
基于视觉-语言特征编码的跨模态融合视觉问答方法
2024-01-01 00:00:00刘润知陈念年曾芳
西南科技大学学报 2024年3期
关键词:注意力机制









摘要:现有的视觉问答方法采用相同编码器编码视觉-语言特征,忽略了视觉-语言模态之间的差异,从而在编码视觉特征时引入与问题无关的视觉干扰特征,导致对关键视觉特征关注不足。提出一种基于视觉-语言特征编码的跨模态融合视觉问答方法:采用一种动态注意力编码视觉特征以实现根据问题动态调整视觉特征的注意力范围;设计了一种具有双门控机制的引导注意力以过滤多模态融合过程带入的干扰信息,提升多模态特征融合的质量,并增强多模态特征的表征能力。该方法在视觉问答公共数据集VQA-2.0上的Test-dev和Test-std两个测试集上的准确率分别达到71.73%和71.94%,相比于基准方法分别提升了1.10和1.04个百分点。本文方法能够提升视觉问答任务的答案预测准确率。
关键词:视觉问答 注意力机制 多模态融合
中图分类号:TP391.41" 文献标志码:A" 文章编号:1671-8755(2024)03-0086-10
Cross-modal Fusion Visual Question Answering Method Based
on Visual-language Feature Encoding
LIU Runzhi, CHEN Niannian, ZENG Fang
(School of Computer Science and Technology, Southwest University of Science
and Technology, Mianyang 621010, Sichuan, China)
Abstract:" Existing Visual Question Answering (VQA) methods use the same encoder to encode" visual-language features, ignoring the differences between visual and language modalities. This introduces visual noise into the encoding of visual features that are irrelevant to the questions, resulting in insufficient attention to key visual features. To address this problem, a cross-modal fusion VQA method based on visual-language features encoding is proposed. A dynamic attention mechanism is used to encode visual features to dynamically adjust the attentional span of visual features based on the question; a guided attention mechanism with dual-gate control is designed to filter out interfering information introduced in the multimodal fusion process, thus improving the quality of multimodal features fusion and the representability of multimodal features. The accuracies on the Test-dev and Test-std datasets of the public VQA-2.0 dataset reach 71.73% and 71.94%, respectively, compared with the baseline methods, which are improved by 1.10% and 1.04%, respectively. The proposed method in this paper can improve the accuracy of answer prediction in visual question-answering tasks.
