
多视角图像与PP-YOLOE 结合的人群QR 码检测方法
2024-01-01 00:00:00张攀邓盼
宜宾学院学报 2024年6期
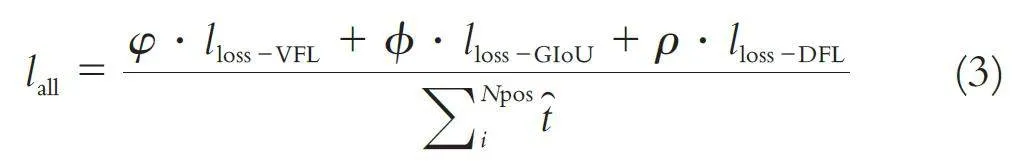


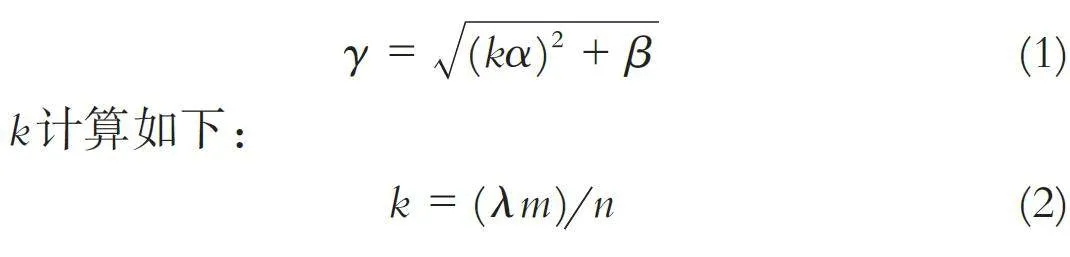
摘 要:现有目标检测系统在人群密集场景中无法有效实现尺寸极小快速响应码(QR 码)的批量自动化检测,为此,提出一种基于多视角图像与改进PP-YOLOE 模型的人群QR 码辅助检测方法:首先构建多视角图像采集系统,通过侧视图与顶视图图像完成多种目标归属主体的正确关联;随后在路径聚合网络(PAN)中增加跨层空间注意力模块,提升模型算法小目标检测能力;利用深度可分离卷积对RepResBlock 模块进行轻量化改进,提升模型算法执行效率. 与其他4 种算法的对比实验表明,最优有效目标检测准确率提高9.9%,单次可完成的检测数量达到13 个、单目标检测平均耗时72.5 ms.
关键词:PP-YOLOE;多视角图像;PAN;深度可分离卷积
中图分类号:TP391
DOI: 10.19504/j.cnki.issn1671-5365.2024.06.06
作为二维码之一的快速响应码(Quick Re⁃sponse Code, QR 码),是万物互联时代重要的信息载体之一,广泛应用于无纸化支付、物流快递标记、个人信息校验等场景. 当前针对单一QR 码的检测定位方法成熟,但当其面对密集QR 码时效果欠佳,尤其在车站、校园、展会等公共场合进行密集人群手持终端QR 码检测时,容易发生快速定位失效现象.作为典型的小目标检测问题,其检测定位受到两方面的挑战:一是QR 码在画面中的有效占比通常低于10%,导致深度卷积神经网络模型运算时获得的特征信息有限,容易出现漏检;二是实时性及多目标检测的需求,带来部署终端较大的算力消耗,造成较高的硬件成本. 对于前者,众多学者在通用多目标检测算法模型框架基础之上,针对小目标特征进行优化改进[1];对于后者,轻量化技术被广泛研究[2],模型运算量及参数量的逐步降低,带来高性能框架在边缘设备运行的可能.
对于深度卷积神经网络适配小目标检测的研究,主要集中于优化网络结构进行小尺度特征的提取与融合. 典型的改进是在通用目标检测模型基础上,添加更大分辨率的输出预测分支,如SSD 模型[3]通过在6 个不同分辨率的尺度分支上进行检测来降低小目标漏检概率;后来Fu 等人改进该模型的骨干网络,并利用特征金字塔(Feature Pyramid Network,FPN)[4]结构进行多级特征融合后形成DSSD 模型[5]提升小目标检测性能. 最近Tang 等人通过在其中引入卷积块注意力模块(Convolutional Block AttentionModule, CBAM),形成交互式通道空间注意力,实现卫星图像中车辆小目标的检测[6]. 此外,Ju 等人使用上下文机制[7]扩大有效特征区域,也提升了小目标检测效果.
