接函数;sigmoid为激活函数。
综上所示,用MSCA替换SK中的GAP之后,MS-SK整体计算过程仍如式(13)所示,唯一的变化就是将生成通道信息S∈RC的式(10)中的GAP更换为MSCA,那么S的第c个元素通过空间维度H×W计算缩小的U公式为
Sc=MSCA(Uc)
(18)
2.3 SIoU损失函数
目标检测算法在训练时必须降低边界框回归损失,使得预测框在预测过程中更加接近真实框的位置和尺寸。为加快模型的收敛速度,在模型中使用SIoU[18]。SIoU由角度损失(angle cost)、距离损失(distance cost)、形状损失(shape cost)和IoU损失(IoU cost)四部分组成。
(1)角度损失的定义为

(19)
式(19)中:ch为真实框和预测框中心点的高度差;λ为真实框和预测框中心点的距离,各自定义为
(20)
(21)
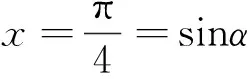
(22)

(2)距离损失定义为

(23)
(3)形状损失定义为
(24)
(4)IoU为预测框(prediction,Pre)和真实框(ground truth,GT)之间的交并比,公式为
(25)
综上所述,最终的SIoU损失公式为

(26)
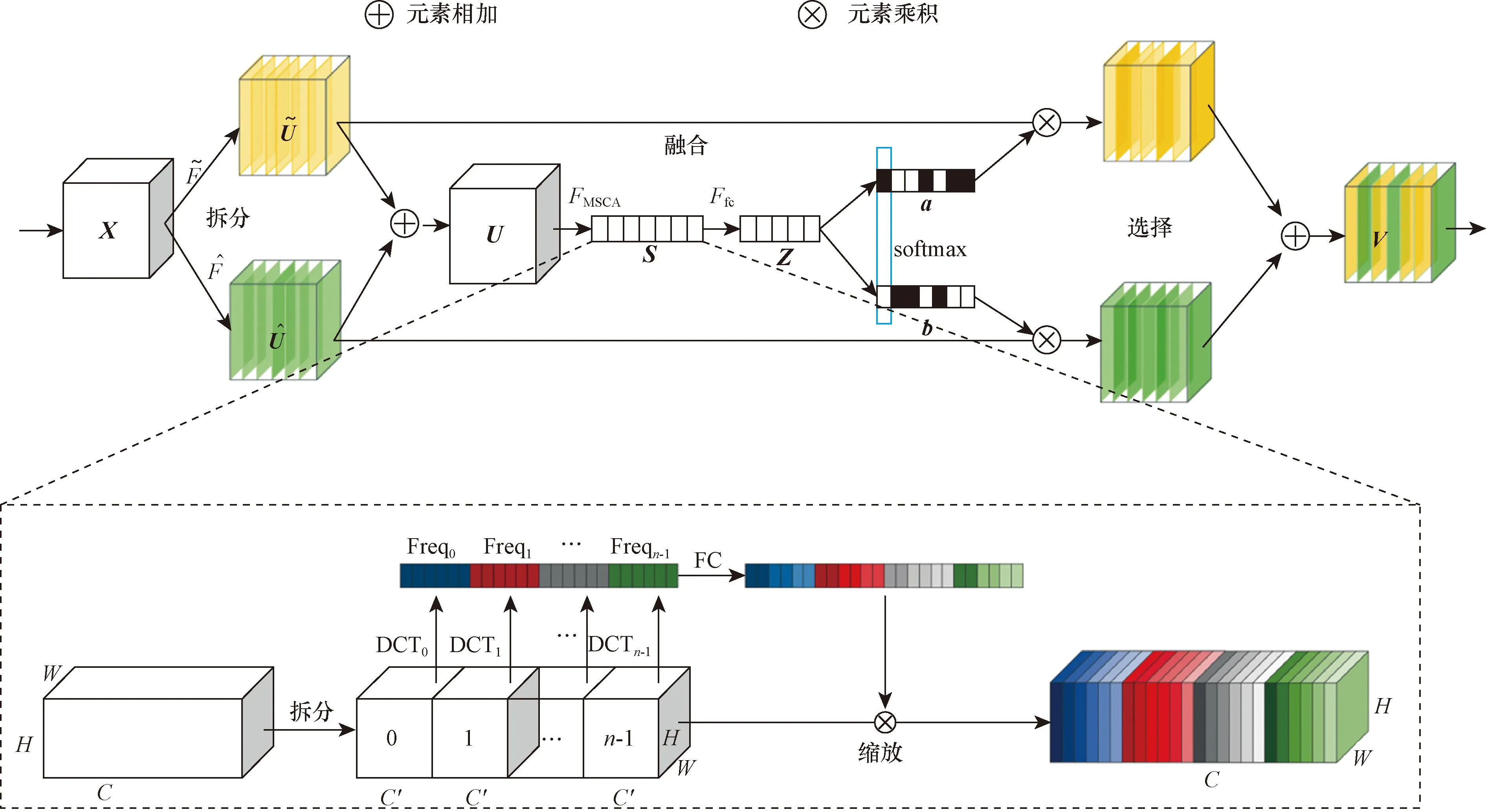
图7 MS-SK网路结构Fig.7 MS-SK network structure
3 实验结果与分析
3.1 实验环境及数据集
本文实验环境的软件和硬件配置如表1所示。
本文实验所用数据集为NEU-DET钢材表面缺陷数据集,数据集图片类别为灰度图,包含Crazing(CR)、Inclusion(IN)、Patches(PA)、Pitted Surface(PS)、Rolled-in Scale(RS)、Scratches(SC)六种缺陷类型,其中每个缺陷类别为600张,共计1 800张图片,部分数据集图片如图8所示。
训练数据集中每个类别的分布如表2所示。
由图9所示数据集缺陷宽高比分布图可知,数据集不同类别的缺陷在位置、形态、大小上差异很大。因此,为增加模型的泛化能力防止过拟合,在训练过程中使用数据增强以及标签平滑策略。模型训练以300个epoch为一轮,batch size大小为16,训练过程中使用余弦退火算法调整学习率和Adam优化器优化参数。保持上述基础参数不变,以YOLOv5s为基线模型,逐步添加改进方案进行训练和测试,并和当前部分主流模型对比分析各模型的参数和性能。