Keywords:" Visual question answering; Attention mechanism; Multimodal fusion
视觉问答(Visual question answering,VQA)是多模态学习[1-2]任务之一。VQA的基本过程为:给定一幅自然场景的图像和一个对应的自然语言描述的问题,同时对图像和问题进行细粒度的语义理解,并结合视觉推理来预测准确的答案。
由于VQA任务中图像和问题属于两种不同的模态,并且视觉信息是由特征提取网络获得的高维特征,故需要不同的编码器对这两种模态进行编码。Lu等[3]提出了分别编码视觉特征和文本特征的模型,并通过共同注意转换器让两种模态相互交互,充分学习多模态知识。Tan等[4]使用对象关系编码器、语言编码器分别提取图像和文本信息中的关键对象和关键词,再结合跨模态编码器学习跨模态关系。Yu等[5]使用编解码结构分别对文本和图像进行编码,并实现跨模态学习,达到准确回答问题的目的。Fukui等[6]使用自注意力和跨模态注意力模块分别构建语言和视觉关系编解码器,并附加特定的任务头,以处理不同的多模态任务。以上这些方法在视觉问答任务中取得了一定的进步,然而它们仍然是依靠Transformer[7]的自注意力机制(Self-attention,SA)在全局依赖建模上的优秀能力用于编码视觉特征和语言特征,本质上使用的仍是同一种编码器,没有区分视觉-语言两种模态之间的差异。最新研究[3,8]表明,如果仅凭SA的全局关注能力不足以完成视觉-语言相互结合的多模态任务(如VQA)。因为VQA模型要正确回答一个问题,不仅需要理解整个视觉内容的语义,更重要的是它们还应在编码视觉特征的同时能够根据问题的不同动态调整视觉注意范围,以找到能够准确回答问题的视觉区域。
另外,VQA作为一种多模态任务,要正确预测答案就必须对多模态融合之后的特征进行学习理解,进而捕获有效的多模态表征。Gamage等[9]提出拼接两种模态的早晚期融合策略来增强两种模态的融合效果,从而提升模型的答案预测能力。Gao等[10]和Wei等[11]则提出一种用于图像和句子匹配的新型多模态交叉注意力网络来相互补充和增强两者之间的关联,促进多模态学习。Li等[12]通过使用对比损失与跨模态注意力在融合前对齐图像和文本两种模态,限制特征融合时带入的无效信息,促进视觉-语言间的特征融合。Dou等[13]通过在图像和文本编码的主干网络中嵌入跨模态注意力,让两种模态在早期就开始进行相互学习,从而增强两种模态的融合效果。上述方法虽在多模态融合上取得了一定的效果,但始终难以打破文本和图像之间的语义鸿沟[14],并且融合策略过于粗略,没有限制特征融合时带入的干扰信息(即将文本信息融入视觉信息时,某些文本信息可能对视觉信息产生干扰,反之亦然),从而导致模型预测出错误的答案。
目前方法存在以下问题:(1)编码视觉-语言时仍采用相同的编码器,忽略了两种模态的差异,导致模型编码视觉特征时引入了一些与问题无关的视觉干扰特征;(2)现有视觉编码器不能动态调整对视觉特征的关注范围,导致模型对关键视觉特征关注不足;(3)视觉-语言融合时没有限制各自模态带入的干扰信息(如将视觉信息融入文本信息时,所有的视觉元素都参与融合)。
为解决上述问题,本文提出了一种基于视觉-语言特征编码的跨模态融合视觉问答方法。首先,为区分视觉和语言两种模态,提出在VQA模型中采用不同编码器的方式以捕获不同模态中的关键特征,即:采用一种动态的自注意力[15-16](Dynamic self-attention,DSA)来编码视觉特征,并在此基础上加入残差连接和多层感知机(MLP)模块,以增强对视觉特征的表示能力。同时,为每个注意力层配置路径控制器,该控制器能根据前一层注意力计算的结果自动选择下一层注意力范围,进而确定与问题相关的视觉区域。以此为基本单元构建视觉编码器,既能建模视觉对象之间的关联,又能动态调整注意力范围,然后与语言编码器共同组成视觉-语言编码器。为了提升多模态融合能力,并消除视觉-语言特征融合时带入的干扰信息,构建了一种深层跨模态融合模块用于提升视觉-语言的融合能力,即:采用具有双门控机制的引导注意力来过滤视觉-语言融合后的多模态信息,从而去除多模态特征中的干扰信息。为了增强多模态特征的表示能力,分别为两条路径配置了SA,DSA和MLP模块。为了让模型能够汲取到更精确的多模态知识,再次对联合嵌入后的多模态特征编码,以增强VQA模型的多模态特征表征能力和推理能力,进而提升模型预测答案的准确率。在公共数据集VQA-2.0[17]上进行了本文方法有效性的实验验证。