对于深度卷积神经网络轻量化的研究,Howard等人在MobileNet 框架中创新地提出深度可分离卷积(Depthwise Convolution),大幅度降低传统卷积运算量和参数量[8],成为后续网络轻量化的标准操作.后续对MobileNet 框架的改进中,Sandler 等人增加了与残差结构相关联的倒残差结构[9],Howard 等人增加了注意力模块[10],最终形成系列化的模型框架.Iandola 等人则是将传统的大尺寸卷积过程替换为多个更小尺寸的卷积核的组合,并最终形成SqueezeNet 系列模型[11]. 在最新的研究中,Wiec⁃zorek 等人将大视野场景下人脸检测模型框架拆分为模糊人脸检测与确定人脸检测两个阶段,并将后一阶段的开启时机与前一阶段关联,进而宏观上使得模型框架轻量化[12].
1 多视角图像采集系统方案
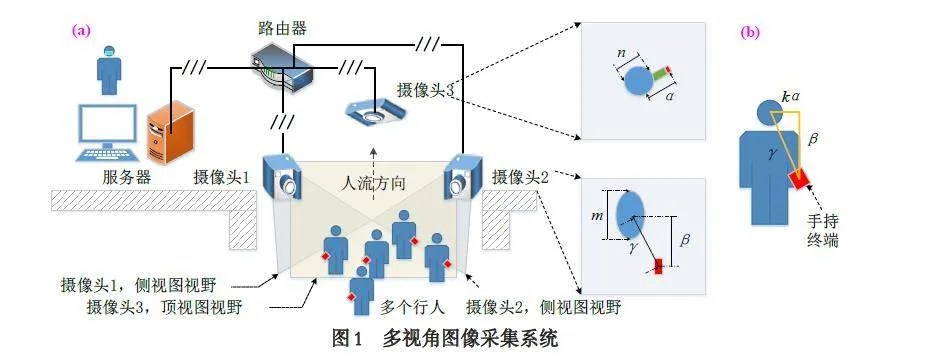
本文设计的多视角图像采集系统如图1(a)所示,主要包括3 个不同视角的摄像头及其网络连接所需路由器,以及执行算法的服务器. 摄像头1 与摄像头2 的视野分别从两个侧面向人群中心形成交叉,以满足QR 码采集方向的多样性. 摄像头3 置于人群正上方,获得顶视图视角下的视野. 侧面图像中会计算行人头部垂直长度m,及其与手持终端之间的垂直距离β 和直线距离γ. 顶视图视角的视野中主要包括行人头部、手臂、手持终端等信息,需要计算行人头部宽度n 及其与手持终端之间的水平距离α. 服务器运行基于PP-YOLOE 改进的小目标轻量化检测算法实现单帧图像中手持终端、行人整体、手臂、头部及QR 码的检测.
由于在侧面图像中进行行人手臂检测时,可能存在被遮挡而检测失效的问题,从而导致行人与手持终端的关联出错,为此本文中提出行人头部与手持终端的位置约束方法. 如图1(b)中所示,在侧面视图中,设定真实的行人头部与手持终端之间的水平距离为kα、垂直距离为β、直线距离为γ,三者近似满足约束关系:
其中λ 为实验统计参数,λ ∈ [ 0.32,0.81].
2 模型算法改进
2.1 PP-YOLOE 目标检测原理
结合通用单阶段目标检测模型在小目标检测与网络模型轻量化方面的最新研究进展,本文基于PP-YOLOE 模型进行轻量化改进. PP-YOLOE 是百度PaddleDetection 团队针对YOLO 系列单阶段目标检测模型的最新改进优化,其在COCO 数据集上的检测平均精确率达到51.4 mAP、在Tesla V100GPU 上的每秒测试帧率达到78.1 FPS,实现了目标检测精确率与效率的兼备[13]. 其模型主要在骨干网络中改进CSPRepResNet 结构、在特征金字塔结构后使用路径聚合网络(Path Aggregation Network,PAN)来进行多尺度特征融合、在检测输出头中提出ET-head (Efficient Task-aligned Head) 结构. CSP⁃RepResNet 骨干网络的核心在于RepResBlock 模块,该模块来自TreeBlock[14]的启发,将残差连接和稠密连接进行结合,更有效地提取目标特征. 路径聚合网络则是Liu 等人在图像分割中提出的一种特征融合机制,与过往单一方向融合不同尺度特征不同,其在上下两个方向都进行多尺度特征融合[15].ET-head 结构使用ESE (Effective Squeeze and Ex⁃traction) 代替TOOD (Task-aligned One-stage Ob⁃ject Detection)中的层注意力,简化分类分支,用分布焦点损失(Distribution Focal Loss, DFL)层[16]代替回归分支,进而协调过往目标检测模型中分类与定位任务之间的矛盾. 模型的总体损失函数lall 为:
其中:lloss - GIoU 为计算IoU 的损失函数值,lloss -VFL 为变焦距损失函数值,lloss -DFL 为分布焦点损失函数值,t̑代表标准化目标分数,φ、ϕ、ρ 等为超参数.
