
基于改进YOLOv5对果园环境中李的识别
2024-01-01 00:00:00贺英豪唐德钊倪铭蔡起起
华中农业大学学报 2024年5期





关键词 李; 机械采摘; 果实识别; YOLOv5; 图像处理; 注意力机制; 目标检测
李(Prunus salicina Lindl.),蔷薇科李属木本植物[1],果实香甜脆爽,营养丰富,深受人们喜爱。目前,我国李的种植面积特别广,但大部分果园机械化采摘应用非常少,果实的采摘任务都是由人工完成,增加了种植成本。机械化采摘既提高生产效率,也降低种植成本,是目前果园收获的主要发展方向之一。采摘过程中的目标识别准确率是影响机械化采摘推广重要影响因素之一。
近年来,为了解决目标因遮挡带来的漏检的问题,许多学者进行了相关研究。李欣等[2]使用YCb⁃Cr 颜色空间模型和OTSU 阈值分割技术对有遮挡的柑橘果实进行识别,检出率达到了90.48%。周文静等[3]针对田间复杂环境下传统算法识别目标准确度低的问题,选取了与人类视觉相近的RGB 颜色空间,实现了田间环境下红葡萄果穗图像的分割。杨晓珍[4]使用Gabor 小波变换和支持向量机对西红柿进行智能分类,提高了果实人工分类的效率。虽然数字图像处理技术在对各种果实识别方面有着较为广泛的应用,但是数字图像处理技术对数据进行处理和分析的过程比较复杂,并且对较为复杂背景下目标的识别效果非常不稳定,实时性较差,难以满足果园采摘任务。因此,需要一种更快、更精确、更稳定的识别方法。
随着深度学习的应用与发展,利用卷积神经网络对水果果实检测获得了优异的效果[5-8]。卷积神经网络的高特征提取能力,使其对复杂背景下目标的检测成为可能。目标检测模型主要为两阶段检测模型和单阶段检测模型。两阶段检测模型中,如Fast-RCNN[9]和Faster-RCNN[10]都是先通过区域建议网络生成区域候选框,然后再对候选框进行进一步预测从而得到检测结果。单阶段检测模型以YO⁃LO 系列模型[11-13]和SSD 系列模型[14]为代表。这些模型使用多尺度检测,融合主干网络中不同层的特征值,可以适应各种不同尺度目标的检测任务。另外还有一类anchor-free 目标检测网络,如Center⁃net[15]和Cornernet[16],它们不依赖于先验框,而是通过预测关键点从而预测出目标的位置。要实现对果园中李的正确识别,就要克服果园环境存在的背景复杂、目标被各种遮挡物遮挡等问题。石展鲲等[17]提出一种改进的Faster-RCNN 模型,通过使用Mo⁃saic 数据增强和引入Soft NMS 算法来增强模型对小目标和密集目标的识别能力,结果表明,改进后的模型的召回率可达91.44%,准确率可达93.35%。Wang 等[18]对YOLOv4 进行改进,使用深度可分离卷积网络将网络压缩至54.05 MB,并额外添加1 个检测尺度来增强模型对小目标和遮挡目标的识别能力,改进后的模型平均精度均值(mPA)可以达到88.56%,检测速度可达42.55 帧/s。杨福增等[19]基于Centernet 提出了1 种密集场景下多苹果目标的快速识别方法,通过设计Tiny Hourglass-24 轻量级骨干网络,同时优化残差模块以提高目标识别速度,并且最终模型的平均精度可达98.90%。曾乾等[20]提出一种基于SSD 的循环融合特征增强目标检测模型,使用K-means 算法改进先验框的尺寸以及引入DIoU-NMS 和ECA 注意力机制,以此来解决复杂背景下青瓜目标识别率低、定位效果不佳等问题,改进后的SSD 模型的平均精度相比于原模型提高了4.61%。但上述的改进方法存在一些不足,如在提高模型精度的同时增加了模型的计算量,使得模型的训练速度和预测速度变慢,或者在压缩模型的同时降低模型的精度,难以做到模型的规模和精度平衡。