1 视觉-语言特征编码的跨模态融合视觉问答方法
本文提出一种视觉-语言特征编码的跨模态融合网络(Visual-language features encoding cross-modal fusion networks,VL-CMFNet)。包含3个模块,其结构如图1所示。
语言编码器:采用自注意力单元与MLP实现文本特征编码,同时使用残差连接进一步增强语言特征的表征能力。为了捕获关键特征信息,本文叠加NL层网络作为语言编码器。
视觉编码器:视觉编码器中使用动态注意力作为特征编码器,该注意力能根据上一层的注意力图自动选择本层图像的注意范围,达到动态选取视觉特征的效果。类似于语言编码器,在构建网络时共叠加NV层。
跨模态融合模块:在该模块的两个分支上采用引导注意力对两种模态进行细粒度融合,并为其设置具有学习能力的门控因子α 与β,起到过滤多模态特征中干扰信息的效果。同时,为了增强多模态特征的表征能力,分别在两个分支上加入 SA,DSA 和 MLP。本文在构建网络时共使用NM层。
此外,本文在构建 VL-CMFNet 时依据文献[18]的思想,在跨模态融合模块的深层,使用多模态特征学习模块,旨在促进词与视觉元素之间相互学习理解和多模态特征的表征能力。
1.1 视觉-语言特征编码器
1.1.1 多头注意力
作为自注意力的基本组成部分,多头注意力对特征关系建模至关重要。其中单头的建模过程是把输入的文本特征 T∈瘙綆n×d(n表示单词个数,d表示维度)线性映射(Linear mapping, LM)得到Q,K,V,然后计算所有Q和K的点积,并除以d,再把结果由softmax函数计算出注意力分数,最后和V相乘得到注意力特征fatt。为了方便计算和降低计算复杂度,故保持三者维度一致。计算过程如式(1)所示:
fatt=Att(Q,K,V)=softmax(QKTd)V(1)
为进一步增强注意力特征的表示能力,把多个独立的fatt拼接在一起。因此,最终多头注意力(Multi-head attention,MHAtt)如式(2)所示:
MHAtt(Q,K,V)=[fatt1,fatt2…fatth]Wo(2)
fatti=Att(QWQi,KWKi,VWVi)(3)
式中:WQi,WKi,WVi∈瘙綆d×dh,为每一个头的映射矩阵;Wo∈瘙綆h*dh×d 且可学习;[·]表示拼接操作;h表示多头注意力中的多头个数;dh表示每个头输出特征的维度;d表示特征向量的维度大小。为防止多头注意力参数量过大,约定dh=d/h。
1.1.2 语言编码器
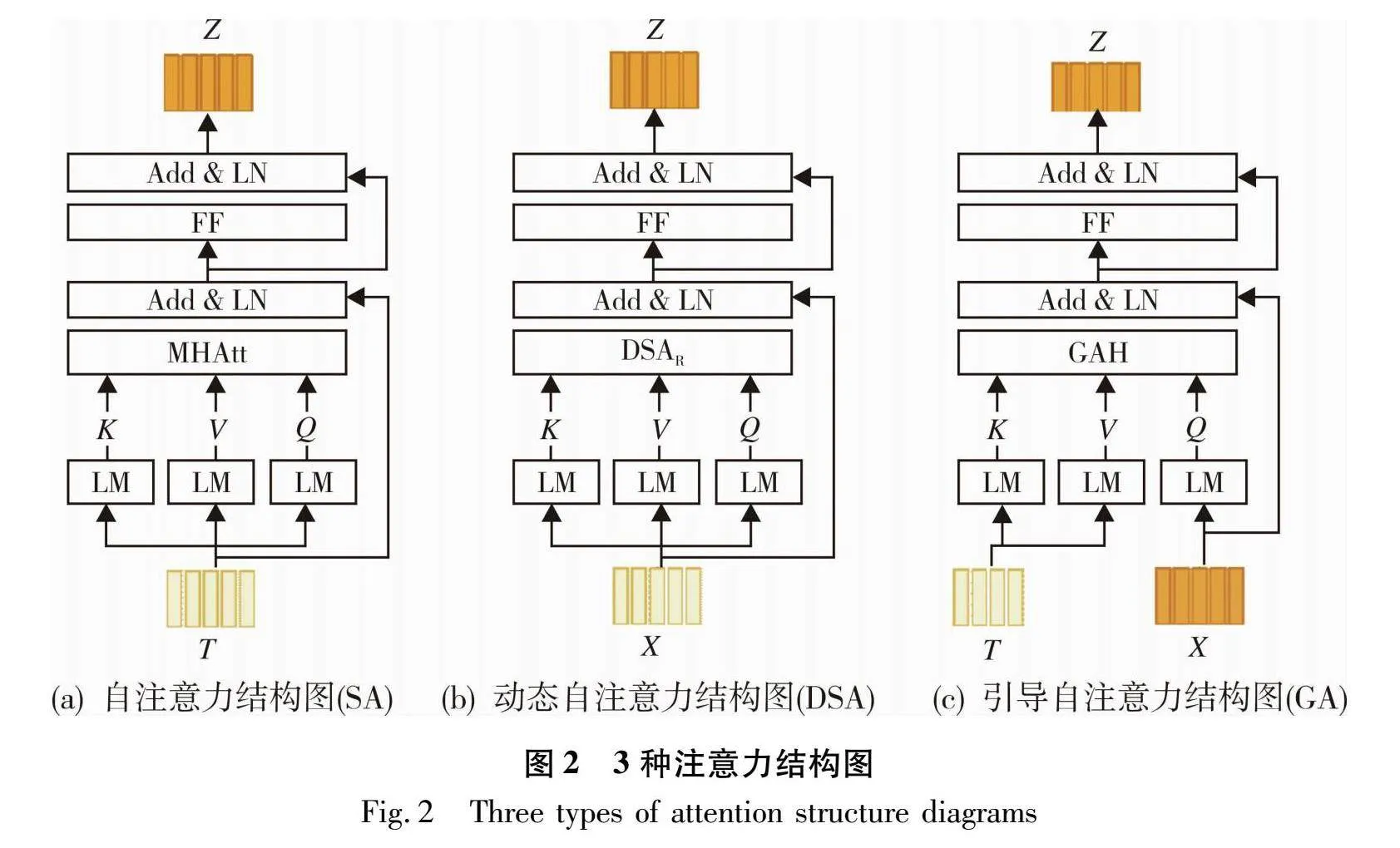
本文所用的语言编码器是在上述多头注意力的基础上构造一个自注意力单元,对输入的文本特征进行建模,实现词与词之间关联关系的构建,其基本结构如图2(a)所示。在多头注意力的基础上,再加入一层前馈网络(Feed forward,FF),FF 是由两层全连接层 FC、激活函数 GELU 和 Dropout 构成(FC-GELU-Dropout(0.1)-FC)。另外,在MHAtt层和FF层使用残差连接[19]和层归一化[20](Layernorm,LN)进一步优化。对于每个自注意力单元都有ti∈T的注意
特征Fi=MHAtt(ti,T,T),这一过程可以看作是所有在T内的样本的相似性对ti的重新构建。因此一个基础的自注意力单元可以表示为:
t~=LN(T+MHAtt(T))
Z=SA(T)=LN(t~+FF(t~))(4)
式中:t~表示经过 MHAtt 和层归一化计算的特征;Z表示最终自注意力的输出特征。
一个基本语言编码器的构成是在上式的基础上再连接一个 MLP 模块,再次增强文本特征的感知能力。所以整体语言编码器层的公式表示为:
FSA=LN(T+Dropout(TSA))