2.2 针对小目标检测的算法改进
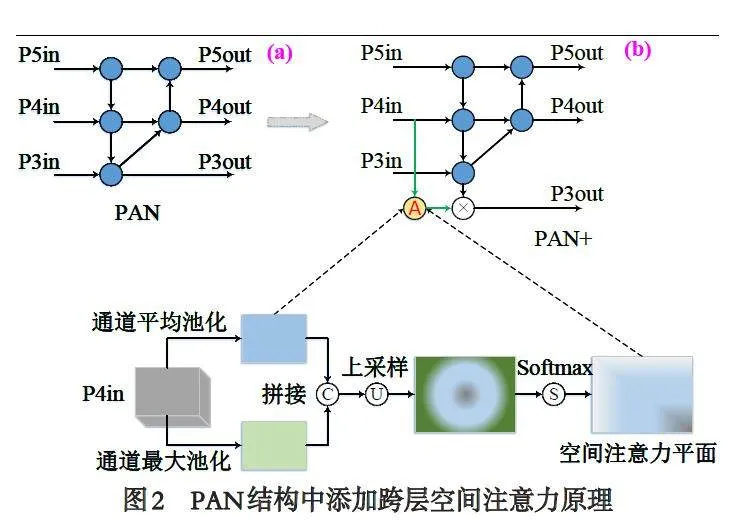
本文将空间注意力机制进行跨层连接,提升PP-YOLOE 框架对小目标的检测能力. 传统空间注意力机制通过对输入的特征图在多通道之间分别进行平均池化和最大池化,并将其输出的特征平面拼接后压缩为单通道特征平面,是一种同层间连接. 如图2(a)所示,PP-YOLOE 框架在P3、P4、P5 三个分支进行输出目标的多尺度预测,且本文场景中的QR 码目标尺寸极小,其主要在P3 分支中进行有效特征提取,同时P4 分支中将进行终端目标的检测. 由于终端目标与QR 码目标的位置总是直接关联,因此本文从P4 分支中进行空间注意力提取,并跨层连接到P3 层,辅助该分支中极小尺寸QR 码的有效检测,如图2(b)所示. 跨层连接时是对平均池化和最大池化输出特征平面的上采样.
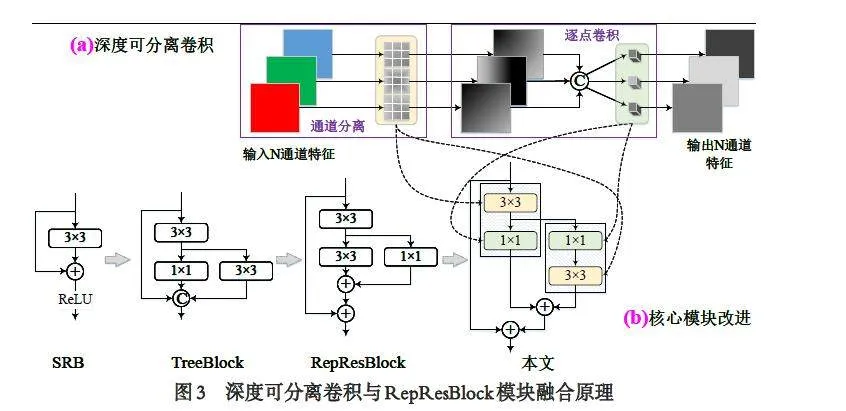
2.3 模型轻量化改进
本文将深度可分离卷积方法融入RepResBlock模块进行模型轻量化改进. 如图3(a)所示,深度可分离卷积将传统卷积运算拆分为通道分离卷积和逐点卷积两个过程,前者要求每个3×3 卷积核只对一个特征通道进行卷积运算,获得平面特征,后者将多通道特征拼接之后利用多维度的1×1 卷积核进行通道间特征的关联,该方法使得参数规模可以降低约30%. 从图3(b)中可以看出,RepResBlock 模块、Tree⁃Block 模块、SRB 模块中都使用3×3 卷积核提取特征,并直接进行残差连接、1×1 卷积核残差连接、或两种组合方式的残差连接. 本文具体融合时,RepResBlock 模块中的第一个3×3 卷积过程替换为先进行分离通道卷积,后进行逐点卷积,且此时的逐点卷积也起到残差连接作用. 第二个3×3 卷积过程则替换为先进行逐点卷积,后进行分离通道卷积,且第二个深度可分离卷积过程的输入数据是第一个卷积核分离通道卷积后的输出,进而使得两个深度可分离卷积过程可有效联合.