另一方面,需要提高模型本身的性能,提高模型对果实的定位精度。郜统哲等[21]使用YOLOv3 对同发育期的杨梅进行识别,该模型对雌花开花、幼果和成熟果实的识别准确率分别可达90.91%、90.79% 和90.83%。黄彤镔等[22]提出1 种基于YOLOv5s 的改进模型,该模型通过引入CBAM 注意力模块来提高网络的特征提取能力,从而降低遮挡目标和小目标的漏检率,结果表明该模型的平均精度可达91.3%,单张图片的检测时间为16.7 ms。赵文清等[23]针对视觉模型识别小目标精度低的问题,基于CornerNet提出隔级融合特征金字塔的方法来提高小目标平均准确率,最终其精度相比于原模型有着较大的提升。
上文所述模型中,YOLOv3 的参数量较大,不适用于实时检测,改进YOLOv5s 模型则引入了额外的参数量,而CornerNet 不适用于遮挡目标的检测。
目前,针对李的目标检测研究较少,并且由于李具有自然环境复杂、枝叶遮挡等特点,使得现有模型很容易出现漏检、误检等问题,不能满足实时精确的检测。针对以上问题,本研究基于YOLOv5s 提出了一个能在复杂的果园环境下识别李的目标检测方法,旨在辅助果农检测李果实以及为果园采摘机器人等智能产品提供算法依据。
1 材料与方法
1.1 数据集采集
数据集采集于四川省成都市的李产业园区,采集设备使用佳能800D 单反相机和荣耀V9 智能手机。采集到的原始图像共621 张,其中使用单反相机采集到的图像包括6 000 像素×4 000 像素和3 984像素×2 656 像素2 种分辨率,分别有429 和89张,使用手机相机采集到103 张图像,分辨率为3 968像素×2 976 像素。另外,为增加数据丰富性,从网络上爬取各种分辨率的图像79张,共700张图像。
1.2 数据集构建
为了增强模型的鲁棒性以及数据的丰富性,同时为了防止由于数据过少发生过拟合,本研究对数据集进行数据增强处理,包括随机亮度调节、随机对比度调节、随机饱和度调节、加入高斯噪声、水平翻转、运动模糊和旋转15°[24-27]。每张图片生成7 张新图片,最终得到5 600 张图片。使用Labeling 工具标注每张图片中的李果实目标区域(图1),遮挡目标只标注其未被遮挡部分,然后按照8︰1︰1 的比例划分为训练集(4 480 张)、验证集(560 张)、测试集(560 张),每个数据集中都包含每种分辨率的图像。
1.3 检测模型
本研究以YOLOv5s 为基础进行了改进。
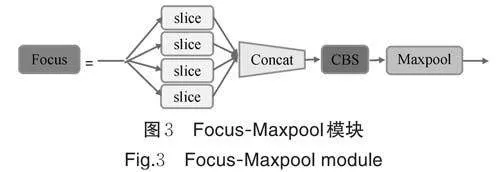
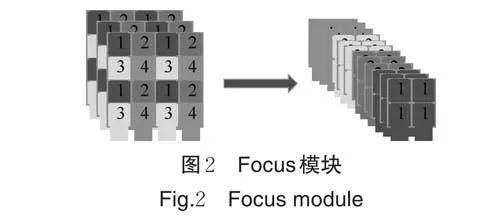
1)Focus-Maxpool(FM)模块。使用常规3×3 卷积对特征图进行下采样,不仅反向传播的参数大,而且会损失特征图信息。在果园的大视场条件下,部分李目标就显得非常小,使用常规卷积对其进行下采样时,会损失这些小目标和高遮挡目标的特征信息,从而造成漏检。在YOLOv5 中,将Focus 放在网络的输入位置,用于将输入的特征图进行2 倍下采样。其原理如图2 所示,Focus 在下采样的过程中不会丢失任何特征信息。
虽然Focus 模块在下采样过程中不会丢失信息,但下采样之后特征图通道数会变为原来的4 倍,因此,在Focus 模块之后一般会连接1 个卷积用于降维。YOLOv5 输入端的Focus 模块之后连接的是1个3×3 的卷积层,若是在模型中大量使用此模块,将会极大程度地增加模型的参数量和计算量。
为了弥补常规卷积在下采样时出现信息丢失的缺点,以及解决Focus 模块参数量过大的问题,我们基于Focus 模块提出了一种新的Focus-Maxpool 结构(图3)。