Ft=LN(FSA+MLP(FSA))(5)
式中:FSA 表示自注意力计算后使用残差连接和层归一化获得的特征;Dropout(·)能够将特征中的部分值置为零,旨在消除过拟合;TSA表示 SA 计算后的结果;Ft为一层编码器计算得出的特征。语言编码器整体结构如图1的语言编码器部分。
1.1.3 视觉编码器
近年来,基于 Transformer 卓越的全局依赖建模能力被广泛应用到视觉-语言任务中,VQA 任务也引入 Transformer 的思想。但 Transformer 中 SA 不会随注意力层数加深动态调整注意力范围,而 VQA 任务需要的视觉注意力范围是一个从宏观到微观的过程。因此,使用一种能动态调整注意力范围的自注意力(DSA)对视觉信息进行动态编码,筛选出对 VQA 预测答案相关的视觉对象。
在 VQA 任务中,本文在经过 ResNext152 提取的视觉特征上引入具有动态调整注意力范围的动态自注意力 DSA。该方式不仅能使图像中整体的视觉对象之间建立关联关系,还能基于上一层的输出来预测下一层注意力图的范围。DSA 结构如图2(b)所示。DSA 为具有动态路径选择的注意力,该注意力使网络能够在不同注意力层的特征图中根据前一层的输出调整本层的注意力范围,这样不仅可以在图像的全局形成注意力依赖关系,还可以根据注意力层的结果选取不同的注意力范围,通过聚合图像全局的特征和局部细节特征,提高图像特征的编码能力达到准确回答问题的目的。
对于输入X∈瘙綆m×d,DSA 对其编码可以简化为mi=0λiFi(X),λi是选择不同路径的概率,Fi是一组不同的注意力,其表达式如式(2)所示。λ可以通过软路由文献[15]的方式得到。然而,这样的路由方案不可避免地会使网络变得非常繁琐,并极大地增加训练开销。因此需要优化这个路由过程,把式(2)的注意力看作如下的过程:
Z=SA(X)=AXWv
A=softmax(XWq(XWk)Td)(6)
在式(6)中,把 SA 看作一个全连接图的特征更新函数,因此A∈瘙綆m×m就可以作为权重邻接矩阵[21]。DSA 的目的是要得到不同注意力范围的特
征,所以只需要对每个输入的全连接图进行限制。
本文基于此为计算完成后的邻接矩阵A增加一组掩码M∈瘙綆m×m,旨在减少全连接图中某些顶点之间的连接,起到限制注意力范围的作用。因此A可以改写为:
A=softmax(XWq(XWk)TdM)(7)
掩码M是一个只包含 0 和 1 的矩阵,在实际训练时 0 被替换为一个无穷大的负值。因此,注意力的范围就只在定义的区域内有效。基于式(7),动态注意力层 DSA 可以被定义为如下形式:
DSAR(X)=ni=0softmax(XWq(XWk)TdMi)XWv(8)
式中:Wq,Wk,Wv是可学习的权重参数,且在不同层之间共享,起到降低参数量的作用。据式(8)分析此过程依然是一个对注意力模块的选择,为了进一步简化计算,将模块选择转变为对邻接矩阵掩码M的选择,新的定义如下:
DSAR(X)=softmax(XWq(XWk)Tdni=0λiMi)XWv(9)
其中对于路径控制器λ有如下定义:
λ=softmax(MLP(fatt))
fatt=AttentionPooling(X)(10)
式中:MLP是一个多层感知机;AttentionPooling为基于注意力的池化方法[5]。因此一个基本的动态自注意力单元如式(11)所示:
x~=LN(X+DSAR(X))
ZDSA=DSA(X)=LN(x~+FF(x~))(11)
式中:x~表示动态编码和层归一化计算得到的特征;ZDSA 表示动态注意力编码的特征。
一个基本视觉编码器的构成是在式(11)的基础上连接一个 MLP 模块,再次增强特征的感知能力,所以整体的视觉编码器编码过程表示如下:
FDSA=LN(X+Dropout(XDSA))
Fv=LN(FDSA+MLP(FDSA))(12)
式中:FDSA" 表示经过残差连接和层归一化后的特征;XDSA 表示 DSA 计算后的特征;Fv为一层视觉编码器编码后的特征。视觉编码器的整体结构如图1中的视觉编码器所示。
1.2 跨模态融合模块