表1 实验环境的软件和硬件配置Table 1 The software and hardware configuration of the experimental environment

图8 数据集部分图片Fig.8 Partial pictures of the dataset

表2 训练数据集类别分布Table 2 Class distribution of training dataset

图9 数据集缺陷宽高分布Fig.9 Defection width and height distribution of dataset
3.2 算法评价指标
为分析模型参数和检测标准,使用平均精度(average precision,AP)作为每个缺陷类别的评估指标,使用平均精度均值(mean average precision,mAP)、检测速度FPS(frames per second)和模型参数量评估模型整体网络性能。AP和mAP具体计算公式为

(27)

(28)

(29)

(30)
式中:P、R分别为准确率和召回率;N为类别数。
3.3 实验及结果分析
3.3.1 CA-ASPP实验
为了验证模型引入CA-ASPP模块的有效性,分别将ASPP和CA-ASPP模块加入YOLOv5s模型中与YOLOv5s原SPP模块做了对比试验。模型分别使用SPP、ASPP和CA-ASPP性能效果如表3所示。
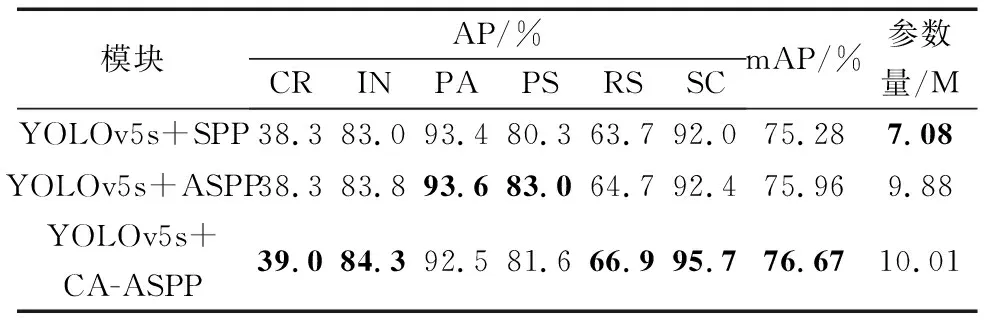
表3 模型分别使用SPP、ASPP和CA-ASPP性能效果Table 3 The performance effect of the model using SPP, ASPP and CA-ASPP respectively
从表3中可以得出,YOLOv5s模型原SPP的mAP为75.28%;使用ASPP替换SPP后,mAP提升至75.96%,相比于SPP模块mAP提升了0.68%;模型使用CA-ASPP之后,mAP提升至76.67%,相比于SPP模块mAP提升了1.39%,相比于ASPP模块mAP提升了0.71%。因此在Yolov5s模型中引入CA-ASPP模块对其性能的提升具有有效性。
3.3.2 MS-SK实验
为了验证本文改进注意力的有效性,分别选取了SE、CBAM、ECA[19]、CA等注意力机制分别加入基线YOLOv5s模型中进行检测性能对比,具体结果如表4所示。
从表4中可以得出,除SE使得模型检测效果稍微下降以外,余下所有通道注意力模块都对模型性能有一定的提升。其中CBAM使得模型提升了近一个百分点,ECA使得模型效果增益0.63%,CA使得模型检测性能提升1.32%,而本文提出的MSSK则在原SK使模型性能提升1.67%的基础之上提升至2.04%。综上所述,本文提出的MS-SK对模型的性能提升是有效的。