该模块由Focus 模块、1×1 的常规卷积和1 个最大池化层组成,其中卷积层用于压缩特征图的通道数。YOLOv5 模型中的下采样卷积的感受野是3×3,而Focus 模块的感受野机制相当于一个全局感受野,它对目标具体特征的观察能力有限,因此在后面连接一个感受野为3×3 的最大池化层用于优化Focus模块的感受野,该池化层不改变特征图大小。该模块在进行反向传播计算时,只会增加用于降维的卷积层的参数,而此卷积层的卷积核为1×1,因此,FM结构的参数量仅是使用3×3 卷积下采样时的4/9。
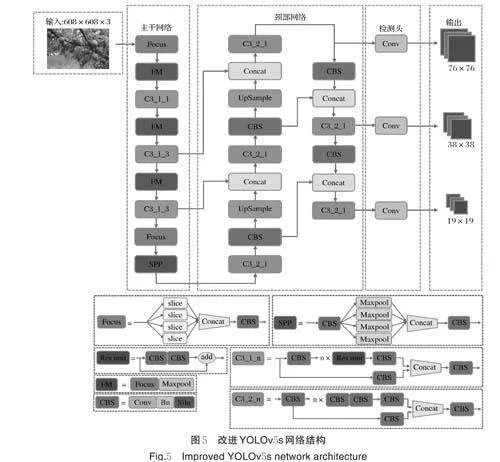
2)改进YOLOv5s 网络结构。图4 是改进之后的YOLOv5s 的主干网络结构,使用新的FM 模块替换主干网络中的下采样卷积层。由于SPP 模块为特征图提供了混合大小的感受野,因此,SPP 模块前的下采样卷积层直接替换为Focus 模块,该层的降维卷积层仍使用1×1 的卷积核,以降低参数量。
图5 是改进YOLOv5s 的结构图。之所以只替换主干网络中的下采样卷积,是因为FM 模块虽然参数量少,但在正向传播时的计算量较大,效率也比常规卷积稍慢,因此在网络中也不宜大量使用该模块。主干网络负责对输入的图像的主要特征的提取,并且主干网络的结构深度较深,更容易丢失信息。颈部网络中“自底向顶”的金字塔的网络结构较浅,使用常规卷积进行下采样也不会丢失太多信息。因此,只替换主干网络中的下采样卷积,以保证主干网络尽可能地减少信息丢失。
3)损失函数。YOLOv5s 的损失函数主要包含定位损失、分类损失和置信度损失。定位损失表示模型预测框的位置与真实框之间的差异,分类损失表示预测类别的概率与真实类别的概率的差异,置信度损失则是表示预测框位置有目标的概率。YO⁃LOv5s 的损失组成为:
式(1)中,l 表示总损失,l loc 表示位置损失,lcls 表示分类损失,lconf 表示置信度损失,a、b 和c 则是权重常数。lloc 的计算方式如式(2)所示,本研究为了降低模型计算的复杂度,使用GIOU 损失(公式中用Giou表示)。GIOU 的计算公式如式(3)所示:
果园环境中粘连目标和高遮挡目标比较多,若是使用常规的交叉熵计算损失,模型会将权重集中在易分类的目标上,而容易忽略图像中不明显的遮挡目标和小目标。为了解决这种正、负样本不平衡的问题,引入焦点损失(focal loss)[28]替换原本的分类损失。focal loss 的计算公式为:
其中,FL表示focal loss,y 表示样本标签的数量。pt 表示目标类别的概率,α 是平衡正、负样本权重的系数,α 的取值范围一般是0 lt; α lt; 1。γ 为难分类样本的调制参数,并且γ gt; 0。
pt 作为目标类别的概率,可直接反映样本分类的难易程度,pt 越大,样本越易分类,反之,pt 越小,样本越难分类。而γ 则是根据pt 的值来调整样本在总损失中所占的比例,γ 越大,易分类样本的损失就越低,难分类样本的权重就增大了,因此,模型在训练时更容易将权重集中在难分类的样本上。
focal loss 容易受噪声影响,当数据集中存在噪声或者错误标签的时候,focal loss 会将权重集中在这些错误的样本上,并且会抑制较易分类样本的损失,从而提高噪音在总损失中的比例。因此,直接用focalloss 替换原分类损失可能会影响训练效果。为了降低噪音对focal loss 的干扰,使用focal loss 和交叉熵损失的加权损失作为模型的分类损失,其计算公式为:
式(5)~(6),j 和k 分别是focal loss 和交叉熵损失的权重系数。CE表示交叉熵损失,t 是真实值,a 是预测值。在本试验中,j 和k 的值皆取0.5。交叉熵函数可以让模型更容易识别目标是否为噪声,从而降低噪声对focal loss 的干扰。
1.4 模型训练与测试