为了促进多模态特征的融合并同时过滤融合时的干扰特征,本文构建了如图1跨模态融合模块所示的多模态融合模块。首先,在引导注意力(Guided-attention,GA)上增加双门控机制,然后,与 DSA 和 SA 共同嵌入主干网络中编码多模态特征。为进一步在多模态特征中汲取知识,在模块的最后两层引入聚合模块对融合后的特征进行整体编码以加强模态间交互能力,进而提升答案预测能力。
1.2.1 引导注意力头的定义
作为 GA 模块的重要组成部分,引导注意力头(Guided attention head,GAH)对视觉-语言相互融合至关重要。其过程是让输入的特征X=[x1,x2…xm]∈瘙綆m×d 和Y=[y1,y2…yn]∈瘙綆n×d 相互引导完成相互学习,由于计算灵活,故两种特征的维度大小可以不同,其公式表示为:
fGAH(X,Y)=GAH(X,[y1,y2…yn])(13)
上式可以理解为是X从Y中学习得到与特征Y相关联的信息。类似的,当输入变为FGAH(Y,X)时表示Y从X中学习。
1.2.2 跨模态融合过程
VQA 任务要求模型不仅要学习与文本相关的视觉内容,同时还应学习与视觉相关的文本内容,以及对模态融合之后的整体理解。本文使用两个 GA 单元以提高模态融合能力,GA 的基本结构如图2(c)所示。首先是文本引导图像从中学习重要的视觉特征,为了便于计算,保持文本和图像的特征维度一致。构造如下的 GA 单元:
ft=fGAH(T,X)
f~t=LN(T+ft)(14)
FGAt=LN(f~t+FF(f~t))
式(14)表示所有输入的文本特征ti∈T和图像特征xj∈X。T引导注意力从X中学习得到注意力特征ft看作是每一个ti在所有X样本中学习得到的与ti相似的跨模态特征,即通过文本去图像中查询出相关的视觉内容并且融合在文本特征中。f~t表示层归一化后的包含视觉信息的特征;FGAt表示文本引导图像获得的多模态特征。
然后是图像引导文本从中学习关键的文本特征,于是构造另一个 GA 单元:
fv=fGAH(X,T)
f~v=LN(X+fv)(15)
FGAv=LN(f~v+FF(f~v))
式(15)则是X引导注意力从T中学习得到注意力特征fv看作是每一个xi在所有T样本中学习得到的与xi相似的跨模态特征,即通过图像去文本中查询出相关的文本内容并且融合在图像特征中。f~v表示层归一化后的包含语言信息的特征;FGAv表示图像引导文本获得的多模态特征。
在此基础上为两个 GA 单元再加入门控因子α和β,过滤掉多模态特征中的干扰信息。得到的多模态特征再分别经过 SA 和 DSA 进一步为得到的多模态特征构建内部关联,之后再经过 MLP 感知细粒度的多模态特征。整个过程表示如下:
α=torch.nn.Parameter(initα)
f~tv=Ft+α*FGAt
ftv=f~tv+SA(f~tv)(16)
Ftv=ftv+MLP(ftv)
β=torch.nn.Parameter(initβ)
f~vt=Fv+β*FGAv
fvt=f~vt+DSA(f~vt)(17)
Fvt=fvt+MLP(fvt)
式中:α,β的初始值分别为initα和initβ;torch.nn.Parameter(·)为机器学习框架PyTorch内置函数,输入该函数参数能随网络训练自动优化。在式(16)中,Ft表示经过语言编码器编码得到的特征;f~tv,ftv 表示计算过程中的隐藏特征;Ftv 表示多模态融合层输出的包含视觉信息的特征;在式(17)中,Fv表示经过视觉编码器编码得到的特征;f~vt,fvt表示隐藏特征;Fvt 表示多模态融合层输出包含问题信息的特征。
1.2.3 聚合模块
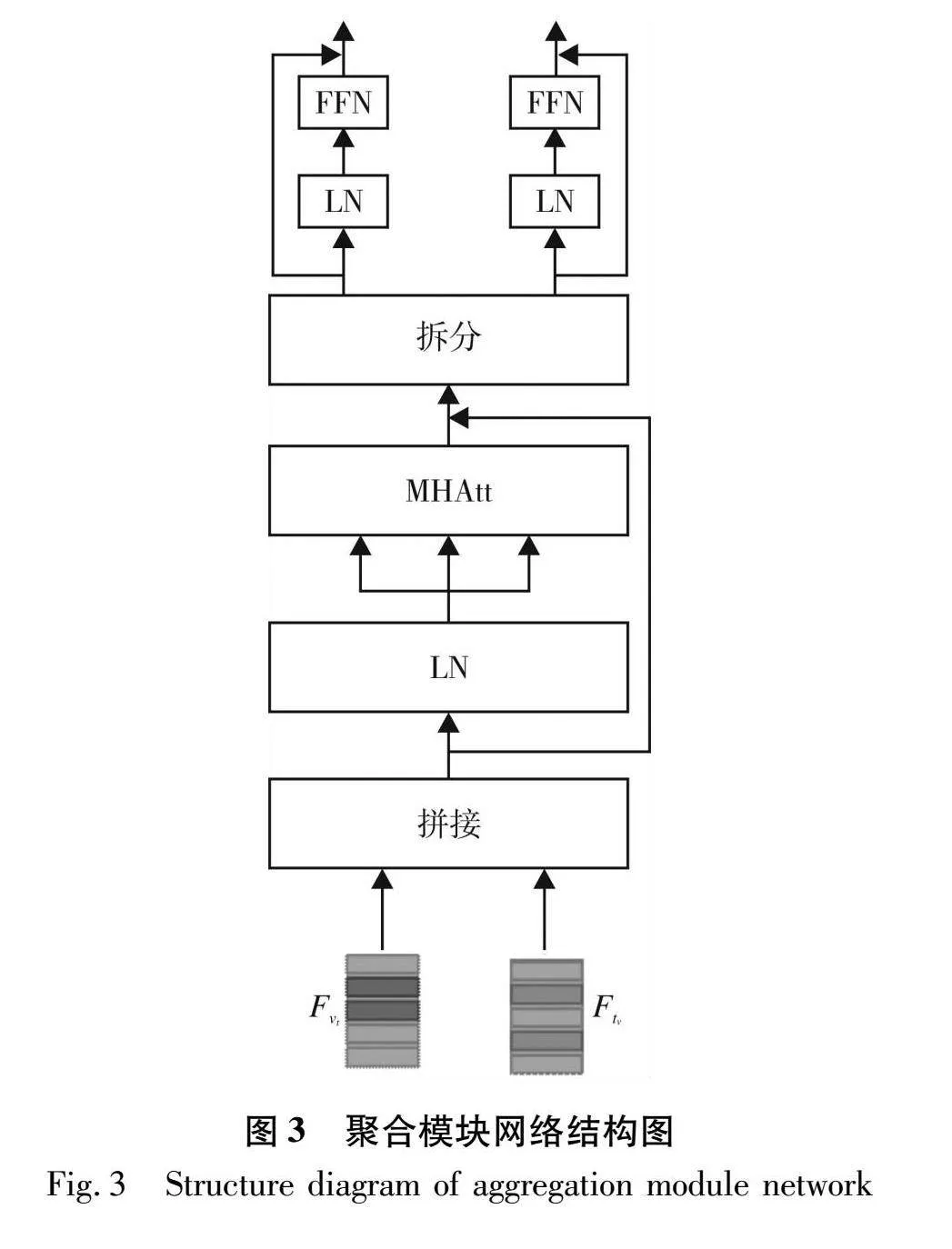
该部分作为门控引导注意力的加强,把经过 GA 单元编码后的文本和图像多模态特征拼接在一起,输入聚合模块对其进行联合建模。聚合模块中使用 MHAtt 对联合特征进行增强编码,再按输入的维度大小拆分开,这有助于学习联合特征中相互关联的关键特征。聚合模块网络结构如图3所示。
聚合模块运算过程可表示为:
fcat=LN([Fvt‖Ftv])
f1, f2=torch.split([Fvt‖Ftv]+MHAtt(fcat))
F1=f1+FFN(LN(f1))
F2=f2+FFN(LN(f2))(18)
式中:[·‖·] 表示把两种特征进行拼接;torch.split(·)表示把拼接后的特征拆分为原大小;fcat,f1,f2,F1,F2为各自特征;FFN(·)表示前馈神经网络。聚合模块运用在多层跨模态融合模块的最后两层。