表4 模型分别使用不同注意力效果Table 4 Model using different attention effects
3.3.3 检测效果对比
为了更加直观地显示出改进模型和基准模型检测能力的区别,分别使用改进模型和原模型对测试集部分图片进行检测,检测结果对比如图10所示。
从检测数据中对比看出,相比于原YOLOv5s模型,改进之后的模型对测试图检测效果有了明显的提升,其中缺陷类别Inclusion、Patches和Scratches最为明显,在原模型检测中检测效果差,且大多都存在较多漏检目标,改进后的模型不仅检测效果得到了明显的提升,而且对缺陷的定位也更加准确。
3.3.4 不同算法模型性能对比
为了进一步评估本文改进算法的性能,在相同数据集划分的基准下,选取了几种主流的目标检测算法,如SSD[20],RetinaNet[21],YOLOx[22]等不同算法和本文改进算法进行检测性能比较。具体结果如表5、表6所示。
根据表5对比数据可以看出,改进算法有效对各个类别缺陷检测的AP值都有一定的提升,尤其对Crazing和Inclusion两种缺陷类别的提升最为明显;根据表6可以看出,本文改进模型mAP优于一些目前主流检测算法。相比SSD模型提升19.03%,相比YOLOv3模型提升7.0%,相比YOLOv5s原模型提升2.85%,相比YOLOx(s)模型提升1.32%。同时模型具有较高的检测速度,达到了103.9 frame/s,实现了对缺陷目标的实时检测。
综上所述,本文所提出的改进模型在检测精度和速度等方面均优于主流目标检测算法,用少量的复杂度开销换取较高检测精度的提升是极具性价比的,能够更好地投入使用钢材表面缺陷检测任务。

图10 模型检测结果对比Fig.10 Comparison of model detection results

表5 不同算法检测的各类别平均精度AP值对比Table 5 Comparison of the average precision AP value of each category detected by different algorithms