1)试验平台。本研究采用Windows10 操作系统,基于Python 3.7.4 和Pytorch 1.9.1 搭建深度学习框架来完成网络模型的训练与测试。使用的计算机配置为Intel Core i9-10900K 处理器,主频3.70 GHz,运行内存为128 GB,GPU 使用NVIDIA QuadroRTX 5000,显存为16 GB,使用的CUDA 版本是10.2,cudnn 版本为7.6.5。
2)模型训练。本研究通过对所有图像中的目标的真实框进行K-means 聚类得到先验框。本研究所使用的先验框为[8,10]、[12,17]、[18,23]、[22,35]、[36,30]、[31,48],[42,60]、[57,83]、[121,137]。模型训练时,将所有训练集图像的分辨率统一转换为608像素×608像素。优化器使用SGD优化器。为了更有效利用显存,训练时使用混合精度训练模型,并且将批量(batch-size)设置为32。权值的衰减速率(weight-decay)设为0.000 5,动量(mo⁃mentum)设为0.937。模型的总epoch 数设为100,并自动保存模型识别精度最高的权重。训练时初始学习率为0.01,并使用余弦退火法来调整每个epoch 的学习率。为了加快模型的收敛速度,先让模型在PASCAL VOC(http://host.robots.ox.ac.uk/pascal/VOC/index.html)数据集上训练并得到预训练模型,再将预训练模型用于本研究数据集的训练。
3)评价指标。采用推理速度作为模型检测速度的评判指标,推理速度代表每秒可识别的图像数量,帧/s。采用平均精度(average precision,AP;公式中用PA表示)作为模型识别精度的评判指标。平均精度与模型的准确率(precision,P)和召回率有关(re⁃call,R)有关:
式(8)~(9)中,TP为正确检测为李的数量,FP表示被错误划分为李的数量,即误检数量,FN则为图像中被漏检的目标的数量。
2 结果与分析
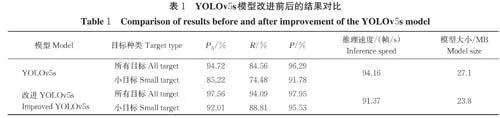
2.1 YOLOv5s 模型改进前后的性能对比
1)整体效果对比。分别将YOLOv5s 模型和改进YOLOv5s 模型在同一测试集上进行测试(表1)。表1 中小目标对应的是测试集中分辨率小于原图像分辨率0.5% 的李果实目标,小目标在整个测试集中占比为65.63%。YOLOv5s 模型在测试集上所有目标的平均精度、召回率和准确率分别为94.72%、84.56% 和96.29%,其中小目标的平均精度、召回率和准确率分别85.22%、74.48% 和91.78%。改进的YOLOv5s 模型在测试集上所有目标的平均精度、召回率和准确率相比原模型分别提高了2.84、9.53 和1.66 百分点;对于小目标,则分别提高了6.79、14.33和3.75 百分点。由此可以看出,改进YOLOv5s 模型的主干网络由于保留了更多的细节信息,使得模型能够识别出更多的小目标,从而使得模型的性能在整体上有了提高。并且新的分类损失函数可以让模型更准确地预测出目标的位置,对模型的精度做出了一定的贡献。主干网络中添加的FM 结构的参数量比常规3×3 卷积少,因此,改进后的模型的大小比原模型降低3.3 MB。由于FM 结构中需要对特征图进行切片、降维和池化操作,因此,FM 结构的工作效率比常规卷积稍低,最终推理速度下降2.79 帧/s,而这对模型的实时检测基本上没有影响。
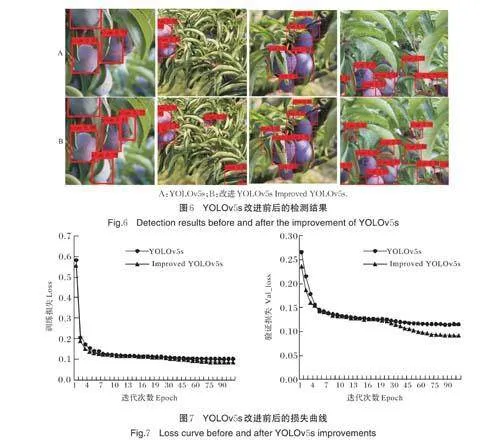
图6 是YOLOv5s 模型改进前后对测试集中李的检测效果。由图6 可知,改进后的模型对李的识别置信度普遍比原YOLOv5s 模型高。相比图6B,图6A中YOLOv5s 模型对高遮挡的李目标的检测均有漏检,而图6B 中改进YOLOv5s 模型可以将被树叶遮挡和被果实遮挡的目标全部检出。