2 实验与结果分析
2.1 数据集
使用 VQA-2.0 数据集[17]评估所提方法的有效性。该数据集中每幅图像至少有 3 个问题,每个问题有 10 个答案。其中包括 82 783张训练图像,40 504张验证图像,81 434张测试图片。问题-答案对包括443 757个训练问题,4 437 570个训练答案,214 354个验证问题,2 143 540个验证答案,447 793 个测试问题。此外,Test-dev 和Test-std 用于在线评估模型的答案预测准确率。结果以每种类型(是/否,计数,其他)的准确率和“整体”准确率组成。
2.2 实验参数设置
实验的 PC 环境为 Ubuntu 20.04.4 LTS,Intel Xeon(R) E5-2650 V4@2.20 GHz×48,GPU 为 NVIDIA TITAN Ⅴ,内存为 12 GB。在 PyTorch1.7 深度学习框架中进行训练与测试。
在实验过程中词向量维度为 300,使用 GRU 编码后的文本特征维度为 512。依据文献[22]统计结果,问题的最大长度为 16 个单词。语言编码器层数NL=10。图像部分首先使用在 Visual Genome 上预训练的 ResNext152 提取视觉特征,特征维度为 512。视觉编码器层数NV=10。跨模态融合模块的层数 NM=10,门控因子α初始化为0,β初始化为 1。MHAtt中头的数量h=8,dh=64。学习率为2.5te-5,t=1,2,3;之后为5e-5,每个轮次衰减 0.25。一共训练 16 个轮次,批量样本大小设置为64,优化器为Adam。
2.3 评价指标
本文所有实验结果的精度评价指标为准确率(Accuracy,A),计算公式如下:
A=min(#ANSWERS3,1)(19)
式中 #ANSWERS表示人工标注的答案,每一个问题的某一个答案数量在3个或以上时则认为该答案是正确答案。
2.4 各模块实验结果对比分析
2.4.1 DSA模块有效性验证
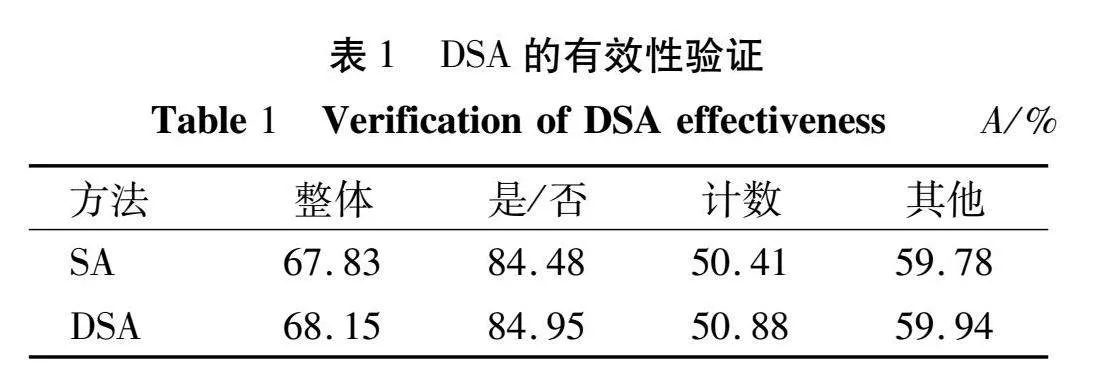
为了验证视觉编码器中使用 DSA 的有效性,本文在 VQA-2.0 数据集上分别比较了使用 DSA 与 SA 方法的模型精度,精度计算方式如式(19)所示。具体实验结果如表1所示,所有结果均是验证集结果。
从表1可知,“是/否”和“计数”类型的问题精度提升了 0.47个百分点,“其他”类问题提升了 0.16 个百分点,“整体”类型的精度提升了 0.32个百分点。由此可得出DSA对于“是/否”和“计数”类的问题更加具有帮助。这是因为要回答“计数”类的问题,需要注意到图像中与问题相关的所有视觉对象,要求模型根据对问题的理解不断优化视觉区域,这体现了DSA的动态调节能力。由此可以看出动态自注意力在保持良好全局注意力的同时能够动态调整图像的注意范围,为正确预测答案提供了有效的视觉信息。
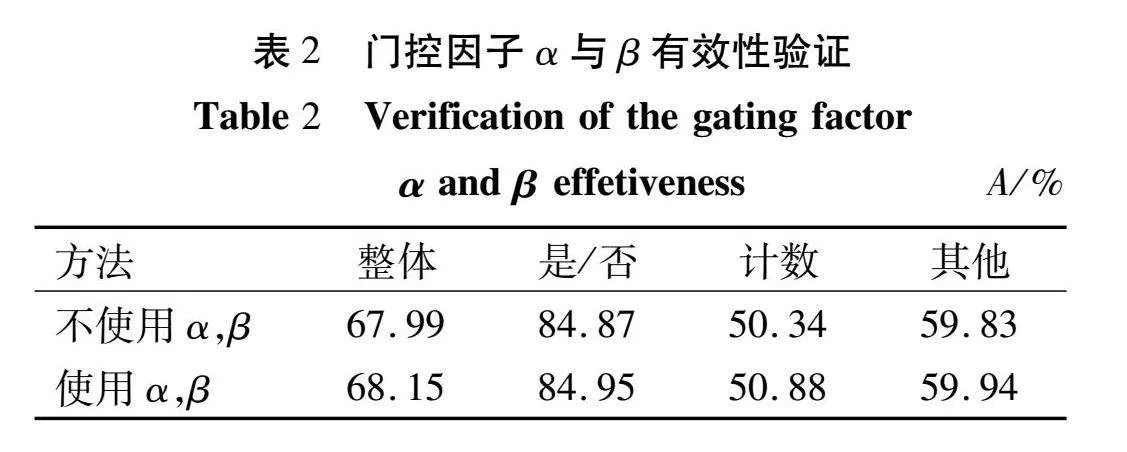
2.4.2 门控因子α与β有效性验证
关于引导注意力中门控因子α与β的有效性验证,主要对比了使用门控因子和不使用门控因子时的实验结果。具体实验结果如表2所示。
从表2可知,使用门控参数之后的“计数”类预测精度提升了 0.54个百分点,“整体”类型的精度提升了 0.16个百分点。“计数”类精度提升较多,这是因为计数类问题大多涉及多个视觉对象,没有门控因子控制时通常会带入干扰信息,同时表明“计数”类问题需要更高质量的多模态知识支持。实验结果证明门控因子α,β起到了过滤双模态特征中干扰信息的作用。
2.4.3 聚合模块有效性验证
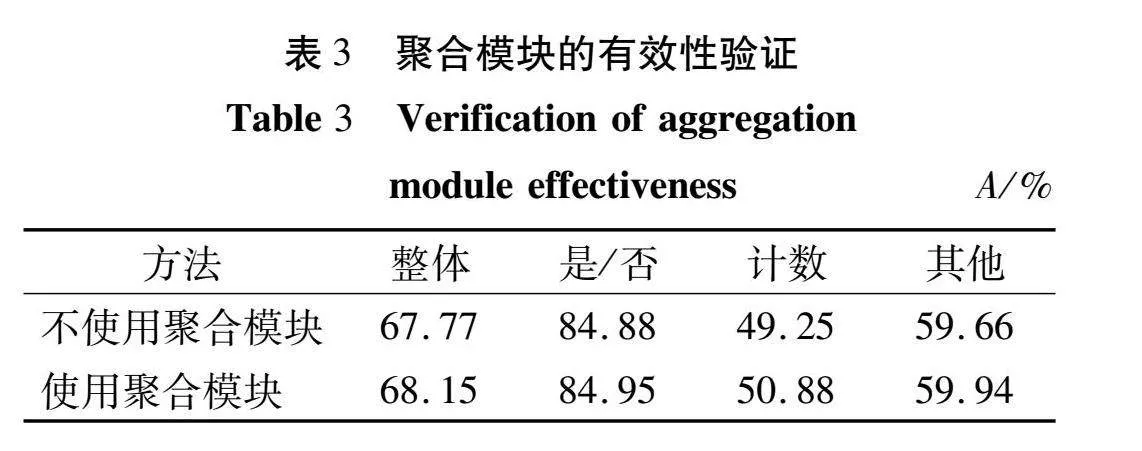
聚合模块主要在跨模态融合模块的最后两层使用,以增强双模态特征的表示能力。本文在VQA-2.0验证集上证明了该模块的有效性,实验结果如表3所示。
从表3可知,使用聚合模块后模型的“整体”类的精度提升了 0.38个百分点;“计数”类的精度提升了 1.63个百分点,这表明使用该模块汲取的多模态知识对“计数”类的问题更有益,同样表明“计数”类的问题需更充分的多模态知识支持。对于表现优秀的“是/否”类型的精度同样有一定的提高。使用聚合模块能够起到增强双模态特征表示能力的作用,并有效提升模型预测答案的准确率。