3 实验及结果分析
3.1 数据集及评价指标
按照图1 所示搭建实验环境,算法服务器配置为RTX2060 显卡、16 GB 内存. 采集的数据样本如图4(a)、图4(b)所示,使用labelme 工具完成行人整体、头部、手臂、手持终端、QR 码等目标的边界框标注. 其共包含11750 个有效行人及其相关目标,其中左右侧视图采集的样本数量整体均衡. 另一个数据集如图4(c)所示,包含22 000 个QR 码图像,用于对模型的QR 码识别能力的预训练.
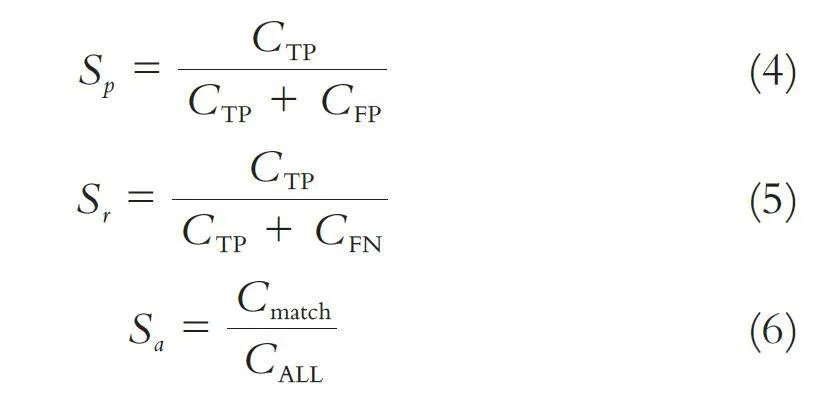
算法结合工程应用场景,设置5 个评价指标. 指标Sp 完成所有可检测目标,在IoU 为0.75 时的精确率计算,以统计正确预测的样本数在被预测到的样本总数中的占比;指标Sr 完成所有可检测目标,在IoU 为0.75 时的召回率的计算,以统计被正确预测的样本数在应当被预测的样本数中的占比;指标Sa用于表示有效核心目标检测数量Cmatch 在总目标数量CALL 中的占比,核心目标的有效性是指正确将行人、QR 码进行关联;指标4 是系统单次可完成的有效核心目标检测数量的最大值Mmax _match;指标5 为tFPS,用于衡量系统检测单个核心目标时的耗时. Sp、Sr 与Sa 计算如下:
其中CTP 表示正确样本被预测为正,CFP 表示错误样本被预测为正,CFN 表示错误样本被预测为负.
3.2 结果分析
对比实验分别选择PP-YOLOE、DSSD[4]、YO⁃LOv3 tiny[17]、YOLOv6[18]算法. YOLOv3 tiny 算法是YOLOv3 模型的缩减版本,损失了部分准确率,但执行效率更高. YOLOv6 是YOLO 系列的改进之一,其将此前的相关模型的有锚范式替换为无锚范式,并在骨干网络中使用RepVGG style 结构,使得模型对硬件性能要求降低. DSSD 算法是在SSD 算法基础上,使用沙漏结构进行编解码,提高对小目标的检测性能.