YOLOv5s 模型改进前后的损失图像如图7 所示。由此也能看出改进后的模型在替换了下采样结构和分类损失后,训练效果要比原模型好,并且收敛过程稳定。
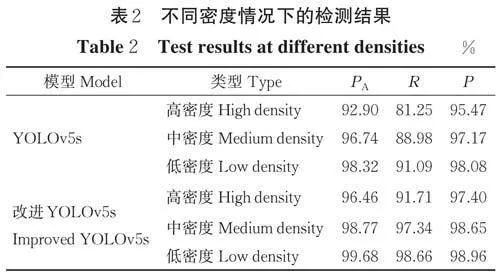
2)不同密度情况下的检测结果。为了进一步验证改进YOLOv5s 模型对不同密度情况下李的检测都有着较高精度,本研究对测试集中的图片根据目标密度进行分类。其中,单位距离间像素大于40 的图片被归类于高密度。由于数据集中有些图片是大视场下的场景,这些图片中的目标数较多,但目标成簇分布,每个簇中目标较为密集,但簇之间的距离较远,直接计算密度会导致密度的值偏低,因此,本研究直接将图片中目标个数大于20 的也归类于高密度。而单位距离间像素小于等于20 且大于等于10的图片被归类于中密度,单位距离间像素小于10 的图片被归类于低密度。最终高密度的图片有205 张,中密度的图片有188 张,低密度的图片有167 张。从表2 可知,改进后模型对不同密度下的检测结果皆优于原模型,改进后模型的性能优势主要表现在召回率上,在高密度、中密度和低密度情况下,改进后模型的召回率比原模型分别提高10.46、8.36 和7.57 百分点。
对比图8 的检测结果可以看到,改进后的模型计算出的目标置信度普遍要高于原模型,并且原模型漏检一些遮挡度较高的目标,而改进模型则识别出了所有目标。改进后的模型可以在果实比较密集且树叶比较密集的情况下有效识别出目标,且有较高的置信度,说明改进后的模型有着较强的对遮挡目标的识别能力。
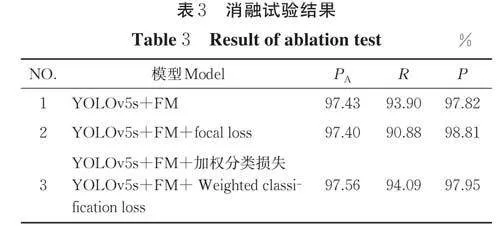
2.2 消融试验
表3 中试验1 是将YOLOv5s 模型的主干网络中的下采样卷积替换为FM 结构的测试结果,对比表1中原模型的测试结果可知,试验1 的平均精度、召回率和准确率分别提升了2.71、9.34 和1.53 百分点。使用FM 结构作下采样可以保留更多的细节信息,避免特征图在多次下采样后丢失小目标和遮挡目标的特征信息,从而降低了整体的漏检率。试验2 是在改进模型的基础上将原分类损失替换为focal loss,从表3可知,试验2 的召回率相对试验1 降低3.02 百分点,这是因为focal loss 容易受噪音影响,而果园中环境背景较为复杂,可能会出现较多的干扰。因此,试验3 在试验2 的基础上,将focal loss 与交叉熵损失函数相结合,取二者的加权值作为模型的分类损失,而最终的平均精度、召回率和准确率相比试验1 分别提升0.13、0.19 和0.13 百分点,加权损失函数可以使模型的性能在整体上有一个小幅度的提升。
2.3 改进YOLOv5s 与其他模型的性能对比试验
为了进一步证明改进YOLOv5s 模型的有效性,本研究将同样的数据集分别在Faster-RCNN、YO⁃LOv4、SSD 和Centernet 上进行了训练。表4 所示是各个模型的性能评估结果。对比表1 中的原YO⁃LOv5s 模型的性能可以看出,虽然YOLOv5s 的召回率不如Faster-RCNN,准确率不如SSD 和Centernet,但其平均精度高于其他4 个模型,且模型大小比其他模型小,推理速度也最快,说明其综合性能最好。这是因为YOLOv5s 有着较优秀的结构设计和训练策略,使其在保持较好性能的同时,也能有较高的推理速度,这也表明了本研究选取YOLOv5s 模型的合理性。