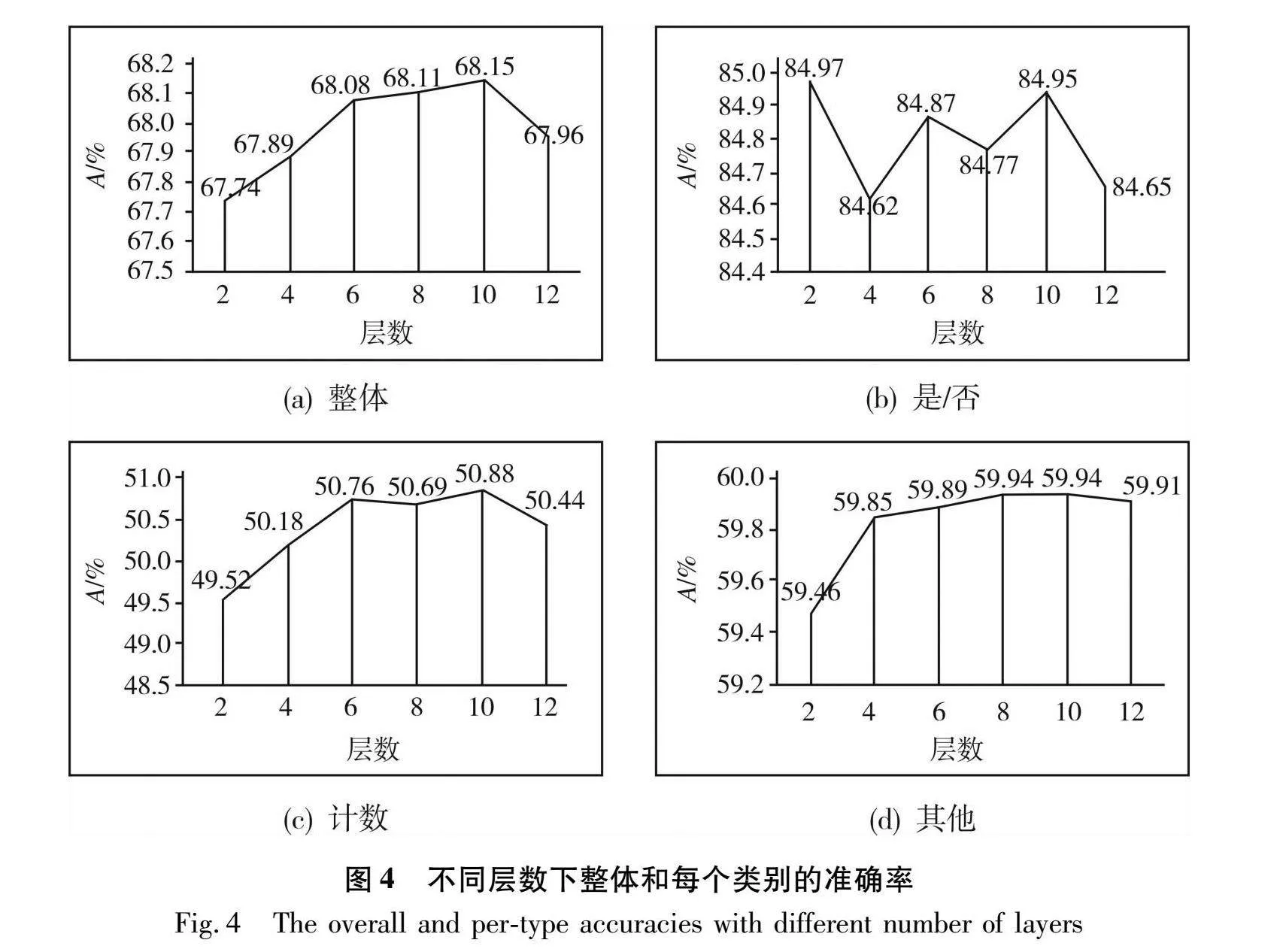
2.4.4 不同层数的网络结构对精度的影响
不同层数的编码器与跨模态融合模块对模型精度影响的验证结果如图4所示。本文主要验证NL,NV,NM∈{2,4,6,8,10,12}的效果。
从图4(a)可知,随网络层数的增加,“整体”类型的精度先随网络层数的增加而增加,当网络层数在第10层时趋于稳定,再次增加网络层数精度反而有所降低;从图 4(b)可以看出,“是/否”类的精度对于层数变化较敏感,但同样在网络层数为10层时趋于稳定,类似的情况同样存在于“计数”和“其他”类中。依据文献[5]分析,当层数大于10时“整体”精度和每个类型的精度都有所降低,是由于在训练期间梯度信息不稳定,进而导致模型优化困难。因此本文采用10层网络结构。
2.5 实验结果与分析
为验证VL-CMFNet模型能够提升答案预测的准确率,与目前5个优秀的算法BAN[23],DFAF[10],ReGAT[24],MCAN[5],MMnasNet[25]进行了对比。
BAN利用双线性注意网络,提取图像区域与问题词之间的双线性交互,并通过低秩双线性池化提取区域与单词之间的联合表示。
DFAF采用模态内和模态间交替在视觉和语言中交互,以提高模型预测能力。
ReGAT通过图注意力机制对每幅图像中的多类型对象间的关系进行建模,以学习问题与目标对象自适应的关系表示,从而提高模型预测精度。
MCAN利用深度协同注意力模块捕获两种模态自身特征和图像引导注意建模,进而提升模型答案预测准确率。
MMnasNet构建一个基于深度编码器-解码器的主干和适用于VQA的任务头,进而改善模型预测答案的准确率。
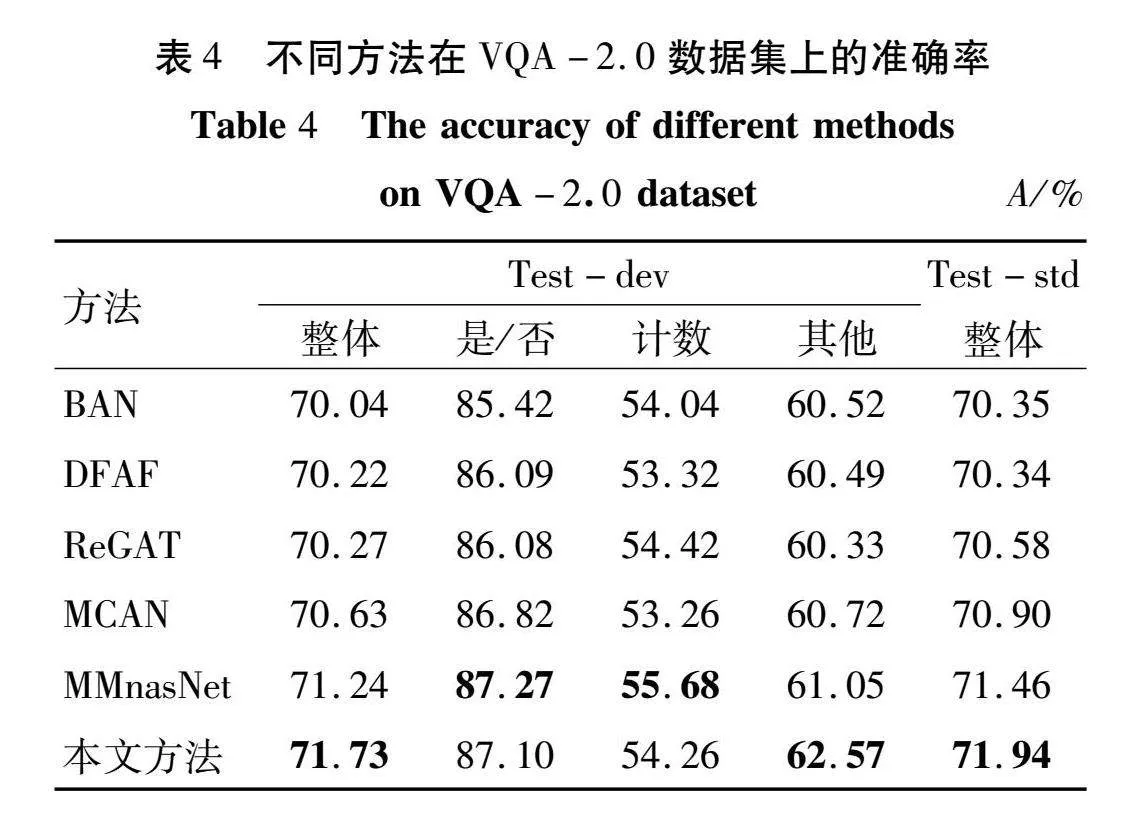
本文算法与其他5个算法在VQA-2.0数据集上准确率对比情况的详细数据如表4所示。
表4中加黑字体表示每个类型的最优精度。从表4可知,“整体”类的精度在Test-dev测试集上达到了71.73%,比BAN高出了1.69个百分点;在Test-std测试集上达到了71.94%,比DFAF高出了1.6个百分点。“整体”类型的精度均超越了目前5个优秀的算法。此外,“其他”类型的精度在Test-dev测试集上比ReGAT高出了2.24个百分点。与常用的基线任务MCAN相比,本文方法在两个测试集上“整体”精度分别提升了1.10和1.04个百分点,“计数”类型的精度提升了1.00个百分点,“其他”类型的精度提升了1.85个百分点;“是/否”类型的普遍准确率较高,本文方法同样能与其他5个方法保持在同一水平,相比基线任务仍有所提升。实验证明本文方法能够在VQA-2.0数据集上提升答案预测的准确率。
从各项实验结果可以看出,使用 DSA 的视觉编码器能够起到提升答案预测准确率的作用;具有门控机制的引导注意力和聚合模块能够在模态融合时起到过滤干扰信息和增强联合多模态特征表示能力的效果。综上,本文所提方法能够提升VQA模型答案预测的准确率。
3 结论
提出了基于视觉-语言特征编码的跨模态融合视觉问答方法,该方法采用了视觉-语言编码器与跨模态融合相结合的方式,利用编码器卓越的建模能力,使模型对单一特征内的关键信息建立关联关系,进而增加单一特征内关键信息的长依赖关系;在跨模态融合模块内采用双门控机制引导注意力,使模型具有“看”什么和“听”什么的能力,同时消除干扰信息并降低语言噪声;聚合模块再次增强联合特征的建模,进而提升多模态知识的学习能力。在VQA-2.0数据集上进行的实验验证表明本文所提方法能够提升答案预测的准确率,为提升多模态特征表示能力提供了一种可行的方法。同时,从本项工作中认识到VQA作为多模态任务不仅对单一模态关系建模重要,对视觉-语言两种模态的共同理解同样能够提升模型预测答案的能力。
参考文献
[1] XU P, ZHU X T, CLIFTON D A. Multimodal learning with transformers: a survey[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2023, 45(10): 12113-12132.