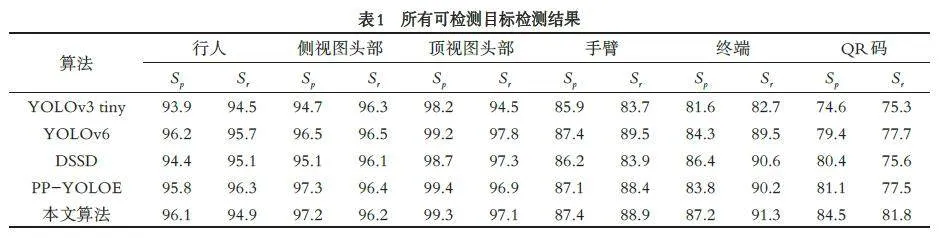
所有可检测目标实验对比结果如表1 所示. 由于大多数行人尺寸相对较大,全部算法对行人检测的性能相当,但不可避免的行人遮挡也导致少量的漏检,同时两个侧方位相机拍摄图像中包含大量行人背面信息,也造成部分错检. 对于中等尺寸的头部的检测,本文算法及PP-YOLOE 算法的性能最佳. 由于行人手臂的无规则运动,所有算法都存在错检与漏检手臂. 对于尺寸较小的终端的检测,本文算法与DSSD 算法获得较好结果,PP-YOLOE 算法与YOLOv6 算法的检测召回率也较高,但精确率相对降低,表明这些算法存在较小尺寸目标的错检,多是将终端检测为QR 码. 对于极小尺寸QR 码的检测,本文算法的精确率优于对比算法中最高值3.4%,召回率优于对比算法中最高值4.1%,这是由于其他算法存在QR 码与终端的混淆以及QR 码的漏检.
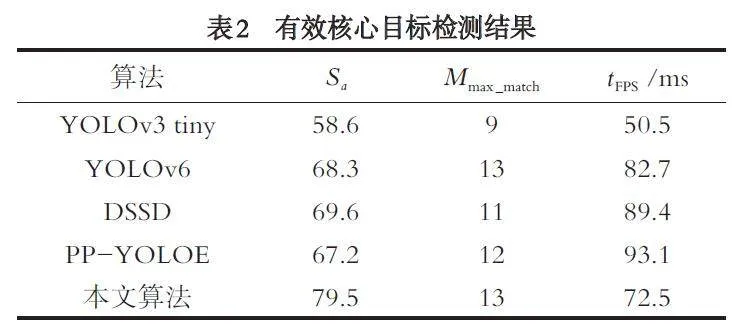
多种算法对有效核心目标的检测结果见表2.本文算法准确率为79.5%,其单次最多可完成13 个有效目标检测,且单目标检测平均耗时为72.5 ms.YOLOv3 tiny 算法获得最优的单目标检测平均时间消耗,但准确率也相对最低,这是由该模型的轻量化裁剪导致的. DSSD 与PP-YOLOE 算法获得较高的准确率,但其相对耗时更多,两者算法中增加的模型结构改善了小目标检测效果,但也带来运算量的增加. YOLOv6 算法的检测准确率与平均耗时相对平衡. 对比可视化结果如图5 所示,本文算法完成了画面中所有10 个目标的检测定位,其他算法都存在目标漏检,其中DSSD 算法仅漏检1 个目标,YOLOv6算法漏检2 个目标,YOLOv3 tiny 与PP-YOLOE 算法都漏检了3 个目标,但后者检测框精度更高.
4 结语
在人群密集场景中实现批量QR 码的检测,具有重要的工程价值,本文针对其中尺寸较小QR 码的实时有效检测困难的问题,构建了以PP-YOLOE模型为基础的人群QR 码辅助检测系统. 系统以PP-YOLOE 模型为尺度跨度较大多类别目标检测的基础. 针对多种目标归属主体的关联问题,提出一种多视角的图像采集系统及其关联约束算法. 通过改进传统空间注意力模块,并添加到PP-YOLOE模型的PAN 网络的两个相邻层中,实现对小目标检测的优化. 结合骨干网络中RepResBlock 模块特征和深度可分离卷积计算过程,实现网络模型的轻量化,在降低算法参数量的同时,提高执行效率. 最终实现密集人群QR 码的实时准确检测. 但受到遮挡现象的干扰,多目标检测及多视角目标主体关联时可能产生错误,其带来的算法模型漏检、错检问题是下一步研究的重点.