对于改进YOLOv5s 模型,其平均精度比Faster-RCNN、YOLOv4、SSD 和Centernet 模型分别高13.69、8.77、6.77 和6.02 百分点。其中,Faster-RCNN 在处理密集目标时会出现重叠区域较多的情况,这会使得检测结果不准确,从而导致准确率低。对于YOLOv4,其颈部网络中采用的都是普通的卷积操作,对来自不同层的特征信息的融合能力有限,而YOLOv5s 的颈部网络中,采用的CSP 结构,拥有更强的网络特征融合的能力,能够提取更多浅层的关于小目标的特征信息。SSD 和Centernet 虽然有着较高的准确率和平均精度,但它们的召回率较低,对小目标和遮挡目标的识别能力有限。Centernet 则是因为需要预测中心点来预测目标位置,在处理遮挡目标和小目标时会丢失细节信息,从而导致召回率较低。综上所述,改进YOLOv5s 模型的综合性能最好,其模型大小仅为SSD 的1/4,推理速度也比Cen⁃ternet 高35.84 帧/s,可以快速有效地识别出李。
图9 是上述5 个模型对测试集中不同尺寸的目标的识别效果。从图9A,B 可以看出,改进YO⁃LOv5s 模型和Faster-RCNN 能够准确识别图片中的每个目标,但Faster-RCNN 的模型较大,且速度较慢。如图9C,D 所示,YOLOv4 模型和SSD 模型都将紫色瓶子误检为了李。图9E 图中Centernet 模型漏检了图像中被遮挡的目标。由此可见,改进后模型对遮挡目标有较高的检出率和识别精度。
对比图9F~J,可以看到,相比于其他模型,改进YOLOv5s 模型可以检测出更多的目标。Faster-RCNN、SSD 和Centernet 模型漏检了许多尺寸较小,遮挡度较高的目标,而YOLOv4 可以检测出较多的目标,但还是漏检了一些被枝叶遮挡的目标。在大视场情况下,果实目标就会显得较小,一些被遮挡的目标则变得更加不明显,而改进YOLOv5s 中的FM模块可以让模型在训练时更多地保留小目标信息和被遮挡目标的信息,从而提升模型对这些较难识别的目标的检测能力。
综上所述,改进YOLOv5s 模型不仅能够对较明显的目标有着高精度和高检出率,并且也能精确识别出尺寸较小和遮挡度较高的目标的位置。本研究提出的改进YOLOv5s 模型在能保证比较高的精度的情况下,又不会使模型在推理过程中引入太多的参数而影响推理速度,改进后YOLOv5s 模型规模较原模型有所降低,所需的算力资源较少,适合部署于嵌入式设备。
3 讨论
本研究基于YOLOv5s 模型提出一种果园自然环境下李果实目标检测模型,制作了自然场景下的李果实数据集用于模型的训练和测试。试验结果表明,改进YOLOv5s 模型识别李果实的平均精度提高到97.56%,识别小目标的平均精度达到92.01%,其模型大小只有23.8 MB,在GPU 上的推理速度为91.37 帧/s,可以满足于嵌入式设备的部署条件。
本研究使用Focus-Maxpool 模块替换主干网络中的下采样卷积,使模型在下采样时能够保留更多高遮挡目标和小目标的特征信息,使用focal loss 和交叉熵函数的加权损失作为模型的分类损失,提升模型对密集目标的识别能力。本研究还设计不同的试验来对比模型改进前后的性能,并且将改进后的模型与YOLOv4、Faster-RCNN、SSD 和Centernet 的作对比,说明改进后模型的优越性。在以后的研究中,可将该模型进一步改良,丰富数据集,实现模型对李子成熟度和病虫害的识别。
猜你喜欢
数字技术与应用(2019年2期)2019-05-14 08:25:10
电子制作(2018年18期)2018-11-14 01:48:20
现代电子技术(2018年8期)2018-04-13 06:36:32
软件工程(2017年11期)2018-01-05 08:06:09
智能计算机与应用(2017年5期)2017-11-08 12:11:51
中国公共安全(2017年8期)2017-10-13 08:12:21
中国公共安全(2017年8期)2017-10-13 08:12:20
软件(2016年4期)2017-01-20 09:38:03
科教导刊·电子版(2016年28期)2017-01-10 22:25:23
科学与财富(2016年28期)2016-10-14 23:45:18