[2] 武阿明, 姜品, 韩亚洪. 基于视觉和语言的跨媒体问答与推理研究综述[J]. 计算机科学, 2021, 48(3): 71-78.
[3] LU J S, BATRA D, PARIKH D, et al. ViLBERT: pretraining task-agnostic visiolinguistic representations for vision-and-language tasks[EB/OL].(2019-08-06) http:∥arxiv.org/abs/1908.02265v1.
[4] TAN H, BANSAL M. LXMERT: learning cross-modality encoder representations from transformers[C]∥Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP). Stroudsburg, PA, USA: Association for Computational Linguistics, 2019: 5100-5111.
[5] YU Z, YU J, CUI Y H, et al. Deep modular co-attention networks for visual question answering[C]∥2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). IEEE, 2019: 6274-6283.
[6] FUKUI A, PARK D H, YANG D, et al. Multimodal compact bilinear pooling for visual question answering and visual grounding[C]∥Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing. Stroudsburg, PA, USA: Association for Computational Linguistics, 2016: 457-468.
[7] VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need[C]∥Proceedings of the 31st International Conferenceon Neural lnformation Processing Systems. 2017:5998-6008.
[8] HUANG Z C, ZENG Z Y, LIU B, et al. Pixel-BERT: aligning image pixels with text by deep multi-modal transformers[EB/OL].(2020-06-22) https://arxiv.org/abs/2004.00849.
[9] GAMAGE B M S V, HONG L C. Improved RAMEN: towards domain generalization for visual question answering[EB/OL].(2021-09-06) http://arxiv.org/abs/2109.02370v1.
[10]GAO P, JIANG Z K, YOU H X, et al. Dynamic fusion with intra- and inter-modality attention flow for visual question answering[C]∥2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). IEEE, 2019: 6639-6648.
[11]WEI X, ZHANG T Z, LI Y, et al. Multi-modality cross attention network for image and sentence matching[C]∥2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). IEEE, 2020: 10938-10947.
[12]LI J N, SELVARAJU R R, GOTMARE A D, et al. Align before fuse: vision and language representation learning with momentum distillation[EB/OL]. (2021-12-07) http:∥arxiv.org/abs/2107.07651v2.
[13]DOU Z Y, KAMATH A, GAN Z, et al. Coarse-to-fine vision-language pre-training with fusion in the backbone[C]∥Advances in Neural Information Processing Systems 35 (NeurIPS 2022), 2022: 32942-32956.
[14]王树徽, 闫旭, 黄庆明. 跨媒体分析与推理技术研究综述[J]. 计算机科学, 2021, 48(3): 79-86.
[15]LI Y W, SONG L, CHEN Y K, et al. Learning dynamic routing for semantic segmentation[C]∥2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). IEEE, 2020: 8550-8559.
[16]YANG L, HAN Y Z, CHEN X, et al. Resolution adaptive networks for efficient inference[C]∥2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). IEEE, 2020: 2366-2375.
[17]GOYAL Y, KHOT T, SUMMERS-STAY D, et al. Making the V in VQA matter: elevating the role of image understanding in visual question answering[C]∥2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). IEEE, 2017: 6325-6334.
[18]YAO T, LI Y H, PAN Y W, et al. Dual vision transformer[EB/OL]. (2022-07-11) https:∥arxiv.org/abs/2207.04976.
[19]HE K M, ZHANG X Y, REN S Q, et al. Deep residual learning for image recognition[C]∥2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). IEEE, 2016: 770-778.
[20]BA J L, KIROS J R, HINTON G E. Layer normalizati-on[EB/OL].(2021-07-21) https:∥arxiv.org/abs/1607.06450.
[21]ZHOU Y Y, JI R R, SUN X S, et al. K-armed bandit based multi-modal network architecture search for visual question answering[C]∥Proceedings of the 28th ACM International Conference on Multimedia. ACM, 2020: 1245-1254.
[22]ANTOL S, AGRAWAL A, LU J S, et al. VQA: visual question answering[C]∥2015 IEEE International Conference on Computer Vision (ICCV). IEEE, 2015: 2425-2433.
[23]KIM J H, JUN J, ZHANG B T. Bilinear attention networks[EB/OL]∥(2018-12-19)[2023-05-21] https:∥doi.org/10.48550/arXiv.1805.07932
[24]LI L J, GAN Z, CHENG Y, et al. Relation-aware graph attention network for visual question answering[C]∥2019 IEEE/CVF International Conference on Computer Vision (ICCV). IEEE, 2019: 10312-10321.
[25]YU Z, CUI Y H, YU J, et al. Deep multimodal neural architecture search[C]∥Proceedings of the 28th ACM International Conference on Multimedia. ACM, 2020: 3743-3752.
猜你喜欢
计算机应用(2019年3期)2019-07-31 12:14:01
无线互联科技(2019年9期)2019-07-29 00:41:36
无线互联科技(2019年9期)2019-07-29 00:41:36
智能计算机与应用(2019年3期)2019-07-01 02:35:55
智能计算机与应用(2019年3期)2019-07-01 02:35:55
智能计算机与应用(2019年3期)2019-07-01 02:35:55
电子技术与软件工程(2019年5期)2019-06-20 10:31:23
软件导刊(2019年1期)2019-06-07 15:08:13
数字技术与应用(2019年2期)2019-05-14 08:25:10
现代电子技术(2018年8期)2018-04-13 06:36:32