表6 各模型检测性能对比Table 6 Comparison of detection performance of each model
3.3.5 消融实验
为验证本文提出三个改进方案的有效性,用数据集NEU-DET且以原YOLOv5s为基线网络模型设计了一组消融实验,实现过程中环境及参数设置均保持不变,具体如表7所示。
由表7可知,在单个改进方案中,CA-ASPP模块的添加使得基线模型增加了1.39%,说明采用添加了CA注意力机制的ASPP模块能够在扩大模型感受野的同时,加强了模型对缺陷特征、位置感知的敏感性,使得模型性能得到提升;改进的SK注意力模型MS-SK使得模型mAP提升了2.04%,其原因在于,MS-SK能够更好地利用特征图中不同频率的信息,能够获取更加丰富的目标特征,从而更好地预测目标,提升模型的表达能力;采用SIoU替换GIoU加快了模型的收敛速度并使得模型的检测能力提升了0.18%。在进一步逐步进行消融实验过程中发现,无论是单独采用MS-SK模块,还是两两组合模块中,MS-SK模块都对模型的增益效果贡献最大。原因在于NEU-DET数据集表面缺陷目标存在利用特征少、定位精度要求高和样本不均匀等问题,而MS-SK不仅使用不同的卷积核进行特征获取,再通过分支处理最后进行特征融合,而且MS-SK弥补了通道注意力机制只关注零频的不足,能够使得模型利用不同频率的信息,增加了模型的特征提取能力和检测能力。
从消融实验中得出的数据发现,最终改进的模型得到的缺陷类别AP中,除Pitted Surface和Rolled-in Scale的类别AP稍低于只添加MS-SK和MS-SK+SIoU模块改进的模型的AP,其余缺陷类别均为最高,尤其是Crazing和Inclusion缺陷类别AP的提升最为明显,这使得模型表现最优,整体mAP效果最好。
4 结论
钢铁产业是中国最主要的经济产业之一,可用于军工、航天和日常生活的各个领域,可以说是整个国家经济发展的命脉。提升钢材表面质量管控对提升钢材性能有着重要意义。本文提出了一种改进的钢材表面缺陷检测算法,改进的YOLOV5s模型对比原模型和几种主流的目标检测算法,检测性能具有明显的优势。相比于原YOLOV5s模型,在模型参数量增加2.6 M的情况下,mAP提升了2.85%,检测速度可达103.9 frame/s。改进模型对各个缺陷类别的检测精度均有不同程度的提升,其中缺陷类别Crazing和Inclusion的检测精度提升最为明显。但改进方案给模型增长了一定的参数量且Crazing缺陷检测问题仍是主要问题,且后续本文将继续展开研究,使模型轻量化并进一步提升模型检测速度及检测精度。
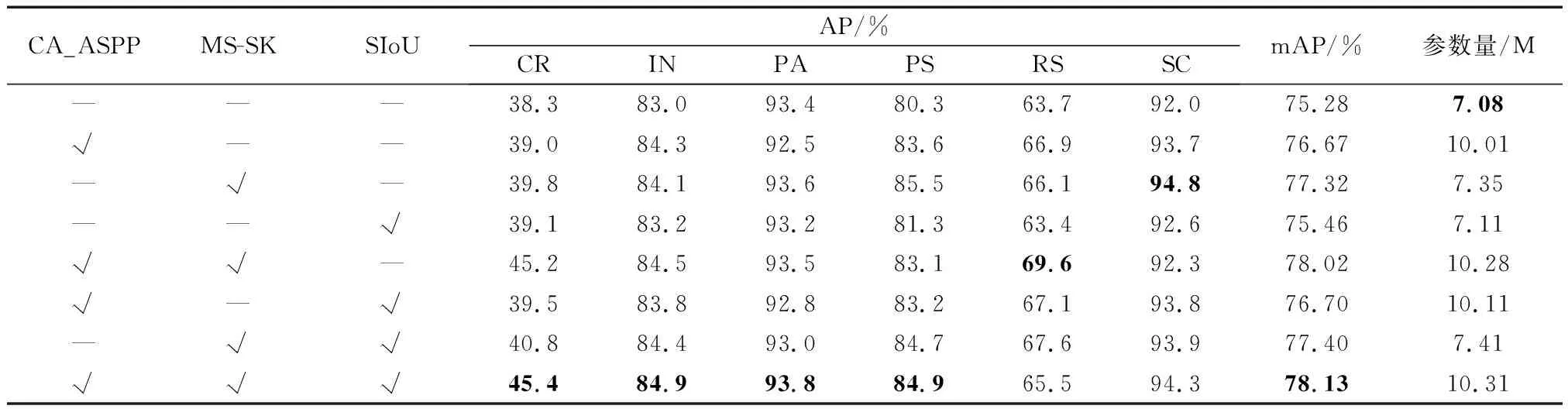
表7 改进方案的消融实验Table 7 Ablation experiments of the improved scheme
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09
疯狂英语·新策略(2019年10期)2019-12-13
当代陕西(2019年10期)2019-06-03
数学小灵通·3-4年级(2017年9期)2017-10-13
传媒评论(2017年3期)2017-06-13
第二课堂(课外活动版)(2016年2期)2016-10-21
新校长(2016年8期)2016-01-10
商事法论集(2014年1期)2014-06-27
中国中医药现代远程教育(2014年16期)2014-03-01
河南科技(2014年23期)2014-02-27