参考文献:
[1] 杜紫薇, 周恒, 李承阳, 等. 面向深度卷积神经网络的小目标检测算法综述[J]. 计算机科学, 2022, 49(12): 205-218.
[2] 毕鹏程, 罗健欣, 陈卫卫. 轻量化卷积神经网络技术研究[J]. 计算机工程与应用, 2019, 55(16): 25-35.
[3] LIU W, ANGUELOV D, ERHAN D, et al. SSD: Singleshot multibox detector[C]//Leibe B, Matas J, Sebe N, et al.Computer Vision – ECCV 2016. Springer, 2016: 21-37.doi: 10.1007/978-3-319-46448-0_2.
[4] LIN T Y, DOLLÁR P, GIRSHICK R. Feature PyramidNetworks for Object Detection[C]//The 2017 IEEE Confer⁃ence on Computer Vision and Pattern Recognition, Hono⁃lulu: IEEE, 2017: 936-944. doi: 10.1109/CVPR.2017.106.
[5] FU C Y, LIU W, RANGA A, et al. DSSD: Deconvolutionalsingle shot detector[EB/OL]. 2017-01-23. arXiv:1701.06659.
[6] TANG T, WANG Y, LIU H, et al. CFAR-guided dualstreamsingle-shot multibox detector for vehicle detection inSAR images[J]. IEEE Geoscience and Remote Sensing Let⁃ters, 2022(19): 1-5. doi: 10.1109/LGRS.2022.3186075.
[7] JU M, LUO J N, WANG Z B, et al. Adaptive feature fusionwith attention mechanism for multi-scale target detection[J].Neural Computing and Applications, 2021, 33(7): 2769-2781. doi: 10.1007/s00521-020-05150-9.
[8] HOWARD A G, ZHU M, CHEN B, et al. Mobilenets: Effi⁃ficient convolutional neural networks for mobile vision appli⁃cations[EB/OL]. 2017-04-17. arXiv:1704.04861.
[9] SANDLER M, HOWARD A, ZHU M, et al. Mobile⁃NetV2: Inverted residuals and linear bottlenecks[C]//2018IEEE/CVF Conference on Computer Vision and PatternRecognition, Salt Lake City: IEEE, 2018: 4510-4520. doi:10.1109/CVPR.2018.00474.
[10] HOWARD A, SANDLER M, CHEN B, et al. Searching formobilenetv3[C]//2019 IEEE/CVF International Conferenceon Computer Vision. Seoul: IEEE, 2019: 1314-1324. doi:10.1109/ICCV.2019.00140.
[11] IANDOLA F N, HAN S, MOSKEWICZ M W, et al.SqueezeNet: AlexNet-level accuracy with 50x fewer param⁃eters and lt; 0.5 MB model size[EB/OL]. 2016-02-24. arXiv:1602.07360.
[12] WIECZOREK M, SIŁKA J, WOŹNIAK M, et al. Lightweightconvolutional neural network model for human face detectionin risk situations[J]. IEEE Transactions on Industrial Informatics,2021, 18(7): 4820-4829. doi: 10.1109/TII.2021.3129629.
[13] XU S, WANG X, LV W, et al. PP-YOLOE: An evolvedversion of YOLO[EB/OL]. 2022-03-30. arXiv:2203.16250.
[14] RAO L. TreeNet: A lightweight one-shot aggregation con⁃volutional network[EB/OL]. 2021-09-25. arXiv:2109.12342.
[15] LIU S, QI L, QIN H, et al. Path aggregation network for in⁃stance segmentation[C]//2018 IEEE/CVF Conference onComputer Vision and Pattern Recognition. Salt Lake City:IEEE, 2018: 8759-8768. doi: 10.1109/CVPR.2018.00 913.
[16] LI X, WANG W, WU L, et al. Generalized focal loss: Learn⁃ing qualified and distributed bounding boxes for dense objectdetection[EB/OL]. 2020-06-08. arXiv:2006.04388.
[17] REDMON J, FARHADI A. YOLOv3: An incremental im⁃provement[EB/OL]. 2018-04-08. arXiv:1804.02767.
[18] LI C, LI L, JIANG H, et al. YOLOv6: A single-stage objectdetection framework for industrial applications[EB/OL].2022-09-07. arXiv:2209.02976.
【编校:王露】
基金项目:内江市东兴区经济和信息化局科研项目(QKJ202103)
